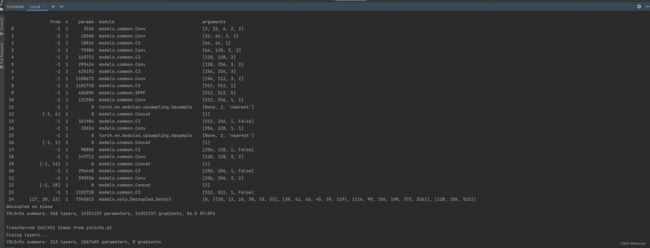
YOLOv5-7.0添加解耦头
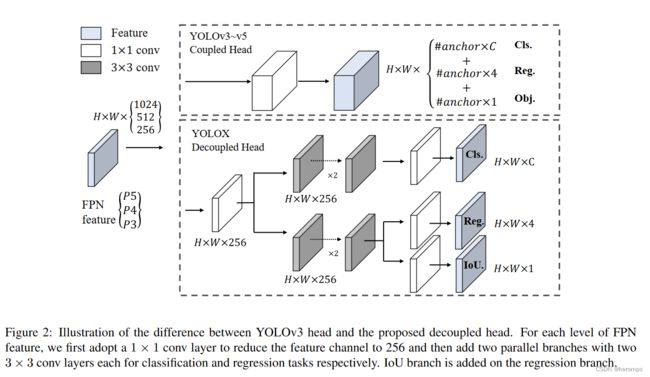
Decoupled Head
Decoupled Head是由YOLOX提出的用来替代YOLO Head,可以用来提升目标检测的精度。那么为什么解耦头可以提升检测效果呢?
在阅读YOLOX论文时,找到了两篇引用的论文,并加以阅读。
第一篇文献是Song等人在CVPR2020发表的“Revisiting the Sibling Head in Object Detector”。
这篇论文中提出了,在目标检测任务的定位和分类任务中,存在spatial misalignment问题,即两个任务所聚焦和感兴趣的地方不同,分类更加关注所提取的特征与已有的类别哪一类更为相近,定位则更加关注与GT Box的位置坐标从而进行边界修正。因此如果采用一个特征图进行分类和定位,效果会不好,产生所谓的spatial misalignment问题。
第二篇文献是Wu等人(也是旷视的团队)在CVPR2020发表的“Rethinking Classification and Localization for Object Detection”
这篇论文重新对检测任务中的分类和定位两个子任务进行解读,结果发现:fc-head更适合分类任务,conv-head更适合定位任务。
总的来说,解耦头考虑到分类和定位所关注的内容不同,所以采用不同的分支进行计算,有利于提升效果!
YOLOv5-7.0引入解耦头
解耦头的网络结构如下图所示:
2.1 修改common.py文件
在common.py文件中加解耦头代码
class DecoupledHead(nn.Module):
def __init__(self, ch=256, nc=80, anchors=()):
super().__init__()
self.nc = nc # number of classes
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.merge = Conv(ch, 256 , 1, 1)
self.cls_convs1 = Conv(256 , 256 , 3, 1, 1)
self.cls_convs2 = Conv(256 , 256 , 3, 1, 1)
self.reg_convs1 = Conv(256 , 256 , 3, 1, 1)
self.reg_convs2 = Conv(256 , 256 , 3, 1, 1)
self.cls_preds = nn.Conv2d(256 , self.nc * self.na, 1)
self.reg_preds = nn.Conv2d(256 , 4 * self.na, 1)
self.obj_preds = nn.Conv2d(256 , 1 * self.na, 1)
def forward(self, x):
x = self.merge(x)
x1 = self.cls_convs1(x)
x1 = self.cls_convs2(x1)
x1 = self.cls_preds(x1)
x2 = self.reg_convs1(x)
x2 = self.reg_convs2(x2)
x21 = self.reg_preds(x2)
x22 = self.obj_preds(x2)
out = torch.cat([x21, x22, x1], 1)
return out
2.2 修改yolo.py文件
修改完common.py文件后,需要修改yolo.py文件。
- 在yolo.py添加Decoupled_Detect代码
class Decouple(nn.Module):
# Decoupled convolution
def __init__(self, c1, nc=80, na=3): # ch_in, num_classes, num_anchors
super().__init__()
c_ = min(c1, 256) # min(c1, nc * na)
self.na = na # number of anchors
self.nc = nc # number of classes
self.a = Conv(c1, c_, 1)
c = [int(x + na * 5) for x in (c_ - na * 5) * torch.linspace(1, 0, 4)] # linear channel descent
self.b1, self.b2, self.b3 = Conv(c_, c[1], 3), Conv(c[1], c[2], 3), nn.Conv2d(c[2], na * 5, 1) # vc
self.c1, self.c2, self.c3 = Conv(c_, c_, 1), Conv(c_, c_, 1), nn.Conv2d(c_, na * nc, 1) # cls
def forward(self, x):
bs, nc, ny, nx = x.shape # BCHW
x = self.a(x)
b = self.b3(self.b2(self.b1(x)))
c = self.c3(self.c2(self.c1(x)))
return torch.cat((b.view(bs, self.na, 5, ny, nx), c.view(bs, self.na, self.nc, ny, nx)), 2).view(bs, -1, ny, nx)
class Decoupled_Detect(nn.Module):
stride = None # strides computed during build
onnx_dynamic = False # ONNX export parameter
export = False # export mode
def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer
super().__init__()
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.grid = [torch.zeros(1)] * self.nl # init grid
self.anchor_grid = [torch.zeros(1)] * self.nl # init anchor grid
self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)
self.m=nn.ModuleList(Decouple(x, self.nc, self.na) for x in ch) #yolov5 provide , old Decouple too much FLOP
self.inplace = inplace # use in-place ops (e.g. slice assignment)
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
y = x[i].sigmoid()
if self.inplace:
y[..., 0:2] = (y[..., 0:2] * 2 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
xy, wh, conf = y.split((2, 2, self.nc + 1), 4) # y.tensor_split((2, 4, 5), 4) # torch 1.8.0
xy = (xy * 2 + self.grid[i]) * self.stride[i] # xy
wh = (wh * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, conf), 4)
z.append(y.view(bs, -1, self.no))
return x if self.training else (torch.cat(z, 1),) if self.export else (torch.cat(z, 1), x)
def _make_grid(self, nx=20, ny=20, i=0, torch_1_10=check_version(torch.__version__, '1.10.0')):
d = self.anchors[i].device
t = self.anchors[i].dtype
shape = 1, self.na, ny, nx, 2 # grid shape
y, x = torch.arange(ny, device=d, dtype=t), torch.arange(nx, device=d, dtype=t)
yv, xv = torch.meshgrid(y, x, indexing='ij') if torch_1_10 else torch.meshgrid(y, x) # torch>=0.7 compatibility
grid = torch.stack((xv, yv), 2).expand(shape) - 0.5 # add grid offset, i.e. y = 2.0 * x - 0.5
anchor_grid = (self.anchors[i] * self.stride[i]).view((1, self.na, 1, 1, 2)).expand(shape)
return grid, anchor_grid
- 在BaseModel类中中修改代码,加入解耦头检测
def _apply(self, fn):
# Apply to(), cpu(), cuda(), half() to model tensors that are not parameters or registered buffers
self = super()._apply(fn)
m = self.model[-1] # Detect()
if isinstance(m, (Detect, Segment,Decoupled_Detect)):
m.stride = fn(m.stride)
m.grid = list(map(fn, m.grid))
if isinstance(m.anchor_grid, list):
m.anchor_grid = list(map(fn, m.anchor_grid))
return self
- 在DetectionModel中修改代码
def _initialize_dh_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
# https://arxiv.org/abs/1708.02002 section 3.3
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
m = self.model[-1] # Detect() module
for mi, s in zip(m.m, m.stride): # from
# reg_bias = mi.reg_preds.bias.view(m.na, -1).detach()
# reg_bias += math.log(8 / (640 / s) ** 2)
# mi.reg_preds.bias = torch.nn.Parameter(reg_bias.view(-1), requires_grad=True)
# cls_bias = mi.cls_preds.bias.view(m.na, -1).detach()
# cls_bias += math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # cls
# mi.cls_preds.bias = torch.nn.Parameter(cls_bias.view(-1), requires_grad=True)
b = mi.b3.bias.view(m.na, -1)
b.data[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
mi.b3.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
b = mi.c3.bias.data
b += math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # cls
mi.c3.bias = torch.nn.Parameter(b, requires_grad=True)
if isinstance(m, (Detect, Segment,ASFF_Detect)):
s = 256 # 2x min stride
m.inplace = self.inplace
forward = lambda x: self.forward(x)[0] if isinstance(m, Segment) else self.forward(x)
m.stride = torch.tensor([s / x.shape[-2] for x in forward(torch.zeros(1, ch, s, s))]) # forward
check_anchor_order(m)
m.anchors /= m.stride.view(-1, 1, 1)
self.stride = m.stride
self._initialize_biases() # only run once
elif isinstance(m, Decoupled_Detect):
s = 256 # 2x min stride
m.inplace = self.inplace
m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forward
check_anchor_order(m) # must be in pixel-space (not grid-space)
m.anchors /= m.stride.view(-1, 1, 1)
self.stride = m.stride
self._initialize_dh_biases() # only run once
- 修改parse_model
elif m in {Detect, Segment,Decoupled_Detect}:
args.append([ch[x] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
if m is Segment:
args[3] = make_divisible(args[3] * gw, 8)
2.3 修改模型的yaml文件
在模型的yaml文件中修改最后一层检测头的结构,把检测头修改为解耦头
# YOLOv5 by Ultralytics, GPL-3.0 license
# Parameters
nc: 8 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v7.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v7.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
# [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
[ [ 17, 20, 23 ], 1, Decoupled_Detect, [ nc, anchors ] ], # Detect(P3, P4, P5)
]
接着训练YOLOv5s,如下图所示:
python train.py --workers 8\
--cache \
--cfg yolov5s.yaml \
--epochs 300\
--img 800\
--batch-size 16\
--data ' '\
--weights yolov5s.pt\
--hyp data/hyps/hyp.scratch-low.yaml\
--name yolov5s_decoupled_head\