Spark源码编译与部署
Spark源码编译与调试
- 源码下载
- 源码编译
- 安装部署Spark
-
- yarn模式
- JobHistoryServer 配置
源码下载
可以从官网下载最新版本: https://spark.apache.org/downloads.html
也可以下载历史版本:https://archive.apache.org/dist/spark/
我下载的是 spark-3.0.0.tgz
源码编译
源码编译步骤可参考官网说明 https://spark.apache.org/docs/3.0.0/building-spark.html
我使用Spark源码自带的Maven工具进行编译。
- 进入spark源码目录,修改spark自带Maven的配置镜像,换成阿里仓库镜像
hadoop@ubuntu2:~$ cd spark-3.0.0
hadoop@ubuntu2:~$ vim ./build/apache-maven-3.6.3/conf/settings.xml
alimaven
aliyun maven
http://maven.aliyun.com/nexus/content/groups/public/
central
2.为防止频繁出现FullGC和CodeCache满的问题,建议修改如下配置
hadoop@ubuntu2:~$ sudo vi /etc/profile.d/my_env.sh
export MAVEN_OPTS="-Xmx2g -XX:ReservedCodeCacheSize=1g"
hadoop@ubuntu2:~$ source /etc/profile
- 输入编译命令,开始编译Spark源码:
hadoop@ubuntu2:~$ ./build/mvn -Phadoop-2.8 -Pyarn -Dhadoop.version=2.8.5 -Phive -Phive-thriftserver clean package -Dmaven.test.skip=true
参数介绍:
-Phadoop:Hadoop版本号,默认版本2.8;
-Dhadoop.version: 同-Phadoop;
-Pyarn :是否支持Hadoop YARN;
-Phive:是否在Spark SQL 中支持hive,hive默认版本2.3.7;
-Phive-thriftserver:同-Phive,支持JDBC server;
-Dmaven.test.skip=true:不执行测试用例,也不编译测试用例类;
clean package依次执行了clean、resources、compile、testResources、testCompile、test、jar(打包)等7个阶段。
创建可运行的发行版:
./dev/make-distribution.sh --name hadoop2.8.5 --tgz -Pyarn -Phadoop-2.8 -Dhadoop.version=2.8.5 -Phive -Phive-thriftserver -DskipTests
-name:发行版文件名后缀
安装部署Spark
yarn模式
Spark 客户端直接连接 Yarn,不需要额外构建 Spark 集群。有 yarn-client 和 yarn-cluster 两种模式,主要区别在于:Driver 程序的运行节点。
yarn-client:Driver 程序运行在客户端,适用于交互、调试,希望立即看到 app 的输出
yarn-cluster:Driver 程序运行在由 RM(ResourceManager)启动的 AP(APPMaster)适用于生产环境。

- 修改 hadoop 配置文件 yarn-site.xml,添加如下内容:
hadoop@ubuntu2:~$ cd /opt/hadoop2.7.1/etc/hadoop
hadoop@ubuntu2:~$ vim yarn-site.xml
yarn.nodemanager.pmem-check-enabled
false
yarn.nodemanager.vmem-check-enabled
false
yarn.log.server.url
http://ubuntu4:19888/jobhistory/logs
- 进入 spark 安装目录下的 conf 文件夹
hadoop@ubuntu2:~$ cd /opt/spark-3.0.0-bin-hadoop2.8/conf
- 修改配置文件名称
hadoop@ubuntu2:~$ mv slaves.template slaves
hadoop@ubuntu2:~$ mv spark-env.sh.template spark-env.sh
hadoop@ubuntu2:~$ mv spark-defaults.conf.template spark-defaults.conf
- 修改 slave 文件,添加 work 节点:
hadoop@ubuntu2:~$ vim slaves
ubuntu2
ubuntu3
ubuntu4
- 修改 spark-env.sh 文件,添加如下配置:
YARN_CONF_DIR=/opt/hadoop-2.7.1/etc/hadoop
- 分发 spark 包
hadoop@ubuntu2:~$ xsync /opt/spark-3.0.0-bin-hadoop2.8
- 提交任务到 Yarn 执行
hadoop@ubuntu2:~$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.12-3.0.0.jar \
100
- 浏览器输入地址查看 ubuntu3:8088/cluster 查看yarn任务

JobHistoryServer 配置
- HDFS 上创建保存Spark日志的目录。
hadoop@ubuntu2:~$ hdfs dfs -mkdir /historyserverforSpark
- 修改 spark-default.conf 文件,开启 Log:
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://ubuntu2:9000/historyserverforSpark
spark.yarn.historyServer.address=ubuntu4:18080
spark.history.ui.port=18080
spark.history.fs.logDirectory hdfs://ubuntu2:9000/historyserverforSpark
spark.history.retainedApplications=30
参数描述:
spark.eventLog.dir:Application 在运行过程中所有的信息均记录在该属性指定的路径下
spark.history.ui.port=18080 WEBUI 访问的端口号为 18080
spark.history.fs.logDirectory=hdfs://hadoop102:9000/historyserverforSpark配置了该属性后,在 start-history-server.sh 时就无需再显式的指定路径,Spark History Server 页面只展示该指定路径下的信息
spark.history.retainedApplications=30 指定保存 Application 历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
- 分发配置文件
hadoop@ubuntu2:~$ xsync spark-defaults.conf
- 启动历史服务
hadoop@ubuntu2:~$ sbin/start-history-server.sh
- 查看历史服务
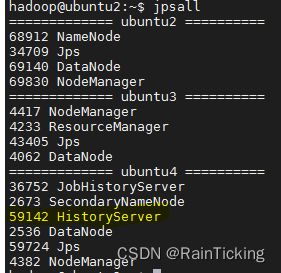
hadoop@ubuntu2:~$ jpsall
下图中的 59142 HistoryServer 就是Spark历史服务
- 在浏览器中查看历史服务
ubuntu4:18080
