“中国法研杯”司法人工智能挑战赛:基于UTC的多标签/层次分类小样本文本应用,Macro F1提升13%+
相关文章推荐:
小样本文本分类应用:基于UTC的医疗意图多分类,训练调优部署一条龙:
本项目主要完成基于UTC的多标签应用,更多部署细节请参考推荐文章。本项目提供了小样本场景下文本多标签分类的解决方案,在 UTC的基础上利用提示学习取得比微调更好的分类效果,充分利用标注信息。
项目以及码源见文末
- 项目背景:
近年来,大量包含了案件事实及其适用法律条文信息的裁判文书逐渐在互联网上公开,海量的数据使自然语言处理技术的应用成为可能。现实中的案情错综复杂,案情描述通常涉及多个重要事实,以CAIL2019数据集中婚姻家庭领域的案情要素抽取为例:
"2013年11月28日原、被告离婚时自愿达成协议,婚生子张某乙由被告李某某抚养,本院以(2013)宝渭法民初字第01848号民事调解书对该协议内容予以了确认,该协议具有法律效力,对原、被告双方均有约束力。"该案件中涉及婚后有子女、限制行为能力子女抚养两项要素。接下来我们将讲解在小样本场景下如何利用多标签模型,对输入文本中进行案情重要要素抽取。
应用部署界面展示

1.UTC(Universal Text Classification介绍
本项目提供基于通用文本分类 UTC(Universal Text Classification) 模型微调的文本分类端到端应用方案,打通数据标注-模型训练-模型调优-预测部署全流程,可快速实现文本分类产品落地。
文本分类是一种重要的自然语言处理任务,它可以帮助我们将大量的文本数据进行有效的分类和归纳。实际上,在日常生活中,我们也经常会用到文本分类技术。例如,我们可以使用文本分类来对新闻报道进行分类,对电子邮件进行分类,对社交媒体上的评论进行情感分析等等。但是,文本分类也面临着许多挑战。其中最重要的挑战之一是数据稀缺。由于文本数据往往非常庞大,因此获取足够的训练数据可能非常困难。此外,不同的文本分类任务也可能面临着领域多变和任务多样等挑战。为了应对这些挑战,PaddleNLP推出了一项零样本文本分类应用UTC。该应用通过统一语义匹配方式USM(Unified Semantic Matching)来将标签和文本的语义匹配能力进行统一建模。这种方法可以帮助我们更好地理解文本数据,并从中提取出有用的特征信息。
UTC具有低资源迁移能力,可以支持通用分类、评论情感分析、语义相似度计算、蕴含推理、多项式阅读理解等多种“泛分类”任务。这使得开发者可以更加轻松高效地实现多任务文本分类数据标注、训练、调优和上线,从而降低文本分类技术门槛。
总之,文本分类是一项重要的自然语言处理任务,它可以帮助我们更好地理解和归纳文本数据。尽管它面临着许多挑战,但是通过使用PaddleNLP的零样本文本分类应用UTC,开发者们可以简单高效实现多任务文本分类数据标注、训练、调优、上线,降低文本分类落地技术门槛。
1.1 分类落地面临难度
分类任务看似简单,然而在产业级文本分类落地实践中,面临着诸多挑战:
- 任务多样:单标签、多标签、层次标签、大规模标签等不同的文本分类任务,需要开发不同的分类模型,模型架构往往特化于具体任务,难以使用统一形式建模;
- 数据稀缺:部分领域数据稀缺,难以获取,且领域专业性使得数据标注门槛高;
- 标签迁移:不同领域的标签多样,并且迁移难度大,尤其不同领域间的标签知识很难迁移。
1.2 UTC亮点
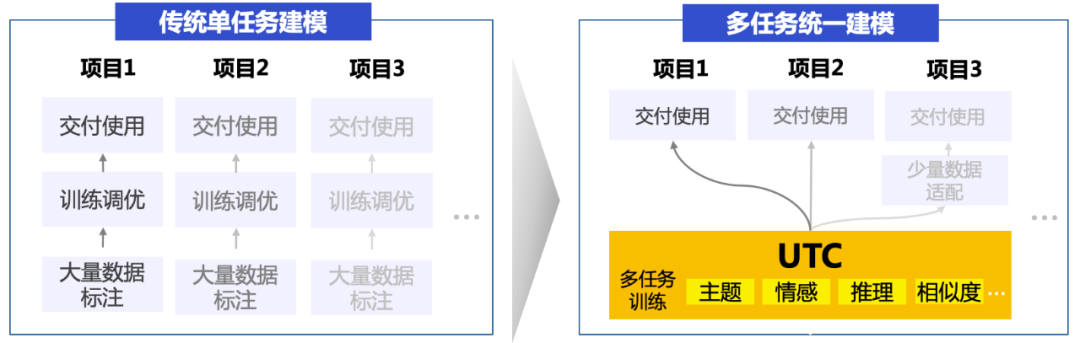
1.2.1 多任务统一建模
在传统技术方案中,针对不同的分类任务需要构建多个分类模型,模型需单独训练且数据和知识不共享。而在UTC方案下,单个模型能解决所有分类需求,包括但不限于单标签分类、多标签分类、层次标签分类、大规模事件标签检测、蕴含推理、语义相似度计算等,降低了开发成本和机器成本。
1.2.2 零样本分类和小样本迁移能力强
UTC通过大规模多任务预训练后,可以适配不同的行业领域,不同的分类标签,仅标注了几条样本,分类效果就取得大幅提升,大大降低标注门槛和成本。
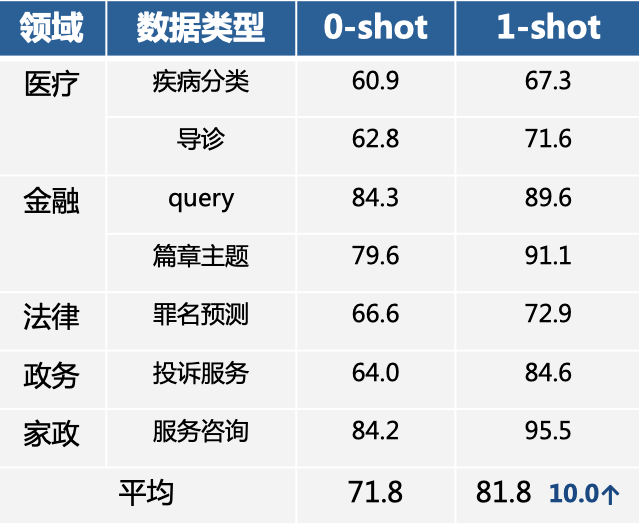
在医疗、金融、法律等领域中,无需训练数据的零样本情况下UTC效果平均可达到70%+(如下表所示),标注少样本也可带来显著的效果提升:每个标签仅仅标注1条样本后,平均提升了10个点!也就是说,即使在某些场景下表现欠佳,人工标几个样本,丢给模型后就会有大幅的效果提升。
1.3 UTC技术思路
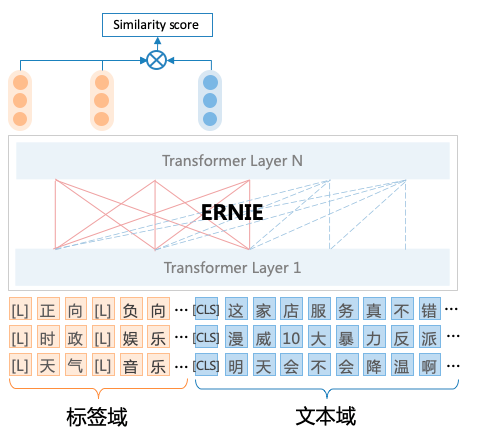
UTC基于百度最新提出的统一语义匹配框架USM(Unified Semantic Matching)[1],将分类任务统一建模为标签与文本之间的匹配任务,对不同标签的分类任务进行统一建模。具体地说:
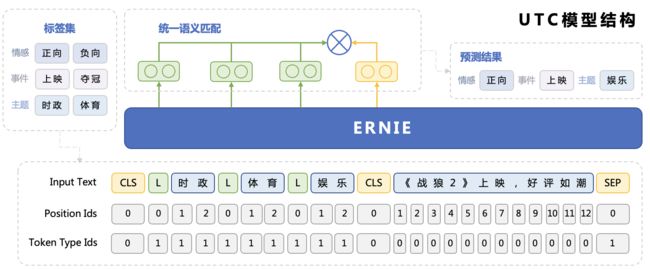
- 为了实现任务架构统一,UTC设计了标签与文本之间的词对连接操作(Label–>CLS-Token Linking),这使得模型能够适应不同领域和任务的标签信息,并按需求进行分类,从而实现了开放域场景下的通用文本分类。
例如,对于事件检测任务,可将一系列事件标签拼接为[L]上映[L]夺冠[L]下架 ,然后与原文本一起作为整体输入到UTC中,UTC将不同标签标识符[L]与[CLS]进行匹配,可对不同标签类型的分类任务统一建模,直接上图:
为了实现通用能力共享,让不同领域间的标签知识跨域迁移,UTC构建了统一的异质监督学习方法进行多任务预训练,使不同领域任务具备良好的零/少样本迁移性能。统一的异质监督学习方法主要包括三种不同的监督信号:
- 直接监督:分类任务直接相关的数据集,如情感分类、新闻分类、意图识别等。
- 间接监督:分类任务间接相关的数据集,如选项式阅读理解、问题-文章匹配等。
- 远程监督:标签知识库或层级标题与文本对齐后弱标注数据。
更多内容参考论文见文末链接 or fork一下项目论文已上传
2.文本分类任务Label Studio教程
2.1 Label Studio安装
以下标注示例用到的环境配置:
- Python 3.8+
- label-studio == 1.7.2
在终端(terminal)使用pip安装label-studio:
pip install label-studio==1.7.2安装完成后,运行以下命令行:
label-studio start在浏览器打开http://localhost:8080/,输入用户名和密码登录,开始使用label-studio进行标注。
2.2 文本分类任务标注
- 2.2.1 项目创建
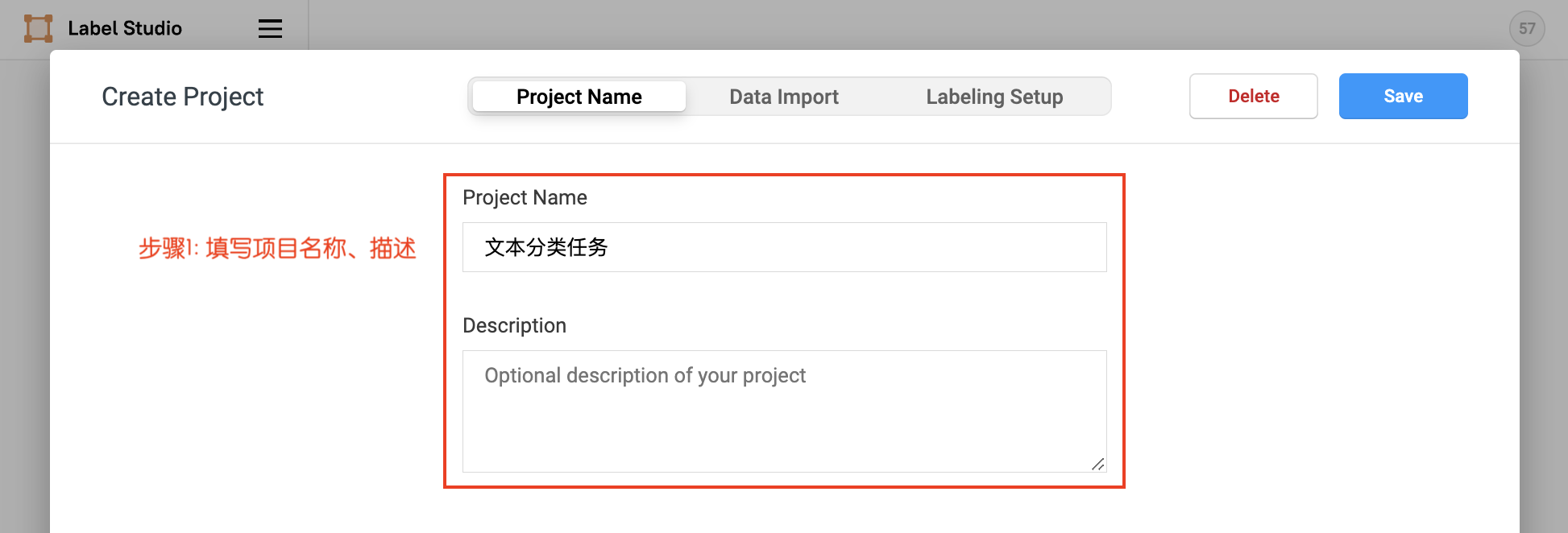
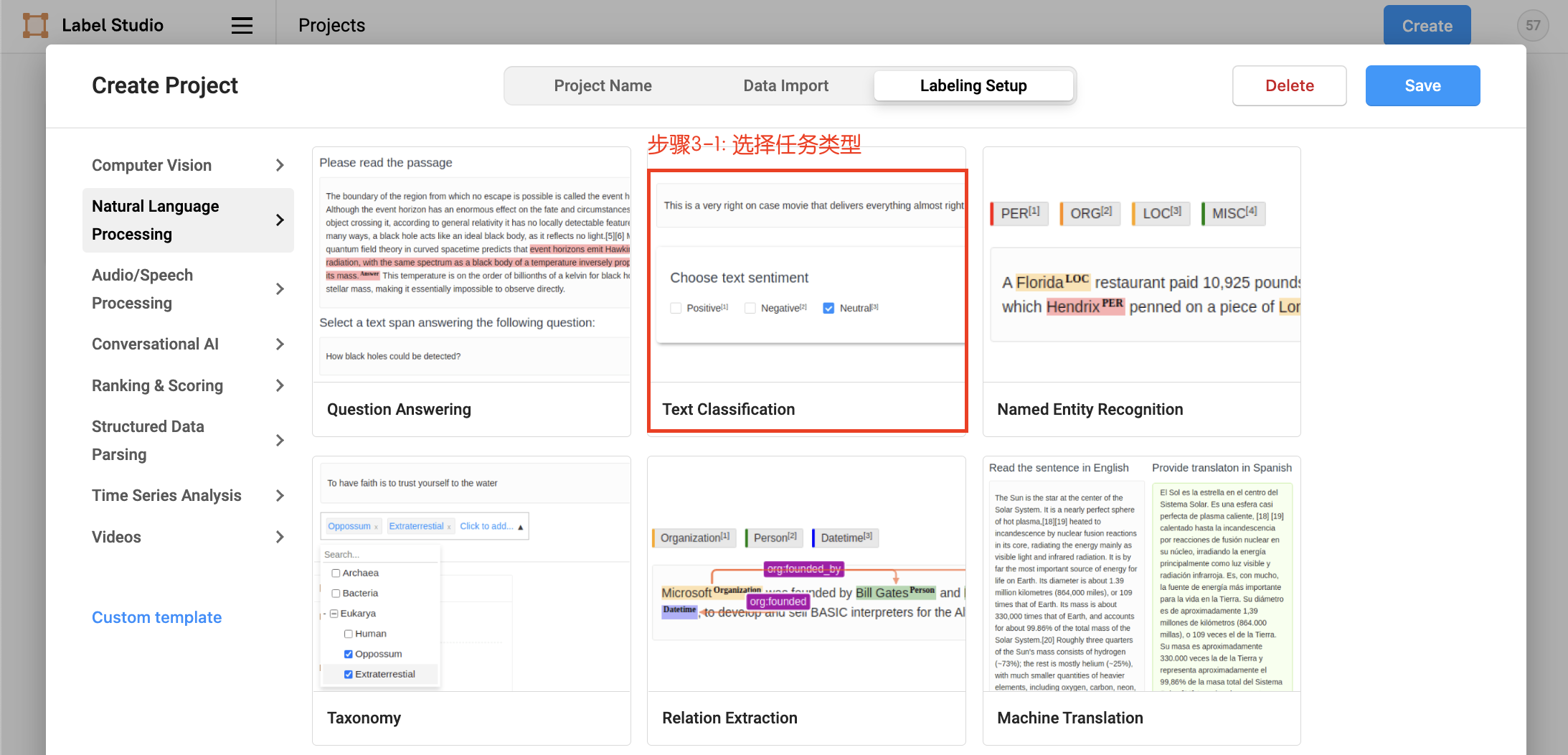
点击创建(Create)开始创建一个新的项目,填写项目名称、描述,然后在Labeling Setup中选择Text Classification。
- 填写项目名称、描述
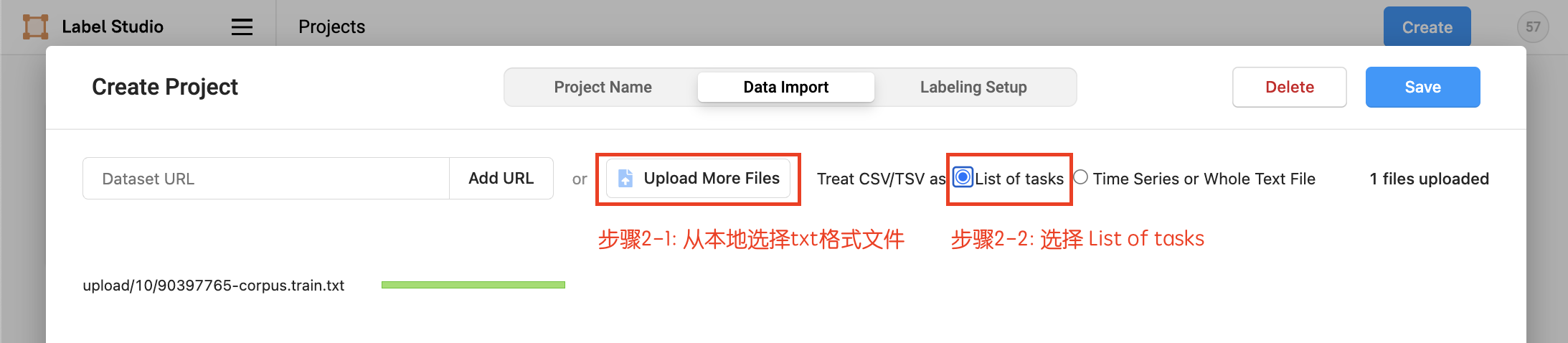
- 数据上传,从本地上传txt格式文件,选择
List of tasks,然后选择导入本项目
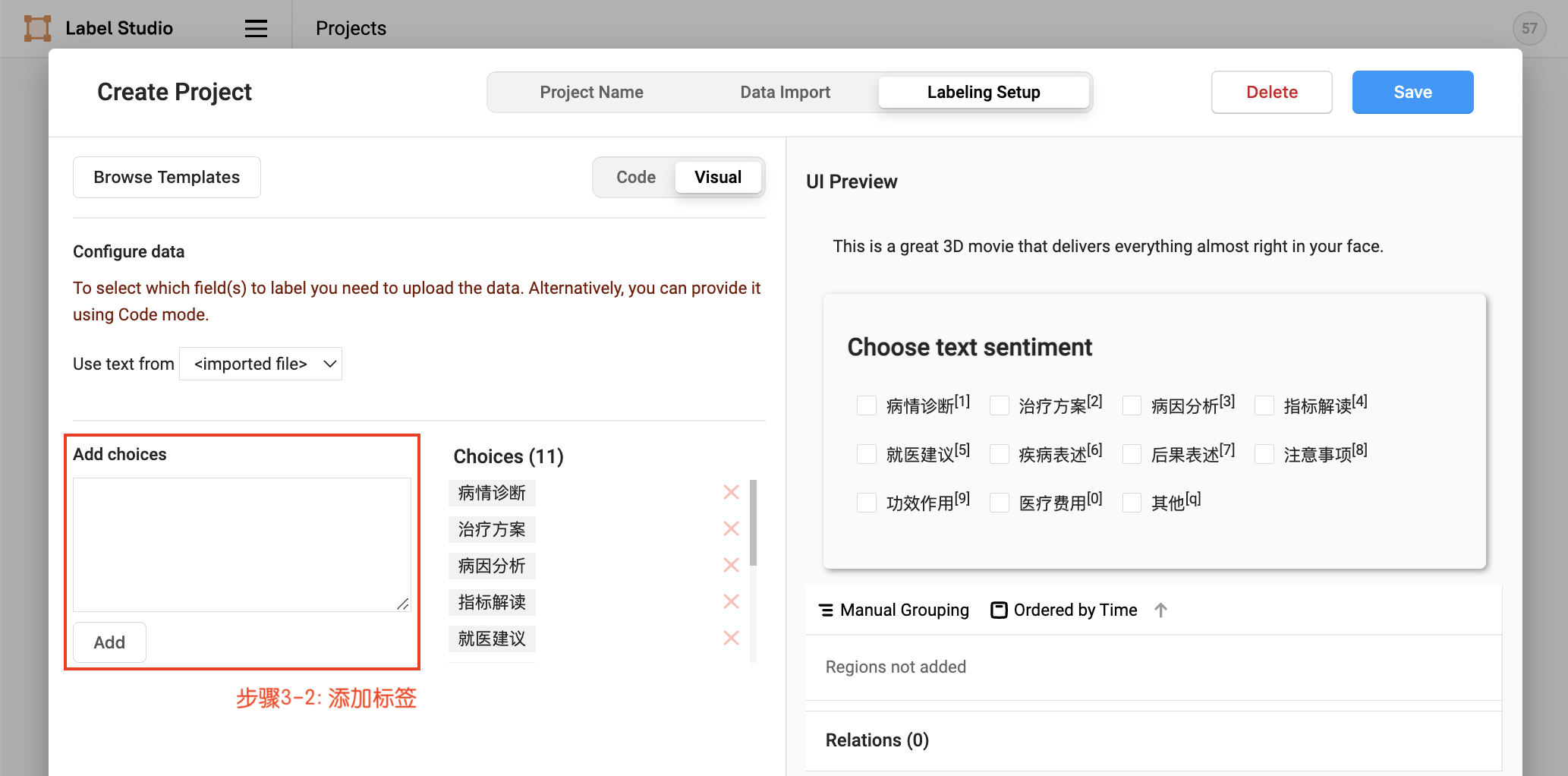
- 设置任务,添加标签
- 数据上传
项目创建后,可在Project/文本分类任务中点击Import继续导入数据,同样从本地上传txt格式文件,选择List of tasks 。
- 2.2.2 标签构建
项目创建后,可在Setting/Labeling Interface中继续配置标签,
默认模式为单标签多分类数据标注。对于多标签多分类数据标注,需要将choice的值由single改为multiple。

- 2.2.3 任务标注
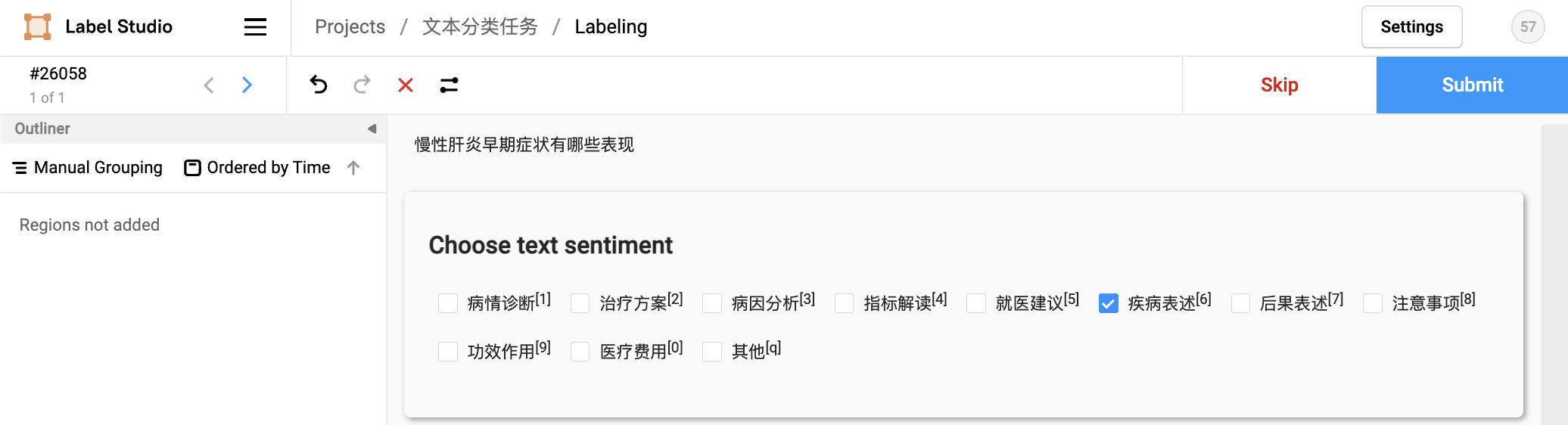
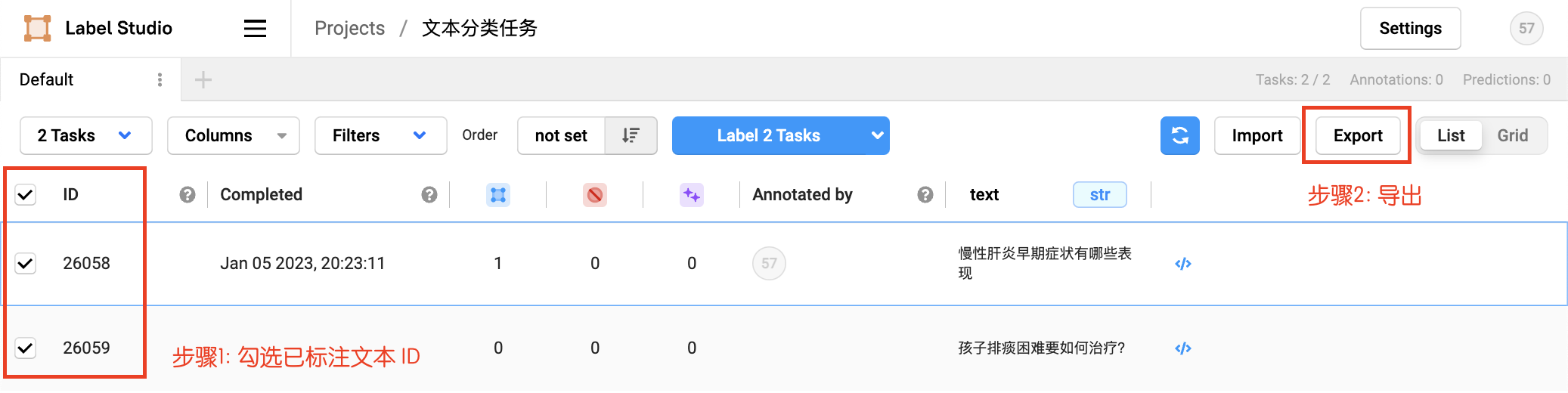
- 2.2.4 数据导出
勾选已标注文本ID,选择导出的文件类型为JSON,导出数据:
参考链接:
3.多标签/层次分类数据转换
这里我们使用CAIL2019“中国法研杯”司法人工智能挑战赛—婚姻家庭要素提取任务数据集的子集作为示例数据集。该数据集中原始训练集包括 14377 条标注样本,我们按每条标签随机采样 4 条样本,得到 80 条样本数据作为训练集,剩余训练集数据作为测试集。
3.1 多标签源数据格式
data/
├── train.txt # 训练数据集
├── dev.txt # 验证数据集
├── test.txt # 测试数据集(可选)
├── data.txt # 待预测数据(可选)
└── label.txt # 分类标签集
- 训练/验证/测试数据
对于训练/验证/测试数据集文件,每行数据表示一条样本,包括文本和标签两部分,由tab符\t分隔,多个标签以英文逗号,分隔。格式如下
<文本>'\t'<标签>','<标签>','<标签>
<文本>'\t'<标签>','<标签>数据集展示
本院认为,涉案房屋系2012年12月4日原、被告婚姻关系存续期间购买,且涉案楼房的产权登记在原、被告名下,依据法律规定,夫妻在婚姻关系存续期间所得的财产,归夫妻共同所有; 不动产分割,有夫妻共同财产
原、被告之间的共同财产应依法分割。 有夫妻共同财产
协议不成时,由人民法院判决”的规定,由于被告后期治疗还需大量费用,原告应给与原告必要的经济帮助。 适当帮助
故原告向法院提起诉讼,要求与被告离婚,婚生女孩随原告生活,被告给付抚养费。 婚后有子女,支付抚养费,限制行为能力子女抚养
2014年12月22日,原告诉至本院,要求与被告离婚,后本院判决不准予原、被告离婚。 二次起诉离婚
男到女家生活,2006年12月婚生一女,取名张某甲。 婚后有子女- 预测数据
对于待预测数据文件,每行包含一条待预测样本,无标签。格式如下
<文本>
<文本>数据集展示
五松新村房屋是被告婚前购买的;
被告于2016年3月将车牌号为皖B×××××出售了2.7万元,被告通过原告偿还了齐荷花人民币2.6万元,原、被告尚欠齐荷花2万元。
2、判令被告返还借婚姻索取的现金33万元,婚前个人存款10万元;
一、判决原告于某某与被告杨某某离婚;- 标签数据
对于分类标签集文件,存储了数据集中所有的标签集合,每行为一个标签名。如果需要自定义标签映射用于分类器初始化,则每行需要包括标签名和相应的映射词,由==分隔。格式如下
<标签>'=='<映射词>
<标签>'=='<映射词>例如,对于婚姻家庭要素提取数据集,原标签字数较多,因此同一个标签依赖的输出也多。为了降低训练难度,我们可以将其映射为较短的短语
有夫妻共同债务==共同债务
存在非婚生子==非婚生子
...Note: 这里的标签映射词定义遵循的规则是,不同映射词尽可能长度一致,映射词和提示需要尽可能构成通顺的语句。越接近自然语句,小样本下模型训练效果越好。如果原标签名已经可以构成通顺语句,也可以不构造映射词,每行一个标签即可,即
3.2层次分类源数据格式
- 训练/验证/测试数据
对于训练/验证/测试数据集文件,每行数据表示一条样本,包括文本和标签两部分,由tab符\t分隔,多个标签以英文逗号,分隔,同一标签内不同层级以##字符连接。格式如下
<文本>'\t'<标签>','<标签>','<标签>
<文本>'\t'<标签>','<标签>
...
紫光圣果副总经理李明雷辞职 组织关系,组织关系##辞/离职
无理取闹辱骂扶贫干部织金一居民被行拘 司法行为,司法行为##拘捕
...- 标签数据
对于分类标签集文件,存储了数据集中所有的标签路径集合,每行是一个标签路径,高层的标签指向底层标签,不同层级的标签用'##'连接,本项目选择为标签层次结构中的每一个节点生成对应的标签路径,详见层次分类任务介绍,标签路径格式如下
<一级标签>
<一级标签>'##'<二级标签>
<一级标签>'##'<二级标签>'##'<三级标签>
...
如果需要自定义标签映射用于分类器初始化,则每行需要包括标签名和相应的映射词,由==分隔。格式如下
<一级标签>'=='<映射词>
<一级标签>'##'<二级标签>'=='<映射词>
<一级标签>'##'<二级标签>'##'<三级标签>'=='<映射词>
...
例如,原标签路径交往##会见中包括特殊符号##,大概率不会在说话或者写作中使用,因此我们将其映射为会见或者见面。
交往==交往
交往##会见==会见
...
3.3 转换后格式
三种分类都可以在 UTC 框架下实现,其中 multi-class 2.5版本需要修改评估代码。multi-label: UTC 默认是 multi-label 形式。
#多分类数据示例
{"text_a": "、月经期间刮痧拔罐会引起身体什么", "text_b": "", "question": "", "choices": ["病情诊断", "治疗方案", "病因分析", "指标解读", "就医建议", "疾病表述", "后果表述", "注意事项", "功效作用", "医疗费用", "其他"], "labels": [5]}#多标签数据示例
{"text_a": "多标签分类示例","text_b": "", "question": "","choices": ["体育", "时政", "娱乐", "电影"], "labels": [2, 3]}hierachical: applications/text_classification/*/few-shot 目录下 hierachical 的代码实现和 multi-label 是相同的,区别是数据层面将多级标签用 ## 分隔符拼接了起来,形式上仍是 multi-label。在 UTC 中也可以使用这种实现,将多级标签直接拼起来,如果只需要分类到细分层级,直接取细分层级效果可能更好。这里就不在重复展示了
#层次分类数据示例
{"text_a": "多层次分类示例", "text_b": "", "question": "", "choices": ["环境 资质优", "环境 资质差", "口味 口感好", "口味 口感差"], "labels": [0, 1]}Note:2.5版本修改代码部分:原有代码中compute_metrics 函数的 sigmoid 实现 run_train.py 和 run_eval.py 均改为 softmax
def compute_metrics(eval_preds): labels = paddle.to_tensor(eval_preds.label_ids, dtype="int64") preds = paddle.to_tensor(eval_preds.predictions) preds = paddle.nn.functional.softmax(preds, axis=-1) preds = preds[labels != -100] labels = paddle.argmax(labels, axis=-1) metric = Accuracy() correct = metric.compute(preds, labels) metric.update(correct) acc = metric.accumulate() return {"accuracy": acc}最新版本已经增加:single_label超参数
- 默认False,即可
- 二分类时,开启single_label时需要将运行脚本中的 metric_for_best_model 参数改为accuracy
4.模型训练预测
多任务训练场景可分别进行数据转换再进行混合:通用分类、评论情感分析、语义相似度计算、蕴含推理、多项式阅读理解等众多“泛分类”任务
##代码结构
├── deploy/simple_serving/ # 模型部署脚本
├── utils.py # 数据处理工具
├── run_train.py # 模型微调脚本
├── run_eval.py # 模型评估脚本
├── label_studio.py # 数据格式转换脚本
├── label_studio_text.md # 数据标注说明文档
└── README.md4.1 模型微调
推荐使用 PromptTrainer API 对模型进行微调,该 API 封装了提示定义功能,且继承自 Trainer API 。只需输入模型、数据集等就可以使用 Trainer API 高效快速地进行预训练、微调等任务,可以一键启动多卡训练、混合精度训练、梯度累积、断点重启、日志显示等功能,Trainer API 还针对训练过程的通用训练配置做了封装,比如:优化器、学习率调度等。
使用下面的命令,使用 utc-base 作为预训练模型进行模型微调,将微调后的模型保存至output_dir:
4.1.1 单卡训练
#安装最新版本paddlenlp
!pip install --upgrade paddlenlp# 单卡启动:
!python run_train.py \
--device gpu \
--logging_steps 100 \
--save_steps 100 \
--eval_steps 100 \
--seed 1000 \
--model_name_or_path utc-base \
--output_dir ./checkpoint_1w/model_best \
--dataset_path ./data/ \
--max_seq_length 512 \
--per_device_train_batch_size 32 \
--per_device_eval_batch_size 32 \
--gradient_accumulation_steps 8 \
--num_train_epochs 20 \
--learning_rate 1e-5 \
--do_train \
--do_eval \
--do_export \
--export_model_dir ./checkpoint_1w/model_best \
--overwrite_output_dir \
--disable_tqdm True \
--metric_for_best_model macro_f1 \
--load_best_model_at_end True \
--save_total_limit 1 \
--save_plm训练样本80下结果:
[2023-05-18 18:47:00,108] [ INFO] - ***** Running Evaluation *****
[2023-05-18 18:47:00,108] [ INFO] - Num examples = 1611
[2023-05-18 18:47:00,108] [ INFO] - Total prediction steps = 806
[2023-05-18 18:47:00,108] [ INFO] - Pre device batch size = 2
[2023-05-18 18:47:00,108] [ INFO] - Total Batch size = 2
[2023-05-18 18:47:23,035] [ INFO] - eval_loss: 2.9577677249908447, eval_micro_f1: 0.9739602731222843, eval_macro_f1: 0.9244269186423556, eval_runtime: 22.9266, eval_samples_per_second: 70.268, eval_steps_per_second: 35.156, epoch: 20.0二分类时需要注意的问题
- ModuleNotFoundError: No module named 'fast_tokenizer'
安装一下fast tokenizer
pip install --upgrade fast_tokenizer- 开启single_label时需要将运行脚本中的 metric_for_best_model 参数改为accuracy
metric_value = metrics[metric_to_check]
KeyError: 'eval_macro_f1'NOTE:
如需恢复模型训练,则可以设置 init_from_ckpt , 如 init_from_ckpt=checkpoint/model_state.pdparams 。
4.1.2 多卡训练
如果在GPU环境中使用,可以指定gpus参数进行多卡训练:
!python -u -m paddle.distributed.launch --gpus "0,1,2,3" run_train.py \
--device gpu \
--logging_steps 100 \
--save_steps 100 \
--eval_steps 100 \
--seed 1000 \
--model_name_or_path utc-base \
--output_dir ./checkpoint_1w/model_best \
--dataset_path ./data/ \
--max_seq_length 512 \
--per_device_train_batch_size 32 \
--per_device_eval_batch_size 32 \
--gradient_accumulation_steps 8 \
--num_train_epochs 20 \
--learning_rate 1e-5 \
--do_train \
--do_eval \
--do_export \
--export_model_dir ./checkpoint_1w/model_best \
--overwrite_output_dir \
--disable_tqdm True \
--metric_for_best_model macro_f1 \
--load_best_model_at_end True \
--save_total_limit 1 \
--save_plm训练样本1.4w+下结果:
[2023-05-18 19:47:58,379] [ INFO] - ***** Running Evaluation *****
[2023-05-18 19:47:58,380] [ INFO] - Num examples = 1611
[2023-05-18 19:47:58,380] [ INFO] - Total prediction steps = 13
[2023-05-18 19:47:58,380] [ INFO] - Pre device batch size = 32
[2023-05-18 19:47:58,380] [ INFO] - Total Batch size = 128
[2023-05-18 19:48:01,395] [ INFO] - eval_loss: 1.095533847808838, eval_micro_f1: 0.9833333333333333, eval_macro_f1: 0.9492148827343941, eval_runtime: 3.0153, eval_samples_per_second: 534.28, eval_steps_per_second: 4.311, epoch: 19.9455该示例代码中由于设置了参数 --do_eval,因此在训练完会自动进行评估。
可配置参数说明:
single_label: 每条样本是否只预测一个标签。默认为False,表示多标签分类。device: 训练设备,可选择 'cpu'、'gpu' 其中的一种;默认为 GPU 训练。logging_steps: 训练过程中日志打印的间隔 steps 数,默认10。save_steps: 训练过程中保存模型 checkpoint 的间隔 steps 数,默认100。eval_steps: 训练过程中保存模型 checkpoint 的间隔 steps 数,默认100。seed:全局随机种子,默认为 42。model_name_or_path:进行 few shot 训练使用的预训练模型。默认为 "utc-base", 可选"utc-xbase", "utc-base", "utc-medium", "utc-mini", "utc-micro", "utc-nano", "utc-pico"。output_dir:必须,模型训练或压缩后保存的模型目录;默认为None。dataset_path:数据集文件所在目录;默认为./data/。train_file:训练集后缀;默认为train.txt。dev_file:开发集后缀;默认为dev.txt。max_seq_len:文本最大切分长度,包括标签的输入超过最大长度时会对输入文本进行自动切分,标签部分不可切分,默认为512。per_device_train_batch_size:用于训练的每个 GPU 核心/CPU 的batch大小,默认为8。per_device_eval_batch_size:用于评估的每个 GPU 核心/CPU 的batch大小,默认为8。num_train_epochs: 训练轮次,使用早停法时可以选择 100;默认为10。learning_rate:训练最大学习率,UTC 推荐设置为 1e-5;默认值为3e-5。do_train:是否进行微调训练,设置该参数表示进行微调训练,默认不设置。do_eval:是否进行评估,设置该参数表示进行评估,默认不设置。do_export:是否进行导出,设置该参数表示进行静态图导出,默认不设置。export_model_dir:静态图导出地址,默认为None。overwrite_output_dir: 如果True,覆盖输出目录的内容。如果output_dir指向检查点目录,则使用它继续训练。disable_tqdm: 是否使用tqdm进度条。metric_for_best_model:最优模型指标, UTC 推荐设置为macro_f1,默认为None。load_best_model_at_end:训练结束后是否加载最优模型,通常与metric_for_best_model配合使用,默认为False。save_total_limit:如果设置次参数,将限制checkpoint的总数。删除旧的checkpoints输出目录,默认为None。--save_plm:保存模型进行推理部署
NOTE:
如需恢复模型训练,则可以设置 init_from_ckpt , 如 init_from_ckpt=checkpoint/model_state.pdparams 。
4.2 模型评估
通过运行以下命令进行模型评估预测:
#80样本
!python run_eval.py \
--model_path ./checkpoint/model_best \
--test_path ./data/test.txt \
--per_device_eval_batch_size 32 \
--max_seq_len 512 \
--output_dir ./checkpoint_test测试结果
test.txt 结果
100%|█████████████████████████████████████████| 879/879 [01:38<00:00, 12.86it/s][2023-05-18 18:52:23,476] [ INFO] - ***** test metrics *****
[2023-05-18 18:52:23,477] [ INFO] - test_loss = 0.7952
[2023-05-18 18:52:23,477] [ INFO] - test_macro_f1 = 0.9491
[2023-05-18 18:52:23,477] [ INFO] - test_micro_f1 = 0.9833
[2023-05-18 18:52:23,477] [ INFO] - test_runtime = 0:01:39.72
[2023-05-18 18:52:23,477] [ INFO] - test_samples_per_second = 141.0
[2023-05-18 18:52:23,477] [ INFO] - test_steps_per_second = 8.814
100%|█████████████████████████████████████████| 879/879 [01:48<00:00, 8.09it/s]dev.txt结果
100%|█████████████████████████████████████████| 101/101 [00:10<00:00, 13.66it/s][2023-05-18 19:03:14,188] [ INFO] - ***** test metrics *****
[2023-05-18 19:03:14,188] [ INFO] - test_loss = 1.0405
[2023-05-18 19:03:14,188] [ INFO] - test_macro_f1 = 0.934
[2023-05-18 19:03:14,188] [ INFO] - test_micro_f1 = 0.9779
[2023-05-18 19:03:14,188] [ INFO] - test_runtime = 0:00:11.60
[2023-05-18 19:03:14,188] [ INFO] - test_samples_per_second = 138.821
[2023-05-18 19:03:14,188] [ INFO] - test_steps_per_second = 8.703
100%|█████████████████████████████████████████| 101/101 [00:11<00:00, 8.56it/s]#1.4w+样本
!python run_eval.py \
--model_path ./checkpoint_1w/model_best \
--test_path ./data/dev.txt \
--per_device_eval_batch_size 16 \
--max_seq_len 512 \
--output_dir ./checkpoint_1w_test测试结果
test.txt 结果
[2023-05-18 19:51:21,323] [ INFO] - test_loss = 1.0959
[2023-05-18 19:51:21,323] [ INFO] - test_macro_f1 = 0.9576
[2023-05-18 19:51:21,323] [ INFO] - test_micro_f1 = 0.9831
[2023-05-18 19:51:21,323] [ INFO] - test_runtime = 0:00:01.23
[2023-05-18 19:51:21,323] [ INFO] - test_samples_per_second = 64.911
[2023-05-18 19:51:21,323] [ INFO] - test_steps_per_second = 4.057dev.txt结果
[2023-05-18 19:52:19,646] [ INFO] - test_loss = 1.0903
[2023-05-18 19:52:19,646] [ INFO] - test_macro_f1 = 0.9492
[2023-05-18 19:52:19,646] [ INFO] - test_micro_f1 = 0.9833
[2023-05-18 19:52:19,646] [ INFO] - test_runtime = 0:00:10.98
[2023-05-18 19:52:19,646] [ INFO] - test_samples_per_second = 146.627
[2023-05-18 19:52:19,646] [ INFO] - test_steps_per_second = 9.193可配置参数说明:
model_path: 进行评估的模型文件夹路径,路径下需包含模型权重文件model_state.pdparams及配置文件model_config.json。test_path: 进行评估的测试集文件。per_device_eval_batch_size: 批处理大小,请结合机器情况进行调整,默认为16。max_seq_len: 文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为512。single_label: 每条样本是否只预测一个标签。默认为False,表示多标签分类。
4.3模型预测
paddlenlp.Taskflow装载定制模型,通过task_path指定模型权重文件的路径,路径下需要包含训练好的模型权重文件model_state.pdparams。
from pprint import pprint
import json
from paddlenlp import Taskflow
def openreadtxt(file_name):
data = []
file = open(file_name,'r',encoding='UTF-8') #打开文件
file_data = file.readlines() #读取所有行
for row in file_data:
data.append(row) #将每行数据插入data中
return data
data_input=openreadtxt('/home/aistudio/input/data2.txt')
# print(data_input)
schema = ["婚后生育", "抚养孩子", "共同财产", "付抚养费", "分不动产", "婚后分居", "二次起诉", "按月付费", "同意离婚", "共同债务", "婚前财产",
"法定离婚", "家庭义务", "非婚生子", "适当帮助", "无视协议", "损害赔偿", "分居两年", "子女分开", "个人财产"]
my_cls = Taskflow("zero_shot_text_classification", model="utc-base", schema=schema, task_path='/home/aistudio/checkpoint/model_best/plm')
results=my_cls(data_input)
with open("/home/aistudio/output/output.txt", "w+",encoding='UTF-8') as f: #a : 写入文件,若文件不存在则会先创建再写入,但不会覆盖原文件,而是追加在文件末尾
for result in results:
print(result)
line = json.dumps(result, ensure_ascii=False) #对中文默认使用的ascii编码.想输出真正的中文需要指定ensure_ascii=False
f.write(line + "\n")
print("数据结果已导出")[2023-05-18 19:14:41,567] [ INFO] - We are using to load 'utc-base'.
[2023-05-18 19:14:41,572] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/utc-base/utc_base_vocab.txt
[2023-05-18 19:14:41,610] [ INFO] - tokenizer config file saved in /home/aistudio/.paddlenlp/models/utc-base/tokenizer_config.json
[2023-05-18 19:14:41,616] [ INFO] - Special tokens file saved in /home/aistudio/.paddlenlp/models/utc-base/special_tokens_map.json
[2023-05-18 19:14:41,622] [ INFO] - Assigning ['[O-MASK]'] to the additional_special_tokens key of the tokenizer
{'predictions': [{'label': '适当帮助', 'score': 0.9990043954170514}], 'text_a': '协议不成时,由人民法院判决”的规定,由于被告后期治疗还需大量费用,原告应给与原告必要的经济帮助。\t\n'}
{'predictions': [{'label': '婚后生育', 'score': 0.9994037939529928}, {'label': '抚养孩子', 'score': 0.9991192036976089}, {'label': '付抚养费', 'score': 0.9995337863092342}], 'text_a': '故原告向法院提起诉讼,要求与被告离婚,婚生女孩随原告生活,被告给付抚养费。\t\n'}
{'predictions': [{'label': '二次起诉', 'score': 0.9996573067393362}], 'text_a': '2014年12月22日,原告诉至本院,要求与被告离婚,后本院判决不准予原、被告离婚。\t\n'}
{'predictions': [{'label': '婚后生育', 'score': 0.9981496013638776}], 'text_a': '男到女家生活,2006年12月婚生一女,取名张某甲。\t'}
数据结果已导出
抽样测试:
- 协议不成时,由人民法院判决”的规定,由于被告后期治疗还需大量费用,原告应给与原告必要的经济帮助。 适当帮助
- 故原告向法院提起诉讼,要求与被告离婚,婚生女孩随原告生活,被告给付抚养费。 婚后生育,付抚养费,抚养孩子
- 2014年12月22日,原告诉至本院,要求与被告离婚,后本院判决不准予原、被告离婚。 二次起诉
- 男到女家生活,2006年12月婚生一女,取名张某甲。 婚后生育
{'predictions': [{'label': '适当帮助', 'score': 0.9990043954170514}], 'text_a': '协议不成时,由人民法院判决”的规定,由于被告后期治疗还需大量费用,原告应给与原告必要的经济帮助。\t\n'}
{'predictions': [{'label': '婚后生育', 'score': 0.9994037939529928}, {'label': '抚养孩子', 'score': 0.9991192036976089}, {'label': '付抚养费', 'score': 0.9995337863092342}], 'text_a': '故原告向法院提起诉讼,要求与被告离婚,婚生女孩随原告生活,被告给付抚养费。\t\n'}
{'predictions': [{'label': '二次起诉', 'score': 0.9996573067393362}], 'text_a': '2014年12月22日,原告诉至本院,要求与被告离婚,后本院判决不准予原、被告离婚。\t\n'}
{'predictions': [{'label': '婚后生育', 'score': 0.9981496013638776}], 'text_a': '男到女家生活,2006年12月婚生一女,取名张某甲。\t'}抽样准确率100%
5.基于gradio可视化展示
6.总结
6.1 UTC提示学习和微调预训练学习模型对比
Macro F1和Micro F1都是评估分类模型性能的指标,但是它们计算方式不同。
- Macro F1是每个类别的F1值的平均值,不考虑类别的样本数。它适用于数据集中各个类别的样本数量相近的情况下,可以更好地反映每个类别的性能。
- Micro F1是所有类别的F1值的加权平均,其中权重为每个类别的样本数。它将所有类别的预测结果汇总为一个混淆矩阵,并计算出整个数据集的精确率、召回率和F1值。Micro F1适用于多分类问题,尤其是在数据集不平衡的情况下,可以更好地反映整体的性能。
总之,Micro F1更关注整个数据集的性能,而Macro F1更关注每个类别的性能。
| model_name | 模型结构 | Micro F1(%) | Macro F1(%) |
|---|---|---|---|
| UTC-base-1.4w+样本 | 12-layer, 768-hidden, 12-heads | 98.33 | 94.92 |
| UTC-base-80样本 | 12-layer, 768-hidden, 12-heads | 97.79 | 93.4 |
| ERNIE 1.0 Large Cw | 24-layer, 1024-hidden, 20-heads | 91.14 | 81.68 |
| ERNIE 3.0 Base | 12-layer, 768-hidden, 12-heads | 90.38 | 80.14 |
| ERNIE 3.0 Medium | 6-layer, 768-hidden, 12-heads | 90.57 | 79.36 |
| ERNIE 3.0 Mini | 6-layer, 384-hidden, 12-heads | 89.27 | 76.78 |
| ERNIE 3.0 Micro | 4-layer, 384-hidden, 12-heads | 89.43 | 77.20 |
| ERNIE 3.0 Nano | 4-layer, 312-hidden, 12-heads | 85.39 | 75.07 |
## 项目链接&码源链接