加速44%!RT-DETR量化无损压缩优秀实战
RT-DETR 模型是飞桨目标检测套件 PaddleDetection 最新发布的 SOTA 目标检测模型。其是一种基于 DETR 架构的端到端目标检测器,在速度和精度上均取得了 SOTA 性能。在实际部署中,为了追求“更准、更小、更快”的效率能力,本文使用飞桨模型压缩工具 PaddleSlim 中的自动压缩工具(ACT, Auto Compression Toolkit)将针对 RT-DETR 进行量化压缩及部署实战。使用 ACT 工具只需要几十分钟,即可完成量化压缩全流程。在模型精度持平的情况下,RT-DETR 模型体积压缩为原来的四分之一,GPU 推理加速44% 。
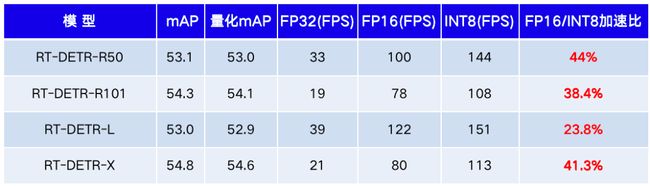
注:上述表格测试使用 Paddle Inference 开启 TensorRT,由于包含 D2H 拷贝时延,和论文 FP16 FPS 相比略慢。
传送门
https://github.com/PaddlePaddle/PaddleSlim/tree/develop/example/auto_compression/detection
1. RT-DETR 模型快速开始
RT-DETR 在一众 YOLO 模型中脱颖而出,成为新 SOTA,它的效果如下图所示。
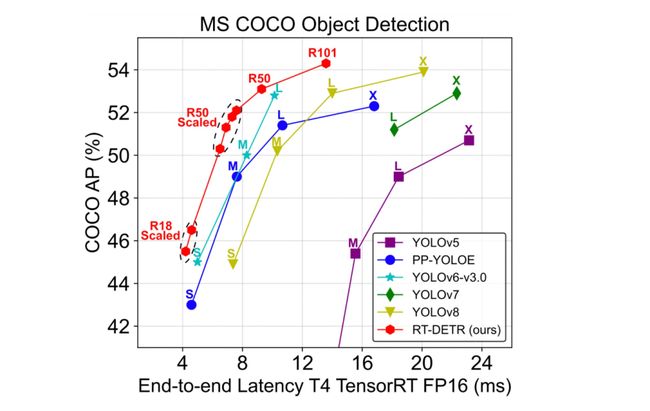
点击下方文章,获取更多RT-DETR信息:
- 超越YOLOv8,飞桨推出精度最高的实时检测器RT-DETR!
为了更方便开发者体验 RT-DETR 的效果,快速跑通从数据校验,模型训练开发到部署的全流程,飞桨在 AI Studio 全新上线了 PaddleX 模型产线。开发者只需要在模型库中选择创建模型产线,即可通过工具箱或者开发者模式快速体验 RT-DETR 模型产线全流程,非常方便易用,欢迎开发者在线体验。
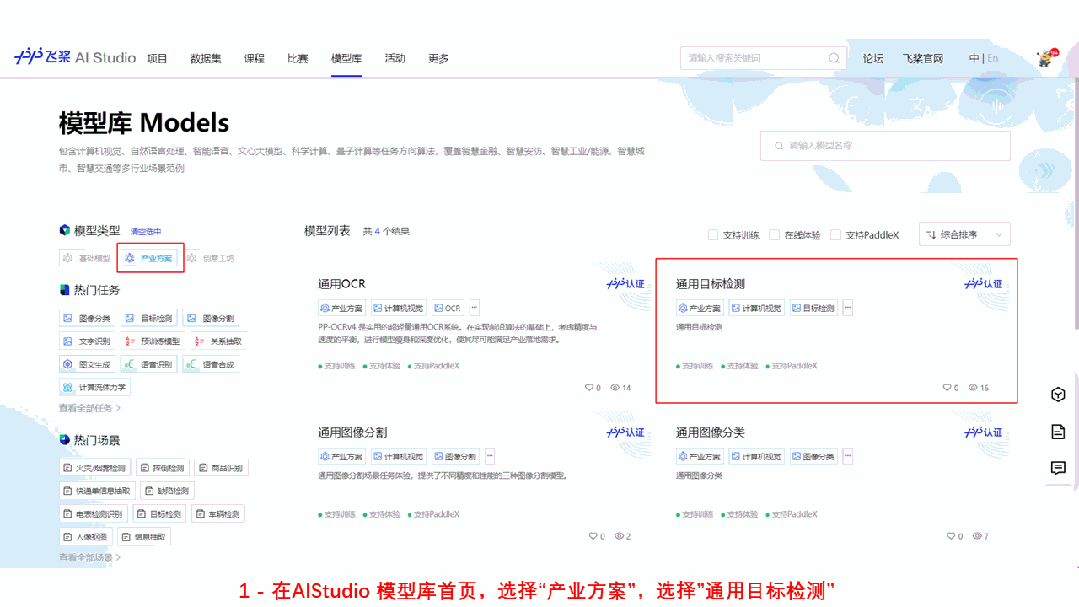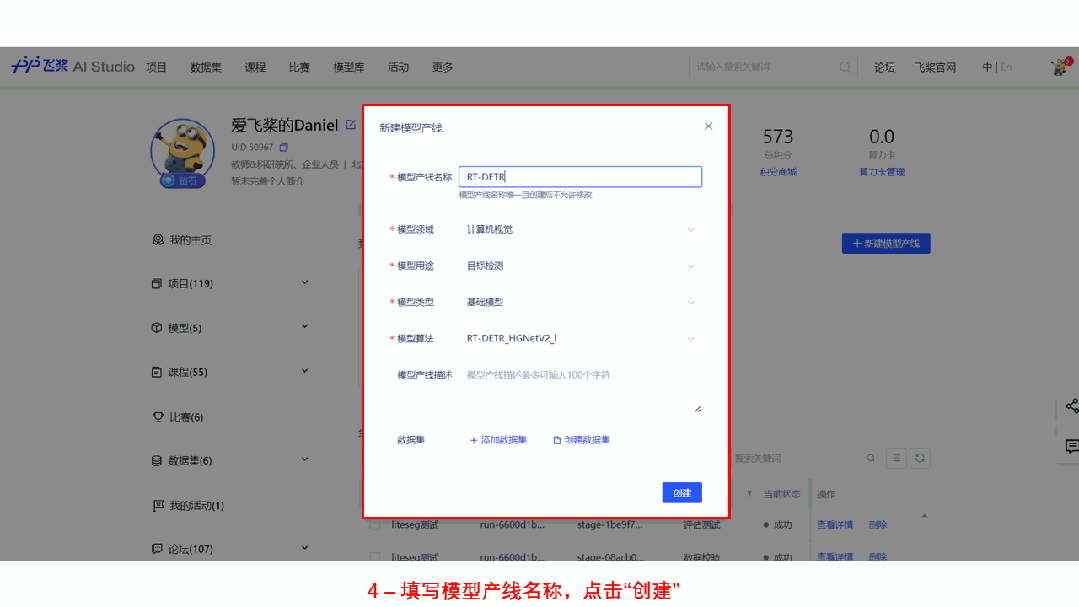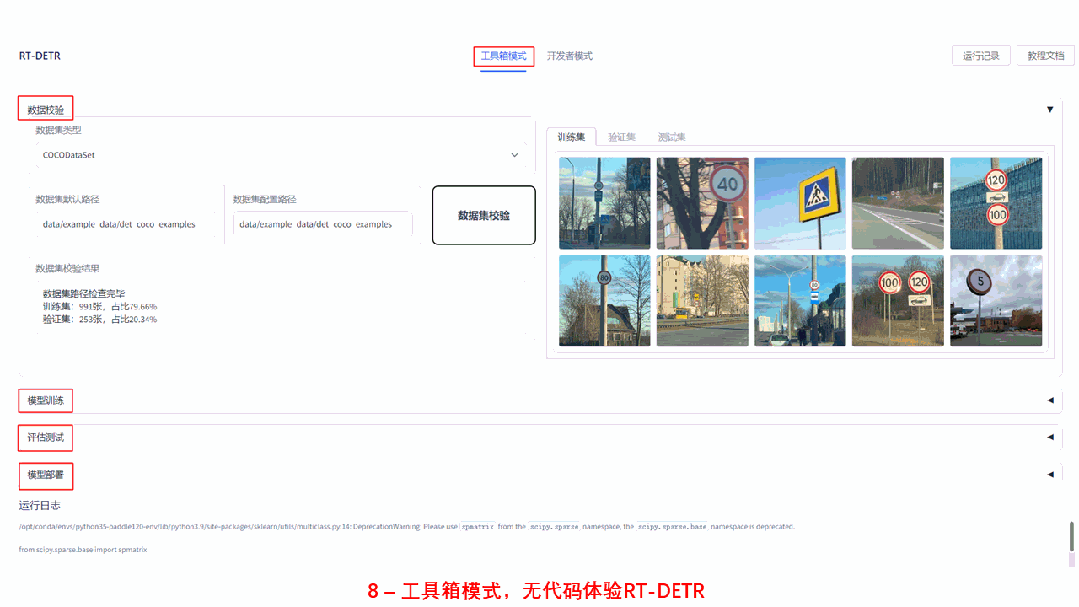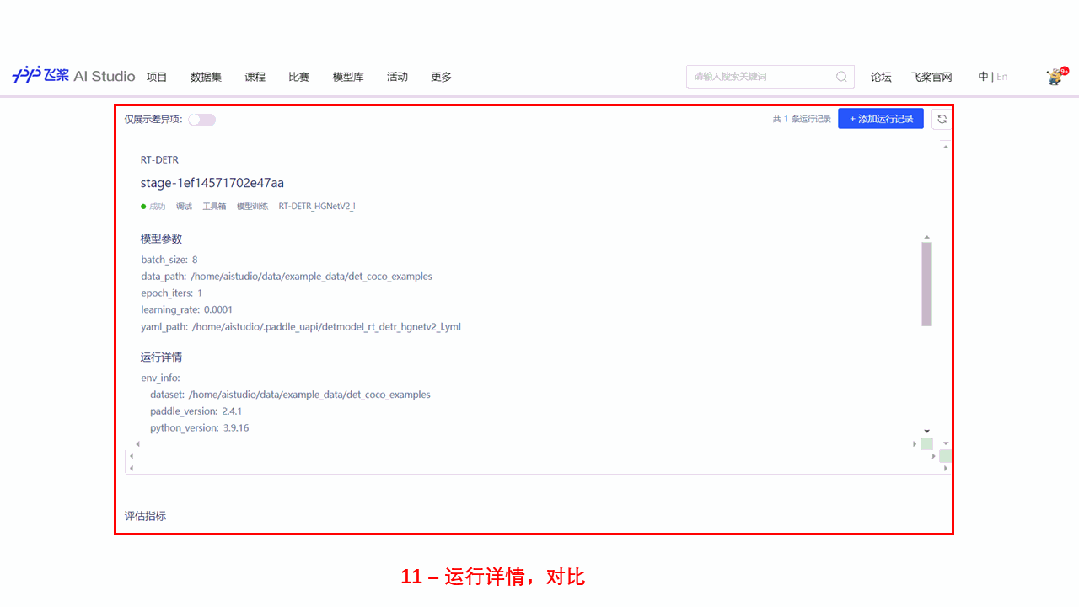
快速体验地址:https://aistudio.baidu.com/aistudio/modelsoverview
2. RT-DETR 模型分析
在对 RT-DETR 量化压缩前,我们对它进行了分析。RT-DETR 网络模型主要由两个部分组成,分别是 ResNet 或者 HGNetv2 构成的 backbone 和 RT-DETR 构成的检测头。在模型的 backbone 中有大量的卷积层,此外在检测头中也有大量的矩阵乘计算,这些操作均可进行量化,从模型结构上分析来看,RT-DETR 模型拥有足够的量化加速潜力。我们使用了量化分析工具分析了各层的激活值分布:
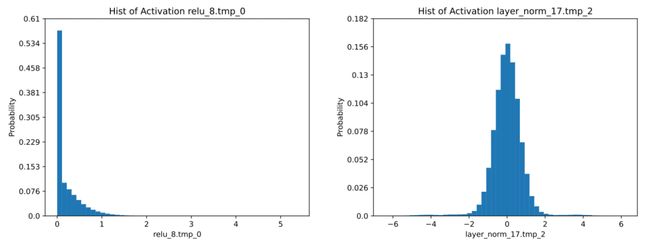
大部分激活值分布都比较集中,离群点很少,这对量化很友好。同时我们分析了各层的权重数值分布:
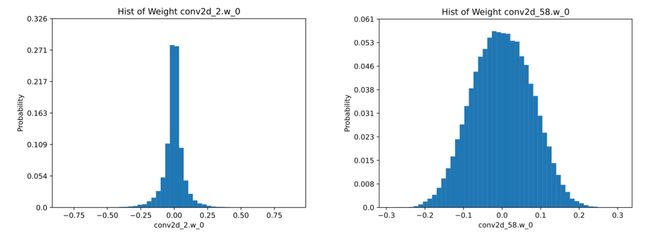
可以看到权重的数据分布基本上符合正态分布,且数值较小,这样的权重分布比较适合量化。分析发现 RT-DETR 有较好的量化压缩潜力,并且为了进一步提升模型部署的性能,我们就开始量化压缩实战吧。
3. RT-DETR 模型压缩实战
RT-DETR 模型准备
PaddleDetection 中提供了官方训练好的使用了不同 backbone 的模型,我们直接使用这些模型作为原始的模型即可。在 PaddleDetection 的环境下按照其流程将模型导出成为静态图模型,这些静态图用于量化压缩和部署测试。
python tools/export_model.py -c configs/rtdetr/rtdetr_r50vd_6x_coco.yml \
-o weights=https://bj.bcebos.com/v1/paddledet/models/rtdetr_r50vd_6x_coco.pdparams trt=True \
--output_dir=output_inference
数据集准备
使用 PaddleSlim 自动压缩工具量化模型需要少量的校准数据,这里我们使用标准的 COCO 数据集进行测试,可以按照 PaddleDetection 中数据准备教程进行准备,数据格式如下所示:
>>tree dataset/coco/
├── annotations
│ ├── instances_train2017.json
│ ├── instances_val2017.json
├── train2017
│ ├── 000000000009.jpg
│ │ ...
├── val2017
│ ├── 000000000139.jpg
│ │ ...
数据准备教程:https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.6/docs/tutorials/data/PrepareDetDataSet.md
模型量化压缩
量化压缩一般是指降低模型存储和计算所用数值的位数,达到减少计算量、存储资源和提升推理速度的效果。在飞桨家族中,PaddleSlim 是一个模型压缩工具库,包含模型剪裁、量化、知识蒸馏、超参搜索和模型结构搜索等一系列模型压缩策略。其中的自动化压缩工具通过无源码的方式,自动对预测模型进行压缩,压缩后模型可直接部署应用。我们使用自动化压缩工具进行模型压缩分为以下3个步骤:
- 准备预处理配置文件
数据预处理的配置和 PaddleDetection 中的模型配置对齐即可:
EvalReader:
sample_transforms:
- Decode: {}
- Resize: {target_size: [640, 640], keep_ratio: False, interp: 2}
- NormalizeImage: {mean: [0., 0., 0.], std: [1., 1., 1.], norm_type: none}
- Permute: {}
batch_size: 1
shuffle: false
drop_last: false
- 定义量化配置文件
定义量化训练的配置文件,Distillation 表示蒸馏参数配置,QuantAware 表示量化参数配置,TrainConfig 表示训练时的训练轮数、优化器等设置。具体超参的设置可以参考 ACT 超参设置文档:https://github.com/PaddlePaddle/PaddleSlim/blob/develop/example/auto_compression/hyperparameter_tutorial.md
Global:
reader_config: configs/rtdetr_reader.yml
model_dir: /rtdetr_r50vd_6x_coco/
……
Distillation:
alpha: 1.0
loss: soft_label
QuantAware:
onnx_format: true
activation_quantize_type: 'moving_average_abs_max'
quantize_op_types:
- conv2d
- matmul_v2
TrainConfig:
train_iter: 1000
eval_iter: 100
learning_rate: 0.00001
optimizer_builder:
optimizer:
type: SGD
weight_decay: 4.0e-05
- 开始运行
少量代码就可以开始 ACT 量化训练。启动 ACT 时,需要传入模型文件的路径(model_dir)、模型文件名(model_filename)、参数文件名称(params_filename)、压缩后模型存储路径(save_dir)、压缩配置文件(config)、dataloader和评估精度的 eval_callback。
ac = AutoCompression(
model_dir=global_config["model_dir"],
model_filename=global_config["model_filename"],
params_filename=global_config["params_filename"],
save_dir=FLAGS.save_dir,
config=all_config,
train_dataloader=train_loader,
eval_callback=eval_func)
ac.compress()
以上是精简后的关键代码,如果想快速体验,可以根据下方链接中的示例文档及代码进行体验:
https://github.com/PaddlePaddle/PaddleSlim/tree/develop/example/auto_compression/detection
如果使用GPU 训练,在几十分钟内就可以完成整个压缩过程。训练完成后会在 save_dir 路径下产出 model.pdmodel和model.pdiparams文件。至此,完成了模型训练压缩工作。
4. RT-DETR 模型部署
飞桨原生推理库 Paddle Inference 性能优异,针对不同平台不同的应用场景进行了深度的适配优化,做到高吞吐、低时延,支持了本项目 RT-DETR 模型的 INT8 加速推理。所以在 RT-DETR 量化压缩后,我们使用 Paddle Inference 推理库进行部署。
推理环境准备
- 硬件环境
需要一台载有支持 INT8 加速推理的 NVIDIA tesla T4 显卡或者 A10 的推理主主机。
- 软件环境
PaddlePaddle develop 版本我们使用以下代码进行量化模型推理速度和精度测试:https://github.com/PaddlePaddle/PaddleSlim/blob/develop/example/auto_compression/detection/paddle_inference_eval.py
具体地,将压缩后的模型拷贝到指定位置,运行指令:
python paddle_inference_eval.py \
--model_path=./rtdetr_r50_quant/ \
--reader_config=configs/rtdetr_reader.yml \
--use_trt=True --precision=int8
值得注意的是,需要运行两次上述指令。第一次运行会收集模型信息并保存 dynamic_shape.txt,用于构建 TensorRT 加速引擎,之后运行会直接加载该文件进行实际预测。最终测试的量化模型的效果如下表所示:
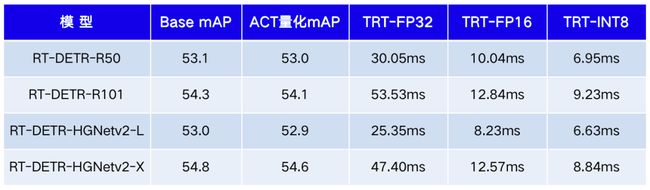
-上表测试环境:Tesla T4,TensorRT 8.6.0,CUDA 11.7,batch_size=1
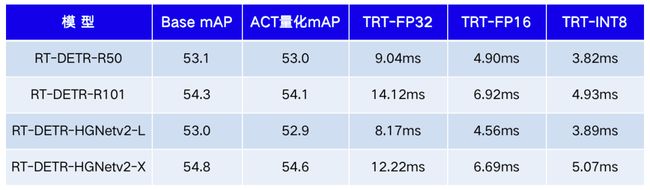
-上表测试环境:A10,TensorRT 8.6.0,CUDA 11.6,batch_size=1-mAP的指标均在COCO val2017数据集中评测得到,IoU=0.5:0.95
⭐Star收藏⭐ 这么好的项目,欢迎大家点star鼓励并前来体验! https://github.com/PaddlePaddle/PaddleSlim
5. 总结与展望
本文对 RT-DETR 检测模型进行了量化压缩的全流程实践,在极小的成本下生成了能高速推理的压缩模型。在 Paddle Inference 中,经过压缩后模型的精度损失几乎可以忽略不计,但是带来的加速效果十分明显,相较于原模型最高加速比为44% 。希望看到这篇文章的开发者们,如果想进一步对 RT-DETR 进行模型压缩和部署,可以动手实践一下,亲自体验加速AI模型的快乐,希望 PaddleSlim 和 Paddle Inference 能够助力更多模型的部署落地。
项目地址
- GitHub
https://github.com/PaddlePaddle/PaddleSlim
- Gitee
https://gitee.com/paddlepaddle/PaddleSlim
拓展阅读
无需训练代码,推理性能提升1.4~7.1倍,业界首个自动模型压缩工具开源!
RT-DETR 快速体验地址
https://aistudio.baidu.com/aistudio/modelsoverview