Apache Kudu入门学习
目录
一、概念
二、背景
三、特点
四、架构
五、应用场景
六、kudu的模式设计
1、列设计
2、主键设计
3、分区设计
1.范围分区Range Partitioning
2.哈希分区Hash Partitioning
3.多级分区Multilevel Partitioning
一、概念
官方概念:
Apache Kudu is an open source distributed data storage engine that makes fast analytics on fast and changing data easy.
Apache Kudu 是一个开源分布式数据存储引擎,可以轻松地对快速变化的数据进行快速分析。
官网地址:
Apache Kudu - Fast Analytics on Fast Data

二、背景
在 KUDU 之前,大数据主要以两种方式存储:
- 静态数据:以 HDFS 引擎作为存储引擎,适用于高吞吐量的离线大数据分析场景。这类存储的局限性是数据无法进行随机的读写。
- 动态数据:以 HBase、Cassandra 作为存储引擎,适用于大数据随机读写场景。这类存储的局限性是批量读取吞吐量远不如 HDFS,不适用于批量数据分析的场景。
当面对既需要随机读写,又需要批量分析的大数据场景时,方案如下:
数据实时写入 HBase,HBase 完成实时的数据更新 ,定时(通常是 T+1 或者 T+H)将 HBase 数据写成静态的文件(如:Parquet)导入到 OLAP 引擎(如:HDFS)。
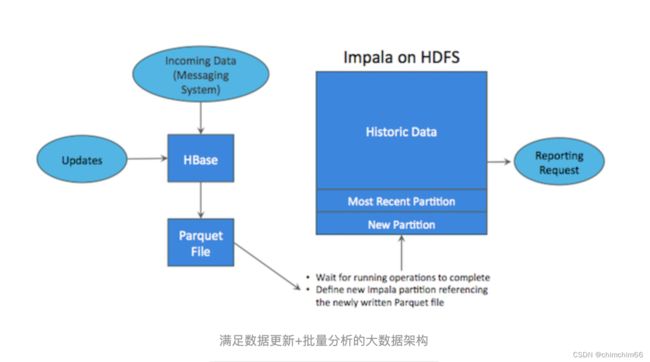
但是也有很多缺点:
- 架构复杂。从架构上看,数据在 HBase、消息队列、HDFS 间流转,涉及环节太多,运维成本很高。最后数据在多个系统上,对数据安全策略、监控等都提出了挑战。
- 维护成本高。用户需要在两套系统间编写和维护复杂的ETL逻辑。
- 存储资源浪费。两套存储系统意味着占用的磁盘资源翻倍了,造成了成本的提升。并且每个环节需要保证高可用,都需要维护多个副本,存储空间也有一定的浪费。
- 时效性低。数据从 HBase 导出成静态文件是周期性的,一般这个周期是一天(或一小时),在时效性上不是很高。
- 难以应对后续的更新。真实场景中,总会有数据是「延迟」到达的。如果这些数据之前已经从 HBase 导出到 HDFS,新到的变更数据就难以处理了,一个方案是把原有数据应用上新的变更后重写一遍,但这代价又很高。
基于HDFS的存储技术,比如Parquet,具有高吞吐量连续读取数据的能力;而HBase和Cassandra等技术适用于低延迟的随机读写场景。Kudu的设计,就是试图在实时分析与随机读写之间,寻求一个最佳的结合。在Cloudera发布的《Kudu: New Apache Hadoop Storage for Fast Analytics on Fast Data》一文中有提及,Kudu作为一个新的分布式存储系统也是为了进一步提升CPU的适用效率。
KUDU 的定位是 「Fast Analytics on Fast Data」,是一个既支持随机读写、又支持 OLAP 分析的大数据存储引擎。

三、特点
-
快速处理 OLAP 工作负载。
-
强大但灵活的一致性模型,允许您基于每个请求选择一致性要求,包括严格序列化一致性的选项。
-
结构化数据模型。
-
同时运行顺序和随机工作负载的强大性能。
-
与 Apache Impala 紧密集成,使其成为将 HDFS 与 Apache Parquet 结合使用的良好、可变的替代方案。
-
与 Apache NiFi 和 Apache Spark 集成。
-
与 Hive Metastore (HMS) 和 Apache Ranger 集成以提供细粒度的授权和访问控制。
-
经过身份验证和加密的 RPC 通信。
-
高可用:Tablet Servers 和 Masters 使用Raft Consensus Algorithm,保证只要有超过一半的 tablet 副本可用,tablet 就可以读写。例如,如果 3 个副本中有 2 个(或 5 个副本中的 3 个等)可用,则平板电脑可用。即使在领导者副本发生故障的情况下,只读跟随者平板副本也可以为读取提供服务。
-
故障自动检测和自我修复:为了保持数据的高可用性,系统会检测故障的 Tablet 副本并从可用的副本中重新复制数据,因此当集群中有足够的 Tablet Server 可用时,会自动替换故障的副本。
-
位置感知(也称为机架感知)以在相关故障的情况下保持系统可用,并允许 Kudu 集群跨越多个可用区。
-
逻辑备份(完整和增量)和还原。
-
多行事务(仅适用于 Kudu 1.15 版本的 INSERT/INSERT_IGNORE 操作)。
-
易于管理和管理。
四、架构
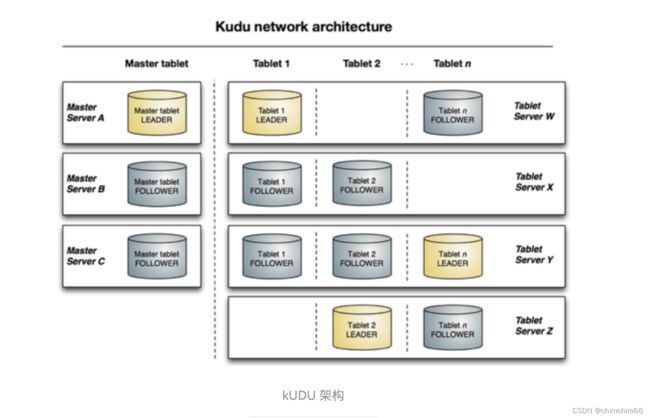
KUDU 中存在两个角色
- Mater Server:负责集群管理、元数据管理等功能。即tablet和表的基本信息,监听TServer的状态,TMaster之间通过raft协议进行数据同步。
- Tablet Server:负责数据存储,并提供数据读写服务。tablet 负责这一张表的某块内容的读写,接受其他tablet leader 传来的同步信息。
Table(表)
一张talbe是数据存储在Kudu的tablet server中。表具有 schema 和全局有序的primary key(主键)。table 被分成称为 tablets 的 segments。
Tablet
一个 tablet 是一张 table连续的segment,tablet是kudu表的水平分区,类似于google Bigtable的tablet,或者HBase的region。每个tablet存储着一定连续range的数据(key),且tablet两两间的range不会重叠。一张表的所有tablet包含了这张表的所有key空间。与其它数据存储引擎或关系型数据库中的 partition(分区)相似。给定的tablet 冗余到多个 tablet 服务器上,并且在任何给定的时间点,其中一个副本被认为是leader tablet。任何副本都可以对读取进行服务,并且写入时需要在为 tablet 服务的一组 tablet server之间达成一致性。
KUDU 的核心对外 API 主要分为写跟读两部分
- 写:Insert、Update、Delete,所有写操作都必须指定主键。
- 读 : Scan 操作,Scan 时用户可以指定一个或多个过滤器,用于过滤数据。
五、应用场景
- Strong performance for both scan and random access to help customers simplify complex hybrid architectures(适用于那些既有随机访问,也有批量数据扫描的复合场景)
- High CPU efficiency in order to maximize the return on investment that our customers are making in modern processors(高计算量的场景)
- High IO efficiency in order to leverage modern persistent storage(使用了高性能的存储设备,包括使用更多的内存)
- The ability to update data in place, to avoid extraneous processing and data movement(支持数据更新,避免数据反复迁移)
- The ability to support active-active replicated clusters that span multiple data centers in geographically distant locations(支持跨地域的实时数据备份和查询)
六、kudu的模式设计
1、列设计
编码类型

列压缩格式
kudu允许的压缩算法是LZ4、Snappy、zlib(gz)。默认情况下,kudu不压缩数据。通常情况下,压缩算法会提高空间利用率,但是会降低scan性能。
2、主键设计
同RDBMS一样,kudu的主键同样采用了唯一性约束。 一旦主键创建了之后便不能更改。
每个kudu表有且仅有一个由一列或多列组成的主键。主键列必须不可为空,并且不能使用bool或者浮点类型。
3、分区设计
1.范围分区Range Partitioning
范围分区的分区方式将数据按照范围进行分类,每个partition会分配一个固定的范围,每个数据只会属于一个分区,不同的partition的范围不能有重叠,分区在表的创建阶段配置,后续不可修改,但是可以删除和新增,如果数据找不到所属的分区将会插入失败。
Range Partitioning 的优势是在数据进行批量读的时候,可以把大部分的读变成同一个 tablet 中的顺序读,能够提升数据读取的吞吐量。并且按照范围进行分区,我们可以很方便的进行分区扩展。其劣势是同一个范围内的数据写入都会落在单个 tablet 上,写的压力大,速度慢。
2.哈希分区Hash Partitioning
hash分区将行通过hash值分配到其中一个存储桶(buckets)中,在single-level hash partitioned tables(单机散列分区表)中,每个存储桶将对应一个tablet。在创建表的时候设置桶数。通常,主键列用作散列的列,但与范围分区一样,可以使用主键列的任何子集。
数据的写入会被均匀的分散到各个 tablet 中,写入速度快。但是对于顺序读的场景这一策略就不太适用了,因为数据分散,一次顺序读需要将各个 tablet 中的数据分别读取并组合,吞吐量低。并且 Hash 分区无法应对分区扩展的情况。
3.多级分区Multilevel Partitioning
kudu支持多层的分区方式,将hash分区和范围分区结合起来。
分区修剪(调优)
当可以通过扫描谓词确定分区可以完全过滤时,Kudu扫描将自动跳过扫描整个分区。要删除哈希分区,扫描必须在每个哈希列上包含相等谓词。要删除范围分区,扫描必须在范围分区列上包含相等或范围谓词。在多级别分区表上的扫描可以独立地利用任何级别上的分区修剪。