CVPR2022 多目标跟踪(MOT)汇总-补充篇
为该文章的后续补充https://blog.csdn.net/qq_34919792/article/details/124343166
七、《Multi-Object Tracking Meets Moving UAV》
作者: Shuai Liu†1, Xin Li†2, Huchuan Lu1,2, You He∗3
1Dalian University of Technology, 2Peng Cheng Laboratory, 3Naval Aeronautical University1Dalian, 2Shenzhen, 3Yantai, China
论文链接:https://openaccess.thecvf.com/content/CVPR2022/papers/Liu_Multi-Object_Tracking_Meets_Moving_UAV_CVPR_2022_paper.pdf
1、摘要
无人机(UAV)视频中的多目标跟踪是一项重要的视觉任务,可应用于广泛的应用。然而,传统的多物体跟踪器由于移动摄像机和三维方向的变化,不能很好地应用于无人机视频。在本文中,我们提出了一种专门用于无人机视图中的多目标跟踪的UAVMOT网络。UAVMOT引入了一个ID特性更新模块,以增强对象的特性关联。为了更好地处理无人机视图下的复杂运动,我们开发了一个自适应运动滤波器模块。此外,利用梯度平衡焦损失来解决不平衡类别和小目标检测问题。在VisDrone2019和UAVDT数据集上的实验结果表明,所提出的UAVMOT比现有的无人机视频跟踪方法取得了相当大的改进。
2、方法
从检测和快速运动目标匹配的角度来优化UAV的MOT。

这个方法是基于FairMOT来改的,主要改了两个地方。
1)增加了一个ID Feature Update,这个模块用了目标间的相互关系进行设计,通过相似性目标的增强和不相似目标的抑制来做一个ID embedding feature的增强。设计如下图:
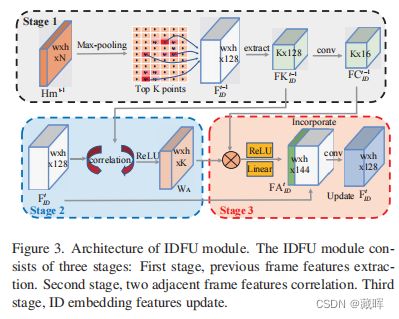
2)Local Relation Filter简单说就是通过无人机和物体的相互关系,把无人机的一些变化从外参补充给到物体位置。
八、《Towards Discriminative Representation: Multi-view Trajectory Contrastive Learning for Online Multi-object Tracking》
作者:En Yu1*, Zhuoling Li2∗
, Shoudong Han1†
1Huazhong Univerisity of Science and Technology 2Tsinghua University
论文链接:https://openaccess.thecvf.com/content/CVPR2022/papers/Yu_Towards_Discriminative_Representation_Multi-View_Trajectory_Contrastive_Learning_for_Online_Multi-Object_CVPR_2022_paper.pdf
1、摘要
判别表征是多目标跟踪中关联步骤的关键。最近的工作主要利用单个或相邻帧的特征来构建度量损失,并授权网络来提取目标的表示。虽然这一策略是有效的,但它不能充分利用整个轨迹中所包含的信息。为此,我们提出了一种策略,即多视图轨迹对比学习,其中每个轨迹都被表示为一个中心向量。通过在一个动态更新的存储库中保持所有的向量,设计了一个轨迹级对比损失来探索整个轨迹中的帧间信息。此外,在该策略中,每个目标被表示为多个自适应选择的关键点,而不是一个预定义的锚点或中心。这种设计允许网络从同一目标的多个视图中生成更丰富的表示,这可以更好地描述被遮挡的对象。此外,在推理阶段,提出了相似引导特征融合策略,进一步提高轨迹表示的质量。
2、方法



该工作主要做了两件事情。
1、认为JDE的方式用中心点无法很好的表征目标,所以他提出了一个offset网络,通过学习偏移量来找到更适合提取embedding的位置。并将这些向量融合成一个向量(类似求均值)
2、更新相似的。只有和之前模板中embedding相似的embedding才可以被更新到模板中,这个做法可以减少错误更新。但是如果目标不像的话或者模型性能不行的话,较容易造成丢目标。
九、《Whose Track Is It Anyway? Improving Robustness to Tracking Errors with Affinity-based Trajectory Prediction》
作者:Xinshuo Weng1,3, Boris Ivanovic3, Kris Kitani1, Marco Pavone2,3
Robotics Institute, Carnegie Mellon University
Department of Aeronautics and Astronautics, Stanford University
NVIDIA Research
论文链接:https://www.xinshuoweng.com/papers/Affinipred/camera_ready.pdf
1、摘要
多目标轨迹预测对于自动驾驶系统的规划和决策至关重要。然而,大多数预测模型都是与它们的上游感知(检测和跟踪)模块分开开发的,假设过去轨迹的GT作为输入。因此,当使用真实世界的噪声跟踪结果作为输入时,它们的性能显著下降。这通常是由从跟踪到预测的误差传播引起的,如有噪声的轨迹、轨迹断裂和切目标。为了减轻这种错误的传播,我们提出了一种新的预测范式,它使用检测及其跨帧的匹配矩阵作为输入,消除了在跟踪过程中容易出错的数据关联的需要。由于匹配矩阵包含关于跨帧检测的相似性和身份的“软”信息,直接从匹配矩阵进行预测比从数据关联生成的轨迹进行预测严格保留更多的信息。
2、方法
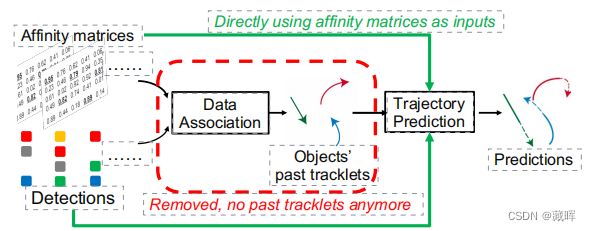

该文提出了一个基于匹配矩阵作为输入的Transformer框架,它消除了需要输入过去的轨迹和容易出错的数据关联步骤,并通过多帧detection的信息来获得更稳定的匹配效果。
该框架将匹配矩阵(iou或者embedding计算获得),原图和检测结果作为网络输入,输出是多个目标的轨迹预测。
1)对于检测结果,作者用了一个past embedding层和prediction embedding层(全连接层)作编码,将过去帧的所有检测结果编码为可以送入transformer的embedding表示。其中,提到可以选择的用一个地图(paper为自动驾驶领域工作,应该指的是BEV的地图)来辅助进行编码,即将地图编码的embedding信息和检测信息concat在一起之后,送入网络中获得每个历史检测的embedding。
考虑到embedding信息会失去时间性质,作者又把每一个detection对应的时间戳添加到embedding之中。
2)对于相邻帧的匹配矩阵,文中将两帧之间的单个匹配矩阵转换为来自所有帧的所有检测之间的一个联合匹配矩阵(如图中affinity construction)

3)输入获得之后,接下来就是如何处理了,对于已经编码好的信息了。对于embedding信息,transformer的很好就处理了。而匹配矩阵则是以一种注意力机制的方式,被融合到detection的信息之中。
4)在训练的过程中,作者引入了另外一个网络用于编码GT的embedding信息,用于中间监督(KL Loss)。此外用GT框来监督预测结果,也把预测的结果作为输入来参与后续轨迹的预测(这有利于网络的自适应,能减少一部分预测错误对后续预测带来的影响)。
十、《Adiabatic Quantum Computing for Multi Object Tracking》
作者:Jan-Nico Zaech1 Alexander Liniger1 Martin Danelljan1 Dengxin Dai1,2 Luc Van Gool1,3
Computer Vision Laboratory, ETH Zurich, Switzerland,
MPI for Informatics, Saarbrucken, Germany, KU Leuven, Belgium
论文链接:https://arxiv.org/pdf/2202.08837.pdf
1、摘要
多对象跟踪(MOT)通常出现在逐检测跟踪范式中,其中对象检测是通过时间关联起来的。关联步骤自然会导致离散优化问题。由于这些优化问题通常是np困难的,它们只能在当前硬件上的小实例中精确地解决。绝热量子计算(AQC)为此提供了一个解决方案,因为它有潜力在不久的将来为一系列np硬优化问题提供相当大的加速。然而,目前的MOT公式由于其尺度特性,不适合用于量子计算。因此,在这项工作中,我们提出了第一个设计用AQC来解决的MOT公式。我们采用了一个Ising模型来表示在AQC上实现的量子力学系统。我们证明,我们的方法与最先进的基于优化的方法相比是有竞争力的,即使在使用现成的整数编程求解器。最后,我们证明了我们的MOT问题已经可以在当前一代的真实量子计算机上解决的小例子,并分析了测量解的性质。
该工作不是做算法性能的优化的,而是做一种以量子力学来构建一种新的计算方式来解决匹配问题。
十一、《Time3D: End-to-End Joint Monocular 3D Object Detection and Tracking for Autonomous Driving》
作者:Peixuan Li
SAIC PP-CEM
论文链接:https://openaccess.thecvf.com/content/CVPR2022/papers/Li_Time3D_End-to-End_Joint_Monocular_3D_Object_Detection_and_Tracking_for_CVPR_2022_paper.pdf
1、摘要
而单独利用单目三维目标检测和2D多目标跟踪可以直接应用于序列图像逐帧的方式,独立跟踪器切断不确定性的传输从3D探测器跟踪而不能通过跟踪误差差异回到3D探测器。在这项工作中,我们提出以端到端方式从单目视频中联合训练三维检测和三维跟踪。关键组件是一个新的时空信息流模块,它聚合了几何和外观特征,以预测当前和过去帧中所有对象的鲁棒相似性得分。具体来说,我们利用了变压器的注意机制,即自注意聚集在特定框架内的空间信息,而交叉注意利用了序列框架的时间域内所有对象的关系和亲和关系。然后监督亲和度,以估计轨迹,并指导相应的三维物体之间的信息流动。此外,我们提出了一个时间一致性损失,明确地涉及到三维目标运动建模到学习中,使三维轨迹在世界坐标系中平滑。
2、方法

Time3D的架构细节。首先,将当前和以前的帧图像输入到Mono3D,以估计具有类别、2D Box、3D框和Re-ID特征的Top K目标。然后,将当前和之前的线索输入embedding ectractor,生成外观和几何嵌入。接下来,学习embeddings通过空间信息流在空间域中相互传播。最后,时间信息流跨帧匹配同一对象,计算匹配矩阵来估计轨迹,同时对输出速度、运动属性和box平滑度进行细化。
这是一个end-to-end的网络,网络中的每一部分参数在训练的过程中都会参与调整。
在推理阶段,作者保存了多个历史的embedding来进行匹配。通过累计多帧的结果来重构匹配矩阵(感觉这部分在训练中是否也可以进行监督来起到更好的效果)。

十二、《Opening up Open World Tracking》
作者:Yang Liu1,* Idil Esen Zulfikar2,* Jonathon Luiten2,3,* Achal Dave3,*
Deva Ramanan3 Bastian Leibe2 Aljosa O ˘ sep ˘
Laura Leal-Taixé1
Technical University of Munich, Germany 2RWTH Aachen University, Germany 3Carnegie Mellon University, USA
论文链接:https://arxiv.org/pdf/2104.11221.pdf
1、摘要
跟踪和检测任何物体,包括在模型训练中从未见过的物体,都是自主系统的一个关键但难以达到的能力。在现实世界中,一个自主代理对以前看不见的物体进行操作,会构成安全隐患——但这是几乎所有当前系统的工作方式。推进跟踪任何物体的主要障碍之一是,这项任务是出了名的难以评估。一个能够让我们对现有工作进行全面比较的基准,是推进这一重要研究领域的关键的第一步。本文解决了这一评价缺陷,并提出了在开放世界环境中检测和跟踪已知和未知物体的场景和评价方法。我们提出了一个新的基准,TAO-OW:在开放世界中跟踪任何对象,分析多对象跟踪中的现有努力,并为该任务构建一个基线,同时突出未来的挑战。
本工作说明了在实际场景中有很多未知物体需要进行Tracking,然而当前指标并不能很好的评测这类目标的跟随。本文提出了一套新的评价体系来促进该领域的发展。