数据结构之二叉树(Binary Tree)详解
目录
1、什么是二叉树?
2、二叉树的遍历:深度优先和广度优先
(1)深度优先搜索(DFS)算法
(2)广度优先搜索(BFS)算法
3、二叉树的性质详解
4、二叉树的类型
(1)满二叉树
(2)完全二叉树
(3)二叉搜索树/二分搜索树
(4)平衡二叉树
(5)线段树
1、什么是二叉树?
二叉树是一种树型数据结构,其中每个节点最多可以有两个子节点,分别称为左子节点和右子节点。// 时间复杂度跟树的深度有关

下面是一个具有整数数据的树节点示例:
class Node {
int key;
Node left, right;
public Node(int item)
{
key = item;
left = right = null;
}
}使用 Java 代码构造一棵二叉树:
public class BinaryTree {
// Root of Binary Tree
Node root;
// Constructors
BinaryTree(int key) {
root = new Node(key);
}
BinaryTree() {
root = null;
}
public static void main(String[] args) {
BinaryTree tree = new BinaryTree();
// 创建根节点
tree.root = new Node(1);
/* 下面是上述语句后的树
1
/ \
null null
*/
tree.root.left = new Node(2);
tree.root.right = new Node(3);
/* 2和3是1的左右子结点
1
/ \
2 3
/ \ / \
null null null null */
tree.root.left.left = new Node(4);
/* 4变成了2的左子结点
1
/ \
2 3
/ \ / \
4 null null null
/ \
null null
*/
}
private static class Node {
int key;
Node left, right;
public Node(int item) {
key = item;
left = right = null;
}
}
}2、二叉树的遍历:深度优先和广度优先
不像线性数据结构(数组,链表,队列,堆栈等)只有一种逻辑方式来遍历它们,树可以用不同的方式遍历。
(1)深度优先搜索(DFS)算法
深度优先遍历(Depth-First Traversal)是一种针对二叉树的遍历方式,它的核心思想是尽可能深地访问二叉树的节点,直到无法继续深入为止,然后回溯到上一层节点继续遍历。深度优先遍历有三种常见的方式:前序遍历、中序遍历和后序遍历。// 本质就是先访问根节点还是后访问根节点
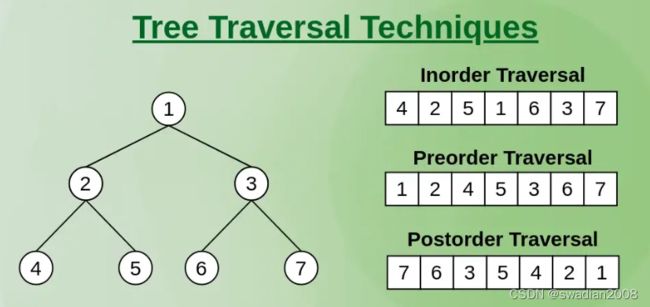
1)前序遍历(Preorder Traversal)
前序遍历的规则是先访问根节点,然后按照从左到右的顺序递归地遍历左子树和右子树。前序遍历的顺序是:根节点 -> 左子树 -> 右子树。
前序遍历的代码实现:
public class BinaryTree {
// 根节点
Node root;
BinaryTree() {
root = null;
}
// 给定一棵二叉树,按顺序打印它的节点
void printPreorder(Node node) {
if (node == null) {
return;
}
// 打印当前节点的数据
System.out.print(node.key + " ");
// 遍历左子树
printPreorder(node.left);
// 遍历右子树
printPreorder(node.right);
}
// Driver code
public static void main(String[] args) {
BinaryTree tree = new BinaryTree();
tree.root = new Node(1);
tree.root.left = new Node(2);
tree.root.right = new Node(3);
tree.root.left.left = new Node(4);
tree.root.left.right = new Node(5);
// Function call
System.out.println("traversal of binary tree is ");
tree.printPreorder(tree.root);
}
private static class Node {
int key;
Node left, right;
public Node(int item) {
key = item;
left = right = null;
}
}
}
//输出
traversal of binary tree is
1 2 4 5 3 2)中序遍历(Inorder Traversal)
中序遍历的规则是先按照从左到右的顺序递归地遍历左子树,然后访问根节点,最后再递归遍历右子树。中序遍历的顺序是:左子树 -> 根节点 -> 右子树。
中序遍历在二叉搜索树中具有特别重要的应用,因为中序遍历会按照节点的值从小到大的顺序遍历。
中序遍历的代码实现:// 只需调整上边代码中的遍历顺序即可
// 给定一棵二叉树,按顺序打印它的节点
void printInorder(Node node) {
if (node == null) {
return;
}
// 遍历左子树
printInorder(node.left);
// 打印当前节点的数据
System.out.print(node.key + " ");
// 遍历右子树
printInorder(node.right);
}
//输出
traversal of binary tree is
4 2 5 1 3 3)后序遍历(Postorder Traversal)
后序遍历的规则是先按照从左到右的顺序递归地遍历左子树和右子树,然后访问根节点。后序遍历的顺序是:左子树 -> 右子树 -> 根节点。
后序遍历的代码实现:// 只需调整上边代码中的遍历顺序即可
// 给定一棵二叉树,按顺序打印它的节点
void printPostorder(Node node) {
if (node == null) {
return;
}
// 遍历左子树
printPostorder(node.left);
// 遍历右子树
printPostorder(node.right);
// 打印当前节点的数据
System.out.print(node.key + " ");
}
//输出
traversal of binary tree is
4 5 2 3 1 (2)广度优先搜索(BFS)算法
二叉树的广度优先遍历(Breadth-First Traversal),也称为层次遍历(Level Order Traversal),是一种按照层级顺序逐层访问二叉树节点的遍历方式。从根节点开始,按照从左到右的顺序依次访问每一层的节点,直到遍历完所有节点。// 按层读取
层序遍历的代码实现:
public class BinaryTree {
// 根节点
Node root;
BinaryTree() {
root = null;
}
/*层序遍历*/
void printLevelOrder() {
int h = height(root);
int i;
for (i = 1; i <= h; i++) {
printCurrentLevel(root, i);
}
}
/* 计算树的高度 -- 从根节点开始沿着最长路径的节点一直到最远的叶节点.*/
int height(Node root) {
if (root == null) {
return 0;
} else {
/* 计算每个子树的高度 */
int lheight = height(root.left);
int rheight = height(root.right);
/* use the larger one */
if (lheight > rheight) {
return (lheight + 1);
} else {
return (rheight + 1);
}
}
}
/* Print nodes at the current level */
void printCurrentLevel(Node root, int level) {
if (root == null) {
return;
}
if (level == 1) {
System.out.print(root.key + " ");
} else if (level > 1) {
printCurrentLevel(root.left, level - 1);
printCurrentLevel(root.right, level - 1);
}
}
// Driver code
public static void main(String[] args) {
BinaryTree tree = new BinaryTree();
tree.root = new Node(1);
tree.root.left = new Node(2);
tree.root.right = new Node(3);
tree.root.left.left = new Node(4);
tree.root.left.right = new Node(5);
// Function call
System.out.println("traversal of binary tree is ");
tree.printLevelOrder();
}
private static class Node {
int key;
Node left, right;
public Node(int item) {
key = item;
left = right = null;
}
}
}
//输出
traversal of binary tree is
1 2 3 4 5 四种遍历方法遍历下面的树:
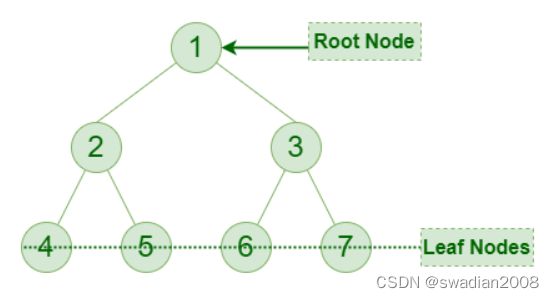
- 前序遍历结果:1-2-4-5-3-6-7
- 中序遍历结果:4-2-5-1-6-3-7
- 后序遍历结果:4-5-2-6-7- 1
- 层序遍历结果:1-2-3-4-5-6-7
3、二叉树的性质详解
二叉树示例图://注意二叉树并没有元素的大小顺序,仅仅只是规定子节点数为2
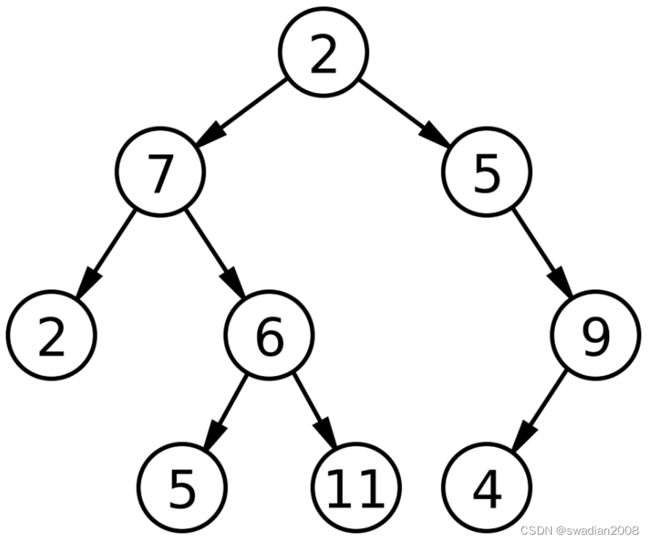
(1)性质1:二叉树的第 i 层上至多有 2^(i-1)(i≥1)个节点。// 每层的节点
- 如果是第 1 层(根节点),那么该层最多有 2^(1-1),也就是 2^0 = 1 个节点。
- 如果是第 3 层,那么该层最多有 2^(3-1),也就是 2^2 = 4 个节点。
(2)性质2:深度为 h 的二叉树中至多含有 2^h - 1 个节点。// 整棵树的节点
- 如果树的深度为 1(只有根节点),整棵树最多有 2^1-1,也就是 2 - 1 = 1 个节点。
- 如果树的深度为 3 ,整棵树最多有 2^3 - 1,也就是 8 - 1 = 7 个节点。
(3)性质3:若在任意一棵二叉树中,有 n0 个叶子节点,有 n2 个度为 2 的节点,则必有 n0 = n2 + 1。
如二叉树示例图,在图中的叶子节点数为 4 个(没有子节点的节点),分别为:2、5、11、4,所以 n0 = 4;度为 2 的节点有 3 个,分别为:2、7、6;则总有:n0 = n2 + 1,在上图所述的二叉树中也就是:3 + 1 = 4 // 有点像叶子节点数量等于前边所有父节点数量之和 + 1(满二叉树)
// 补充:什么是二叉树的度?
二叉树的度是指树中所有节点的度数的最大值。1 度就代表只有一个子节点或者它是单子树, 2 度就代表有两个子节点或是左右子树都有,二叉树的度小于等于 2,因为二叉树的定义要求二叉树中任意节点的度数(节点的分支数)小于等于 2 。// 节点个数的最大值
(4)性质4:具有 n 个节点的满二叉树的深度为 [log(2)n] + 1。([ ]表示向下取整)
如下图,一颗满二叉树有 15 个节点,那么 [log(2) 15] = 3,那么这棵二叉树的深度为:3 + 1 = 4。
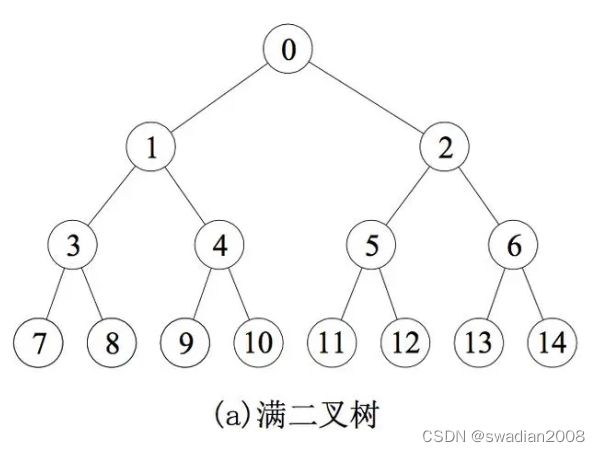
log(2)n 的计算方式示例:根据 2^4 = 16,可得 log(2) 16 = 4。
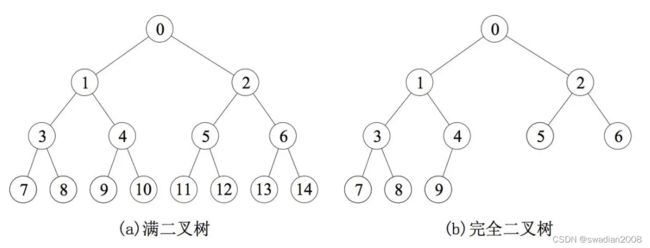
// 补充:什么是满二叉树和完全二叉树?
满二叉树:除最后一层无任何子节点外,每一层上的所有结点都有两个子结点的二叉树。
完全二叉树:一棵深度为 k 的有 n 个结点的二叉树,对树中的结点按从上至下、从左到右的顺序进行编号,如果编号为 i(1≤i≤n)的结点与满二叉树中编号为 i 的结点在二叉树中的位置相同,则这棵二叉树称为完全二叉树。// 满二叉树的缩小版
(5)性质5:若对一棵有 n 个节点的完全二叉树进行顺序编号(1≤i≤n),那么,对于编号为 i(i≥1)的节点:
- 当 i = 1 时,该节点为根,它无双亲节点。
- 当 i > 1 时,则结点 i 的父结点编号为 int_down(i/2) // int_down 表示向下取整,比如 5 的父节点为 2 -> int_down( 5 /2) = 2
- 若 2i ≤ n,则有编号为 2i 的左节点,否则没有左节点。// 下图中的 2、4、6 节点
- 若 2i + 1 ≤ n,则有编号为 2i + 1 的右节点,否则没有右节点。// 下图中的 3、5 节点

4、二叉树的类型
(1)满二叉树
满二叉树(Full Binary Tree),也称为严格二叉树,是一种特殊的二叉树。在满二叉树中,除了叶子节点外,每个节点都有两个子节点,并且所有的叶子节点都位于同一层上。
满二叉树具有以下性质:
- 所有的非叶子节点都有两个子节点。
- 所有的叶子节点都在同一层上。
- 深度为 h 的满二叉树,总共有 2^h - 1 个节点。
下面是一棵满二叉树的结构:

(2)完全二叉树
完全二叉树(Complete Binary Tree)是一种特殊的二叉树结构,在完全二叉树中,除了最后一层的叶子节点可能不满外,其他层的节点都是满的,并且最后一层的叶子节点都连续地靠左排列。
若设二叉树的深度为 h ,那么除第 h 层外,其它各层的结点数都达到最大个数,第 h 层所有的结点都连续集中在最左边。
下面是展示了一个完全二叉树的结构:

满二叉树是完全二叉树的特殊形态,如果一棵二叉树是满二叉树,则它必定是完全二叉树。
(3)二叉搜索树/二分搜索树
二叉搜索树(Binary Search Tree,BST)是一种有序的二叉树数据结构,其中对于任意节点,其左子树中的节点值都小于该节点的值,其右子树中的节点值都大于该节点的值。简而言之,二叉搜索树满足以下性质:
对于任意节点N:
- 其左子树中的所有节点的值都小于N的值。
- 其右子树中的所有节点的值都大于N的值。
- 其左子树和右子树也都是二叉搜索树。
这个性质使得二叉搜索树具有以下特点:
- 二叉搜索树中左子树中的节点值小于根节点的值,右子树中的节点值大于根节点的值,因此在二叉搜索树中查找特定值的操作可以通过比较节点值大小来进行二分搜索,提高查找效率。
- 二叉搜索树的中序遍历结果是有序的,即按照升序排列。
以下是一个二叉搜索树的结构:
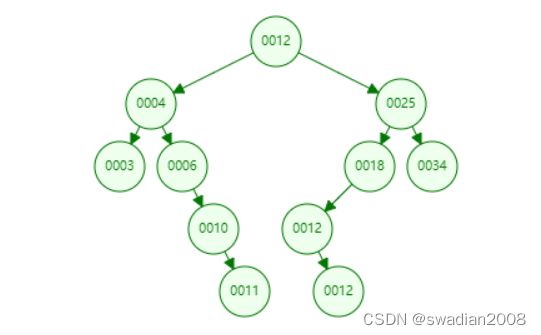
由于二叉搜索树的有序性质,它可以用作高效的数据存储和检索结构。例如,在数据库中,使用二叉搜索树可以加速查找、插入和删除操作,提高数据的访问效率。// 二分搜索,后续将详细介绍
(4)平衡二叉树
平衡二叉树(Balanced Binary Tree)是一种特殊的二叉树结构,其目的是在插入和删除节点时保持树的平衡,以提高搜索、插入和删除等操作的效率。// 主要是降低树的高度,防止二叉树退化成链表
平衡二叉树具有以下性质:
- 对于任意节点,其左子树和右子树的高度差不超过1,即左子树和右子树的高度之差的绝对值不超过1。
- 每个子树都是平衡二叉树。
平衡二叉树的常见实现包括AVL树和红黑树。这些树在插入或删除节点时会自动进行平衡操作,保持树的平衡性。平衡操作包括左旋、右旋、双旋等,通过调整节点的位置和平衡因子,使得树的高度差保持在可接受的范围内。
平衡二叉树的平衡性质保证了树的高度较低,从而使得搜索、插入和删除等操作的时间复杂度保持在O(log n)级别。相比于非平衡的二叉搜索树,平衡二叉树在大规模数据集和频繁动态操作的场景中具有更好的性能。
然而,平衡二叉树的维护需要付出额外的代价,例如在插入和删除节点时进行平衡操作可能会导致较高的复杂性。因此,在某些特定的应用场景中,可能会选择其他更适合的数据结构,如B树或跳表,以平衡性能和复杂性的需求。
以下是一个AVL树的结构:// AVL树后续会在其他文章详细介绍,此处只做简介

以下是一个红黑树的结构:// AVL树后续会在其他文章详细介绍,此处只做简介

红黑树是一种平衡二叉查找树的变体,它的左右子树高差有可能大于 1,所以红黑树不是严格意义上的平衡二叉树(AVL),但对之进行平衡的代价较低, 其平均统计性能要强于 AVL 树。
重要性质:从任一结点到其每个叶子的所有路径都包含相同数目的黑色结点。// 黑节点平衡
(5)线段树
线段树是一种二叉搜索树,与区间树相似,它将一个区间划分成一些单元区间,每个单元区间对应线段树中的一个叶结点。使用线段树可以快速的查找某一个节点在若干条线段中出现的次数,时间复杂度为O(logN)。
线段树是将每个区间 [L,R] 分解成 [L,M] 和 [M+1,R] (其中 M = (L+R) / 2 这里的除法是整数除法,即对结果下取整),直到 L == R 为止。
开始时是区间 [1,n],通过递归来逐步分解,假设根的高度为 1 的话,树的最大高度为 (n>1)。
(n>1)。
线段树对于每个 n 的分解是唯一的, 所以 n 相同的线段树结构相同,这也是实现可持久化线段树的基础。
下图展示了区间 [1,13] 的分解过程:
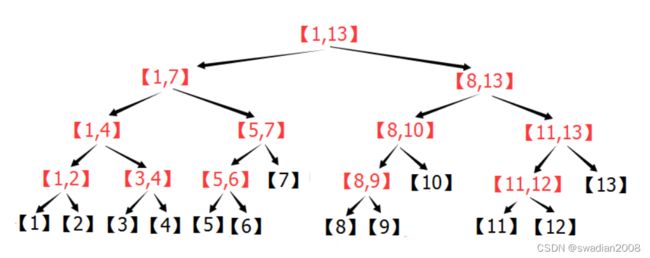
上图中,每个区间都是一个节点,每个节点存自己对应的区间的统计信息。
总结:
线段树的核心思想是将给定的区间划分为多个较小的子区间,并在每个节点上维护与该区间相关的信息。通常情况下,线段树是一棵平衡二叉树,每个叶节点表示原始数据中的一个单独元素,而其他节点表示其对应区间的聚合信息。
线段树的主要优点是可以在O(log n)的时间复杂度内进行区间查询和更新操作。通过利用线段树的特殊结构,可以快速定位并操作涉及的区间。线段树常被用于解决各种区间查询问题,如区间最值查询、区间修改、区间覆盖等。
关于线段树的推荐阅读文章,点击《线段树》。