【深度学习】BERT变种—百度ERNIE 3.0
预训练的模型在各种自然语言处理(NLP)任务中取得了最先进的成果。扩大预训练语言模型的规模可以提高其泛化能力。然而,现有的大规模预训练模型,主要依赖纯文本学习,缺乏大规模知识指导学习,模型能力存在局限。ERNIE 3.0 进一步挖掘大规模预训练模型的潜力,用于预训练大规模知识增强模型。
ERNIE 3.0框架,探索知识增强大规模预训练模型的有效性,对包括纯文本和知识图谱在内的大规模无监督语料进行模型预训练。此外,我们采用各种类型的预训练任务,使模型能够更有效地学习由有意义的词汇、句法和语义信息组成的不同层次的知识,其中预训练任务分布在三个任务范式中,即自然语言理解、自然语言生成和知识提取。因此,ERNIE 3.0创新性地设计了一个连续的多范式统一预训练框架,以实现多任务范式间的协同预训练。ERNIE 3.0的明确介绍将在以下节中说明。
论文题目:ERNIE 3.0: LARGE-SCALE KNOWLEDGE ENHANCED PRE-TRAINING FOR LANGUAGE UNDERSTANDING AND GENERATION
论文链接:https://arxiv.org/pdf/2107.02137.pdf
1. ERNIE 3.0简介
大规模预训练模型,带来了人工智能领域新的突破,由于其强大的通用性和卓越的迁移能力,掀起了预训练模型往大规模参数化发展的浪潮。但这些大规模的模型是在没有引入语言知识和世界知识的情况下对普通文本进行训练的。此外,大多数大型模型是以自回归的方式训练的。因此,这种传统的微调方法在解决下游语言理解任务时表现出相对较弱的性能。然而,现有的大规模预训练模型,主要依赖纯文本学习,缺乏大规模知识指导学习,模型能力存在局限。
ERNIE 3.0 的研究者进一步挖掘大规模预训练模型的潜力,为了解决单一的自回归框架造成的问题,并探索大规模参数的知识增强预训练模型的性能,首次在百亿级预训练模型中引入大规模知识图谱,用于预训练大规模知识增强模型,提出了海量无监督文本与大规模知识图谱的平行预训练方法(Universal Knowledge-Text Prediction)。
通过将大规模知识图谱的实体关系与大规模文本数据同时输入到预训练模型中进行联合掩码训练,促进了结构化知识和无结构文本之间的信息共享,大幅提升了模型对于知识的记忆和推理能力。
融合了自回归网络和自编码网络,在一个由普通文本和大规模知识图谱组成的4TB语料库上用100亿个参数训练该模型。因此,训练后的模型可以很容易地用于自然语言理解和生成任务的零样本学习、少样本学习或微调。
此外,该框架还支持随时引入各种定制任务。这些任务共享相同的编码网络并通过多任务学习进行训练。这种方法使不同任务之间的词汇、句法和语义信息的编码成为可能。此外,当给定一个新任务时,我们的框架可以根据以前的训练参数逐步训练分布式表征,而不需要从头开始训练。此外,为了帮助模型有效地学习词汇、句法和语义表征,ERNIE 3.0利用了ERNIE 2.0中引入的持续的多任务学习框架。
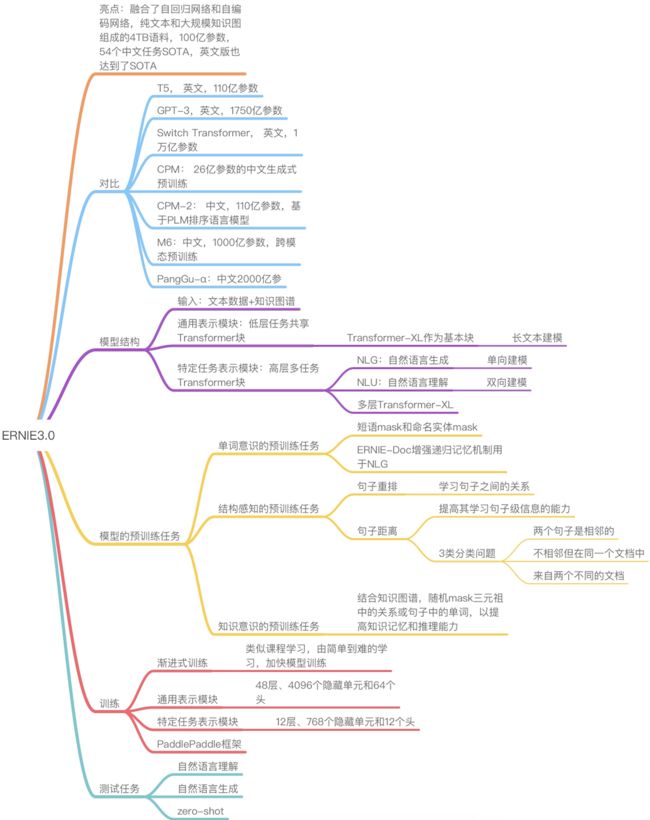
2.ERNIE 3.0框架
预训练语言模型从大规模语料库中获取句法和语义知识,但缺乏世界知识。世界知识的典型形式是一个知识图谱。许多工作将知识图谱中的实体和关系嵌入到预训练的语言模型中。
ERNIE 3.0的框架如图所示,它可广泛用于预训练、微调和零/少样本学习。具体来说,ERNIE 3.0采用了一个通用表示模块(主干共享网络)和两个特定任务表示模块的协作架构,即自然语言理解(NLU)特定表示模块和自然语言生成(NLG)特定表示模块。
ERNIE3.0 框架分为两层。第一层是通用语义表示网络,该网络学习数据中的基础和通用的知识,扮演着通用语义特征提取器的角色(例如,它可以是一个多层转化器),其中的参数在各种任务范式中都是共享的。第二层是任务语义表示网络,该网络基于通用语义表示,学习任务相关的知识。不同任务语义表示网络可通过自编码结构或者自回归结构实现,并通过底层共享实现交互和增强。在学习过程中,任务语义表示网络只学习对应类别的预训练任务,其中的参数是由特定任务的目标学习的,而通用语义表示网络会学习所有的预训练任务。

百度研究者提出了将通用语义表示与任务语义表示相结合的模型框架,该框架融合自编码和自回归等不同的任务语义表示网络,既可同时处理语言理解和语言生成任务,还能做无标注数据的零样本学习(Zero-shot Learning)和有标注数据的微调训练(Fine-tuning)。此外,ERNIE 3.0 在持续学习框架的基础上,增加了任务语义表示网络,加速模型进化。
2-1 通用表示模块
ERNIE 3.0使用多层Transformer-XL作为骨干网络,就像其他预训练模型如XLNet、Segatron和ERNIE-Doc一样,其中Transformer-XL与Transformer类似,但引入了一个辅助递归记忆模块以帮助对长文本建模。我们把这个骨干称为通用表示模块,它在所有的任务范式中都是共享的。众所周知,Transformer可以通过自我注意来捕捉序列中每个标记的上下文信息,并生成一个上下文嵌入的序列。显然,Transformer模型的规模越大,其捕捉和存储各种不同层次的语义信息的能力就越强。因此,ERNIE 3.0设置了规模较大的通用表示模块,使模型能够通过学习不同范式的各种预训练任务,有效地从训练数据中捕获通用的词法和句法信息。而需要特别注意的是,当控制注意力屏蔽矩阵时记忆模块只对自然语言生成任务有效。
2-2 特定任务表征模块
与基本的共享表征模块类似,特定任务表征模块也是一个多层Transformer-XL,用于捕获不同任务范式的顶层语义表征。ERNIE 3.0将特定任务的表征模块设置为可管理的规模,即基础模型规模,而不是多任务学习中常用的多层感知器或浅层Transformer,这将产生三个明显的好处,第一是基础网络比多层感知器和浅层Transformer有更强的捕捉语义信息的能力;第二是具有基础模型规模的特定任务网络使ERNIE 3. 0能够在不大幅增加大规模模型参数的情况下区分不同任务范式的顶层语义信息;最后,与共享网络相比,特定任务网络的模型规模更小,在只对特定任务表示模块进行微调的情况下,会导致大规模预训练模型的可实现的实际应用。ERNIE 3.0构建了两个特定任务的表示模块,即NLU特定表示模块和NLG特定表示模块,其中前者是一个双向的建模网络,而后者是一个单向的建模网络。
3.预训练任务
ERNIE 3. 0中为各种任务范式构建了几个任务,以捕捉训练语料中不同方面的信息,并使预训练模型具有理解、生成和推理的能力。
3-1 词汇感知的预训练任务
3-1-1 知识屏蔽语言模型
ERNIE 1.0提出了一个有效的策略,即知识整合屏蔽语言模型任务,通过知识整合来增强表示。它引入了短语屏蔽和命名实体屏蔽,预测整个被屏蔽的短语和命名实体,以帮助模型学习本地语境和全局语境中的依赖信息。
3-1-2 文档语言建模
生成性预训练模型通常利用传统的语言模型(如GPT、GPT-2)或序列到序列的语言模型(如BART、T5、ERNIE-GEN)作为预训练任务,后者在具有辅助解码器结构的网络上进行训练。ERNIE 3.0选择了传统的语言模型作为预训练任务,以降低网络的复杂性,提高统一预训练的效果。此外,为了使ERNIE 3.0的NLG网络能够对较长的文本进行建模,我们引入了ERNIE-Doc中提出的增强递归记忆机制,通过将移位一层向下递归改为同层递归,可以对比传统递归转化器更大的有效语境长度进行建模。
3-2 结构感知的预训练任务
3-2-1 句子重排
句子重排任务是在ERNIE 2.0中引入的,目的是训练模型通过重组排列的句段来学习句子之间的关系。在长度上,一个给定的段落在预训练中被随机分割成1到m个片段,所有组合被随机的排列组合洗牌。然后预训练的模型被要求重新组织这些排列组合的片段,被建模为一个k类分类问题。

3-2-2 句子距离
句子距离任务是传统的下一句预测(NSP)任务的延伸,被广泛用于各种预训练模型,以提高其学习句子级信息的能力,它可以被建模为一个3类分类问题。这三类分别代表两个句子是相邻的,不相邻但在同一个文档中,以及来自两个不同的文档。
3-3 知识感知的预训练任务
3-3-1 通用知识-文本预测
为了将知识纳入一个预训练语言模型,我们引入了通用知识-文本预测(UKTP)任务,它是知识屏蔽语言模型的延伸。知识屏蔽语言模型只需要非结构化文本,而通用知识-文本预测任务则需要非结构化文本和知识图谱。
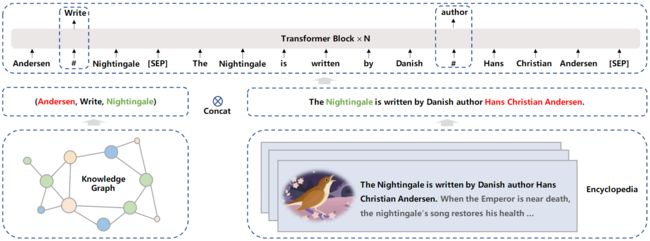
上图说明了通用知识-文本预测任务。给出一对来自知识图谱的三联体和来自百科全书的相应句子,我们随机屏蔽三联体中的关系或句子中的单词。为了预测三联体中的关系,模型需要检测头部实体和尾部实体的提及,并确定它们在相应句子中的语义关系。这个过程的本质与关系提取任务中的远距离监督算法相似。远距离监督算法认为,如果两个实体有某种关系,任何包含这两个实体的句子都可能表达这种关系。同时,为了预测相应句子中的词,该模型不仅考虑了句子中的依赖信息,还考虑了三联体中的逻辑关系。具体来说,获得一个三联体和这个对应句子的步骤如下:从百科全书中给定一个文档,我们首先在知识图谱中找到提及头部实体或尾部实体为该文档标题的候选三联体,然后从候选三联体中选择头部实体和尾部实体在该文档的同一句子中被提及的三联体。
ERNIE 3.0通过知识屏蔽语言建模训练NLU网络以提高捕获词法信息的能力,训练句子重排任务和句子距离辨别任务以加强捕获句法信息的能力,最后用通用知识-文本预测任务优化模型以提高知识记忆和推理能力。同时,ERNIE 3.0用文档语言建模任务训练NLG网络,以实现各种生成方式。
4.数据与设置
4-1 预训练数据
为了保证ERNIE 3.0预训练的成功,我们构建了一个大规模、多种类、高质量的中文文本语料库,存储量达4TB,分11个不同类别。据我们所知,与CLUECorpus2020(100GB)、中文多模态预训练数据(300GB)、CPM-2使用的WuDaoCorpus2.0(2.3TB中文数据和300GB英文数据)和PanGu Corpus(1.1TB)相比,这是目前最大的中文预训练语料。
具体而言,我们在ERNIE 2.0(包括百科、Feed等)、百度搜索(包括百家号、知乎、贴吧、经验)、网络文本、QA-long、QA-short、Poetry 2&Couplet 3、医疗、法律、金融等领域的特定数据以及百度知识图谱(超过5000万条事实)的基础上,为ERNIE 3.0建立了语料。为了提高数据质量,我们采取了以下预处理策略:
重复数据删除是在不同的粒度上进行的,包括字符级、段落级和文档级。在字符层面,我们用一个单一的字符替换连续的相同字符(即空格、制表符、感叹号、问号等)。在段落层面,我们用一个单一的段落替换两个由N个句子组成的相同的连续段落,其中0
我们进一步使用正则表达式进行句子分割,并基于百度的单词分割工具进行单词分割。这有助于ERNIE 3.0在预训练期间学习更好的句子边界和命名实体知识。
然后,每个数据集都要乘以用户定义的乘数,以增加截断数据后的数据多样性,用于NLU网络预训练。
4-2 预训练设置
ERNIE 3.0的通用表示模块和特定任务表示模块都使用Transformer-XL结构作为骨干。对于通用表示模块,我们采用了一个具有48层、4096个隐藏单元和64个头的结构。对于特定任务的表示模块,我们采用12层、768个隐藏单元和12个头的结构。通用表示模块和特定任务表示模块的总参数为100亿。使用的激活函数是GeLU。上下文的最大序列长度和语言生成的内存长度分别设置为512和128。所有预训练任务的总批次大小被设置为6144。我们使用Adam,学习率为1e-4,β1=0.9,β2=0.999,L2权重衰减为0.01,学习率在前一万步中进行预热,学习率线性衰减。在前一万步中,我们还使用渐进式学习来加速预训练初始阶段的收敛。该模型用384块NVDIA v100 GPU卡训练了总共3750亿个tokens,并在PaddlePaddle框架上实现。我们设法减少了我们的模型的内存使用,并解决了模型的总参数超过单个GPU卡的内存的问题。
4-3 微调任务的实验
4-3-1 自然语言理解任务的微调
1. 情感分析
情感分析是一项分类任务,旨在确定一个句子是积极的、消极的还是中性的。ERNIE 3.0使用了来自不同领域的4个数据集,包括购物(NLPCC2014-SC)、电子(SE-ABSA16_PHNS、SE-ABSA16_CAM)和金融(BDCI2019)。ERNIE 3.0在所有四个数据集上都实现了大幅改进。
2.观点提取
与情感分析任务类似,观点提取要求模型挖掘一个句子的观点。ERNIE 3.0使用了来自中国顾客评论(COTE)的3个子数据集。实验结果表明,ERNIE 3.0也以很大的优势超过了目前的SoTA系统。
3.自然语言推理
自然语言推理任务是确定一个给定的前提是否在语义上包含另一个假设。ERNIE 3.0使用OCNLI和XNLI数据集。结果表明,ERNIE 3.0在两个数据集上分别取得了3.9和0.7的准确性改进。在XNLI数据集上的改进相当有限,这可能是由于数据集的质量较差,因为XNLI数据集是从英语翻译过来的。
4.Winograd Schemas挑战赛
WSC2020是一项解决回指问题的任务,要求模型决定句子中的代词和名词是否共指,ERNIE 3.0取得了25.7分的重大改进。
5.关系提取
关系提取的任务是识别不同实体如人和组织之间的关系。ERNIE 3.0考虑了FinRE和SanWen这两个关系提取数据集,分别用于金融新闻和中国文学。ERNIE 3.0比以前的SoTA模型平均高出2.46分。
6.事件提取
与关系提取类似,事件提取任务的目的是识别事件实体并将其归入不同的类别。ERNIE 3.0选择CCKS2020–一个金融领域的文本级事件主体提取数据集。ERNIE 3.0在测试集上有3分的改进。
7.语义相似度
语义相似性是一项经典的NLP任务,它决定了各种术语如单词、句子、文档之间的相似性。ERNIE 3.0在不同领域的几个数据集上测试ERNIE 3.0,包括AFQMC、LCQMC、CSL、PAWS-X和BQ,专注于句子层面的相似性任务。实验结果表明,ERNIE 3.0的性能明显优于基线模型。特别是在参数数量相当的情况下,ERNIE 3.0在LCQMC数据集上以1.2分的优势超过了CPM-2。
8.中文新闻分类
ERNIE 3.0在中文新闻分类上进行了评估。ERNIE 3.0考虑了6个数据集,包括新闻标题(TNEWS)、应用描述(IFLYTEK)和新闻故事(THUCNEWS、CNSE、CNSS)。在不同类型的分类任务下,ERNIE 3.0能够持续实现更好的准确性,平均提高2.8分。
9.闭卷答题
闭卷答题的目的是直接回答问题,不需要任何额外的参考资料或知识。ERNIE 3.0选择了一个一般的QA数据集NLPCC-DBQA和三个医学领域的数据集–CHIP2019、cMedQA和cMedQA2来测试ERNIE 3.0的能力。实验结果表明,ERNIE 3.0在所有的QA任务上都表现得更好,知识增强的预训练方法确实给闭卷的QA任务带来了好处。
10.黑话理解
黑话,也被称为双关语,是人类的一种高级语言用法。然而,对于机器来说,理解这种类型的语言是相当困难的。在DogWhistle–一个基于Decrypto游戏的数据集上测试了ERNIE 3.0的cant理解能力。该模型需要在相应的cant的指导下选择正确的答案。ERNIE 3.0得到了最好的结果,并显示了它在理解更难的语言方面的潜力。
11.命名实体识别
命名实体识别是一项经典的NLP任务,对文本中的实体进行提取和分类。ERNIE 3.0选择了广泛使用的OntoNotes、CLUENER、微博,以及一个特定领域的数据集CCKS2019。从结果来看,ERNIE 3.0在所有数据集上的表现都优于基线模型。
12.机器阅读理解
全面评估了ERNIE 3.0在不同方面的机器阅读理解能力,包括跨度预测阅读理解(CMRC2018,DuReader,DRCD,DuReaderchecklist),多选阅读理解(C3,DuReaderyesno),cloze和完成(CHID,CMRC2019),以及鲁棒性测试(Dureaderrobust)。在知识强化预训练的帮助下,ERNIE 3.0超越了基线模型,在所有类型的任务上都有明显的提升。更具体地说,ERNIE 3.0在5个跨度预测任务上实现了至少1.0分的EM改进,在多项选择任务上平均实现了0.89分的准确性改进。另外,在参数数量相当的情况下,ERNIE 3.0在C3数据集上以0.6分的成绩超越了CPM-2。对于鲁棒性测试,ERNIE 3.0在具有过度敏感和过度稳定样本的测试集上也表现最好。
13.法律文档分析
为了测试ERNIE 3.0在文档分析上的能力,选择了两个特定领域的法律任务。这两个来自CAIL2018的数据集都是多标签的文档分类任务。ERNIE 3.0的性能优于ERNIE 2.0,并有明显的提升。
14.文档检索
文档检索的目的是匹配给定查询的文档。在搜狗日志上评估了ERNIE 3.0的检索能力。按照以前的工作,NDCG@1在测试-相同测试集上的表现和MRR在测试-原始测试集上的表现,ERNIE 3.0优于CPM-2。
4-3-2 自然语言生成任务的微调
1.文本摘要
我们考虑了大规模中文短文总结(LCSTS)数据集,它需要一个模型来理解文本并提炼关键信息,以生成连贯的、信息丰富的总结。LCSTS是一个经典的中文文本总结数据集,由200万个真实的中文短文和来自新浪微博的短文总结组成。ERNIE 3.0实现了48.46%的Rouge-L得分,超过了参数数量相当的CPM-2(11B)和目前的SoTA ProphetNet-zh。
2.问题生成
问题生成是机器阅读理解(MRC)的反向任务,要求模型理解文档并根据给定的简短答案生成一个合理的问题。ERNIE 3.0使用了三套数据集,包括知识库问题生成(KBQG),两个名为Dureader和Dureaderrobust的MRC数据集。与基线相比,ERNIE 3.0在这三个数据集上的表现最好。
3.数学
为了测试ERNIE 3.0执行简单算术运算的能力,使用了Math23K数据集,它包含了23161个小学生的真实数学单词问题,有问题描述、结构化方程和答案。ERNIE 3.0经过微调,可以根据问题描述生成结构化方程的后缀表达式,然后用Python的eval()函数计算出最终答案(注意’[‘和’]‘应分别替换为’(‘和’)‘,同时’%‘应替换为’*0.01’以避免使用Python的eval()函数解题失败)。这表明ERNIE 3.0是一个很好的数学求解器,与CPM-2的69.37%相比,实现了75%的高精确度。
4.广告生成
考虑AdGen,它由119K对广告文本和来自中国电子商务平台的服装规格表组成。 它要求模型生成一个长的广告文本,涵盖一件衣服的所有给定的属性-价值对。一个属性-价值对用冒号连接,几个属性-价值对根据其段号用"|"依次连接。然后把结构性的属性-价值对字符串作为ERNIE 3.0的输入。结果表明,ERNIE 3.0能够通过从结构输入中提取信息,生成连贯的、耐人寻味的长篇广告文本,与CPM-2相比,在BLEU-4上提高了19.56%。
5.翻译
对于ERNIE 3.0,主要考虑对中文语料库进行预训练。为了测试其多语言能力,实验中扩大了词汇量,包括额外的10K个英文子词。在经典的多语言数据集WMT20-enzh上,对ERNIE 3.0进行了微调,将英语翻译成中文。与mT5-xxLarge和CPM-2相比,ERNIE 3.0是最好的,呈现出卓越的多语言能力。
6.对话生成
使用ERNIE 3.0对对话生成任务进行评估。使用了一个中文多领域知识驱动的对话数据集,其中包含三个领域(电影、音乐和旅游)的4.5K对话。在上述三个领域的融合数据集上训练和测试ERNIE 3.0,只给出对话历史来生成当前语料。知识三要素被排除在输入之外,所以它适合于测试模型在预训练期间利用固有的知识来模拟多轮对话的能力。与基线相比,ERNIE 3.0的性能提高了很多,提高了8.1个百分点,验证了知识图谱极大增强了预训练属性。
5.总结
统一的框架ERNIE3.0,它结合了自回归网络和自编码网络,这样训练出来的模型就可以通过零样本学习、少样本学习或微调来处理自然语言理解和生成任务。
训练过程中用100亿个参数对大规模知识增强模型进行预训练,并在自然语言理解和自然语言生成任务上进行了一系列的实验评估。实验结果表明,ERNIE 3.0在54项基准测试中始终以较大的优势胜过最先进的模型,并在SuperGLUE基准测试中取得了第一名的成绩。