YOLOv8 训练自己的数据集
本范例我们使用 ultralytics中的YOLOv8目标检测模型训练自己的数据集,从而能够检测气球。
#安装
!pip install -U ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simpleimport ultralytics
ultralytics.checks()一,准备数据
公众号算法美食屋后台回复关键词:yolov8,获取本文notebook源代码和数据集。
训练yolo模型需要将数据集整理成yolo数据集格式。然后写一个yaml的数据集配置文件。
yolo_dataset
├── images
│ ├── train
│ │ ├── train0.jpg
│ │ └── train1.jpg
│ ├── val
│ │ ├── val0.jpg
│ │ └── val1.jpg
│ └── test
│ ├── test0.jpg
│ └── test1.jpg
└── labels
├── train
│ ├── train0.txt
│ └── train1.txt
├── val
│ ├── val0.txt
│ └── val1.txt
└── test
├── test0.txt
└── test1.txt其中标签文件(如train0.txt)格式如下:
class_id center_x center_y bbox_width bbox_height
0 0.300926 0.617063 0.601852 0.765873
1 0.575 0.319531 0.4 0.551562注意class_id从0开始,中心点坐标和高宽都是相对坐标。
使用 Labelme或者 makesense标注样本可以直接导出该种类型样本。
%%writefile balloon.yaml
# Ultralytics YOLO , GPL-3.0 license
path: /tf/liangyun2/torchkeras/notebooks/datasets/balloon # dataset root dir
train: images/train # train images (relative to 'path') 128 images
val: images/val # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes
names:
0: ballonOverwriting balloon.yamlimport torch
from torch.utils.data import DataLoader
from ultralytics.yolo.cfg import get_cfg
from ultralytics.yolo.utils import DEFAULT_CFG,yaml_load
from ultralytics.yolo.data.utils import check_cls_dataset, check_det_dataset
from ultralytics.yolo.data import build_yolo_dataset,build_dataloader
overrides = {'task':'detect',
'data':'balloon.yaml',
'imgsz':640,
'workers':4
}
cfg = get_cfg(cfg = DEFAULT_CFG,overrides=overrides)
data_info = check_det_dataset(cfg.data)ds_train = build_yolo_dataset(cfg,img_path=data_info['train'],batch=cfg.batch,
data_info = data_info,mode='train',rect=False,stride=32)
ds_val = build_yolo_dataset(cfg,img_path=data_info['val'],batch=cfg.batch,data_info = data_info,
mode='val',rect=False,stride=32)#dl_train = build_dataloader(ds_train,batch=cfg.batch,workers=0)
#dl_val = build_dataloader(ds_val,batch=cfg.batch,workers =0,shuffle=False)dl_train = DataLoader(ds_train,batch_size = cfg.batch, num_workers = cfg.workers,
collate_fn = ds_train.collate_fn)
dl_val = DataLoader(ds_val,batch_size = cfg.batch, num_workers = cfg.workers,
collate_fn = ds_val.collate_fn)for batch in dl_val:
breakbatch.keys()dict_keys(['im_file', 'ori_shape', 'resized_shape', 'ratio_pad', 'img', 'cls', 'bboxes', 'batch_idx'])二,定义模型
from ultralytics.nn.tasks import DetectionModel
model = DetectionModel(cfg = 'yolov8n.yaml', ch=3, nc=1)
#weights = torch.hub.load_state_dict_from_url('https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt')
weights = torch.load('yolov8n.pt')
model.load(weights['model'])model.args = cfg
model.nc = data_info['nc'] # attach number of classes to model
model.names = data_info['names']三,训练模型
1,使用ultralytics原生接口
使用ultralytics的原生接口,只需要以下几行代码即可。
from ultralytics import YOLO
yolo_model = YOLO('yolov8n.pt')
yolo_model.train(data='balloon.yaml',epochs=10)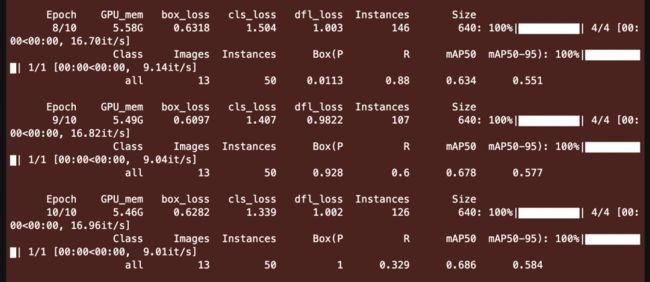
2,使用torchkeras梦中情炉
尽管使用ultralytics原生接口非常简单,再使用torchkeras实现自定义训练逻辑似乎有些多此一举。
但ultralytics的源码结构相对复杂,不便于用户做个性化的控制和修改。
并且,torchkeras在可视化上会比ultralytics的原生训练代码优雅许多。
此外,掌握自定义训练逻辑对大家熟悉ultralytics这个库的代码结构也会有所帮助。
for batch in dl_train:
breakfrom ultralytics.yolo.v8.detect.train import Loss
model.cuda()
loss_fn = Loss(model)
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-4)
x = batch['img'].float()/255
preds = model.forward(x.cuda())
loss = loss_fn(preds,batch)[0]
print(loss)tensor(74.5465, device='cuda:0', grad_fn=) from torchkeras import KerasModel
#我们需要修改StepRunner以适应Yolov8的数据集格式
class StepRunner:
def __init__(self, net, loss_fn, accelerator, stage = "train", metrics_dict = None,
optimizer = None, lr_scheduler = None
):
self.net,self.loss_fn,self.metrics_dict,self.stage = net,loss_fn,metrics_dict,stage
self.optimizer,self.lr_scheduler = optimizer,lr_scheduler
self.accelerator = accelerator
if self.stage=='train':
self.net.train()
else:
self.net.eval()
def __call__(self, batch):
features = batch['img'].float() / 255
#loss
preds = self.net(features)
loss = self.loss_fn(preds,batch)[0]
#backward()
if self.optimizer is not None and self.stage=="train":
self.accelerator.backward(loss)
self.optimizer.step()
if self.lr_scheduler is not None:
self.lr_scheduler.step()
self.optimizer.zero_grad()
all_preds = self.accelerator.gather(preds)
all_loss = self.accelerator.gather(loss).sum()
#losses
step_losses = {self.stage+"_loss":all_loss.item()}
#metrics
step_metrics = {}
if self.stage=="train":
if self.optimizer is not None:
step_metrics['lr'] = self.optimizer.state_dict()['param_groups'][0]['lr']
else:
step_metrics['lr'] = 0.0
return step_losses,step_metrics
KerasModel.StepRunner = StepRunnerkeras_model = KerasModel(net = model,
loss_fn = loss_fn,
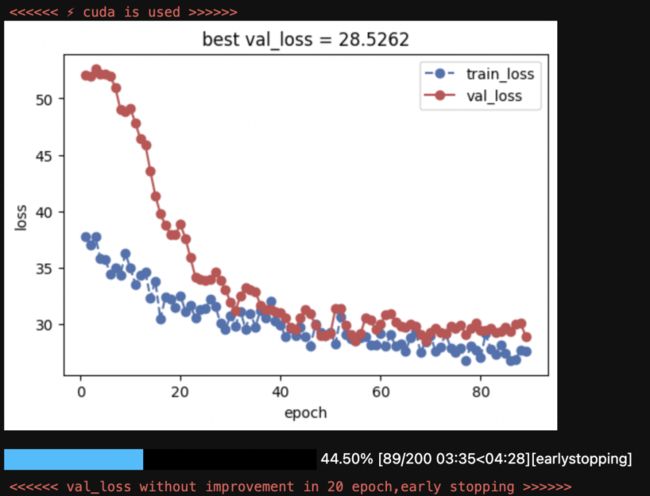
optimizer = optimizer)keras_model.fit(train_data=dl_train,
val_data=dl_val,
epochs = 200,
ckpt_path='checkpoint.pt',
patience=20,
monitor='val_loss',
mode='min',
mixed_precision='no',
plot= True,
wandb = False,
quiet = True
)

四,评估模型
为了便于评估 map等指标,我们将权重再次保存后,用ultralytics的原生YOLO接口进行加载后评估。
keras_model.evaluate(dl_val)100%|██████████████████████████████████████████████████| 1/1 [00:00<00:00, 1.32it/s, val_loss=28.7]
{'val_loss': 28.715129852294922}from ultralytics import YOLO
keras_model.load_ckpt('checkpoint.pt')
save_dic = dict(model = keras_model.net, train_args =dict(cfg))
torch.save(save_dic, 'best_yolo.pt')from ultralytics import YOLO
best_model = YOLO(model = 'best_yolo.pt')metrics = best_model.val(data = cfg.data )metrics.results_dict{'metrics/precision(B)': 0.9188790992746612,
'metrics/recall(B)': 0.74,
'metrics/mAP50(B)': 0.8516599658911874,
'metrics/mAP50-95(B)': 0.7321355695315829,
'fitness': 0.7440880091675434}import pandas as pd
df = pd.DataFrame()
df['metric'] = metrics.keys
for i,c in best_model.names.items():
df[c] = metrics.class_result(i)
df
五,使用模型
from pathlib import Path
root_path = './datasets/balloon/'
data_root = Path(root_path)
best_model = YOLO(model = 'best_yolo.pt')val_imgs = [str(x) for x in (data_root/'images'/'train').rglob("*.jpg") if 'checkpoint' not in str(x)]
img_path = val_imgs[5]import os
from PIL import Image
result = best_model.predict(source = img_path,save=True)
best_model.predictor.save_dir/os.path.basename(img_path)
Image.open(best_model.predictor.save_dir/os.path.basename(img_path))六,导出模型
best_model.export(format='onnx')from ultralytics.yolo.v8.detect.predict import DetectionPredictor
predictor = DetectionPredictor(
overrides=dict(model='best_yolo.onnx'))results = list(predictor.stream_inference(source=img_path))公众号算法美食屋后台回复关键词:yolov8,获取本文notebook源代码和数据集。