广告数仓:数仓搭建
系列文章目录
广告数仓:采集通道创建
广告数仓:数仓搭建
文章目录
- 系列文章目录
- 前言
- 一、环境搭建
-
- 1.hive安装
- 2.编写配置文件
- 3.拷贝jar包
- 4.初始化源数据库
- 5.修改字符集
- 6.更换Spark引擎
-
- 1.上传并解压spark
- 2.修改配置文件
- 3.在hadoop上创建需要的文件夹
- 4.上传依赖
- 5.优化hive
- 6.测试hive
- 二、数仓搭建
-
- 1.客户端链接
- 2.ODS层创建
-
- 广告信息表
- 推广平台表
- 产品表
- 广告投放表
- 日志服务器列表
- 广告监测日志表
- 数据装载
- 3.DIM层创建
-
- 广告信息维度表
- 平台信息维度表
- 数据装载
- 总结
前言
我们利用Hive来进行数仓搭建。
一、环境搭建
1.hive安装
将尚硅谷提供的hive压缩包上传解压修改名称,由于我们需要更换spark引擎,所以必须适用尚硅谷提供的,因为里面将spark依赖更换重编译了。

2.编写配置文件
vim conf/hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--配置Hive保存元数据信息所需的 MySQL URL地址-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false&useUnicode=true&characterEncoding=UTF-8&allowPublicKeyRetrieval=true</value>
</property>
<!--配置Hive连接MySQL的驱动全类名-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<!--配置Hive连接MySQL的用户名 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!--配置Hive连接MySQL的密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>000000</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>
sudo vim /etc/profile.d/my_env.sh
###
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin
source /etc/profile.d/my_env.sh
3.拷贝jar包
cp /opt/software/mysql/mysql-connector-j-8.0.31.jar /opt/module/hive/lib/
4.初始化源数据库
数据库操作
mysql -uroot -p000000
create database metastore
终端操作
schematool -initSchema -dbType mysql -verbose
5.修改字符集
mysql操作
use metastore;
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table TABLE_PARAMS modify column PARAM_VALUE mediumtext character set utf8;
登录Hive测试一下,依赖于hadoop环境,记得启动hive之前先启动hadoop
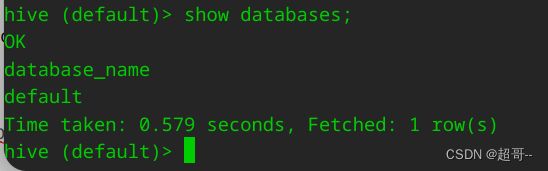
6.更换Spark引擎
1.上传并解压spark
这个没有特殊修改所以可以直接下载
阿里源

2.修改配置文件
mv conf/spark-env.sh.template conf/spark-env.sh
vim conf/spark-env.sh
export HADOOP_CONF_DIR=/opt/module/hadoop/etc/hadoop/

sudo vim /etc/profile.d/my_env.sh
##########
# SPARK_HOME
export SPARK_HOME=/opt/module/spark
export PATH=$PATH:$SPARK_HOME/bin
vim /opt/module/hive/conf/spark-defaults.conf
#####
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop102:8020/spark-history
spark.executor.memory 1g
spark.driver.memory 1g
spark.yarn.populateHadoopClasspath true
vim /opt/module/hive/conf/hive-site.xml
#####
<!--Spark依赖位置(注意:端口号8020必须和namenode的端口号一致)-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://hadoop102:8020/spark-jars/*</value>
</property>
<!--Hive执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
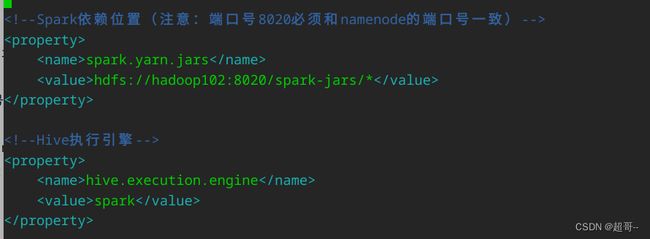
3.在hadoop上创建需要的文件夹
hadoop fs -mkdir /spark-history
hadoop fs -mkdir /spark-jars

4.上传依赖
依赖下载阿里源

将这个文件夹里的jar包全部上传
hadoop fs -put ./jars/* /spark-jars

共有184个。
5.优化hive
这个现在用不到,但是提前做了
mv /opt/module/hive/conf/hive-env.sh.template /opt/module/hive/conf/hive-env.sh
vim /opt/module/hive/conf/hive-env.sh
将注释去掉

6.测试hive
hive
create table student(id int, name string);
insert into table student values(1,'abc');
第一次运行spark引擎需要一些时间,因为他需要调依赖。

在插入一条数据就很快了。

二、数仓搭建
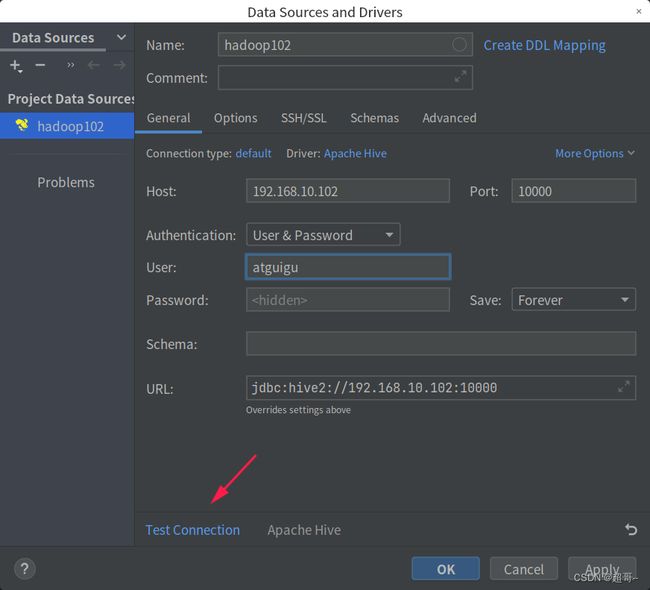
1.客户端链接
这里我们使用JetBrains开发的DataGrip

填写配置信息。然后打开hadoop和hiveservice2

第一次链接会下载依赖,时间会稍微长一点
我们创建一个数据库测试一下
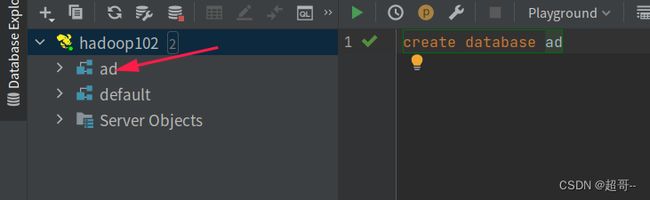
然后把数据库操作挑到ad

2.ODS层创建
广告信息表
drop table if exists ods_ads_info_full;
create external table if not exists ods_ads_info_full
(
id STRING comment '广告编号',
product_id STRING comment '产品id',
material_id STRING comment '素材id',
group_id STRING comment '广告组id',
ad_name STRING comment '广告名称',
material_url STRING comment '素材地址'
) PARTITIONED BY (`dt` STRING)
row format delimited fields terminated by '\t'
LOCATION '/warehouse/ad/ods/ods_ads_info_full';
推广平台表
drop table if exists ods_platform_info_full;
create external table if not exists ods_platform_info_full
(
id STRING comment '平台id',
platform_name_en STRING comment '平台名称(英文)',
platform_name_zh STRING comment '平台名称(中文)'
) PARTITIONED BY (`dt` STRING)
row format delimited fields terminated by '\t'
LOCATION '/warehouse/ad/ods/ods_platform_info_full';
产品表
drop table if exists ods_product_info_full;
create external table if not exists ods_product_info_full
(
id STRING comment '产品id',
name STRING comment '产品名称',
price decimal(16, 2) comment '产品价格'
) PARTITIONED BY (`dt` STRING)
row format delimited fields terminated by '\t'
LOCATION '/warehouse/ad/ods/ods_product_info_full';
广告投放表
drop table if exists ods_ads_platform_full;
create external table if not exists ods_ads_platform_full
(
id STRING comment '编号',
ad_id STRING comment '广告id',
platform_id STRING comment '平台id',
create_time STRING comment '创建时间',
cancel_time STRING comment '取消时间'
) PARTITIONED BY (`dt` STRING)
row format delimited fields terminated by '\t'
LOCATION '/warehouse/ad/ods/ods_ads_platform_full';
日志服务器列表
drop table if exists ods_server_host_full;
create external table if not exists ods_server_host_full
(
id STRING comment '编号',
ipv4 STRING comment 'ipv4地址'
) PARTITIONED BY (`dt` STRING)
row format delimited fields terminated by '\t'
LOCATION '/warehouse/ad/ods/ods_server_host_full';
广告监测日志表
drop table if exists ods_ad_log_inc;
create external table if not exists ods_ad_log_inc
(
time_local STRING comment '日志服务器收到的请求的时间',
request_method STRING comment 'HTTP请求方法',
request_uri STRING comment '请求路径',
status STRING comment '日志服务器相应状态',
server_addr STRING comment '日志服务器自身ip'
) PARTITIONED BY (`dt` STRING)
row format delimited fields terminated by '\u0001'
LOCATION '/warehouse/ad/ods/ods_ad_log_inc';
数据装载
vim ~/bin/ad_hdfs_to_ods.sh
######
#!/bin/bash
APP=ad
if [ -n "$2" ] ;then
do_date=$2
else
do_date=`date -d '-1 day' +%F`
fi
#声明一个Map结构,保存ods表名与origin_data路径的映射关系
declare -A tableToPath
tableToPath["ods_ads_info_full"]="/origin_data/ad/db/ads_full"
tableToPath["ods_platform_info_full"]="/origin_data/ad/db/platform_info_full"
tableToPath["ods_product_info_full"]="/origin_data/ad/db/product_full"
tableToPath["ods_ads_platform_full"]="/origin_data/ad/db/ads_platform_full"
tableToPath["ods_server_host_full"]="/origin_data/ad/db/server_host_full"
tableToPath["ods_ad_log_inc"]="/origin_data/ad/log/ad_log"
load_data(){
sql=""
for i in $*; do
#判断路径是否存在
hadoop fs -test -e ${tableToPath["$i"]}/$do_date
#路径存在方可装载数据
if [[ $? = 0 ]]; then
sql=$sql"load data inpath '${tableToPath["$i"]}/$do_date' overwrite into table ${APP}.$i partition(dt='$do_date');"
fi
done
hive -e "$sql"
}
case $1 in
"ods_ads_info_full")
load_data "ods_ads_info_full"
;;
"ods_platform_info_full")
load_data "ods_platform_info_full"
;;
"ods_product_info_full")
load_data "ods_product_info_full"
;;
"ods_ads_platform_full")
load_data "ods_ads_platform_full"
;;
"ods_server_host_full")
load_data "ods_server_host_full"
;;
"ods_ad_log_inc")
load_data "ods_ad_log_inc"
;;
"all")
load_data "ods_ads_info_full" "ods_platform_info_full" "ods_product_info_full" "ods_ads_platform_full" "ods_server_host_full" "ods_ad_log_inc"
;;
esac
添加权限并运行
chmod +x ~/bin/ad_hdfs_to_ods.sh
ad_hdfs_to_ods.sh all 2023-01-07
内存计算非常快

确定数据导入成功即可
3.DIM层创建
广告信息维度表
drop table if exists dim_ads_info_full;
create external table if not exists dim_ads_info_full
(
ad_id string comment '广告id',
ad_name string comment '广告名称',
product_id string comment '广告产品id',
product_name string comment '广告产品名称',
product_price decimal(16, 2) comment '广告产品价格',
material_id string comment '素材id',
material_url string comment '物料地址',
group_id string comment '广告组id'
) PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/ad/dim/dim_ads_info_full'
TBLPROPERTIES ('orc.compress' = 'snappy');
平台信息维度表
drop table if exists dim_platform_info_full;
create external table if not exists dim_platform_info_full
(
id STRING comment '平台id',
platform_name_en STRING comment '平台名称(英文)',
platform_name_zh STRING comment '平台名称(中文)'
) PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/ad/dim/dim_platform_info_full'
TBLPROPERTIES ('orc.compress' = 'snappy');
数据装载
vim ~/bin/ad_ods_to_dim.sh
######
#!/bin/bash
APP=ad
# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n "$2" ] ;then
do_date=$2
else
do_date=`date -d "-1 day" +%F`
fi
dim_platform_info_full="
insert overwrite table ${APP}.dim_platform_info_full partition (dt='$do_date')
select
id,
platform_name_en,
platform_name_zh
from ${APP}.ods_platform_info_full
where dt = '$do_date';
"
dim_ads_info_full="
insert overwrite table ${APP}.dim_ads_info_full partition (dt='$do_date')
select
ad.id,
ad_name,
product_id,
name,
price,
material_id,
material_url,
group_id
from
(
select
id,
ad_name,
product_id,
material_id,
group_id,
material_url
from ${APP}.ods_ads_info_full
where dt = '$do_date'
) ad
left join
(
select
id,
name,
price
from ${APP}.ods_product_info_full
where dt = '$do_date'
) pro
on ad.product_id = pro.id;
"
case $1 in
"dim_ads_info_full")
hive -e "$dim_ads_info_full"
;;
"dim_platform_info_full")
hive -e "$dim_platform_info_full"
;;
"all")
hive -e "$dim_ads_info_full$dim_platform_info_full"
;;
esac
测试一下
chmod +x ~/bin/ad_ods_to_dim.sh
ad_ods_to_dim.sh all 2023-01-07
总结
数仓一次写不完了,剩下的下次在写