低延迟流式语音识别技术在人机语音交互场景中的实践
美团语音交互部针对交互场景下的低延迟语音识别需求,提出了一种全新的低出字延迟流式语音识别方案。本方法将降低延迟问题转换成一个知识蒸馏过程,极大地简化了延迟优化的难度,仅通过一个正则项损失函数就使得模型在训练过程中自动降低出字延迟。在实验测试集上,本方法能够获得最高近 200 毫秒左右的平均出字延迟降低。
-
1. 前言
-
1.1 语音识别技术简介
-
1.2 问题与挑战
-
-
2. 尖峰优先正则化方法
-
2.1 CTC 模型基础
-
2.2 尖峰优先正则化方法描述
-
2.3 梯度分析
-
-
3. 相关工作
-
3.1 强制对齐方法
-
3.2 路径分解方法
-
3.3 最小贝叶斯风险方法
-
3.4 自对齐方法
-
-
4. 评价指标
-
4.1 字错误率
-
4.2 平均尖峰延迟(平均出字延迟)
-
4.3 PR50/PR90
-
-
5. 实验与分析
-
5.1 实验与模型搭建
-
5.2 出字延迟比较
-
5.3 可视化分析
-
-
6. 总结与展望
1. 前言
| 1.1 语音识别技术简介
人机交互一直都是人工智能大背景下的“热门话题”,语音交互作为人机交互的一个重要分支,具有广泛的应用价值,也被应用到美团的多个业务场景中,如智能客服、电话营销和电话满意度反馈等。而流式语音识别技术是整个交互链条的入口,对交互体验影响巨大。
常见的语音识别大多都是非流式语音识别技术,它是指模型在用户说完一句话或一段话之后再进行识别。这意味着模型需要等待用户停顿或结束说话才能开始识别,并且只能在用户停顿或结束说话后才能输出完整的识别结果。这样做的缺点是会导致较长的延迟和不连贯的交互。例如,在会议场景中,如果使用非流式语音识别技术,就可能出现会议参与者说了很长时间的话才显示出他们所说的内容,而且可能因为网络延迟或其他原因导致内容显示不全或错误。这样就会影响会议参与者之间的沟通和理解,并且降低会议效率和质量。
而与之对应的是流式语音识别技术,它是指可以在处理音频流的过程中,支持实时返回识别结果的一类语音识别模型。这意味着模型不需要等待用户说完整句或整段话就可以开始识别,并且可以随着用户说话的进度逐渐输出识别结果。这样做的好处是能够大大减少人机交互过程中语音识别的处理时间,提高用户体验和交互效率。例如,在智能客服场景中,使用流式语音识别技术,就可以实现用户说一句话很快就能获得机器人响应,而不是等到用户说完一段话才给出回答。这样就可以让用户更快地得到满意的解决方案,并且减少用户的等待时间和不满情绪,提升用户满意度。在美团内部的众多业务场景中广泛使用了流式语音识别技术。
本文将详细阐述团队在语音交互场景中的低延迟流式语音识别方案,目前以该方案形成的技术论文《Peak-First CTC: Reducing the Peak Latency of CTC Models by Applying Peak-First Regularization》已经被语音领域国际顶级会议ICASSP 2023收录。
| 1.2 问题与挑战
对一个好的流式语音识别系统而言,不仅仅需要高的识别准确率,还应该具有很低的延迟。在交互场景中,低延迟可以提高用户体验和满意度,让用户感觉不到语音识别的处理时间,更加自然和流畅地进行对话和问答。低延迟也可以减少通话交流中的误解和冲突,让用户能够及时地收到反馈结果,避免重复或打断对方的说话。此外,低延迟还可以增加语音应用的可用性和灵活性,让用户能够在各种场景下通过说话来完成任务(例如在线游戏、语音助手、智能家居等),节省下来的延迟也可以用于在语音服务的上下游部署更加复杂的模型结构,从而进一步完善交互链路等。
在美团的交互场景中,广泛使用联结时序分类模型(Connectionist Temporal Classification, CTC )作为基础模型来构架流式语音识别系统。CTC 模型由于其优雅的模型结构、卓越的模型表现以及良好的扩展性受到了广泛的青睐。目前已经广泛应用在语音识别(Automatic Speech Recognition, ASR)、语音翻译(Speech Translation, ST) 以及 光学字符识别(Optical Character Recognition, OCR)等领域。
下图展示了一种典型的 CTC 模型结构,其依赖 DFSMN 网络结构搭建,仅包含声学编码器(Acoustic Encoder)和输出线性映射层两部分。声学编码器用来将输出的声学特征序列转变成声学编码序列,而输出线性映射层则负责将利用声学编码表示,计算得到模型预测出不同文本标记的概率值。对比其他流式语音识别模型,CTC 模型不需要复杂的编码解码(Encoder-Decoder)结构或者注意力机制(Attention Mechanism)就能实现两个不等长序列之间的转换(对于语音识别而言是从声学特征序列转换到目标文本序列)。

基于 CTC 的流式语音识别系统对于延迟也有着非常高的要求。从用户发音结束到系统识别出对应文字之间的时间差被称之为出字延迟。出字延迟越低则意味着 ASR 系统吐字的速度越快,用户体验越好。下图展示了 CTC 模型的输出概率分布,其中顶部色块表示用户说的每个文本的发声范围,而底部对应颜色的尖峰则表示系统识别出的文本所在的位置。出字延迟则对应着色块尾部与概率尖峰位置之间的时间差。本文所展示的工作就聚焦于如何降流式 CTC 语音识别系统的出字延迟。

2. 尖峰优先正则化方法
| 2.1 CTC 模型基础
CTC 模型能够直接建模了声学序列到文本序列的转换关系,而不需要注意力机制等结构。由于文本序列的长度远远小于声学特征序列(通常情况下声学特征序列以帧作为单位,相邻两帧之间间隔为 10ms,时长为 1s 的语音就可以被划分为100 帧),而在模型预测过程中,每帧特征都有一个预测标签。CTC 损失计算过程中引入了空格标记 φ 来作为填充标记符,以使得文本序列与声学序列的长度相等。
以下图(a)中所展示的 CTC 路径空间为例,其中横轴表示声学特征序列,纵轴表示目标文本序列。一条语音预测出文本序列“CAB”的概率可以被描述为后验概率P(CAB | X),为了方便计算损失,需要使用空格标记 φ 对文本标记填充,填充之后会出现与目标序列对应的多条路径(对应图3(a)中的实线与虚线,从图中左上角开始空格标记或者非空格标记开始,沿着线段转移至右下角空格或者非空格标记的路径均是一条可能的解码路径),所有路径的概率和等于后验概率 P(CAB | X)为了避免路径穷举导致的计算爆炸问题,CTC 损失计算过程实际上使用了基于动态规划思想的前后向算法,来对所有可行的解码路径进行概率求和,并最终以负对数概率作为最终损失函数来进行优化。
| 2.2 尖峰优先正则化方法描述

由于 CTC 的输出概率中蕴含着海量的可行解码路径,为了降低输出延迟,我们对所有的解码路径进行了仔细的分析和观察,如上面(a)图所示,网格中包含与文本“CAB”对应的多条可能的路径,以橙色和蓝色实线连接的路径为例,显然两条路径的转移位置存在明显区别,蓝色路径分别在,和位置预测出字符"C","A","B";而橙色路径则在 , 和 位置才预测出对应的字符。因此蓝色路径相对橙色路径具有更低的出字延迟,其从时间轴上来看,蓝色路径相对橙色路径更加靠左。基于这个观察,我们可以得出结论:具有低延迟的路径在时间轴上的非空格标记概率尖峰的位置会更加靠前一些。因此,我们提出了一个猜想,可以通过将 CTC 输出的概率分布整体左移的方式来降低模型的出字延迟。
基于这个假设,本文提出了一个简单的正则化方法--尖峰优先正则化方法(Peak-First Regularization, PFR),来使得 CTC 模型的模型输出的概率分布实现整体左移以降低出字延迟。PFR 方法巧妙使用了知识蒸馏的方法,迫使 CTC 输出概率分布的每一帧概率都学习其邻近下一帧的信息。如上图(b)所示,利用逐帧的知识蒸馏函数,使得每一帧的概率分布 都学习其后一帧,随着迭代的进行,模型实现了整体分布的左移。其损失计算过程可以被表述为以下形式:

该损失函数仅作为正则项使用,整体损失函数可以被描述为:

其中 作为权重,用来平衡两个损失之间的关系,避免输出概率持续移动最终导致训练崩溃的问题。PFR 正则项在学习过程中实际上呈现损失数值上升的态势,当输出分布不再移动的时候,损失值也趋于平衡。
虽然模型在训练过程中仅学习后面一帧(约等于40 ms)的内容,但是随着训练结果的累积,可以获得远超 40ms 的延迟降低。这样设置有三方面的考虑:
-
首先,模型在完全学习到下一帧内容后,整体分布已经左移了 40ms。再继续学习后一帧内容,可以实现延迟效果的累加。
-
其次,考虑到 CTC 的输出概率分布是稀疏的,如果学习后面第 N 帧的内容,有非常大的可能性第 N 帧是空格标记,起不到学习效果,甚至学不到时序移动的关系。
-
最后,仅学习后面一帧的内容会降低训练难度,这种情况下经过平滑后的相邻两帧之间的概率分布的相似程度比较高,比较容易直接学习。如果直接学习后面第 N 帧的内容,也容易使得模型初始情况下面临更加困难的学习环境。
| 2.3 梯度分析
虽然本文通过间接的方法来实现降低延迟的效果,但是其仍然具有一定的解释性。可以对其梯度进行分析,假如 CTC 在第 t时刻预测出第 K个标记的概率是,则其梯度可以被描述为:

其中 CTC 损失部分梯度为:

通过公式可以知道概率和它邻近下一帧的概率紧密相关,如果下一帧预测出同一个标记 的概率很大(即下一帧是一个概率尖峰),则会促使当前帧梯度发生较大变化,进而实现概率分布左移,而如果下一帧的概率很小,则对当前帧梯度影响不大,不会产生概率分布位移。
3. 相关工作
伴随着智能交互技术的发展,大家对于交互体验的要求越来越高,如何降低语音识别系统的出字延迟再次成为了研究热点,各种思路层出不穷。整体来看方法可以被归结为以下四类。
| 3.1 强制对齐方法
强制对齐(Force Alignment)方法依托外部模型提前生成强制对齐标注信息。这些信息中包含用户发音与标注文本之间的准确对齐关系,在 CTC 或者 Transducer 模型损失计算过程中对路径的延迟进行限制,对具有高延迟的路径施加惩罚,以此来实现降低延迟的目的[3,5]。这一方案将延迟作为约束引入到损失函数的计算过程中,需要修改损失函数以及梯度的计算环节。
| 3.2 路径分解方法
路径分解方法以 FastEmit 方法为代表[4],主要应用到 RNNT 模型上,其对 RNNT 损失计算过程中的每个节点进行了路径分解,在损失函数的计算过程中,对低延迟路径赋予更高的权重,进而达成了鼓励模型在空格标记和非空格标记中优先预测非空格标记来降低出字延迟的目的。
基于这种逻辑训练出来的模型具有较低的延迟。虽然该方法摆脱了对于强制对齐的依赖,可以使得模型在训练过程中自然而然得地学习到低延迟路径,但是这种方法仍然需要修改损失函数前向计算环节和修改梯度的计算公式,具体实现相对复杂。
| 3.3 最小贝叶斯风险方法
最小贝叶斯风险方法(Bayes Risk CTC)方法将延迟作为贝叶斯风险值加入到损失函数的计算过程中[6]。为了避免大量的计算,使用了分而治之的策略来将路径分组,同组内指定相同的延迟风险值。本方法虽然能够获得延迟降低,但是需要修改损失函数和梯度的计算过程,甚至需要模型方面的改动,增加了延迟优化问题的复杂度。
| 3.4 自对齐方法
自对齐方法(Self-Alignment)方法不需要修改损失函数的计算过程,而是从上一轮的模型的解码结果中选择低延迟路径,并将其作为正则项添加到本轮模型的优化过程中[7],这种方法虽然简化了计算量,但是面临新的问题,这种在线解码的方法需要消耗大量的解码时间,当面临海量数据的时候,在线解码会严重训练的进度,延缓训练流程。
综上所述,本文提出的延迟优化策略最为简单,不需要复杂的损失与梯度计算,也不依赖外部强制对齐结果,且在小数据和大规模生产数据上同样有效。
4. 评价指标
| 4.1 字错误率
字错误率(Character Error Rate, CER)用来衡量标注文本与识别文本之间的编辑距离。字错误越低则语音识别结果越好。计算公式如下:

| 4.2 平均尖峰延迟(平均出字延迟)
平均尖峰延迟(Average Peak Latency, APL)是统计的每个解码正确的概率尖峰的首帧与通过强制对齐方法获得的每个文本标签人声范围的尾帧之间的时间差的平均值。这一指标反映了系统的平均延迟水平。平均尖峰延迟越低则意味着出字延迟越低,ASR 识别系统反馈识别结果的速度越快。
| 4.3 PR50/PR90
由于真实的 CTC 预测的出字延迟分布具有长尾分布的特点,所以引入了 尖峰延迟的 50 分位数和 90 分位数来衡量延迟分布的特点。其计算方法是根据每句话的平均出字延迟进行从小到大进行排序,以整个分部中第 50% 和 90% 条句子的平均出字延迟作为指标。PR50/PR90 越低表示整个长尾分布的尾巴越短,长尾分布中尾巴部分的数据延迟越低,比例越小。
5. 实验与分析
| 5.1 实验与模型搭建
本文基于开源中文语音识别数据集 AISHELL-1 进行实验,并采用了流式和非流式两种模型进行比较验证。两个模型均为 Transformer 模型结构,包含两层 2D 卷积构建的前端特征处理模块,以及 12 层 Transformer 编码层构建的编码模块以及一个输出线性映射层。其中流式模型依赖 510ms 的声学下文。
| 5.2 出字延迟比较
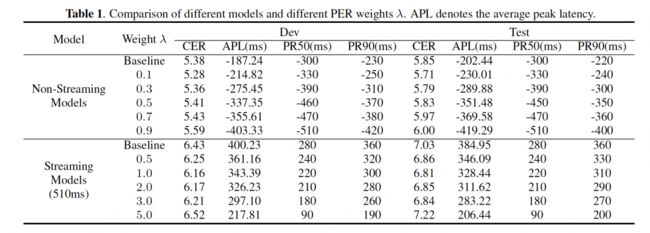
上图中分别展示了流式识别模型与非流式识别模型在开源测试集上的字准确率和延迟结果。从实验结果很容易发现,无论是非流式模型还是流式模型,采用本文提出的尖峰优先正则化方法均能够降低各种延迟指标,并且延迟的变化值与权重的设置关系密切。通过调节权重设置可以显著改变延迟的大小,权重设置越大,延迟越低。在字错误率(CER)不降低的条件下,非流式模型和流式模型在测试集中分别可以获得 149 毫秒和 101 毫秒的延迟降低,在 CER波动的可接受范围内,延迟甚至可以降低200 毫秒以上。
当权重设置比较小的时候,模型甚至能够同时获得CER 和平均延迟的降低,我们猜想造成这种现象的原因是正则化使得模型在学习邻近帧的时候同时学到了更长的声学下文信息。随着权重的变大,模型的识别错误率可能出现上升,此时权重的设置已经破坏了两个损失之间的平衡关系,模型在训练过程中会更激进地倾向于选择低延迟的路径,这种情况下会损失更多的声学下文信息,造成识别结果的衰退。
| 5.3 可视化分析

本文随后通过可视化的方式对系统的延迟变化进行分析。上图中左侧三幅图表示非流式模型的输出概率分布,右侧三幅图则表示流式模型的输出概率分布。图上方的色块与概率尖峰一一对应,便是每个标记的发声范围,而下面的概率尖峰则表示 CTC 预测到对应标记的位置与概率。
很容易发现图中非流式模型中原本每个尖峰的位置就处于其对应的发声范围中,引入尖峰优先策略后尖峰的位置甚至能够提前其发声范围。而流式模型的概率尖峰也往往滞后于其发声范围,而引入尖峰优先策略后同样可以获得较大的延迟降低效果。通过图中不同权重的参数设置也可以发现,使用较大的权重能够更大程度地降低系统延迟。
6. 总结与展望
本文通过对 CTC 的输出概率分布进行分析,将 CTC 的出字延迟问题转化为一个知识蒸馏过程。通过知识蒸馏方法将 CTC 的输出概率分布沿着时间轴左移,从而有效地降低 CTC 模型的出字延迟。本文提出的方法简单有效,不需要强制对齐标注信息,也不需要复杂的损失和梯度计算方法。此外该方法也具有一定的扩展空间,或许可以扩展到 Transducer 等语音识别模型上。
7. 本文作者
正坤、鸿雨、李敏、飞飞、丁科、广鲁等,均来自美团平台/语音交互部。
8. 参考文献
[1] Alex Graves, Santiago FernÅLandez, Faustino Gomez, and JÅNurgen Schmidhuber, “Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks,” in Proceedings of the 23rd international conference on Machine learning. ACM, 2006, pp. 369–376.
[2] Dario Amodei, Sundaram Ananthanarayanan, Rishita Anubhai, Jingliang Bai, Eric Battenberg, Carl Case, Jared Casper, Bryan Catanzaro, Qiang Cheng, Guoliang Chen, et al., “Deep speech 2: End-to-end speech recognition in english and mandarin,” in International conference on machine learning, 2016, pp. 173–182.
[3] Andrew Senior, Has.im Sak, FÅLelix de Chaumont Quitry, Tara Sainath, and Kanishka Rao, “Acoustic modelling with cd-ctcsmbr lstm rnns,” in 2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU). IEEE, 2015, pp. 604– 609.
[4] Jiahui Yu, Chung-Cheng Chiu, Bo Li, Shuo-yiin Chang, Tara N Sainath, Yanzhang He, Arun Narayanan,Wei Han, Anmol Gulati, Yonghui Wu, et al., “Fastemit: Low-latency streaming asr with sequence-level emission regularization,” in ICASSP 2021- 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 6004–6008.
[5] Yusuke Shinohara and Shinji Watanabe, “Minimum latency training of sequence transducers for streaming end-to-end speech recognition,” in Proc. Interspeech 2022, 2022, pp.2098–2102.
[6] Jinchuan Tian, Brian Yan, Jianwei Yu, Chao Weng, Dong Yu, and Shinji Watanabe, “Bayes risk ctc: Controllable ctc alignment in sequence-to-sequence tasks,” arXiv preprint arXiv:2210.07499, 2022.
[7] Jaeyoung Kim, Han Lu, Anshuman Tripathi, Qian Zhang, and Hasim Sak, “Reducing streaming asr model delay with self alignment,” arXiv preprint arXiv:2105.05005, 2021.
[8] Shinji Watanabe, Takaaki Hori, Shigeki Karita, Tomoki Hayashi, Jiro Nishitoba, Yuya Unno, Nelson Enrique Yalta Soplin, Jahn Heymann, Matthew Wiesner, Nanxin Chen, et al., “Espnet: End-to-end speech processing toolkit,” arXiv preprint arXiv:1804.00015, 2018.
---------- END ----------
美团科研合作
美团科研合作致力于搭建美团技术团队与高校、科研机构、智库的合作桥梁和平台,依托美团丰富的业务场景、数据资源和真实的产业问题,开放创新,汇聚向上的力量,围绕机器人、人工智能、大数据、物联网、无人驾驶、运筹优化等领域,共同探索前沿科技和产业焦点宏观问题,促进产学研合作交流和成果转化,推动优秀人才培养。面向未来,我们期待能与更多高校和科研院所的老师和同学们进行合作。欢迎老师和同学们发送邮件至:[email protected]。
推荐阅读
| MRCP在美团语音交互中的实践和应用
| 对话摘要技术在美团的探索(SIGIR)
| 检索式对话系统在美团客服场景的探索与实践