YOLO V2原理总结

yolo v2在yolo v1的基础上添加或更换了一些内容,一定程度上结局了yolo v1的一些问题。
✨1 概括
做出的改变有8个:
- 添加Batch Normalization层
- 高分辨率主干网络
- anchor box机制
- 全卷积网络结构
- 新的主干网络
- K-means聚类先验框
- 使用更高分辨率特征
- 多尺度训练
✨2 添加Batch Normalization层
使用Batch Normalizaiton后yolo v1得到了一次性能提升,在VOC2007测试集上,从原本的63.4% mAP提升到65.8%mAP。
具体Batch Normalization单独总结
✨3 高分辨率主干网络
yolo v1中backbone在ImageNet预训练的图像尺寸是224,而做检测任务时,接收到的图像尺寸是448,因此,网络必须要先克服由分辨率尺寸的剧变所带来的问题。
为了解决这个问题:在224×224的低分辨率图像上训练好的分类网络又在448×448的高分辨率图像上进行微调,共微调10个轮次。微调完毕后,再去掉最后的全局平均池化层和softmax层,作为最终的backbone网络。
yolo v1网络获得了第二次性能提升:从65.8% mAP提升到69.5% mAP。
4 anchor box机制
这里指的是anchor based,除此之外还有一个叫anchor free。
这里第一次出现是Faster R-CNN,单独总结过,不再总结。
5 全卷积网络结构
yolo v1中出现了几个明显的问题:
- flatten破坏了特征的空间结构
- 全连接层也导致了参数量的爆炸
- 同一网格出现多目标无法预测、
针对flatten破坏空间结构和参数量爆炸的问题:
网络的输入图像尺寸从448改为416,去掉了YOLOv1网络中的最后一个池化层和所有的全连接层,修改后的网络的最大降采样倍数为32,最终得到的也就是13×13的网格,不再是7×7。
同一网格无法多目标预测问题:
这里采用anchor box机制。每个网格处都预设了k个的anchor box。网络只需要学习将先验框映射到真实框的尺寸的偏移量即可,无需再学习整个真实框的尺寸信息,这使得训练变得更加容易。同时加入先验框后,YOLOv2改为每一个先验框都预测一个类别和置信度,即每个网格处会有多个边界框的预测输出。因此,yolo v2的输出张量大小是S×S×k×(1+4+C),每个边界框的预测都包含1个置信度、4个边界框的位置参数和C个类别预测。可以多目标检测。
进行上述改进后,网络的精度并没有提升,反倒是略有所下降,69.5% mAP降为69.2%mAP,但召回率却从81%提升到88%。召回率的提升意味着YOLO可以找出更多的目标了,尽管精度下降了一点点。由此可见,每个网格输出多个检测结果确实有助于网络检测更多的物体。因此,作者并没有因为这微小的精度损失而放弃掉这一改进。
✨ 6 新的主干网络
yolo v2设计了新的backbone,用于提取特征,网络结构如下所示:

首先,作者在ImageNet上进行预训练,获得了72.9%的top1准确率和91.2%的top5准确率。
在精度上,DarkNet19网络达到了VGG网络的水平,但前者模型更小,浮点运算量只有后者1/5左右,因此运算速度极快。
训练完成后去掉第24,25和26层作为yolo v2的backbone,yolo v1网络从上一次的69.2%mAP提升到69.6%mAP。
✨7 K-means聚类先验框
前面提到的anchor based机制,一些参数是需要选择的,如anchor的高宽,高宽比,数量。不同于Faster R-CNN由人工设计,yolo v2采用kmeans方法在VOC数据集上进行聚类,一共聚类出k个先验框**(使用IOU作为衡量指标)**,通过实验,作者最终设定。聚类是为了检测适合该数据集anchor的高和宽。
为了解决yolo v1中线性输出器带来的问题,这里对4个边界框的位置参数做一些改变:
- 对于中心坐标偏移量本身应该介于0-1之间,但是线性输出器没有范围约束,这就容易导致在学习的初期,网络可能预测的值非常大,导致bbox分支学习不稳定。因此,在YOLOv2的时候,作者就添加了sigmoid函数来将其映射到01范围内。
- 而高和宽应该是非负数,这里采用exp-log方法,具体来说,就是将w,h 用log函数来处理一下:

这里做的事情是在训练集标签上,然后让网络训练趋近它!
预测时我们需要根据边界框参数得到中心坐标和高宽,如何做呢:
-
假设先验框的宽和高分别是
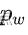 和
和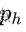
-
输出高宽偏量是
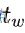 和
和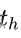
。 -
假设先验框中心坐所在网格坐标是
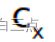 和
和
,输出位移偏量是
和
。
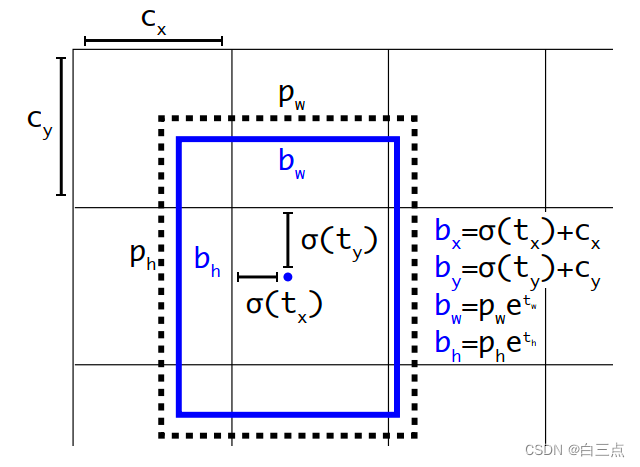
用图片中的公式即可求得中心坐标和高宽
使用kmeans聚类方法获得先验框,再配合“location prediction”的边界框预测方法,YOLOv1的性能得到了显著的提升:从69.6% mAP提升到74.4% mAP。
7 使用更高分辨率特征
这里借鉴了SSD的工作。之前yolo v1的工作中,都是用最后又一个特征层做预测,到了yolo v2,作者将backbone第17层卷积输出26x26x512的特征层做一次降采样得到13x13x2048的特征层于最后的输出在通道维度上进行拼接。
经过上述操作,该特征图具备了更多的信息。然后再拿去进行检测
但是需要注意的是,这里的降采样操作是reorg,降采样后特征图的宽高会减半,而通道则扩充至4倍。好处是降低分辨率的同时没有丢掉任何细节,信息量保持不变。
该操作后,在VOC 2007测试集上的mAP从74.4%再次涨到了75.4%。
✨8 多尺度训练
将特征金字塔的思想引入yolo。
具体来说,在训练网络时,每迭代10次,就从{320,352,384,416,448,480,512,576,608}选择一个新的图像尺寸用作后续10次训练的图像尺寸(这些尺寸都是32的整数倍,因为网络的最大降采样倍数就是32,倘若输入一个无法被32整除的图像尺寸,则会遇到些不必要的麻烦)
这种多尺度训练的好处就在于可以改变数据集中各类物体的大小占比,比如说,一个物体在608的图像中占据较多的像素,面积较大,而在320图像中就会变少了,就所占的像素数量而言,相当于从一个较大的物体变成了较小物体。通常,多尺度训练是常用的提升模型性能的技巧之一。若是目标不会有明显的尺寸变化,该技巧就不会由明显的效果,那么也就没必要进行多尺度训练了。
配合多尺寸训练,YOLOv1再一次获得了提升:从75.4% mAP提升到76.8% mAP。
✨9 先验框适配问题
通过kmeans聚类的方法所获得的先验框显然会更适合于所使用的数据集:
从A数据集聚类出的先验框显然难以适应新的B数据集。尤其A和B两个数据集中所包含的数据相差甚远时,这一问题会更加的严重。当我们换一个数据集,如Pasical Voc到COCO数据集,则需要重新进行一次聚类。
由聚类所获得的先验框严重依赖于数据集本身,倘若数据集规模过小、样本不够丰富,那么由聚类得到的先验框也未必会提供足够好的尺寸先验信息。
但这个问题其实就Anchor based都存在的问题,直到Anchor free的出现才解决。