Spark01-Spark快速上手、运行模式、运行框架、核心概念
1 概述
- Spark和Hadoop
- Hadoop
- HDFS(GFS:TheGoogleFileSystem)
- MapReduce
- 总结:性能横向扩展变得容易,横向拓展:增加更多的计算节点来扩展系统的处理能力
- Hbase:分布式数据库
- Spark
- Spark Core
- Spark SQL
- SQL 方言(HQL)
- Spark Streaming:提供了丰富的 处理数据流的 API。
- Spark or Hadoop
-
多次循环迭代式数据流以及数据可复用场景,例如:机器学习、图挖掘算法、交互式数据挖掘算法诞生spark。MR相对来说是串行
-
Spark多个作业数据通信基于内存,Hadoop基于磁盘
-
Spark写的shuffle写入磁盘,Hadoop每一次MR交互都写入磁盘
-
Spark采用fork线程(一种子线程形式),Hadoop创建新线程
fork线程补充:
含义:fork 线程是指在主线程中创建一个子线程,该子线程会复制主线程的所有资源和状态,然后在子线程中执行任务
意义:
提高并发性能,因为每个任务都可以在独立的线程中执行,从而避免了线程之间的竞争和阻塞。
同时,fork 线程也可以避免线程池中线程数量不足的问题,因为每个任务都可以在需要时动态地创建一个新的线程来执行
场景:fork 线程通常用于执行 RDD 的转换操作,以及在任务执行过程中进行数据的缓存和持久化。
- Spark缓存机制比Hadoop高效
- Spark内容

- Spark Core:base
- Spark SQL:操作结构化数据,SQL方言
- Spark Streaming:流式计算
- Spark MLlib:个机器学习算法库
- Spark GraphX:图计算
2 Spark 快速上手
- Wordcount案例
scala版本
// 创建 Spark 运行配置对象
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
// 创建 Spark 上下文环境对象(连接对象)
val sc : SparkContext = new SparkContext(sparkConf)
// 读取文件数据
val fileRDD: RDD[String] = sc.textFile("input/word.txt")
// 将文件中的数据进行分词
val wordRDD: RDD[String] = fileRDD.flatMap( _.split(" ") )
// 转换数据结构 word => (word, 1)
val word2OneRDD: RDD[(String, Int)] = wordRDD.map((_,1))
// 将转换结构后的数据按照相同的单词进行分组聚合
val word2CountRDD: RDD[(String, Int)] = word2OneRDD.reduceByKey(_+_)
// 将数据聚合结果采集到内存中
val word2Count: Array[(String, Int)] = word2CountRDD.collect()
// 打印结果
word2Count.foreach(println)
//关闭 Spark 连接
sc.stop()
太抽象了,来个java版本对照方便理解
SparkConf sparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
JavaRDD<String> fileRDD = sc.textFile("input/word.txt");
JavaRDD<String> wordRDD = fileRDD.flatMap(line -> Arrays.asList(line.split(" ")).iterator());
JavaPairRDD<String, Integer> word2OneRDD = wordRDD.mapToPair(word -> new Tuple2<>(word, 1));
JavaPairRDD<String, Integer> word2CountRDD = word2OneRDD.reduceByKey((x, y) -> x + y);
List<Tuple2<String, Integer>> word2Count = word2CountRDD.collect();
word2Count.forEach(tuple -> System.out.println(tuple._1() + ": " + tuple._2()));
sc.stop();
3 Spark运行环境
3.1 Local模式
- 含义:就是不需要其他任何节点资源就可以在本地执行 Spark 代码的环境
- 操作:
- 直接解压压缩包起spark
bin/spark-shell
- 上传文件并且处理数据
scala
sc.textFile("data/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
- 提交
这一步的目的是:spark-submit 命令可以将应用程序打包成一个 JAR 文件,并将其提交到 Spark 运行时环境中执行。在提交应用程序时,需要指定应用程序的类名、运行模式、JAR 文件路径等信息
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
1) --class 表示要执行程序的主类,此处可以更换为咱们自己写的应用程序
2) --master local[2] 部署模式,默认为本地模式,数字表示分配的虚拟 CPU 核数量
3) spark-examples_2.12-3.0.0.jar 运行的应用类所在的 jar 包,实际使用时,可以设定为咱
们自己打的 jar 包
3.2 Standalone模式
只使用 Spark 自身节点运行的集群模式,一般搞个三台
- 修改slaves的文件增加节点名字
linux1
linux2
linux3
- 修改spark-env.sh文件增加java的环境变量以及对应的master节点的名字
这一步的原因是:在 Spark 的 standalone 模式中,需要使用 Spark 自带的集群管理器来管理计算资源和任务调度。在启动 Spark 集群时,需要指定一个主节点(Master)和多个工作节点(Worker),其中主节点负责管理整个集群的资源和任务调度,而工作节点负责执行具体的计算任务。为了让主节点能够正确地启动和管理集群,需要在主节点上配置一些环境变量和参数
export JAVA_HOME=/opt/module/jdk1.8.0_144
SPARK_MASTER_HOST=linux1
SPARK_MASTER_PORT=7077
- 使用分发脚本进行分发然后起起来
xsync spark-standalone
sbin/start-all.sh
- 提交
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://linux1:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10

提交参数说明


- 高可用
采用Zookeeper配置置多个 Master 节点,一旦一个Master 故障后,备用 Master 提供服务
- 修改spark-env.sh配置内容,增加zookeeper的配置
注释如下内容:
#SPARK_MASTER_HOST=linux1
#SPARK_MASTER_PORT=7077
添加如下内容:
#Master 监控页面默认访问端口为 8080,但是可能会和 Zookeeper 冲突,所以改成 8989,也可以自
定义,访问 UI 监控页面时请注意
SPARK_MASTER_WEBUI_PORT=8989
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=linux1,linux2,linux3
-Dspark.deploy.zookeeper.dir=/spark
- 提交,master改成两个
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://linux1:7077,linux2:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
后面可以杀掉master1的进程,master2就会替补上去了
3.3 Yarn模式
采用Yarn作为资源调度的框架,Spark是用于计算的
-
修改hadoop中的配置文件yarn-site.xml
-
修改conf/spark-env.sh,YARN_CONF_DIR表示设置 YARN 配置文件的路径,以便 Spark 应用程序能够正确地连接到 YARN 集群管理器
mv spark-env.sh.template spark-env.sh
。。。
export JAVA_HOME=/opt/module/jdk1.8.0_144
YARN_CONF_DIR=/opt/module/hadoop/etc/hadoop
- 提交
master做出变化了
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
3.4 K8S模式
4 Spark运行框架
4.1 核心组件

- Driver
- 驱使整个应用起来的程序
- 在Executor之间调度任务以及跟踪Executor执行情况
- Executor
- 负责启动spark具体计算,并将结果返回Driver
- 自身块管理器(Block Manager)中对RDD进行内存式存储,方便迭代式计算
- Master&Worker
是自身的资源调度框架,类似Yarn的ResourceManager以及NodeManager,Master就是负责资源的调度和分配,并进行集群的监控等职责,Worker由 Master分配资源对数据进行并行的处理和计算
- ApplicationMaster
也就是Yarn中的ApplicationMaster作用,向ResourceManager请求资源然后给到Container
4.2 核心概念
- Executor 与 Core
Spark Executor 是集群中运行在工作节点(Worker)中的一个 JVM 进程,是整个集群中 的专门用于计算的节点。
可以指定参数去设置计算节点的个数,以及对应的资源(Executor 的内存大小和使用的虚拟 CPU 核(Core数量)

- 并行度
我们将整个集群并行执行任务的数量称之为并行度
并发和并行的主要区别:
并行度指的是在一个RDD上进行操作时,分区的数量。每个分区都可以在不同的节点上并行处理,从而提高处理效率。并行度越高,意味着可以同时处理更多的数据,但也会增加通信和调度的开销。
而并发度指的是在整个集群上同时运行的任务数量。并发度越高,意味着可以同时处理更多的任务,从而提高整个集群的处理能力。但并发度过高也会导致资源竞争和调度问题。
- 有向无环图
DAG(Directed Acyclic Graph)有向无环图是由点和线组成的拓扑图形,该图形具有方向,不会闭环
含义:DAG有向无环图是一种数据结构,它由一组节点和有向边组成,其中每个节点表示一个计算任务,每条边表示任务之间的依赖关系。DAG有向无环图中的边都是单向的,且不存在环路,因此可以保证任务的执行顺序,避免了循环依赖和死锁等问题。
作用:
在计算任务中,DAG有向无环图通常用于表示任务之间的依赖关系,例如一个任务的输出作为另一个任务的输入。
通过构建DAG有向无环图,可以将任务按照依赖关系进行排序,从而保证任务的正确执行顺序。
此外,DAG有向无环图还可以用于优化计算任务的执行顺序,例如通过合并相邻的计算任务,减少数据的传输和计算的开销,提高计算效率。
- 提交流程

- Yarn Client 模式
用于测试多
- Yarn Cluster 模式
➢ 在 YARN Cluster 模式下,任务提交后会和 ResourceManager 通讯申请启动 ApplicationMaster,
➢ 随后 ResourceManager 分配 container,在合适的 NodeManager 上启动 ApplicationMaster, 此时的 ApplicationMaster 就是 Driver。
➢ Driver 启动后向 ResourceManager 申请 Executor 内存,ResourceManager 接到 ApplicationMaster 的资源申请后会分配 container,然后在合适的 NodeManager 上启动 Executor 进程
➢ Executor 进程启动后会向 Driver 反向注册,Executor 全部注册完成后 Driver 开始执行main 函数,
➢ 之后执行到 Action 算子时,触发一个 Job,并根据宽依赖开始划分 stage,每个 stage 生成对应的 TaskSet,之后将 task 分发到各个 Executor 上执行。
5 Spark核心编程
5.1 RDD
5.1.1 RDD
(Resilient Distributed Dataset)叫做弹性分布式数据集。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行 计算的集合。
➢ 弹性
- 存储的弹性:内存与磁盘的自动切换;
- 容错的弹性:数据丢失可以自动恢复;
- 计算的弹性:计算出错重试机制;
- 分片的弹性:可根据需要重新分片。
➢ 分布式:数据存储在大数据集群不同节点上
➢ 数据集:RDD 封装了计算逻辑,并不保存数据
➢ 数据抽象:RDD 是一个抽象类,需要子类具体实现
➢ 不可变:RDD 封装了计算逻辑,是不可以改变的,想要改变,只能产生新的 RDD,在 新的 RDD 里面封装计算逻辑
➢ 可分区、并行计算
5.1.2 核心属性
-
分区列表 :RDD 数据结构中存在分区列表,用于执行任务时并行计算,是实现分布式计算的重要属性。
-
分区计算:函数 Spark 在计算时,是使用分区函数对每一个分区进行计算
-
RDD 之间的依赖关系:RDD 是计算模型的封装,当需求中需要将多个计算模型进行组合时,就需要将多个 RDD 建立依赖关系
-
分区器(可选):当数据为 KV 类型数据时,可以通过设定分区器自定义数据的分区
-
首选位置(可选):计算数据时,可以根据计算节点的状态选择不同的节点位置进行计算
这边讲的太概念了,就是需要额外的结合下面分区的知识去理解的
5.1.3 总体执行原理
- 启动Yarn集群环境

- Spark 通过申请资源创建调度节点和计算节点

- Spark 框架根据需求将计算逻辑根据分区划分成不同的任务

- 调度节点将任务根据计算节点状态发送到对应的计算节点进行计算
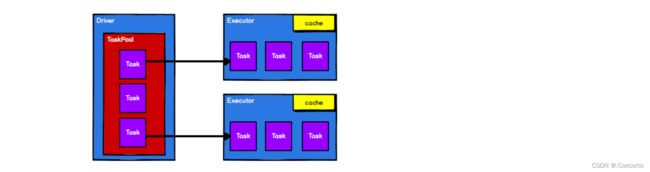
RDD 在整个流程中主要用于将逻辑进行封装,并生成 Task 发送给 Executor 节点执行计算
5.1.4 基础编程
- RDD创建
- 使用parallelize 和 makeRDD
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sparkContext = new SparkContext(sparkConf)
val rdd1 = sparkContext.parallelize(List(1,2,3,4))
val rdd2 = sparkContext.makeRDD(List(1,2,3,4))
rdd1.collect().foreach(println)
rdd2.collect().foreach(println)
sparkContext.stop()
- parallelize 和 makeRDD的关系
def makeRDD[T: ClassTag](seq: Seq[T],numSlices: Int = defaultParallelism):
RDD[T] = withScope {parallelize(seq, numSlices)
}
scala层面理解
创建一个RDD(弹性分布式数据集),其中包含了一个给定的序列。它使用了Spark的makeRDD方法,该方法接受一个序列和一个可选的分区数作为参数,并返回一个RDD对象。
在这段代码中,[T: ClassTag]表示类型T必须有一个ClassTag,这个ClassTag可以在运行时获取T的类型信息。这个ClassTag是隐式参数,因此在调用makeRDD方法时,可以不用显式地传递ClassTag参数,编译器会自动查找符合要求的隐式值。
seq是一个给定的序列,numSlices是可选的分区数,默认值为defaultParallelism,它表示默认的并行度,即在没有指定分区数时,使用的分区数。
withScope是一个Spark的方法,它用于创建一个新的作用域,以便在其中执行一些操作。在这段代码中,withScope方法用于将makeRDD方法的执行范围限定在当前作用域内,以便在执行过程中进行一些额外的操作。
最后,parallelize方法用于将序列转换为RDD,并将其分成指定数量的分区。这个方法返回一个RDD对象,它包含了分区后的数据,并可以在集群上进行并行计算。
总之,这段Scala代码的作用是创建一个包含给定序列的RDD,并将其分成指定数量的分区,以便在集群上进行并行计算。同时,它还使用了隐式参数和作用域限定等特性,以简化代码并提高可读性和可维护性。
改成java理解,但是java中没有Scala中的隐式参数(implicit parameter)的概念
public <T> RDD<T> makeRDD(Seq<T> seq, int numSlices) {
return withScope(parallelize(seq, numSlices));
}
- 从外部存储创建RDD,用textFile
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sparkContext = new SparkContext(sparkConf)
val fileRDD: RDD[String] = sparkContext.textFile("input")
fileRDD.collect().foreach(println)
sparkContext.stop()
- RDD 并行度与分区
- 可以设置并行度:,Spark 可以将一个作业切分多个任务后,发送给 Executor 节点并行计算,而能够并行计算的任务数量我们称之为并行度
makeRDD(List(1,2,3,4),4)和textFile(“input”,2)
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sparkContext = new SparkContext(sparkConf)
val dataRDD: RDD[Int] =sparkContext.makeRDD(List(1,2,3,4),4)
val fileRDD: RDD[String] =sparkContext.textFile("input",2)
fileRDD.collect().foreach(println)
sparkContext.stop()
- 读取内存分区的源码
数据可以按照并行度的设定进行数据的分区操作
def positions(length: Long, numSlices: Int): Iterator[(Int, Int)] = {
(0 until numSlices).iterator.map { i =>
val start = ((i * length) / numSlices).toInt
val end = (((i + 1) * length) / numSlices).toInt(start, end)
}
代码理解
这段Scala代码的作用是将一个长度为length的数据集分成numSlices个分区,并返回每个分区的起始位置和结束位置。具体来说,它使用了Scala的迭代器(Iterator)和映射(map)等函数式编程特性。
在这段代码中,positions方法接受一个长度为length的数据集和一个分区数numSlices作为参数,并返回一个迭代器,该迭代器包含了每个分区的起始位置和结束位置。
首先,(0 until numSlices).iterator生成了一个从0到numSlices-1的整数序列,并将其转换为一个迭代器。然后,map函数对每个整数i进行映射操作,将其转换为一个包含起始位置和结束位置的元组。
在映射操作中,start和end分别表示当前分区的起始位置和结束位置。它们的计算方式是根据分区数和数据集长度来确定的,具体来说,start的计算方式是(i * length) / numSlices,end的计算方式是((i + 1) * length) / numSlices。这样可以保证每个分区的大小大致相等,从而提高并行计算的效率。
最后,将start和end组成一个元组返回,即表示当前分区的起始位置和结束位置。这个迭代器可以用于将数据集分成指定数量的分区,并在集群上进行并行计算。
总之,这段Scala代码使用了函数式编程特性和迭代器等概念,以简化代码并提高可读性和可维护性。它的作用是将一个数据集分成指定数量的分区,并返回每个分区的起始位置和结束位置。
代码作用
这段代码是用来将一个长度为length的数据分成numSlices个部分的代码。
在Spark中,读取内存数据时,可以根据并行度的设定将数据进行分区操作,将数据分成多个部分,每个部分可以在不同的计算节点上并行处理,数据分区的数量可以通过并行度来控制,即将数据集分成的分区数。在读取内存数据时,可以使用positions方法来将数据集分成指定数量的分区,并在集群上进行并行计算。这样可以提高计算效率和性能,同时也可以避免资源竞争和调度问题。
分区规则:
数据分区规则可以根据具体的需求进行设定,比如可以按照数据的键值进行分区,或者按照数据的大小进行分区等。通过合理的数据分区,可以充分利用计算资源,提高计算效率。
转成java理解下
public Iterator<Tuple2<Integer, Integer>> positions(long length, int numSlices) {
return IntStream.range(0, numSlices).mapToObj(i -> {
int start = (int) ((i * length) / numSlices);
int end = (int) (((i + 1) * length) / numSlices);
return new Tuple2<>(start, end);
}).iterator();
}
- 读取文件数据时切片分区
数据是按照 Hadoop文件读取的规则进行切片分区,而切片规则和数据读取的规则有些差异
具体差异:
在Spark中,切片规则和数据读取规则有一些差异。具体来说,切片规则是用来将数据分成多个部分,以便在不同的计算节点上并行处理。而数据读取规则是用来从数据源中读取数据,并将其转换成Spark中的数据结构,以便进行后续的计算。在Spark中,切片规则和数据读取规则是分开的,因为它们的目的不同,需要采用不同的策略来实现。
具体来说,切片规则是由Spark的分区器来实现的。分区器是一个用来将数据分成多个部分的策略,可以根据不同的需求来选择不同的分区器。比如,可以使用Hash分区器将数据按照键值进行分区,也可以使用Range分区器将数据按照大小进行分区。分区器的选择可以根据数据的特点和计算任务的需求来进行调整,以便充分利用计算资源,提高计算效率。
数据读取规则则是由Spark的数据源来实现的。数据源是一个用来读取数据的接口,可以支持多种不同的数据源,比如HDFS、本地文件系统、数据库等。数据源可以根据不同的需求来选择不同的读取策略,比如可以使用并行读取来提高读取速度,也可以使用压缩算法来减少数据的存储空间。数据源的选择可以根据数据的来源和计算任务的需求来进行调整,以便充分利用计算资源,提高计算效率。
Hadoop中java源码
public InputSplit[] getSplits(JobConf job, int numSplits)throws IOException {
long totalSize = 0; // compute total size
for (FileStatus file: files) { // check we have valid files
if (file.isDirectory()) {throw new IOException("Not a file: "+ file.getPath());
}
totalSize += file.getLen();
}
long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits);
long minSize = Math.max(job.getLong(org.apache.hadoop.mapreduce.lib.input.FileInputFormat.SPLIT_MINSIZE, 1), minSplitSize);
...
for (FileStatus file: files) {
...
if (isSplitable(fs, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(goalSize, minSize, blockSize);
...
}
protected long computeSplitSize(long goalSize, long minSize,
long blockSize) {
return Math.max(minSize, Math.min(goalSize, blockSize));
}
代码理解
这段代码是Hadoop中FileInputFormat类的一个方法,用来计算输入数据的切片大小。
具体来说,该方法接受两个参数,一个是JobConf对象,另一个是切片的数量numSplits。方法首先计算输入数据的总大小totalSize,然后根据切片数量和总大小计算出每个切片的目标大小goalSize。接着,方法会检查输入数据是否合法,如果是一个目录则抛出异常。然后,方法会计算出每个切片的最小大小minSize,这个值可以通过JobConf对象的SPLIT_MINSIZE属性来设置。
接下来,方法会遍历输入数据中的每个文件,对于每个文件,如果它是可切分的,则计算出它的块大小blockSize和切片大小splitSize。计算切片大小的方法是,取minSize和goalSize的最大值,然后再取这个值和blockSize的最小值。最终,方法返回一个InputSplit数组,其中每个元素表示一个切片。