单阶段检测算法主流的标签分配方法总结
作者:极市平台 Mr.Felix
编辑:3D视觉开发者社区
导读
详解6种主流标签分配方法原理以及方法步骤。
简 介
目前主流的轻量化目标检测算法基本都是(Anthor-base或Anthor -free)单阶段结构。主体结构主要包括Backbone、Neck、Head以及Loss。
其中受限于硬件资源,Backbone主要选取轻量化的主干网络,如MobileNet系列、ShuffleNet系列等;Neck主要基于FPN的变种,意在增强深层和浅层特征的更好融合;Head主要是对Backbone提取到的特征进行解码得到预测结果,具体就是将分类和回归分支单独使用少量卷积解码到指定通道数;Loss只存在于训练阶段,用于告诉网络预测结果是否接近标签值,并给出对应惩罚(Loss)通过反向传播指导网络向预期(Loss减小)的方向收敛。 其中Loss的计算就涉及到正负样本的分配,合适的正负样本对最终检测效果的影响很大(详见ATSS论文分析)。
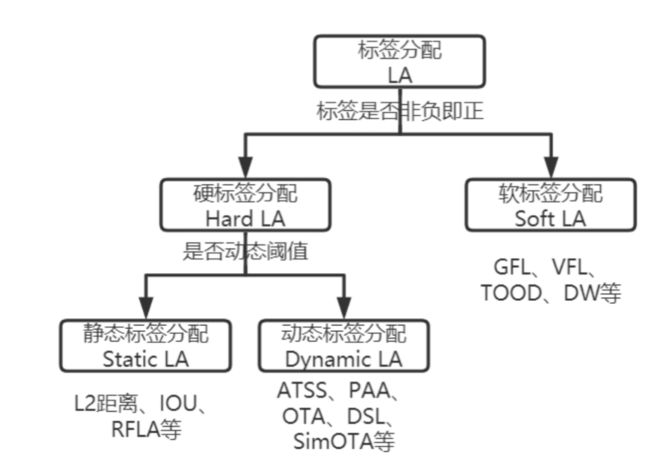
目前的标签分配方法根据标签是否非负即正分为硬标签分配(Hard LA)和软标签分配(Soft LA)两大类。
硬标签分配方法主要利用预设框或预测框与GT框比较的结果区分正负样本,样本非负即正。根据正负样本阈值是否会动态变化,硬标签分配方法又细分为静态和动态两类。静态标签分配方法主要基于距离、IOU等先验知识设置固定阈值去区分正负样本,如FCOS、两阶段标检测算法、RFLA等;动态标签分配方法则根据不同策略动态设置阈值选择正负样本,如ATSS、PAA、OTA、DSL、SimOTA等。硬标签分配本质上不区分训练过程中不同质量的预测框,即样本非负即正。
软标签分配方法会基于预测结果与真实框计算软标签和正负权重,在候选正样本(一般为落在GT内点)的基础上根据正负权重潜在分配正负样本和计算损失,且会在训练过程中动态调整软标签和正负权重,如GFL、VFL、TOOD、DW等。
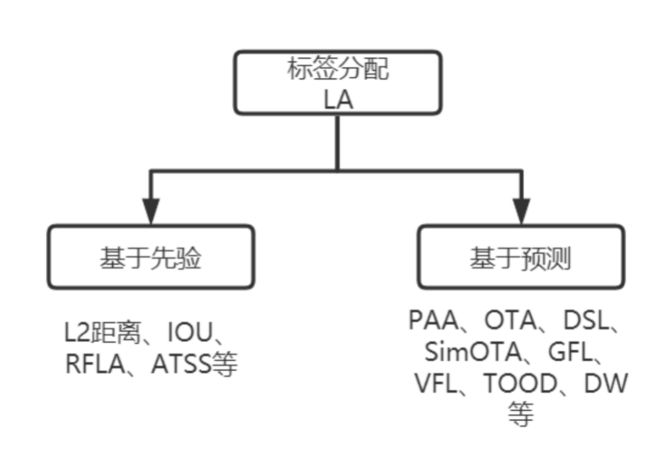
按照本人浅显的看法,根据是否有预测结果参与,标签分配方法又可以分为基于先验和基于预测两类。
基于先验的方法仅利用训练前就已知的先验信息(距离、IOU等)去进行标签分配,本质上当网络结构和数据集确定后,正负样本的分配就已经确定且不会在训练过程改变,包括静态标签分配和部分动态标签分配方法,如FCOS、ATSS等。
基于预测的方法则会根据模型预测结果和GT框的耦合结果去动态匹配正负样本,正负样本会跟随训练过程动态变化,理论上只要模型预测的越准确,匹配算法求得的结果也会更优秀,包括部分动态标签分配方法和软标签分配方法,如DSL、SimOTA、GFL、VFL、TOOD、DW。这里就会存在一个训练冷启动的问题,正如RangiLyu在NanoDet-Plus知乎文章中提到的,神经网络在随机初始化情况下具备一定抗噪能力,会自动学习到最容易的特征,一些算法也会在损失计算中引入中心先验信息(center prior)来解决冷启动问题,如Autoassign、DW等。
另外,硬标签分配方法其实是可以和软标签分配方法同时使用,典型的如NanoDet使用了ATSS和GFL,NanoDet-Plus使用了DSL和GFL。当两者联合使用时,硬标签分配方法就相当于给软标签分配方法提供了候选正样本,否则软标签分配方法将直接使用GT框内样本作为候选正样本。但是联合使用可能会导致对小目标检测不够友好。
对于小目标,本身落在下采样特征图GT框内的正样本就较少,尤其在基于预测的硬标签分配方法阶段,模型初始化训练效果较差很容易导致分配给小目标的正样本不够,之后在计算损失函数时又引入软标签,进一步对这些正样本区分正负权重,导致最终用于监督训练的正样本损失信号较弱,影响最终的训练和检测效果,这部分在DW论文最后也有提及。但是这样联合使用对于大模型(抗噪和收敛能力强)和中大尺寸物体的检测还是有帮助。
ATSS
原理: 基于L2距离和IOU等先验信息自适应计算正负样本阈值。
步骤:
1、对于图像上每个真实框(GT),在不同层级特征图上选取L2距离最近的前k(默认为9)个预设框作为候选正样本;
2、针对每个真实框(GT),计算所有层级特征图上候选正样本与真实框的交并比(IOU),并求取均值和方差;
3、以均值和方差之和作为IOU阈值,大于阈值的候选正样本为最终正样本(分配到多个GT框时选择最大的),剩余为负样本;
RFLA
原理: 基于距离和IOU来进行标签分配,对于小目标来说,容易出现当真实框内不包含任何特征点或IOU=0时,导致分配不到足够的正样本。另外,根据文献1结论,特征点对应原图的感受野符合高斯分布,所以将预设框建模为高斯分布并计算与真实框的KL散度相比基于框或点的先验更加合适。
步骤:
1、根据各层特征图的步长及感受野计算公式得到每个特征点对应预设框;
2、将所有预设框默认分配为背景;
3、对于每个预设框,与所有真实框的KL散度(与IOU作用相同)小于负样本阈值(默认0.8)为负样本;
4、对于每个真实框,选取KL散度最大的前k(默认为3)个预设框作为正样本;
5、对预设框长宽进行放缩,之后重复步骤4(注意此步骤k会适当减小,一般取1);
6、对步骤4和步骤5得到的正样本求交集得到最终正样本;
SimOTA & DSL
原理: 通过计算模型输出与真实框的代价矩阵和IOU,在训练过程中根据预测结果动态分配预设框。
步骤:
1、将落在真实框内的特征点作为候选正样本;
2、将模型输出的候选正样本预测结果与真实框(GT)计算代价矩阵,代价矩阵包括关于分类的交叉熵损失和关于回归的IOU损失;
3、对于每个真实框(GT),选取IOU最大的前k1(默认为16)个模型输出的候选正样本预测框,并对这k1个IOU值求和作为各个真实框最终的动态k2,即对于每个真实框,最终选取代价矩阵最小的前k2个候选正样本预测框作为正样本,其他作为负样本,分配到多个GT的预测框取代价最小的GT;
这种策略与之前的ATSS最大的不同就是,它不再只依赖先验的静态的信息,而是使用当前的预测结果去动态寻找最优的匹配,只要模型预测的越准确,匹配算法求得的结果也会更优秀。
AutoAssign
原理: 将落在真实框内的点区分前后景,并根据IOU、分类得分以及中心先验分别计算正负权重,实现对真实框内物体形状的自适应(区分前背景)和对不同FPN上正负样本的自动划分,并引入ImpObj分支输出前背景得分。
步骤:
1、所有FPN层的特征点落在GT框内的作为候选正样本,其他为负样本;
2、针对候选正样本,根据其与GT框的IOU计算负权重,针对GT框外的负样本,负权重固定为1;
3、负权重与所有样本的负置信度(分类得分*前后景得分)相乘后计算交叉熵得到所有样本的负权重损失;
4、针对候选正样本,结合分类得分、前后景得分、回归损失得到正置信度,并根据正置信度和基于高斯分布的中心先验得到正权重,与正置信度相乘计算交叉熵得到候选正样本的正权重损失;
5、Loss = 所有样本的负权重损失 + 候选正样本的正权重损失
TOOD
原理: 针对分类回归任务解耦头带来的不对齐问题,根据正样本要高得分准确框、负样本要低得分的预期,设置了融合分类得分和框IOU的度量方式区分正负样本。
步骤:
1、所有FPN层的特征点落在GT框内的作为候选正样本,其他为负样本;
2、计算预测框与真实框的IOU,并根据计算得到度量t作为分类标签;
3、根据t排序并选择前k个预测框作为正样本;
4、如果一个预测框分配到多个GT,则选择IOU最大的那个作为唯一GT;
5、计算预测框分数与对应度量t的交叉熵分类损失和回归损失。
DW
原理: 针对软标签分配方法中关于正样本正负权重耦合导致无法有效区分部分候选正样本问题,提出针对正负权重解耦的计算方式,并引入Box Refine模块获得更加精准的坐标回归。
步骤:
1、所有FPN层的特征点落在GT框内的作为候选正样本,其他为负样本;
2、针对候选正样本,根据与GT框IOU计算分段负置信度,并与分类得分(centerness)耦合得到负权重,针对GT框外负样本的负权重固定为1;
3、负权重与分类得分(centerness)的交叉熵相乘得到所有样本的负权重损失;
4、针对候选正样本,根据分类得分(centerness)、IOU(实际代码使用回归损失)和基于高斯分布的中心先验耦合得到正权重,与分类得分(centerness)的交叉熵相乘得到候选正样本的正权重损失;
5、针对候选正样本计算GIOU损失,并乘以正权重;
6、Loss = 所有样本的负权重损失 + 候选正样本的正权重损失 + GIOU损失
其他思考:
DW的很多思想和实现与Autoassign相似,具体的:
相同:
1、都针对GT框内候选正样本进行正负权重计算,区分前背景;
2、针对GT框外负样本的负权重均为1;
3、针对GT框内候选正样本的正权重计算都采用分类得分、回归损失、基于高斯分布的中心先验;
区别:
1、Autoassign引入ImpObj分支输出前背景得分(0.9AP),DW保留centerness分支(可被基于高斯分布的中心先验替代?),并增加Box Refine模块获得更加精准的坐标回归(0.7AP);
2、针对GT框内候选正样本的负权重计算,Autoassign采用关于IOU的单调函数,DW采用基于IOU的分段函数和分类得分;
3、交叉熵的计算,Autoassign将权重和置信度相乘后求交叉熵,DW则将权重放在置信度的交叉熵外;
4、Autoassign没有单独设置回归损失,DW则在正负权重损失之外保留了GIOU回归损失;
5、正置信度的计算,Autoassign采用分类得分、前后景得分、回归损失的耦合,DW则只采用分类得分和centerness得分;
DW与GFL对比:
GFL主要解决训练时质量分支只针对正样本有监督,但是在预测时正负样本均会输出质量分数并与分类得分相乘作为最终得分,负样本的质量分数在训练时没有监督信号就可能在推理时输出随机的高质量分数,导致最终得分排在前面损害检测精度的问题,为此引入QFL,将质量分支和分类分支合并并监督所有正负样本。
相同:
1、看似解决问题不同,但都引入预测框与GT框的IOU作为候选正样本监督信号或软标签,本质思想都源于Autoassign区分GT框内前背景特征点并计算正负权重的思想;
2、分类分支的计算本质都是交叉熵损失;
不同:
1、GFL的候选正样本为经过ATSS等标签分配方法获取,DW则为落在GT框内所有特征点;
2、GFL的正负权重只引入了分类得分和IOU且正负权重存在耦合,DW则引入了分类得分、IOU和中心先验分开计算正负权重,且正负权重具体的计算公式存在差异;
参考文献:
1、Shifeng Zhang, Cheng Chi, Yongqiang Yao, Zhen Lei, and Stan Z Li. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection.
2、Xu C, Wang J, Yang W, et al. RFLA: Gaussian receptive field based label assignment for tiny object detection[C]//European Conference on Computer Vision. Springer, Cham, 2022: 526-543.
3、Luo, W., Li, Y., Urtasun, R., Zemel, R.: Understanding the effective receptive field in deep convolutional neural networks. Advances in Neural Information Processing Systems 29 (2016)
4、Ge Z, Liu S, Wang F, et al. Yolox: Exceeding yolo series in 2021[J]. arXiv preprint arXiv:2107.08430, 2021.
5、Xiang Li, Wenhai Wang, Lijun Wu, Shuo Chen, Xiaolin Hu, Jun Li, Jinhui Tang, and Jian Yang. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection.
6、Benjin Zhu, Jianfeng Wang, Zhengkai Jiang, Fuhang Zong,Songtao Liu, Zeming Li, and Jian Sun. Autoassign: Differentiable label assignment for dense object detection.
7、Li S, He C, Li R, et al. A Dual Weighting Label Assignment Scheme for Object Detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 9387-9396.
8、https://zhuanlan.zhihu.com/p/158218797
9、https://zhuanlan.zhihu.com/p/449912627
版权声明:本文仅做学术分享,版权归原作者所有,若涉及侵权内容请联系删文。
3D视觉开发者社区是由奥比中光给所有开发者打造的分享与交流平台,旨在将3D视觉技术开放给开发者。平台为开发者提供3D视觉领域免费课程、奥比中光独家资源与专业技术支持。
加入【3D视觉开发者社区】学习行业前沿知识,赋能开发者技能提升! 加入【3D视觉AI开放平台】体验AI算法能力,助力开发者视觉算法落地!
往期 · 推荐
1、奥比中光&英伟达第三届3D视觉创新应用竞赛圆满落幕!
2、 速来!2023第三届3D视觉创新应用竞赛决赛即将开启!
3、DeepMIM:MIM中引入深度监督方法
4、SPM: 一种即插即用的形状先验模块!