selenium 定位元素(并集)
并集:
answer = driver.find_element(By.CLASS_NAME, ‘info_content’ and ‘huida_con’).text
1. id
说明:通过元素的id属性来定位元素,具有唯一性,定位后基本不会重复
前提:元素有id属性
id定位方法:find_element(by=By.ID, value=’ ‘)或 find_element (“id”, value=’ ')
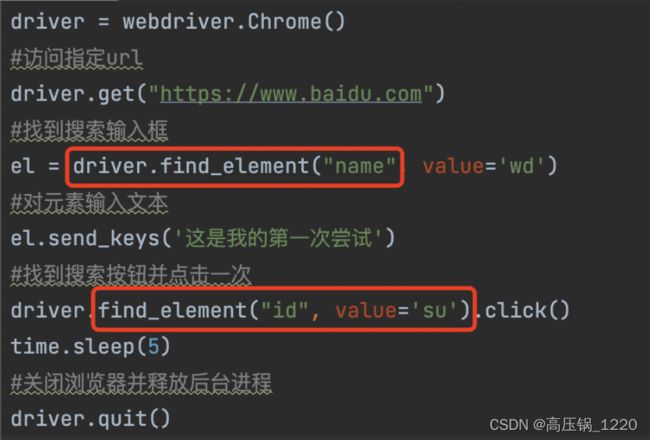
示例:打开百度搜索页面,通过id定位,输入搜索关键字
2. name
说明:通过name属性来指定元素名称,相对少见,但容易重名
前提:元素有name属性
name定位方法:find_element(by=By.NAME, value=’ ')或 同上
示例:打开百度搜索页面,通过name定位,输入搜索关键字
3. class_name
说明:指定元素的类名,通过class属性来定位;不推荐,重复的概率非常高
前提:元素有class属性
class_name定位方法:find_element (by=By.CLASS_NAME, value=’ ') 或 同上
示例:打开百度搜索页面,通过class_name定位,输入搜索关键字
4. tag_name
说明:HTML本质就是由不同的tag(标签)组成,而每个tag都是指同一类,所以一定会返回多个结果,一般不建议使用,可用于查找多个重复的内容的时候使用。
tag_name定位方法:find_element(by=By.TAG_NAME, value=’ ')
以下两种是根据超链接的文本定位
5. link_text
说明:link_text定位与前面4个定位有所不同,它专门用来定位超链接文本(文本值)
前提:定位的元素是链接标签(a标签)
link_text定位方法:find_element(by=By.LINK_TEXT, value=’ ')
示例:打开首页,通过link_text定位到登录按钮,并进行点击操作
6. partial_link_text
说明:partial_link_text定位是对link_text定位的补充,partial_link_text为模糊匹配;link_text为精确匹配。
前提:定位的元素是链接标签(a标签);通过传入a标签局部文本或全部文本来定位元素,要求输入的文本能够唯一找到这个元素
partial_link_text定位方法:find_element(by=By.PARTIAL_LINK_TEXT, value=’ ')
示例:打开百度首页,通过partial_link_text定位到新闻,并进行点击操作
元素路径定位(如果同一页面中有多个结构相同的元素,可以用xpath定位)
7. xpath
说明:有自己的独特语法,基于文件系统树状结构形态定位的
相对路径:类似于一种查询的调用
//*[@id=“kw”]
// 全局范围
*/a/span 任何一个元素或者增加筛选精度指定一个标签
[ ] 添加筛选条件
@ 表示添加的条件是属性
id 属性的名称
kw 属性的值
and 可以进行多个条件的关联
text() 可以通过文本来查找 eg://*[text()="新闻"]
/.. 通过子级定位到它的父级 eg: //*[@id="kw"] /..
/ 通过父级定位到它的子级 eg: //*[text()="新闻"] /span[1]
contains函数 eg: //a[contains(text(),"百度"])
contains() eg: form[contains(@id,"f"])
8. 元素定位之css selector(选择器定位)
find_element_by_css_selector("css选择器定位策略”)
find_elements_by_css_selector("css选择器定位策略”)
8.1 css可以通过元素的 id,class,标签 这三个常规属性直接定位到
tips:若用id定位,则用 #。若用class定位,则用 .
下面是百度搜索框的HTML代码:
通过css selector定位有如下三种常规方式:
find_element_by_selector(“#kw”) (#表示通过id定位)
find_element_by_selector(“.s_ipt”) (. 表示通过class定位)
find_element_by_selector("标签名“”) 其实单纯通过标签名来定位元素,是有很大局限性的,因为一个页面中,非常大可能的
存在标签名的重复,因此无法很精确的定位。
8.2 css通过其他属性定位
通过 标签+属性 即 标签名[属性名=属性值]。 还是以百度搜索框为例:
find_element_by_css_selector("input[autocomplete='off']")
tips:和xpath定位不同的是,标签名前不用// ,[ ]内的属性名前不用@符号,而xpath则需要。其余的规则与xpath相同。
如果属性是唯一的,那么标签名可以不用写。
8.3 层级定位
通过 父标签[父标签属性名=父标签属性值]>(或者空格)子标签 我们以百度搜索按钮为例:
find_element_by_css_selector("span[class='bg s_btn_wr']>input")
通过搜索按钮的父标签中的class属性定位,然后找到其子标签input,也就是我们的搜索按钮元素所在。
8.4 索引定位
当父标签中有很多相同的子标签时,通过索引找到所需要定位的元素。
通过 父标签[父标签属性名=父标签属性值]>子标签:nth-child(索引序号)
tips:索引从1开始
我们以126邮箱的密码输入框为例:
find_element_by_css_selector("div[class='u-input box]>input:nth-child(2)')
记住:用css_selector进行元素定位,父标签到子标签都用>或空格。如果用的是>,意思是指第一个子标签
而用空格的话,则可以为任何子标签。
8.5 逻辑定位
在xpath中,逻辑定位用到“and”,"or",“not”,而在我们的css_selector中,则不需要。
通过 标签名[标签名1= 属性值1][标签名2=属性值2]
同样,我们通过126邮箱的密码输入框为例:
8.6 模糊匹配
^:以什么开头
$:以什么结尾
*:匹配所有
find_element_by_css_selector(“标签名[属性名*(或^,或$)='属性值']”)
9 例子