深度学习模型训练的一些小技巧(过拟合如何处理,超参数的选取)
四、本轮学习中学到的一些小技巧:
1.过拟合问题如何处理
过拟合是指模型对训练数据拟合程度过当的情况,反映在评估指标上,就是模型在训练数据上表现很好,但是在测试数据和新数据上表现较差。换句话说,从误差=偏差+方差+噪声的角度去思考,过拟合指的就是偏差在可接受范围内而方差过高的现象,造成模型在训练数据上几乎完美,而在新数据上预测结果可能跟真实值相差过大
过拟合产生的原因:
1.训练次数epoch较多
2.数据量太小
3.数据质量很差:噪声较多
4.模型的复杂度太大,或者模型不适用
5.训练集和测试集样本的分布不同
6.特征太多,多于样本的大小
如何解决过拟合问题:
1. 模型层面 : 主要是减小模型的复杂度,减少参数个数和参数值
a. L1,L2正则化
具体内容可以参考这一篇文章 http://t.csdn.cn/pz9hK
可以直接在添加卷积层的时候加入到模型中
model.add(tf.keras.layers.Conv2D(filters=256, kernel_size=[3, 3],
strides=1,activation='relu',padding='SAME',
kernel_regularizer=tf.keras.regularizers.l2(0.0005)))
b. Dropout()
这个函数在深度学习里面也是十分常见,dropout是指在神经网络中丢弃掉一些隐藏或可见单元。通常来说,是在神经网络的训练阶段,每一次迭代时,都会随机选择一批单元,让其被暂时忽略掉,所谓的忽略是不让这些单元参与前向推理和后向传播。但是在测试阶段仍然使用这些神经元,
model.add(tf.keras.layers.Dropout(0.4)) # ()括号的是每次随机忽略神经元的比例
c. BatchNormalization()
Batch Normalization是2015年提出的一种方法,在进行深度网络训练时,大都会采取这种算法,主要解决了:深度神经网络随着网络深度加深,训练起来越困难,收敛越来越慢的问题。机器学习领域有个很重要的假设:独立同分布假设,BatchNorm就是在深度神经网络训练过程中使得每一层神经网络的输入保持相同分布的
model.add(tf.keras.layers.BatchNormalization())
BN层的作用还有: 防止梯度消失和梯度爆炸 以及 加快网络的训练和收敛的速度
d. 权值衰减decay
权值衰减——weight_decay,简单的理解就是乘在正则项的前面的系数,目的是为了使得权值衰减到很小的值,接近如0。一般在深度学习好中,tensorflow或pytorch的提供的优化器都可以设置的。
optimizer = tf.keras.optimizers.SGD(learning_rate=learning_rate,
decay=1e-6, momentum=momentum, nesterov=True)

加入BN Dropout 激活函数 卷积的一般顺序。
2. 数据层面
a、保证数据集分布一致性
在切分数据集的时候要保证分布一致性。可以使用sklearn包中,model_selection相关train_text_split来实现数据集切割后分布的一致性。
b、增加数据集的规模
可以采用一定的数据增强策略,来实现数据集的扩充。注意的是这里可能会引入一定的噪声,噪声也会影响模型的性能的,要注意利弊的取舍。另外CV和NLP的数据增强是不一样的,NLP数据增强更难。常见的数据增强有一下几个常用的方法。
datagen = ImageDataGenerator(
rotation_range=15, # 图片可能在(-15,15)度内旋转
width_shift_range=0.05, # 图片可能在左右比例(-0.05,0.05)(百分比)内水平移动
height_shift_range=0.05, # 图片可能在上下比例(-0.05,0.05)(百分比)内水平移动
shear_range=0.05, # 图片可能以比例(-0.05,0.05)内错切变换
zoom_range=0.1, # 图片可能以比例(-0.1,0.1)内缩放
horizontal_flip=True, # 图片可能水平翻转
fill_mode='nearest') # 图片填充模式为 aaaabcdeghhhhhh
)
datagen.fit(x_train)
3. 训练层面
对模型实施early-stopping。神经网络的训练过程中我们会初始化一组较小的权值参数,随着模型的训练,这些权值也变得越来越大了.或者根据经验一次训练一小部分个epoch,然后凭借已有的loss图像考虑要不要再次训练。
注意事项
如果上述方法同时使用的情况:顺序考虑一般是:
CONV/FC -> BatchNorm -> ReLu(or other activation) -> Dropout -> CONV/FC ->
2.超参数的选取
batchsize(批大小):
当batch_size设置为2的次幂时能够充分利用矩阵运算效果会较好。当数据集的数据较多的时候一般选择64,128效果较为优秀。

a. 大的batchsize 减少训练时间,提高稳定性。 这是肯定的,同样的epoch数目,在性能允许情况下,大的batchsize需要的batch数目减少了,所以可以减少训练时间。另一方面,大的batch size梯度的计算更加稳定,因为模型训练曲线会更加平滑。在微调的时候,大的batch size可能会取得更好的结果。
b, 过大的batchsize 泛化能力下降。 在一定范围内,增加batchsize有助于收敛的稳定性,但是随着batchsize的增加,模型的性能会下降。
c, 同样是通过对训练步数的影响,小的batch_size使模型迭代次数增多,提前到达拟合点,但是epoch没结束,继续学习训练数据,容易导致过拟合于原始数据
epoch(训练次数):
从小批量开始训练,一次20次左右,观察训练集和测试集的acc&&loss图像。
如果loss一直在下降就继续训练,通常来说大的batchsize需要大的epoch达到收敛。


learning_rate(学习率):


• 学习率高的话,模型学习数据时间加快,提前到达拟合点,但是epoch没结束,继续学习训练数据,容易导致过拟合于原始数据。
• 从公式就可以看出,学习率越大,输出误差对参数的影响就越大,参数更新的就越快,但同时受到异常数据的影响也就越大,很容易发散。
• 因此选择lr,也就是不断试的过程,基本范围大概就是0.1,0.01,0.001,0.0001这样子,一个数量级一个数量级的尝试就可以了,直到找到最优的学习率。一般选择较大的学习率开始训练然后随着迭代的次数使学习率不断减小,使得模型的loss逐渐稳定。
decay的重要性:
decay 是学习率衰减率,公式如下图。
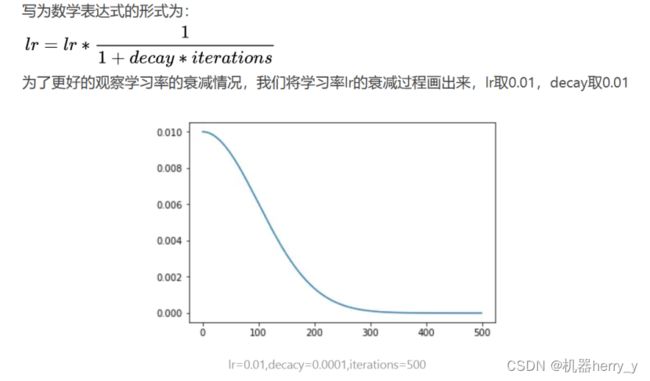
• 如果在整个梯度下降过程中,保持learning rate不变,如果learning rate设置小了,会导致梯度下降过慢,如果设置大了,对于mini-batch来说最后就很难收敛,一直在最小值附近盘旋。所以动态改变learning rate很重要,在开始的时候,设置较大的learning rate,可以保证梯度下降的速度,慢慢减小,可以使最后的cost function在最小值非常小的范围内盘旋,得到一个比较满意的值。
• 学习率过大,在算法优化的前期会加速学习,使得模型更容易接近局部或全局最优解。但是在后期会有较大波动,甚至出现损失函数的值围绕最小值徘徊,波动很大,始终难以达到最优。所以引入学习率衰减的概念,直白点说,就是在模型训练初期,会使用较大的学习率进行模型优化,随着迭代次数增加,学习率会逐渐进行减小,保证模型在训练后期不会有太大的波动,从而更加接近最优解。
3.关于不同loss&&val_loss变化的处理方法:
观察损失图像:
• train loss 下降⬇,val loss下降⬇,说明网络仍在学习;奈斯,继续训练
• train loss 下降⬇,val loss上升⬆,说明网络开始过拟合了; 赶紧停止,然后数据增强、正则、Dropout。
• train loss 不变,val loss不变,说明学习遇到瓶颈;调小学习率或批量数目
• train loss 不变,val loss下降⬇,说明数据集100%有问题;检查数据集标注有没有问题
• train loss 上升⬆,val loss上升⬆,说明网络结构设计不当,训练超参数设置不当,数据集经过清洗等问题。
loss震荡?
轻微震荡一般是正常的,在一定范围内,一般来说 Batch Size 越大,其确定的下降方向越准,引起训练震荡越小,如果震荡十分剧烈,那估计是Batch Size设置的太小。
参考文献:
1.过拟合产生的原因和方法
2.L1 L2正则化
3.BN层的原理及其作用
4.学习率和batchsize的选取
5.关于不同loss&&val_loss变化的处理方法