TPU Memory (2)
As we know, the data structure in the TPU is tensor, which can be regarded as a four-dimensional array, and the shape is (N, C, H, W).
To describe how a tensor is arranged on the TPU of SOPHGO, we have to know a concept first. That’s stride.
Which measures the distance between two elements of a tensor in the same NPU.
For example, a W_Stride means how many elements between tensor n,c,h,w and n,c,h,w+1
And H_stride means the number of elements we need to go through from n,c,h,w to n,c,h+1,w
Similarly, we can get the meaning of C_stride and N_stride on global memory,

But for local memory, as you can see, it is a bit different, in c_stride, it is the (number of ) element from n,c,h,w to n,c+X,h,w, where X denotes the number of NPU.

And in N_stride we also need to consider the index of local memory that we start storing data.
I will further explain this later.
So, with the shape and stride of a tensor, we basically can get the address of each element in a tensor on memory
But the unit of stride is a single element in tensor, so for different data types, to calculate their exact address, we have to count their bytes as well.
For example, in a F32 tensor, the actual distance between w and w+1 element is 1 * 4.

In global memory, the data is stored in a continuous manner, that's easy to understand. Since global memory is a complete DDR, we put each element of the tensor one after one, so the w_stride equals 1, and h_stride equals w, for c_stride, it is just h times of w, and n_stride is c times c_stride.
For example, for a tensor with the shape of (2,2,3,2),
the w_stride is 1, a new h starts after each 2 elements, so the h_stride is 2, each channel contains 3 * 2 elemtens, so c_stride should be 6, similarly, we can easily get n_stride, which is 12.
But for local memory, things turning a bit more complicated,
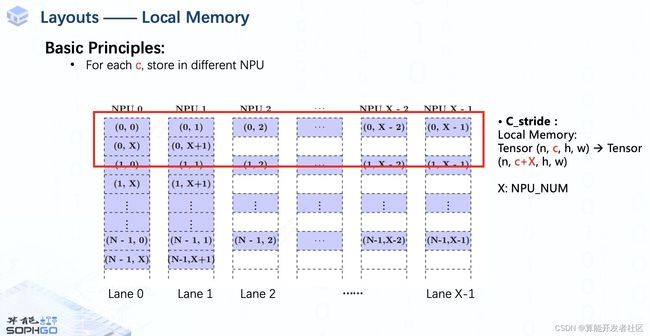
Firstly, the different channels of the tensor will be put on different NPUs. if the channel is greater than the number of NPUs, it will wrap back to the first one.
That’s why the C_stride of local memory is for n,c,h,w to n,c+X,h,w. Stride only measures the distance in the same local memory.
For example, we use X NPU to store tensor with X + 2 channel, we will put in elements of each channel from the first NPU to the last. Then store the rest two from the first NPU again.
For each batch of tensors, we will start storing from a new row on the same NPU.
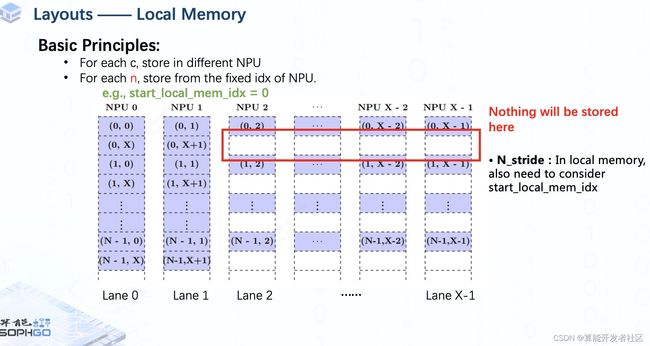
Like this example, after we finish the storage of the first batch, even if the rest memory in the same bank is empty, we won't store anything there but start from NPU0 again.
That explains why we need to consider the start index of local memory when calculating N_stride.
Based on the mentioned principles, tensors in local memory are laid out in many different ways.

The most commonly used one is the aligned layout.
This means the beginning address of the tensor should be divisible by EU_BYTE.
In addition, for data in different channels, the area to save them respectively should be multiple of EU_NUM,
so in the mathematical term, C_stride should be like this (on slide). When H * W is smaller than EU_NUM, C_stride is EU_NUM. when it is between one and two times of EU_NUM, C_stride should be 2 times (of EU_NUM).
When it comes to N_stride since sometimes the number of channels is greater than NPU_NUM or the start index of local memory is non-zero, which may cause data of different channels stored in the same NPU, the formula of N_stride should also do the round-up operation like shown in the slide.
For example, we gonna process a fp16 tensor with the shape of 2,3,4,5 on a TPU with 64 EU_BYTE. There are 4 NPU and the start index of local memory is set to 0.
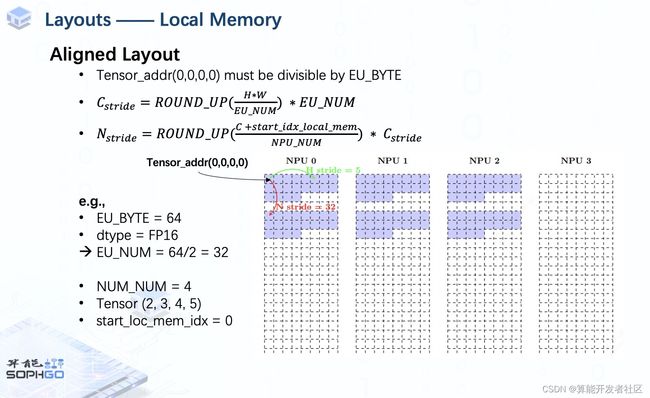
So we will store the tensor from NPU0, W_stride and H_stride are obviously 1 and 5.
Since H * W is smaller than EU_NUM, C_stride equals 32.
Plus, N_stride is 32 as well since channel of this tensor is smaller than NPU_NUM.
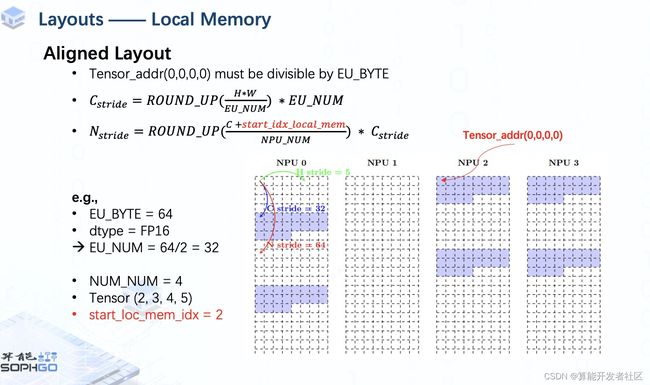
But when the start index is set to 2, things gonna be a bit different, C stride is still 32, but since the last channel of the tensor is wrapped back to the first NPU, data in the next batch should be stored from the next row of NPU2, then N_stride should be 64.
Another common type of layout is compact layout. Except for C_stride, the rest part is similar to the aligned one.
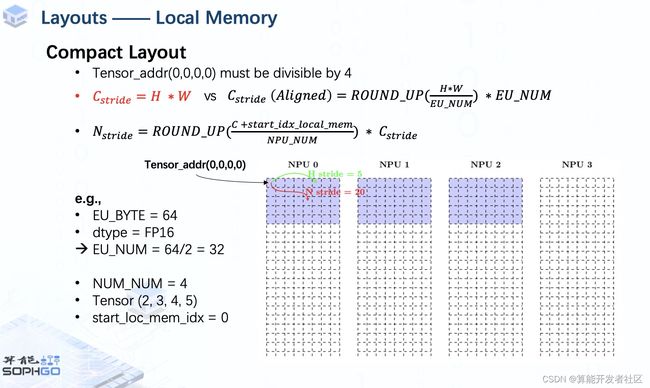
Due to the time issue, I won't go further in this part, you guys can pause here and try to compute the stride by yourselves. If you are interested in more kinds of layouts, let me know and I will make another video for it in the future.
Reference
SOPHGO TPU-MLIR:https://tpumlir.org
SOPHGO TPU-MLIR GitHub:https://github.com/sophgo/tpu-mlir
SOPHGO TPU-MLIR Gitee:https://gitee.com/sophgo/tpu-mlir