推荐系统初谈
文章目录
- 简介
-
- 推荐系统与搜索引擎
- 发展历史
- 所属领域
- 推荐系统分类
-
- 概览
- 基于内容的推荐
- 基于协同过滤的推荐
-
- 基于内存的协同过滤
- 基于模型的协同过滤
-
- 基于矩阵分解的推荐
- 推荐系统的评价指标
- 推荐系统存在的问题
- 参考文献
简介
21年笔记迁移,主要介绍了推荐系统的定义、发展历史以及几种基本的推荐算法。
推荐系统与搜索引擎
什么是信息过载问题?
信息过载是指社会信息超过了个人或系统所能接受、处理或者有效利用的范围,是大数据时代,信息过于丰富的负面影响之一[6]。在信息过载的时代,我们该如何快速、准确的去获取所需要的高质量信息?
针对海量数据引起的信息过载(Information overload)问题,人们提出了搜索引擎和推荐系统这两个解决方案。当大家提到推荐系统的时候,最常联想到的技术就是搜索引擎,所以为了与搜索引擎对应,人们有时候也会习惯叫推荐系统为推荐引擎。这两者都是为了解决信息过载问题而提出的技术,一个问题,两种解决的出发点。文献1中戏称他俩是兄弟,着实形象有趣。
搜索引擎倾向于人们有明确的目的。它将人们对于信息的寻找需求转换为一个个精准的关键字,交给搜索引擎来返回一系列信息,用户可以对这些返回结果进行反馈。在这个过程中,用户是扮演主动角色的。但是它有一个很明显的问题:马太效应,即流行的东西会随着搜索的迭代而变得更加流行,而不流行的东西则更加不流行。
推荐引擎则倾向于人们没有明确的目的,或者说他们的目的是模糊的,通俗的讲,用户自己都不知道他们想要什么。推荐系统收集用户的历史行为、用户的兴趣偏好或者用户的人口统计学特征来送给推荐算法,然后推荐算法会产生用户可能感兴趣的项目列表。在这个过程中,用户对于推荐引擎是被动的。推荐系统没有过于明显的马太效应(实际上我觉得它也是有的),是因为它一定程度上利用了长尾理论,这也是推荐系统的价值所在。
所谓长尾,实际上是统计学中幂律和帕累托分布特征的一个口语化表达。

试验表明,长尾位置上曝光率低的项目所产生的利润,并不低于曝光率高的项目的利润,有的时候甚至更大。这一理论最早是由"wired"杂志的主编安德森在2004年提出,安德森还认为,网络时代是关注“长尾”,发挥长尾效应的时代。推荐系统正好可以给所有项目提供曝光的机会,以此来挖掘长尾的潜在利润。
推荐系统在当代互联网经济中的重要性:亚马逊35%的销售来自推荐、Google News推荐增加了38%的点击率,网飞NetFlix(DVD实体租赁)2/3的电影出租来自推荐系统。
发展历史
在信息过载的时代,推荐系统的主要任务就是联系用户和信息,一方面帮助用户发现对自己有价值的信息,另一方面让信息能够展现在对它感兴趣的用户面前,从而实现信息消费者和信息生产者的双赢。
目前,比较公认的推荐系统最早工作,是1992年首次提出的个性化邮件推荐系统Tapstry,也有学者认为是1994年的基于协同过滤的新闻推荐系统GroupLens(因为他们认为协同过滤算法的提出才真正标志着推荐系统领域的正式形成)。
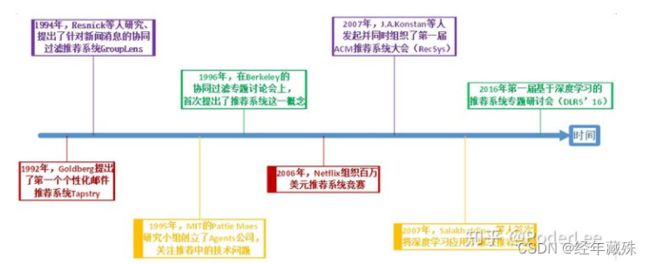
1994年,最早的自动化协同过滤系统被提出。明尼苏达大学双城分校计算机系的 GroupLens 研究组设计了名为 GroupLens 的新闻推荐系统。该工作 不仅首次提出了协同过滤的思想,并且为推荐问题建立了一个形式化的模型,为随后几十年推荐系统的发展带来了巨大影响(直到现在,推荐系统基本跟协同过滤画上了等号)。该研究组后来创建了 MovieLens 推荐网站,一个推荐引擎的学术研究平台,其包含的数据集是迄今为止推荐领域引用量最大的数据集。
推荐系统的追本溯源或许有些争议,但是要说历史上,是谁将推荐系统的研究推向高潮的,当非Netflix的百万美金大赛莫属。2006年,Netflix宣布提供一百万美元奖金给第一个能将他们公司现有推荐算法(CineMatch)的准确度提升 10%以上的参赛者。(朋友们,06年的百万美金是什么概念呢?同期,平均汇率是1美元=7.97元人民币,而当时北京的商品房成交均价是6000~8000)
重赏之下必有勇夫,自古至今皆是如此。
Netflix把广告打出去之后,立即吸引了186个国家的4万多只参赛队伍逐鹿中原。短短两周,Netflix公司就收到了169个递交,一个月后就超过了一千。
开赛几个月后,就有参赛者将原有CineMatch算法提升了5%,一年后,最好的答案已经非常接近9%,然而攻破那最后1%,足足花了大家两年。到后期,这场比赛已经演变成了一场学术研究时间,一些参与者甚至还将自己的算法完整公布出来供同行参考。
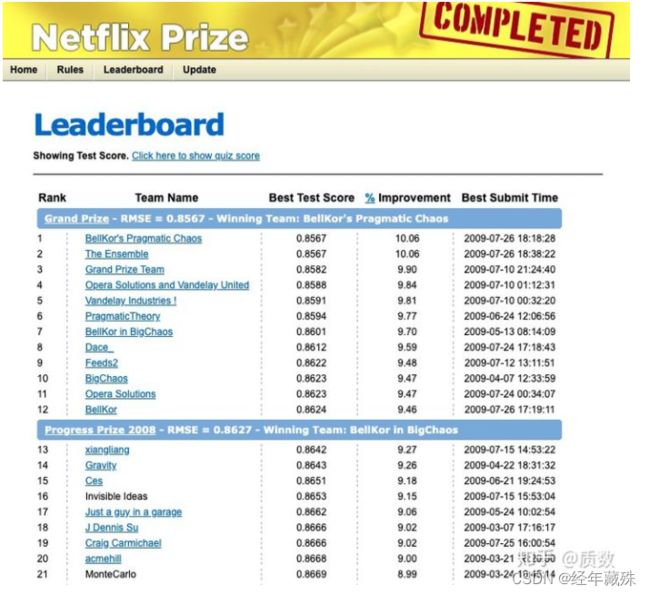
直到2009年6月26日,才有团队BellKor首次把算法准确率突破10%的门槛,达到了10.05%。后期最终获奖的也是这个团队。有趣的是,BellKor团队的获奖并不是一帆风顺。按照比赛规则,如果有团队突破了10%且30天内无人能够递交高于该团队的新算法的话,那么该团队将赢得这场比赛。
2009年7月26日,比赛结束的最后一天,BellKor团队提交了他们的最新算法10.06%,RMSE(均方根误差)为0.856704,而20min后,The Ensemble团队(其中还有个中国人)同样提交了他们的最新算法,也达到了10.06%,均方根误差为0.856714,但是由于提交时间晚了20min,且比赛规定只看小数点后四位,最终大奖颁给了BellKor团队。时间就是金钱,绝妙的注解。
所以,经过三年的角逐后,一个由工程师和统计学家组成的七人团队BellKor获得了大奖,拿到了那张百万支票,如图:

这里放一下最终的排行榜截图:

这个比赛还有两个有意思的事情。
获奖团队中有两个AT&T实验室的员工,由于他们参加百万大赛时利用了工作时间,所以他们俩所获的奖金最终归AT&T所有,最后AT&T实验室把这笔奖金捐给了当地的教育慈善机构和中小学,以鼓励青少年从事科学、技术、工程、数学(STEM)方面的学习和工作。
第一次大赛结束后,NetFlix就着热度很快提出了第二次百万美金大赛:为那些不经常做影片评级或者根本不做评级的顾客推荐影片。这就需要使用用户真实的地理信息和行为数据等。新的比赛用数据集有一亿条数据,包括评级数据,顾客年龄,性别,居住地 区邮编,和以前观看过的影片等信息。尽管所有的数据都是匿名的,没有办法把这些数据直接关联到 Netflix 的任何一位顾客,但是把顾客的年龄、性别、居住地邮编等信息公开让许多人感到不安。美国联邦政府交易委员会开始关注这项大赛对顾客隐私的损害,有一家律师事务所也代表客户递交了对Netflix的诉状。为了防止官司缠身,Netflix 在 2010 年 3 月宣布取消了第二个百万美金大奖赛,之后似乎也没再办过。
所属领域
推荐系统(Recommender System,简称RS)是属于多个领域的交叉研究。包括但不限于信息检索(Information Retrieval, IR),数据挖掘(Data Mining,DM),机器学习(Machine Learning,ML),计算机视觉(Computer Vision,CV),多媒体(MultiMedia,MM),数据库(Database,DB),哦当然还有人工智能(Artificial Intelligence,AI)。
顺便摘录一下各领域涉及的相关会议:
RS(Recommender System):RecSys
IR (Information Retrieval): SIGIR
DM(Data Mining): SIGKDD,ICDM, SDM
ML (Machine Learning): ICML, NIPS
CV (Computer Vision): ICCV, CVPR, ECCV
MM (MultiMedia): ACM MM
DB (Database): CIKM, WIDM
AI (Artificial Intelligence): IJCAI, AAAI
推荐系统分类
概览
这里的分类架构按照参考文献1展开:
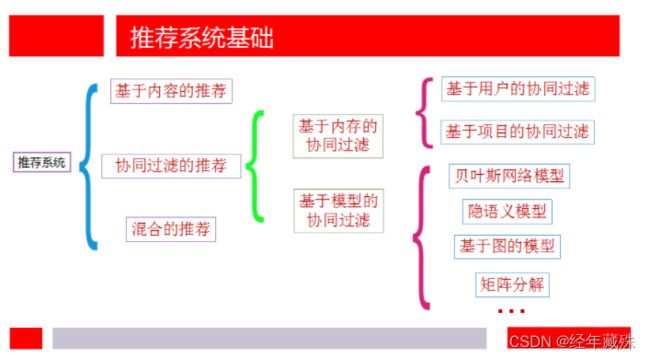
为防图片丢失,文字纪录一遍
推荐系统分类:
- 基于内容的推荐
- 基于协同过滤的推荐
- 基于内存的协同过滤
- 基于用户的协同过滤
- 基于项目的协同过滤
- 基于模型的协同过滤
- 贝叶斯网络模型
- 隐语义模型
- 基于图的模型
- 矩阵分解
- 。。。。。
- 基于内存的协同过滤
- 混合推荐
首先明确几个概念, 在推荐系统中,一般用Item来代指所推荐的物品,而User表示用户。所以有时候在推荐系统中你会看到UI矩阵这个概念,实际上讲的就是User-Item矩阵,用来描述用户和物品之间的交互情况。(以购物为例,矩阵里每个元素的值实际上就是,该用户是否购买过该产品,或者说购买过几次该产品)
基于内容的推荐
基于内容的推荐,实际上就是基于Item本身属性、内容的推荐。比如说音乐的流派、类型、节拍等,电影的风格、类别等。它不需要构建UI矩阵,因为它是基于Item本身内容来做推荐的,一般来讲,并不需要根据用户对item的评价,是直接用机器学习方法根据内容来挖用户的兴趣???
简单来讲,基于内容的推荐过程是这样的:
- 转化每个item的内容特征向量,每个user的用户特征向量;
- 基于item的内容特征向量,互相之间来计算相似度,或某种分数,找到与目标项目最接近的Item列表,然后把符合某种约束的(比如用户没有行为记录,且评分较高的)项目推荐给用户。
当然,实际过程要比这个稍微复杂一些。
参考文献1中提出了他在看andrew NG的机器学习课程中,学到的一个例子:
首先定义一个效用函数,来评价特定用户c对于特定项目s的评分:
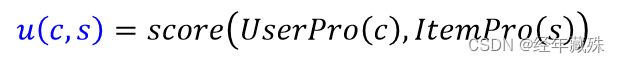
那如何根据项目的内容属性来学习一个同样维度的用户属性呢?
这就需要再定义一个目标函数:

上面应该是一个带L2惩罚范数的均方误差。我记得带L2范数是为了降低模型复杂度。
然后通过梯度下降或者其他方式来最小化这个函数,其中 θ j {\theta_j} θj就是需要学习的用户维度特征, X i {X_i} Xi是项目的内容维度特征。我们需要做的就是持续的将用户j已访问过的项目统统扔进去训练,以实现观测数据和预测数据的最小误差。
上面公式每次是首先计算第j个用户对第i个item的分数,y应该是第j个用户对第i个产品的实际评价分,俗称标签label,这里应该可以理解成01,这么说的话,再前面定义的效用函数u,实际上就是 θ T x \theta^Tx θTx。
基于协同过滤的推荐
集体智慧。
协同过滤可以算是最经典、最初代的推荐算法了,经久不衰,学界到现在还在推陈出新它的变体。
核心思想用一句话来形容就是:喜欢商品A的人也会喜欢商品B。假设大多数人都同时喜欢商品A和B,你喜欢A,那把B推荐给你准没错。(在协同过滤的文章中时常能看到这么一句话:物以类聚,人以群分。)
专业一点儿来描述就是:如何为特定用户找到他感兴趣的内容?首先需要找到与该用户具有相似兴趣的其他用户,然后将这些用户感兴趣的,且该特定用户没有看过的内容,推荐给他。
所以问题的关键在于:如何计算,或者说量化,用户之间兴趣的相似度呢?
最常用的方法是最近邻技术。基于用户的历史喜好等各种信息,转换出用户的兴趣特征向量,然后跟其他用户的兴趣特征向量算距离,找出在空间中,离该用户最近的一个或多个邻居用户,用这些邻居对某种Item的评价(或者加权评价等)来预测目标用户对此item的评价。这个过程就需要搭建User-Item矩阵。
基于协同过滤的推荐算法,根据针对对象的不同,目前公认的有两大类:
- Item-based CF:基于商品维度的协同过滤,
- User-based CF:基于用户维度的协同过滤。
但是后来协同过滤的实现方案越来越多,于是为了稍作区分,有人提出从实现技术的角度,将CF再分为两类:
- Memory-Based CF:基于内存的协同过滤;
- Model-Based CF:基于模型的协同过滤。
至于为什么这么分,二者的界限在哪里,网上给出的理由很多,莫衷一是。但比较公认的理由是“是否借助机器学习算法思想来实现”。简单看了看,我觉得这个说法也不太严格,毕竟CF本身就算是一种机器学习算法了,我个人比较倾向于去顾名思义,基于内存的协同过滤应该是指每次都需要把评分矩阵写入内存,直接进行统计计算,适用于数据量小的场合;而基于模型的CF比较适用大数据场景,需要利用数据做离线计算,会得到训练好的机器学习模型这一中间产物。大概是这样,后续看完再来具体写吧这块
基于内存的协同过滤
基于内存的协同过滤,多是基于启发式方法,依靠经验来做推荐。
最主要的步骤是相似度函数的选择上。
如何选择合适的相似度函数,来度量两个项目或者用户之间的相似度,是整个算法的关键。
另一个步骤是推荐策略上,最简单的推荐策略是,推荐大多数人(指邻居)产生过行为,而目标用户未产生行为的项目。
Item-Based CF:
- 构建UI矩阵;
- 根据UI矩阵来计算列(商品维度)之间的相似度;
- 选择与特定商品(用户所购商品或商品s)最接近的K个商品组成推荐列表;
- 从推荐列表中,选择特定用户还没有购买过的商品,予以推荐。
User-Based CF:
- 构建UI矩阵;
- 根据UI矩阵来计算行(用户维度)之间的相似度;
- 选择与特定用户最相似的K个用户;
- 为特定用户推荐,特定用户尚未购买,但相似用户购买较多的商品(高频购买)。
UI矩阵示例:
| 刀 | 枪 | 甲 | 马 | 盾 | |
|---|---|---|---|---|---|
| 刘玄德 | 1 | 1 | 1 | 1 | 1 |
| 关云长 | 1 | 1 | 1 | 0 | 1 |
| 张翼德 | 1 | 1 | 1 | 0 | 0 |
User_based CF,关羽和刘备的相似度很高,属于一类人,所以给关羽推荐马;
Item-based CF,刀枪甲属于一类,这时候上来一个用户,叫黄忠,他买了刀和枪,那我们就把甲推荐给他。
对于商品来说,购买过的用户,就是商品的特征;
对于用户来说,购买过的商品,就是用户的特征。
想起了啤酒与尿布的故事,某种意义上讲,它有点像Item-Based CF。
啤酒与尿布的故事,算是数据分析领域的经典案例,据说发生在20世纪90年代的美国超市中,超市管理人员分析销售数据时发现了一个令人难于理解的现象:在某些特定的情况下,“啤酒”与“尿布”两件看上去毫无关系的商品会经常出现在同一个购物篮中,经过调查,原因是这样的:在美国有婴儿的家庭中,一般是母亲在家中照看婴儿,年轻的父亲前去超市购买尿布。父亲在购买尿布的同时,往往会顺便为自己购买啤酒,这样就会出现啤酒与尿布这两件看上去不相干的商品经常会出现在同一个购物篮的现象。
超市发现了这一独特的现象,开始在卖场尝试将啤酒与尿布摆放在相同的区域,让年轻的父亲可以同时找到这两件商品,并很快地完成购物。
基于模型的协同过滤
所谓的运用机器学习的思想来推荐。
这部分范围比较广,
首先是问题的定性,比如说可以把“推荐”看待成一个分类问题,或者聚类问题也可以。
定好性之后,围绕问题又可以使用不同的技术来解决,比如说回归、矩阵分解算法、神经网络、图模型,都可以。
- 损失函数 + 正则项(最上面的例子就是这样)
- 神经网络+层
基于矩阵分解的推荐
基于矩阵分解(Matrix Factorization)的推荐,将“推荐”视为是一个**矩阵补全(填充)**任务。
假设我们有M个商品,N个用户,那我们的UI矩阵就是M*N大小,当然这是一个稀疏矩阵,因为用户对于商品的评分是不充分的,基本不可能有人会对所有商品评分。我们的任务是通过分析已有的数据(观测数据)来对未知的数据进行预测,这就是一个矩阵补全任务。
可以通过矩阵分解技术来完成矩阵补全的任务。
矩阵分解技术中,最常用的是奇异值分解法(Singualr Value Decomposition,简称SVD)。由此衍生了很多基于SVD的矩阵分解技术。
如:
-
99年的NMF:丰富了矩阵分解在推荐系统中应用的理论基础。
-
06年的FunkSVD、
-
08年的PMF(FunkSVD变体)、
-
09年的BiasSVD:某些用户会自带一些特质,比如天生愿意给别人好评,心慈手软,比较好说话,有的人就比较苛刻,总是评分不超过3分(5分满分)。
-
10年的SVD++(
公认的精品,改进的BiasSVD):用户对于项目的历史评分记录或者浏览记录可以从侧面反映用户的偏好,加入了隐式反馈; -
10年的timeSVD(
用户的兴趣或者偏好不是一成不变的,而是随着时间而动态演化) -
14年的NCRPD-MF:矩阵分解 + 文本评论信息 + 地理邻居信息 + 项目类别信息 + 流行度等信息;
-
16年的ConvMF:矩阵分解 + CNN提取文档信息;
由于都是基于矩阵分解,所以核心套路都差不多。
以FunkSVD为例,核心就是将UI矩阵转换为两个低秩的用户和商品矩阵,同时降低计算复杂度:
U I m ∗ n = U m ∗ k I k ∗ n UI_{m*n} = U_{m*k}I_{k*n} UIm∗n=Um∗kIk∗n
然后第u个用户对第i个产品的预测评分为:
p u i = U u T I i p_{ui} = U_u^TI_i pui=UuTIi
即第u行乘以第i列
其核心目标是最小化预测评分与实际评分的差,如:
m i n p ∑ ( r u i − p u i ) 2 min_p \sum (r_{ui}-p_{ui})^2 minp∑(rui−pui)2
至于优化方法,则梯度下降等皆可。
推荐系统的评价指标
评价指标是对推荐系统好坏的直观度量。
一般来说,按照推荐任务的不同,最常用的推荐质量度量方法可以划分为三类:
- 对预测的评分进行评估,适用于评分预测任务;
- 对预测的item集合进行评估,适用于Top- N推荐任务;
- 按排名列表对推荐效果加权进行评估,既可以适用于评分预测任务也可以用于Top-N推荐任务。
这三类度量方法对应的具体评价指标分别为:
-
评分预测指标:如准确度指标:平均绝对误差(MAE)、均方误差根(RMSE)、标准化平均误差(NMAE);以及覆盖率(Coverage,
可以简单理解成多样性,促进长尾效应)(按照正常回归预测来走就行) -
集合推荐指标:如精密度(Precision)、召回(Recall)、 ROC和AUC;
-
排名推荐指标:Half-Life utility(半衰期效用指标),折扣累计收益(discounted cumulative gain, DCG)
符号定义:
-
U表示测试集中的user集合;
-
I表示测试集中的item集合;
-
r u i r_{ui} rui表示用户u对商品i的真实评分,NULL表示空缺的评分( r u i r_{ui} rui=NULL表示用户u对i没有评过分);
-
p u i p_{ui} pui表示算法预测的,用户u对商品i的评分。
则均方根误差(Root Mean Squared Error,RMSE):
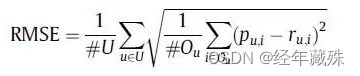
有兴趣的话可以直接去看参考文献10,讲的很全面清晰,这里就不展开讲了,主要是因为我也没看完
推荐系统存在的问题
虽然推荐系统经过了漫长的发展时间,尤其是最近在深度学习技术的帮助下取得了很大的飞跃,但时至今日,仍然存在着很多问题:
- 数据稀疏性(Data Sparsity)
- 冷启动问题(Cold start)
- 同义词问题(Synonymy)
- 孤独用户问题(Gray Sheep)
- 托打击问题(Shilling Attack)
- 其他的问题,如隐私、解释性、新颖性等等。
数据稀疏性
以淘宝为例,用户多,商品也多,而且对于一个用户而言,他能接触、了解到的商品可能只占总量的1%。在Netflix Database中共包含有48000用户,17770部电影以及上亿条评分记录。这样的UI矩阵是极为稀疏的。这样的稀疏矩阵,一方面是信息比较分散,另一方面是参数太多,计算量大。
解决方法:降维(Dimensionality Reduction)。通过奇异值分解(SVD, Singular Value Decomposition)来降低稀疏矩阵的维度,为原始矩阵求的最好的低维近似,但是存在大数据量运算成本及对效果的影响等问题(经过了 SVD变化之后,一些不活跃的用户或者物品被扔掉了,对这类用户或者物品的推荐效果就要打折扣,小众群体的存在体现不出来),不太符合挖掘长尾效应的初衷。
冷启动问题
新用户和新商品无历史行为信息。
一种解决方法是混合推荐,即混合使用多种推荐方法;
另一种方法是引入用户的个人资料,如人口学统计特征:年龄、性别、居住地等,来计算用户相似度。虽然此种做法会在一定程度上降低推荐精度,但是在数据非常稀疏的情况下也可以考虑使用。
以微博为例,微博注册后登录,或者流失一段时间后重新登录时,会让你选择几个你感兴趣的领域,并且推荐给你几个对应的账号,这也算是应对冷启动问题的一种方式。
同义词问题
该问题表现为推荐系统中同一类物品有时被归为不同的名字,这会进一步加重数据的稀疏性。解决方法有同义词挖掘、各种语义分析等。
孤独用户问题
总有一些用户的偏好跟任何人都不同,甚至还有一些用户的偏好跟正常人完全相反。这个现实中很难解决。
托打击问题
实际上是垃圾过滤的问题,即有些人对自己的东西或者对自己有利的东西打高分,而对竞争对手的东西打低分,这会影响协同过滤算法的正常工作。主动的解决方法是做清洗过滤,被动的解决方法是采用Item-Based CF(作弊者总是较少数,在计算Item相似度的时候影响较小)或者Hybrid混合算法等。
参考文献
- 推荐系统从入门到接着入门 写的很不错,尤其是简介部分对推荐系统和搜索引擎的背景介绍
- 推荐系统干货总结 跟文献1的作者一样
- 百度百科-长尾理论
- 章一 协同过滤推荐算法:基于内存的协同过滤
- 推荐系统(Recommendation System)及其矩阵分解技术 好文,但是要啃
- 百度百科-信息过载
- 推荐系统发展概述
- 回忆Netflix百万美金大奖激烈之过程
- NetFlix百万美金数据建模大奖的故事
- 推荐系统研究中常用的评价指标 详细,层次清晰
- 推荐系统的十二大评价指标总结
- 推荐系统中的矩阵分解总结 这个总结的也不错,还附带了各算法的出处论文,可以跟参考文献5连起来看