zookeeper学习笔记(最全)
Zookeeper
文章目录
- Zookeeper
-
- 1 Zookeeper概述
-
- 1.1 Zookeeper简介
- 1.2 Zookeeper工作原理
-
- 1.3 Zookeeper特点
- 1.4 Zookeeper数据结构
- 1.5 Zookeeper应用场景
- 2 Zookeeper本地模式安装
-
- 2.1 Zookeeper下载
- 2.2 虚拟机的克隆
- 2.3 Zookeeper安装
- 2.4 Zookeeper配置
- 2.5 Zookeeper基本操作
- 2.6 Zookeeper配置参数解析
- 3 Zookeeper内部原理
-
- 3.1选举策略
- 3.2 节点类型
- 3.3 监听器原理
- 3.4 写数据流程解析
- 4 Zookeeper集群搭建
-
- 4.1 分布式环境安装部署
- 4.2 Zookeeper集群搭建
-
- 4.1.1 配置服务的id(编号)
- 4.1.2 配置集群IP
- 4.1.3 配置其他两台服务
- 4.1.4 集群操作
- 4.2.5 集群启动的问题
- 4.3 Zookeeper客户端命令
-
- 4.3.1 客户端命令
- 4.3.2 节点操作
- 5 Zookeeper实战
-
- 5.1 Zookeeper的API应用
-
- 5.1.1 项目环境搭建
- 5.1.2 创建Zookeeper客户端
- 5.1.3 创建节点
- 5.1.4 查询节点的值
- 5.1.5 修改节点的值
- 5.1.6 删除节点
- 5.1.7 判断节点是否存在
- 5.1.8 获取子节点
- 5.1.9 监听节点的变化
- 5.2 案例-模拟美团商家上下线
-
- 5.2.1 分析需求
- 5.2.2 项目环境搭建
- 5.2.3 商家服务类
- 5.2.4 客户端
- 5.2.5 运行测试
- 5.3 案例-分布式锁商品秒杀
-
- 5.3.1 分布式锁
- 5.3.2 数据准备
- 5.3.3 搭建工程
- 5.3.4 搭建SSM环境
- 5.3.5 功能的开发
- 5.3.6 Zookeeper解决并发问题
- 6 Zookeeper总结
- 重点问题:
学习内容:
- Zookeeper技术(概念、使用场景、特点…)
- Zookeeper本地安装(在本地搭建Zookeper环境、集群的方式进行搭建)
- Zookeeper内部原理(掌握Zookeeper工作机制)
- Zookeeper实战开发(Zookeeper的API使用、美团服务监控系统、分布式秒下系统场景的搭建)
1 Zookeeper概述
1.1 Zookeeper简介
Zookeeper是一个分布式的(多台机器同时干一件事情)、开源框架,分布式应用程序的协调服务。
Google公司Chubby产品,他是Hadoop和HBase重要的组件。
它是一个分布式应用程序提供一致性的服务的软件,提供功能包括:
- 配置维护
- 域名服务
- 分布式同步
- 组服务
- …
Zookeeper目标封装了大量的复杂关键的技术(服务),将简单的接口(API)暴露、高效的使用Zookeeper,稳定性非常的高。
在大数据生态圈,Zookeeper(动物管理员)是一个非常重要的基础技术,Hadoop(大象)、Hive(蜜蜂)、Pig(小猪)。
1.2 Zookeeper工作原理
1.Zookeeper从设计模式的角度:是一个基于观察者设计模式(一个人干活,有人在盯着他干活)一个分布式的服务管理框架。
2.它负责存储和管理数据。
- 接收观察者进行注册
- Zookeeper就可以将负责注册好的服务通知给客户端
- 从服务器集群中进行主节点和从节点的管理模式(Master、Slave)。
3.Zookeeper = 文件系统 + 通知机制。
- 商家营业后需要入驻
- 获取到当前正在营业的所有饭店和餐馆列表
- 服务节点下线
- 服务节点下线的事件通知
- 重新去获取最新的服务列表

1.3 Zookeeper特点
分布式和集群区别?
-
无论分布式或者是集群,都是很多服务在一起工作。
-
开了一家餐馆,生意不错,我需要进行招聘:
(1)分布式:招聘了个员工,1个是服务员、1个是厨师、1个收银员,3个员工服务的工作不一样,但是最终的目的是一致的。
(2)集群:招聘了三个服务员,3个服务员做的事同一件事物。
Zookeeper特点主要有下面几个:
-
1.是一个leader和多个follower来组成的集群(例如:在狮群中,一头雄狮和N头母狮)。
-
2.集群中只要有半数以上的节点存活, Zookeeper就能正常工作(5台服务器挂掉2台,没问题; 4台服务器挂掉2台,就停止)。
-
3.全局数据一致性,每台服务器都保存一份相同的数据副本,无论Client连接哪台Server,数据都是一致的。
-
4.数据更新原子性,一次数据要么成功,要么失败(不成功便成仁)。
-
5.实时性,在一定时间范围内,Client能读取到最新数据。
-
6.更新的请求按照顺序执行,会按照发送过来的顺序,逐一执行(发来123 ,就执行123 ,而不是321或者别的)。
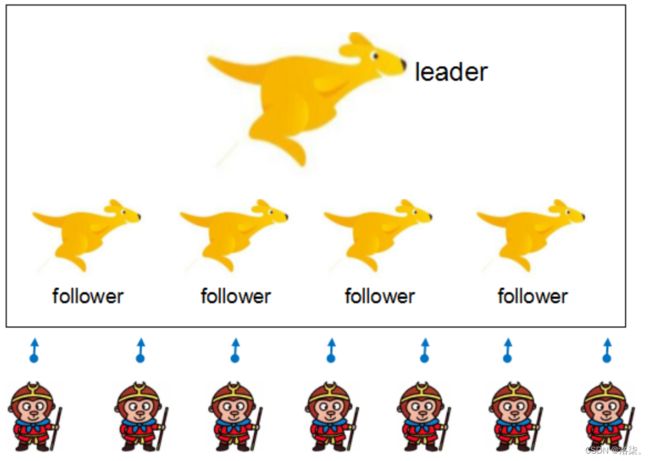
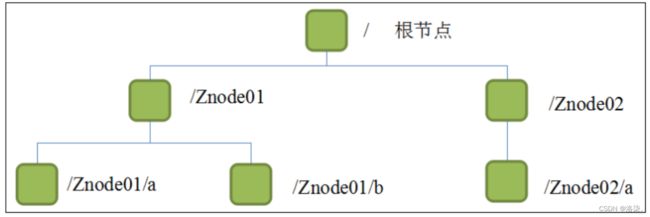
1.4 Zookeeper数据结构
1.Zookeeper数据模型类型与Linux操作系统的文件结构,整体上可以看作是一个倒挂着的树。每一个节点称之为是一个ZookeeperNode。
2.每一个ZNode是用来保存数据,默认情况下每一个节点的保存数据大小为1MB(元数据)
3.Zookeeper元数据:表示用来描述数据的数据。又称之为中介数据、中继数据,data about data。主要是用来描述数据的属性信息(这个数据文件的:大小、创建实现、存放位置、历史访问记录、文件记录等)。
1.5 Zookeeper应用场景
提供服务服务:
- 统一命名服务(域名)
- 统一配置管理(监听完成同步更新)
- 统一集群管理
- 服务节点动态上下线
- 软负载均衡(请求被均匀的发布到集群中的每一台服务器上)
1.统一命名服务
在分布式的环境下,通常可以对应用程序或者服务器通过一个统一的命名来识别进行访问。
例如:服务器的IP地址基于非常的困难,可以通过指定一个域名的形式来进行访问,便于记忆。
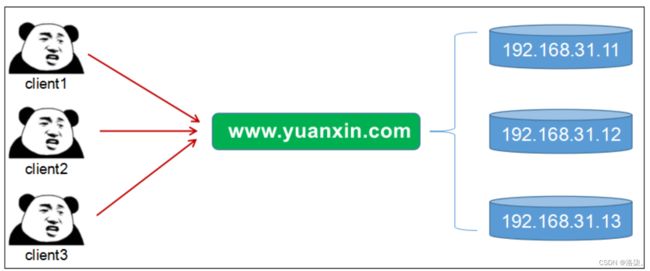
2.统一配置管理
在分布式的环境下,配置文件做同步更新操作,可以通过监听来完成。
举例:1000台服务器,如果要去逐一修改这1000台服务器中的数据,运维人员可能会被逼疯,如果有一个节点专门用于维护全局的数据,然后让其他的节点来监听该节点,一旦该节点中的数据发生改变,同步到其他集群中的所有节点上。
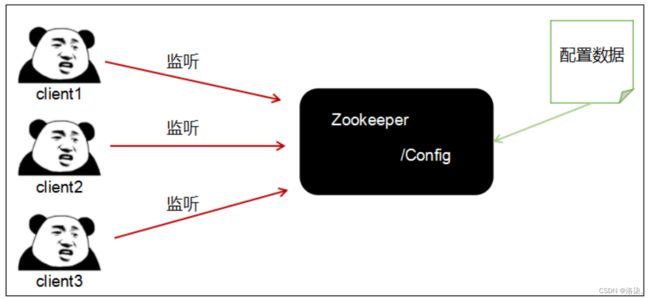
Zookeeper管理配置文件:
- 将配置文件写入到Zookeeper的某个节点上(需要有一台服务器来维护这个配置文件)
- 告知客户端去监听这一台服务器上的这个文件(/Config)
- 一旦该节点上的这个文件中的数据发生了改变,Zookeeper就可以通过通知来告诉所有的客户端,客户端即完成了同步(数据同步)
3.服务节点动态上下线
客户端能够实时的获取服务器的状态,服务器上下线的状态。服务器实现的运行状态可以被Zookeeper获取(心跳机制)。
例如:在美团的APP上实时看到最新的商家营业的情况,是否处于打烊的状态。
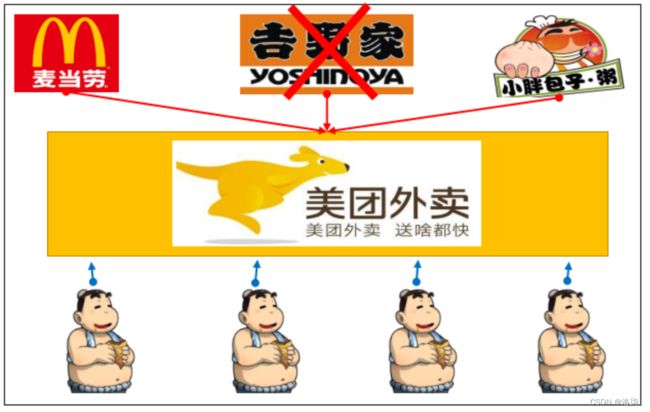
4.软负载均衡
Zookeeper会记录每一台服务器访问的次数,让访问最少的服务器去处理最新的请求,请求被均匀分发到集群中每一台服务器是上(雨露均沾的效果)。

2 Zookeeper本地模式安装
Zookeeper是使用Java语言开发,Zookeeper看作是一个Java的应用程序。依赖于JDK的环境。前提条件是需要在Linux系统上安装JDK(>=1.8)。
2.1 Zookeeper下载
1.CentOS7安装Java的JDK。
2.Zookeeper镜像库下载地址:http://archive.apache.org/dist/zookeeper。
- 包含bin:此安装包中包含了所有的Zookeeper相关的依赖jar,直接下载后解压就可以使用。
- 不含bin:必须在Linux系统上安装Maven工具,然后通过Maven去下载Zookeeper关联的依赖jar。
2.2 虚拟机的克隆
1.必须要把目标的虚拟关闭状态,进行克隆。在虚拟机上右键【管理】-【克隆】-【完整克隆】。将可能的目录目标主机放在zk_vm/zk01文件中(一台Linux系统)。
2.克隆完成后,启动这台虚拟机。
2.3 Zookeeper安装
1.xft将zookeeper安装包上传到/opt目录下。
2.执行解压操作(tar)。
3.重命名mv指令。
2.4 Zookeeper配置
1.配置Zookeeper数据存放的目录(zookeeper/zkData)。
2.配置Zookeeper的日志存放目录(zookeeper/zkLog)。
3.zookeeper/conf/zoo_sample.cfg,表示zookeeper的配置模板文件(zoo.cfg)。
4.zoo.cfg文件中来配置。
dataDir=/opt/zookeeper/zkData
dataLogDir=/opt/zookeeper/zkLog
2.5 Zookeeper基本操作
1.启动Zookeeper(bin目录下)。
[root@localhost bin]# ./zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
2.查看是否启动:
[root@localhost bin]# jps
3581 Jps
3503 QuorumPeerMain
QuorumPeerMain:表示Zookeeper启动入口类,表示配置启动线程处于运行的状态。
3.查看状态。
[root@localhost bin]# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: standalone
说明:
1.Zookeeper默认访问端口2181。
2.localhost表示Zookeeper安装本台主机上。
3.standalone表示采用非集群的方式启动(表示孤独的意思)。
4.启动Zookeeper的客户端。
./zkCli.sh
5.退出Zookeeper客户端。
quit
6.停止Zookeeper服务。
[root@localhost bin]# ./zkServer.sh stop
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED
2.6 Zookeeper配置参数解析
Zookeeper中的配置文件zoo.cfg中参数含义解读如下:
| 参数 | 描述 |
|---|---|
| tickTime=2000 | 通信心跳数, Zookeeper服务器与客户端心跳时间,单位毫秒。Zookeeper使用的基本时间,服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个tickTime时间就会发送一个心跳,时间单位为毫秒。 |
| initLimit=10 | LF初始通信时限。集群中的Follower跟随者服务器与Leader领导者服务器之间,启动时能容忍的最多心跳数。10 * 2000(10个心跳时间)如果领导和跟随者没有发出心跳通信,就视为失效的连接,领导和跟随者彻底断开。 |
| syncLimit=5 | LF同步通信时限。集群启动后,Leader与Follower之间的最大响应时间单位,假如响应超过syncLimit*tickTime=10秒,Leader就认为Follwer已经死掉,会将Follwer从服务器列表中删除。 |
| dataDir | 数据文件目录 + 数据持久化路径。 |
| dataLogDir | 日志文件目录。 |
| clientPort=2181 | 客户端连接端口。监听客户端连接的端口。 |
Zookeeper服务端口,默认是8080。修饰Zookeeper服务的默认端口的配置。
admin.serverPort=8081
3 Zookeeper内部原理
3.1选举策略
半数机制:在集群环境中半数以上的机器存活,这个集群就可用。所以在设计Zookeeper集群系统时,通常会选择奇数台服务器来搭建Zookeeper的集群。
在配置文件中即便不去配置任何关于主节点和从节点的内容。Zookeeper集群启动成功后,仍然会选择出主节点和从节点,Zookeeper是有临时选举策略的。
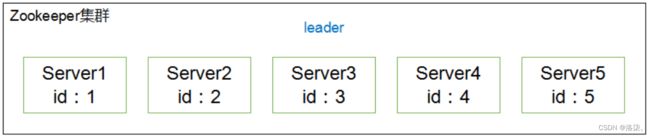
1.Server1先投票,投给自己,自己为1票,没有超过半数,根本无法成为leader,顺水推舟将票数投给了id比自己大的Server2。
2.Server2也把自己的票数投给了自己,再加上Server1给的票数,总票数为2票,没有超过半数,也无法成为leader,也学习Server1,顺水推舟,将自己所有的票数给了id比自己大的Server3。
3.Server3得到了Server1和Server2的两票,再加上自己投给自己的一票。3票超过半数,顺利成为leader。
4.Server4和Server5都投给自己,但是无法改变Server3的票数,只好听天由命,承认Server3是leader。
3.2 节点类型
1.持久型
1.特点:客户端如果和Zookeeper断开了连接,对应的节点上数据依旧持久保存着。
2.创建ZNode时按照顺序来进行标识节点,ZNode名称后面追加一个数字的值,例如:Znode001、Znode002、Znode003…顺序号是一个单调递增的数字来进行标记。
2.短暂型
1.特点:客户端和Zookeeper断开连接之后,该节点会被自动的回收(自动的删除)。
2.创建ZNode节点的时候,ZNode名称会追加一个数字的值,顺序编号是一个单调递增的数字:例如:Znode001、Znode002、Znode003…
3.3 监听器原理
1.在main方法中创建Zookeeper客户端的同时就会创建两个线程,一个负责网络连接通信,一个负责监听。
2.监听事件就会通过网络通信发送给Zookeeper。
3.Zookeeper获得注册的监听事件后,立刻将监听事件添加到监听列表里。
4.Zookeeper监听到数据变化或路径变化,就会将这个消息发送给监听线程。常见的监听:
-
监听节点数据的变化:get path [watch]
-
监听子节点增减的变化:ls path [watch]
5.监听线程就会在内部调用process()方法(需要开发者实现process()方法的内容)。

3.4 写数据流程解析
1.Client想向ZooKeeper的Server1上写数据,必须得先发送一个写的请求。
2.如果Server1不是Leader,那么Server1会把接收到的请求进一步转发给Leader。
3.这个Leader会将写请求广播给各个Server,各个Server写成功后就会通知Leader。
4.当Leader收到半数以上的Server数据写成功了,那么就说明数据写成功了。
5.随后,Leader会告诉Server1数据写成功了。
6.Server1会反馈通知Client数据写成功了,整个流程结束。

4 Zookeeper集群搭建
4.1 分布式环境安装部署
Zookeeper集群环境搭建:需要使用3台CentOS系统,分别在这三台系统安装Zookeeper,并配置Zookeeper的相关配置。这三台服务器就构成了一个集群的环境。
虚拟时可以完整性克隆的。只需要搭建好一台Zookeeper服务,然后将这台Zookeeper服务器作为一个原始系统,进行克隆。
4.2 Zookeeper集群搭建
4.1.1 配置服务的id(编号)
IP每态操作系统都有一个IP(192.168.230.131、192.168.230.132、192.168.230.133)
1.Zookeeper要求必须在dataDir=/opt/zookeeper/zkData属性所指向的目录下创建一个文件myid作为文件。这个文件中的数字就表示当前Zookeeper编号。zk02的编号:2;zk03的编号:3。
/opt/zookeeper/zkData/myid
1
4.1.2 配置集群IP
1.zoo.cfg文件维护了Zookeeper的IP集群配置。
# server.A=B:C:D
server.1=192.168.230.131:2888:3888
server.2=192.168.230.132:2888:3888
server.3=192.168.230.133:2888:3888
2.配置参数解读server.A=B:C:D。
| 参数 | 描述 |
|---|---|
| A | 一个数字,表示第几号服务器。集群模式下配置的/opt/zookeeper/zkData/myid文件里面的数据就是A的值 |
| B | 服务器的IP地址 |
| C | 与集群中Leader服务器交换信息的端口 |
| D | 选举时专用端口,万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口 |
4.1.3 配置其他两台服务
1.zk02配置IP,myid的值为2。
2.zk03配置IP,myid的值为3。
3.通过VM提供的克隆技术来完成以上两台主机的搭建。
4.1.4 集群操作
1.关闭集群中的每一个节点的防火墙。
systemctl stop firewalld.service # 停止防火墙,临时停止,如果服务器重启,则防火墙会自动开启
systemctl disable firewalld # 禁止防火墙开机自启动
2.查看当前防火墙的状态:(active表示运行、dead表示关闭)。
systemctl status firewalld
3.启动Zookeeper服务。
./zkServer.sh start
4.查看Zookeeper状态。
./zkServer.sh status
说明:
Model: follower:表示该Zookeeper服务是一个从节点
Model: leader:表示该Zookeeper服务是一个主节点
4.2.5 集群启动的问题
1.物理内存不足。例如物理主机内容8G,默认每一台虚拟机分配的内存4G。关闭虚拟机,编辑虚拟机,将虚拟机的分配内存设置2G。
2.提示:bash: ./zkServer.sh : Permission denied…表示没有权限访问和执行zkServer.sh。
chmod u+x zkServer.sh
3.提示…not running。可能的原因:
-
JDK安装的正确。比如检查JDK是否正常安装、检查JDK的环境变量的配置。
-
单台zk节点无法启动。zoo.cfg配置有误。dataDir、dataLogDir。
#dataDir=/opt/zookeeper/zkData dataLogDir=/opt/zookeeper/zkLog -
集群环境无法正常启动。集群的配置有问题,每台主机上的集群IP是否,myid文件(1、2、3)。
4.3 Zookeeper客户端命令
4.3.1 客户端命令
1.启动Zookeeper的客户端。bin目录下的zkCli.sh
./zkCli.sh
2.查看Zookeeper提供的常见命令。
help
3.查看当前节点下ZNode中包含的内容。默认有一个zookeeper的节点。
[zk: localhost:2181(CONNECTED) 1] ls /
[zookeeper]
4.查看当前节点详情数据。
[zk: localhost:2181(CONNECTED) 2] ls -s /
[zookeeper]
cZxid = 0x0
ctime = Wed Dec 31 19:00:00 EST 1969
mZxid = 0x0
mtime = Wed Dec 31 19:00:00 EST 1969
pZxid = 0x0
cversion = -1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 1
节点的参数信息:
| 参数名 | 描述 |
|---|---|
| cZxid | 创建节点的事务。每次修改ZooKeeper状态都会收到一个zxid形式的时间戳,也就是ZooKeeper事务ID。事务ID是ZooKeeper中所有修改总的次序。每个修改都有唯一的zxid,如果zxid1小于zxid2,那么zxid1在zxid2之前发生。 |
| ctime | 被创建的毫秒数(从1970年开始) |
| mZxid | 最后更新的事务zxid |
| mtime | 最后修改的毫秒数(从1970年开始) |
| pZxid | 最后更新的子节点zxid |
| cversion | 创建版本号,子节点修改次数 |
| dataVersion | 数据变化版本号 |
| aclVersion | 权限版本号 |
| ephemeralOwner | 如果是临时节点,这个是znode拥有者的session id。如果不是临时节点则是0 |
| dataLength | 数据长度 |
| numChildren | 子节点数 |
4.3.2 节点操作
1.在根节点下创建(create)两个节点(/)。
create /cn
create /us
2.在创建节点的时候,同时向节点中保存数据。
create /rus 'pujing'
3.获取节点中的数据。
get /rus
4.多级节点的创建。如果父节点节点不存在,则会提示错误信息。
[zk: localhost:2181(CONNECTED) 8] create /jp/Tokyo 'hot'
Node does not exist: /jp/Tokyo # 父节点不存在,所以创建失败
[zk: localhost:2181(CONNECTED) 9] create /jp
Created /jp
[zk: localhost:2181(CONNECTED) 10] create /jp/Tokyo 'hot'
Created /jp/Tokyo
[zk: localhost:2181(CONNECTED) 11] get /jp/Tokyo
hot
5.创建短暂节点。在客户端断开连接后,这个节点就会被回收。
create -e /uk # 参数-e表示标记当前的节点是一个临时节点(短暂节点)
6.创建带序号的节点。
- 在cn节点下,创建三个城市节点
- 如果创建的节点期望顺序编号,需要指定一个参数-s。
- 如果在指定节点下,已经存在了一个节点,所创建出来的新节点编号从1开始取值(默认值从0开始取值)
7.修改节点中的数据。
set /jp/Tokyo 'too hot'
8.删除节点。
delete /jp/Tokyo
9.通过递归的方式来删除指定节点及该节点下所有的子节点。
deleteall /cn
10.监听指定节点的值改变或者子节点的变化(路径发生变化)。
(1)在zk03节点上注册一个事件监听(通过节点的名称来确定要监听谁)。
addWatch /us
(2)在zk01节点上修改了us节点的数据内容。
set /us 'meiguo'
(3)在zk03节点上,提示监听到了us的事件,事件被触发了。
WATCHER::
WatchedEvent state:SyncConnected type:NodeDataChanged path:/us
(4)在zk01节点上,给us节点添加了子节点。
create /us/NewYork
(5)查看zk03节点,监听到了目标节点子节的改变。
WATCHER::
WatchedEvent state:SyncConnected type:NodeCreated path:/us/NewYork
5 Zookeeper实战
建立在SSM框架的基础上来实现的(再度复习SSM框架开发和使用)。
5.1 Zookeeper的API应用
目的通过Zookeeper提供Java的API技术,来操作和访问Zookeeper集群。例如,向集群中插入节点,或者获取集群中某个节点的数据内容,例如删除集群中某个节点。
5.1.1 项目环境搭建
1.创建一个项目:test_zookeeper。项目类型Maven类型。
2.添加依赖。
<dependencies>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.13.2version>
<scope>testscope>
dependency>
<dependency>
<groupId>org.apache.zookeepergroupId>
<artifactId>zookeeperartifactId>
<version>3.8.0version>
dependency>
<dependency>
<groupId>org.apache.logging.log4jgroupId>
<artifactId>log4j-coreartifactId>
<version>2.8.2version>
dependency>
dependencies>
3.在resources目录下创建一个log4j.properties。
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/zk.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
5.1.2 创建Zookeeper客户端
在项目测试包下进行测试:ZookeeperTests测试类。
package com.cy;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import org.junit.Test;
import java.io.IOException;
/**
* Zookeeper客户端
*/
public class ZookeeperTests {
// 集群的IP地址,集群的IP使用","分隔,同时需要指定客户端通过那一个端口连接集群(2181)
private String connectionStr =
"192.168.230.131:2181,192.168.230.132:2181,192.168.230.133:2181";
// 创建Zookeeper客户端对象,通过该对象来节点Zookeeper集群
private ZooKeeper zooKeeperClient;
// 单位是毫秒
// sessionTimeout属性:在指定的时间内来尝试连接Zookeeper集群,如果超出该指定的时间,此群如果来没有连接上,不会再去尝试连接
private int sessionTimeout = 60 * 1000; // 如果超出了60秒还没有连接上集群,会报错
// 连接Zookeeper集群前的初始化工作准备
@Test
public void init() throws IOException { // Zookeeper三台服务器是处于正常运行状态
// Zookeeper集群是可以创建监听器,主要监听节点数据变化或者子节点变化
Watcher watcher = new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
System.out.println("监听事件执行....");
}
};
// 初始化Zookeeper对象
zooKeeperClient = new ZooKeeper(connectionStr, sessionTimeout, watcher);
}
}
5.1.3 创建节点
1.ACL对象介绍
代码实现:
zooKeeperClient.create(
"/yuanxin",
"袁老师".getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
一个ACL对象就是一个Id和permission对。
-
表示哪个/哪些范围的Id(Who)在通过了怎样的鉴权(How)之后,就允许进行那些操作(What)。即Who How What。
-
permission(What)就是一个int表示的位码,每一位代表一个对应操作的允许状态。
-
类似Linux的文件权限,不同的是共有5种操作:CREATE、READ、WRITE、DELETE、ADMIN(对应更改ACL的权限)。
| 参数 | 描述 |
|---|---|
| OPEN_ACL_UNSAFE | 创建开放节点,允许任意操作(用的最多,其余的权限用的很少) |
| READ_ACL_UNSAFE | 创建只读节点 |
| CREATOR_ALL_ACL | 创建者才有全部权限 |
2.创建节点实现
通过Zookeeper对象来创建节点。需要使用@Before去修饰init()方法。
// 创建节点
@Test
public void createNode() throws InterruptedException, KeeperException {
/**
* create()方法:表示在指定的节点下创建一个新的节点。create()方法会将创建成功的节点名称作为方法的返回值
* - 参数1:表示创建的节点名称,需要指定完整的父节点
* - 参数2:表示在创建该节点的同时,初始化的节点数据
* - 参数3:节点权限
* - 参数4:节点的类型
*/
String nodeCreated = zooKeeperClient.create(
"/yuanxin",
"袁老师".getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
System.out.println("nodeCreated=" + nodeCreated);
}
3.Session超时异常
在运行createNode()方法的时候抛出一个异常:ClientCnxn$SesssionTimeoutException异常。
解决方案:
- 防火墙没有关闭:systemctl stop firewalled
- 检查客户端IP集群定义的字符串是否正确
- 增加sessionTimeout变量的取值(等待时间加大-50*1000)
5.1.4 查询节点的值
getData()方法查询节点的数据。
// 查询节点的数据
@Test
public void find() throws InterruptedException, KeeperException {
/**
* 参数1:表示被查询的节点名称(完整节点路径)
* 参数2:是一个boolean类型的取值(false不需要)
* 参数3:接收一个Stat类型的对象,直接new实例化一个Stat对象
*/
byte[] data = zooKeeperClient.getData("/yuanxin", false, new Stat());
// 把字节码数组转化成一个字符串
String content = new String(data);
System.out.println("content=" + content);
}
5.1.5 修改节点的值
setData()方法用来设置节点的数据内容。
// 节点更新
@Test
public void update() throws InterruptedException, KeeperException {
/**
* 参数1:表示被修改的节点名称(即对那一个节点的数据进行修改操作)
* 参数2:被修改的新数据(需要转化成字节数组)
* 参数3:dataVersion=0属性的取值为0,数据变化版本号(0-n)
*/
Stat stat = zooKeeperClient.setData("/yuanxin", "新哥".getBytes(), 0);
// 表示是当前操作的节点元数据,输出的这个节点详情信息
// stat=12884901913,12884901921,1669694202793,1669702964097,1,0,0,0,6,0,12884901913
System.out.println("stat=" + stat);
}
5.1.6 删除节点
delete()方法用来删除指定节点。
// 删除节点
@Test
public void delete() throws InterruptedException, KeeperException {
/**
* 参数1:表示根据节点名来删除指定的节点
* 参数2:表示增删改的操作都需要指定一个版本号dataVersion=1
*/
zooKeeperClient.delete("/yuanxin", 1);
System.out.println("删除成功!");
}
5.1.7 判断节点是否存在
exists()方法用来判断指定的节点是否存在。
// 判断节点是否存在
@Test
public void exist() throws InterruptedException, KeeperException {
// 如果stat返回值为null表示指定的节点不存在
Stat stat = zooKeeperClient.exists("/yuanxin", false);
System.out.println("stat=" + stat);
String flag = stat == null ? "该节点不存在" : "该节点存在";
System.out.println("flag=" + flag);
}
5.1.8 获取子节点
getChildren()方法用来获取指定节点的所有子节点。
// 获取指定节点的所有子节点
@Test
public void getChildrenNodes() throws InterruptedException, KeeperException {
// 根据指定的节点名称来获取该节点下所有的子节点
List<String> childNodes = zooKeeperClient.getChildren("/cn", false);
for (String node : childNodes) {
System.out.println(node);
}
}
5.1.9 监听节点的变化
watch是一个boolean类型的变量,表示是否开启对应的节点监听,true表示开启这个节点的监听。
@Test
public void listenChildNodes() throws InterruptedException, KeeperException, IOException {
/**
* 参数1:表示指定要获取那一个节点下所有的子节点
* 参数2:true表示注册监听器
*/
// List getChildren(String path, boolean watch)
List<String> childNodes = zooKeeperClient.getChildren("/" , true);
for (String node : childNodes) {
System.out.println(node);
}
// 让线程不停止,等待监听器的响应
System.in.read(); // 线程在当前代码处处于等待的状态,不会在往后执行了
}
5.2 案例-模拟美团商家上下线
5.2.1 分析需求
1.模拟一个美团的服务平台,完成商家营业状态、打烊状态的通知和监控。
2.创建一个/meituan节点。
create /meituan
5.2.2 项目环境搭建
1.创建一个Maven类型的项目,项目名称设置为:zk_meituan。
2.添加依赖。
<dependencies>
<dependency>
<groupId>org.apache.zookeepergroupId>
<artifactId>zookeeperartifactId>
<version>3.8.0version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.13.2version>
<scope>testscope>
dependency>
<dependency>
<groupId>org.apache.logging.log4jgroupId>
<artifactId>log4j-coreartifactId>
<version>2.8.2version>
dependency>
dependencies>
3.在项目的resources目录下log4j.properties文件。
5.2.3 商家服务类
商家服务类名称:MerchantServer。定义业务功能(应该状态)。
package com.cy.meituan;
import org.apache.zookeeper.*;
import java.io.IOException;
public class MerchantServer {
// zk集群IP地址
private static String connectionString =
"192.168.230.131:2181,192.168.230.132:2181,192.168.230.133:2181";
// zk连接等待时间
private static int sessionTimeout = 60 * 1000;
// zk客户端对象
private ZooKeeper zookeeperClient = null;
// 封装一个方法,创建Zookeeper集群的客户端连接对象
public void getConnection() throws IOException {
zookeeperClient = new ZooKeeper(connectionString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
// 监听器会被回调的方法
}
});
}
/**
* 注册到集群(/meituan/新哥刀削面、/meituan/杨哥蛋炒饭)
*
* ox000000 - 新哥刀削面
* ox000001 - 杨哥蛋炒饭
*
* create -s /cn/city --> 连续执行了3遍
* city0x000000000
* city0x000000001
* city0x000000002
* city0x000000003
*/
public void register(String merchantName) throws InterruptedException, KeeperException { // 方法的参数接收一个商家的名字,即表示被注册的商家
// EPHEMERAL_SEQUENTIAL表示当前所创建的节点是一个短暂型节点,并且是是有序型的
// 返回的字符串名称就是被创建的商家节点名称(merchant0x000000001)
String create = zookeeperClient.create(
"/meituan/merchant",
merchantName.getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL);
System.out.println(merchantName + ":开始营业!" + create);
}
// 业务功能
public void business(String merchantName) throws IOException {
System.out.println(merchantName + ":正在营业中....");
// 耗时操作
System.in.read();
}
// 生命周期main
public static void main(String[] args) throws IOException, InterruptedException, KeeperException { // KFC
// 1.创建商家服务对象
MerchantServer merchantServer = new MerchantServer();
// 2.连接Zookeeper服务集群(和美团平台取得连接)
merchantServer.getConnection();
// 3.将商家入住美团(将服务器节点节点进行注册)
merchantServer.register(args[0]);
// 4.业务逻辑处理(做生意)
merchantServer.business(args[0]);
}
}
5.2.4 客户端
客户端类的名称:Customers类。
package com.cy.meituan;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.data.Stat;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/**
* 客户端类
*/
public class Customers {
private static String connectionString
= "192.168.230.131:2181,192.168.230.132:2181,192.168.230.133:2181";
private static int sessionTimeout = 60 * 1000;
private ZooKeeper zooKeeperClient = null;
// 创建Zookeeper的客户端连接
public void getConnection() throws IOException {
zooKeeperClient = new ZooKeeper(connectionString, sessionTimeout, new Watcher() {
// 回调方法:当监听的节点发生改变的时候,此方法会被自动的回调
@Override
public void process(WatchedEvent watchedEvent) {
// 一旦/meituan节点下的子节点发生改变,需要将最新的节点在客户端进行重新请求获取最新的节点列表
try {
// 获取罪行的商家列表
getMerchantList();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (KeeperException e) {
e.printStackTrace();
}
}
});
}
// 获取服务器商家列表信息(如果要获取某个节点下所有的子节点:getChildren()方法完成)
public void getMerchantList() throws InterruptedException, KeeperException {
// 1.获取了商家的列表(处于运营状态的商家列表)
// true表示开启对/meituan监听(merchant0x0000001)
List<String> merchants = zooKeeperClient.getChildren("/meituan", true);
// 2.根据节点的名称来获取该节点对应的数据信息。可以声明一个字符串集合来存储所有节点的数据
List<String> merchantDataList = new ArrayList<>();
// 3.通过遍历节点的名称来获取节点的数据,再把获取的数据保存到merchantDataList集合中
for (String merchant : merchants) {
byte[] data = zooKeeperClient.getData("/meituan/" + merchant, false, new Stat());
merchantDataList.add(new String(data));
}
// 4.打印服务器商家最新的列表信息
System.out.println(merchantDataList);
}
// 业务功能
public void business() throws IOException {
System.out.println("客户正在浏览外卖商家的店....");
System.in.read();
}
public static void main(String[] args) throws IOException, InterruptedException, KeeperException {
// 1.创建Zookeeper连接(客户打开了美团APP)
Customers client = new Customers();
// 2.连接平台
client.getConnection();
// 3.获取/meituan节点下所有的子节点(从美团平台上获取商家的列表信息)
client.getMerchantList();
// 4.业务进行调用(浏览外卖点,对比商家、点餐)
client.business();
}
}
5.2.5 运行测试
1.测试客户端类。
2.测试服务端类。通过IDEA对main方法进行传参数。
5.3 案例-分布式锁商品秒杀
5.3.1 分布式锁
锁:我们在多线程中接触过,作用就是让当前的资源不会被其他线程访问。
-
我的日记本,不可以被别人看到。所以要锁在保险柜中。
-
当我打开锁,将日记本拿走了,别人才能使用这个保险柜。
在Zookeeper中使用传统的锁会引发的“羊群效应”。1000个人创建节点,只有一个人能成功,999人需要等待。
羊群是一种很散乱的组织,平时在一起也是盲目地左冲右撞,但一旦有一只头羊动起来,其他的羊也会不假思索地一哄而上,全然不顾旁边可能有的狼和不远处更好的草。羊群效应就是比喻人都有 一种从众心理,从众心理很容易导致盲从,而盲从往往会陷入骗局或遭到失败。
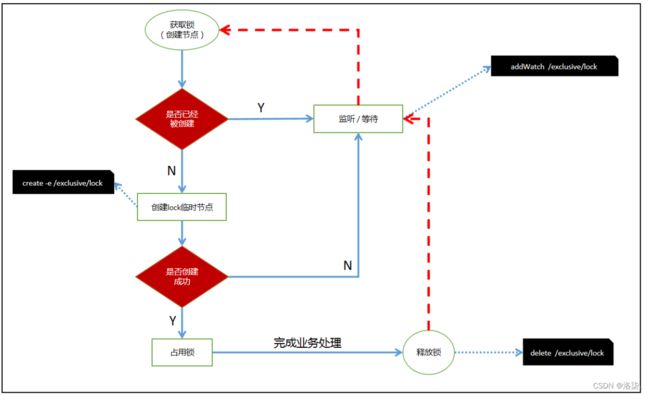
为了避免“羊群效应”的产生,Zookeeper采用分布式锁来解决“羊群效应”的问题。
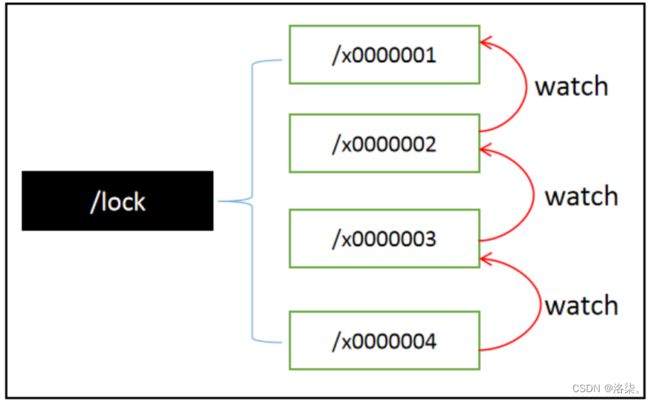
1.所有请求进来,在/lock下创建临时顺序节点,Zookeeper会帮你编号排序。
2.判断自己是不是/lock下最小的节点。
-
是,获得锁(创建节点)
-
否,对前面小我一级的节点进行监听
3.获得锁请求,处理完业务逻辑,释放锁(删除节点),后一个节点得到通知。
4.重复上面的步骤二。
5.3.2 数据准备
创建一个商品表,保存5件优惠商品。创建一个订单表。放在一个指定的库。
-- 商品表
create table `product` (
id int primary key auto_increment, -- 商品编号
product_name varchar(20) not null, -- 商品名称
stock int not null, -- 库存
version int not null -- 版本
);
insert into product (product_name, stock, version) values ('锦鲤-清空购物车-大奖', 5, 0);
-- 订单表
create table `order` (
id varchar(100) primary key, -- 订单编号
pid int not null, -- 商品编号
userid int not null -- 用户编号
);
5.3.3 搭建工程
1.创建一个Maven类型的项目,项目的名称:zk_product。
2.手动的创建webapp目录,自动生成WEB-INF/web.xml。
3.使用SSM架构来搭建项目的后台(SSM框架整合)。
4.引入项目的依赖(Zookeeper依赖、分布式锁依赖…)。
<dependencies>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-contextartifactId>
<version>${spring.version}version>
dependency>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-beansartifactId>
<version>${spring.version}version>
dependency>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-webmvcartifactId>
<version>${spring.version}version>
dependency>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-jdbcartifactId>
<version>${spring.version}version>
dependency>
<dependency>
<groupId>org.mybatisgroupId>
<artifactId>mybatisartifactId>
<version>3.5.5version>
dependency>
<dependency>
<groupId>org.mybatisgroupId>
<artifactId>mybatis-springartifactId>
<version>2.0.5version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druidartifactId>
<version>1.1.10version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>8.0.20version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.12version>
<scope>testscope>
dependency>
<dependency>
<groupId>org.apache.curatorgroupId>
<artifactId>curator-recipesartifactId>
<version>4.2.0version>
dependency>
dependencies>
5.添加了项目的内嵌Tomcat插件,通过plugin标签进行的配置。
<build>
<plugins>
<plugin>
<groupId>org.apache.tomcat.mavengroupId>
<artifactId>tomcat7-maven-pluginartifactId>
<version>2.2version>
<configuration>
<port>8001port>
<path>/path>
configuration>
<executions>
<execution>
<phase>packagephase>
<goals>
<goal>rungoal>
goals>
execution>
executions>
plugin>
plugins>
build>
5.3.4 搭建SSM环境
1.创建一个文件夹mybatis,在该文件夹下配置mybatis-config.xml。
DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<settings>
<setting name="logImpl" value="STDOUT_LOGGING"/>
<setting name="mapUnderscoreToCamelCase" value="true"/>
<setting name="cacheEnabled" value="true"/>
settings>
configuration>
2.创建spring文件夹,Spring框架的核心配置文件spring.xml(配置Spring框架和SpringMVC框架)。
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx.xsd">
<context:component-scan base-package="com.cy.product" />
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver" />
<property name="url" value="jdbc:mysql://localhost:3306/zk_db?serverTimezone=GMT" />
<property name="username" value="root" />
<property name="password" value="123456" />
<property name="maxActive" value="10" />
<property name="minIdle" value="5" />
bean>
<bean id="sessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource" />
<property name="configLocation" value="classpath:mybatis/mybatis-config.xml" />
bean>
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="com.cy.product.mapper" />
bean>
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
bean>
<tx:annotation-driven />
beans>
3.配置前端控制器:DispatcherServlet处理请求(spring核心配置文件的位置、编码)。
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd"
version="4.0">
<servlet>
<servlet-name>springMVCservlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServletservlet-class>
<init-param>
<param-name>contextConfigLocationparam-name>
<param-value>classpath:spring/spring.xmlparam-value>
init-param>
<load-on-startup>1load-on-startup>
<async-supported>trueasync-supported>
servlet>
<servlet-mapping>
<servlet-name>springMVCservlet-name>
<url-pattern>/url-pattern>
servlet-mapping>
web-app>
5.3.5 功能的开发
1.需求分析
1.模拟一个抢购功能。
update from product set stock = stock - 1
2.某个用户下单成功。
insert into `order` (id, pid, userid) values (?,?,?)
2.创建实体类
1.创建Product实体类。
package com.cy.product.pojo;
import lombok.Data;
import java.io.Serializable;
/**
* 商品表的实体类
*/
@Data
public class Product implements Serializable {
private int id;
private String productName;
private int stock;
private int version;
// toString、set、set、equals
}
2.创建Order实体类。
package com.cy.product.pojo;
import lombok.Data;
import java.io.Serializable;
/**
* 订单表实体类
*/
@Data
public class Order implements Serializable {
private String id;
private int pid;
private int userid;
}
3.Mapper层
1.创建ProductMapper接口。
package com.cy.product.mapper;
import com.cy.product.pojo.Product;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Select;
import org.apache.ibatis.annotations.Update;
import org.springframework.stereotype.Component;
@Mapper // 表示通过Mybatis提供的代理类,来实现该结构的
@Component // 将该类对象交给Spring框架管理
public interface ProductMapper {
// 1.查询查询该商品是否还有存库
@Select("select * from product where id=#{id}")
Product getProduct(@Param("id") int id);
// 2.减少商品存库数量的
@Update("update product set stock = stock-1 where id=#{id}")
int reduceStock(@Param("id") int id);
}
2.创建OrderMapper接口。
package com.cy.product.mapper;
import com.cy.product.pojo.Order;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Mapper;
import org.springframework.stereotype.Component;
@Mapper
@Component
public interface OrderMapper {
// 生成订单
@Insert("insert into `order` (id, pid, userid) values (#{id}, #{pid}, #{userid})")
int insert(Order order);
}
4.service层开发
1.创建一个ProductService接口。
package com.cy.product.service;
public interface ProductService {
void reduceStock(int id) throws Exception;
}
2.创建该接口的实现类ProductServiceImpl。
package com.cy.product.service.impl;
import com.cy.product.mapper.OrderMapper;
import com.cy.product.mapper.ProductMapper;
import com.cy.product.pojo.Order;
import com.cy.product.pojo.Product;
import com.cy.product.service.ProductService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.UUID;
@Service
public class ProductServiceImpl implements ProductService {
@Autowired
private ProductMapper productMapper;
@Autowired
private OrderMapper orderMapper;
@Override
public void reduceStock(int id) throws Exception {
// 1.获取秒杀商品的信息(获取到了当前商品的库存数量)
Product product = productMapper.getProduct(id); // stock == 0
// 2.判断当前的商品是否库存数小于等于0
if (product.getStock() <= 0) { // 该商品已被抢光
throw new RuntimeException("该商品已被抢光!!!");
}
// 3.执行商品秒杀操作(商品库存数量-1)
int row = productMapper.reduceStock(id);
if (row == 1) { // 该用户抢到商品,商品的抢购信息新增订单表中
Order order = new Order();
order.setId(UUID.randomUUID().toString());
order.setPid(id);
order.setUserid(1001);
orderMapper.insert(order);
} else {
throw new RuntimeException("当前排队人数过多,请稍后重试!");
}
}
}
4.Controller层开发
创建一个类ProductController类,添加一个请求处理方法,根据商品的id执行商品秒杀抢购功能。
package com.cy.product.controller;
import com.cy.product.service.ProductService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController // @Controller + @Response的组合注解
public class ProductController {
@Autowired
private ProductService productService;
@GetMapping("/product/reduce")
public String reduceStock(int id) throws Exception {
productService.reduceStock(id);
return "success";
}
}
5.功能测试
APIPost、Postmain等测试工具,来测试该接口的测试。
1.将项目通过内嵌的Tomcat端口配置,来指定8001和8002端口,操作同一台数据,个时候就可能有请求的兵法问题。
2.使用ApiPost测试工具,在指定的时间内容,发送多个请求,模拟出了请求并发。
3.数据的商品库存数据被抢购到小于0的数字,这个是和业务的场景符,需要通过手动来解决该问题。
5.3.6 Zookeeper解决并发问题
Curator是基于Zookeeper原生的客户端类实现的一个中分布式并发问题的解决依赖。
1.Curator引入该依赖。
<dependency>
<groupId>org.apache.curatorgroupId>
<artifactId>curator-recipesartifactId>
<version>4.2.0version>
dependency>
在该依赖中包含有Zookeeper的相关技术。
2.在控制层来控制分布式锁的使用。
package com.cy.product.controller;
import com.cy.product.service.ProductService;
import org.apache.curator.RetryPolicy;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.recipes.locks.InterProcessLock;
import org.apache.curator.framework.recipes.locks.InterProcessMutex;
import org.apache.curator.retry.ExponentialBackoffRetry;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController // @Controller + @Response的组合注解
public class ProductController {
@Autowired
private ProductService productService;
// 声明Zookeeper集群环境的IP
private static String connectionString = "192.168.230.131:2181,192.168.230.132:2181,192.168.230.133:2181";
@GetMapping("/product/reduce")
public String reduceStock(int id) throws Exception {
// 1.创建一个重试策略(重试3次,每次重试的时间间隔是1秒)
/**
* 参数1:表示每一次重试的时间间隔
* 参数2:表示重试多少次
*/
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3);
// 2.创建Curator对象(表示一个Zookeeper连接的工具对象)
CuratorFramework client = CuratorFrameworkFactory.newClient(connectionString, retryPolicy);
// 3.开启客户端:表示连接上集群
client.start();
// 4.根据client工具类创建一个"内部互斥锁"对象
/**
* 参数1:表示目标客户端(client对象)
* 参数2:表示这个锁在集群中的节点名称(要求唯一)
*/
InterProcessMutex lock = new InterProcessMutex(client, "/product_" + id);
try {
// 5.开启锁(在目标方法指定之前开启锁)
lock.acquire();
productService.reduceStock(id); // 并发了调用该方法
} catch (Exception e) {
e.printStackTrace();
} finally {
// 6.释放锁(目标方法被调用,无论是否产生异常,理论上都应该将锁释放掉)
lock.release();
}
return "success";
}
}
3.测试:在指定的时间内容,通过ApiPost发送并发的请求,通过访问8001和8002端口,发现分布式锁的作用就生效。
6 Zookeeper总结
1.Zookeeper概念
- Zookeeper原理
- 特点
- 数据结果
- 应用场景
2.Zookeeper的安装
-
单台节点进行安装
-
myid - dataDir所指向的文件(zkData)
-
zoo.cfg:日志目录、数据目录、集群的IP环境
-
Zookeeper基本操作
3.Zookeeper内部原理
- 选举策略:采用投票机制来进行,当半数以上的票如果投给了指定节点,这个节点就是主节点
- 节点类型:持久型、短暂型
- 监听器原理:如果被节点发生改变或者被监听的节点的子节点发生改变,回调process()。
- 写数据流程解析:子节点接收到请求后,将请求传递给主节点,主节点广播到所有的节点,所以的子节点执行写入数据操作。
4.Zookeeper集群搭建
- zoo.cfg配置集群的IP群:server.1 = 192.168.230.131:2888:3888
- myid给每一个节点分配一个编号(必须唯一)
- 克隆(修改IP地址)
5.Zookeeper实战
- Zookeeper的API节点操作集群
- 模拟美团商家上下线的通知(商家服务端、点餐的客户端)
- 分布式商品秒杀:SSM框架搭建后台业务(库存-1)、Curator分布式锁API
重点问题:
- zookeeper是什么?
- zookeeper的选举机制是什么?
- zookeeper的优点?(6个)
- zookeeper的应用场景(5个)
- zookeeper的监听原理?
- zookeeper的写数据流程?
- server.A=B:C:D; 中A? B? C? D?
- zookeeper如何解决并发问题?
- zookeeper实现分布式锁的原理?分布式锁的实现步骤?