【深度学习】Attention is all you need
1.前言
Transformer是谷歌大脑在2017年底发表的论文attention is all you need中所提出的seq2seq模型。BERT和GPT就是从Transformer中衍生出来的预训练语言模型,Bert 中训练的是双向语言模型,应用了 Transformer Encoder 部分。GPT 中训练的是单向语言模型,应用 Transformer Decoder部分。
2.Transformer
Transformer和LSTM的最大区别,就是LSTM的训练是迭代的、串行的,必须要等当前字处理完,才可以处理下一个字。而Transformer的训练却是并行的,即所有字是同时训练的,这样就大大增加了计算效率。Transformer使用了位置嵌入(Positional Encoding)来理解语言的顺序,使用自注意力机制(Self Attention Mechanism)和全连接层进行计算。
Transformer模型主要分为两大部分,分别是Encoder和Decoder。Encoder负责把输入(语言序列)隐射成隐藏层(下图中第2步用九宫格代表的部分),然后解码器再把隐藏层映射为自然语言序列。

2-1 Transformer Encoder

2-1-1 Positional Encoding
由于Transformer模型没有循环神经网络的迭代操作, 所以我们必须提供每个字的位置信息给Transformer,这样它才能识别出语言中的顺序关系。Positional Encoding(位置嵌入),位置嵌入的维度为,![]() 位置嵌入的维度与词向量的维度是相同的,都是
位置嵌入的维度与词向量的维度是相同的,都是![]() 。
。![]() 属于超参数,指的是限定每个句子最长由多少个词构成。
属于超参数,指的是限定每个句子最长由多少个词构成。
我们一般以字为单位训练Transformer模型。首先初始化字编码的大小为![]() ,
,![]() 为字库中所有字的数量,
为字库中所有字的数量,![]() 为字向量的维度,对应到Torch中,其实就是
为字向量的维度,对应到Torch中,其实就是![]() ,论文中使用了sin和cos函数的线性变换来提供给模型位置信息。
,论文中使用了sin和cos函数的线性变换来提供给模型位置信息。

pos指的是一句话中某个字的位置,取值范围是 [0,max_sequence_length ) ,i指的是字向量的维度序号,取值范围是 [0,embedding_dimension/2)。![]() 指的是embedding_dimension的值。
指的是embedding_dimension的值。
sin和cos的一组公式,也就对应着embedding dimension维度的一组奇数和偶数的序号的维度,例如0,1为一组、2,3为一组,分别用sin和cos函数做处理,从而产生不同的周期性变化,而位置嵌入在embedding dimension维度上随着维度序号增大,周期变化会越来越慢,最终产生一种包含位置信息的纹理,就像论文原文中第六页讲的,位置嵌入函数的周期从 2 π 到 10000 ∗ 2 π变化,而每一个位置在embedding dimension维度上都会得到不同周期的sin和cos函数的取值组合,从而产生独一的纹理位置信息,最终使得模型学到位置之间的依赖关系和自然语言的时序特性。
下面画一下位置嵌入,纵向观察,随着embedding dimension序号增大,位置嵌入函数的周期变化越来越平缓。
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import math
def get_positional_encoding(max_seq_len, embed_dim):
# 初始化一个positional encoding
# embed_dim: 字嵌入的维度
# max_seq_len: 最大的序列长度
positional_encoding = np.array([
[pos / np.power(10000, 2 * i / embed_dim) for i in range(embed_dim)]
if pos != 0 else np.zeros(embed_dim) for pos in range(max_seq_len)])
positional_encoding[1:, 0::2] = np.sin(positional_encoding[1:, 0::2]) # dim 2i 偶数
positional_encoding[1:, 1::2] = np.cos(positional_encoding[1:, 1::2]) # dim 2i+1 奇数
return positional_encoding
positional_encoding = get_positional_encoding(max_seq_len=100, embed_dim=16)
plt.figure(figsize=(10,10))
sns.heatmap(positional_encoding)
plt.title("Sinusoidal Function")
plt.xlabel("hidden dimension")
plt.ylabel("sequence length")plt.figure(figsize=(8, 5))
plt.plot(positional_encoding[1:, 1], label="dimension 1")
plt.plot(positional_encoding[1:, 2], label="dimension 2")
plt.plot(positional_encoding[1:, 3], label="dimension 3")
plt.legend()
plt.xlabel("Sequence length")
plt.ylabel("Period of Positional Encoding")
2-1-2 Self Attention Mechanism
对于输入的句子X,通过WordEmbedding得到该句子中每个字的字向量,同时通过Positional Encoding得到所有字的位置向量,将其相加(维度相同,可以直接相加),得到该字真正的向量表示。第t个字的向量记作Xt。self-attention的计算过程可以分为以下5步。
1.定义三个矩阵![]() 、
、![]() 、
、![]() 。
。
2.使用这三个矩阵分别对所有的字向量进行三次线性变换,于是所有的字向量又衍生出三个新的向量![]() 、
、![]() 、
、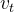 ,将所有的
,将所有的![]()
![]() 向量拼成一个大矩阵,记作查询矩阵Q,将所有的
向量拼成一个大矩阵,记作查询矩阵Q,将所有的![]() 向量拼接成一个大矩阵,记作键矩阵K,将所有的向量拼成一个大矩阵,记作值矩阵V。
向量拼接成一个大矩阵,记作键矩阵K,将所有的向量拼成一个大矩阵,记作值矩阵V。
3.为了获得第一个字的注意力权重,我们需要用第一个字的查询向量q1乘以键矩阵K。
4.将得到的矩阵进行softmax,使得他们的和为1。
5.得到第一个字的权重,使用第一个字的权重乘以所有字的值向量V,相加得到第一个字的输出。
以下是图文过程
1.获得查询矩阵Q、键矩阵K、值矩阵V
2.为了获得第一个字的注意力权重,我们需要用第一个字的查询向量q1乘以键矩阵K。
[0, 4, 2]
[1, 0, 2] x [1, 4, 3] = [2, 4, 4]
[1, 0, 1]
3.之后还需要将得到的值经过softmax,使得它们的和为1(见下图)
softmax([2, 4, 4]) = [0.0, 0.5, 0.5]
4.有了权重之后,将权重其分别乘以对应字的值向量Vt
0.0 * [1, 2, 3] = [0.0, 0.0, 0.0]
0.5 * [2, 8, 0] = [1.0, 4.0, 0.0]
0.5 * [2, 6, 3] = [1.0, 3.0, 1.5]5.最后将这些权重化后的值向量求和,得到第一个字的输出(见下图)
[0.0, 0.0, 0.0]
+ [1.0, 4.0, 0.0]
+ [1.0, 3.0, 1.5]
-----------------
= [2.0, 7.0, 1.5]

6.对其它的输入向量也执行相同的操作,即可得到通过self-attention后的所有输出
第二个input输出
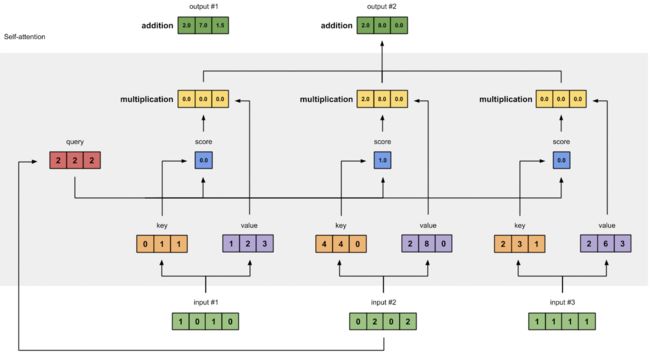
第三个input输出

矩阵计算
在计算时,可以将单个向量组合成矩阵的形式,通过矩阵相乘并行计算出所有时刻的输出。
1.计算出所有时刻的Q、K、V,输入矩阵X,矩阵第t行表示第t个词的向量表示Xt。

2.接下来将Q和![]() 相乘,然后除以
相乘,然后除以![]() ,经过softmax以后再乘以V得到输出。
,经过softmax以后再乘以V得到输出。

2-1-3 Multi-Head Attention
一组Q,K,V 可以让一个词attend to相关的词,定义多组Q , K , V让它们分别关注不同的上下文。 这就是Multi-Head Attention的定义。计算 Q , K , V的过程还是一样,只不过线性变换的矩阵从一组 ,变成了多组
,变成了多组 

对于输入矩阵 X,每一组Q、K、V 都可以得到一个输出矩阵Z ,如下图所示。

最后用图进行总结:
Padding Mask

Self Attention的计算过程中,通常使用mini-batch来计算,也就是一次计算多句话,即X的维度是[batch_size, sequence_length],sequence_length是句长,而一个mini-batch是由多个不等长的句子组成的,我们需要按照这个mini-batch中最大的句长对剩余的句子进行补齐,一般用0进行填充,这个过程叫做padding。但这时在进行softmax就会产生问题,softmax函数公式如下:

此时做运算时,![]() 是有值的,这样的话softmax中被padding的部分就参与了运算,相当于让无效的部分参与了运算,这可能会产生很大的隐患。因此需要做一个mask操作,让这些无效的区域不参与运算,一般是给无效区域加一个很大的负数偏置。
是有值的,这样的话softmax中被padding的部分就参与了运算,相当于让无效的部分参与了运算,这可能会产生很大的隐患。因此需要做一个mask操作,让这些无效的区域不参与运算,一般是给无效区域加一个很大的负数偏置。
2-1-4 残差连接和Layer Normalization
1.残差连接
得到self- attention的加权输出之后,将其记为![]() 与X的词嵌入相加,做残差连接。
与X的词嵌入相加,做残差连接。

将“加入位置编码后的词向量”与“摞在一起的Attention值” 相加。残差链接减小了梯度消失的影响。加入残差链接,就能保证层次很深的模型不会出现梯度消失的现象。
2.Layer Normalization
Layer Normalization的作用是把神经网络中隐藏层归一为标准正态分布,以起到加快训练速度,加速收敛的作用。Layer Normalization是对每一个样本进行标准化,将每一个样本都变为标准正态分布。在NLP任务中,一般选用的都是LN,不用BN。因为句子长短不一,每个样本的特征数很可能不同,造成很多句子无法对齐,所以不适合用BN。Layer Normalization计算过程如下。
1.以矩阵的列(column)为单位求均值。

2.以矩阵的列(column)为单位求方差。

3. 然后用每一列的每一个元素减去这列的均值,再除以这列的标准差,从而得到归一化后的数值,加 ϵ是为了防止分母为0。
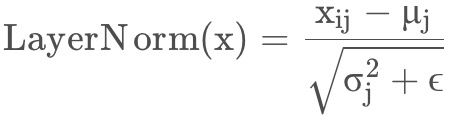
3.Bath Normalization
假设每列代表一个样本,每行代表一个特征。Bath Normalization按照特征进行标准化,将每一个特征都变为标准正态分布。batch_size较小时,Bath Normalization效果差。因为小批量的均值和方差不能很好的代表整体。 
Bath Normalization对batch size的大小是有要求的,一般batch size越大,计算出的特征越好。另外由于embedding size 设置的比较大,而layer normalization 正好是延这个方向做的,所以正好使得layer normalization计算的更稳定 。
2-1-5 前馈神经网络 Feed Forward
输入x1和x2经self-attention层之后变成z1和z2,然后和输入的x1、x2进行残差连接,并进行LayerNorm标准化。
之后分别通过两个Feed Forward(由两个全连接层构成的网络:Linear(ReLU(Linear(Zi))))经过LayerNorm后输出给全连接层。 先把输入向量从512维映射到2048维,然后再映射到512维。实现时,就是使用两个linear层,第一个linear的输入是512维,输出是2048维,第二个linear的输入是2048,输出是512。

然后再接一个残差链接,即Zi和Feed Forward的输出Add对位相加。最后把相加的结果进行一次LayerNorm标准化。最后再输出给下一个Encoder(每个Encoder Block中的FeedForward层权重都是共享的)

2-1-6 Encoder的整体计算流程
1). 字向量与位置编码
![]()
2). 自注意力机制

3). self-attention残差连接与Layer Normalization

4). FeedForward
![]()
5). FeedForward残差连接与Layer Normalization

维度说明:

2-2 Transformer Decoder
Decoder包括三个部分,Masked Multi-Head Self-Attention(带掩码的多头注意力)、Multi-Head Encoder-Decoder Attention(N个普通的多头注意力)、FeedForward Network(前馈网络)

2-2-1 Masked Self-Attention
传统Seq2Seq中Decoder使用的是RNN模型,因此在训练过程中输入t时刻的词,模型不到未来时刻的词,因为循环神经网络是时间驱动的,只有当t时刻运算结束了,才能看到t+1时刻的词。
而Transformer Decoder抛弃了RNN,改为Self-Attention,由此就产生了一个问题,在训练过程中,整个ground truth都暴露在Decoder中,这显然是不对的,我们需要对Decoder的输入进行一些处理,该处理被称为Mask。 如果像encoder的注意力机制那里一样没有mask,那么在训练decoder时,如果要生成预测结果,就需要用到整个句子的所有词。但是在真正预测的时候,并看不到未来的信息。
例如Decoder的ground truth为"![]() 、
、![]() 、
、![]() )得到Q、K、V,之后进行self-attention操作。通过
)得到Q、K、V,之后进行self-attention操作。通过![]() 得到矩阵caled Scores,接下来要对Scaled Scores进行Mask。当我们输入"I"时,模型目前仅知道包括"I"在内之前所有字的信息,即"
得到矩阵caled Scores,接下来要对Scaled Scores进行Mask。当我们输入"I"时,模型目前仅知道包括"I"在内之前所有字的信息,即"
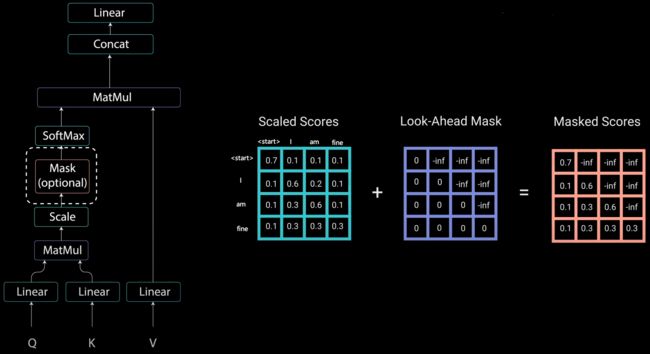
然后再做softmax,就能将-inf变为0,得到的这个矩阵即为每个字之间的权重。

2-2-2 Multi-Head Encoder-Decoder Attention
Decoder中的多头注意力和Encoder是相同的,唯一的区别就是,encoder的多头注意力里的Q、K、V是初始化多个不同的![]() 、
、![]() 、
、![]() 矩阵得到的。而decoder的K、V是来自于encoder的输出,Q是上层Masked Self-Attention的输出。
矩阵得到的。而decoder的K、V是来自于encoder的输出,Q是上层Masked Self-Attention的输出。
如果解码部分的多头注意力有多层,那么输入到每层多头注意力里的K、V都来自于encoder。除了第一层的Q来自于masked Multi-Head Attention的输出,其余的Q都来自于上层encoder的输出。
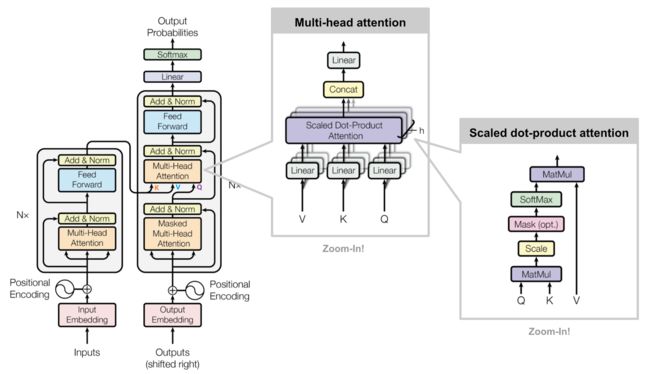
Scaled Dot-Product Attention 三个变量输入(Q、K、V),具体含义如下所述:
1.Q 表示查询上下文,可以理解为一句话中的语境。
2.K 表示注意力的查询关键词,token 序列的每一个向量都是一个查询关键词,而 attention 会作用在每一个 token 上。因此为了方便表示一般把K表示为一个max_seq_length×dim的矩阵。dim 是 token 的向量长度,max_seq_length 是 token 序列的最大长度。
3.V 存储值,Attention 所提供的就是对不同存储值的权重,最后 Attention 机制的目标是在上下文Q的情况下,对于一个关键词K,对于V的不同分量计算各自的权重,最后以加权和的 embedding 表示关键词K。
相对于一般的 self-attention 可以看到,Scaled Dot-Product Attention 主要是多了 Scale 和 Mask 两个环节,并且输出会将 softmax 的输出与V进行点乘(MatMul)。
Scale 单元会对输入矩阵的每个元素除以![]() ,
,![]() 是 K 的维度。
是 K 的维度。
Mask 单元会将一部分输入矩阵的元素置为 0,在论文中只有 Decoder 的 Multi-Head Attention 中使用了这个单元,将进入这个单元的矩阵的下半反对角矩阵的值清空,主要是为了防止 Decoder 部分对预测结果发生泄漏。
2-2-3 Feed Forward
这一部分和encoder是一样的,即一个两层的、带残差链接的全连接网络,后边再接一个Layer Normalization层。
3.总结
3-1 Transformer与CNN、RNN对比
1.CNN 的 kernel 对较远距离的文字造成太多的信息损失:Transformer 采用了 Attention 机制,保留了不同距离的文字信息。
2.线性 kernel 不适用于文字:所以在 Feed Forward 中引入了类似于核函数的权重共享,并且使用了 Relu 激活函数而不是线性核。
3. 简单池化对信息的损失过大:Transformer 不进行池化,采用 Seq2Seq 的结构可以得到每个 token 的表达。
4.CNN 无法把握顺序的概念:Transformer 通过引入 position encoding 机制来对位置进行编码,从而让模型可以感知到顺序。
5.RNN 无法进行并行训练:通过 Mask 将后向的输出进行隐藏,可以对每个位置进行并行的计算。
6.RNN 存在潜在的梯度消失和梯度爆炸问题:通过 Transformer 中大量使用 Relu 以及 residual connection,保证了梯度消失问题的影响相对较小。对于梯度爆炸通过梯度裁剪可以较好地控制。
7.位置信息的确定:LSTM 以顺序输入的方式考虑位置信息。Transformer 采用函数式绝对位置的方式,使用三角函数为每个词计算一个唯一的位置向量表示,然后加到对应的词向量上。
3-2 Transformer总结
Transformer 引入的注意力机制从根本上解决了长记忆丢失问题。注意力机制会以遍历的方式计算序列中任意两个词之间的相关性,所以不管两个词相隔多远,都能捕捉到之间的依赖关系,从根本上解决难以建立长时依赖的问题。
Transformer 摒弃了顺序输入的方式,一次性输入一个序列的所有词进行计算。这给模型带来了很好的可并行性,可批量的对多个序列进行计算。
参考
1.https://mathor.blog.csdn.net/article/details/107352167
2.Transformer统治的时代,LSTM模型并没有被代替,LSTM比Tranformer优势在哪里? - 知乎
文章中的原理和图解部分很多参考了文章1,自己在理解时遇到的问题部分进行了补充,增加了对部分细节的补充,可能稍显啰嗦。另外参考了文章2中对Transformer和传统神经网络的一些思考。