ClickHouse引擎介绍
ClickHouse引擎介绍
1. 数据库引擎
1.1 Mysql
MySQL引擎用于将远程的MySQL服务器中的表映射到ClickHouse中,并允许您对表进行INSERT和SELECT查询,以方便您在ClickHouse与MySQL之间进行数据交换。
MySQL数据库引擎会将其查询语句转换为MySQL语法并发送到MySQL服务器中,因此可以执行诸如SHOW TABLES或SHOW CREATE TABLE之类的操作。
但无法对其执行以下操作:
- RENAME
- CREATE TABLE
- ALTER
用法:
CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster]ENGINE = MySQL('host:port', ['database' | database],'user', 'password')
参数介绍:
host:port — 链接的MySQL的IP和端口。
database — 链接的MySQL数据库。
user — 链接的MySQL用户。
password — 链接的MySQL用户密码。
Mysql和ClickHouse数据类型对比:

其他的MySQL数据类型将全部转换为字符串。同时以上的所有类型都支持Nullable。
使用示例:
在MySQL中创建表:
create table `mysql_table` ( `int_id` INT NOT NULL AUTO_INCREMENT,`float` FLOAT NOT NULL,PRIMARY KEY (`int_id`));
insert into mysql_table (`int_id`, `float`) VALUES (1,2);
select * from mysql_table;
+--------+-------+
| int_id | value |
+--------+-------+
| 1 | 2 |
+--------+-------+
1 row in set (0,00 sec)
在ClickHouse中创建MySQL类型的数据库,同时与MySQL服务器交换数据:
CREATE DATABASE mysql_db ENGINE = MySQL('node169:3306', 'test', 'root', '123456')
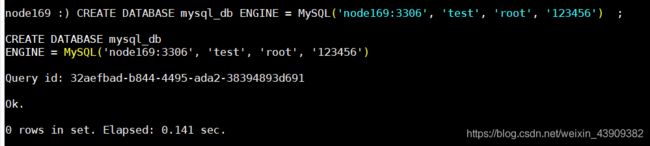
SHOW DATABASES;
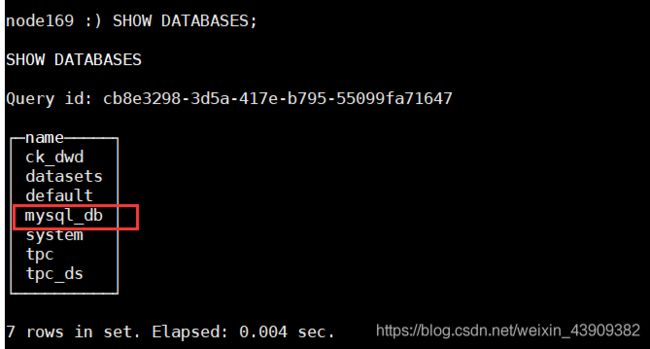
SHOW TABLES FROM mysql_db;
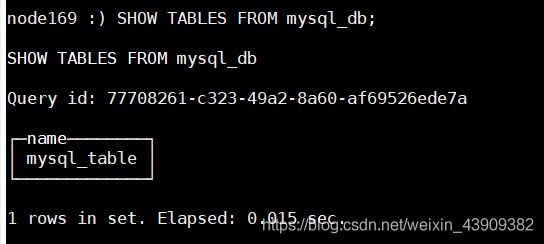
SELECT * FROM mysql_db.mysql_table
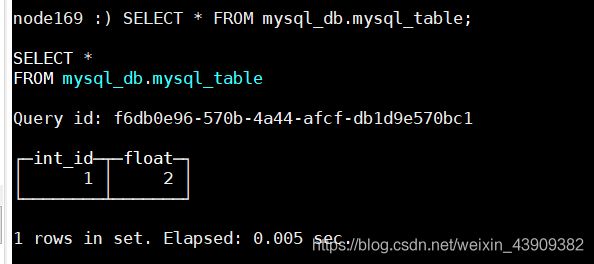
ClickHouse表中插入数据:
INSERT INTO mysql_db.mysql_table VALUES (3,4);
SELECT * FROM mysql_db.mysql_table;
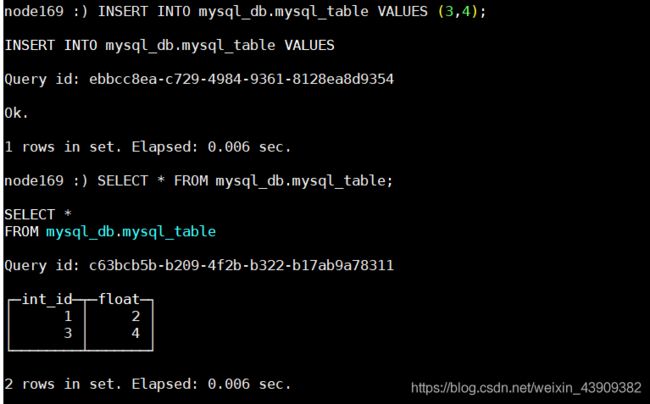
Mysql中查看数据:
select * from test.mysql_table;
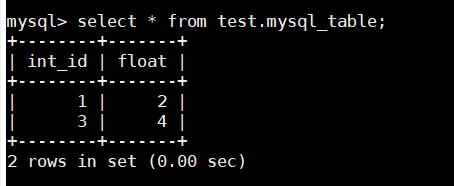
以上结果说明ClickHouse和Mysql表数据关联交换成功。
1.2 延时引擎Lazy
在距最近一次访问间隔expiration_time_in_seconds时间段内,将表保存在内存中,仅适用于 *Log引擎表。由于针对这类表的访问间隔较长,对保存大量小的 *Log引擎表进行了优化,
创建数据库 :
CREATE DATABASE testlazy ENGINE = Lazy(expiration_time_in_seconds);
1.3 Atomic
它支持非阻塞 DROP 和 RENAME TABLE 查询以及原子 EXCHANGE TABLES t1 AND t2 查询。默认情况下使用Atomic数据库引擎。
创建数据库 :
CREATE DATABASE test ENGINE = Atomic;
2. 表引擎
表引擎(即表的类型)决定了:
数据的存储方式和位置,数据写到哪里以及从哪里读取数据:
- 支持哪些查询以及如何支持。
- 并发数据访问。
- 索引的使用(如果存在)。
- 是否可以执行多线程请求。
- 数据复制参数。
2.1 表引擎类型
2.1.1 MergeTree Family
MergeTree Family包含多种引擎:
- MergeTree
- ReplacingMergeTree
- SummingMergeTree
- AggregatingMergeTree
- CollapsingMergeTree
- VersionedCollapsingMergeTree
- GraphiteMergeTree
Clickhouse 中最强大的表引擎当属 MergeTree 引擎及该系列(*MergeTree)中的其他引擎。MergeTree 系列的引擎被设计用于插入极大量的数据到一张表中。数据可以以数据片段的形式一个接着一个快速写入,数据片段在后台按照一定的规则进行合并。相比在插入时不断修改(重写)已存储的数据,这种策略会高效很多。
主要特点:
- 存储的数据按主键排序:这使得能够创建一个小型的稀疏索引来加快数据检索
- 如果指定了 partitioning key 的话,可以使用分区:在相同数据集和相同结果集的情况下 ClickHouse 中某些带分区的操作会比普通操作更快。查询中指定了分区键时 ClickHouse 会自动截取分区数据。这也有效增加了查询性能。
- 支持数据副本:ReplicatedMergeTree 系列的表提供了数据副本功能。
- 支持数据采样:需要的话,您可以给表设置一个采样方法。
这里选择MergeTree和ReplacingMergeTree进行介绍。
2.1.1.1 MergeTree
建表语法:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ...]
参数介绍:
- ENGINE - 引擎名和参数。 ENGINE = MergeTree() 时MergeTree 引擎没有参数。
- ORDER BY - 排序键。可以是一组列的元组或任意的表达式。 例如: ORDER BY (CounterID, EventDate) 。如果没有使用 PRIMARY KEY 显式指定的主键,ClickHouse 会使用排序键作为主键。如果不需要排序,可以使用ORDER BY tuple()语法创建没有主键的表,在这种情况下,ClickHouse 按插入顺序存储数据。如果要在INSERT … SELECT查询插入数据时保存数据顺序,请设置max_insert_threads = 1。
- PARTITION BY - 分区键(可选)。要按月分区,可以使用表达式 toYYYYMM(date_column) ,这里的 date_column 是一个 Date 类型的列。分区名的格式会是 “YYYYMM” 。
- PRIMARY KEY - 如果要 选择与排序键不同的主键,可以使用primary key(可选)。默认情况下主键跟排序键(由 ORDER BY 子句指定)相同。因此,大部分情况下不需要再专门指定一个 PRIMARY KEY 子句。
- SAMPLE BY - 用于抽样的表达式(可选)。如果要用抽样表达式,主键中必须包含这个表达式。例如:
SAMPLE BY intHash32(UserID) ORDER BY (CounterID, EventDate, intHash32(UserID))。 - TTL - 指定行存储的持续时间并定义数据片段在硬盘和卷之间的移动逻辑的规则列表(可选)。表达式中必须存在至少一个 Date 或 DateTime 类型的列,比如:
TTL date + INTERVAl 1 DAY规则的类型DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'指定了当满足条件(到达指定时间)时所要执行的动作:移除过期的行,还是将数据片段(如果数据片段中的所有行都满足表达式的话)移动到指定的磁盘(TO DISK ‘xxx’) 或 卷(TO VOLUME ‘xxx’)。默认的规则是移除(DELETE)。可以在列表中指定多个规则,但最多只能有一个DELETE的规则。 - SETTINGS - 控制 MergeTree 行为的额外参数(可选)。
- index_granularity - 索引粒度。索引中相邻的『标记』间的数据行数。默认值8192 。
- index_granularity_bytes - 索引粒度,以字节为单位,默认值: 10Mb。如果想要仅按数据行数限制索引粒度, 请设置为0(不建议)。
- min_index_granularity_bytes - 允许的最小数据粒度,默认值:1024b。该选项用于防止误操作,添加了一个非常低索引粒度的表。
- enable_mixed_granularity_parts - 是否启用通过
index_granularity_bytes控制索引粒度的大小。index_granularity配置能够用于限制索引粒度的大小。当从具有很大的行(几十上百兆字节)的表中查询数据时候,index_granularity_bytes配置能够提升ClickHouse的性能。如果您的表里有很大的行,可以开启这项配置来提升SELECT 查询的性能。 - use_minimalistic_part_header_in_zookeeper - ZooKeeper中数据片段存储方式 。如果
use_minimalistic_part_header_in_zookeeper=1,ZooKeeper 会存储更少的数据。 - min_merge_bytes_to_use_direct_io - 使用直接 I/O 来操作磁盘的合并操作时要求的最小数据量。合并数据片段时,ClickHouse 会计算要被合并的所有数据的总存储空间。如果大小超过了 min_merge_bytes_to_use_direct_io 设置的字节数,则 ClickHouse 将使用直接 I/O 接口(O_DIRECT 选项)对磁盘读写。如果设置
min_merge_bytes_to_use_direct_io = 0,则会禁用直接 I/O。默认值:10 * 1024 * 1024 * 1024 字节。 - merge_with_ttl_timeout - TTL合并频率的最小间隔时间,单位:秒。默认值: 86400 (1 天)。
- write_final_mark - 是否启用在数据片段尾部写入最终索引标记。默认值: 1(不要关闭)。
- merge_max_block_size - 在块中进行合并操作时的最大行数限制。默认值:8192。
- storage_policy - 存储策略。
- min_bytes_for_wide_part,min_rows_for_wide_part 在数据片段中可以使用Wide格式进行存储的最小字节数/行数。您可以不设置、只设置一个,或全都设置。
- max_parts_in_total - 所有分区中最大块的数量(意义不明)。
- max_compress_block_size - 在数据压缩写入表前,未压缩数据块的最大大小。您可以在全局设置中设置该值。建表时指定该值会覆盖全局设置。
- min_compress_block_size - 在数据压缩写入表前,未压缩数据块的最小大小。您可以在全局设置中设置该值。建表时指定该值会覆盖全局设置。
- max_partitions_to_read - 一次查询中可访问的分区最大数。您可以在全局设置中设置该值。
建表示例:
create table test.merge_tree on CLUSTER clickhouse_cluster (
id Int8 ,
name String ,
ctime Date
)
engine=MergeTree()
order by id
partition by name ;
插入数据:
insert into test.merge_tree values(1,'zhangsan','2021-07-26'),(4,'zhangsan','2021-07-26'),(3,'lisi','2021-07-26'),(2,'lisi','2021-07-26') ;


继续插入数据:
insert into test.merge_tree values(5,'zhangsan','2021-07-26'),(6,'lisi','2021-07-26') ;
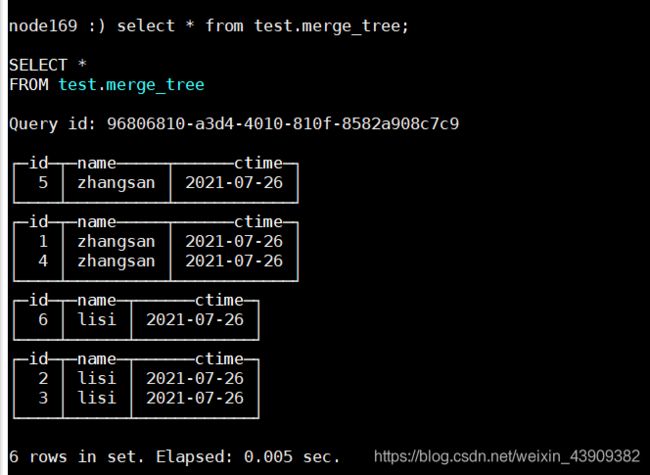
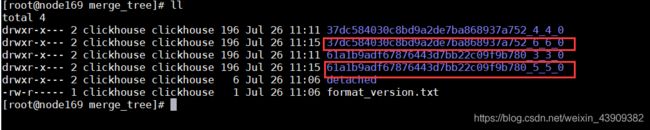
合并多次插入数据的分区:
optimize table test.merge_tree;
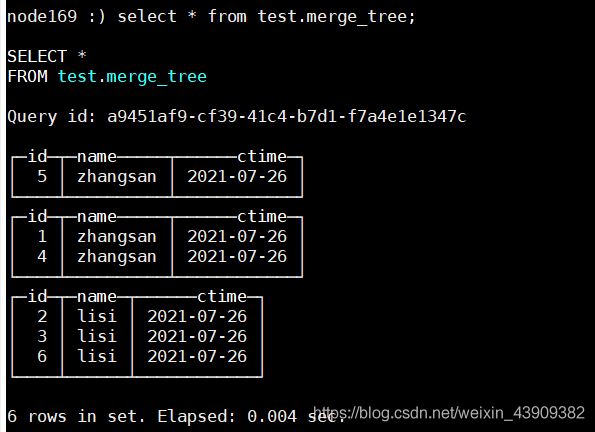
继续合并:
optimize table test.merge_tree;
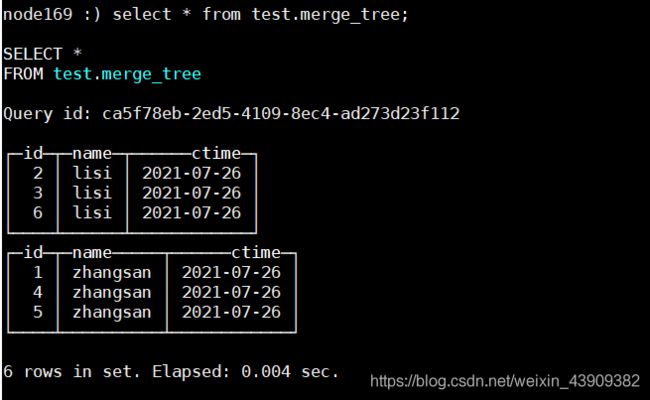
查看数据目录,发现多了两个文件夹:

一段时间之后,ClickHouse内部会自动删除合并前的多余的文件夹。
2.1.1.2 ReplacingMergeTree
该引擎和 MergeTree 的不同之处在于它会删除排序键值相同的重复项。
数据的去重只会在数据合并期间进行。合并会在后台一个不确定的时间进行,因此你无法预先作出计划。有一些数据可能仍未被处理。尽管你可以调用 OPTIMIZE 语句发起计划外的合并,但请不要依靠它,因为 OPTIMIZE 语句会引发对数据的大量读写。因此,ReplacingMergeTree 适用于在后台清除重复的数据以节省空间,但是它不保证没有重复的数据出现。
建表语法:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = ReplacingMergeTree([ver])
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
参数介绍:
ver - 版本列(可选)。类型为 UInt*, Date 或 DateTime。
在数据合并的时候,ReplacingMergeTree 从所有具有相同排序键的行中选择一行留下:
- 如果 ver 列未指定,保留最后一条。
- 如果 ver 列已指定,保留 ver 值最大的版本。
其它参数和MergeTree含义一样。
2.1.2 日志引擎系列
这些引擎是为了需要写入许多小数据量(少于一百万行)的表的场景而开发的。
这系列的引擎有:
- StripeLog
- Log
- TinyLog
共同属性 :
- 数据存储在磁盘上。
- 写入时将数据追加在文件末尾。
- 不支持突变操作。
- 不支持索引。这意味着
SELECT在范围查询时效率不高。 - 非原子地写入数据。如果某些事情破坏了写操作,例如服务器的异常关闭,你将会得到一张包含了损坏数据的表
差异性:
Log 和 StripeLog 引擎支持:
- 并发访问数据的锁。
INSERT请求执行过程中表会被锁定,并且其他的读写数据的请求都会等待直到锁定被解除。如果没有写数据的请求,任意数量的读请求都可以并发执行。 - 并行读取数据。在读取数据时,ClickHouse 使用多线程。 每个线程处理不同的数据块。
Log 引擎为表中的每一列使用不同的文件。StripeLog 将所有的数据存储在一个文件中。因此 StripeLog 引擎在操作系统中使用更少的描述符,但是 Log 引擎提供更高的读性能。
TinyLog 引擎是该系列引擎中最简单的引擎,功能最少,性能最低。TinyLog 引擎不支持并行读取和并发数据访问,并将每一列存储在不同的文件中。它比其余两种支持并行读取的引擎的读取速度更慢,并且使用了和 Log 引擎同样多的描述符。你可以在简单的低负载的情景下使用它。
2.1.2.1 Log
Log 与 TinyLog 的不同之处在于,“标记” 的小文件与列文件存在一起。这些标记写在每个数据块上,并且包含偏移量,这些偏移量指示从哪里开始读取文件以便跳过指定的行数。这样就可以在多个线程中读取表数据。对于并发数据访问,可以同时执行读取操作,而写入操作则阻塞读取和其它写入。Log引擎不支持索引。同样,如果写入表失败,则该表将损坏,并且从该表读取将返回错误。Log引擎适用于临时数据,write-once 表以及测试或演示目的。
2.1.2.2 StripeLog
在你需要写入许多小数据量(小于一百万行)的表的场景下使用这个引擎。
建表语法:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
column1_name [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
column2_name [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = StripeLog
写数据:
StripeLog 引擎将所有列存储在一个文件中。对每一次 Insert 请求,ClickHouse 将数据块追加在表文件的末尾,逐列写入。
ClickHouse 为每张表写入以下文件:
- data.bin - 数据文件。
- index.mrk — 带标记的文件。标记包含了已插入的每个数据块中每列的偏移量。
StripeLog 引擎不支持 ALTER UPDATE 和 ALTER DELETE 操作。
读数据 :
带标记的文件使得 ClickHouse 可以并行的读取数据。这意味着 SELECT 请求返回行的顺序是不可预测的。可以使用 ORDER BY 子句对行进行排序。
新建表:
CREATE TABLE test.stripe_log_table on CLUSTER clickhouse_cluster
(
timestamp DateTime,
message_type String,
message String
)
ENGINE = StripeLog
;
插入数据:
INSERT INTO test.stripe_log_table VALUES (now(),'REGULAR','The first regular message');
INSERT INTO test.stripe_log_table VALUES (now(),'REGULAR','The second regular message'),(now(),'WARNING','The first warning message');

我们使用两次 INSERT 请求从而在 data.bin 文件中创建两个数据块。
ClickHouse 在查询数据时使用多线程。每个线程读取单独的数据块并在完成后独立的返回结果行。这样的结果是,大多数情况下,输出中块的顺序和输入时相应块的顺序是不同的。例如:
SELECT * FROM test.stripe_log_table;
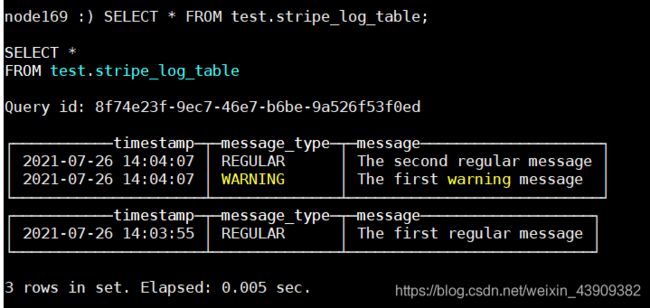
对结果排序(默认增序):
SELECT * FROM test.stripe_log_table ORDER BY timestamp;
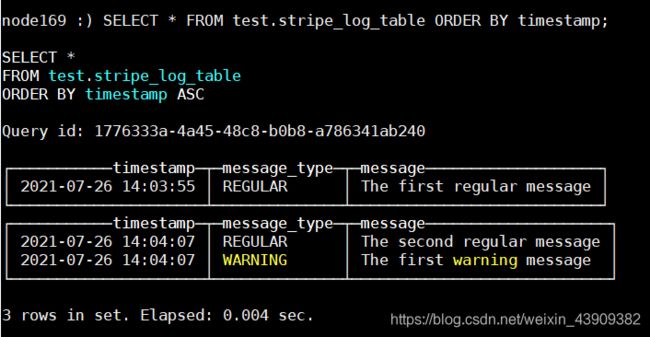
2.1.2.3 TinyLog
最简单的表引擎,用于将数据存储在磁盘上。每列都存储在单独的压缩文件中。写入时,数据将附加到文件末尾。
并发数据访问不受任何限制:
- 如果同时从表中读取并在不同的查询中写入,则读取操作将抛出异常
- 如果同时写入多个查询中的表,则数据将被破坏。
这种表引擎的典型用法是 write-once:首先只写入一次数据,然后根据需要多次读取。查询在单个流中执行。换句话说,此引擎适用于相对较小的表(建议最多1,000,000行)。如果您有许多小表,则使用此表引擎是适合的,因为它比Log引擎更简单(需要打开的文件更少)。当您拥有大量小表时,可能会导致性能低下,但如果已经在其它 DBMS 使用过,则您可能会发现切换使用 TinyLog 类型的表更容易。并且TinyLog不支持索引。
新建表:
create table test.tiny_log_table on CLUSTER clickhouse_cluster
(
id Int8
,name String
,age Int8
) engine=TinyLog
;
插入数据:
insert into test.tiny_log_table values(1,'张三',56),(2,'李四',55),(3,'王五',123) ;
查询:
select * from test.tiny_log_table;
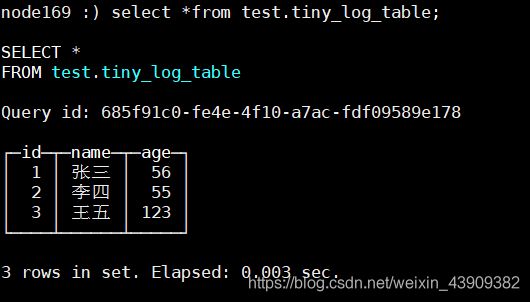
每列都存储在单独的压缩文件中:

再次插入数据:
insert into test.tiny_log_table values(4,'陈六',66),(5,'田七',55);
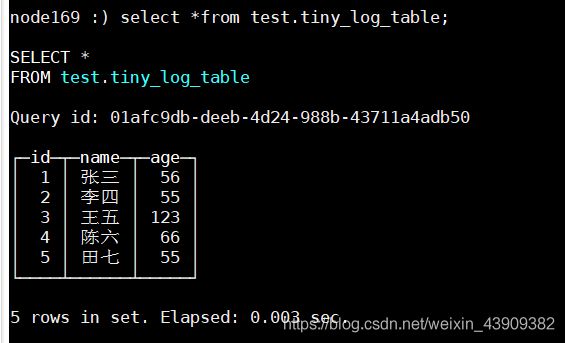
写入时,数据将附加到文件末尾。
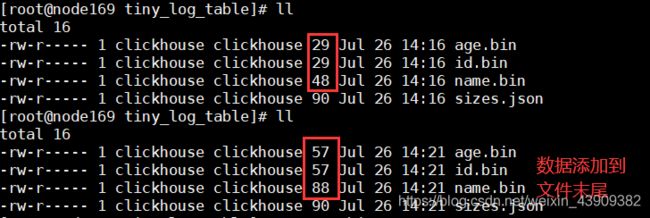
3. 集成
ClickHouse 提供了多种方式来与外部系统集成,包括表引擎。像所有其他的表引擎一样,使用CREATE TABLE或ALTER TABLE查询语句来完成配置。然后从用户的角度来看,配置的集成看起来像查询一个正常的表,但对它的查询是代理给外部系统的。这种透明的查询是这种方法相对于其他集成方法的主要优势之一,比如外部字典或表函数,它们需要在每次使用时使用自定义查询方法。
支持的集成方式:
- JDBC
- ODBC
- MySQL
- HDFS
- MongoDB
- S3
- Kafka
- EmbeddedRocksDB
- RabbitMQ
- PostgreSQL
这里以HDFS为例演示。
3.1 HDFS
这个引擎提供了与 Apache Hadoop 生态系统的集成,允许通过 ClickHouse 管理 HDFS 上的数据。这个引擎类似于文件 和 URL 引擎,但提供了 Hadoop 的特定功能。
用法:
ENGINE = HDFS(URI, format)
参数说明:
- URI - HDFS 中整个文件的 URI。路径部分 URI 可能包含 glob 通配符。 在这种情况下,表将是只读的。
- format - 指定一种可用的文件格式。 执行SELECT 查询时,格式必须支持输入,执行INSERT 查询时,格式必须支持输出.。
建表:
先在HDFS上创建文件夹:
hdfs dfs -mkdir /user/hive/warehouse/test.db/hdfs_engine_table/
CREATE TABLE test.hdfs_engine_table (name String, value UInt32) ENGINE=HDFS('hdfs://node169:8020/user/hive/warehouse/test.db/hdfs_engine_table/a.csv', 'CSV');
插入数据:
INSERT INTO test.hdfs_engine_table VALUES ('one', 1), ('two', 2), ('three', 3);
此时,hdfs上已经有了刚才插入的数据。
![]()
演示URI中存在通配符的情况:

CREATE TABLE test.test1 (name String, value UInt32) ENGINE=HDFS('hdfs://node169:8020/user/hive/warehouse/test.db/test1/*', 'CSV');
select * from test.test1;
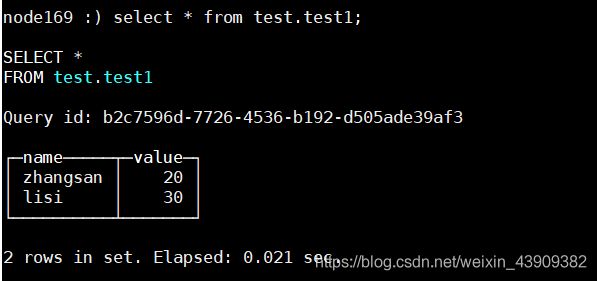
INSERT INTO test.test1 VALUES ('wangwu', '40');
DB::Exception: URI 'hdfs://node169:8020/user/hive/warehouse/test.db/test1/*' contains globs, so the table is in readonly mode.
更多文档请参阅:ClickHouse表引擎,如有问题,欢迎留言交流!