BERT,ELMO,GPT
1.BERT
bert全称bidirectional encoder representation from transformer,是使用无监督方式利用大量无标注文本形成的语言模型,其架构为tranformer中的encoder。
bert虽然利用了transformer的encoder部分,但是其在部分中还是略有不同。
1.embedding
bert的embedding由三种embedding求和而成:
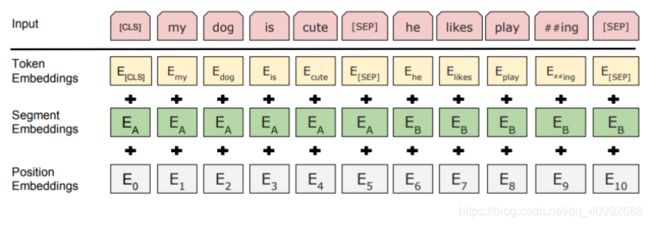
token embedding是词向量,也就对应了transformer中的词嵌入部分,这里第一个位置上的标记是CLS,用于之后的分类任务
这里面之所以可以将三者相加,本质上是因为大矩阵的乘法等于将矩阵切分成小的矩阵分别进行乘法,然后结果相加。
我们是把不同向量的one-hot给cancatenate起来后过的一个全连接层。
我们实际上还是对不同部分的权重矩阵做了训练。
2.bert的两个任务
Masked Language Model
我们知道bert使用的是transformer的encoder部分,但是encoder部分会将整个ground truth暴露出来,于是bert对应的使用了Mask遮盖部分单词,这样我们在预测mask部分的时候,实际上是同时使用了上下文信息的,这也就是所谓的“双向”的含义。
那么MLM是怎么做的呢?
1.随机把一句话中15%的token替换为以下内容:
①80%几率被替换为[mask]
②10%几率被替换为任意一个其他的token
③10%几率原封不动
为什么这么做,原文作者并没有说,但是我们可以合理推断,使用这3种多样的替换方式能够使得模型有更好的抗噪能力,如果全部使用mask,由于在预测的时候实际上是并不存在这个分类的,就会造成一定的mismatch。
之后我们使用模型预测和还原被遮盖或者替换掉的部分,经过encoder得到的向量维度为(batch_size, sequence_length, embedding_size),得到后我们将其乘以一个(embedding_size, vocab_size)的矩阵,得到(batch_size, sequence_length, vocab_size)的矩阵,再过一个softmax就可以对每个单词进行预测,不过这里需要注意的是,我们只对于遮盖部分计算损失。
从这里也可以看出,bert的目的是最大化概率:
![]()
这与ELMO的目的:
![]()
是大不相同的。
Next Sentence Prediction
首先我们要取得属于上下文的一对句子,然后在两个句子的中间和句末加入分隔符[sep],句首需要加入[CLS]
这个任务实际上是因为设计了QA和NLI的任务而设计,目的是使得模型能够理解两个句子之间的联系。
这里我们需要准备1:1的两种句子对,分别是满足上下文和不满足上下文的,最终使用[CLS]向量进行预测。
为什么要用CLS做分类呢,这是因为,CLS本身是没有任何意义的,如果我们使用其他任意一个有意义的单词做分类,则最终会导致这个单词更看重本身,这样的向量来代表一个句子显然是不对的。
需要注意的是,损失函数是两者的和。
2.ELMO
elmo即embedding form language model,他是通过无监督的方式对语言模型进行预训练来学习单词表示。

elmo希望最大化的概率为:
![]()
在之前2013年的word2vec及2014年的GloVe的工作中,每个词对应一个vector,对于多义词无能为力。ELMo的工作对于此,提出了一个较好的解决方案。不同于以往的一个词对应一个向量,是固定的。在ELMo世界里,预训练好的模型不再只是向量对应关系,而是一个训练好的模型。使用时,将一句话或一段话输入模型,模型会根据上线文来推断每个词对应的词向量。这样做之后明显的好处之一就是对于多义词,可以结合前后语境对多义词进行理解。
ELMO使用正向和反向的多层LSTM,最终某个单词的向量由这些层的拼接构成,而权重参数是通过学习一个向量的来的。
3.GPT
gpt使用了单向的transformer block,即其利用了masked self attention,是单向的,其目的只是为了最大化概率:
![]()
训练过程也非常简单,即将词嵌入加上学习的位置嵌入送到transfomer中,分别去预测下一个单词。
