论文笔记:ZERO-SHOT RESTORATION OF UNDEREXPOSED IMAGES VIA ROBUST RETINEX DECOMPOSITION
通过稳健的 Retinex 分解对曝光不足的图像进行零镜头恢复
会议:2020 IEEE International Conference on Multimedia and Expo (ICME)
论文地址:Zero-Shot Restoration of Underexposed Images via Robust Retinex Decomposition | IEEE Conference Publication | IEEE Xplore
论文代码:https://aaaaangel.github.io/RRDNet-Homepag
摘要
曝光不足的图像通常会遭受严重的质量下降,例如黑暗中的可见度差和潜在噪声。大多数以前的曝光不足图像恢复方法都会忽略噪声并在拉伸对比度期间将其放大。我们明确地预测噪声以实现去噪的目标,同时恢复曝光不足的图像。具体来说,提出了一种新颖的三分支卷积神经网络,即 RRDNet(Robust Retinex Decomposition Network 的缩写),将输入图像分解为三个分量,即光照、反射和噪声。作为一个特定于图像的网络,RRDNet 不需要任何先前的图像示例或先前的训练。相反,RRDNet 的权重将通过迭代最小化专门设计的损失函数的零样本方案进行更新。这种损失函数旨在评估测试图像的当前分解并指导噪声估计。实验表明,RRDNet 可以实现稳健的校正,具有整体自然度和令人愉悦的视觉质量。为了使结果可重现,源代码已在 https://aaaaangel.github.io/RRDNet-Homepage 上公开。
索引词——曝光不足的图像恢复、Retinex 分解、零样本学习
“1. INTRODUCTION
一、简介”
光照条件差会导致拍摄图像的质量严重下降,例如整体黑暗或背光区域中难以辨认的表面细节。此外,在光线不足的情况下,相机传感器获取的图像通常包含潜在噪声。如何为曝光不足的图像开发有效且强大的恢复器仍然是一个未解决的问题。
曝光不足图像增强的一个重要但被忽视的问题是如何在拉伸图像对比度的同时抑制暗区的噪声。在经典的 Retinex 模型 [1](该领域最广泛使用的范式之一)[2,3,4] 中,图像 I 可以分解为照度 S 和反射率 R:
![]()

图 1 RRDNet 的恢复结果。左栏中的图像是不同场景中曝光不足的图像,而右栏中的图像是恢复的结果。
其中 x 表示像素的空间位置。然而,这个经典的 Retinex 模型忽略了噪点,这在曝光不足的图像中是不可避免的。为此,[5] 中的鲁棒 Retinex 模型引入了噪声项 N,如:
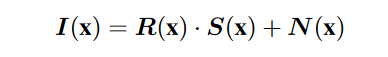
在这项工作中,我们采用方程式中的鲁棒 Retinex 模型。 (2)并引入零样本方案,即RRDNet,将输入图像分解为三个分量,光照、反射和噪声。 RRDNet 是一种新颖的三分支 CNN(卷积神经网络 [6]),可以显式估计输入图像的三个分量。分解后,可以调整光照,去除噪声,最终生成可见度高的无噪声输出。图 1 给出了几个例子。
大多数最先进的曝光不足图像恢复方法都是基于学习的,但数据驱动的训练方案极大地限制了其模型的泛化能力。在我们的方案中,RRDNet 在测试的同时进行训练,这意味着它的权重是通过迭代最小化一个专门设计的损失函数来更新的。这样的损失函数旨在评估输入图像的当前分解并确保恢复输出的质量。同时,它可以引导RRDNet根据光照分布估计噪声,从而进行去噪以避免噪声在黑暗中被放大。这种零样本方案不需要任何先前的图像示例或先前的训练。
“2. RELATED WORK AND OUR CONTRIBUTIONS
----
2. 相关工作和我们的贡献”
“2.1. Related work
----
2.1。相关工作”
曝光不足图像的恢复一直是一个长期存在的问题,在过去十年中取得了很大进展。在这里,我们根据是否使用监督学习将它们分为两类,普通类和数据驱动类。
朴素的方法。可以探索传统的图像增强方法,例如基于直方图的方法 [7、8、9、10] 来增强曝光不足的图像,但在大多数情况下,它们的功效非常有限。 Yuan 和 Sun [11] 提出了一种使用 S 曲线色调映射的自动曝光校正方法。张等人。 [12] 设计了一种无监督方案来估计输入的最佳拟合 S 曲线。这些方法中采用的参数化 S 曲线可能会压缩中间色调,并且输出图像看起来过于平坦和不自然。
基于 Retinex 理论的早期尝试 [13, 14] 去除光照并直接提取反射率作为增强结果。该分支的后期工作主要集中在光照的估计[3, 4]和调整[2]上。这些基于 Retinex 的方法假设输入图像是无噪声的,并放大了暗区的潜在噪声。傅等人。 [15]同时估计照度和反射率。李等人。 [5] 进一步将噪声项引入经典的 Retinex 分解。这两种方法通过对反射率或噪声施加约束来抑制噪声。不同的是,我们将照明引导应用于噪声估计,从而在黑暗中进行更有针对性的去噪。
数据驱动的方法。黑盒模型 [16, 17, 18, 19] 大致遵循这样的流程:首先收集或合成包含输入输出对的数据集,然后根据该数据集找到映射关系或训练曝光校正模型。基于 Retinex 理论,Shen 等人。 [20] 提出了基于多尺度 Retinex 理论的 MSR-net,并在合成的成对图像上对其进行了训练。王等人。 [21] 在他们构建的新数据集上训练了一个光照映射估计网络,包括曝光不足的图像和专家修饰的参考。魏等人。 [22]和张等人。 [23] 在包含低/正常光图像对的数据集上训练分解网络。这些基于监督学习的方法的性能高度依赖于训练数据集,尽管构建这样一个包含各种类型的照明和内容的数据集本身就是一项具有挑战性的任务。
“2.2. Our contributions
----
2.2.我们的贡献”
使用基于学习的方法是最近的趋势。然而,数据驱动的方法在泛化能力方面存在潜在的缺陷。曝光不足图像的暗区中的潜在噪声也是大多数先前方法忽略的问题。我们的贡献总结如下:
• 提出了一种用于曝光不足图像恢复的特定图像CNN,即RRDNet。 RRDNet 不需要事先培训;相反,它依赖于对单个输入图像的内部优化,确保其在各种拍摄场景和各种光照条件下的泛化能力。
• RRDNet 具有三个分支,能够明确预测输入图像的光照、反射率和噪声。这使得调整照明和完全去除噪声成为可能,以防止对比度拉伸后噪声被放大。
• 在RRDNet 中,为了优化输入图像的分解,提出了一种新的损失。这样的损失可以保证恢复的结果具有丰富的纹理细节。同时,它可以引导RRDNet根据光照分布对较暗区域的噪声进行重点估计,从而进行更有针对性的去噪,避免噪声在黑暗中被放大。
• 由于RRDNet 的CNN 结构,我们的方法可以学习Retinex 分解的表示。随着处理图像的增加,RRDNet 在面对看不见的图像时收敛到最优分解的迭代次数减少,证明了基于无监督学习的方案的优越性。
“3. RRDNET: A ROBUST RETINEX DECOMPOSITION NETWORK FOR UNDEREXPOSED IMAGE RESTORATION
----
3. RRDNET:用于曝光不足图像恢复的强大的 RETINEX 分解网络”
在本节中,将在第 2 节中介绍使用 RRDNet 进行曝光不足图像恢复的建议方法的工作流程。 3.1,然后在 Sec。 3.2我们将介绍RRDNet的损失函数的细节,它是为零样本学习而设计的。
“3.1. Three-branch decomposition and restoration
----
3.1。三分支分解与还原”
给定一张曝光不足的图像,分解是根据鲁棒的 Retinex 模型 [5] 执行的。具体来说,一张曝光不足的图像 I 可以分解为三个分量、反射率 R、照度 S 和噪声 N 为,
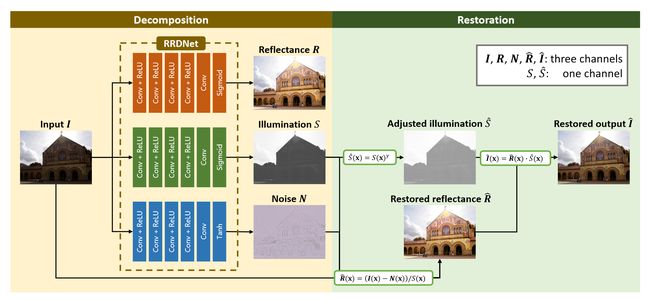
图 2. 所提出的使用 RRDNet 进行曝光不足图像恢复的方法的工作流程。 RRDNet 的三个分支分别用于估计反射率、光照和噪声(噪声图为可视化而归一化)。通过 Gamma 变换调整光照图并计算无噪声反射率。结合调整后的照度和恢复的反射率,生成恢复的输出。
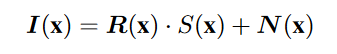
需要注意的是,为简单起见,通常假设三个颜色通道具有相同的照明 [2]。
图 2 是所提出方法的工作流程,包括分解和恢复两个阶段。在分解阶段,RRDNet 是一个三分支全卷积神经网络,其结构如图 2 所示。三个分支分别用于估计反射率、光照和噪声。反射和照明的分支以 sigmoid 层结束,以确保强度落在 [0, 1] 内。不同的是,为了更好地拟合加性噪声,使用 tanh 层作为噪声分支的最后一层,可以使噪声值落在 [-1, 1] 内。图 2 中所示的噪声图经过标准化以进行可视化。在最小化损失函数的迭代(损失函数的细节在第 3.2 节中介绍)和更新 RRDNet 的权重之后,可以生成输入图像的最终分解。
在恢复阶段,照明分量通过 Gamma 变换调整为,
![]()
其中 γ 是一个预定义的参数。根据方程式。 (3),无噪声反射率可以计算为,
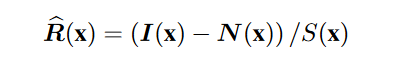

图 3 RRDNet 的分解和恢复结果。 (a) 是输入曝光不足的图像,(c)-(e) 分别是其估计的照度、反射率和归一化噪声图,(b) 是恢复输出。
结合调整后的光照度和无噪声反射率,最终的恢复结果可以计算为:
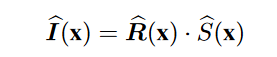
“3.2. Loss function for zero-shot learning
----
3.2.零样本学习的损失函数”
为了更新 RRDNet 的权重,我们需要一个损失函数来评估当前的分解并引导网络生成更精确的组件。我们设计了一个损失函数 L,它由三部分组成:
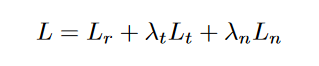
其中 Lr、Lt 和 Ln 是损失分量,λt 和 λn 是相应的权重因子。
Retinex 重建损失。图像的分解成分必须首先满足根据方程重建图像的要求。 (3)、以保证合理分解。在 Retinex 理论中,R、G、B 通道强度的最大值 S0(x) = max c∈{R,G,B} Ic(x) 通常用作光照的初始估计,反射率通过图像与其光照图之间的像素分割[3, 4]。这里我们选择这种方式作为对光照和反射率的约束。 Retinex 重建损失可以表示为,
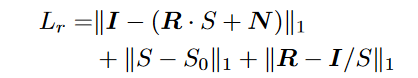
其中 I 表示输入图像,重建图像计算为 (R · S + N )。 ‖X‖1 计算 X 中所有条目的绝对值之和。l1-norm 用于指导网络生成锐利的照明和反射率。
纹理增强损失。在自然图像中,通常一个表面的光照强度是相对平坦的。分段平滑照明图有助于增强暗区的纹理。这是因为当相邻像素的强度接近时,它们的对比度会在除以相同的照度值(落在[0, 1])时被放大。为了保证纹理得到增强,设计了一个平滑度损失项 Lt 为:
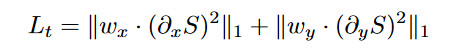
其中 x 和 y 表示水平和垂直方向。 wx 和 wy 是确保估计的地图分段平滑的权重。受 RTV 损失 [26] 的启发,权重项应与梯度成反比。在这里,我们将权重设计为,
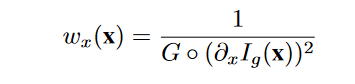
其中 G 是高斯滤波器,◦ 表示卷积算子,Ig 是输入的灰度版本。 wy 可以用类似的方式计算。
照明引导的噪声估计损失。在曝光不足的图像恢复任务中,暗区的对比度将被拉伸以提高其可见度。但与此同时,隐藏在黑暗中的噪音也会被放大。因此,有必要抑制噪声,尤其是在暗区。幸运的是,图像的光照图已经被估计出来,可以用来指导图像去噪任务,并且可以通过加权帮助 RRDNet 专注于估计黑暗中的噪声。光照引导的噪声估计损失项设计为,
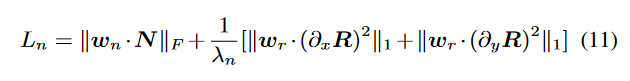
其中‖X‖F 表示矩阵 X 的 Frobenius 范数,wn 和 wr 是光照引导的权重项,设计为,
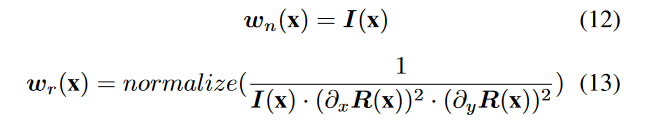
其中 normalize 表示最小-最大归一化。我们为噪声估计设计的损失函数基于两个考虑。首先,需要限制噪声图中的值范围。其次,可以通过平滑反射分量来抑制噪声。与光照平滑不同,它侧重于水平梯度和垂直梯度都较小的点,确保对真实噪声点而不是边缘进行平滑处理。为了估计黑暗中的噪声,以上两项通过光照图进行加权和限制。
图 3 给出了一个分解示例。通过结合这三个损失项,最终的 RRDNet 可以收敛,将图像 (a) 分解为局部平滑光照图 (c)、无噪声和纹理丰富的反射率 (d),以及噪声集中在黑暗区域 (e)。 (b) 是恢复结果。

“4. EXPERIMENTAL RESULTS
----
4. 实验结果”
我们进行了实验,以定量和定性地比较 RRDNet 与最先进的曝光不足图像恢复方法的性能。此外,进行消融研究以评估 RRDNet 损失函数的每个组件的影响。在所有实验中,我们设置 γ = 0.4,λt = 1 和 λn = 5000。实验在工作站上进行3.0GHz Intel Core i7-5960X CPU 和 Nvidia GeForce GTX 980Ti GPU。

图 4. 噪声图像的比较。 (a) 是输入图像,(b)-(g) 是 Yuan 和 Sun 的 [11]、NPE [2]、3) RetinexNet [22]、Zhang 等人的 [4]、ExCNet [12] 和RRDNet。

图 5. 曝光不足图像的比较。 (a) 是输入图像,(b)-(g) 是 Yuan 和 Sun 的 [11]、NPE [2]、3) RetinexNet [22]、Zhang 等人的 [4]、ExCNet [12] 和RRDNet。
数据集和比较方法。实验在四个曝光不足的图像数据集上进行,包括 MEF [24]、LIME [3]、DICM [25] 和 NPE [2]。 RRDNet 与五个曝光不足的图像恢复器进行了比较,包括 1) Yuan 和 Sun 的 [11]、2) NPE [2]、3) RetinexNet [22]、4) Zhang 等人的 [4] 和 5) ExCNet [12]。
客观评价。与[4, 5]类似,我们采用两种常用的无参考图像质量评估指标,NIQE(自然图像质量评估器)[27]和CPCQI(基于色彩的基于补丁的对比度质量指数)[28]来评估曝光不足图像恢复方法。 NIQE 评估恢复结果的整体自然度。 CPCQI从平均强度、信号强度和信号结构分量三个方面来评估输入和增强输出之间的增强效果。较低的 NIQE 值大致对应于较高的整体自然度,而较大的 CPCQI 值表示较高的对比度。
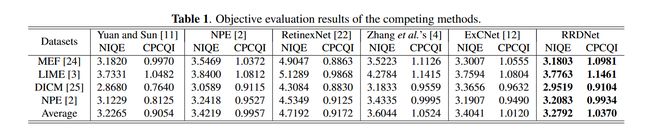
表 1 报告了四个数据集的结果。在每个数据集上,RRDNet 可以获得低 NIQE 值和高 CPCQI 值。 NPE [2]、RetinexNet [22] 和 ExCNet [12] 在自然度和对比度上均不如 RRDNet,尤其是 RetinexNet。由于 RetinexNet 是基于监督学习的,它的泛化能力在看不见的测试集上会显着恶化。 Yuan 和 Sun 的 [11] 方法可以产生具有高自然度的结果,但对比度相对较低。 Zhang 等人的 [4] 方法可以产生高对比度的输出。但是,由于它不能抑制噪声,因此会放大黑暗中的噪声,因此生成的图像会显得不自然。
视觉质量。图 4 和图 5 分别比较了噪声图像和曝光不足图像的恢复结果。图 4 和图 5 中的(c)、(d)和(e)由于过度增强,在暗区有严重的噪点,使它们显得不自然。至于两个图中的(b)和(f),它们的细节存在对比度失真。这是由于他们依赖的 S 曲线调整模型,它压缩了中间色调,使纹理看起来过于平坦。这些观察结果与表 1 中的客观评价一致。相比之下,我们的方法 RRDNet 可以自然地揭示隐藏在图像暗区中的细节,同时获得没有噪声伪影的高质量输出。
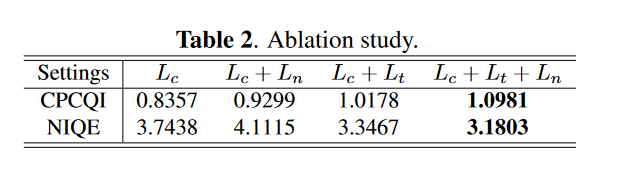
消融研究。我们对 MEF 数据集进行了消融研究,通过组合不同的损失项来定量评估 RRDNet 损失函数中每个项带来的优点。结果总结在表2中。可以看出,添加纹理增强损失项和噪声估计损失项可以明显提高恢复输出的对比度和自然度。性能的逐步改进证明了每个损失项的有效性。
“5. CONCLUSION
----
5. 结论”
在本文中,我们专注于曝光不足的图像恢复,并提出了一种零镜头方案,即 RRDNet 来执行 Retinex 分解和恢复。 RRDNet 可以显式地预测输入图像的分解图。 RRDNet 的权重是通过迭代最小化专门设计的损失函数来更新的。根据分解后的照度、反射率和噪声分量,可以生成高度可见且无噪声的输出。在不同数据集上的实验表明了我们的方法在自然度和对比度方面的优越性。未来,我们将进一步探索照明组件的调整方法。
“6. ACKNOWLEDGMENT
----
6. 致谢”
本研究部分由国家自然科学基金委员会资助,项目编号为 61672380、61973235、61972285 和 61936014,部分由上海市自然科学基金项目资助,项目编号为 19ZR1461300。