【论文笔记】DS-UNet: A dual streams UNet for refined image forgery localization
DS-UNet:用于细化图像伪造定位的双流UNet
摘要
提出了一种名为DS-UNet的双流网络来检测图像篡改和定位伪造区域。DS-UNet采用RGB流提取高级和低级操纵轨迹,用于粗定位,并采用Noise流暴露局部噪声不一致,用于精定位。由于被篡改对象的形状和大小总是不同的,DS-UNet采用了轻量级的分层融合方法,使得DS-UNet能够感知不同尺度的篡改对象。之后,DS-UNet通过单个解码器接收跳跃连接路径中丰富的低层操纵轨迹和空间定位信息。通过解码器,逐步恢复目标细节和空间维数,生成高分辨率预测图。在对比分析中,引入了比现有作品更多的评价指标,以获得更全面的评价。在5个数据集上进行了大量的实验,得到了令人满意的结果,证明了它的性能优于最先进的方法。
引言
根据图像的语义内容是否改变,操作类型可以分为两类:内容独立操作和内容依赖操作。前者包括全局调整,如亮度调整、对比度增强、去模糊、去噪和图像压缩。后者依赖于内容的伪造涉及拼接、复制-移动和内容删除,如图1所示。

DS-UNet受RGB-N的启发,在u型编解码器网络中采用分层融合的方式,由双流编码器和单解码器组成。
- 一个流是RGB流,提供了导致粗像素级定位的高级和低级操纵轨迹。
- 噪声流作为编码器的另一个流,通过噪声残差中的判别特征,学会区分被操纵区域和未被操纵区域,进行精细的操纵定位。
- 然后以分层融合的方式将双流连接起来,好处:一是考虑了不同尺度的伪造特征,如不同形状和大小的伪造区域。另一方面,区别噪声残差特征作为RGB特征的补充,使伪造定位更加准确。
该方法采用u型编解码器结构作为网络的整体结构。具体来说,特征图的分辨率在编码路径中逐渐降低,而在深度路径中,长程相关信息更容易被捕获。此外,解码器在跳跃连接路径中接收到丰富的低层操纵轨迹和空间定位信息,然后逐步恢复目标细节和空间维数,最终生成高分辨率的预测图。该模型采用端到端训练,没有任何前处理或后处理,与现有工作相比,加快了训练和预测过程。
主要贡献
- 基于大量实验的分析,发现DenseNet是一个适合IFLD的backbone,因为每个Dense块都有能力传输高频信息,并构建一个低层特征的抽象表示。
- 与后期融合方法和早期融合方法不同,我们在图像伪造定位中采用了RGB流和Noise流的分层融合方法。这种分层融合融合了多个尺度上的特征,因此很适合于检测各种形状和大小的篡改对象。
- 通过对几种高通滤波器和不同损失函数的比较实验,我们发现SRM滤波器在固定参数设置的基础上,能够在稳定性和优越性之间取得平衡,而Dice loss和Focal loss相结合可以实现类平衡能力,处理图像伪造定位中存在的类失衡问题。
本文提出的方法采用U型网络作为整体网络结构,它的跳跃连接随空间定位信息包含更多的低层特征,辅助高层特征逐步提高定位性能。更重要的是**,这些低阶特征也带来了丰富的低阶操纵痕迹**。
方法
如图2是提出的IFLD网络的总体结构。DS-UNet的RGB流在编码器侧学习高级别(如对比度和失真)和低级别(如邻近像素的局部依赖关系)特征的操作轨迹。同时,噪声流通过SRM滤波层传输RGB图像,得到噪声残差特征,学习低阶被操纵的痕迹,为像素级分类提供额外的证据。跳跃连接特性和全局编码特性在相应的层次结构中汇总在一起。
在解码器部分,我们使用双线性上采样层对上采样层的特征图进行上采样,使用卷积层和Inplace-ABN层对上采样结果进行细化。当feature map被放大2倍时,通道数减少2或4,增强了feature map的非线性表达能力。Up-Conv块的滤波器个数分别为256、512、256、64、32。跳跃连接特征和早期特征以通道方式级联并馈给两个子卷积层和Inplace-ABN层,以合并通道特征并减少通道数。Conv块中的输出通道数分别为1024、512、256、64、16。最后,最后的1*1sigmoid卷积层生成一个概率图,该概率图具有与输入图像相同大小的单个通道,表示真实像素和伪造像素的可能性。每个子模块的详细描述将在下面的小节中给出。

网络总体架构和backbone
比较了U-Net和LinkNet,它们的特征分别是通道级联和元素级和操作。U-Net首先在医学图像分割领域提出,它由捕获全局上下文的收缩路径和融合底层特征的对称扩展路径组成,使得精确定位能力逐步提高。相反,LinkNet提供了一种更轻松的跳跃连接的方式,它允许低级特征和高级特征以元素方式相加,以实现一种有效的方式。
对于初始层的特征重用是十分重要的。在大多数情况下,这些初始层处理丰富的低层特征和高频信息,作为后续层的输入。后一层倾向于从前一层积累各种低级特征,显著加强了特征的重用,提高了从各种操纵痕迹中学习有效特征的能力。由于这种特性,密集块可以强调低层次的篡改痕迹,因此更适合于图像伪造的检测。
图3是基于CASIA v1的LinkNet与U-Net不同backbone的比较。观察得到,U-Net架构内的DenseNet-121在度量AUC和MCC上得分最高,这明确表明它在定位上更精确。

现代神经网络的设计原理向更深、更窄的网络方向发展。这样就可以有效地忽略低水平干扰特征,如噪声,提取高水平语义特征,这与IFLD社区的初衷是背道而驰的。因此,适当的网络深度应该平衡高、低层次特征的捕获能力。此外,对于经过篡改的图像中的篡改区域,一般可以将图像伪造分为平滑可见的区域或复杂的、不同形状和大小的、难以察觉的物体。多尺度信息有助于增强图像的捕获能力,使操作区域多样化。
表1显示了不同网络深度的比较结果,设置与表3相同。在编码器主干深度为5(这里深度代表编码器中尺度的数量)的情况下,我们将密集块4切下,得分最高的指标表明已经达到了合适的深度。然而,当我们缩小网络深度时,度量值显著下降,同时也大量丢失了全局上下文。因此,根据比较性能,我们采用没有密集块4的深度为5的DenseNet-121作为调整后的最优编码器backbone。由于学习到的低级操作特征非常脆弱,容易受到池化层的干扰,因此分别从图像源、初始块和三个阶段密集块中选择跳跃连接特征。在这个过程中,编码器将输入图像转换成判别特征图,解码器通过进一步处理特征图输出像素级预测。

用于粗定位的RGB流
RGB流作为内容流,自动且同时捕获高级别和低级别操纵的轨迹。操纵的痕迹不仅存在于低级特征中,而且存在于高级特征中。
只用RGB流的结果如图4。

用于细化定位的噪声流
比较了三种滤波器,发现SRM的效果最好,如表3(参见#3,#4和#6)。原因
- 将相应层次中的RGB流和noise流相加,这就要求这两个流具有和数据分布一样稳定、接近的模式。但Bayar层的强制更新模式会干扰数据的分布并带来不稳定性。
- 自适应层虽然可以根据图像自适应更新参数获得高频纹理特征,但这些纹理特征与Bayar层和SRM层相比不足以反映被篡改区域与原始区域的差异。
- SRM滤波器作为一种固定的手工特征提取器,具有足够的稳定性来提取噪声残差。因此,我们将这些噪声残差特征直接反馈到后验网络结构中。

噪声流和RGB流都使用DenseNet作为Backbone,便于后面的融合。噪声流加强了对脆弱的低级别操纵痕迹的重用,并作为局部噪声描述符来暴露图像指纹之间的差异。对比图4中的RGB流和DS-UNet,我们可以看到DS-UNet在将Noise流作为辅助流之后得到了细化的结果,这说明了Noise流的重要性。
分层融合方式
对比实验结果如上表3所示,其中#5和#6分别表示通道级联(见图6)和元素级和操作。可以看出,#6网络优于#5,说明在这种情况下求和操作更合适。实际上是先添加对应的feature map,然后再进行下一次卷积运算,相当于添加一个先验:对应信道的feature map信息相似,权值相同。因此,基于元素的和运算允许两个流在空间位置上尽可能接近地分布,从而获得更好的定位性能。

此外,通道级联操作过于冗余,而层次融合方式的元素级和操作设计简单、高效。因此,我们分别在图像源处、不同尺度的跳跃位置和编码器末端对RGB流和噪声流进行求和运算融合,提供丰富的低阶操纵痕迹,并能够感知不同尺度下的篡改对象。
损失函数
Dice loss和focal loss

Experiments and discussions
Datasets
Columbia、DSO-1、Coverage、CASIA和NIST Nimble 2016(即NIST16)
Ablation study
如表3所示。

- 单流和双流对比:可以看出,仅使用SRM滤波器作为初始层(#2)的噪声流是无法实现有效定位的,因为固定的手工提取器在去除其他有用特征的同时,只保留了噪声残差特征。虽然RGB流(#1)可以获得比噪声流更高的结果,但仍然存在较高的虚警率和粗定位性能。通过以分层融合的方式整合RGB流和噪声流,DS-UNet的性能优于其他分支。特别是DS-UNet在IOU和MCC指标(4.5%和4.9%)上大大优于RGB流,因为它可以通过暴露噪声残差的不一致性来细化定位性能和降低误报率。
- 在噪声流中使用的不同初始层,即Bayar层、Adaptive层和SRM层,分别参见#3、#4和#6。结果表明,3号和4号网络变体的性能明显低于6号网络变体。原因是自适应层暴露的文本特征很难揭示被篡改区域和原始区域之间的不一致性。此外,对于Bayar层,由于其强制更新模式,在RGB流与噪声流的融合过程中会产生不稳定性,导致其结果比SRM层更差。具有固定参数的SRM层足够稳定,可以获得更好的定位精度,使其性能远远超过同类层。
- RGB和噪声流的不同融合方案。#5和#6不同的网络分别表示通道级联和元素级和操作。结果表明,#6 DS-UNet在IOU、AUC和MCC三方面以逐元和融合方式表现最佳。因此,本文提出的DS-UNet基于其优越的性能,采用逐元求和作为融合运算。
Datasets description
Pre-trained dataset
在人工创建的合成数据集上预训练的,然后在标准操作数据集上对预训练模型进行微调。
标准操纵数据集

Metric
cIOU、AUC、F1 score、ACCuracy、IOU
Evaluation and Comparison
用于图像拼接伪造
表5是在Columbia和DSO-1数据集上的评价性能。
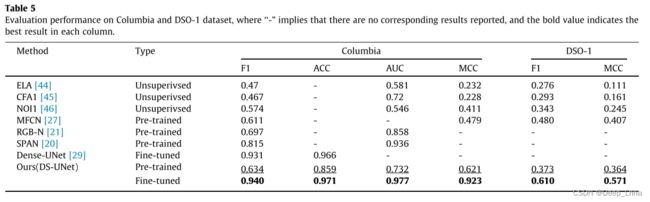
可以看出,与预训练模型和现有模型相比,微调模型在大多数指标下的性能都有很大的提高。主要原因:
- 预训练的拼接数据集不够完美或逼真,因为它包含了更多的高级操纵轨迹,使得模型容易捕获局部对比度而忽略了低级别的局部不一致性。
- 将这些深度学习方法在大量的、多样化的伪造数据集(如MT-Net和SPAN)或真实的手工数据集(如MFCN和MAG)上进行预训练。
- 这些方法,正如他们在原文中提到的,大多对每一幅测试图像都取了最优阈值,但由于缺乏相应的ground truth,在实际应用中很难实现。
表6是哥伦比亚和DSO-1数据集上cIOU度量的比较。

用于复制粘贴伪造
如表7所示。

用于多次操纵伪造
表8和表9分别显示了我们的模型相对于现有模型在处理两个数据集上的多个操作时的性能。


然而,我们也注意到,在AUC方面的结果不如从表7到表9的其他指标。这主要是因为训练前的数据集在颜色和亮度上都有非常强烈的对比,而训练前的模型对局部的高对比非常敏感,使得误报率略高于AUC指标。总体而言,该方法的AUC结果与其他方法的最佳结果非常接近。其他指标如ACC、F1、MCC、IOU的性能均优于竞争对手,说明该方法对图像伪造的检测和定位非常有效。
定位结果


Robustness analysis

Columbia数据集(从86.7%到97.7%)的结果对压缩攻击更敏感。原因是Columbia数据集的分辨率与网络输入大小相似,因此训练中的下采样量非常小,保留了最多的人为痕迹,在原始图像中取得了令人满意的定位结果。相反,NIST16在原始图像上的AUC要比Columbia低很多,这是由于在模型训练过程中,下采样的严重程度和大部分人为痕迹的丢失造成的。因此,当遇到JPEG压缩时,Columbia数据集是相当敏感的,因为在原始图像中保留了大量的痕迹,而NIST16是不敏感的,因为大多数经过操作的痕迹已经被删除。
Conclusion
本文提出了一种新的用于图像操作区域定位的名为DS-UNet的双流网络。它由两个流编码器提取特征和一个单一的解码器恢复特征图和生成预测图。作为编码器之一,RGB流用于学习用于粗略定位的高级和低级操纵轨迹。此外,噪声流是网络编码器结构中不可或缺的一部分,提供了低级别操作轨迹的额外细微信息。通过采用SRM滤波器作为初始层,噪声残差特征被馈送到噪声流以获得精确的定位结果。然后,这些双流在相应的层次结构中融合在一起。在单个解码器中采用来自编码器的跳过特征,逐渐恢复高分辨率特征图,并最终生成概率预测图。在五个标准操作数据集上的广泛实验表明,所提出的DS-UNet是非常有效的,优于最先进的方法。
未来工作
- 为了只通过对模型进行预训练而不进行任何微调就能获得更好的结果,我们会更加注重制作高质量的操纵样本的过程。
- 我们将进一步研究合适的图像降尺度方案来匹配网络输入,使其保留脆弱的低级篡改痕迹,避免性能显著下降。