Django之路由层
一、路由的作用
路由即请求地址与视图函数的映射关系,如果把网站比喻为一本书,那路由就好比是这本书的目录,在Django中路由默认配置在urls.py中,如下图:
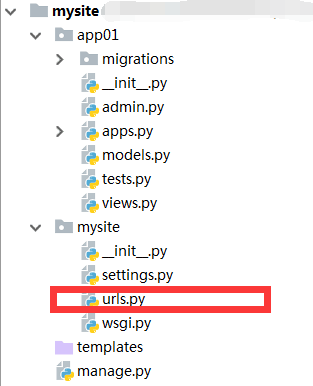
二、简单的路由配置
# urls.py
from django.urls import re_path
# 由一条条映射关系组成的urlpatterns这个列表称之为路由表
urlpatterns = [
re_path(regex, view, kwargs=None, name=None),
]
# re_path参数介绍
# 1、regex:正则表达式,专门用来匹配url地址(url地址中所有内容均被当作字符串)的路径部分,不考虑请求方法如GET、POST或者域名,例如:
# 请求url地址为:https://www.example.com/myapp/,,正则表达式要匹配的部分是myapp/
# 请求url地址为: https://www.example.com/myapp/?page=3, 正则表达式要匹配的部分是myapp/
# 注意:
# 1.1 django的url配置不会考虑请求方法,换句话说,对于相同的URL地址,所有的请求方法如POST、GET、HEAD等,都将被路由到相同的功能view上
# 1.2 切记正则表达式开头无需加/
# 2、view:通常为一个视图函数,用来处理业务逻辑
# 3、kwargs:额外传递给视图函数的参数,可选(用法详见第三小节:分组)
# 4、name:为正则表达式匹配到的url地址起别名,可选(用法详见第五小节:反向解析)案例:
urls.py文件
from django.contrib import admin
from django.urls import path, re_path # 导入re_path,关于path的使用我们在本章最后一小节介绍
from app01 import views # 导入模块views.py
urlpatterns = [
path('admin/', admin.site.urls), # 由django自动生成该行代码,本质与re_path一样都只是一条匹配规则而已,只不过该规则的实现由django框架提供(对应的视图为admin.site.urls),在没有正式介绍该行代码作用之前,忽略即可,暂时注释掉也可以
re_path(r'^index/$',views.index), # 新增一条
]
views.py文件
from django.shortcuts import render
from django.shortcuts import HttpResponse # 导入HttpResponse,用来生成响应信息
# 新增视图函数index
def index(request):
return HttpResponse('index page...')
测试:
python manage.py runserver 8001 # 在浏览器输入:http://127.0.0.1:8001/index/ 会看到 index page...注意事项
注意一:
正则表达式不需要添加一个前导的反斜杠,因为每个URL都有。例如,应该是^index而不是 ^/index
注意二:
每个正则表达式前面的'r' 是可选的但是建议加上
注意三:
如果我们想匹配的路径就只是index/,那么正则表达式应该有开始符与结束符, 如 ^index/$。这样逻辑才算严谨
注意四:
刚刚我们在浏览器输入:http://127.0.0.1:8001/index/,Django会拿着路径部分index/去路由表中自上而下匹配正则表达式,一旦匹配成功,则立即执行其后的视图函数,不会继续往下匹配,此处匹配成功的正则表达式是 r'^index/$'。
注意五:
但是我们在浏览器输入:http://127.0.0.1:8001/index,Django同样会拿着路径部分index去路由表中自上而下匹配正则表达式,貌似并不会匹配成功任何正则表达式( r'^index/$'匹配的是必须以 / 结尾,所以不会匹配成功index),但实际上仍然会看到结果 index page...,原因如下:
在配置文件settings.py中有一个参数APPEND_SLASH,该参数有两个值True或False
当APPEND_SLASH=True(如果配置文件中没有该配置,APPEND_SLASH的默认值为True),并且用户请求的url地址的路径部分不是以 / 结尾,例如请求的url地址是 http://127.0.0.1:8001/index,Django会拿着路径部分(即index)去路由表中匹配正则表达式,发现匹配不成功,那么Django会在路径后加 / (即index/)再去路由表中匹配,如果匹配失败则会返回路径未找到,如果匹配成功,则会返回重定向信息给浏览器,要求浏览器重新向 http://127.0.0.1:8001/index/地址发送请求。
当APPEND_SLASH=False时,则不会执行上述过程,即一旦url地址的路径部分匹配失败就立即返回路径未找到,不会做任何的附加操作
注意: 在输入一次url地址后,浏览器会将其记录到缓存中,若第二次输入相同的url地址,浏览器也会直接在url地址后填充/结尾,如果想规避浏览器缓存的影响,可以像下面这么测试,并且每次测试都换一下?后的变量,保证url地址每次都不同
http://127.0.0.1:8000/index?aaaaa=111111 对应视图函数index1
http://127.0.0.1:8000/index/?aaaaa=22222 对应视图函数index2
了解:
# django1.x中有一个函数url与Django2.x中的re_path一样,可以查看一下源码如下
'''
from django.conf.urls import url
...
def url(regex, view, kwargs=None, name=None):
return re_path(regex, view, kwargs, name)
'''
from django.urls import re_path # django2.x中的re_path
from django.conf.urls import url # 在django2.x中同样可以导入1.x中的url
urlpatterns = [
# 用法完全一致
url(r'^index/$', views.index),
re_path(r'^home/$', views.home),
]
django2.x还有一个path,它的用法牵扯到其他知识,所以我们将其放在最后介绍三、分组
什么是分组、为何要分组呢?比如我们开发了一个博客系统,当我们需要根据文章的id查看指定文章时,浏览器在发送请求时需要向后台传递参数(文章的id号),可以使用 http://127.0.0.1:8001/article/?id=3,也可以直接将参数放到路径中http://127.0.0.1:8001/article/3/
针对后一种方式Django就需要直接从路径中取出参数,这就用到了正则表达式的分组功能了,分组分为两种:普通分组与命名分组
1、普通分组
urls.py文件
from django.contrib import admin
from django.urls import path,re_path
from app01 import views
urlpatterns = [
path('admin/', admin.site.urls),
# 下述正则表达式会匹配url地址的路径部分为:article/数字/,匹配成功的分组部分会以位置参数的形式传给视图函数,有几个分组就传几个位置参数
re_path(r'^article/(\d+)/$',views.article),
]
views.py文件
from django.shortcuts import render
from django.shortcuts import HttpResponse
# 需要额外增加一个形参用于接收传递过来的分组数据
def article(request,article_id):
return HttpResponse('id为 %s 的文章内容...' %article_id)
测试:
python manage.py runserver 8001 # 在浏览器输入:http://127.0.0.1:8001/article/3/ 会看到: id为 3 的文章内容...2、命名分组
当我们对分组命名后,就会按照key=value的关键字参数形式为视图函数传参
urls.py文件
from django.contrib import admin
from django.urls import path,re_path
from app01 import views
urlpatterns = [
path('admin/', admin.site.urls),
# 该正则会匹配url地址的路径部分为:article/数字/,匹配成功的分组部分会以关键字参数(article_id=匹配成功的数字)的形式传给视图函数,有几个有名分组就会传几个关键字参数,需要强调一点是:视图函数得到的值均为字符串类型
re_path(r'^article/(?P\d+)/$',views.article),
] views.py文件
from django.shortcuts import render
from django.shortcuts import HttpResponse
# 需要额外增加一个形参,形参名必须为article_id
def article(request,article_id):
return HttpResponse('id为 %s 的文章内容...' %article_id)测试:
python manage.py runserver 8001 # 在浏览器输入:http://127.0.0.1:8001/article/3/ 会看到: id为 3 的文章内容...总结
普通分组和命名分组都是为了获取路径中的参数,并传递给视图函数,区别在于普通分组是以位置参数的形式传递,命名分组是以关键字参数的形式传递。
强调
普通分组和有名分组不要混合使用
3、指定默认值
# urls.py中
from django.urls import re_path
from app01 import views
urlpatterns = [
re_path(r'^article/$', views.article), # 第一条
re_path(r'^article/(?P\d+)/$',views.article), # 第二条
]
# views.py中,可以为num指定默认值
from django.shortcuts import HttpResponse
def article(request, article_id="1"):
return HttpResponse('id为 %s 的文章内容...' %article_id)
为视图函数article指定默认参数article_id="1"后,urlpattrens中的两条匹配规则就可以共用一个视图函数了,具体分析如下:
当url为:http://127.0.0.1:8080/article/时,匹配成功第一条
当url为:http://127.0.0.1:8080/article/111/时,匹配成功第二条 4、re_path的参数kwargs
如果我们想额外给视图函数传递参数,就用到了kwargs参数,该参数要求传入一个字典,会按照key=value的形式为视图函数额外传递参数,我们通常用kwargs中的参数来为多个共用一个视图函数的re_path做标记
# urls.py中
from django.contrib import admin
from django.urls import path,re_path
from app01 import views
urlpatterns = [
path('admin/', admin.site.urls),
re_path(r'^user/([a-zA-Z]+)/$', article,kwargs={'tag': 1}), # 第一条
re_path(r'^user/(\d{4})/$', article,kwargs={'tag':2}), # 第二条
re_path(r'^user/(\d{2})/$', article,kwargs={'tag':3}), # 第三条
]
# views.py中,可以为num指定默认值
def article(request, x,tag): # 通过tag的值即可判定是来自于匹配了不同的url
if tag == 1:
print('name is %s' %x)
elif tag == 2:
print('year is %s' %x)
elif tag == 3:
print('mon is %s' %x)
return HttpResponse('ok')
# 输入url地址依次测试即可
http://127.0.0.1:8080/user/egon/
http://127.0.0.1:8002/user/1995/
http://127.0.0.1:8002/user/12/注意:如果命名分组的名字与额外参数的key相同了,视图函数最终会获取额外参数中的值,所以应该尽量避免出现这种情况
# urls.py中
urlpatterns = [
re_path(r'^user/(?P\w+)/$', test,kwargs={'xxx':111})
]
# views.py中, xxx的值始终为111
def test(request,xxx):
print(xxx)
return HttpResponse('ok') 四、路由分发
随着项目功能的增加,app会越来越多,路由也越来越多,每个app都会有属于自己的路由,如果再将所有的路由都放到一张路由表中,会导致结构不清晰,不便于管理,所以我们应该将app自己的路由交由自己管理,然后在总路由表中做分发,具体做法如下
1 创建两个app
# 新建项目mystie2
E:\git>django-admin startproject mysite2
# 切换到项目目录下
E:\git>cd mysite2
# 创建app01和app02
E:\git\mysite2>python3 manage.py startapp app01
E:\git\mysite2>python3 manage.py startapp app022在每个app下手动创建urls.py来存放自己的路由,如下:
app01下的urls.py文件
from django.urls import re_path
# 导入app01的views
from app01 import views
urlpatterns = [
re_path(r'^index/$',views.index),
]app01下的views.py
from django.shortcuts import render
from django.shortcuts import HttpResponse
def index(request):
return HttpResponse('我是app01的index页面...')app02下的urls.py文件
from django.urls import re_path
# 导入app02的views
from app02 import views
urlpatterns = [
re_path(r'^index/$',views.index),
]app02下的views.py
from django.shortcuts import render
from django.shortcuts import HttpResponse
def index(request):
return HttpResponse('我是app02的index页面...')3 在总的urls.py文件中(mysite2文件夹下的urls.py)
from django.contrib import admin
from django.urls import path,re_path,include
# 总路由表
urlpatterns = [
path('admin/', admin.site.urls),
# 新增两条路由,注意不能以$结尾
# include函数就是做分发操作的,当在浏览器输入http://127.0.0.1:8001/app01/index/时,会先进入到总路由表中进行匹配,正则表达式r'^app01/'会先匹配成功路径app01/,然后include功能会去app01下的urls.py中继续匹配剩余的路径部分
re_path(r'^app01/', include('app01.urls')),
re_path(r'^app02/', include('app02.urls')),
]测试:
python manage.py runserver 8001
# 在浏览器输入:http://127.0.0.1:8001/app01/index/ 会看到:我是app01的index页面...
# 在浏览器输入:http://127.0.0.1:8001/app02/index/ 会看到:我是app02的index页面...五、反向解析
在软件开发初期,url地址的路径设计可能并不完美,后期需要进行调整,如果项目中很多地方使用了该路径,一旦该路径发生变化,就意味着所有使用该路径的地方都需要进行修改,这是一个非常繁琐的操作。
解决方案就是在编写一条re_path(regex, view, kwargs=None, name=None)时,可以通过参数name为url地址的路径部分起一个别名,项目中就可以通过别名来获取这个路径。以后无论路径如何变化别名与路径始终保持一致。
上述方案中通过别名获取路径的过程称为反向解析
案例:登录成功跳转到index.html页面
在urls.py文件中
from django.contrib import admin
from django.urls import path,re_path
from app01 import views
urlpatterns = [
path('admin/', admin.site.urls),
re_path(r'^login/$', views.login,name='login_page'), # 路径login/的别名为login_page
re_path(r'^index/$', views.index,name='index_page'), # 路径index/的别名为index_page
]在views.py中
from django.shortcuts import render
from django.shortcuts import reverse # 用于反向解析
from django.shortcuts import redirect #用于重定向页面
from django.shortcuts import HttpResponse
def login(request):
if request.method == 'GET':
# 当为get请求时,返回login.html页面,页面中的{% url 'login_page' %}会被反向解析成路径:/login/
return render(request, 'login.html')
# 当为post请求时,可以从request.POST中取出请求体的数据
name = request.POST.get('name')
pwd = request.POST.get('pwd')
if name == 'egon' and pwd == '123':
url = reverse('index_page') # reverse会将别名'index_page'反向解析成路径:/index/
return redirect(url) # 重定向到/index/
else:
return HttpResponse('用户名或密码错误')
def index(request):
return render(request, 'index.html')login.html
登录页面
index.html
首页
我是index页面...
测试:
python manage.py runserver 8001
# 在浏览器输入:http://127.0.0.1:8001/login/ 会看到登录页面,输入正确的用户名密码会跳转到index.html
# 当我们修改路由表中匹配路径的正则表达式时,程序其余部分均无需修改总结:
在views.py中,反向解析的使用:
url = reverse('index_page')
在模版login.html文件中,反向解析的使用
{% url 'login_page' %}拓展:
如果路径存在分组的反向解析使用:
from django.contrib import admin
from django.urls import path,re_path
from app01 import views
urlpatterns = [
path('admin/', admin.site.urls),
re_path(r'^article/(\d+)/$',views.article,name='article_page'), # 普通分组
re_path(r'^user/(?P\d+)/$',views.article,name='user_page'), # 命名分组
]
# 1 针对普通分组,比如我们要反向解析出:/article/1/ 这种路径,写法如下
在views.py中,反向解析的使用:
url = reverse('article_page',args=(1,))
在模版login.html文件中,反向解析的使用
{% url 'article_page' 1 %}
# 2 针对命名分组,比如我们要反向解析出:/user/1/ 这种路径,写法如下
在views.py中,反向解析的使用:
url = reverse('user_page',kwargs={'uid':1})
在模版login.html文件中,反向解析的使用
{% url 'user_page' uid=1 %}
# ps:如果有多个参数,按空格分隔开即可
{% url 'xxx_page' 1 2 %}
{% url 'yyy_page' a=1 b=2 %} 六、名称空间
当我们的项目下创建了多个app,并且每个app下都针对匹配的路径起了别名,如果别名存在重复,那么在反向解析时则会出现覆盖,如下
1 创建两个app
# 新建项目mystie2
E:\git>django-admin startproject mysite2
# 切换到项目目录下
E:\git>cd mysite2
# 创建app01和app02
E:\git\mysite2>python3 manage.py startapp app01
E:\git\mysite2>python3 manage.py startapp app022 在每个app下手动创建urls.py来存放自己的路由,并且为匹配的路径起别名
app01下的urls.py文件
from django.urls import re_path
from app01 import views
urlpatterns = [
# 为匹配的路径app01/index/起别名'index_page'
re_path(r'^index/$',views.index,name='index_page'),
]app02下的urls.py文件
from django.urls import re_path
from app02 import views
urlpatterns = [
# 为匹配的路径app02/index/起别名'index_page',与app01中的别名相同
re_path(r'^index/$',views.index,name='index_page'),
]3 在每个app下的view.py中编写视图函数,在视图函数中针对别名'index_page'做反向解析
app01下的views.py
from django.shortcuts import render
from django.shortcuts import HttpResponse
from django.shortcuts import reverse
def index(request):
url=reverse('index_page')
return HttpResponse('app01的index页面,反向解析结果为%s' %url)app02下的views.py
from django.shortcuts import render
from django.shortcuts import HttpResponse
from django.shortcuts import reverse
def index(request):
url=reverse('index_page')
return HttpResponse('app02的index页面,反向解析结果为%s' %url)3 在总的urls.py文件中(mysite2文件夹下的urls.py)
from django.contrib import admin
from django.urls import path,re_path
# 总路由表
urlpatterns = [
path('admin/', admin.site.urls),
# 新增两条路由,注意不能以$结尾
re_path(r'^app01/', include('app01.urls')),
re_path(r'^app02/', include('app02.urls')),
]4、测试:
python manage.py runserver 8001在测试时,无论在浏览器输入:http://127.0.0.1:8001/app01/index/还是输入http://127.0.0.1:8001/app02/index/ 针对别名'index_page'反向解析的结果都是/app02/index/,覆盖了app01下别名的解析。
解决这个问题的方法之一就是避免使用相同的别名,如果就想使用相同的别名,那就需要用到django中名称空间的概念,将别名放到不同的名称空间中,这样即便是出现重复,彼此也不会冲突,具体做法如下
1、总urls.py在路由分发时,指定名称空间
from django.contrib import admin
from django.urls import path,re_path,include
# 总路由表
urlpatterns = [
path('admin/', admin.site.urls),
# 传给include功能一个元组,元组的第一个值是路由分发的地址,第二个值则是我们为名称空间起的名字
re_path(r'^app01/', include(('app01.urls','app01'))),
re_path(r'^app02/', include(('app02.urls','app02'))),
]2、修改每个app下的view.py中视图函数,针对不同名称空间中的别名'index_page'做反向解析
app01下的views.py
from django.shortcuts import render
from django.shortcuts import HttpResponse
from django.shortcuts import reverse
def index(request):
url=reverse('app01:index_page') # 解析的是名称空间app01下的别名'index_page'
return HttpResponse('app01的index页面,反向解析结果为%s' %url)3、测试:
python manage.py runserver 8001浏览器输入:http://127.0.0.1:8001/app01/index/反向解析的结果是/app01/index/
在浏览器输入http://127.0.0.1:8001/app02/index/ 反向解析的结果是/app02/index/
总结+补充
1、在视图函数中基于名称空间的反向解析,用法如下
url=reverse('名称空间的名字:待解析的别名')2、在模版里基于名称空间的反向解析,用法如下
哈哈
七、django2.x中的path
在Django2.x中新增了一个path功能,用来解决:数据类型转换问题与正则表达式冗余问题,如下
urls.py文件
from django.urls import re_path
from app01 import views
urlpatterns = [
# 问题一:数据类型转换
# 正则表达式会将请求路径中的年份匹配成功然后以str类型传递函数year_archive,在函数year_archive中如果想以int类型的格式处理年份,则必须进行数据类型转换
re_path(r'^articles/(?P[0-9]{4})/$', views.year_archive),
# 问题二:正则表达式冗余
# 下述三个路由中匹配article_id采用了同样的正则表达式,重复编写了三遍,存在冗余问题,并且极不容易管理,因为一旦article_id规则需要改变,则必须同时修改三处代码
re_path(r'^article/(?P[a-zA-Z0-9]+)/detail/$', views.detail_view),
re_path(r'^articles/(?P[a-zA-Z0-9]+)/edit/$', views.edit_view),
re_path(r'^articles/(?P[a-zA-Z0-9]+)/delete/$', views.delete_view),
] views.py
from django.shortcuts import render,HttpResponse
# Create your views here.
def year_archive(request,year):
print(year,type(year))
return HttpResponse('year_archive page')
def detail_view(request,article_id):
print(article_id, type(article_id))
return HttpResponse('detail_view page')
def edit_view(request,article_id):
print(article_id, type(article_id))
return HttpResponse('edit_view page')
def delete_view(request,article_id):
print(article_id, type(article_id))
return HttpResponse('delete_view page')Django2.0中的path如何解决上述两个问题的呢?请看示例
from django.urls import path,re_path
from app01 import views
urlpatterns = [
# 问题一的解决方案:
path('articles//', views.year_archive), # 相当于一个有名分组,其中int是django提供的转换器,相当于正则表达式,专门用于匹配数字类型,而year则是我们为有名分组命的名,并且int会将匹配成功的结果转换成整型后按照格式(year=整型值)传给函数year_archive
# 问题二解决方法:用一个int转换器可以替代多处正则表达式
path('articles//detail/', views.detail_view),
path('articles//edit/', views.edit_view),
path('articles//delete/', views.delete_view),
] 强调:
#1、path与re_path或者2.x中的re_path的不同之处是,传给path的第一个参数不再是正则表达式,而是一个完全匹配的路径,相同之处是第一个参数中的匹配字符均无需加前导斜杠
#2、使用尖括号(<>)从url中捕获值,相当于有名分组
#3、<>中可以包含一个转化器类型(converter type),比如使用 使用了转换器int。若果没有转化器,将匹配任何字符串,当然也包括了 / 字符 django默认支持以下5种转换器(Path converters)
str,匹配除了路径分隔符(/)之外的非空字符串,这是默认的形式
int,匹配正整数,包含0。
slug,匹配字母、数字以及横杠、下划线组成的字符串。
uuid,匹配格式化的uuid,如 075194d3-6885-417e-a8a8-6c931e272f00。
path,匹配任何非空字符串,包含了路径分隔符(/)(不能用?)例如
path('articles////', views.article_detail)
# 针对路径http://127.0.0.1:8000/articles/2009/123/hello/,path会匹配出参数year=2009,month=123,other='hello'传递给函数article_detail
很明显针对月份month,转换器int是无法精准匹配的,如果我们只想匹配两个字符,那么转换器slug也无法满足需求,针对等等这一系列复杂的需要,我们可以定义自己的转化器。转化器是一个类或接口,它的要求有三点:
• regex 类属性,字符串类型
• to_python(self, value) 方法,value是由类属性 regex 所匹配到的字符串,返回具体的Python变量值,以供Django传递到对应的视图函数中。
• to_url(self, value) 方法,和 to_python 相反,value是一个具体的Python变量值,返回其字符串,通常用于url反向引用。
自定义转换器示例:
在app01下新建文件path_ converters.py,文件名可以随意命名
class MonthConverter:
regex='\d{2}' # 属性名必须为regex
def to_python(self, value):
print('===>to_python run')
return int(value)
def to_url(self, value):
print('===>to_url run')
return value # 匹配的regex是两个数字,返回的结果也必须是两个数字在urls.py中,使用register_converter 将其注册到URL配置中:
from django.urls import path,register_converter
from app01.path_converts import MonthConverter
register_converter(MonthConverter,'mon')
from app01 import views
urlpatterns = [
path('articles////', views.article_detail, name='aaa'),
] views.py中的视图函数article_detail
from django.shortcuts import render,HttpResponse,reverse
def article_detail(request,year,month,other):
print(year,type(year))
print(month,type(month))
print(other,type(other))
print(reverse('aaa',args=(1988,12,'hello'))) # 反向解析结果/articles/1988/12/hello/
return HttpResponse('xxxx')测试
# 1、在浏览器输入http://127.0.0.1:8000/articles/2009/12/hello/,path会成功匹配出参数year=2009,month=12,other='hello'传递给函数article_detail
# 2、在浏览器输入http://127.0.0.1:8000/articles/2009/123/hello/,path会匹配失败,因为我们自定义的转换器mon只匹配两位数字,而对应位置的123超过了2位