Golang 基础一
Go 入门指南
一、变量
1、基础
1)变量声明
Go语言引入了关键字var,而类型信息放在变量名之后
var a int // 默认值为0
2)变量初始化
在定义变量时,就给变量赋值,这种方式就是变量的初始化
var a int = 10 //”=”符号,读作“赋值号”,不能读作“等号
3)变量赋值
var a, b int
a = 10
4)自动推导类型
num := 30
5)多重赋值 匿名变量
a, b, c := 10, 20, 30
6)匿名变量
_匿名变量,丢弃数据不进行处理, _匿名变量配合函数返回值使用才有价值
_, a = 10, 20
7)输出格式
fmt.Println("a = ", a)
双引号内的内容会原样输出。这样结构比较清晰,注意与变量名之间用逗号分隔。
除了使用Println()函数换行输出以外,还有另外一个函数Printf()也可以实现换行输出。
func Printf(format string, a ...any) (n int, err error)
fmt.Printf("a = %d\nb = %d", a, b)
a:=123456
b:=3.14159
//%d 占位符 表示输出一个整型数据
//%f 占位符 表示输出一个浮点型数据
//\n 表示转义字符 相当于换行符
fmt.Printf("==%3d==\n",a)
//%f占位符默认保留六位小数 %.3f表示小数点后面保留三位小数 会对第四位四舍五入
fmt.Printf("%.4f\n",b)
//%p 占位符 表示输出一个数据对应的内存地址 &a
//0x表示十六进制数据
fmt.Printf("%p",&a)
# 通用
%v the value in a default format
when printing structs, the plus flag (%+v) adds field names
%#v a Go-syntax representation of the value
%T a Go-syntax representation of the type of the value
%% a literal percent sign; consumes no value
# Boolean:
%t the word true or false
# Integer:
%b base 2
%c the character represented by the corresponding Unicode code point
%d base 10
%o base 8
%O base 8 with 0o prefix
%q a single-quoted character literal safely escaped with Go syntax.
%x base 16, with lower-case letters for a-f
%X base 16, with upper-case letters for A-F
%U Unicode format: U+1234; same as "U+%04X"
# 浮点数和复数:
%b decimalless scientific notation with exponent a power of two,
in the manner of strconv.FormatFloat with the 'b' format,
e.g. -123456p-78
%e scientific notation, e.g. -1.234456e+78
%E scientific notation, e.g. -1.234456E+78
%f decimal point but no exponent, e.g. 123.456
%F synonym for %f
%g %e for large exponents, %f otherwise. Precision is discussed below.
%G %E for large exponents, %F otherwise
%x hexadecimal notation (with decimal power of two exponent), e.g. -0x1.23abcp+20
%X upper-case hexadecimal notation, e.g. -0X1.23ABCP+20
# 字符串和字节切片(用这些动词等价地处理):
%s the uninterpreted bytes of the string or slice
%q a double-quoted string safely escaped with Go syntax
# 使用Go语法安全转义的双引号字符串
%x base 16, lower-case, two characters per byte
%X base 16, upper-case, two characters per byte
# Slice:
%p address of 0th element in base 16 notation, with leading 0x
# 以16进制表示的第0个元素的地址,前导为0x
# Pointer:
%p base 16 notation, with leading 0x
The %b, %d, %o, %x and %X verbs also work with pointers,
formatting the value exactly as if it were an integer.
| 格式 | 含义 |
|---|---|
| %% | 一个%字面量 |
| %b | 一个二进制整数值(基数为2),或者是一个(高级的)用科学计数法表示的指数为2的浮点数 |
| %c | 字符型。由对应的Unicode码位表示的字符 |
| %d | 一个十进制数值(基数为10) |
| %o | 八进制无前导,一个以八进制表示的数字(基数为8) |
| %O | 八进制,前导 “0o” |
| %x | 以十六进制表示的整型值(基数为十六),数字a-f使用小写表示 |
| %X | 以十六进制表示的整型值(基数为十六),数字A-F使用小写表示 |
| %e | 以科学记数法e表示的浮点数或者复数值 |
| %E | 以科学记数法E表示的浮点数或者复数值 |
| %f | 以标准记数法表示的浮点数或者复数值 |
| %s | 字符串。输出字符串中的字符直至字符串中的空字符(字符串以’\0‘结尾,这个’\0’即空字符) |
| %t | 以true或者false输出的布尔值 |
| %g | 以%e或者%f表示的浮点数或者复数,任何一个都以最为紧凑的方式输出 |
| %G | 以%E或者%f表示的浮点数或者复数,任何一个都以最为紧凑的方式输出 |
| %p | 以十六进制(基数为16)表示的一个值的地址,前缀为0x,字母使用小写的a-f表示 |
| %q | 使用Go语法以及必须时使用转义,以双引号括起来的字符串或者字节切片[]byte,或者是以单引号括起来的数字 |
| %T | 使用Go语法输出的值的类型 |
| %U | 一个用Unicode表示法表示的整型码点,默认值为4个数字字符 |
| %v | 使用默认格式输出的内置或者自定义类型的值,或者是使用其类型的String()方式输出的自定义值,如果该方法存在的话 |
| %+v | the plus flag (%+v) adds field names |
| %#v | a Go-syntax representation of the value |
| %w | 操作数error 将实现一个返回 error 的Unwrap方法。包含一个以上%w谓词或向其提供不实现error 接口的操作数都是无效的。动词%w在其他方面是%v的同义词 |
8)接收输入
//空格或者回车作为接收结束
var age int
_, err := fmt.Scanf("%d", &age) // “&”符号,表示获取内存单元的地址
另外一种获取用户输入数据的方式
_, err = fmt.Scan(&age)
通过Scan函数接收用户输入,这时可以省略掉%d
2、变量命名规范
1)名字必须以一个字母(Unicode字母)或下划线开头,后面可以跟任意数量的字母、数字或下划线。大写字母和小写字母是不同的:heapSort和Heapsort是两个不同的名字。
2)除了上面提到的规范要求以外,GO语言自己特有的,具有一定含义的一些字符,也不能作为变量名称。具有特殊含义的字符,我们称为关键字
break default func interface select
case defer go map struct
chan else goto package switch
const fallthrough if range type
continue for import return var
此外,还有大约30多个预定义的名字,比如int和true等
true false iota nil
int int8 int16 int32 int64
uint uint8 uint16 uint32 uint64 uintptr
float32 float64 complex128 complex64
bool byte rune string error
make len cap new append copy close delete
complex real imag
panic recover
(3) 驼峰命名法
小驼峰式命名法(lower camel case): 第一个单词以小写字母开始;第二个单词的首字母大写,例如:myName、aDog
大驼峰式命名法(upper camel case): 每一个单字的首字母都采用大写字母,例如:FirstName、LastName
不过在程序员中还有一种命名法比较流行,就是用下划线“_”来连接所有的单词,比如send_buf
二、基础数据类型
| 类型 | 名称 | 长度 | 零值 | 说明 |
|---|---|---|---|---|
| bool | 布尔类型 | 1 | false | 其值不为真即为假,不可以用数字代表true或false |
| byte | 字节型 | 1 | 0 | uint8别名 |
| rune | 字符类型 | 4 | 0 | 专用于存储unicode编码,等价于uint32 |
| int, uint | 整型 | 4或8 | 0 | 有符号或无符号32位、64位 |
| int8 | 整型 | 1 | 0 | -128 ~ 127 |
| int16 | 整型 | 2 | 0 | -32768 ~ 32767 |
| int32 | 整型 | 4 | 0 | -2147483648 到 2147483647 |
| int64 | 整型 | 8 | 0 | 0 到 18446744073709551615(1844京) |
| uint8 | 整型 | 1 | 0 | 0 |
| uint16 | 整型 | 2 | 0 | 0 ~ 65535 |
| uint32 | 整型 | 4 | 0 | 0 到 4294967295(42亿) |
| uint64 | 整型 | 8 | 0 | -9223372036854775808到 9223372036854775807 |
| float32 | 浮点型 | 4 | 0.0 | 小数位精确到7位 |
| float64 | 浮点型 | 8 | 0.0 | 小数位精确到15位 |
| complex64 | 复数类型 | 8 | ||
| complex128 | 复数类型 | 16 | 64 位实数和虚数 | |
| uintptr | 整型 | 4或8 | ⾜以存储指针的uint32或uint64整数 | |
| string | 字符串 | “” | utf-8字符串 |
用单引号括起来的单个字符是字符类型,用双引号括起来的字符是字符串类型。
2.1、字符串
Go语言中,汉字相当于3个字符
Go string 实现原理剖析(你真的了解string吗)
Go语言中的字符串字面量使用 双引号 或 反引号 来创建 :
- 双引号用来创建 可解析的字符串字面量 (支持转义,但不能用来引用多行);
- 反引号用来创建 原生的字符串字面量 ,这些字符串可能由多行组成(不支持任何转义序列),原生的字符串字面量多用于书写多行消息、HTML以及正则表达式。
fmt.Println(raw string)
如何高效地拼接字符串
性能比较:
strings.Join ≈ strings.Builder > bytes.Buffer > “+” > fmt.Sprintf
func main(){
a := []string{"a", "b", "c"}
//方式1:+
ret := a[0] + a[1] + a[2]
//方式2:fmt.Sprintf
ret := fmt.Sprintf("%s%s%s", a[0],a[1],a[2])
//方式3:strings.Builder
var sb strings.Builder
sb.WriteString(a[0])
sb.WriteString(a[1])
sb.WriteString(a[2])
ret := sb.String()
//方式4:bytes.Buffer
buf := new(bytes.Buffer)
buf.Write(a[0])
buf.Write(a[1])
buf.Write(a[2])
ret := buf.String()
//方式5:strings.Join
ret := strings.Join(a,"")
}
2.2 uintptr
三、常量
//常量的存储位置在数据区
//常量一般用大写字母表示
//栈区 系统为每一个应用程序分配1M空间用来存储变量 在程序运行结束系统会自动释放
const NUM int = 10
3.1、字面常量
所谓字面常量(literal),是指程序中硬编码的常量
常量的命名规范与变量命名规范一致。
问题:什么场景下会用到常量呢?
在程序开发中,我们用常量存储一直不会发生变化的数据,例如:π,身份证号码等。
3.1415
"123"
3.2、iota枚举
常量声明可以使用iota常量生成器初始化,它用于生成一组以相似规则初始化的常量
iota,特殊常量,可以认为是一个可以被编译器修改的常量。
在每一个const关键字出现时,被重置为0,然后再下一个const出现之前,每出现一次iota并且换行,其所代表的数字会自动增加1。
const(
a=iota //0
b=iota //1
c=iota //2
d=iota
)
//如果定义枚举时,常量写在同一行值相同 换一行值加一
const (
a=iota //0
b, c = iota, iota
d, e
)
//在定义枚举时可以为其赋初始值 但是换行后不会根据值增长
const(
a=10 //10
b,c=iota,iota //b,c 1
d,e //d,e 2
)
const (
a = iota //0
b //1
c //2
d = "ha" //独立值,iota += 1
e //"ha" iota += 1
f = 100 //iota +=1
g //100 iota +=1
h = iota //7,恢复计数
i //8
)
fmt.Println(a,b,c,d,e,f,g,h,i) // 0 1 2 ha ha 100 100 7 8
const (
name = 1 << iota // 1
name1 = 1 << iota // 2
name2 = 1 << iota // 4
name3 // 8
name4 // 16
)
四、运算符
GO语言中常见的运算符有算术运算符,赋值运算符,关系运算符,逻辑运算符等。
4.1、算术运算符
| 运算符 | 术语 | 示例 | 结果 |
|---|---|---|---|
| + | 加 | 10 + 5 | 15 |
| - | 减 | 10 - 5 | 5 |
| * | 乘 | 10 * 5 | 50 |
| / | 除 | 10 / 5 | 2 |
| % | 取模(取余) | 10 % 3 | 1 |
| ++ | 后自增,没有前自增 | a=0; a++ | a=1 |
| – | 后自减,没有前自减 | a=2; a– | a=1 |
类型转换
Go语言中不允许隐式转换,所有类型转换必须显式声明(强制转换),而且转换只能发生在两种相互兼容的类型之间
a:=10
b:=3.99
//将不同类型转成相同类型进行计算操作
//类型转换格式 数据类型(变量) 数据类型(表达式)
//c:=float64(a)*b
//将浮点型转成整型数据 保留浮点型整数部分 舍弃小数部分 不会进行四舍五入
c:=a*int(b) //30
//虽然int32和int64都是整型 但是不允许相互转换
//只有类型匹配的数据才能进行运算
//在go语言中习惯将低类型转成高类型 保证数据完整性
var a int32=10
var b int64=20
// c := a + b 错误
c:=int64(a)+b
4.2、赋值运算符
赋值运算符 =
| 运算符 | 说明 | 示例 |
|---|---|---|
| = | 普通赋值 | c = a + b 将 a + b 表达式结果赋值给 c |
| += | 相加后再赋值 | c += a 等价于 c = c + a |
| -= | 相减后再赋值 | c -= a 等价于 c = c - a |
| *= | 相乘后再赋值 | c *= a 等价于 c = c * a |
| /= | 相除后再赋值 | c /= a 等价于 c = c / a |
| %= | 求余后再赋值 | c %= a 等价于 c = c % a |
var a = 10
//a += a * 5 //60
a += a - 1 //19
4.3、关系运算符
关系运算符我们又称为比较运算符,关系运算的结果是布尔类型的。
| 运算符 | 术语 | 示例 | 结果 |
|---|---|---|---|
| == | 相等于 | 4 == 3 | false |
| != | 不等于 | 4 != 3 | true |
| < | 小于 | 4 < 3 | false |
| > | 大于 | 4 > 3 | true |
| <= | 小于等于 | 4 <= 3 | false |
| >= | 大于等于 | 4 >= 1 | true |
4.4、逻辑运算符
| 运算符 | 术语 | 示例 | 结果 |
|---|---|---|---|
| ! | 逻辑非 | !a | 如果a为假,则!a为真;如果a为真,则!a为假。 |
| && | 逻辑与 | a && b | 如果a和b都为真,则结果为真,否则为假。 |
| || | 逻辑或 | a || b | 如果a和b有一个为真,则结果为真,二者都为假时,结果为假。 |
有逻辑运算符连接的表达式叫做逻辑表达式
通过以上表格我们发现:逻辑表达式的结果同样也是bool类型
逻辑运算符两边放的一般都是关系表达式或者bool类型的值。
4.5、其他运算符
| 运算符 | 术语 | 示例 | 说明 |
|---|---|---|---|
| & | 取地址运算符 | &a | 变量a的地址 |
| * | 取值运算符 | *a | 指针变量a所指向内存的值 |
4.6、运算符优先级
在Go语言中,一元运算符(一些只需要一个操作数的运算符称为一元运算符(或单目运算符)。)拥有最高的优先级,二元运算符的运算方向均是从左至右。
下表,由上至下代表优先级由高到低
| 优先级 | 分类 | 运算符 |
|---|---|---|
| 14 | 后缀运算符 | ( )、[ ]、. |
| 13 | 单目运算符 | !、*(指针)、& 、++、–、+(正号)、-(负号) |
| 12 | 乘法/除法/取余. | *(乘号)、/、% |
| 11 | 加法/减法 | +、- |
| 10 | 位移运算符 | <<、>> |
| 9 | 关系运算符 | <、<=、>、>= |
| 8 | 相等/不等 | ==、!= |
| 7 | 按位与 | & |
| 6 | 按位异或 | ^ |
| 5 | 按位或 | | |
| 4 | 逻辑与 | && |
| 3 | 逻辑或 | || |
| 2 | 赋值运算符 | =、+=、-=、*=、/=、 %=、 >=、 <<=、&=、^=、|= |
| 1 | 逗号运算符 | , |
//括号 () 结构体成员. 数组下标[]
//单目运算符
//逻辑非! 取地址& 取值* 自增++ 自减--
//双目运算符
//乘除 * / %
//加减 + -
//关系 == != > >= < <=
//逻辑 || &&
//赋值 = += -= *= /= %=
func main1001() {
a:=10
b:=20
c:=30
//d:=a+b*c
//var d int
//d=(a+b)*c
//fmt.Println(d)
fmt.Println(a+b>=c && !(b>c))
}
五、流程控制
顺序结构:程序按顺序执行,不发生跳转。
选择结构:我们也称为判断结构,依据是否满足条件,有选择的执行相应功能。
循环结构:依据条件是否满足,循环多次执行某段代码。
5.1、if结构
在编程中实现选择判断结构就是用if
if结构基本语法
if 条件判断{
代码语句
}
/* 使用 if 语句判断布尔表达式 */
if a < 20 {
/* 如果条件为 true 则执行以下语句 */
fmt.Printf("a 小于 20\n" )
}
if —else—结构
if 条件判断{
代码语句1
}else{
代码语句2
关于if-else结构的嵌套
if-else if 结构
if 条件判断{
要执行的代码段
}else if 条件判断{
要执行的代码段
}
……
else{
}
5.2、switch结构
switch 变量或者表达式的值{
case 值1:
要执行的代码
case 值2:
要执行的代码
case 值3:
要执行的代码
……
default:
要执行的代码
}
# 例如:
var marks int = 90
switch marks {
case 90: grade = "A"
case 80: grade = "B"
case 50,60,70 : grade = "C"
default: grade = "D"
}
Go里面switch默认相当于每个case最后带有break,匹配成功后不会自动向下执行其他case,而是跳出整个switch, 但是可以使用fallthrough强制执行下一个的case代码,fallthrough不会判断下一条case的expr结果是否为true。
参考:类型判断:type-switch
switch 语句还可以被用于 type-switch 来判断某个 interface 变量中实际存储的变量类型。
switch x.(type){
case type:
statement(s);
case type:
statement(s);
/* 你可以定义任意个数的case */
default: /* 可选 */
statement(s);
}
var x interface{}
switch i := x.(type) {
case nil:
fmt.Printf(" x 的类型 :%T",i)
case int:
fmt.Printf("x 是 int 型")
case float64:
fmt.Printf("x 是 float64 型")
case func(int) float64:
fmt.Printf("x 是 func(int) 型")
case bool, string:
fmt.Printf("x 是 bool 或 string 型" )
default:
fmt.Printf("未知型")
}
5.3 select 语句
select {
case <- channel1:
// 执行的代码
case value := <- channel2:
// 执行的代码
case channel3 <- value:
// 执行的代码
// 你可以定义任意数量的 case
default:
// 所有通道都没有准备好,执行的代码
}
- 每个 case 都必须是一个通道,要么是发送要么是接收
- 所有 channel 表达式都会被求值
- 所有被发送的表达式都会被求值
- 如果任意某个通道可以进行,它就执行,其他被忽略。
- 如果有多个 case 都可以运行,select 会随机公平地选出一个执行,其他不会执行。
- 否则:
- 如果有 default 子句,则执行该语句。
- 如果没有 default 子句,select 将阻塞,直到某个通道可以运行;Go 不会重新对 channel 或值进行求值。
5.4 循环结构
在GO语言中,我们有专门实现这种循环的结构就是for结构(GO语言中只有for循环结构,没有while,do-while结构),基本语法结构如下:
for 表达式1;表达式2;表达式3{
循环体
}
表达式1:定义一个循环的变量,记录循环的次数
表达式2:一般为循环条件,循环多少次
表达式3:一般为改变循环条件的代码,使循环条件终有一天不再成立
死循环指的就是一直循环,跳不出来了
for{
println("hello")
}
range关键字
GO的range具体使用
Go 语言中 range 关键字用于 for 循环中迭代数组(array)、切片(slice)、通道(channel)或集合/哈希表(map)、字符串中的元素。在数组和切片中它返回元素的索引和索引对应的值,在集合中返回 key-value 对。
for…range 的数据是如何传递的?
数据都是通过复制传递的,也就是都是值传递的,
如果你只需要索引,你可以忽略第二个变量
// key, value 这两个都是仅 `for` 循环内部可见的局部变量
// 格式
for key, value := range oldMap {
newMap[key] = value
}
// 以上代码中的 key 和 value 是可以省略。
// 如果只想读取 key,格式如下:
for key := range oldMap
// 或者
for key, _ := range oldMap
// 如果只想读取 value,格式如下:
for _, value := range oldMap
seasons := []string{"Spring", "Summer", "Autumn", "Winter"}
for ix := range seasons {
fmt.Printf("%d", ix)
}
// Output: 0 1 2 3
//range也可以用来枚举 Unicode 字符串。第一个参数是字符的索引,第二个是字符(Unicode的值)本身。
for i, c := range "go" {
fmt.Println(i, c)
}
// 0 103
// 1 111
map 类型
Map 是一种无序的键值对的集合。
5.5 跳转语句
关于GO语句中的跳转语句,有break, continue, goto(与函数结合使用)
break的作用就是跳出(本层)循环
continue 结束本次循环,继续下次循环
for row := range screen {
for column := range screen[row] {
screen[row][column] = 1
}
}
六、函数
6.1、函数定义
函数就是将一堆代码进行重用的一种机制。
func function_name( [parameter list] ) [return_types] {
函数体
}
通过func关键字来定义函数,函数名后面必须加括号。
一般都会将相同要求,相同功能的代码放在一个函数中,也就是基本上每一个函数都是实现单独的功能。(函数的功能一定要单一),这也是定义函数的基本原则
给函数传递参数分为两种情况:第一种情况为普通参数列表,第二种情况为不定参数列表
6.2、普通参数列表
所谓的普通参数列表指的是,我们给函数传递的参数的个数都是确定好
但是一定要注意:在定义函数时,形参与实参的个数与类型都要保持一致。
6.3、不定参数列表
func Test(args ...int) {
for i := 0; i < len(args); i++ {
println(args[i])
}
}
func Test02(args ...int) {
for i, data := range args {
println("编号为:", i)
println("值为:", data)
}
}
range会从集合中返回两个数,第一个是对应的坐标,赋值给了变量i,第二个就是对应的值,赋值了变量data
当然在使用不定参数时,要注意几个问题:
第一:一定(只能)放在形参中的最后一个参数。
第二:在对函数进行调用时,固定参数必须传值,不定参数可以根据需要来决定是否要传值。
6.4、函数嵌套调用
- 基本函数嵌套调用
函数也可以像我们在前面学习if选择结构,for循环结构一样进行嵌套使用。所谓函数的嵌套使用,其实就是在一个函数中调用另外的函数。 - 不定参数函数调用
不定参数的函数在调用的时候,要注意一些细节问题。
func Test01(args ...int) {
Test02(args...)
}
Test02(args…)表示将参数全部传递
如果我们只想传递一部分数据,而不是传递所有的数据,应该怎样进行传递呢?
func Test01(args ...int) {
Test02(args[2:]...)
}
将编号为2(包含2)及以后的数据全部传递,从0开始计算
func Test01(args ...int) {
Test02(args[0:2]...)
}
将编号为0到2(不包含2)之间的数据全部传递
6.5、返回值
6.5.1、返回一个值
//在定义函数Sum时,后面加了int, 表示该函数最终返回的是一个整型的数据
func Sum() int {
var sum1 = 5
var sum2 = 7
sum := sum1 + sum2
return sum
}
另一种语法:给返回值命名
对Golang函数的返回值参数进行命名,相当于在函数的内部首先就定义了变量作为返回值,并将其初始化为零值。
func Sum() (sum int) {
var sum1 = 5
var sum2 = 7
sum = sum1 + sum2
return
}
func Sum() (sum int) {
var sum1 = 5
var sum2 = 7
sum = sum1 + sum2
return sum
}
6.5.2、返回多个值
func Test03() (a, b, c int) {
a, b, c = 1, 2, 3
return a, b, c
}
6.6、函数类型
在GO语言中还有另外一种定义使用函数的方式,就是函数类型,所谓的函数类型就是将函数作为一种类型可以用来定义变量
func Test04(a int, b int) (sum int) {
sum = a + b
return
}
type funcType func(int, int) int
func main() {
var result funcType
result = Test04
println(result(2, 3))
}
主要用在面向对象编程
6.7、函数作用域
1)局部变量
我们把定义在函数内部的变量称为局部变量。
局部变量的作用,为了临时保存数据需要在函数中定义变量来进行存储,这就是它的作用。
不同的函数,可以定义相同的名字的局部变量,但是各用个的不会产生影响
2)全局变量
所谓的全局变量: 既能在一个函数中使用,也能在其他的函数中使用,这样的变量就是全局变量. 也就是定义在函数外部的变量就是全局变量。全局变量在任何的地方都可以使用。
当全局变量与局部变量名称一致时,局部变量的优先级要高于全局变量
注意:大家以后在开发中,尽量不要让全局变量的名字与局部变量的名字一样。
6.8、匿名函数与闭包
匿名函数
前面我们定义函数的时候,发现是不能在一个函数中,再次定义一个函数。如果我们想在一个函数中再定义一个函数,那么可以使用匿名函数,所谓匿名函数就是没有名字的函数。
匿名函数或lambda函数是未绑定到标识符的函数定义
func(){ 函数体 }
func main() {
sum := 9
f := func() {
sum++
fmt.Println("匿名函数:", sum) //10
}
f()
fmt.Println("main函数:", sum) //10
}
在这里,有一件非常有意思的事情,就是在匿名函数中可以直接访问main( )函数中定义的局部变量,并且在匿名函数中对变量的值进行了修改,最终会影响到整个main( )函数中定义的变量的值。所以上面两行输入都是10.
// 定义匿名函数时,直接调用
func main() {
sum := 9
func() {
sum++
fmt.Println("匿名函数:", sum)
}()
fmt.Println("main函数:", sum)
}
该方式,需要在匿名函数的末尾加上小括号,表示调用。同时也不需要将定义好的匿名函数赋值给某个变量。
闭包
所谓的闭包是指有权访问另一个函数作用域中的变量的函数,就是在一个函数内部创建另一个函数。
在Go语言里,所有的匿名函数(Go语言规范中称之为函数字面量)都是闭包(closure)。
func Test05() func() int {
var x int
return func() int {
x++
return x
}
}
func main() {
f := Test05()
println(f()) // 1
println(f()) // 2
println(f()) // 3
fmt.Println(test05()()) // 1
fmt.Println(test05()()) // 1
fmt.Println(test05()()) // 1
}
因为匿名函数(闭包),有一个很重要的特点:
它不关心这些捕获了的变量和常量是否已经超出了作用域,所以只要有闭包还在使用它,这些变量就还会存在。
闭包的作用就是简化了主程序和匿名函数之间变量交换,参数传递的过程,不需要额外定义变量,直接传。容易导致变量得不到释放,因为闭包函数会延长变量的生命周期。
6.9、延迟调用defer
1)defer基本使用
函数定义完成后,只有调用函数才能够执行,并且一经调用立即执行。
defer 语句是Go提供的语法糖,可以指定某个函数或语句在当前函数执行完毕后调用,不管是return正常结束还是panic导致的异常结束。(为什么要在返回之后才执行这些语句?因为 return 语句同样可以包含一些操作,而不是单纯地返回某个值)。在需要释放资源的时候,使用defer非常有用。
关键字 defer 的用法类似于面向对象编程语言 Java 和 C# 的 finally 语句块,它一般用于释放某些已分配的资源。(文件关闭函数, 网络编程时,最后也要关闭整个网络的链接)
注意,defer语句只能出现在函数的内部
2)defer执行顺序
如果一个函数中有多个defer语句,它们会以逆序执行(类似栈,即后进先出)
即使函数或某个延迟调用发生错误,这些调用依旧会被执行。
3)defer与匿名函数结合使用
程序执行到匿名函数时,虽然没有立即调用执行匿名函数,但是已经完成了参数的传递
func f1() (r int)
// r = 2 // 这行代码有与没有结果都为1
defer func() {
r++
}()
r = 0
return
}
func main() {
i := f1()
fmt.Println(i) // 1
}
Go语言defer用法大总结(含return返回机制)
6.10、递归函数
如果一个函数在内部不调用其它的函数,而是自己本身的话,这个函数就是递归函数。
递归函数的作用:
举个例子,我们来计算阶乘 n! = 1 * 2 * 3 * … * n
其它应用场景:
电商网站中的商品类别菜单的应用。
查找某个磁盘下的文件
七、数组
声明的格式是:
var identifier [len]type
如:
var arr1 [5]int
数组是具有相同 唯一类型 的一组已编号且长度固定的数据项序列(这是一种同构的数据结构);这种类型可以是任意的原始类型例如整型、字符串或者自定义类型。数组长度必须是一个常量表达式,并且必须是一个非负整数。数组长度也是数组类型的一部分,所以 [5]int 和 [10]int 是属于不同类型的
注意事项: 如果我们想让数组元素类型为任意类型的话可以使用空接口作为类型。当使用值时我们必须先做一个类型判断
数组元素可以通过 索引(位置)来读取(或者修改),索引从 0 开始,第一个元素索引为 0,第二个索引为 1,以此类推(数组以 0 开始在所有类 C 语言中是相似的)。
元素的数目(也称为长度或者数组大小)必须是固定的并且在声明该数组时就给出(编译时需要知道数组长度以便分配内存);数组大小最大为 2GB
Go 语言中的数组是一种 值类型,可以通过 new() 来创建: var arr1 = new([5]int)。
那么这种方式和 var arr2 [5]int 的区别是什么呢?arr1 的类型是 *[5]int,而 arr2 的类型是 [5]int。
var arr1 = new([5]int)
var arr2 [5]int
arr2 = *arr1 // 完成一次值拷贝
arr2[2] = 100
fmt.Println(arr1) // &[0 0 0 0 0]
fmt.Println(arr2) // [0 0 100 0 0]
数组作为函数参数传递
在函数中数组作为参数传入时,如 func1(arr2),会产生一次数组拷贝,func1() 方法不会修改原始的数组 arr2。
如果你想修改原数组,那么 arr2 必须通过 & 操作符以引用方式传过来,例如 func1(&arr2)
另一种方法就是生成数组切片并将其传递给函数,这种方式也会改变原来的数组,是引用方式传递
7.1 数组常量
如果数组值已经提前知道了,那么可以通过 数组常量 的方法来初始化数组。
var arrAge = [5]int{18, 20, 15, 22, 16}
c := [4]int{5, 3: 10} // 可指定索引位置初始化
var arrLazy = [...]int{5, 6, 7, 8, 22} // 编译器按初始值数量确定数组长度
e := [...]int{10, 3: 100} // 支持索引初始化,但注意数组长度与此有关
var arrLazy = []int{5, 6, 7, 8, 22} //注:初始化得到的实际上是切片slice
var arrKeyValue = [5]string{3: "Chris", 4: "Ron"}
var arrKeyValue = []string{3: "Chris", 4: "Ron"} //注:初始化得到的实际上是切片slice
for i:=0; i < len(arrKeyValue); i++ {
fmt.Printf("Person at %d is %s\n", i, arrKeyValue[i])
}
7.2 多维数组
数组通常是一维的,但是可以用来组装成多维数组,例如:[3][5]int,[2][2][2]float64。
内部数组总是长度相同的。
对于多维数组定义中,仅第一维度允许使用...
b := [...][2]int{ // 二维数组
{10, 20},
{30, 40},
}
c := [...][2][2]int{ // 三维数组
{
{1, 2},
{3, 4},
},
{
{10, 20},
{30, 40},
},
}
八、切片
runtime.hstruct Slice{
byte* array; // actual data
uintgo len; // number of elements
uintgo cap; // allocated number of elements
};
在64位机器上一个切片需要24字节:指针字段8字节,长度字段8字节,容量字段8字节
声明切片的格式是:
var identifier []type // 不需要说明长度
一个切片在未初始化之前默认为 nil,长度为 0
切片的初始化格式是:
var slice1 []type = arr1[start:end] // `start:end` 被称为切片表达式
切片 (slice) 是对数组一个连续片段的引用(该数组我们称之为相关数组,通常是匿名的),所以切片是一个引用类型,它本身就是一个指针!!
这个片段可以是整个数组,或者是由起始和终止索引标识的一些项的子集。终止索引标识的项不包括在切片内
var slice1 []type = arr1[:] // slice1 就等于完整的 arr1 数组
// 等价于 arr1[0:len(arr1)]
// 等价于 slice1 = &arr1
-
arr1[2:]和arr1[2:len(arr1)]相同,都包含了数组从第三个到最后的所有元素。
arr1[:3]和arr1[0:3]相同,包含了从第一个到第三个元素(不包括第四个) -
如果你想去掉
slice1的最后一个元素,只要slice1 = slice1[:len(slice1)-1]。
一个由数字 1、2、3 组成的切片可以这么生成:s := [3]int{1,2,3}[:]或s := []int{1,2,3} -
s2 := s[:]是用切片组成的切片,拥有相同的元素,但是仍然指向相同的相关数组。 -
一个切片
s可以这样扩展到它的大小上限:s = s[:cap(s)]
切片不能被重新分片以获取数组的前一个元素。
对于每一个切片(包括 string),以下状态总是成立的:
s == s[:i] + s[i:] // i是一个整数且: 0 <= i <= len(s)
len(s) <= cap(s)
切片在内存中的组织方式实际上是一个有 3 个域的结构体:指向相关数组的指针,切片长度以及切片容量
8.1 长度
切片是可索引的,并且可以由 len() 函数获取长度: end - start
切片的长度可以在运行时修改,最小为 0, 最大为相关数组的长度:切片是一个 长度可变的数组。
8.2 容量
计算容量的函数 cap() :它等于从切片第一个元素开始,切片的长度 + 数组除切片之外的长度。如果 s 是一个切片,cap(s) 就是从 s[0] 到数组末尾的数组长度。0 <= len(s) <= cap(s)
一个切片和相关数组的其他切片是共享存储的
8.3 将切片传递给函数
如果你有一个函数需要对数组做操作,你可能总是需要把参数声明为切片。
func add(arr []int) int {
sum := 0
for _, data := range arr {
sum += data
}
return sum
}
i2 := add(arr1[:]) //调用
8.4 用 make() 创建一个切片
当相关数组还没有定义时,我们可以使用 make() 函数来创建一个切片,同时创建好相关数组
var slice1 []type = make([]type, len)
也可以简写为 slice1 := make([]type, len)
len 是数组的长度并且也是 slice 的初始长度。
make() 接受 2 个参数:元素的类型以及切片的元素个数。
如果你想创建一个 slice1,它不占用整个数组,而只是占用以 len 为个数个项,那么只要:slice1 := make([]type, len, cap)。
字符串是纯粹不可变的字节数组,它们也可以被切分成切片
var str1 string = "我是中国人"
slice1 := str1[3:6]
fmt.Println(slice1) // 是
2. make()函数
内置的make函数只分配和初始化slice、map或chan类型的对象。与new一样,第一个参数是类型,而不是值。
make() 的使用方式是:
func make([]T, len, cap) // 其中 cap 是可选参数。
new() 和 make() 的区别
但是它们的行为不同,适用于不同的类型。
new(T)为每个新的类型T分配一片内存,初始化为0并且返回类型为*T的内存地址:这种方法 返回一个指向类型为T,值为0的地址的指针,它适用于值类型如数组和结构体;它相当于&T{}。make(T)返回一个类型为 T 的初始值,它只适用于 3 种内建的引用类型:切片、map和channel。
new() 函数分配内存,make() 函数初始化
make() 的三种类型:
slices / maps / channels
使用逃逸分析后,如果编译器发现这个变量在该函数结束后不会再调用了,就会把这个变量分配到栈上,毕竟使用栈速度快、不会产生内存碎片。如果编译器发现某个变量在函数之外还有其他地方要引用,那么就把这个变量分配到堆上。
为什么不将变量全部分配到堆空间上呢?像C那样不是也挺好的吗?
这是因为堆不能像栈那样函数一结束就自动清理,会导致GC频繁工作,而通过逃逸分析,我们可以尽可能把变量分配到栈上,可以减少内存碎片,减少GC回收的时间,所以逃逸分析是Go用来减少GC压力的一个技巧。
8.5 多维切片
Go 语言的多维切片可以任意切分。而且,内层的切片必须单独分配(通过 make() 函数)。
bytes 包
类型 []byte 的切片十分常见,Go 语言有一个 bytes 包专门用来提供这种类型的操作方法。
十分有用的类型 Buffer
Buffer 可以这样定义:
var buffer bytes.Buffer
或者使用 new() 获得一个指针:var r *bytes.Buffer = new(bytes.Buffer)。
或者通过函数:func NewBuffer(buf []byte) *Buffer,创建一个 Buffer 对象并且用 buf 初始化好;NewBuffer 最好用在从 buf 读取的时候使用。
通过 buffer 串联字符串
buffer.WriteString(s) 方法将字符串 s 追加到后面,最后再通过 buffer.String() 方法转换为 string:
8.6 切片重组 (reslice)
改变切片长度的过程称之为切片重组 reslicing,做法如下:slice1 = slice1[0:end],其中 end 是新的末尾索引(即长度)
将切片扩展 1 位可以这么做:
sl = sl[0:len(sl)+1]
切片可以反复扩展直到占据整个相关数组。
8.7 切片的复制与追加
如果想增加切片的容量,我们必须创建一个新的更大的切片并把原分片的内容都拷贝过来。
slFrom := []int{1, 2, 3}
slTo := make([]int, 10)
n := copy(slTo, slFrom)
fmt.Println(slTo)
fmt.Printf("Copied %d elements\n", n) // n == 3
sl3 := []int{1, 2, 3}
sl3 = append(sl3, 4, 5, 6)
fmt.Println(sl3)
内建函数
1. copy()
func copy(dst []Type, src []Type) int
将类型为 Type 的切片从源地址 src 拷贝到目标地址 dst,覆盖 dst 的相关元素,并且返回拷贝的元素个数。
源地址和目标地址可能会有重叠。拷贝个数是 src 和 dst 的长度最小值。
如果 src 是字符串那么元素类型就是 byte
3. append()
func append(s[]T, x ...T) []T
append() 方法将 0 个或多个具有相同类型 s 的元素追加到切片后面并且返回新的切片;追加的元素必须和原切片的元素是同类型。
如果 s 的容量不足以存储新增元素,append() 会分配新的切片来保证已有切片元素和新增元素的存储。
返回值
返回的切片可能已经指向一个不同的相关数组了。append() 方法总是返回成功,除非系统内存耗尽了。
九、Map
需要提醒你关于 golang 中 map 使用的几点注意事项
Go语言中的 map 在并发情况下,只读是线程安全的,同时读写是线程不安全的。同一个变量在多个goroutine中访问需要保证其安全性。
map 是一种特殊的数据结构:一种元素对 (pair) 的无序集合,也称为关联数组或字典
map 这种数据结构在其他编程语言中也称为字典 (Python) 、hash 和 HashTable 等。
在Go语言中,map[key]函数返回结果可以是一个值,也可以是两个值。
map 是引用类型,未初始化的 map 的值是 nil。
var map1 map[keytype]valuetype
key 可以是任意可以用 == 或者 != 操作符比较的类型,比如 string、int、float32(64),但是指针和接口类型也可以。数组、切片和结构体不能作为 key (译者注:含有数组切片的结构体不能作为 key,只包含内建类型的 struct 是可以作为 key 的),如果要用结构体作为 key 可以提供 Key() 和 Hash() 方法,这样可以通过结构体的域计算出唯一的数字或者字符串的 key。
golang 哪些类型可以作为map key
value 可以是任意类型的;通过使用空接口类型,我们可以存储任意值,但是使用这种类型作为值时需要先做一次类型断言。
map 也可以用函数作为自己的值,这样就可以用来做分支结构:key 用来选择要执行的函数。
取值:
如果 key1 是 map1 的 key,那么 map1[key1] 就是对应 key1 的值
赋值:
map1[key1] = val1。
令 v := map1[key1] 可以将 key1 对应的值赋值给 v;如果 map 中没有 key1 存在,那么 v 将被赋值为 map1 的值类型的空值。
注意 map 不是按照 key 的顺序排列的,也不是按照 value 的序排列的。
map 的本质是散列表,而 map 的增长扩容会导致重新进行散列,这就可能使 map 的遍历结果在扩容前后变得不可靠,Go 设计者为了让大家不依赖遍历的顺序,每次遍历的起点–即起始 bucket 的位置不一样,即不让遍历都从某个固定的 bucket0 开始,所以即使未扩容时我们遍历出来的 map 也总是无序的。
9.1 map长度
len(map1) 方法可以获得 map 中的 pair 数目
func main() {
var mapLit map[string]int
var mapAssigned map[string]int
mapLit = map[string]int{"one": 1, "two": 2} // 字面量初始化
mapCreated := make(map[string]float32) // 使用make()创建
// `mapAssigned` 也是 `mapLit` 的引用,对 `mapAssigned` 的修改也会影响到 `mapLit` 的值
mapAssigned = mapLit
mapCreated["key1"] = 4.5
mapCreated["key2"] = 3.14159
mapAssigned["two"] = 3
fmt.Printf("Map literal at \"one\" is: %d\n", mapLit["one"]) // 1
fmt.Printf("Map created at \"key2\" is: %f\n", mapCreated["key2"]) // 3.14159
fmt.Printf("Map assigned at \"two\" is: %d\n", mapLit["two"]) // 3
fmt.Printf("Map literal at \"ten\" is: %d\n", mapLit["ten"]) // 0
}
make()创建:
var map1 = make(map[keytype]valuetype)
不要使用
new(),永远用make()来构造map
Golang中的println与fmt.Prinltn的区别与输出顺序问题
在[http://golang.org/ref/spec#Bootstrapping]中的文档中,对于内置的输出函数print与println等有如下描述
Current implementations provide several built-in functions useful during bootstrapping. These functions are documented for completeness but are not guaranteed to stay in the language. They do not return a result.
fmt中的fmt.Println()是默认输出到stdout(standard output)的,而println是输出到stderr(standard error),因此在IDE中看到的结果顺序是并不是预期的顺序。
9.2 map 容量
和数组不同,map 可以根据新增的 key-value 对动态的伸缩,因此它不存在固定长度或者最大限制。但是你也可以选择标明 map 的初始容量 capacity,
make(map[keytype]valuetype, cap)
所以出于性能的考虑,对于大的 map 或者会快速扩张的 map,即使只是大概知道容量,也最好先标明。
9.3 用切片作为 map 的值
如果一个 key 要对应多个值怎么办?例如,当我们要处理 Unix 机器上的所有进程,以父进程(pid 为整型)作为 key,所有的子进程(以所有子进程的 pid 组成的切片)作为 value。通过将 value 定义为 []int 类型或者其他类型的切片,就可以优雅地解决这个问题。
mp1 := make(map[int][]int)
mp2 := make(map[int]*[]int)
9.4 测试键值对是否存在及删除元素
键值对是否存在
val1, isPresent = map1[key1]
isPresent 返回一个 bool 值:如果 key1 存在于 map1,val1 就是 key1 对应的 value 值,并且 isPresent 为 true;如果 key1 不存在,val1 就是一个空值,并且 isPresent 会返回 false。
_, ok := map1[key1] // 如果key1存在则ok == true,否则ok为false
或者:
if _, ok := map1[key1]; ok {
// ...
}
删除
从 map1 中删除 key1:
直接 delete(map1, key1) 就可以。
如果 key1 不存在,该操作不会产生错误。
9.5 map 类型的切片
假设我们想获取一个 map 类型的切片,我们必须使用两次 make() 函数,第一次分配切片,第二次分配切片中每个 map 元素
// Version A:
items := make([]map[int]int, 5)
for i:= range items {
items[i] = make(map[int]int, 1)
items[i][1] = 2
}
// [map[1:2] map[1:2] map[1:2] map[1:2] map[1:2]]
fmt.Printf("Version A: Value of items: %v\n", items)
// Version B: NOT GOOD!
items2 := make([]map[int]int, 5)
for _, item := range items2 {
item = make(map[int]int, 1) // item is only a copy of the slice element.
item[1] = 2 // This 'item' will be lost on the next iteration.
}
// [map[] map[] map[] map[] map[]]
fmt.Printf("Version B: Value of items: %v\n", items2)
需要注意的是,应当像 A 版本那样通过索引使用切片的 map 元素。在 B 版本中获得的项只是 map 值的一个拷贝而已,所以真正的 map 元素没有得到初始化。
9.6 map 的排序
map 默认是无序的,
如果你想为 map 排序,需要将 key(或者 value)拷贝到一个切片,再对切片排序(使用 sort 包),然后可以使用切片的 for-range 方法打印出所有的 key 和 value。
但是如果你想要一个排序的列表,那么最好使用结构体切片,这样会更有效:
type name struct {
key string
value int
}
9.7 将 map 的键值对调
这里对调是指调换 key 和 value。如果 map 的值类型可以作为 key 且所有的 value 是唯一的,那么通过下面的方法可以简单的做到键值对调。
// 对调 map[string]int
invMap := make(map[int]string, len(barVal))
for k, v := range barVal {
invMap[v] = k
}
十、结构 (struct) 与方法 (method)
Go 通过类型别名 (alias types) 和结构体的形式支持用户自定义类型,或者叫定制类型。一个带属性的结构体试图表示一个现实世界中的实体。
结构体也是值类型,因此可以通过 new 函数来创建。
结构体是复合类型 (composite types)
组成结构体类型的那些数据称为 字段 (fields)。每个字段都有一个类型和一个名字;在一个结构体中,字段名字必须是唯一的。
因为 Go 语言中没有类的概念,因此在 Go 中结构体有着更为重要的地位。
10.1 结构体定义
type identifier struct {
field1 type1
field2 type2
...
}
结构体里的字段都有 名字,像 field1、field2 等,如果字段在代码中从来也不会被用到,那么可以命名它为 _。
结构体的字段可以是任何类型,甚至是结构体本身,也可以是函数或者接口
结构体导出性
如果结构体名称首字母小写,则结构体不会被导出。这时,即使结构体成员字段名首字母大写,也不会被导出。
如果结构体名称首字母大写,则结构体可被导出,但只会导出大写首字母的成员字段,那些小写首字母的成员字段不会被导出。
10.2 创建
使用 new() 函数给一个新的结构体变量分配内存,它返回指向已分配内存的指针:var t *T = new(T)
var t *T
t = new(T) // 此时结构体字段的值是它们所属类型的零值
声明 var t T 也会给 t 分配内存,并零值化内存,但是这个时候 t 是类型 T 。在这两种方式中,t 通常被称做类型 T 的一个实例 (instance) 或对象 (object)。
10.3 初始化一个结构体实例
1) 结构体字面量:struct-literal
type struct1 struct {
i1 int
f1 float32
str string
}
ms := &struct1{10, 15.5, "Chris"}
// 此时 ms 的类型是 *struct1
var ms struct1
ms = struct1{10, 15.5, "Chris"}
混合字面量语法 (composite literal syntax) &struct1{a, b, c} 是一种简写,底层仍然会调用 new(),这里值的顺序必须按照字段顺序来写。
表达式 new(Type) 和 &Type{} 是等价的。
放上字段名来初始化字段
type Interval struct {
start int
end int
}
intr := Interval{0, 3} (A)
intr := Interval{end:5, start:1} (B)
intr := Interval{end:5} (C)
结构体类型和字段的命名遵循可见性规则
类型 struct1 在定义它的包 pack1 中必须是唯一的,它的完全类型名是:pack1.struct1。
Go 语言中,结构体和它所包含的数据在内存中是以连续块的形式存在的,即使结构体中嵌套有其他的结构体
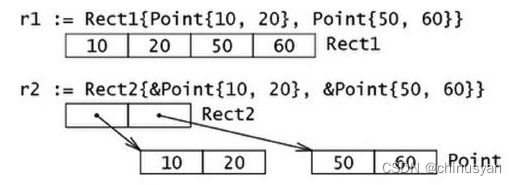
10.4 字段的访问与赋值
var s T // T 是结构体类型
s.a = 5
s.b = 8
使用点号符给字段赋值:
structname.fieldname = value
同样的,使用点号符可以获取结构体字段的值:structname.fieldname。
在 Go 语言中这叫 选择器 (selector)。无论变量是一个结构体类型还是一个结构体类型指针,都使用同样的 选择器符 (selector-notation) 来引用结构体的字段:
type myStruct struct { i int }
var v myStruct // v 是结构体类型变量
var p *myStruct // p 是指向一个结构体类型变量的指针
v.i
p.i
数组可以看作是一种结构体类型,不过它使用下标而不是具名的字段。
pers2 := new(Person)
pers2.firstName = "Chris"
pers2.lastName = "Woodward"
(*pers2).lastName = "Woodward" // 这是合法的
可以直接通过指针,像 pers2.lastName = "Woodward" 这样给结构体字段赋值,没有像 C++ 中那样需要使用 -> 操作符,Go 会自动做这样的转换。
注意也可以通过解指针的方式来设置值:(*pers2).lastName = "Woodward"
10.5 递归结构体
结构体类型可以通过引用自身来定义。
如:定义链表或二叉树的元素(通常叫节点)
链表:

type Node struct {
data float64
su *Node
}
双向链表
type Node struct {
pr *Node
data float32
su *Node
}
二叉树:
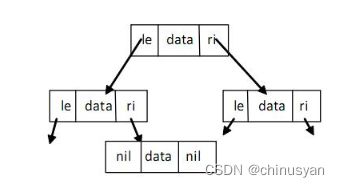
type Tree struct {
le *Tree
data float32
ri *Tree
}
10.6 结构体转换
Go 中的类型转换遵循严格的规则。当为结构体定义了一个 alias 类型时,此结构体类型和它的 alias 类型都有相同的底层类型,但属于不同的类型
type number struct {
f float32
}
type nr number // alias type
func main() {
a := number{5.0}
b := nr{5.0}
// var i float32 = b // compile-error: cannot use b (type nr) as type float32 in assignment
// var i float32 = float32(b) // compile-error: cannot convert b (type nr) to type float32
// var c number = b // compile-error: cannot use b (type nr) as type number in assignment
// needs a conversion:
var c = number(b)
fmt.Println(a, b, c)
}
10.7 结构体工厂
Go 语言不支持面向对象编程语言中那样的构造子方法
工厂的名字以 new... 或 New... 开头
type File struct {
fd int // 文件描述符
name string // 文件名
}
// 结构体类型对应的工厂方法,它返回一个指向结构体实例的指针
func NewFile(fd int, name string) *File {
if fd < 0 {
return nil
}
return &File{fd, name}
}
在 Go 语言中常常像上面这样在工厂方法里使用初始化来简便的实现构造函数。
我们可以说是工厂实例化了类型的一个对象
如果 File 是一个结构体类型,那么表达式 new(File) 和 &File{} 是等价的。
如果想知道结构体类型 T 的一个实例占用了多少内存,可以使用:size := unsafe.Sizeof(T{})。返回的是字节数
强制使用工厂方法
type matrix struct {
...
}
func NewMatrix(params) *matrix {
m := new(matrix) // 初始化 m
return m
}
map 和 struct 比较
new 可以创建 struct 类型,不可以创建 map
make 不可以创建 struct 类型, 可以创建 map
type Foo map[string]string
u := new(Foo) // u 是一个空指针
(*u)["x"] = "goodbye" // 运行时错误!! panic: assignment to entry in nil map
(*u)["y"] = "world"
10.8 带标签的结构体
结构体中的字段除了有名字和类型外,还可以有一个可选的标签 (tag):它是一个附属于字段的字符串,可以是文档或其他的重要标记。标签的内容不可以在一般的编程中使用,只有包 reflect 能获取它。
type TagType struct { // tags
field1 bool "An important answer"
field2 string "The name of the thing"
field3 int "How much there are"
}
func main() {
tt := TagType{true, "Barak Obama", 1}
for i := 0; i < 3; i++ {
refTag(tt, i)
}
}
func refTag(tt TagType, ix int) {
ttType := reflect.TypeOf(tt)
ixField := ttType.Field(ix)
fmt.Printf("%v\n", ixField.Tag)
}
输出结果:
An important answer
The name of the thing
How much there are
10.9 匿名字段和内嵌结构体
结构体可以包含一个或多个 匿名(或内嵌)字段,即这些字段没有显式的名字,只有字段的类型是必须的,此时类型就是字段的名字。匿名字段本身可以是一个结构体类型,即 结构体可以包含内嵌结构体。
Go 语言中的继承是通过内嵌或组合来实现的,所以可以说,在 Go 语言中,相比较于继承,组合更受青睐。
在一个结构体中对于每一种数据类型只能有一个匿名字段。
type innerS struct {
i1 int
f2 int
}
type TagType struct {
Field1 bool "an important answer"
field2 string "the name of thing"
int "how much there are"
innerS
}
func main() {
tt := TagType{}
tt.Field1 = true
tt.field2 = "field2"
tt.int = 100
tt.i1 = 200
tt.f2 = 300
fmt.Printf("%+v\n", tt)
}
// {Field1:true field2:field2 int:100 innerS:{i1:200 f2:300}}
}
外层结构体通过 tt.int 直接进入内层结构体的字段,内嵌结构体甚至可以来自其他包。
这个简单的“继承”机制提供了一种方式,使得可以从另外一个或一些类型继承部分或全部实现。
命名冲突
当两个字段拥有相同的名字(可能是继承来的名字)时该怎么办呢?
- 外层名字会覆盖内层(即内嵌结构体)名字(但是两者的内存空间都保留),这提供了一种重载字段或方法的方式;
- 如果相同的名字在同一级别出现了两次,如果这个名字被程序使用了,将会引发一个错误(不使用没关系)。没有办法来解决这种问题引起的二义性,必须由程序员自己修正。
type A struct {
a int
}
type B struct {
a int
b int
}
type C struct {
b float32
A
B
}
func main() {
var c C = C{b: 10}
fmt.Println(c.b) // 10
fmt.Println(c.B.b) //0
fmt.Println(c.a) // 错误:ambiguous selector c.a
}
10.10 方法
定义方法的一般格式如下:
// 在方法名之前,func 关键字之后的括号中指定 receiver
func (recv receiver_type) methodName(parameter_list) (return_value_list) { ... }
recv 就像是面向对象语言中的 this 或 self
如果 recv 是 receiver 的实例,Method1 是它的方法名,那么方法调用遵循传统的 object.name 选择器符号:recv.Method1()。
如果 recv 是一个指针,Go 会自动解引用。
如果方法不需要使用 recv 的值,可以用 _ 替换它,比如:
func (_ receiver_type) methodName(parameter_list) (return_value_list) { ... }
recv 就像是面向对象语言中的 this 或 self,但是 Go 中并没有这两个关键字。随个人喜好,你可以使用 this 或 self 作为 receiver 的名字。
在 Go 语言中,结构体就像是类的一种简化形式。
在 Go 中有一个概念,方法:Go 方法是作用在接收者 (receiver) 上的一个函数,接收者是某种类型的变量。因此方法是一种特殊类型的函数。
接收者类型可以是(几乎)任何类型,不仅仅是结构体类型:任何类型都可以有方法,甚至可以是函数类型,可以是 int、bool、string 或数组的别名类型。
但是接收者不能是一个接口类型,
最后接收者不能是一个指针类型,但是它可以是任何其他允许类型的指针。
一个类型加上它的方法等价于面向对象中的一个类。一个重要的区别是:在 Go 中,类型的代码和绑定在它上面的方法的代码可以不放置在一起,它们可以存在在不同的源文件,唯一的要求是:它们必须是同一个包的。
类型 T(或 *T)上的所有方法的集合叫做类型 T(或 *T)的方法集 (method set)。
因为方法是函数,所以同样的,不允许方法重载,即对于一个类型只能有一个给定名称的方法。但是如果基于接收者类型,是有重载的。
func (a *denseMatrix) Add(b Matrix) Matrix
func (a *sparseMatrix) Add(b Matrix) Matrix
别名类型没有原始类型上已经定义过的方法。
类型和作用在它上面定义的方法必须在同一个包里定义,这就是为什么不能在 int、float32(64) 或类似这些的类型上定义方法。
但是有一个间接的方式:可以先定义该类型(比如:int 或 float32(64))的别名类型,然后再为别名类型定义方法。比如将它作为匿名类型嵌入在一个新的结构体中。
函数和方法的区别
函数将变量作为参数:Function1(recv)
方法在变量上被调用:recv.Method1()
接收者有一个显式的名字,这个名字必须在方法中被使用。
在接收者是指针时,方法可以改变接收者的值(或状态),这点函数也可以做到(当参数作为指针传递,即通过引用调用时,函数也可以改变参数的状态)。
receiver_type 叫做 (接收者)基本类型,方法必须和这个类型在同样的包中。
在 Go 中,(接收者)类型关联的方法不写在类型结构里面,耦合更加宽松;类型和方法之间的关联由接收者来建立。
方法没有和数据定义(结构体)混在一起:它们是正交的类型;表示(数据)和行为(方法)是独立的。
10.10.1 指针或值作为接收者
鉴于性能的原因,recv 最常见的是一个指向 receiver_type 的指针(因为我们不想要一个实例的拷贝,如果按值调用的话就会是这样),特别是在 receiver 类型是结构体时,就更是如此了。
如果想要方法改变接收者的数据,就在接收者的指针类型(会自动解引用)上定义该方法。否则,就在普通的值类型上定义方法。
对于类型 T,如果在 \*T 上存在方法 Meth(),并且 t 是这个类型的变量,那么 t.Meth() 会被自动转换为 (&t).Meth()。
指针方法和值方法都可以在指针或非指针上被调用,但只有指针方法才可以改变类型的值(或状态)
type B struct {
thing int
}
func (b *B) change(val int) {
b.thing = val
}
func main() {
var b B
fmt.Println("原始值:", b)
b.change(12)
fmt.Println(b)
}
10.10.2 未导出字段
可以通过面向对象语言一个众所周知的技术来完成:提供 getter() 和 setter() 方法。对于 setter() 方法使用 Set... 前缀,对于 getter() 方法只使用成员名。
package person
type Person struct {
firstName string
lastName string
}
func (p *Person) FirstName() string {
return p.firstName
}
func (p *Person) SetFirstName(newName string) {
p.firstName = newName
}
并发访问对象
对象的字段(属性)不应该由 2 个或 2 个以上的不同线程在同一时间去改变。如果在程序发生这种情况,为了安全并发访问,可以使用包 sync中的方法。可以通过 goroutines 和 channels 探索另一种方式。
脏读
脏读又称无效数据的读出,是指在数据库访问中,事务T1将某一值修改,然后事务T2读取该值,此后T1因为某种原因撤销对该值的修改,这就导致了T2所读取到的数据是无效的,值得注意的是,脏读一般是针对于update操作的。
10.11 内嵌类型的方法的继承
当一个匿名类型被内嵌在结构体中时,匿名类型的可见方法也同样被内嵌,这在效果上等同于外层类型 继承 了这些方法:将父类型放在子类型中来实现亚型。这个机制提供了一种简单的方式来模拟经典面向对象语言中的子类和继承相关的效果,也类似 Ruby 中的混入 (mixin)。
内嵌结构体上的方法可以直接在外层类型的实例上调用,但是以内嵌结构体中的数据为基准计算
type Point struct {
x, y float64
}
func (p *Point) abs() float64 {
return math.Sqrt(p.x*p.x + p.y*p.y)
}
type NamedPoint struct {
Point
name string
}
func (n *NamedPoint) Abs() float64 {
return n.Point.Abs() * 100.
}
func main() {
var namep NamedPoint
namep.x = 3
namep.y = 4
fmt.Println(namep.abs()) // 5
}
内嵌将一个已存在类型的字段和方法注入到了另一个类型里:匿名字段上的方法“晋升”成为了外层类型的方法。
可以覆写方法(像字段一样):和内嵌类型方法具有同样名字的外层类型的方法会覆写内嵌类型对应的方法。
结构体内嵌和自己在同一个包中的结构体时,可以彼此访问对方所有的字段和方法。
10.12 如何在类型中嵌入功能
主要有两种方法来实现在类型中嵌入功能:
A:聚合(或组合):包含一个所需功能类型的具名字段。
B:内嵌:内嵌(匿名地)所需功能类型
聚合(或组合)
type Log struct {
msg string
}
type Customer struct {
Name string
log *Log
}
内嵌
type Log struct {
msg string
}
type Customer struct {
Name string
Log
}
如果内嵌类型嵌入了其他类型,也是可以的,那些类型的方法可以直接在外层类型中使用。
type Point struct {
x, y float64
person.Person
}
func (p *Point) abs(a float64) float64 {
return math.Sqrt(p.x*p.x+p.y*p.y) + a
}
type NamedPoint struct {
Point
name string
}
func (p *NamedPoint) abs() float64 {
return p.Point.abs(10) * 10
}
func main() {
var namep NamedPoint
namep.x = 3
namep.y = 4
namep.SetFirstName("firstname")
fmt.Println(namep.abs())
fmt.Println(namep.FirstName())
}
因此一个好的策略是创建一些小的、可复用的类型作为一个工具箱,用于组成域类型。
多重继承
多重继承指的是类型获得多个父类型行为的能力,它在传统的面向对象语言中通常是不被实现的(C++ 和 Python 例外)。
type Camera struct{}
func (c *Camera) TakeAPicture() string {
return "Click"
}
type Phone struct{}
func (p *Phone) Call() string {
return "Ring Ring"
}
type CameraPhone struct {
Camera
Phone
}
10.13 通用方法和方法命名
在编程中一些基本操作会一遍又一遍的出现,比如打开 (Open)、关闭 (Close)、读 (Read)、写 (Write)、排序(Sort) 等等,并且它们都有一个大致的意思:打开 (Open)可以作用于一个文件、一个网络连接、一个数据库连接等等。具体的实现可能千差万别,但是基本的概念是一致的。
在 Go 语言中,通过使用接口,标准库广泛的应用了这些规则,在标准库中这些通用方法都有一致的名字,比如 Open()、Read()、Write()等。
想写规范的 Go 程序,就应该遵守这些约定,**给方法合适的名字和签名,**就像那些通用方法那样。这样做会使 Go 开发的软件更加具有一致性和可读性。比如:如果需要一个 convert-to-string() 方法,应该命名为 String(),而不是 ToString()
10.14和其他面向对象语言比较 Go 的类型和方法
在如 C++、Java、C# 和 Ruby 这样的面向对象语言中,方法在类的上下文中被定义和继承:在一个对象上调用方法时,运行时会检测类以及它的超类中是否有此方法的定义,如果没有会导致异常发生。
在 Go 语言中,这样的继承层次是完全没必要的:如果方法在此类型定义了,就可以调用它,和其他类型上是否存在这个方法没有关系。在这个意义上,Go 具有更大的灵活性。
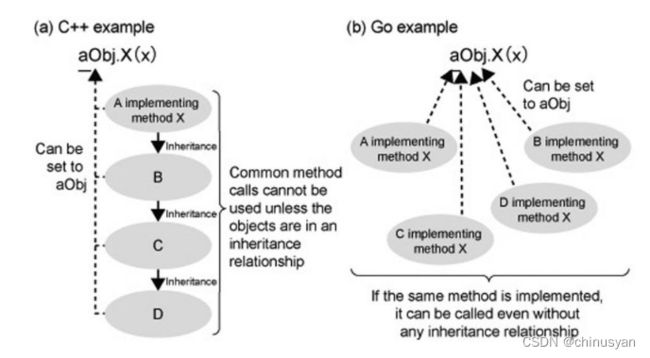
继承有两个好处:代码复用和多态
在 Go 中,代码复用通过组合和委托实现,多态通过接口的使用来实现:有时这也叫 组件编程 (Component Programming)。
10.15 类型的 String() 方法和格式化描述符
当定义了一个有很多方法的类型时,十之八九你会使用 String() 方法来定制类型的字符串形式的输出,换句话说:一种可阅读性和打印性的输出。如果类型定义了 String() 方法,它会被用在 fmt.Printf() 中生成默认的输出:等同于使用格式化描述符 %v 产生的输出。还有 fmt.Print() 和 fmt.Println() 也会自动使用 String() 方法。
注意:不要在 String() 方法里面调用涉及 String() 方法的方法,它会导致意料之外的错误,比如下面的例子,它导致了一个无限递归调用(TT.String() 调用 fmt.Sprintf,而 fmt.Sprintf 又会反过来调用 TT.String()),很快就会导致内存溢出:
type TT float64
func (t TT) String() string {
return fmt.Sprintf("%v", t)
}
t.String()
10.16 垃圾回收和 SetFinalizer
Go 开发者不需要写代码来释放程序中不再使用的变量和结构占用的内存,在 Go 运行时中有一个独立的进程,即垃圾收集器 (GC),会处理这些事情,它搜索不再使用的变量然后释放它们的内存。可以通过 runtime 包访问 GC 进程。
如果需要在一个对象 obj 被从内存移除前执行一些特殊操作,比如写到日志文件中,可以通过如下方式调用函数来实现:
runtime.SetFinalizer(obj, func(obj *typeObj))
在对象被 GC 进程选中并从内存中移除以前,SetFinalizer 都不会执行,即使程序正常结束或者发生错误。