linux搭建hadoop集群
linux搭建hadoop集群
- 1、创建4台虚拟机
- 2、修改主机名
- 3、配置网络
- 4、配置hosts文件
- 5、分配本地网络给虚拟机
- 6、下载jdk,hadoop压缩包
- 7、用xftp传输到虚拟机
- 8、配置jdk
- 9、配置hadoop
- 10、创建脚本shell脚本,方便同步数据
- 11、配置ssh免密登录
- 12、同步jdk和hadoop到其它机子
- 13、hadoop核心配置文件
- 15、配置workers
- 15、向其它机子同步以上修改的配置文件
- 16、启动集群
- 17、WordCount测试
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算
1、创建4台虚拟机
创建1台克隆3台即可,这里默认大家都会装了!
我创建的时候用户名是vm1,创建不同的后面命令需要自行甄别

2、修改主机名
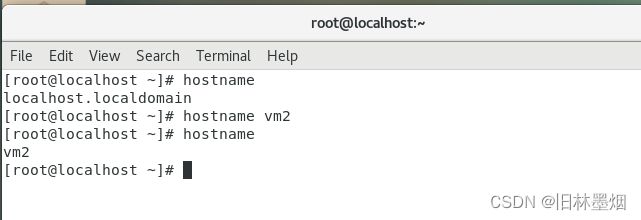
方法一:临时修改,重启失效
hostname vm2
即把主机名改为vm2
方法二:修改文件,重启生效(4台主机都应该按第二种来配置
编辑 vi /etc/hostname
重启 reboot (可以先不重启,配置完第4点再重启)

3、配置网络
4台机子都要配!
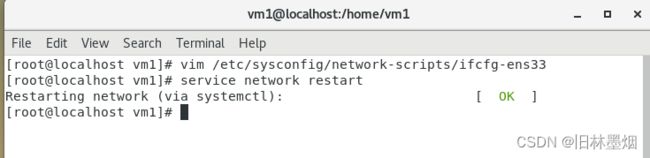
命令 vim /etc/sysconfig/network-scripts/ifcfg-ens33
重启网络 service network restart
添加以下配置
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="cce078fd-5c83-4f0a-a39f-ddaae8c9a1c3"
DEVICE="ens33"
ONBOOT="yes"
IPADDR=192.168.122.101
GATEWAY=192.168.122.2
DNS1=8.8.8.8
4、配置hosts文件
4台机子都要配!
命令 vim /etc/hosts
重启 reboot
配置如下:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.122.101 vm1
192.168.122.102 vm2
192.168.122.103 vm3
192.168.122.104 vm4

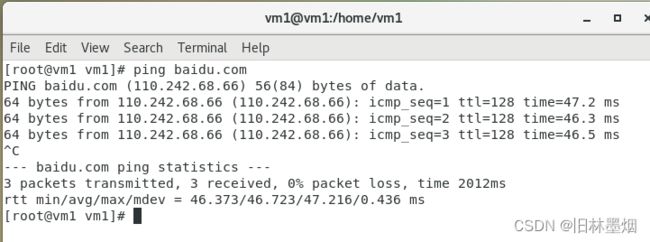
5、分配本地网络给虚拟机


配置参考一下:

测试ping百度
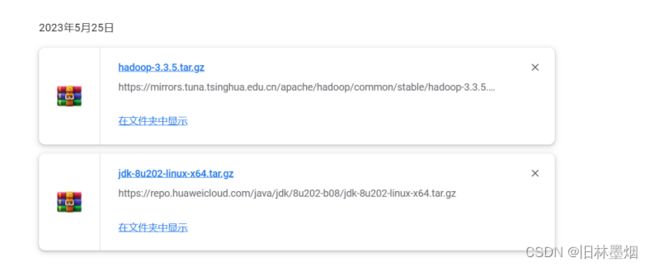
6、下载jdk,hadoop压缩包
我下载的是jdk1.8,hadoop3.3.5
7、用xftp传输到虚拟机
没有xftp可以去下载一个,用共享文件夹传也是可以的。有办法搞到压缩包发到linux机子就行
先创建文件夹
mkdir /usr/java
mkdir /home/hadoop



传输完成
8、配置jdk
解压 tar -zxvf /usr/java/jdk-8u202-linux-x64.tar.gz -C /usr/java/
配置环境变量 vim /etc/profile.d/my_env.sh
配置如下:
#JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_202
export PATH=$PATH:$JAVA_HOME/bin

重新加载profile文件,使配置立即生效 source /etc/profile
检验配置是否成功 java -version

9、配置hadoop
解压 tar -zxvf /home/hadoop/hadoop-3.3.5.tar.gz -C /home/hadoop/
配置环境变量 vim /etc/profile.d/my_env.sh
追加以下配置
#HADOOP_HOME
export HADOOP_HOME=/home/hadoop/hadoop-3.3.5
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin

重新加载prfile文件,使配置立即生效 source /etc/profile
检验配置是否成功 hadoop
10、创建脚本shell脚本,方便同步数据
mkdir /home/vm1/bin (vm1为用户名)
vim /home/vm1/bin/xsync
输入以下内容:
#!/bin/bash
#1.判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2.遍历集群所有机器
for host in vm1 vm2 vm3 vm4
do
echo ============================ $host ============================
#3。遍历所有目录,挨个发送
for file in $@
do
#4.判断文件是否存在
if [ -e $file ]
then
#5。获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6.获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done

修改文件权限 chmod 777 /home/vm1/bin/xsync
测试:xsync /home/vm1/bin/xsync
把当前文件同步给其它三台机子,因为没有ssh免密登录,所以需要输入每台机子的密码,按要求输入即可,后面会配置ssh免密登录的
去别的机子查看文件是否同步过来了
ls /home/vm1/bin

发现其它机子都收到了这个文件,以后我们想要别的机子同步本机子的文件直接使用这个脚本
11、配置ssh免密登录
hadoop要求必须配的,配了之后就可以不输入密码直接登录别的机子了
在vm1上执行以下命令
生成密钥对 ssh-keygen -t rsa (三连回车)
把公钥放在vm1上 ssh-copy-id vm1 (要输入yes并输入密码)
把公钥放在vm2上 ssh-copy-id vm2 (要输入yes并输入密码)
把公钥放在vm3上 ssh-copy-id vm3 (要输入yes并输入密码)
把公钥放在vm4上 ssh-copy-id vm4 (要输入yes并输入密码)

测试免密登录
登录 ssh vm2
退出 exit
现在只能在vm1免密登录其它机子,要相互免密登录的话按上面步骤在每台机子都执行一次
成功后不妨回归测试一下,之前的脚本已经不用输入密码了,想同步数据非常方便
xsync /home/vm1/bin/xsync

12、同步jdk和hadoop到其它机子
在vm1执行同步命令
xsync /home/hadoop/hadoop-3.3.5 /usr/java/jdk1.8.0_202 /etc/profile.d/my_env.sh
第一次同步文件有点多,耐心等一下
完成后去另外的机子查看同步结果
ls /usr/java/
ls /home/hadoop/
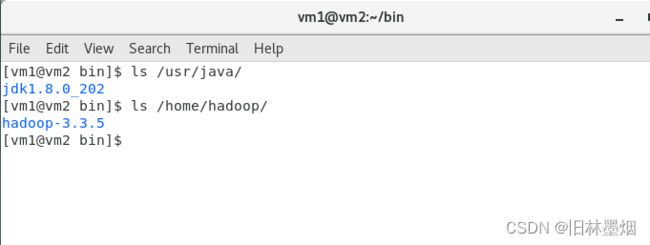
重新加载环境,使环境变量立即生效 source /etc/profile
测试是否完成 java -version

13、hadoop核心配置文件
(1)配置core-site.xml
命令:vim $HADOOP_HOME/etc/hadoop/core-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://vm1:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-3.3.5/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为atguigu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>vm1</value>
</property>
</configuration>

(2)HDFS配置文件
配置hdfs-site.xml
命令:vim $HADOOP_HOME/etc/hadoop/hdfs-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>vm1:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>vm3:9868</value>
</property>
</configuration>

(3)YARN配置文件
配置yarn-site.xml
命令:vim $HADOOP_HOME/etc/hadoop/yarn-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>vm2</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>

(4)MapReduce配置文件
配置mapred-site.xml
命令:vim $HADOOP_HOME/etc/hadoop/mapred-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>

15、配置workers
命令:vim $HADOOP_HOME/etc/hadoop/workers
在该文件中增加如下内容:
vm1
vm2
vm3
vm4
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
15、向其它机子同步以上修改的配置文件
命令:xsync $HADOOP_HOME
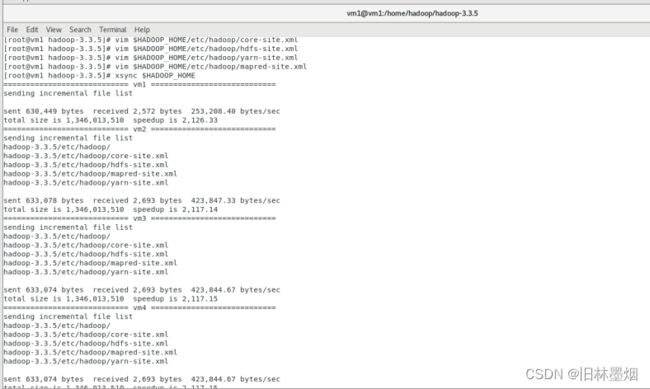
可以去验证有没有同步完成
16、启动集群
(1) 如果集群是第一次启动,需要在vm1节点格式化NameNode (注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。)
格式化命令:hdfs namenode -format

(2)启动HDFS
命令:$HADOOP_HOME/sbin/start-dfs.sh

(3)在配置了ResourceManager的节点(vm2)启动YARN
命令:$HADOOP_HOME/sbin/start-yarn.sh
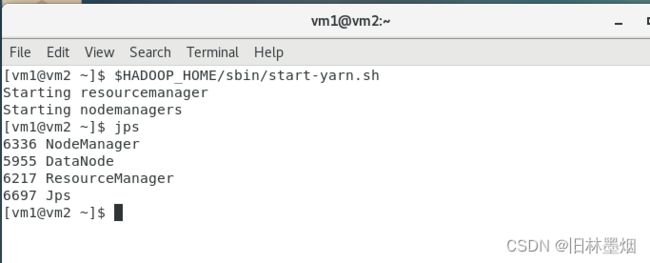
(4)Web端查看HDFS的NameNode
浏览器中输入:http://vm1:9870

(5)Web端查看YARN的ResourceManager
浏览器中输入:http://vm2:8088

17、WordCount测试
1、本地写文件
创建文件夹:mkdir $HADOOP_HOME/WordCount
创建文件1:
echo 'This is the first hadoop test program!' > $HADOOP_HOME/WordCount/file1.txt
创建文件2:
echo 'This program is not very difficult, but this program is a common hadoop program!' > $HADOOP_HOME/WordCount/file2.txt
2、文件上传到fs
创建文件夹:hadoop fs -mkdir /input
上传文件:hadoop fs -put $HADOOP_HOME/WordCount/*.txt /input
3、执行程序
执行wordcount程序:hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.5.jar wordcount /input /output
查看输出文件:hadoop fs -ls /output
查看查询结果:hadoop fs -cat /output/part-r-00000

觉得不错就点个赞吧!