融合模型stacking14条经验总结和5个成功案例(互联网最全,硬核收藏)_机器学习_人工智能_模型竞赛_论文参考
我看了很多关于融合模型stacking文章,很多作者倾向于赞美融合模型stacking,对其缺点轻描淡写,这容易误导初学者。一叶障目就是这意思。
我的很多学员喜欢用融合模型作为论文或专利创新点,这是一个热门技术。
最近有个同学在论文建模咨询中问到融合模型stacking真的可靠吗?这一问让我深思,我觉得写这篇文章让大家更清楚认识融合模型stacking。这篇文章是我数年长期实验对融合模型stacking经验总结。写这篇文章也花了半个月时间,大部分实验用于实验。这篇文章比较长,涉及内容比较多,实验数据集比较多,估计短时间难以看完,大家可以先收藏此文章,以后慢慢琢磨,帮助大家少走万年坑。
此文章比较适合融合模型爱好者,模型竞赛参赛者,正在写论文,专利学员。
stacking堆叠或堆叠泛化是一种集成机器学习算法。
它使用元学习算法来学习如何最好地结合来自两个或多个基础机器学习算法的预测。
堆叠的好处是它可以利用一系列性能良好的模型在分类或回归任务上的能力,并可能做出比集成中任何单个模型性能更好的预测。大家注意我说的是可能,不是绝对。

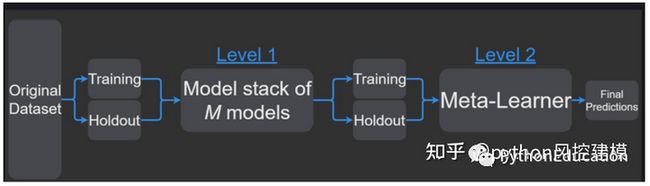
下图是融合模型的算法流程图,我们看到子模型(base model)是读取所有训练数据training data,而不是每个子模型只读取训练数据的一部分。因此前期可以多加入子模型进行观察。
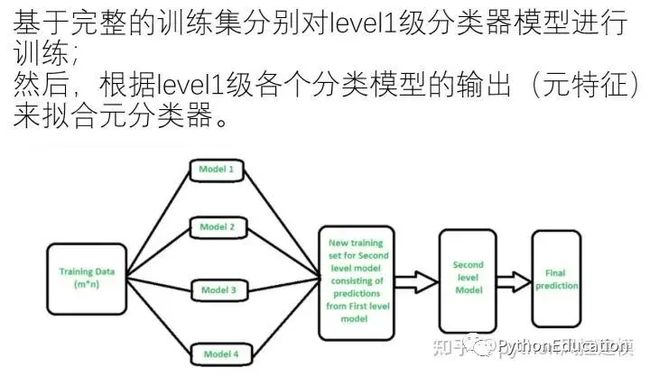
最终训练的融合模型就像一个真正模型,具有预测能力,分类能力,回归能力。
之前发布过文章
《模型竞赛大杀器-融合模型(stacking)》介绍融合模型stacking,具体细节大家可以去看看。
1.融合模型stacking难以应用于商业模型
因为融合模型stacking堆叠集成的计算时间比单个机器学习模型要长得多。商业公司模型要考虑算法复杂度,时间成本和可解释性,这些都是融合模型stacking的痛点。之前kaggle模型竞赛有位国外选手用融合模型stacking夺冠,但主办方资助公司并未采纳,就是因为融合模型的子模型太多,非常耗时,难以应用于实际业务。
2.融合模型stacking在学术界论文大受欢迎
融合模型stacking的缺点也可以成为优点,那就是用于学术界,特别是论文发布用。我们接触过大量论文咨询,学术界的很多同仁认为模型越复杂,价值越高。他们眼中深度学习模型段位就是高于机器学习和统计模型。这都是误区,模型算法选择要与实际结合,看场景和具体数据集,没有完全准确的通用套路。学术界同仁很多没有商业模型从业经验,这是可以理解的。因此我看多过大量融合模型相关论文。融合模型stacking可以由大量子模型组成,存在诸多组合情况,也能创造大量论文创新点。
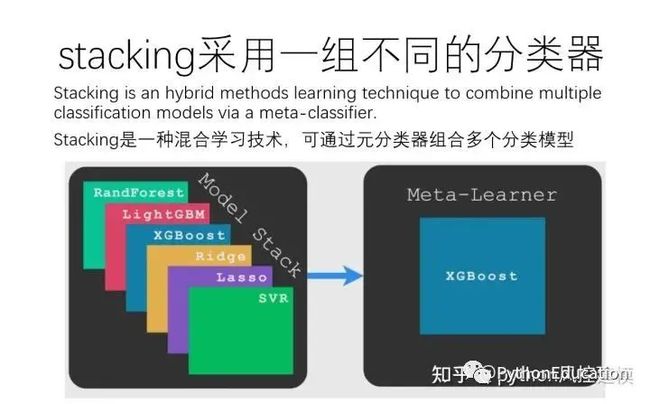
3.scikit-learn和mlxtend库
scikit-learn和mlxtend库提供了 Python 中堆叠集成的标准实现。scikit-learn和mlxtend库各有优劣。scikit-learn库优点是可以用逻辑回归作为元模型(第二层模型)。mlxtend库在运行stacking融合模型时速度更快,但运用逻辑回归,支持向量机外的模型作为元模型会报错。
4.融合模型stacking实验时间成本高
很多子模型有着不同数据预处理方法,例如支持向量机,神经网络需要对数据的缺失值填充,数据平滑处理,但集成学习算法不需要。集成学习直接用原始数据可能得到更好效果。
子模型不同数据预测逻辑造成融合模型实验多样性和次数增加,从而增加了时间成本。
5.融合模型性能并非一定能高于子模型
互联网上很多关于融合模型介绍会传递一个误区,那就是融合模型性能一定高于单一模型。我们建模后,应该用融合模型提升性能。但实时并非如此,我们在大量实验中发现很多时候融合模型难以提升,性能反而不如子模型,而且还消耗大量时间实验。
例如在对乳腺癌数据集实验中,我们发现融合模型auc为 0.9820,反而不如上述子模型。
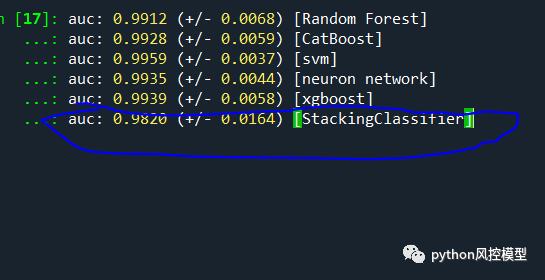
但我们加入KNN,lightgbm子模型后,融合模型性能有的大幅提升,并且超越所有子模型。
我们看到大量论文中描述融合模型性能优于子模型,那是作者花了大量时间实验,测试出一组固定子模型搭配,得到融合模型性能提升的结论。你看的的子模型组合不是偶然,而是大量时间实验后精心筛选的结果。
6.融合模型性能提升具体指标
我们在大量实验中,发现融合模型提升准确率accuracy和f1分数的概率高于AUC。你用一组子模型融合后可以提升某个指标,但不保证能提升所有指标。
7.融合模型提升技巧-cv参数运用
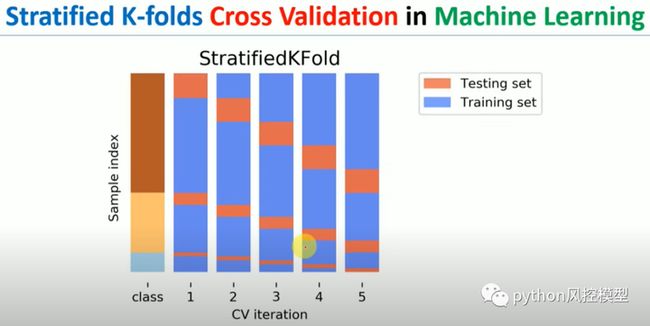
Stratified英文意思是分层的,stratifiedkfold翻译成中文就是分层K折交叉验证。当数据集目标变量是非平衡数据时,cross validation交叉验证在划分数据时会遇到不够随机情况,例如好客户划分比例高,坏客户划分比例少,甚至一个都没分到。
stratifiedkfold有利于非平衡数据处理。如果选择Stratified K折交叉验证,那每次训练时交叉验证会保证原始标签中的类别比例,训练标签的类别比例,验证标签的类别比例一致。
下图是stratifiedkfold算法流程图,我们可见class目标变量有三个分类,不同分类都有均匀的交叉验证抽样。
我们在调用cross_val_score函数时,记得输入cv参数,一般选择5或10。输入任意整数,表示在Stratified K折验证中的折数。因此cv参数非常智能化,可以帮我们自动解决目标变量非平衡数据处理难题。数据集不大时,cv10模型性能可能好于cv5。
scores = model_selection.cross_val_score(clf, X, y,
cv=5, scoring='roc_auc')8.融合模型提升技巧-元模型meta_classifier选择
对于大多数学员,我推荐逻辑回归作为元模型meta_classifier。在部分数据集实验中,其他算法为元模型效果不如逻辑回归好。在以乳腺癌数据集为案例,我用逻辑回归为元模型得到融合模型为auc 0.9959,用支持向量机为元模型得到融合模型AUC为0.982.
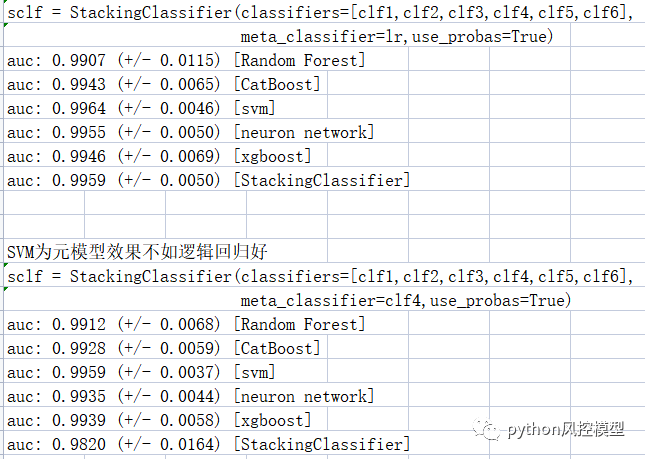
和一些朋友交流中,也发现例外,他们数据集有时用集成树算法作为元模型获得更好融合模型性能。融合模型参数太多,一切以自己实验结果为准。
9.融合模型提升技巧-子模型数量恰到好处
我们在实验中发现融合模型stacking的子模型并非越多越好,或越少越好,恰到好处才最好。
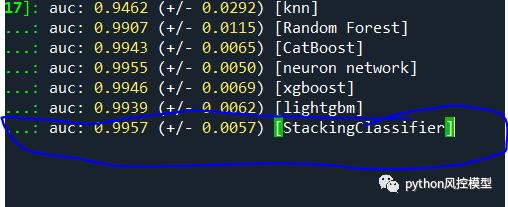
我们用了KNN,随机森林等9个子模型来搭建融合模型,AUC为0.9953,
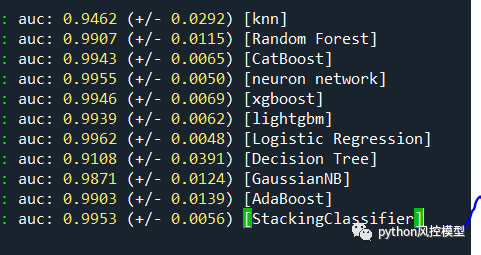
我们精简子模型数量后,用了6个子模型搭建融合模型,AUC为0.9957,远高于9个子模型大家的融合模型AUC。这说明融合模型的子模型不是越多越好。
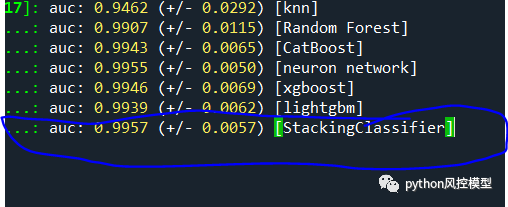
10.融合模型提升技巧-删除最弱子模型,融合模型可以提升
我们在实验融合模型时,可以先尽可能增加子模型数量,然后观察哪些子模型性能较弱,删除明显拖后腿的子模型,融合模型可以提升。如下图决策树子模型AUC为0.91,高斯贝叶斯AUC为0.98,明显低于其他子模型性能,删除这两个子模型后,融合模型AUC从0.9953提升到0.9957。我们在诸多实验中,发现决策树和高斯贝叶斯模型性能太差,当然这可能和我们实验样本有关。不排除在某些数据集上,这两个算法有良好表现。
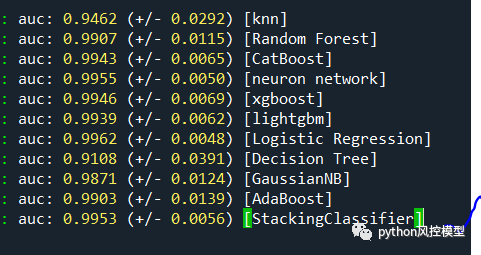
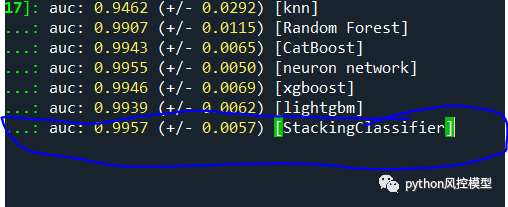
11.融合模型提升技巧-预测的类概率用于元模型训练
元分类器可以在预测的类标签上训练,也可以在预测的类概率训练。我们用level1模型预测的类概率到level2元模型里,可以得到更好融合模型性能。如果用预测的类标签效果,融合模型效果很差。
这逻辑很简单,大家思考一下,类标签结果很少,如果是二分类模型,类标签只有0和1;如果我们选择概率预测,结果是从0-1的小数。因此类概率得到多样性可以很好让模型学习,提升模型性能。
大家只要把设置use_probas=True,就可以设置类概率用于元模型训练。
sclf = StackingClassifier(classifiers=[clf1,clf2,clf3,clf4,clf5,clf6],
meta_classifier=lr,use_probas=True)12.融合模型提升技巧-多样性实验
某些理论称子模型之间的差别越大、彼此之间就越独立,融合模型提升空间越大。这理论可以解释,元模型一般为逻辑回归,逻辑回归要求去掉相关性高的变量。
多个高相关性变量有时候反而拖累模型性能。当子模型相关性越低,逻辑回归发挥空间越大。集成树算法对变量相关性要求没有这么高,可以适当放松一些。大家可以实验一下,如果元模型为集成树算法,子模型独立性要求还是否成立?
上述只是理论,实际测试中差异较大,各位学员以实际测试为准,这里只做参考。
我看了菜菜老师视频,她对多样性解释很细致,具体如下:
12.1.样本多样性:使用相同变量建模,但每次训练时抽样出不同的样本子集进行训练。当数据量较小时,抽样样本可能导致模型效果急剧下降。
12.2·变量多样性:使用相同变量矩阵,但每次训练时抽样出不同的特征子集进行训练。当特征量较小时,抽样特征可能导致模型效果急剧下降。
我们可以使用pipeline封装方法获取数据集的部分变量来训练。
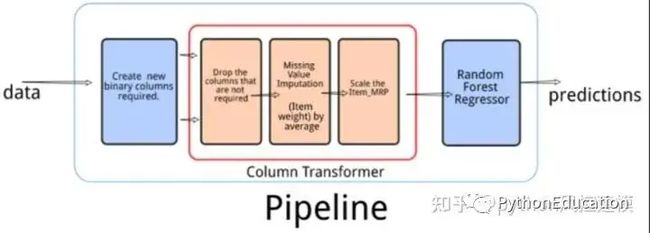

12.3·随机多样性/训练多样性:使用相同的算法,但使用不同的随机数种子random_state((会导致使用不同的特征、样本、起点)、或使用不同的损失函数、使用不同的不纯度下降量等。
12.4·算法多样性:增加类型不同的算法,如集成、树、概率、线性模型相混合。但需要注意的是,模型的效果不能太糟糕,无论是投票还是平均法,如果模型效果太差,可能大幅度降低融合的结果。
13.融合模型提升技巧-速度提升
融合模型使用交叉验证,速度非常慢。如果遇到小的数据集还好;如果遇到大的数据集,需要慎重选择子模型。假设我们数据集非常大,又想节约时间,SVM和catboost算法可以去掉,这两个子模型非常耗时。SVM对大的数据集需要很长时间训练,catboost是对称树算法,训练数据也很耗时。
数据集中噪音变量或意义不大变量可以删除,这样可以减少数据集维度,提升模型训练时间。
Python读取Excel表格数据速度要慢于csv数据,我们尽量调用pandas的read_csv()函数读取数据,这样可以节省大量时间。如果数据集特别大,也可用pickle包保存,读取时候速度较快。
总之,变量筛选,算法筛选,csv数据读取这3个方面都可以提升融合模型训练速度。
14.融合模型提升技巧-数据标准化处理
数据集方差较大时,我们子模型预测能力有很大差异。在医疗领域,数据集方差很小,比如年龄,血常规检测,数值一般从0-100分布。但在金融领域,数据方差非常大,比如张三月收入是5000元,比尔盖茨月收入是5000亿。当数据方差较大时,子模型较多独立性较强时,我们需要对数据标准化处理,缩小数据方差。如果子模型都是集成树算法,就不需要数据标准化处理。Toby老师一般优雅的称数据标准化处理为平滑处理,处理后数据更加顺滑,不会大起大落。
Python处理代码很简单,调用sklearn包的preprocessing.scale()函数即可
from sklearn import preprocessing
X= preprocessing.scale(X)stacking融合模型成功案例
stacking融合模型成功案例1-乳腺癌细胞数据集
乳腺癌细胞数据集有三十多个变量,用于建立乳腺癌细胞识别模型。
威斯康辛乳腺癌数据集,Toby老师用knn,Random Forest,CatBoost,neuron network,xgboost,lightgbm六个子模型大家stacking融合模型,融合模型AUC高于所有子模型。

Toby老师用knn,Random Forest,CatBoost,neuron network,xgboost,lightgbm,svm七个子模型搭建的融合模型,融合模型的accuracy高于任何子模型。
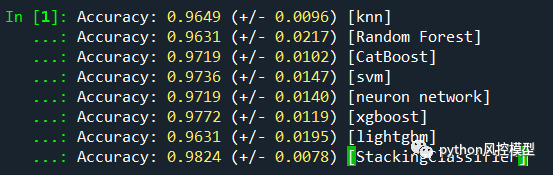
Toby老师用knn,Random Forest,neuron network,xgboost,svm五个子模型搭建的融合模型,融合模型f1分数性能高于任何子模型。
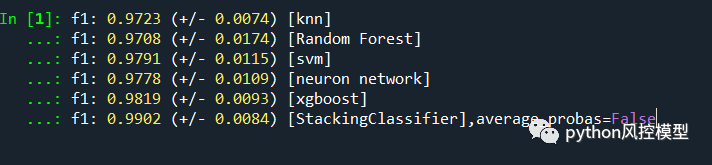
乳腺癌十大经典机器学习建模代码和完整融合模型代码可以通过《python机器学习-乳腺癌细胞挖掘》获取。
stacking融合模型成功案例2-天池糖尿病数据集
天池糖尿病数据集用于建立糖尿病风险预测模型,有几个个变量,数据量5000多。
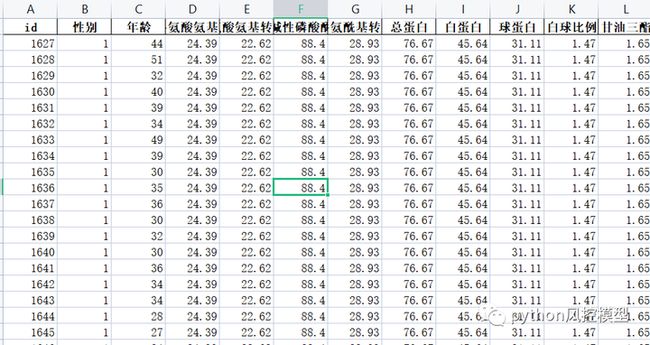
Toby老师用Random Forest,adaboost,gradientboost 3个子模型搭建的融合模型,融合模型f1分数性能高于任何子模型。
融合模型f1分数性能提升比AUC容易得多,而且不需要太多子模型。
Toby老师用Random Forest,adaboost,xgboost 3个子模型搭建的融合模型,融合模型auc分数性能高于任何子模型。在建模前,Toby老师用中位数填充缺失数据,做了一定数据预处理后,才有此效果。

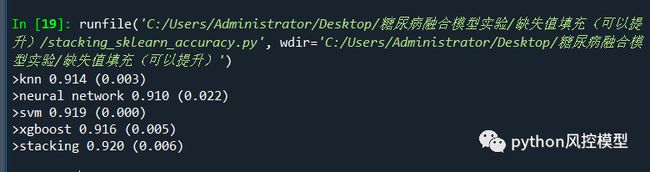
天池糖尿病数据集在accuracy准确率提升方面比较难,Toby老师花了大量时间实验,先用中位数填充缺失值,然后用knn,neuron network,xgboost,svm四个子模型搭建的融合模型,融合模型accuracy分数性能高于任何子模型。
这四个子模型算法原理差异大,保证了算法多样性,实验效果也不错。
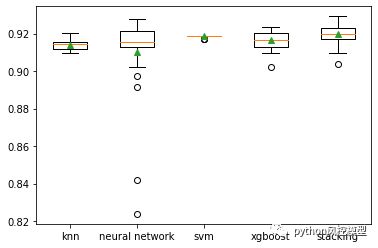
下图是Toby老师对子模型和融合模型accuracy指标的可视化,主要由箱型图体现。我们看到融合模型accuracy最高。
stacking融合模型成功案例3-lending club数据集
lending club是美国知名金融科技公司,有120多个变量,数据量上百万,共十年左右数据集。属于金融风控领域数据集,适用于银行,消费金融公司,助贷公司,金融科技公司。
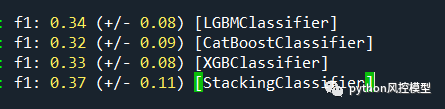
Toby老师仅用lightgbm,catboost,xgboost三个子模型搭建融合模型,显著提升f1分数。
由于lendingclub数据集比较大,Toby老师时间有限。如何用Toby老师传授经验来提升accuracy和AUC就当成大家课后作业来完成。
如果大家对lending club机器学习建模感兴趣,可以通过《python风控建模实战lendingClub》
获取。
stacking融合模型成功案例4-联想子公司翼龙贷p2p数据集
翼龙贷已在全国一百多个地级市设立运营中心,覆盖上千个区、县及近万个乡镇,并将在全国众多的一、二线城市建立全国性的服务网络。通过这一平台,可以帮助信用良好的且有不同需求的人群解决资金短缺问题,同时能够为有财富增值需求的客户将手中的富余资金进行较高回报的投资。翼龙贷主要贷款对象为帮助三农家庭、个体工商户、小微企业主。由于金融监管要求,P2P必须转型,目前翼龙贷放款已经逐步减少。
Toby老师仅用lightgbm,catboost,xgboost三个子模型搭建融合模型,显著提升f1分数。
stacking融合模型成功案例5-克罗恩致病基因挖掘模型
克罗恩病,又称局限性肠炎、局限性回肠炎、节段性肠炎和肉芽肿性肠炎,是一种原因不明的肠道炎症性疾病,在胃肠道的任何部位均可发生,但多发于末端回肠和右半结肠。和慢性非特异性溃疡性结肠炎两者统称为炎症性肠病(IBD)。临床表现为腹痛、腹泻、肠梗阻,伴有发热、营养障碍等肠外表现。病程多迁延,反复发作,不易根治。尚无根治的一般方法,许多病人出现并发症时,需进行手术治疗。复发率与病变范围、病症侵袭的强弱、病程的延长、年龄的增长等因素有关。
很多名人都有克罗恩疾病患病史,
1.NBA现役骑士队当家球员小拉里·南斯是曾经的NBA扣篮王老南斯的儿子,继承父志在球场上驰骋的他就是一名克罗恩病患者。小南斯15岁时换上克罗恩病,这种病让小南斯的食欲大减、精神不振,开始变得嗜睡,没有精力投入到篮球和学业中去,同时直接导致了他身高停止增长,一度让他产生放弃篮球的念头。
2.2004年时,时任美国波士顿市市长梅尼诺在观看棒球比赛时,因为吃花生米而导致剧烈腹痛,送医就诊后也被确认患上了克罗恩病。
3.最知名的是二战时期的盟军最高统帅、五星上将,后来的美国总统艾森豪威尔,在竞选开始前6个月,他接受了克罗恩病手术。

4.被追授为“时代楷模”的中科院上海药物研究所研究院、博导王逸平生前就长期遭受克罗恩病的折磨,从1993年确诊到2018年因病去世,25年间王逸平带病坚持搞科研,与死神争夺时间,身后留下的是一个中药现代化的光明图景。

得了克罗恩病的痛苦,是一般人所无法知道的。克罗恩病的症状包括慢性腹泻、腹痛、体重减轻、食欲不振、发烧和直肠出血、肠梗阻、关节痛等,严重影响生活质量。患者会因吃不下饭和腹泻而导致身体虚弱,会因关节疼痛而无法运动,会完全改变饮食习惯。加上自身不能控制的频繁如厕和排气,连正常的社会交往都会存在障碍。Toby老师以为克罗恩病非常罕见,但随着数据查询,发现该病患病率逐年上升,哔哩哔哩就有很多自称克罗恩疾病患者,发视频分享他们患病生活。
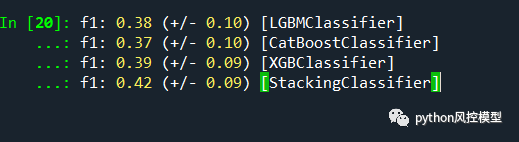
Toby老师仅用lightgbm,catboost,xgboost三个子模型搭建融合模型,提升accuracy准确率。
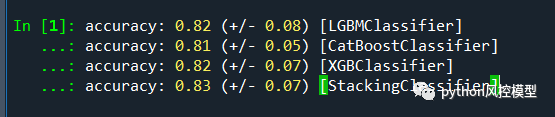
Toby老师还通过数据挖掘,找出克罗恩致病的高危基因,后续有时间再为大家介绍。Toby和中科院教授合作过慢病项目,看着曾经罕见病逐年增多,不得不感叹,大家各自保重,爱惜自己身体,工作恰到好处,不要太拼了。
Toby老师还有更多stacking融合模型成功案例,后续会陆续更新。欢迎大家关注和收藏课程《python金融风控评分卡模型和数据分析微专业课》。
版权声明:文章来自公众号(python风控模型),未经许可,不得抄袭。遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。