【收藏向】免费分享数据采集和爬虫入门教程!全文共计5.5W字,一篇文章带你走进爬虫世界!
全文总计5.5万字,免费分享数据采集和爬虫入门教程,最初目的是作者本人期末考试复习,内有概念解释、案例分析和通用代码!创作不易,麻烦点赞、收藏、关注!
本篇适合爬虫初学者以及期末复习同学!
数据采集和爬虫入门教程
- 一、数据采集导论
-
- (一)数据
-
- 1、数据概念
- 2、数据类型
- 3、数据组织形式
- 4、数据分析过程
- (二)数据采集
-
- 1、数据采集概念
- 2、数据采集的三大要点
- 3、数据采集数据源
- 4、数据采集方法
- (三)互联网大数据采集
-
- 1、互联网大数据来源
- 2、大数据定义
- 3、互联网大数据特征
- 4、互联网大数据采集场景
- 二、数据采集基础
-
- (一)网络基础概念
-
- 1、URI和URL
- 2、DNS
- 3、超文本
- (二)HTTP协议
-
- 1、HTTP协议
- 2、HTTP请求过程
- 3、HTTP请求报文
- 4、HTTP响应报文
- 5、HTTPS协议
- (三)Cookie
-
- 1、Session和Cookie
- 2、使用Cookie的状态管理过程
- 3、Cookie的缺陷
- 4、会话Cookie和持久Cookie
- (四)网页基础
-
- 1、HTML定义、常用标签
- 2、CSS定义、语法、选择器
- 3、js定义
- 4、HTML结构树-DOM
- (五) 编码体系及规范
-
- 1、网页编码是什么
- 2、具体编码形式
- 3、python中的编码处理
- (六)代理
-
- 1、概念
- 2、代理的作用
- 3、爬虫代理
- 4、代理分类
- 5、代理实现举例
- (七)Robots协议
-
- 1、网络爬虫的危害和治理
- 2、Robots协议的规范和实现
- (八)反爬虫技术和反反爬虫技术
-
- 1、反爬虫技术
- 2、反反爬虫技术
- 三、 爬虫介绍和关键策略
-
- (一)爬虫介绍
- (二)爬虫关键策略
-
- 1、超链接爬行策略
- 2、PageRank算法
- 3、在线重要指数(OPIC)策略
- 4、大站优先策略
- 四 、页面爬取技术
-
- (一)基于Requests的页面爬取
-
- 1、Requests库介绍:
- 2、Requests库基于HTTP协议的主要方法:
- 3、响应对象属性
- 4、通用代码
- (二)动态Ajax页面爬取
-
- 1、Ajax介绍
- 2、如何爬取Ajax界面?
- 3、基于微博动态Ajax网页爬取的通用代码
- 4、备注:RequestException和raise_for_status()有什么区别?
- 5、Ajax与JSON格式的关系
- 五、页面解析技术
-
- (一)Beautiful Soup
-
- 1、Beautiful Soup 概念
- 2、Beautiful Soup解析页面
- 3、Beautiful Soup查找节点
- 3、Beautiful Soup中的方法选择器
- 4、Beautiful Soup CSS 选择器
- 5、 Beautiful Soup 遍历文档树
- (二)XPath
-
- 1、XPath概念
- 2、XPath解析页面
- 3、XPath查找结点
- 4、Xpath的节点轴
- (三)正则表达式
-
- 1、正则表达式概念
- 2、正则表达式匹配规则
- 3、 正则表达式匹配方法
- 4、正则表达式修饰符
- 5、`compile()` 方法和 `match()`、`search()`、`findall()`、`sub()` 等其他方法的关联?
- 6、贪婪匹配和非贪婪匹配
- 六、 页面存储技术
-
- (一)TXT文本存储
-
- 1、txt文本存储通用代码
- 2、Open()函数详解
- (二)JSON文件存储
-
- 1、JSON定义
- 2、Python 中解析 JSON 数据
- 3、获取json中的内容
- 4、Python 对象转换为 JSON 字符串
- (三)CSV文件存储
-
- 1、CSV定义
- 2、通用CSV读取代码
- 七、经典爬虫框架——Scrapy
-
- (一)Scrapy 介绍
- (二)Scrapy 结构
-
- (三)Scrapy爬虫基本步骤
一、数据采集导论
(一)数据
1、数据概念
数据是记录、描述和识别事物的符号,通过有意义的组合来表达现实世界中某种实体的特征,数据用属性描述,属性也称为变量、特征、字段或维度等
2、数据类型
广义上的数据类型分为数字、图像、声音、文字
3、数据组织形式
计算机系统中的数据组织形式主要有两种,即文件和数据库。
4、数据分析过程
主要分为四个部分,分别是:数据采集和预处理、数据存储和管理、数据处理与分析、数据可视化
(二)数据采集
1、数据采集概念
数据采集又称数据获取,即通过各种技术手段把外部各种数据源产生的数据实时或非实时地采集并加以利用
数据采集范围多样,实际上包括网络数据采集、专利数据采集、社会信息采集、以及基于Hadoop架构的(日志采集,分布式消息数据采集,数据仓库中的数据采集)
2、数据采集的三大要点
通常分为三个方面,分别是全面性、多维性、高效性
(1)全面性:全面性是指确保数据采集覆盖到所有需要的数据,不漏一项,不误一点。只有全面收集数据,才能准确反映数据所在问题领域的情况,为后续数据分析和应用提供最充分的数据保障。在数据采集过程中,需要有完整的数据清单和采集计划,并对数据进行分类、标准化和控制,以确保所有必要数据都被收集。
(2)多维性:多维性是指收集数据时应该尽可能地覆盖数据领域中的各个层面和维度,包括时间、地域、产业、品类、用户等,从而能够获得全面、多角度的数据视角,为数据分析和应用提供更为精确的支持。
(3)高效性:高效性是指在数据采集过程中,需要充分利用采集工具和技术,以提高数据的采集速度和效率。例如,使用自动化采集技术、数据挖掘、机器学习等方式来增强数据采集效率,从而能够更快地获取、整理和分析数据。
3、数据采集数据源
通常来源于传感器、互联网数据、企业业务系统数据、日志文件
4、数据采集方法
主要分为四个方面,分别是网络数据采集、ETL、系统日志采集、分布式消息订阅分发
(1)网络数据采集是通过互联网爬取和采集网络上的各种信息,包括网页、图片、视频、音频等。网页抓取工具是网络数据采集的重要手段,通过这些工具可以自动化地获取特定网站或特定信息的数据。同时,还可以采用爬虫的方式进行网络数据采集,通过利用网站的结构性信息和规律性,将海量的网络数据快速地收集、处理和存储到本地数据库中。网络数据采集可以支持数据挖掘和分析,为商业智能、市场调研和竞争情报等方面提供基础数据。
(2)ETL(Extract,Transform,Load)是指数据从一个或多个来源提取、转换和加载到目标系统中的一系列数据处理过程。ETL是数据仓库和商业智能的核心处理程序,主要用于将数据库中存储的数据转换为决策支持信息。ETL工具通常具有可视化开发环境和复杂的数据处理和转换功能,支持从不同方面提取数据,并按照需求进行数据清洗、加密、过滤等处理。数据从ETL中导出到目标系统,被用于数据挖掘、商业智能等分析领域。
(3)系统日志采集是指对计算机系统和网络中日志信息的收集、处理和分析。日志是系统、应用和服务运行过程中记录事件的基础数据,记录着服务器、网络和设备的状态信息,以及用户行为和操作信息。通过对系统日志的采集、分析和挖掘,可以用于排查和解决系统性能问题,监测网络安全风险和异常行为,甚至是设备损坏等方面提供数据支持。
(4)分布式消息订阅分发是指分布式计算中与消息相关的数据采集和分发。它是一种基于事件驱动的数据传递机制,数据的收集播发全基于异步通信方式,系统的解耦性更强。生产者将数据发布到某个topic(主题)上,订阅者则从topic上订阅自己感兴趣的消息。分布式消息订阅分发技术能够实现数据采集系统的高效协作,并支持水平扩展、容错、负载均衡等各种高级特性,广泛用于云计算、大数据和物联网等领域。
(三)互联网大数据采集
1、互联网大数据来源
社交媒体、社交网络、百科知识库、评论信息、位置型信息
2、大数据定义
大数据是以容量大、类型多、存取速度快、价值密度低为主要特征的数据集合(5V:数量、多样性、速度、难辨识、数据价值)
3、互联网大数据特征
类型和语义更加丰富、数据规范程度较弱(数据的相似性、内容的不一致性、数据内涵的多样性)、数据流动性大、数据开放性更好、数据来源更加丰富、价值体现更加多样化。
4、互联网大数据采集场景
(1)采集型爬虫
定义:采集型爬虫:是一种通过互联网自动抓取并分析网页内容的程序,主要用于获取网络数据,如搜索引擎爬虫、数据采集爬虫等。采集型爬虫会跟随链接从一个页面到另一个页面,获取页面上的数据,并将这些数据存储到数据库或其他数据存储系统中。
主要应用:互联网搜索引擎、互联网舆情监测、知识图谱构建、社交媒体评论信息的检测、学术论文的采集、离线浏览
(2)检测型爬虫
定义:是一种由网站管理员或安全工程师使用的程序,目的是为了检测并识别恶意爬虫或者其他非法行为。检测型爬虫主要使用各种技术手段来区分常规访问和不良访问,如基于请求频率、请求来源、请求数据量等进行检测并进行相应的响应处理。
主要应用:应用安全检测、内容安全检测
二、数据采集基础
(一)网络基础概念
1、URI和URL
(1)URL为统一资源定位器,用来唯一标识一个资源,同时指明该资源的位置。
组成:协议头(schema)、服务器地址(host)、端口(port)、路径(path)
协议头表示的是访问资源和服务的协议(网络协议为计算机网络中进行数据交换而建立的规则、标准或约定的集合)
服务器地址表示的的是资源所在主机的完全限定域名(比如:www.baidu.com)
端口:表示协议所使用的TCP端口号(HTTP协议默认端口号为80)
路径:指明服务器上某资源的位置,与端口一样,路径并非总是需要的。
(2)URN为统一资源命名,人们可以通过URN来指出某个资源,而无需指出其位置和获取方式。资源是无需基于互联网的
(3)URI(uniform resource identifier)统一资源表示符,用来唯一的标识一个资源。URI包括了URL和URN。
Schema 指的是 URL 中的协议类型,常见的 Schema 协议有:
http://:超文本传输协议,用于 Web 页面的传输和通信。
https://:安全的超文本传输协议,使用 SSL/TLS 加密技术来保护数据传输安全。
ftp://:文件传输协议,用于计算机之间的文件传输。
mailto://:电子邮件协议,用于发送邮件。
telnet://:远程登录协议,使用户能够在本地终端连接到远程主机并执行操作。
file://:本地文件协议,用于指定本地文件的路径,可以用于本地文件的查看和访问。
data::数据 URL 协议,将数据编码为 URL 的一部分,常用于编码图片、音频等数据。
irc://:Internet Relay Chat 协议,用于在线聊天室和实时讨论组。
git://:版本控制系统协议,主要用于 Git 版本控制系统的操作。
smb://:Server Message Block 文件共享协议,用于在 Windows 网络上共享文件和打印机等资源
2、DNS
(1)域名地址是由若干个英文字母或数字组成,主要用来对计算机的定位标识。
IP地址:是指互联网协议地址。 IP协议给因特网上的每台计算机和其它设备都规定了一个唯一的逻辑地址,叫做“IP地址”,保证在网络寻址时能够准确的找到相应的计算机。
域名系统(Domain Name System):它是互联网的一项服务,作为将域名和IP地址相互映射的一个分布式数据库,能够使人们更方便地访问互联网
(2)DNS缓存指的是DNS返回了域名对应的IP之后,系统将这个域名-IP对应结果临时存储起来,同时设置一个缓存有效期,在有效期内,再次访问网站就无需访问域名系统了,大大加速了网站访问的效率。
DNS访问的运行流程
1、主机向本地 DNS 服务器发送域名解析请求,本地 DNS 服务器通常由 ISP(互联网服务提供商)提供。
2、如果本地 DNS 服务器的缓存中已经存在相应的域名解析结果(即 IP 地址),则直接返回结果给主机;否则,本地 DNS 服务器向根 DNS 服务器发送请求。
3、根 DNS 服务器返回本地 DNS 服务器所需的顶级域服务器的地址。
4、本地 DNS 服务器向所需的顶级域服务器发送请求。
5、顶级域服务器返回本地 DNS 服务器所需的下一级域名服务器的地址,例如 .com 域的服务器地址。
6、本地 DNS 服务器向下一级域名服务器发送请求,并将请求逐级向下传递,直到找到所需的域名解析结果。
7、最后,本地 DNS 服务器将解析结果缓存起来并返回给主机,同时将结果保存在缓存中以便下次使用。
3、超文本
超文本(Hypertext ) 是一种文档系统,可将文档中任意位置的信息与其他信息(文本或图片等)建立关联,即超链接文本。详细的说,超文本(Hypertext)是一种基于计算机网络的文本形式,其特点是可以通过链接(hyperlinks)从一个文本节点跳转到另一个文本节点。每个节点可以包含多种媒体,例如文本、图像、音频和视频等,用户可以通过超链接在这些媒体之间自由导航。超文本是Web文档的基础,也是现代计算机技术发展过程中的关键技术之一。
(二)HTTP协议
1、HTTP协议
HTTP 全称超文本传输协议(Hyper Text Transfer Protocol, HTTP),是用于从网络传输超文本数据到本地浏览器的传送协议,它能保证高效而准确地传送超文本文档
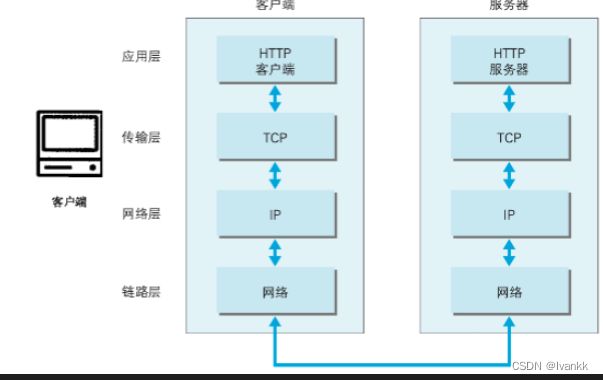
2、HTTP请求过程
(1)域名解析
客户端将域名解析为IP地址,通常使用DNS进行域名解析。
(2)建立TCP连接
客户端使用TCP协议与Web服务器建立连接,这个连接通常称为“三次握手”,包含SYN、ACK、和FIN三个步骤,这个过程主要是客户端和服务器之间发送一些控制信息来同步连接的状态,确保双方能够正常通信。
(3)发送HTTP请求
客户端通过TCP连接发送HTTP请求包,HTTP请求包由请求行、请求头、请求体三部分组成。请求行含有请求方式(GET,POST等),请求的URL和对应的HTTP版本号。请求头包含请求的头部信息,例如客户端的User-Agent信息、客户端支持的压缩类型、以及请求服务器需要提供的信息等。请求体通常是POST请求时所携带的表单数据或者其他数据。
(4)服务器响应
服务器收到请求后,返回一个HTTP响应包,包含响应行、响应头和响应体三部分。响应行包含HTTP的版本号、返回的状态码和对应的文本描述。响应头包含响应的头部信息,例如服务器的类型、内容类型、响应的长度、以及其他信息。响应体通常包含一个HTML文件或者其他需要返回的内容。
(5)关闭TCP连接
当数据传输完成后,客户端与Web服务器之间的TCP连接被关闭,这个过程通常称为“四次挥手”。
Name:请求的名称,一般将URL最后一部分作为名称•Status:响应状态码,200代表响应正常
Type:请求文档类型,document代表我们请求的HTML文档Initiator:请求源,标记请求的对象,即哪一个脚本的哪一行触发了请求
Size:请求资源的大小,memory cache/ disk cache/资源大小如5K
Time:发起请求到响应的时间
Waterfall:请求的可视化瀑布流
3、HTTP请求报文
请求报文包括4部分内容:请求方法(RequestMethod),请求网址(RequestURL),请求头(RequestHeaders)和请求体(RequestBody)
GET 方法用来请求访问URL,并返回响应内容。POST 方法用来提交表单或上传文件,传输数据放在请体中。
GET请求的参数包含在URL里,数据显示在URL中,而POST请求的数据以表单形式传输,不体现在URL中,同时GET请求提交的数据最大为1024字节(512汉字),但是POST方法没有限制
请求头中的主要内容:
请求体:一般承载的内容是PSOT请求中的表单数据,而对于GET请求,请求体为空
4、HTTP响应报文
响应报文包括:响应状态码(ResponseStatusCode),响应头(Response Header)和响应体(ResponseBody)
响应码:HTTP 响应码是客户端向服务器发出请求后,服务器返回的状态码,它们表示服务器对请求的处理结果

响应头中的主要部分:

响应的正文数据都在响应体中,比如请求网页时,它的响应体就是网页的HTML代码:请求一张图片时,它的响应体就是图片的二进制数据。编写爬虫后,我们主要通过响应体获取网页源代码、JSON数据等,基于响应体进行数据内容提取。
5、HTTPS协议
HTTPS全称HyperTextTransferProtocoloverSecureSocketLayer,是以安全为目标的HTTP通道,在HTTP下层加入SSL层(Secure Sockets Layer 安全套接字协议),通过SSL加密后实现资源的传输。
HTTPS的主要作用建立一个信息安全通道来保证数据传输的安全确认网站的真实性,凡是使用了HTTPS的网站,都可以通过点击浏览器地址栏的锁头标志来查看网站认证后的真实信息,也可以通过CA机构颁发的安全签章来查询。
(三)Cookie
1、Session和Cookie
Session(会话):用来存储特定用户会话所需的属性及配置信息。使用Cookie来管理Session
Cookie 是一种用于在客户端和服务器之间传输数据的技术,可以用于实现用户身份验证、会话管理、状态保持等功能。它是由服务器发送给客户端的一小段文本信息,客户端将其保存在本地并在以后的请求中传递给服务器,服务器根据其中携带的信息进行相应的处理。
一般通过在请求和响应报文中写入Cookie 信息来控制客户端的状态。
2、使用Cookie的状态管理过程

3、Cookie的缺陷
Cookie会被附加在每个HTTP请求中,所以无形中增加了流量。
由于在HTTP请求中的cookie是明文传递的,所以安全性成问题。(除非用HTTPS)
Cookie的大小限制在4KB左右。对于复杂的存储需求来说是不够用的。
4、会话Cookie和持久Cookie
从表面意思来说,会话Cookie就是把Cookie放在浏览器内存里;浏览器在关闭之后该Cookie即失效;持久Cookie则会保存到客户端的硬盘中,下次还可以继续使用,用于长久保持用户登录状态。
其实严格来说,没有会话Cookie和持久Cookie之分,只是由Cookie的MaxAge域Expires学段决定了过期的时间。因此,一些持久化登录的网站其实就是把Cookie的有效时间和会话有效期设置得比较长,下次再访问页面时仍然携带之前的Cookie,就可以直接保持登录状态。
(四)网页基础
1、HTML定义、常用标签
(1)定义
HTML(超文本标记语言)是一种用于创建Web页面的标记语言。使用HTML,我们可以定义Web页面中的文本、图像、链接、列表、表格和其他一些元素。
HTML遵循标记语言的基本规则:结构-内容-样式。每一个HTML元素都由标签、属性和内容组成。标记用于定义起始和结束标记,属性用于提供有关标记的额外信息,内容用于说明标记的作用。
例如,下面是一个HTML的基本结构:

在这个例子中, (1)CSS为层叠样式表,用来表现HTML的文件样式的标记语言,静态的修饰网页 JavaScript(简称 JS)是一种轻量级的编程语言,是一种解释性语言,被广泛应用于 Web 开发中,常用于网页前端交互开发和后端服务器开发。JavaScript 由 Brendan Eich 在1995年创造,并在 Netscape Navigator 浏览器中首次得到实现。JavaScript 是一种基于对象的脚本语言,同时也是一种动态类型、解释型的编程语言,提供了与浏览器交互的能力。与 C、C++、Java 等编译型语言不同,JavaScript 是由浏览器解释执行,代码无需编译即可运行。 JavaScript 可以应用于很多场景,比如浏览器的动态效果、轮播图、表单验证、AJAX 请求、Node.js 服务器端开发等等。在浏览器端,JavaScript 主要用于改变网页外观和操作行为,例如添加动画效果、更改 HTML 内容、监听用户事件等等。在 Node.js 等后端环境中,JavaScript 被用于服务器端编程,可以进行文件操作、网络请求等等。 JavaScript 在 Web 开发中有着广泛的应用,是 Web 开发的核心之一。与其他编程语言相比,JavaScript 语法简单并且易于学习,对于入门编程的初学者而言是非常适合的,凭借其在浏览器和服务器端的广泛应用,JavaScript 已经成为一种不可或缺的编程语言。 下面以一个简单的案例来讲解一下 JavaScript 的应用。 假设我们有一个网页,其中有一个按钮,当用户点击该按钮时,页面中的文本内容变为“Hello, World!"。这个效果可以通过 JavaScript 实现。具体实现步骤如下: 可以看到,在网页的 在网页中引入这个 JavaScript 文件,在文件中定义一个名为 这样,当用户点击页面上的按钮时,网页中的文本内容就会变成 “Hello, World!”。 以上是一个简单的 JavaScript 应用案例,通过 JavaScript,可以轻松实现网页的动态效果和交互,使网页更加生动有趣。 DOM(文档对象模型)是HTML文档的编程接口,它把HTML文档以及其中的标签、属性、文本内容和事件等信息封装为一组对象和方法,并通过JavaScript来操作这些对象和方法。DOM以树形结构组织HTML文档,也被称为HTML结构树。 HTML结构树是由各种HTML元素和它们之间的关系构成的层次结构,其中最上层是HTML(或者XHTML)元素,它作为树形结构的根节点。树形结构的每个节点都代表着一个HTML元素,节点之间的关系代表着HTML元素之间的嵌套关系。每个HTML元素都可以包含指定的标签、文本和属性。 通过DOM可以以编程方式访问和操作这些HTML元素和它们的属性、文本和事件,包括创建、修改和删除,从而改变HTML文档的内容和样式。例如,可以使用DOM操作来创建一个新的HTML元素、修改元素的样式或者添加事件处理程序来响应用户交互事件。 常见的网页编码包括UTF-8、GBK、ISO-8859-1等等。在网页设计和开发中,选择恰当的字符编码是至关重要的,因为不同的编码方式具有不同的特点和适用范围。例如,UTF-8编码是一种常用的国际化编码方式,可兼容多种语言、字符集和设备,而GBK编码主要用在中文网页中,ISO-8859-1编码则是西方的字符编码方式。 在HTML文档中,通常需要在head标签中使用meta标签来指定网页的字符编码,例如:meta charset=“utf-8” 。这样浏览器才能正确地解析网页中的字符并显示出来,避免出现乱码等问题。 (1)ASCII(American Standard Code for Information Interchange):ASCII 是一种由美国标准技术研究所(ANSI)开发的字符编码方式。它最初是为了使电脑和电传打字机之间进行通信而设计的,包含了 128 个字符(从 0 至 127),包括 33 个不可打印字符。 (2)GBK(Guo Biao Kai):GBK 编码是一种中文编码,它支持简体和繁体中文、韩文、日文等语言。与 UTF-8 不同,GBK 是一种固定长度的编码方式,一个汉字占用两个字符位。 (3)Unicode:Unicode 是一种用于字符编码的标准,它支持几乎所有的语言和字符集,包括日文、韩文、汉字、英文字母等等。 (4)UTF-8(Unicode Transformation Format):UTF-8 是一种可变长度的编码方式,能够表示所有 Unicode 字符。UTF-8 是最常用的网页字符编码方式,在因特网上广泛使用。它能够表示几乎所有的语言的字符,包括亚洲语言、西里尔语、希腊语、拉丁语、符号和表情符号等。 (1)访问控制:通过代理可以实现对网络的访问控制,例如限制访问特定网站、禁止特定 IP 地址的访问、限制访问特定的端口等。 (2)缓存加速:代理服务器可以缓存已经访问过的资源,当用户再次访问同一资源时,可以直接从代理服务器中获取,避免了网络传输的时间消耗,从而加速访问速度。 (3)安全过滤:代理服务器可以对访问数据进行安全过滤,例如过滤恶意程序或病毒、屏蔽多余的广告、过滤有害信息等。 (4)隐藏真实 IP:代理服务器可以修改发送请求中的源 IP 地址,隐藏请求方的真实 IP 地址,从而提高匿名性和安全性。 (5)访问限制:在一些网络环境受限的情况下,代理可以帮助用户绕过网络限制,例如在企业或学校网络中访问被屏蔽的网站。 爬虫代理(Crawler Proxy),简称代理,是指在网络爬虫程序中,使用代理服务器来访问被爬取的网站。代理服务器可以屏蔽爬虫的真实 IP 地址,避免被网站屏蔽,同时也能够减轻爬虫的访问负载。 (1)匿名度:按照匿名级别可分为透明代理、匿名代理和高匿代理,其中透明代理会将请求方的真实 IP 地址直接暴露给服务器,匿名代理则会隐藏请求方 IP 地址,而高匿代理则隐藏请求方 IP 地址同时伪装请求头部,使得被访问的服务器无法检测到请求方真实 IP 的存在。 (2)用途:按照代理的应用领域可以分为 HTTP 代理、HTTPS 代理、SOCKS 代理等不同类型,主要用于不同的网络环境和应用场景。 (3)身份验证:按照是否需要进行用户身份验证可以分为免费代理和付费代理,免费代理一般不需要进行身份验证,可直接使用,而付费代理则需要账号和密码等身份验证信息,可以提供更高质量的服务和更稳定的代理源。 (4)地理位置:代理服务器可以按照地理位置进行分类,主要根据距离和网络延迟等因素进行选择。在进行网络爬虫等任务时,可以选择距离目标网站较近且网络延迟较小的代理服务器,以提高爬取效率和速度。 实现代理的方法这里简要介绍一下: 这里将 无论采取何种代理方式,都需要注意合理的设置代理请求频率,避免被网站限制或封禁 IP 的风险。 (1)危害: (1)Robots协议是一种由网站所有者制定的网页爬虫规范,即爬虫应该遵守哪些网页爬取规则。该协议通常存储在网站的根目录下的 robots.txt 文件中,有些搜索引擎爬虫在爬取网站前会先访问该文件,从而了解该网站的robots协议规则。 (2)关键语句 User-agent: 该命令指明了本条规则适用于哪些网络爬虫或搜索引擎。例如,“User-agent: Googlebot” 表示该规则适用于 Google 搜索引擎爬虫。 Disallow: 该命令用于指定禁止被爬取的页面或目录。例如,“Disallow: /private/” 表示禁止爬取 “/private/” 目录下的所有页面。 Allow: 该命令用于指定允许被爬取的页面或目录,如果未指定,则默认允许所有页面被爬取。 Crawl-delay: 该命令用于指定爬虫访问同一网站时的请求间隔时间。例如,“Crawl-delay: 10” 表示每次访问间隔 10 秒。 Sitemap: 该命令用于指定网站地图的位置,方便爬虫有序地进行网站内容爬取。例如,“Sitemap: http://www.example.com/sitemap.xml” 表示网站地图文为"http://www.example.com/sitemap.xml"。 (1)正常用户浏览行为和爬虫行为 (2)爬虫检测技术: (3)爬虫阻断技术 (1)针对IP与访问间隔的限制: 简单地说,爬虫就是获取网页并提取和保存信息的自动化程序,也就是获取信息-提取信息-保存信息 爬虫(Crawler),也称网络蜘蛛(Web Spider)或者网络爬虫(Web Crawler),是一种自动化程序,可以模拟人类用户对网页进行访问,并抓取其中的内容。 爬虫在网络应用和数据分析等领域有着广泛的应用。例如,搜索引擎通过爬虫来获取和索引网页内容,企业和科研机构可以通过爬虫来收集和分析社交媒体数据、产品信息等;实时的新闻、天气、财经传票等信息也可以通过爬虫及时获取。但同时,如果用户使用爬虫进行恶意抓取、刷量等行为,对网站的稳定性、用户体验和数据安全都会产生影响。因此,需要在开发爬虫和使用爬虫的过程中注意遵守行业规范、合法合规使用,避免产生不良影响。 超链接爬行策略是指通过遍历一个网站内的所有页面来抓取数据的方法。常见的两种策略是深度优先和广度优先。 深度优先爬行策略是指首先访问一个页面,然后访问该页面的所有链接,直到所有链接都被访问过,然后再转入下一个页面并重复这个过程。这种策略的主要优点是速度较快,可以快速抓取深处的数据,但可能无法发现网站的所有链接,存在遗漏的可能性。 广度优先爬行策略是指从一个页面开始,访问该页面所有的链接,然后访问这些链接所指向的网页,再逐一访问这些网页的链接,以此类推,直到所有页面都被访问过。这种策略可以有效遍历网站的所有页面,但速度较慢,需要较长的时间。 深度优先和广度优先爬行策略各有优缺点,因此需要结合实际需要和情况选择合适的策略。在实际应用中,通常采用混合策略。 例如,可以优先使用广度优先策略,以便快速发现站点的整体结构和所有链接,然后在进一步深入抓取数据时采用深度优先策略。这样既能保证整体遍历的广度,又能充分抓取到网站深层次的数据。如果需要检索特定内容的页面,则可以采用从某个页面出发的深度优先策略。 PageRank算法是一种基于链接分析的页面排序算法,广泛应用于网页排名、搜索引擎、社交网络等领域。在爬虫方面,PageRank算法通常被用来识别和抓取最有价值的网页。 PageRank算法的基本思想是:对于一个网络中的每个网页,分配一个权值,这个权值取决于其他网页对它的链接数量以及这些其他网页的权值。权值越高的网页越可能是重要的。具体来说,PageRank算法建立起一个网页图,该图的节点分别是网络中的网页,边表示网页之间的链接关系,然后通过不断迭代和更新,计算每个网页的权重值,最终得到每个网页的PageRank值。 PageRank算法的大致步骤如下: 值得注意的是,PageRank算法在处理复杂网络和大规模数据时速度较慢,对于其中的某些节点可能存在值分配不足或分配偏向相似网页的渗透问题。为了解决这些问题,还需要采用一些衍生算法和改进方法,例如HITS算法、TrustRank算法、Topic-Sensitive PageRank算法和Local PageRank算法等。这些方法可以进一步提高PageRank算法的准确性和应用效果。 在线重要指数(OPIC)是一种用于评估网页重要性的算法。在爬虫领域中,OPIC 策略被广泛应用于基于链接分析的页面排序和索引算法中。 OPIC 的核心思想是将页面的重要性转化为一个数值优化问题,通过迭代计算不断更新每个页面的重要性得分。具体来说,OPIC 算法将每个页面视为一个节点,并通过它们之间的链接关系来计算页面的权重值。在每个节点上,OPIC 算法会计算两部分得分:一部分是该页面本身的重要性得分,另一部分是指向该页面的链路贡献的权重值。然后,通过不断通过网络图来调整每个页面的权重分配,OPIC 算法可以更准确地评估页面的重要性。 值得注意的是,OPIC 算法不同于 PageRank 算法。尽管它们都是基于链接分析的评估算法,但它们是使用不同的权重计算方法和迭代过程。OPIC 算法是一个更为灵活和通用的算法,在处理复杂网络、非线性结构和高度关联的页面时,能够取得更好的效果。 其计算过程可以简单概括为以下几步: 相对于传统的PageRank算法,OPIC算法采用更为平滑的引用赋权机制,并且可以克服一些PageRank算法的局限性。 OPIC 算法也可以通过一些扩展方法来解决一些复杂网络的问题,例如对垃圾邮件检测、社会网络分析等领域有很好的应用。 在爬虫中,大站优先策略指的是对一些权威网站或者流量较大的网站进行优先爬取,以提高爬取效率和数据质量。这样做的好处是,这些大站通常有更好的服务器和带宽资源,可以更快地返回数据,而且数据量更大、质量更高。同时,有些小站或者个人网站可能存在反爬虫机制,限制了爬虫的访问频率和并发数,因此优先处理大站可以减少被限制的风险。 下面是一些实现大站优先策略的方法: 需要注意的是,在实际操作中,优先处理大站并不意味着可以不考虑小站和个人网站,也不意味着可以忽略反爬虫机制。为了保证爬虫的稳定性和可持续性,应该对所有网站都进行合理的访问调度和反爬虫策略,例如设置 User-Agent、使用代理、轮换 IP 等措施。### 5、合作抓取策略 requests库是Python中常用的第三方网络请求库,它基于urllib3实现,requests通过代码模拟浏览器发送请求报文、接受相应报文 还有一些其他的方法,例如requests.head()、requests.options()等,这里不再一一介绍。 requests库中的响应对象提供了多个属性,可以帮助我们获取HTTP响应的信息,常见的属性如下: 这些响应属性可以帮助我们获取HTTP响应的详细信息,从而进行进一步的处理和分析 备注:为什么要有这一步?r.encoding = r.apparent_encoding 在使用requests库发送HTTP请求并获取响应时,我们可以通过response对象的encoding属性来获取HTTP响应的文本编码方式。通常情况下,如果HTTP响应包含有charset信息,那么requests会自动检测并设置response对象的encoding属性。但有时,由于一些特殊原因,HTTP响应会缺少charset信息,这时requests就无法自动检测响应文本的编码方式,从而无法正确解码响应内容。因此,当我们遇到这种情况时,可以通过r.apparent_encoding的方法来获取HTTP响应的编码方式,然后再将该编码方式赋给response对象的encoding属性。这样就可以确保我们能够正确解析HTTP响应内容了。 Ajax 全称是 Asynchronous JavaScript And XML,是用于在Web应用程序中,异步地向服务器发送 HTTP 请求并动态更新网页内容的一种技术。 在传统Web应用程序中,当用户触发某个事件(如点击按钮)时,浏览器会向服务器发送一个 HTTP 请求,服务器处理请求后返回响应,浏览器根据响应的结果刷新页面。这种方式需要每次都刷新整个页面,造成了许多不便。 而通过 Ajax 技术,Web 应用程序无需进行整个页面刷新,仅需更新需要修改的内容部分。具体而言,Ajax 将一个 HTTP 请求异步发送至服务器(不会阻塞页面),服务器返回请求的结果,浏览器接收到响应后,使用 JavaScript 解析响应内容,并相应地修改页面某个区域的内容。同时Ajax的核心是XMLHttpRequest对象,xhr是Ajax的特殊请求类型 爬取Ajax页面和爬取普通静态页面的最大区别在于数据获取方式不同,Ajax页面的数据是通过异步请求获取的,而不是直接在HTML页面中展示。 当我们需要爬取 Ajax 页面时,主要需要进行以下三个具体步骤: 打开浏览器开发者工具,切换到网络(或者 Network )面板,在观察页中执行 Ajax 操作,可以看到浏览器向服务器发送的网络请求。通过浏览器开发者工具中的网络面板,我们可以观察到请求的 URL、请求方式、请求头和请求参数等信息。 通过以上步骤,我们可以获取到该 Ajax 请求的相关信息。接下来,我们需要在爬虫代码中模拟该请求。 常见的模拟网络请求的方式是使用 Python 第三方库 Requests(或者其他 HTTP 客户端库),向指定的 URL 发送网络请求,并附带在步骤 1 中观察到的请求头和请求体等参数。 对于一些复杂的 Ajax 请求,我们需要仔细分析请求参数的含义,向服务器发送正确的请求参数和请求头等信息。如果无法直接获取 Ajax 请求中的参数,可以使用浏览器开发者工具进行分析,或者使用 Fiddler、Charles 等抓包工具进行分析。 如果一切顺利,我们应该能够从步骤 2 中发送的请求中获取到响应数据。Ajax 响应数据通常是 JSON 格式的。我们可以使用 Python 内置的 需要注意的是,Ajax 页面的数据通常都是通过 JavaScript 动态渲染的。因此在处理 Ajax 页面时,我们需要注意爬取到的数据是否已经完成了 JavaScript 的渲染。可以通过使用浏览器自动化测试工具(例如 Selenium)来模拟 JavaScript 的执行,从而获取完整数据。 以上是爬取 Ajax 页面的具体步骤。需要注意的是,因为 Ajax 页面的数据通常是通过 JavaScript 动态渲染的,因此需要特别小心,确保所有数据都被正常渲染。此外,爬取 Ajax 页面时需要注意发送正确的请求参数和请求头等信息,并避免对服务器造成不必要的负担。 在以上代码中,我们调用 简单地说, 除了 在上面的代码中,我们使用 需要注意的是, 在AJAX中,通常使用JSON格式作为数据交换的标准,因此,AJAX返回的数据通常是JSON格式。返回数据的格式主要取决于后端服务器的实现。在AJAX和后端服务器之间进行数据交换时,服务器会按照所请求的返回的数据格式返回相应的数据。 实际上,AJAX并不关心服务器返回的数据格式,只需要通过JavaScript解析返回的数据即可。常见的JSON解析库有 以下是一个简单的AJAX请求,并将返回的JSON字符串转化为JS对象: 以上代码使用 需要注意的是,虽然JSON格式越来越广泛地应用于数据交换,但并不是所有的HTTP响应都是JSON格式的。在开发过程中,我们需要仔细阅读API文档,了解服务器响应的格式和具体要求,以便正确处理返回的数据。 Beautiful Soup 是一个 Python 包,用于从 HTML 和 XML 文档中提取数据。它可以解析 HTML 或 XML 文档,并构建相应的树形结构,在此基础上提供了简单的 API,方便用户快速地索引、修改以及遍历文档中的节点。 Beautiful Soup 的基本语法非常简单,主要分为两部分:解析页面和查找节点。 Beautiful Soup 是一个 Python 的 HTML/XML 解析库,它可以将 HTML/XML 文档转换为解析树,并提供了一些方法来搜索、遍历和修改解析树。 以下是一个使用 Beautiful Soup 解析 HTML 的示例: This is some content. 在上述代码中,我们首先导入了 常见的解析器有以下几种: 根据解析器的特性和应用场景,可以选择合适的解析器,假设都安装了,那么根据系统设定,解析器的默认优先顺序为:lxml,html5lib,pyhton标准库。 注意:使用 (1)HTML 节点树 HTML 节点树是由 HTML 标签元素和文本节点组成的树形结构,其中 HTML 文档有且仅有一个根节点 html,每个标签元素都是该节点的一个子节点,文本节点也可以作为标签元素的子节点。 节点之间的关系如下: (2)各个节点 Tag就是HTML中的一个个标签,它有两个重要属性,分别是name和attrs 但是通过点取属性只能获得当前名字的第一个tag,要想获取更多内容时,需要使用一些搜索函数,比如 find_all() NavigableString,当我们获取标签之后,可以通过,tag.string来获取标签之间的内容,比如上述的tag_a.string,输出之后就是“百度一下,你就知道” 以上示例中,我们定义了一个名为 对于标签节点,递归调用 需要注意的是,使用递归方式获取子节点的文本内容时,需要注意避免陷入无限递归的情况。对于复杂的 HTML 文档,建议单独编写处理函数,并仔细测试避免出现异常情况。 BeautifulSoup对象表示的是一个文档的全部内容,通常情况下把它当作tag对象,但是要注意,它并不是完全的tag,因此没有name和attribute属性 Comment对象是一个特殊的NavigableString对象,它主要用来处理注释对象。通常以 以下是一个示例 HTML 文档,其中包含了一个注释: 我们可以使用 Beautiful Soup 来解析该文档,并获取其中的注释内容。示例如下: 以上示例中,我们遍历了 输出结果为 虽然可以采用属性来选择,但是在进行一些比较复杂的选择,它就不够灵活了,因此我们可以采用方法选择器来解决问题 以下是一些常用的方法选择器: 其中, 以下是一个示例 HTML 文档: 我们可以使用方法选择器来选择其中的节点,示例如下: Hello, World! Goodbye, World! Paragraph 1 Paragraph 2 以上示例中,我们使用 如果将多个标签名作为列表参数传递给 以下是一个示例 HTML 文档: 我们可以使用 Paragraph 1 Paragraph 2 以上示例中,我们使用 在 CSS 中,选择器被分为五种种类,它们分别是:基本选择器、关系选择器、属性选择器、伪类选择器和伪元素选择器。下面我们来介绍这五种选择器在 Beautiful Soup 中的用法。 (1)基本选择器 标签选择器:用标签名选取元素,例如 soup.select(‘p’) 查找所有 p 标签元素; 示例代码: (2)组合选择器 后代选择器(空格):选取所有满足条件的后代元素,例如 soup.select(‘div a’) 查找所有 div 标签下的 a 标签; (3)属性选择器 在 Beautiful Soup 中,可以使用 [attr=value] 的形式来选取具有特定属性和属性值的元素,例如 soup.select(‘[href=“https://www.baidu.com/”]’) 能够选取所有 href 属性值为 https://www.baidu.com/ 的元素。 注意!在 Beautiful Soup 中,基本上没有使用到伪类选择器和伪元素选择器。 在 Beautiful Soup 中,通过遍历文档树,我们可以获取标签节点的各种信息,同时也可以进行标签节点的筛选、过滤和修改等操作。以下是几种主要的遍历方法: 我们可以通过 示例代码: Paragraph 1 Paragraph 2 在这个示例中,我们通过 我们可以通过 示例代码: Paragraph 1 Paragraph 2 在这个示例中,我们通过 我们可以通过 示例代码: Paragraph 1 Paragraph 2 在这个示例中,我们通过 总之,通过 Beautiful Soup 提供的遍历方法,我们可以轻松地遍历文档树,并操作其中的元素节点,从而实现对网页内容的抽取和解析。需要注意的是,输出格式不是列表,而是 Beautiful So XPath 是一种在 XML 和 HTML 文档中进行导航和查找的语言。在网络爬虫中,XPath 是一种常用的元素解析方法。使用 XPath,我们可以针对网页的特定元素节点,快速地获取其内容,从而实现对网页数据的抓取和解析,Xpath的基本语法同样是页面解析和查找。 注意,当网页为文件时,可以采用以下 示例代码 XPath 节点轴(Axis)是在 XPath 表达式中用于查找节点之间关系的一种机制。 它定义了一种从一个节点向其它方向移动的方式,如父节点、子节点、同级节点等,并允许使用特殊语法来查找满足某些关系或条件的节点。 以下是常见的 XPath 轴: 示例代码 正则表达式(Regular Expression,简称为 Regex 或 RE)是一种文本模式,经常用于在文本中按照某种规则进行匹配、查找或替换。在 Python 中,可以使用 re 模块来操作正则表达式。 以下是一些常见的正则表达式匹配规则及其解释: 这些规则可以结合起来使用,构成更复杂的模式。例如: 在实际的正则表达式中,通常还会使用一些元字符和特殊字符,例如 正则表达式在 Python 中,常用的四种方法分别是: re.match(pattern, string, flags=0):从字符串的起始位置匹配一个模式,如果匹配成功,则返回一个匹配对象,否则返回 None。 re.search(pattern, string, flags=0):从字符串的任何位置匹配一个模式,如果匹配成功,则返回一个匹配对象,否则返回 None。 re.findall(pattern, string, flags=0):搜索字符串,以列表的形式返回其中所有匹配模式的子串。 re.sub(pattern, repl, string, count=0, flags=0):在字符串中替换指定的模式,将其中匹配模式的子串替换为指定的字符串或函数的返回值。 这些方法都接收三个参数:模式 举个例子,下面是一个使用了这些方法的示例: 在这个示例中,我们定义了一个简单的正则表达式 另外详细解释一下sub()。在正则表达式中, 其中, 举个例子,假设我们需要将字符串中的所有数字替换为 在这个示例中,我们定义了一个字符串 需要注意的是, 正则表达式支持一些修饰符,它们可以用来改变正则表达式引擎的某些行为。以下是一些常见的修饰符: re.I:忽略大小写。 下面是一些具体的例子,来详细说明正则表达式中的修饰符: 这个修饰符可以用来忽略大小写,即在匹配时不区分大小写。例如,正则表达式 在这个示例中,我们使用了 这个修饰符可以用来支持匹配多行文本,即会将文本分成多行,并允许 在这个示例中,我们使用了 这个修饰符可以用来启用点任意匹配模式,即允许 在这个示例中,我们使用了 这个修饰符可以用来限制匹配到 ASCII 字符集,即仅匹配 ASCII 字符。例如,正则表达式 在这个示例中,我们使用了 这些修饰符可以单独使用,也可以混合使用 例如,我们可以使用 在这个示例中,我们使用 编译后的正则表达式对象也可以使用 总之,正则表达式的核心操作是通过 当然,如果需要反复使用同一个正则表达式的话,推荐使用 compile() 方法,这样可以大大提高效率,因为这些函数多次调用时都会进行正则表达式编译,造成不必要的重复工作。 贪婪匹配和非贪婪匹配都是正则表达式中的概念,用于控制匹配的规则和方式。贪婪匹配指的是在匹配过程中尽可能多地尝试匹配,并且不会回退。而非贪婪匹配则表示在匹配过程中尽可能少地尝试匹配,并且在匹配完成后还可以回退。 在正则表达式中,尽可能多地匹配表示为在一个子表达式末尾加上一个 以一个简单的例子来说明: 在这个例子中,我们定义了一个简单的待匹配的字符串 最后,我们输出了这两种匹配方式返回的结果,可以发现贪婪匹配返回了两个 a 标签中间的所有内容,包括第一个 a 标签和第二个 a 标签间的文本。而非贪婪匹配只返回了每个 a 标签中间的内容,没有包括中间的文本。 txt文本存储优点是简单并且兼容任何平台,缺点是不利于检索,因此,对检索和数据结构要求不高的,使用方便的话,可以使用txt文本存储 通用代码 在 Python 中, file:文件名(字符串),包含文件路径。 mode:读取文件的模式,通常用以下几种: encoding:用于对文本模式进行编码/解码的编码方式,通常使用 UTF-8 等编码方式。 errors:指定编码和解码过程中可能出现的错误的处理方式,通常使用 例如,使用 这里使用 JSON (JavaScript Object Notation)是一种轻量级的数据交换格式,常用于Web开发和移动应用中。它由两个部分组成:结构化的数据和表示数据结构的语法。 JSON 数据格式由键值对组成,由大括号 下面是一个 JSON 格式数据的示例: 该 JSON 数据表示一个人(Tom)的信息,包括姓名、年龄、性别、兴趣爱好和所在地。其中,“hobbies” 和 “location” 是嵌套的键值对,即一个数组和一个对象。 在 Python 中,我们可以使用 在这个 Python 示例中,通过 JSON 格式的出现使得不同的应用程序可以通过 JSON 数据进行交换和共享,减少了应用程序间的耦合,提升了系统的可扩展性和可维护性,因此被广泛应用在 Web 应用程序开发中。 在 Python 中,使用 json 模块可以很方便地读取 JSON 数据。具体来说,可以使用 json.load() 和 json.loads() 两种方法将 JSON 数据转换为 Python 对象。 两者的区别在于 使用 在 Python 中,我们可以使用索引来获取 JSON 对象中的内容。如果我们要获取 JSON 对象中的某个属性的值,可以使用键名进行索引。 以下是一个例子,假设我们有以下的 JSON 数据: 我们可以使用以下代码获取数据: 在上面的代码中,我们使用了字典的形式来获取 JSON 数据中的属性值,其中 需要注意的是,如果 JSON 数据中不存在对应的键值对,以上代码将会抛出 其中,第一个参数 以下是一个示例,将一个 Python 字典转换为 JSON 格式的字符串: 在使用 需要注意的是,如果 Python 对象中包含了一些自定义的数据类型或实例,需要提供一个可序列化的函数来转换这些对象,否则将会抛出 如果要将一个 在上面的示例中,我们定义了一个名为 CSV(Comma-Separated Values)是一种常见的文件格式,用于存储和交换表格数据。CSV 文件以文本形式存储数据,文件中的每一行都代表一条记录,每一列由逗号、分号、制表符等字符分隔。 在 CSV 文件中,每一行的数据通常被组织成若干个字段,每个字段之间使用逗号或其他分隔符隔开。通常,第一行为标题行,包含每一列的列名,而后面的行则为数据行,存储着对应的值。 以下是一个示例,展示了一个简单的 CSV 文件: 在这个示例中,每一行代表一个人的信息,其中第一行为标题行,包含 name、age 和 country 三个字段;后面的三行则为数据行,分别对应三个人的信息。 上述代码使用 Python 内置的 值得注意的是,在进行 CSV 文件读取时,我们需要指定文件编码方式。在示例中,我们使用了 UTF-8 编码,可以根据文件的实际情况进行相应的调整。 如果需要将数据写入 CSV 文件中,可以使用 在上述示例中,我们首先定义了一个 Python 列表 Scrapy 是一个基于 Python 的开源网络爬虫框架,用于快速开发高效、可扩展的网络爬虫应用程序。 Scrapy 框架提供了一些便捷的功能,例如自动的请求调度、数据解析、异步处理、数据存储等等,可以通过它们轻松地构建一个完整的网络爬虫系统,同时还具有优秀的可扩展性和灵活性。因此,Scrapy 在网络数据爬取方面被广泛地应用于各种场景中。 下面是一些 Scrapy 框架的主要特点: Scrapy 基于 Twisted 异步网络框架,所以自带异步处理和数据抓取速度快的优势。同时拥有强大的架构设计和并发性能,使得数据的爬取、存储变得更为高效和稳定。 Scrapy 采用了插件式架构设计,用户可以根据需求很容易地扩展 Scrapy 的功能,例如自定义中间件、管道、扩展等。此外,Scrapy 还提供了丰富的插件和 API 接口供用户使用和开发。 Scrapy 内置了基于 lxml 以及 Beautiful Soup 的解析器,可以灵活地解析和提取出页面中的数据。而且,它也支持将数据存储到多种不同的数据存储系统中,如 MySQL,MongoDB,Redis 等等。 Scrapy 的调度器能够自动处理请求的优先级和排队,并且自动支持对失效请求的重试,这样可以保证爬虫全天候高效稳定运行。 Scrapy 支持多种文件协议,例如 HTTP、FTP 等,同样支持包括 SSL 和 TLS 在内的各种网络安全协议。 在使用 Scrapy 框架时,需要熟悉 Scrapy 的基本组件,包括爬虫、调度器、下载器处理器、项目管道、中间件、扩展程序等等。同时,还需要熟练掌握 Python 网络编程、异步编程、反爬机制、数据解析等相关技术。 总之,Scrapy 是一个高效、可扩展、易用、灵活的 Python 网络爬虫框架,通过它你可以轻松地构建一个高效的网络爬虫系统,快速地获取所需数据。 5+2 结构,也叫做 Scrapy Distributed Crawler Architecture,是一种常用的分布式爬虫系统架构。 该架构将整个爬虫系统分成两层,前五层是同步的数据处理流程,而后两层是异步分布式任务调度和处理流程。 具体而言,这个架构包含以下几个部分: User Interface (UI):用户界面,是用户与整个系统交互的前端,通常是通过网页、移动应用或其他可视化界面来进行爬虫任务的管理和配置等操作。 Scheduler:调度器,是整个爬虫系统的核心,它接收用户界面的指令,将请求添加到调度队列中,并将下载器调度到请求队列中去。通过调度器,可以实现队列的优先级和去重,以确保爬虫的有效运行。 Spiders:爬虫,是一组模块,用于执行网络爬取操作。通常通过 URL 管理器来控制爬取的 URL 列表。对于每一个 URL,爬虫可以在页面中提取数据内容,生成对应的数据项目并发送给 Item Pipeline 进行处理。 Item Pipeline:项目管道,是数据流中一系列处理程序的链。它负责对抓取请求进行后续的处理,包括清洗、存储、去重、存储频率控制等。数据可能会被处理为不同的格式,并存在不同的存储系统中,如数据库、文本文件、二进制文件、内存中等。 Downloader:下载器,是用于下载网页内容的组件。它接收调度器的请求,发送请求并接收响应,将响应传递给爬虫进行处理。下载器负责处理代理、超时、重试和其他下载相关的问题,常常在使用代理时需要注意进行 IP 池的维护。 Scheduler Queue:调度器队列,是一种高效的消息队列,用于存储和传输爬虫任务请求消息,以便多个爬虫和分布式节点处理这些任务消息。 Distributed Queue:分布式队列,是一个分布式的任务队列,用于协调和监测多个分布式数据节点的任务状态。当分布式数据节点完成任务时,它们会向该分布式队列发送状态更新信息。 5+2 结构将整个爬虫系统划分成前五个层次,这五个层次可以简单高效地控制整个爬虫的流程,后两个层次则将系统扩展为分布式架构,使其可以更高效且可扩展地进行海量数据抓取任务的处理。 步骤1: 创建一个Scrapy爬虫工程 步骤1:创建一个 Scrapy 爬虫工程,可以使用以下命令: 步骤2:在工程中产生一个 Scrapy 爬虫,可以使用以下命令: 步骤3:配置 Item 文件,可以在项目的 items.py 文件中定义需要采集的数据字段: 步骤4:配置产生的 spider 爬虫 quotes,可以在项目的 spiders/quotes.py 文件中根据需要配置爬虫的规则、数据提取等相关内容: 步骤5:编写 Item Pipeline,可以在项目的 pipelines.py 文件中定义 Item Pipeline 进行数据处理: 步骤6:优化配置策略,可以在项目的 settings.py 文件中进行相关配置: 步骤7:运行 Scrapy 或保存到文件,在命令行中使用以下命令来运行程序并输出结果: 或者,将运行结果保存到文件中: 以上就是一个简单的 Scrapy 爬虫的编写和运行过程,具体的实现方式和配置参数可以根据实际需要进行调整和修改。是需要指定文档类型的声明标记,标签是整个文档的根标签,标签包含了元素的元数据信息,如标题、关键字和描述等,标签包含了文档的主体内容,包括各种HTML元素,例如段落、标题等。
在HTML中还有许多其他类型的标记可以使用,例如图像标签、列表标签等等。使用这些标记,我们可以快速、灵活地创建Web页面。
(2)注意!
HTML是一种标记语言,编程语言通常在程序执行前需要使用编译器,将高级语言翻译成低级语言、机器语言,脚本语言不需要编译器,它需要解释器,即在运行时逐句输入代码及数据,由解释器进行解释执行,标记语言是表示语言,不含有任何逻辑和算法(比如HTML、XML)
(3)常用标签:

2、CSS定义、语法、选择器
CSS语法由选择器、属性和值三个部分组成

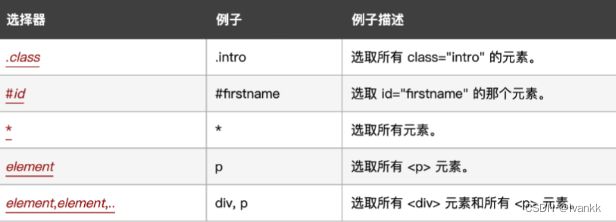
(2)CSS选择器可以分为五类:简单选择器、组合选择器、属性选择器、伪类选择器、伪元素选择器
简单选择器:
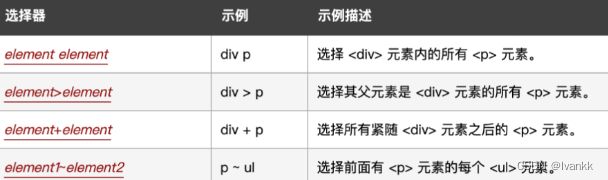
组合选择器
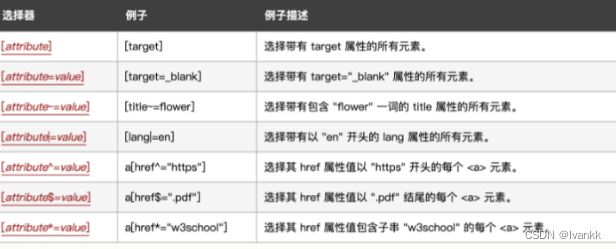
属性选择器
属性选择器根据HTML元素的属性来选择元素,可以指定匹配属性的值或属性值以特定值开头或者结尾。
伪类选择器

伪元素选择器

3、js定义
JavaScript是一种实现页面实时、交互、动态的脚本语言
doctype html>
<html>
<head>
<meta charset="UTF-8">
<title>JS Exampletitle>
<script src="main.js">script>
head>
<body>
<h1 id="greeting">Welcome to my websiteh1>
<button onclick="changeText()">Click mebutton>
body>
html>
标签中,我们定义了一个 标签,其中有一个 id 属性为 “greeting”。还定义了一个按钮,通过 onclick 事件来调用 JavaScript 函数。
function changeText() {
document.getElementById("greeting").innerHTML = "Hello, World!";
}
changeText() 的函数,该函数通过 document.getElementById() 方法找到页面上的 greeting 元素,然后将其内容更改为 “Hello, World!”。4、HTML结构树-DOM
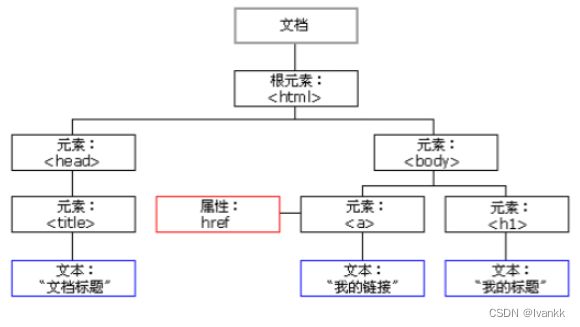
(五) 编码体系及规范
1、网页编码是什么
网页编码是指网页中的字符编码方式。
2、具体编码形式
3、python中的编码处理
pyhton3中字符串默认的编码为unicode。必须使用encode()将unicode编码为utf-8、gbk等,而使用decode()将utf-8、gbk等字符编解码为unicode
(六)代理
1、概念
代理实际上指的是代理服务器(proxy server),它的功能是代理网络用户去获取网络信息
2、代理的作用
3、爬虫代理
4、代理分类
5、代理实现举例
import requests
proxies = {
'http': 'http://10.10.1.10:3128',
'https': 'http://10.10.1.10:1080',
}
response = requests.get(url, proxies=proxies)
http 和 https 协议都设置了代理服务器的地址和端口,注意 https 建议使用 socks5 类型的代理。
import requests
import socks
import socket
socks.set_default_proxy(socks.SOCKS5, 'localhost', 1080) #设置代理类型和代理服务器地址和端口
socket.socket = socks.socksocket #将 socket 的默认代理设置为 SOCKS5
response = requests.get(url)
(七)Robots协议
1、网络爬虫的危害和治理
对服务器进行性能骚扰
面临法律风险(服务器数据的产权归属,网络爬虫获取数据后牟利将带来的法律风险)
个人隐私泄露
(2)网络爬虫治理
来源审查:判断User-Agent进行限制,检查来访的User-Agent,只相应浏览器或友好爬虫的访问
发布公告:发吧Ronots协议,要求爬虫遵守协议2、Robots协议的规范和实现
一般在浏览器打开网站后,在网站地址后添加"/robots.txt",如果网站设置了访问许可,则可以看到网站的robots协议。(八)反爬虫技术和反反爬虫技术
1、反爬虫技术
反爬虫的工作主要包括两个方面,即不友好爬虫的识别和爬虫行为的组织。
爬虫检测技术:识别爬虫,区分不友好爬取行为与正常浏览行为及友好爬虫的差异
爬虫阻断技术“阻止恶意的爬取,同时能够在识别错误时为正常请求提供一个放行的通道



2、反反爬虫技术
不使用真实IP,爬虫使用代理服务器或者云主机等方式进行IP的切换
(2)针对Header的内容验证
使用内嵌浏览器进行浏览器的访问和模拟,构造合理的Headers信息
(3)针对cookies验证
使用不同的线程来来记录访问的信息,为每个线性保存cookies
(4)针对验证码:
当前流行的验证码主要分为4类,即计算验证码,滑块验证码、识图验证码、语言验证码,主流的破解有两种,即机器图像识别与人工打码,还可以使用浏览器插件绕过验证码
(5)针对页面异步加载与客户端JS支持判断:
可以使用Selenium进行js解析
(6)针对动态调整页面结构:
最好的办法就是先采集页面,然后根据采集到的页面进行分类处理,尝试使用正则表达式,将结构中的随机因子摒弃
(7)针对蜜罐方式的拦截:
只有一个策略,爬虫在解析出一个超链接后不要着急进入超链接,首先分析蜜罐的结构,分析出异常后,再提交表单和采集页面时绕过蜜罐三、 爬虫介绍和关键策略
(一)爬虫介绍
爬虫的基本原理是通过网络协议和通信接口向服务器发送请求,获取数据并进行解析、处理和存储。通常情况下,爬虫需要具备以下功能:
(二)爬虫关键策略
1、超链接爬行策略
2、PageRank算法
3、在线重要指数(OPIC)策略
4、大站优先策略
通过服务器的IP地址来分解,让爬虫仅仅抓取某个地址段的网页。或者通过网页域名来分解,让爬虫仅抓取某个域名段网页四 、页面爬取技术
(一)基于Requests的页面爬取
1、Requests库介绍:
2、Requests库基于HTTP协议的主要方法:
url表示所请求的URL;可选参数params是一个字典或者字节流,用于向URL查询字符串里添加额外的参数。url表示所请求的URL;可选参数data是一个字典或字符串,用于向请求体里添加额外的参数;可选参数json是发送POST请求时要提交的JSON数据,该参数以JSON格式提供一个对象,它将自动被编码为JSON,并添加到请求体中。requests.post()方法相似,只是该方法会发送PUT请求。url表示所请求的URL。headers来传递HTTP头信息以及其他设置,例如代理、认证等。其中,参数method是所请求的HTTP方法字符串,参数url是所请求的URL。3、响应对象属性
.text:HTTP响应内容的字符串形式,如果响应信息为文本,返回Unicode字符串;如果是二进制数据,返回的是bytes类型数据。.content:HTTP响应内容的二进制形式,返回类型为bytes。在获取位于响应体中的二进制数据时非常有用。.status_code:HTTP响应的状态码,如200表示请求成功,404表示找不到页面等。可以通过这个属性判断请求是否成功。.headers:HTTP请求的响应头,以字典形式返回。每个键代表一个头部,每个值代表相应的头部值。.cookies:HTTP响应的cookies。以字典形式返回,可以通过这个属性来获取服务器设置的cookie。.url:HTTP响应的URL地址,返回一个字符串。.encoding:HTTP响应的编码方式。.json():将HTTP响应解析为JSON数据,并返回一个Python对象。如果响应的内容不是JSON格式,会抛出一个ValueError异常。4、通用代码
def Get(url):
try:
r=requests.request('get',url)#采用get方法
r.raise_for_status() # 判断HTTP响应码是否出错
r.encoding = r.apparent_encoding#避免出现中文乱码
return r.text
except:
return"产生异常"
(二)动态Ajax页面爬取
1、Ajax介绍
2、如何爬取Ajax界面?
json 库将响应数据解析成 Python 对象(例如字典或列表)。3、基于微博动态Ajax网页爬取的通用代码
from urllib.parse import urlencode #将字符串以URL编码形式展现
import requests
from requests.exceptions import RequestException #`RequestException` 是 requests 库中封装所有异常情况的基类,涵盖了raise_for_status()函数的功能
base_url=''
headers ={
'User-Agent':''
'cookie':r''
'X-Requested-With':'XMLHttpRequest'
}
def get_page(page,since_id):
if page == 1:
params = {
'uid':'',
'page':page
}
else:
params = {
'uid':'',
'page':page,
'since_id':since_id
}
url =base_url+urlencode(params) #上面的过程都是为了获取url
try:
response =requests.get(url,headers=headers)
response.encoding = response.apparent_encoding
r.raise_for_status() # 判断HTTP响应码是否出错
since_id =response.json().get('data').get('since_id')
return since_id,response.json()
except RequestException as e:
print('Error',e.args)
def parse_page(json): #解析页面
if json:
items = json.get('data').get('list')
for item in items:
weibo = {}
weibo['length'] = item.get('textLength')
weibo['comments_count'] = item.get('comments_count')
weibo['attitudes_count']=item.get('attitudes_count')
weibo['content']
=item.get('text_raw').replace("\u200b","")
yield weibo
4、备注:RequestException和raise_for_status()有什么区别?
raise_for_status()和RequestException是两个不同的概念。raise_for_status()是一个response对象方法。我们可以使用这个方法检查HTTP响应的状态码是否是200,如果不是,则会抛出一个HTTPError异常,其中包含了响应码及其原因。这个方法可以确保我们在进行页面解析或其它操作之前先检查响应是否成功,从而避免抛出不必要的错误。RequestException是requests库中的异常类,用于抛出任何发送请求过程中发生的异常。这个异常类是HTTPError,ConnectionError,Timeout和URLRequired等异常的基类。如果你的请求发生了异常,则会抛出这个异常。在使用requests库发送HTTP请求时,我们通常使用try/except语句处理可能发生的异常,例如:import requests
from requests.exceptions import RequestException
try:
response = requests.get(url)
response.raise_for_status()
except RequestException as e:
print(e)
raise_for_status()方法检查响应是否成功,如果不成功则会抛出一个HTTPError异常,该异常会被try语句捕获,然后打印出错误信息。如果在请求过程中发生了其他异常,例如服务器无法连接或超时异常,也会抛出RequestException异常,同样会被try语句捕获,进行相应的处理。raise_for_status()是一个response对象方法,用于检查HTTP响应的状态码是否正常;RequestException是一个异常类,用于处理请求过程中可能发生的异常。args方法外,RequestException类还提供了其他几个属性和方法,可以用来获取异常的具体信息,例如:request,response,message等。以下是这些方法和属性的示例:import requests
from requests.exceptions import RequestException
try:
response = requests.get("http://www.example.com", timeout=5)
response.raise_for_status()
except RequestException as e:
print("RequestException args:", e.args) # 获取异常参数
print("RequestException request:", e.request) # 获取请求对象
print("RequestException response:", e.response) # 获取响应对象
print("RequestException message:", e.message) # 获取异常消息
print("RequestException str:", str(e)) # 获取异常的字符串表示形式
RequestException捕获请求过程中可能出现的任何异常,并使用上述属性和方法来获取异常的各种信息。这些方法和属性可以帮助我们更好地了解异常的具体情况,从而更好地处理异常。response属性在请求成功并返回响应时会有值,而在请求失败时不会有值,因此在处理异常时需要进行判断。5、Ajax与JSON格式的关系
JSON.parse()和jQuery.parseJSON(),将JSON字符串转换成JS对象。var xhr = new XMLHttpRequest();
xhr.open('GET', '/api/data', true);
xhr.onreadystatechange = function(){
if (xhr.readyState === 4 && xhr.status === 200){
var data = JSON.parse(xhr.responseText);
console.log(data);
}
};
xhr.send();
XMLHttpRequest对象发起了一个GET请求,请求地址为'/api/data',并在收到响应时将响应的JSON字符串转化成JS对象并输出到控制台中。五、页面解析技术
(一)Beautiful Soup
1、Beautiful Soup 概念
2、Beautiful Soup解析页面
from bs4 import BeautifulSoup
html_doc = '''
Heading
'''
soup = BeautifulSoup(html_doc, 'html.parser')
# 获取标题
print(soup.title.text)
# 获取第一个段落
print(soup.p.text)
# 获取所有 li 标签
for li in soup.find_all('li'):
print(li.text)
bs4 模块中的 BeautifulSoup 类,然后定义了一个名为 html_doc 的字符串,该字符串表示要解析的 HTML 文档。接着,使用 BeautifulSoup() 方法将 html_doc 字符串转换为解析树,并指定使用 html.parser 解析器。可以使用不同的解析器,具体取决于要解析的文档的类型。
html.parser:Python 内置的 HTML 解析器,速度适中,依赖 Python 库。lxml:速度很快,但需要安装 C 语言库。xml:Python 内置的 XML 解析器。html5lib:最好的跨平台 HTML 解析器,但解析速度很慢,需要安装额外的库。BeautifulSoup() 会自动输入文档转化为Unicode编码,输出为utf-8编码,所以不用考虑编码方式,除非使用不同的编码3、Beautiful Soup查找节点
Beautiful Soup 通过解析 HTML/XML 文档,将它们转换为节点树,节点树的每一个节点是一个标签、属性或文本。
父节点(parent node):每个节点都有一个父节点,除了根节点(root node)。
子节点(child node):直接位于某个节点下方的节点被称为该节点的子节点,一个节点可以拥有多个子节点。
同级节点(sibling node):位于同一级别的节点被称为同级节点,它们具有相同的父节点。
前后节点(previous node/next node):位于同一父节点下的节点都有前后关系,一个节点的前一个节点被称为前节点,后一个节点被称为后节点。<html>
<head>
<title>This is a titletitle>
head>
<body>
<h1>This is a headingh1>
<p>This is a paragraphp>
<a href="https://www.example.com/">
This is a link
a>
body>
html>
在这个文档中,<html> 是根节点,它有一个子节点 <head> 和一个子节点 <body>,<head> 和 <body> 都是 <html> 的子节点,同时也是相互独立的同级节点。<head> 元素有一个子节点 <title>,<body> 元素有三个子节点 <h1>、<p> 和 <a>。<h1>、<p> 和 <a> 都是 <body> 的子节点,同时也是相互独立的同级节点,其中 <a> 元素又包含了文本节点。
在pyhon中,实际上所有节点都是python对象,而所有对象又可以归纳为为4种,分别是:Tag 、 Navigable String 、 BeautifulSoup、 Comment
(name:输出标签的标签类型名 attrs:以字典的形式获取标签的属性,例如id,class等)from bs4 import BeautifulSoup
html_doc = """
<html>
<head>
<title>Page Titletitle>
head>
<body>
<h1 class="headline">Heading 1h1>
<p>Paragraph 1p>
<p>Paragraph 2p>
<div><a href="https://www.baidu.com/" target="_blank">百度一下,你就知道a>div>
body>
html>
"""
soup = BeautifulSoup(html_doc, 'html.parser')
tag_h1 = soup.h1
tag_a = soup.a
#获取标签名称
print(tag_h1.name)
print(tag_a.name)
# 访问标签属性字典
print(tag_h1.attrs)
print(tag_a.attrs)
#访问标签属性
print(tag_a.attrs['name'])
实际上可以忽略掉attrs,直接写tag_a['name']即可,因为是字典格式
# 使用 get() 方法获取属性值
print(tag_h1.get('class'))
print(tag_a.get('href'))
但是标签中如果包含多个字符串,其输出结果为None,这时候我们可以采用循环获取的方式
如果采用循环获取的方式,可以使用节点对象的 children 属性来遍历节点的所有子节点。然后,对于每个子节点,如果它是一个文本节点,则可以获取它的 string 属性。如果它是一个标签节点,则可以递归遍历它的子节点,获得其所有的文本内容。示例如下:from bs4 import BeautifulSoup, NavigableString
html_doc = '''
get_text() 的函数,该函数接受一个节点对象作为参数,然后递归遍历该节点的所有子节点,并拼接每个子节点的文本内容。对于文本节点,使用 string 属性获取其内容,并使用 strip() 方法去掉多余的空格和换行符。get_text() 函数获取其内部的所有文本内容,并将它们拼接到结果字符串后面。最终返回结果字符串。 结尾。Beautiful Soup 会自动识别注释并将其解析为 Comment 对象,我们可以通过判断节点对象是否为 Comment 类型,来处理 HTML 文档中的注释内容。DOCTYPE html>
<html>
<head>
<title>Baidutitle>
head>
<body>
<a href="https://www.baidu.com/">百度一下,你就知道a>
body>
html>
from bs4 import BeautifulSoup, Comment
html_doc = '''
body 标签的所有子节点,如果节点类型为 Comment 类型,则将其输出到控制台中。" This is a comment ",是该文档中的注释内容。需要注意的是,注释节点的 string 属性就是注释内容,不包括注释标记 。如果需要输出包括注释标记在内的完整内容,可以使用 node.encode() 方法,该方法会将节点的内容编码为字节串并输出。3、Beautiful Soup中的方法选择器
Beautiful Soup 提供了一种基于方法来选择节点的方式,称为「方法选择器」。使用方法选择器,我们可以通过节点的方法名称、参数等信息来选择节点。
find_all(name, attrs, recursive, text, limit, **kwargs):按照条件查找所有符合要求的节点,并返回一个列表。find(name, attrs, recursive, text, **kwargs):查找第一个符合要求的节点,如果找不到则返回 None。select(css_selector):使用 CSS 选择器来选择节点,并返回一个列表。find_all() 和 find() 方法的参数说明如下:
name:节点的名称,可以是字符串、正则表达式或列表等类型。attrs:节点的属性,可以是字典、关键字参数、正则表达式等类型。recursive:是否递归搜索,默认为 True。text:搜索节点的文本内容。limit:搜索结果的最大数量限制。DOCTYPE html>
<html>
<head>
<title>Baidutitle>
head>
<body>
<p class="one">Hello, World!p>
<p class="two">Goodbye, World!p>
<div class="two">
<p>Paragraph 1p>
<p>Paragraph 2p>
div>
body>
html>
from bs4 import BeautifulSoup, Tag
html_doc = '''
find_all() 方法查找所有的 p 标签,并输出它们的内容。使用 find() 方法查找第一个 class 为 one 的 p 标签,并输出它的内容。同时,使用 select() 方法使用 CSS 选择器查找文档中名为 div 并且 class 为 two 的标签,并输出它的内容。最后,在该标签内再次使用 select() 方法查找名为 p 的标签,并输出它们的内容。find_all() 方法,它将返回一个包含所有指定标签名的标签对象列表。
例如,soup.find_all(['p', 'a', 'div']) 方法将返回文档中所有的 p、a 和 div 标签对象。DOCTYPE html>
<html>
<head>
<title>Baidutitle>
head>
<body>
<p>Paragraph 1p>
<a href="https://www.baidu.com/">Link 1a>
<div>Div 1div>
<p>Paragraph 2p>
<a href="https://www.baidu.com/">Link 2a>
<div>Div 2div>
body>
html>
find_all() 方法来选择其中的标签,示例如下:from bs4 import BeautifulSoup, Tag
html_doc = '''
find_all() 方法选择文档中所有的 p、a 和 div 标签,并输出它们的内容。4、Beautiful Soup CSS 选择器
基本选择器的作用是选取所有符合条件的元素,包括标签名、类名和 id。在 Beautiful Soup 中,基本选择器的用法与 CSS 中类似。
类选择器:用类名选取元素,需要在类名前面加上点号 .,例如 soup.select(‘.headline’) 查找所有类名为 headline 的元素;
id选择器:用 id 选取元素,需要在 id 前面加上井号 #, 比如soup.select(‘#title’) 查找 id 为 title 的元素。from bs4 import BeautifulSoup
html_doc = """
<html>
<head>
<title id="title">Page Titletitle>
head>
<body>
<h1 class="headline">Heading 1h1>
<p>Paragraph 1p>
<p>Paragraph 2p>
<div><a href="https://www.baidu.com/" class="headline">百度一下,你就知道a>div>
body>
html>
"""
soup = BeautifulSoup(html_doc, 'html.parser')
# 标签选择器
tags = soup.select('p')
print(tags)
# 类选择器
tags = soup.select('.headline')
print(tags)
# id选择器
tags = soup.select('#title')
print(tags)
组合选择器用于选择父元素、子元素、前一个兄弟元素、后一个兄弟元素等,其中包括以下几种关系选择器:
子选择器(大于号):选取满足条件的直接子元素,例如 soup.select(‘body > p’) 查找 body 元素下直接的 p 标签;
相邻兄弟选择器(加号):选取与当前元素相邻的下一个元素,例如 soup.select(‘p + div’) 查找 p 标签后面的第一个 div 标签;
后继兄弟选择器(波浪号):选取满足条件的所有后继兄弟元素,例如 soup.select(‘h1 ~ p’) 查找 h1 标签后面所有的 p 标签。from bs4 import BeautifulSoup
html_doc = """
<html>
<head>
<title>Page Titletitle>
head>
<body>
<h1 class="headline">Heading 1h1>
<p>Paragraph 1p>
<p>Paragraph 2p>
<div>
<a href="https://www.baidu.com/" class="headline">百度一下,你就知道a>
<p>Paragraph 3p>
div>
body>
html>
"""
soup = BeautifulSoup(html_doc, 'html.parser')
# 后代选择器
tags = soup.select('div a')
print(tags)
# 子选择器
tags = soup.select('body > p')
print(tags)
# 相邻兄弟选择器
tags = soup.select('p + div')
print(tags)
# 后继兄弟选择器
tags = soup.select('h1 ~ p')
print(tags)
属性选择器用于选取带有特定属性的元素,常见的属性选择器包括等于、包含、开始于、结束于、不等于等操作。from bs4 import BeautifulSoup
html_doc = """
<html>
<head>
<title>Page Titletitle>
head>
<body>
<a href="https://www.baidu.com/">首页a>
<a href="https://www.baidu.com/s?wd=Python">Pythona>
<a href="https://news.baidu.com/">新闻a>
body>
html>
"""
soup = BeautifulSoup(html_doc, 'html.parser')
# 选取 href 属性值包含 "Python" 的 a 标签
tags = soup.select('a[href*="Python"]')
print(tags)
5、 Beautiful Soup 遍历文档树
children 属性来获取一个标签的所有子节点,返回的数据类型是一个生成器类型的对象。from bs4 import BeautifulSoup
html_doc = """
Heading 1
soup.body.children 获取文档树的子节点,并遍历输出了子节点的内容。输出的格式是一个生成器类型的对象,不是列表。
parent 属性来获取当前标签的父节点,返回的数据类型是一个标签类型的对象。from bs4 import BeautifulSoup
html_doc = """
Heading 1
child.parent 获取当前子节点的父节点,并遍历输出了父节点的内容。输出的格式是一个标签类型的对象。
next_sibling 和 previous_sibling 属性来获取当前节点的下一个兄弟节点和上一个兄弟节点。from bs4 import BeautifulSoup
html_doc = """
Heading 1
child.next_sibling 获取当前子节点的下一个兄弟节点,并遍历输出了它们的内容。输出的格式是一个标签类型的对象。(二)XPath
1、XPath概念
以下是一些常用的 XPath 表达式:/:根节点。
//:匹配子孙节点。
.:当前节点。
..:父节点。
@:属性。
tagname:选择指定名称的节点。
*:选择所有子节点。
[@attrib]:选择指定属性名的节点。
[@attrib='value']:选择指定属性名和属性值的节点。
tagname[@attrib='value']:选择指定名称、属性名和属性值的节点。
tagname[position]:选择指定位置的节点。
tagname[last()]:选择最后一个指定名称的节点。
tagname[position() <= n]:选择前 n 个指定名称的节点。
2、XPath解析页面
import requests
from lxml import etree
# 1. 发起网络请求,获取网页内容
url = 'https://www.baidu.com/'
response = requests.get(url)
# 2. 将网页内容交给 etree.HTML 对象进行解析,得到 XPath 解析对象
html = response.content.decode('utf-8')
selector = etree.HTML(html)
# 从本地 HTML 文件解析为 XML 文档对象
doc = etree.parse('example.html')
3、XPath查找结点
import requests
from lxml import etree
# 1. 发起网络请求,获取页面内容
url = 'https://www.baidu.com'
response = requests.get(url)
html = response.content.decode('utf-8')
# 2. 将页面内容交给 etree.HTML 对象进行解析
selector = etree.HTML(html)
# 3. 使用 XPath 表达式进行节点选择和数据提取
# 选取所有节点
nodes = selector.xpath('//*')
print(len(nodes))
# 选取第一个 h3 节点的子节点和文本值
h3_node = selector.xpath('//h3')[0]
print(etree.tostring(h3_node, encoding='utf-8').decode())
print(h3_node.xpath('./a/@href')[0])
print(h3_node.xpath('./a/text()')[0])
# 选取第一个 a 节点的父节点和文本值
a_node = selector.xpath('//a')[0]
print(etree.tostring(a_node.getparent(), encoding='utf-8').decode())
print(a_node.xpath('text()')[0])
# 选取第一个 input 节点的 name 属性
input_node = selector.xpath('//input')[0]
print(input_node.xpath('@name')[0])
# 选取第一个 span 节点的文本值
span_node = selector.xpath('//span')[0]
print(span_node.xpath('text()')[0])
# 选取 href 属性值为指定字符串的 a 节点,多属性匹配
a_nodes = selector.xpath('//a[@href="https://www.baidu.com/more/"]')
print(len(a_nodes))
# 4. 将解析结果进行保存或处理
# 这里只是简单地输出了结果,可以将结果存储到本地文件或数据库中。
4、Xpath的节点轴
祖先轴(ancestor):用于选取所有祖先节点,可以使用 ancestor:: 或 // 来表示。
后代轴(descendant):用于选取所有后代节点,可以使用 descendant:: 或 // 来表示。
父轴(parent):用于选取当前节点的父节点,可以使用 parent:: 或 … 来表示。
子轴(child):用于选取当前节点的所有直接子节点,可以使用 child:: 或 / 来表示,默认情况下也可以省略。
兄弟轴(following-sibling 和 preceding-sibling):用于选取当前节点的相邻同级节点,可以使用 following-sibling:: 或 preceding-sibling 来表示。
自身轴(self):用于选取当前节点本身,可以使用 self:: 或 . 来表示。import requests
from lxml import etree
# 发起网络请求,获取百度首页的 html 内容
url = 'https://www.baidu.com/'
response = requests.get(url)
html = response.content.decode('utf-8')
# 将页面内容交给 etree.HTML 对象进行解析
selector = etree.HTML(html)
# 获取当前节点的名称
node = selector.xpath('//div')[0]
print('节点名称:', node.tag)
# 获取当前节点的属性值
node = selector.xpath('//div')[0]
print('id 属性值:', node.get('id'))
# 获取当前节点的父节点及祖先节点
node = selector.xpath('//div')[0]
print('父节点名称:', node.getparent().tag)
ancestors = node.xpath('ancestor::*')
print('祖先节点个数:', len(ancestors))
# 获取当前节点的所有子节点和后代节点
node = selector.xpath('//div[@id="s-top-left"]')[0]
children = node.xpath('child::*')
print('子节点个数:', len(children))
descendants = node.xpath('descendant::*')
print('后代节点个数:', len(descendants))
# 获取当前节点之后的所有节点和兄弟节点
node = selector.xpath('//div[@id="s-top-left"]')[0]
following_nodes = node.xpath('following::*')
print('之后的节点个数:', len(following_nodes))
following_siblings = node.xpath('following-sibling::*')
print('之后的兄弟节点个数:', len(following_siblings))
# 获取当前节点之前的所有节点和兄弟节点
node = selector.xpath('//div[@id="s-top-left"]')[0]
preceding_nodes = node.xpath('preceding::*')
print('之前的节点个数:', len(preceding_nodes))
preceding_siblings = node.xpath('preceding-sibling::*')
print('之前的兄弟节点个数:', len(preceding_siblings))
# 获取当前节点本身
node = selector.xpath('//div[@id="s-top-left"]')[0]
self_node = node.xpath('self::node()')
print('当前节点名称:', self_node[0].tag)
(三)正则表达式
1、正则表达式概念
2、正则表达式匹配规则
.:匹配任意单个字符(除了换行符)。*:匹配前面的字符 0 次或多次。+:匹配前面的字符 1 次或多次。?:匹配前面的字符 0 次或 1 次。^:匹配字符串的开头。$:匹配字符串的结尾。[]:匹配括号中任意一个字符。[a-z]:匹配 a 到 z 中的任意一个字符。[^a-z]:匹配不在 a 到 z 中的任意字符。\d:匹配任意数字,相当于 [0-9]。\D:匹配任意非数字字符,相当于 [^0-9]。\w:匹配任意字母数字,相当于 [a-zA-Z0-9_]。\W:匹配任意非字母数字字符,相当于 [^a-zA-Z0-9_]。\s:匹配任意空格字符。\S:匹配任意非空格字符。
[a-zA-Z0-9]+:匹配任意字母或数字。^[a-zA-Z]+_[a-zA-Z]+$:匹配由两个单词组成,中间以 _ 分隔。(\d{3}-)?\d{3}-\d{4}:匹配美国电话号码格式,可以包含区号,例如 123-456-7890 或 456-7890。|、()、\b、\B 等,以及一些量词符号,例如 {m,n}、{m,} 等,用于表示匹配范围和重复次数等。需要注意的是,在使用元字符时可能需要进行转义,例如 \\| 表示匹配竖线字符。3、 正则表达式匹配方法
pattern、待匹配的字符串 string 和一个可选的标志位 flags。其中,模式 pattern 是一个正则表达式,string 是需要匹配的字符串,flags 是可选的匹配标志,用于控制匹配的行为。import re
# 定义一个正则表达式
pattern = r'(\d+)'
# 定义一个待匹配的字符串
string = '12345a6789'
# 用 match() 方法匹配文本
result = re.match(pattern, string)
if result:
print('match() 方法:', result.group(1))
else:
print('match() 方法:匹配失败')
# 用 search() 方法查找文本
result = re.search(pattern, string)
if result:
print('search() 方法:', result.group(1))
else:
print('search() 方法:查找失败')
# 用 findall() 方法查找文本
result = re.findall(pattern, string)
if result:
print('findall() 方法:', result)
else:
print('findall() 方法:查找失败')
# 用 sub() 方法替换文本
repl = r'(\1)'
result = re.sub(pattern, repl, string)
print('sub() 方法:', result)
pattern,它可以匹配字符串中的数字,然后我们使用上述四个方法来分别进行匹配、查找、查找和替换操作。最后,我们输出了每个方法返回的结果,验证了其正确性。sub() 方法是用来替换字符串中指定模式的子串,其基本语法如下:re.sub(pattern, repl, string, count=0, flags=0)
pattern 表示一个正则表达式,repl 表示一个字符串或可调用对象,用来替换匹配到的子串,string 是需要进行替换的字符串。count 和 flags 是可选参数,分别用来限制替换次数和匹配行为。num,可以使用正则表达式和 sub() 方法来实现:import re
# 定义待替换的字符串
string = 'abc123def456'
# 使用 sub() 方法替换字符串中的数字为 'num'
result = re.sub(r'\d+', 'num', string)
# 输出替换后的结果
print(result) # 'abcnumdefnum'
string,其中包含一些数字。然后,我们使用 re.sub() 方法将其中的数字都替换为字符串 'num',得到了一个新的字符串 'abcnumdefnum'。注意,在这个例子中,我们使用了正则表达式中的 \d+ 来匹配所有的数字,然后用 'num' 来替换它们。sub() 方法返回的是一个新的字符串,原始字符串并没有发生任何改变。此外,sub() 方法还支持使用函数作为替换字符串 repl,这样可以更灵活地控制替换4、正则表达式修饰符
re.M:多行模式,将 ^ 和 $ 分别匹配行的开头和结尾。
re.S:让 . 匹配包括换行符在内的任意字符。
re.U:Unicode 模式,可以匹配 Unicode 字符序列。
re.X:允许使用正则表达式中的注释和空白字符。注释以 # 开头,一直到行末或者被转义的换行符为止。
这些修饰符可以通过在正则表达式的开头使用 (?i)、(?m)、(?s)、(?u)、(?x) 的形式来启用。
[A-Z]+ 可以匹配大写字母,使用修饰符 re.I 可以将其改为不区分大小写的模式。具体来说,可以这样使用:import re
# 定义文本
text = 'apple, ORANGE, banana'
# 定义模式,使用 re.I 修饰符不区分大小写
pattern = re.compile(r'[a-z]+', re.I)
# 搜索文本并打印结果
result = pattern.findall(text)
print(result) # ['apple', 'ORANGE', 'banana']
re.I 修饰符来忽略大小写,并定义了一个正则表达式模式 [a-z]+,用来匹配文本中的小写字母。然后,我们使用这个模式进行搜索,并将结果打印出来。在打印结果中,可以看到不同大小写的字母都被正确地匹配了。
^ 和 $ 匹配每行的开头和结尾。例如,正则表达式 ^hello 可以匹配一行开头的 hello,使用修饰符 re.M 可以将其改为匹配多行文本。具体来说,可以这样使用:import re
# 定义文本
text = 'hello\nworld\n'
# 定义模式,使用 re.M 修饰符允许 ^ 和 $ 匹配每行的开头和结尾
pattern = re.compile(r'^hello', re.M)
# 搜索文本并打印结果
result = pattern.findall(text)
print(result) # ['hello']
re.M 修饰符来支持多行模式,并定义了一个正则表达式模式 ^hello,用来匹配每行开头的 hello。然后,我们使用这个模式进行搜索,并将结果打印出来。在打印结果中,只有开头一行的 hello 被正确地匹配了。
. 匹配包括换行符在内的任何字符。例如,正则表达式 hello.world 可以匹配 hello 和 world 中间存在换行符的文本串,使用修饰符 re.S 可以将其改为支持点任意匹配模式。具体来说,可以这样使用:import re
# 定义文本
text = 'hello\nworld\n'
# 定义模式,使用 re.S 修饰符启用点任意匹配模式
pattern = re.compile(r'hello.world', re.S)
# 搜索文本并打印结果
result = pattern.findall(text)
print(result) # ['hello\nworld']
re.S 修饰符来启用点任意匹配模式,并定义了一个正则表达式模式 hello.world,用来匹配含有换行符的文本串。然后,我们使用这个模式进行搜索,并将结果打印出来。在打印结果中,可以看到多行文本被正确地匹配了。
\w+ 可以匹配包括字母、数字和下划线在内的单词字符(例如 hello_world),而使用修饰符 re.A 可以将其改为仅匹配 ASCII 字符。具体来说,可以这样使用:import re
# 定义文本
text = 'hello_world'
# 定义模式,使用 re.A 修饰符限制匹配到 ASCII 字符集
pattern = re.compile(r'\w+', re.A)
# 搜索文本并打印结果
result = pattern.findall(text)
print(result) # ['hello_world']
re.A 修饰符来限制匹配到 ASCII 字符集,并定义了一个正则表达式模式 \w+,用来匹配单词字符。然后,我们使用这个模式进行搜索,并将结果打印出来。在打印结果中,可以看到单词字符被正确地匹配了,而其他非 ASCII 字符则被忽略。5、
compile() 方法和 match()、search()、findall()、sub() 等其他方法的关联?compile() 方法用于将正则表达式字符串编译成正则表达式对象,从而提高正则表达式的执行效率。同时,正则表达式对象也可以传递给其他正则表达式方法使用。compile() 方法来将一个正则表达式字符串编译为正则表达式对象:import re
# 编译正则表达式
pattern = re.compile('\d+')
# 使用正则表达式对象进行匹配
result = pattern.findall('hello123world456')
print(result) # ['123', '456']
re.compile() 方法编译了一个正则表达式 \d+,并将其赋值给变量 pattern。然后,我们使用这个正则表达式对象调用 findall() 方法,来匹配文本中的数字,并将结果打印出来。在输出结果中,可以看到正则表达式成功地匹配了两个数字。match()、search()、findall()、sub() 等其他方法进行字符串匹配和操作。这些方法在使用正则表达式对象时与使用正则表达式字符串时的语法是一样的,只需要将正则表达式对象传递给这些方法的参数中即可。compile() 方法将正则表达式字符串编译成正则表达式对象,然后使用正则表达式方法对于字符串进行匹配和操作。
事实上,Python 的正则表达式模块(re 模块)提供了多个函数(上述四个)用于直接对字符串进行正则式匹配、替换等操作,而不必通过 compile() 方法生成正则表达式对象。但是与通过 compile() 生成正则表达式对象后再调用不同的是,这些函数通常是作为单独独立的函数去调用,适用于仅需要进行一次性、简单的正则式匹配操作的场合。6、贪婪匹配和非贪婪匹配
+ 或 * 贪婪限定符,尽可能少地匹配则表示为在这些贪婪限定符后面加上 ? 非贪婪限定符。import re
# 定义一个待匹配的字符串
string = 'aaabbbcc'
# 使用贪婪匹配查找文本中的 a 标签内容
pattern = r'.*'
result = re.findall(pattern, string)
print('贪婪匹配:', result)
# 使用非贪婪匹配查找文本中的 a 标签内容
pattern = r'.*?'
result = re.findall(pattern, string)
print('非贪婪匹配:', result)
string,它包含两个 a 标签,中间是一些文本。然后,我们使用正则表达式来匹配其中的 a 标签内容,分别尝试了贪婪匹配和非贪婪匹配。具体来说,贪婪匹配是使用 .* 来匹配任意字符(无限重复),然后再匹配 。这种方式会尽可能多地匹配,直到找到最后的 。而非贪婪匹配是在贪婪匹配的基础上加上了一个 ? 非贪婪限定符,这样可以尽可能少地匹配,一旦找到第一个 就停止匹配。六、 页面存储技术
(一)TXT文本存储
1、txt文本存储通用代码
def write_file(content):
#使用 with···as 语句打开文件时,Python 会自动调用 close() 方法来关闭文件。
with open ('123.txt','a',encoding='utf-8') as file:
file.read()#读取文件内容
file.wirte(content)#写入文件内容
2、Open()函数详解
open() 函数是内置函数 open(),用于打开一个文件,常见的参数如下:
'r':读取(默认)。'w':写入,若文件存在则覆盖。'x':创建一个新的文件,如果文件已经存在则返回错误。'a':附加到文件的末尾(即写入到文件已有的内容之后)。'b':以二进制模式打开文件。't':以文本模式打开文件(默认)。'+':可读写。'strict'、'ignore'、'replace' 等方式。open() 函数读取一个文本文件例如 example.txt,并使用 UTF-8 编码进行解码:with open('example.txt', mode='r', encoding='utf-8') as f:
content = f.read()
print(content)
with 语句对文件进行上下文管理,当代码执行完 with 块后,文件会自动关闭。用 open() 函数打开文件时,一般最好使用上下文管理,确保文件关闭,避免资源浪费。(二)JSON文件存储
1、JSON定义
它通过对象(pyhton中的字典)和数组(python中的列表)组合而表示数据{} 定义对象,由方括号 [] 定义数组。键和值之间使用冒号 : 分隔,键值对之间使用逗号 , 分隔。{
"name": "Tom",
"age": 20,
"gender": "male",
"hobbies": ["reading", "running", "swimming"],
"location": {
"city": "Beijing",
"country": "China"
}
}
json 模块来解析和生成 JSON 数据。例如,读取上面例子中的 JSON 数据:import json
# 定义 JSON 数据
json_data = '{"name": "Tom", "age": 20, "gender": "male", "hobbies": ["reading", "running", "swimming"], "location": {"city": "Beijing", "country": "China"}}'
# 解析 JSON 数据
data = json.loads(json_data)
# 访问 JSON 数据
print(data['name']) # 输出值为 Tom
json.loads() 函数将 JSON 数据解析为 Python 字典格式,然后通过字典的键来访问 JSON 数据的值。2、Python 中解析 JSON 数据
json.load() 和 json.loads() 都是 Python 中用于解析 JSON 数据的方法。
json.load():用于加载一个 JSON 文件(.json),返回一个 Python 字典格式的数据。
json.load(file_object)。import json
with open('data.json', mode='r', encoding='utf8') as f:
data_dict = json.load(f)
print(data_dict)
json.loads():用于将 JSON 字符串转化为 Python 字典格式。
json.loads(json_string)。import json
json_str = '{"name": "Tom", "age": 20}'
data_dict = json.loads(json_str)
print(data_dict)
json.load() 是对文件进行解析,而 json.loads() 是对字节串或字符串进行解析。在使用时需要根据传入的数据类型,选择适合的解析方法。json.load() 和 json.loads() 这两种方式进行 JSON 数据转化操作时,需要确保 JSON 数据的合法性,否则将会报错。例如,在 JSON 数据格式中如果缺少双引号或者写错了键名等情况都会导致解析过程出现错误。3、获取json中的内容
{
"name": "Tom",
"age": 20,
"gender": "male",
"hobbies": ["reading", "running", "swimming"],
"location": {
"city": "Beijing",
"country": "China"
}
}
import json
json_data = '{"name": "Tom", "age": 20, "gender": "male", "hobbies": ["reading", "running", "swimming"], "location": {"city": "Beijing", "country": "China"}}'
data = json.loads(json_data)
# 获取 name 的值
print(data['name']) # 输出 "Tom"
# 获取 hobbies 数组中第二个元素的值 "running"
print(data['hobbies'][1])
# 获取 location 对象中 city 的值 "Beijing"
print(data['location']['city'])
data['name'] 表示获取属性名为 name 的值,data['hobbies'][1] 表示获取 hobbies 数组中的第二个元素,即 running。最后一个示例中,我们使用了嵌套索引的方式,返回 location 中 city 对应的值 Beijing。KeyError 异常。如果无法确定 JSON 数据中是否存在对应的键值对,可以使用 get() 方法来避免异常的发生。例如,data.get('nonexistent_key', 'default_value') 可以返回键名为 nonexistent_key 的值,如果键名不存在则返回默认值 default_value。4、Python 对象转换为 JSON 字符串
dumps() 方法是 Python 的 json 模块中用于将 Python 对象转换为 JSON 格式的字符串的方法,它的完整语法如下:json.dumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False)
obj 是必需的,它代表要转换的 Python 对象,可以是字典、列表、元组、数字、字符串等各种数据类型。
obj 表示需要转换为 JSON 字符串的 Python 对象。dumps() 方法会返回一个字符串,表示序列化后的 JSON 对象.
以下是一些常用的参数:
skipkeys:指定是否跳过那些不合法的键值,默认为 False。
ensure_ascii:指定是否将数据中的非 ASCII 字符转义为 \uXXXX 形式的字符,默认为 True,即转义。
indent:指定输出时的缩进空格数,默认为 None,即表示不需要缩进输出。
separators:指定用于分隔 JSON 对象中的各个元素的字符,可以指定为元组,含有两个元素,分别表示键值之间的分隔符和整个对象之间的分隔符。
default:用于指定在遇到无法序列化的对象时的自定义序列化规则。import json
data = {
"name": "Tom",
"age": 20,
"gender": "male"
}
json_str = json.dumps(data)
print(json_str) # 输出 '{"name": "Tom", "age": 20, "gender": "male"}'
dumps() 方法时,可以设置很多选项,比如序列化时是否跳过字典中的非字符串键名,是否确保所有字符都是 ASCII 码等等。如果需要了解更多选项及其含义,可以参考 Python 官方文档。TypeError 异常。例如,如果我们有一个自定义的类 Person:class Person:
def __init__(self, name, age):
self.name = name
self.age = age
Person 类型的对象转换为 JSON 格式的字符串,可以使用 default 参数来提供一个转换函数。以下是一个示例:import json
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def person_to_dict(person):
return {'name': person.name, 'age': person.age}
tom = Person('Tom', 20)
json_str = json.dumps(tom, default=person_to_dict)
print(json_str) # 输出 '{"name": "Tom", "age": 20}'
person_to_dict 的函数,该函数用于将 Person 类型的对象转换为字典格式,然后在调用 dumps() 方法时,使用 default 参数将该函数传递进去,以保证 Person 类型的对象能够正确地进行转换。(三)CSV文件存储
1、CSV定义
name,age,country
John,25,USA
Alice,28,UK
Bob,31,China
2、通用CSV读取代码
import csv
filename = 'data.csv'
with open(filename, 'r', encoding='utf-8') as csvfile:
reader = csv.reader(csvfile)
header = next(reader) # 读取标题行
data = []
for row in reader:
data.append(row)
print(header) # 输出标题行
print(data) # 输出数据行
csv 模块来读取 CSV 文件,示例中读取了一个名为 data.csv 的 CSV 文件。下面是代码的解释:
open() 函数打开文件,并使用 csv.reader() 函数将文件对象转化为可进行 CSV 读取的 reader 对象。next(reader) 方法读取文件中的第一行,即标题行,并将其赋值给 header 变量。这时候 reader 对象指向文件的第二行,即数据行。data,用于存储 CSV 文件中的数据。for 循环遍历 reader 对象中的每一行,并将每一行的数据存储到 data 列表中。csv.writer() 函数来创建一个用于写入 CSV 文件的 writer 对象。以下是一个示例,将一个 Python 列表写入 CSV 文件中:import csv
data = [
['name', 'age', 'gender'],
['Tom', '20', 'male'],
['Lucy', '18', 'female']
]
with open('data.csv', 'w', encoding='utf-8', newline='') as csvfile:
writer = csv.writer(csvfile)
for row in data:
writer.writerow(row)
data,该列表包含了文件中的标题行和两行数据。然后,我们使用 open() 函数打开文件,并使用 csv.writer() 函数创建一个用于写入 CSV 文件的 writer 对象。接着,使用 writerow() 方法向文件中写入数据。需要注意的是,写入 CSV 文件时要指定 newline='',这是因为在 Windows 环境中,如果不指定该参数,将会产生一个额外的空行。七、经典爬虫框架——Scrapy
(一)Scrapy 介绍
(二)Scrapy 结构
(三)Scrapy爬虫基本步骤
步骤2: 在工程中产生一个Scrapy爬虫
步骤3:配置Item文件
步骤4:配置产生的spider爬虫“quotes”
步骤5:编写ItemPipeline
步骤6:优化配置策略
步骤7: 运行Scrapy或保存到文件
以下是根据上述步骤编写的示例代码和命令:$ scrapy startproject myproject
$ cd myproject
$ scrapy genspider quotes quotes.toscrape.com
import scrapy
class QuoteItem(scrapy.Item):
text = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()
import scrapy
from myproject.items import QuoteItem
class QuotesSpider(scrapy.Spider):
name = "quotes"
allowed_domains = ["quotes.toscrape.com"]
start_urls = (
'http://quotes.toscrape.com/page/1/',
)
def parse(self, response):
for quote in response.xpath('//div[@class="quote"]'):
item = QuoteItem()
item['text'] = quote.xpath('span[@class="text"]/text()').extract_first()
item['author'] = quote.xpath('span/small/text()').extract_first()
item['tags'] = quote.xpath('div[@class="tags"]/a[@class="tag"]/text()').extract()
yield item
import json
import codecs
class MyprojectPipeline(object):
def __init__(self):
self.file = codecs.open('items.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
def spider_closed(self, spider):
self.file.close()
BOT_NAME = 'myproject'
SPIDER_MODULES = ['myproject.spiders']
NEWSPIDER_MODULE = 'myproject.spiders'
ITEM_PIPELINES = {'myproject.pipelines.MyprojectPipeline': 300}
FEED_EXPORT_ENCODING = 'utf-8'
$ scrapy crawl quotes
$ scrapy crawl quotes -o quotes.json
你可能感兴趣的:(爬虫,数据挖掘,数据仓库,大数据,python)