容量与分级设计
YARN为它正在调度的资源定义了最小分配和最大分配:每个为YARN运行worker的服务器都有一个NodeManager,它提供资源分配,可以是内存和/或cpu核心。来自所有节点Node Managers的资源的集合作为容量调度器可用的所有资源的作为‘root’ 提供
Capacity Scheduler的基本基础是如何布局队列和如何为它们分配资源。队列是分层设计的,最上面的父队列是集群队列的“root”,从这里, leaf (child)队列可以从‘root’ 分配,或者分支本身可以有叶子节点。将容量作为层次结构中父队列的最小百分比和最大百分比分配给这些队列。最小容量是当集群上的所有资源都运行到极限时,队列应该期望拥有的可用资源量。最大容量是一种类似弹性的容量,它允许队列利用没有被用于填充其他队列中最小容量需求的资源
上图中的队列继承了父队列的资源。例如,在
Preference分支中,Low叶子队列获得Preference 20%最小容量的20%,而High 队列获得20%最小容量的80%。对于父节点下的所有叶子,最小容量必须总和为100%
Minimum User Percentage and User Limit Factor
Minimum User Percentage以及User Limit Factor如何在用户使用的队列中分配资源的方法。Minimum User Percentage是对单个用户在请求时应该访问的最小资源量的软限制。例如,10%的最小用户百分比意味着,假设10个用户都要求获得10%的用户百分比;这个值在某种意义上是软的,即如果其中一个用户要求的更少,我们可能会将更多用户放入队列中。
User Limit Factor是一种控制单个用户可以使用的最大资源数量的方法。用户限制因子设置为队列最小容量的倍数,其中用户限制因子为1表示用户可以使用队列的全部最小容量。如果用户限制因子大于1,则用户有可能增长到最大容量,如果该值设置为小于1,例如0.5,则用户将只能获得队列最小容量的一半。如果您希望用户也能够增长到队列的最大容量,则将值设置为大于1将允许用户超过最小容量多次。
原型
通过设计队列原型来描述队列中租户的有效行为,提供了一种度量更改的方法,以查看更改是否符合或偏离预期。虽然这不是一个完整的工作负载行为列表,但是下面的列表是一个很好的开始。当应用程序和最终用户执行模式类型时,创建您自己的组织所需队列类型的定义。
- AD-HOC
在这里可以运行随机的用户查询、未知的和新的工作负载,对资源分配行为没有任何期望,但可以作为最初运行应用程序的好地方,以了解每个应用程序的调优需求。 - 低延迟
这些应用程序应该在获得资源之前获取资源,并将资源保留更长时间。这可能是由于许多原因,如赶上应用程序、紧急运行或其他操作需求。 - 机器学习
机器学习应用程序的典型特点是运行时间长、资源需求大或密集。对于某些机器学习工作负载,任务的终止可以极大地延长持续时间,从而产生长时间运行的影响 - 仪表盘
并发性低(刷新率),但每天查询的数量多。仪表板需要在预期的时间内刷新,但工作负载是非常可预测的 - 探索
搜索用户需要低延迟的查询,需要通过非常大的数据集处理数据。资源很可能会在用户探索提供交互体验的整个过程中使用 - 批处理工作流程
旨在为转换和批处理工作负载提供通用计算需求。安装程序最关心的是应用程序的吞吐量,而不是单个应用程序的延迟 - 实时
应用程序总是在没有完成概念的情况下运行。在等待新工作到来的同时保持资源供应的应用程序。Slider部署了LLAP等实例
Container Churn
CHURN Container指的是,Queue能够持续不断地启动以及释放掉的容器。Queue能够重新快速地回到它的minimum capacity,以及能够将它的Capacity公平地分配给每个用户。
而于此相反,那些一直在运行,并且不会被释放的容器,则可能会导致Queue不能接受新的Application。
如果不允许preemption,那么资源永远不会被回收回来。所以,如果你发现一个Queue中,有这种Application,就要小心了。考虑把他们放到一个特殊的队列中,给启动这些Application的用户设置User Limit Factors,或者允许preemption.
CPU SCHEDULING (DOMINANT RESOURCE FAIRNESS)
在YARN中,默认情况下,是不允许CPU调度的。有一种叫做Dominant Resource Fairness(DRF)的方式,即选择那个你最常用的调度的资源类型进行调度。
如果按照这种方式,且按照CPU进行调度,那么CPU最终会成为系统的瓶颈。因为一个集群中,一般来说,CPU相对于内存来说,更容易成为瓶颈。
下面我们来看一幅图片,来了解按照CPU进行调度的话,启用的CPU更少
我们可以看到,如果按照内存进行调度,能够运行20个容器,而如果按照CPU进行调度的话,则仅仅只能运行10个容器。
Preemption
当应用程序在其队列中使用弹性容量时,另一个应用程序出现并要求返回其最小容量(在另一个队列中作为弹性使用)时,通常应用程序必须等待任务完成才能获得其资源分配。通过启用抢占,可以回收其他队列中的资源,为需要它的队列提供最小容量。抢占将尝试不彻底杀死一个应用程序,并将减少最后,因为他们必须重复更多的工作比映射器,如果他们不得不重新运行。从排序的角度来看,抢占首先查看最年轻的应用程序和最超额订阅的应用程序,以便回收任务。
另外,需要注意的是,由于preemption是跨Queue的,所以不要指望着,一个Queue中,会通过preemption的方式来保持各个用户分配到相等的资源。
Queue Ordering Policies
目前,容量调度器支持两种排序策略:FIFO和FAIR。默认的队列开始是FIFO,在我的经验中,这不是客户期望从他们的队列的行为。通过在Queue Leaf级别上配置FIFO和FAIR,您可以创建导致吞吐量驱动处理或在运行的应用程序之间共享公平处理的行为。关于排序策略需要了解的一件重要事情是,它们在队列中的应用程序级别操作,并不关心哪个用户拥有应用程序。
使用FIFO策略应用程序,按照最老到最年轻的顺序进行资源分配。如果一个应用程序有未完成的资源请求,它们会立即得到先到先得的处理。这样做的结果是,如果一个应用程序有足够多的未完成请求,它们将在完成之前多次使用整个队列,那么当其他应用程序作为最老的应用程序第一次被分配资源时,它们将阻止其他应用程序启动。正是这种行为对用户来说是最意想不到的,也是最令人不满的,因为用户甚至可以用自己的应用程序来阻止自己的应用程序!
这种行为在今天很容易通过使用FAIR排序策略来解决。当在叶队列上使用FAIR排序策略时,首先评估资源分配请求的应用程序,最先和最后使用最少资源的应用程序。这样,进入队列但没有处理资源的新应用程序将首先被要求获得所需的分配以启动。一旦队列中的所有应用程序都拥有资源,它们就会在所有请求资源的用户之间得到公平的平衡。
需要注意的是,这种行为只发生在队列中有良好的容器搅动的情况下。因为抢占在队列中不存在,资源不能在队列中强制重新分配,而且FAIR排序策略只关心资源的新分配,而不是当前的资源;这是什么意思?如果当前使用队列的任务从未完成或长时间运行,且不允许在队列中发生容器搅动,则该队列将持有资源并仍然阻止应用程序执行。
Username and Application Driven Calculations
当试图提供分配时,Capacity Scheduler中的计算将查看两个主要属性:用户名和应用程序ID。当提到在队列中的用户之间共享资源时,像最小用户百分比和用户限制因子都是着眼于用户名本身;如果您为多个用户使用一个服务帐户来运行作业,这显然会导致一些冲突问题,因为容量调度器只会显示一个用户。在一个队列中,应用程序获得的资源分配是由叶队列排序策略驱动的:FIFO或FAIR,它们只关心应用程序,而不关心哪个用户在运行它。在FIFO中,资源首先分配给队列中最老的应用程序,只有当它不再需要时,下一个应用程序才会得到分配。对于使用资源最少的FAIR应用程序,首先询问是否有待处理的分配,如果有,则完成,如果没有,则检查下一个资源最少的应用程序;这有助于与通常使用队列的应用程序平均共享队列。
Priority
当资源分配到多个队列时,相对容量最低的队列首先获得资源。如果您希望拥有一个高优先级队列,它在其他队列之前接收资源,然后切换到一个更高优先级的队列,这是一种简单的方法。如今,在LLAP和Tez中使用队列优先级可以实现更多的交互式工作负载,因为这些队列可以以更高的优先级分配资源,从而减少最终用户可能经历的终端延迟。
从上图中,我们可以看到,即使Queue B用的Capacity已经比较多了,但是由于相对来说,它的可用Capacity的比例比Queue A多,所以,新的Application还是会优先在Queue B上分配。
Default Queue Mapping
我们当然可以在提交Application的时候,通过指定Queue的名字来提交到特定的Queue。但是除此之外,我们还可以配置当我们没有指定Queue的名字时,通过一定的映射规则,将我们的Application提交到特定的Queue。有两种映射方法,一种是通过Group name,一种是通过User name。
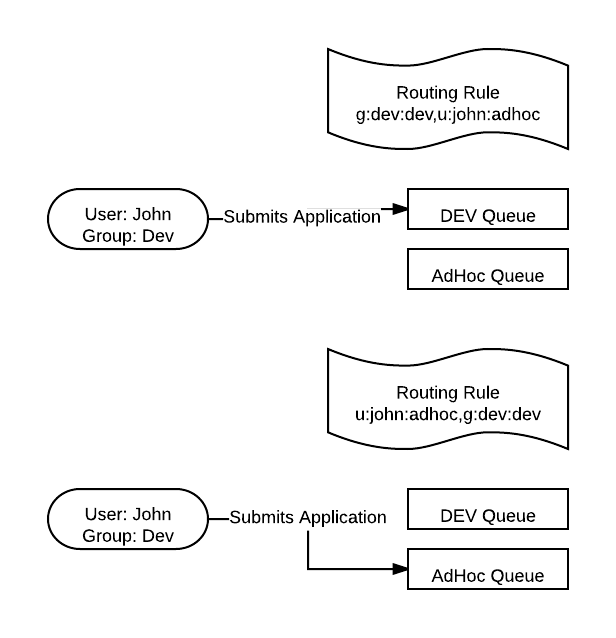
配置时,需要注意是把Group name还是User name放在前面,因为它总是会寻找最前面的那个
LABELS
标签最好描述为集群的分区。所有集群都以一个默认的标签或分区开始,这个默认的标签或分区是排他的,因为新的标签分区被添加到集群中,它们不与原始的默认集群分区共享。标签在创建时被定义为独占或共享,并且一个节点只能有一个分配给它的标签。标签更常见的用途是针对集群中的GPU硬件,或者仅针对集群的特定子集部署授权软件。如今,LLAP还使用标签来为长时间运行的进程利用专用主机。
共享标签允许其他有标签分区(如默认集群)中的应用程序成长为共享标签,并在没有特定应用程序请求标签的情况下利用硬件。如果出现了一个以标签为目标的应用程序,那么使用该标签的其他应用程序将从标记节点上被抢占,以便需要它的应用程序可以使用它。独家标签就是这样,独家的,不会被任何其他人分享;只有专门针对标签的应用程序才会在它们上面运行。为叶队列提供了对标记分区的访问,因此用户能够向它们提交,从而能够以标签为目标。如果你希望自动路由用户标签,例如创建一个GPU队列,自动使用GPU标签,这是可能的
Label,主要用于集群内部的partition。每个Node,都有一个与之相关的Label,就这样划分出了一个个的Partition。每个Partition都是相互独立的。
Label一般是用在集群中,标注有GPU硬件的Node.
也有一类Label比较特殊,即Shared label。标注有这些Label的节点,可以在空闲时,被其他的Application使用。而一旦有那些注明要使用这些Label标注的节点,那么,这些节点中的Application占用的资源就会被回收。
Queue Names
队列叶名称必须与容量调度器是唯一的。例如,如果你在容量调度器中创建了一个队列作为root.adhoc.dev, dev将必须是唯一的,作为所有队列名称的叶子,你不能有一个root.workflow.dev队列,因为它不再是唯一的。这与仅使用叶名而不是整个复合队列名指定提交队列的方式是一致的。叶子的父类永远不会被直接提交,也不需要是唯一的,所以你可以使用root.adhoc.dev和root.adhoc.qa,因为dev和qa都是唯一的叶子名称。
Limiting Applications per Queue
通过将许多应用程序启动到队列中来生成队列,从而使其中没有一个应用程序能够有效地完成,这可能会创建瓶颈并影响sla。在最坏的情况下,整个队列会陷入死锁,如果不进行物理kill作业,就无法进行处理,从而为计算任务释放资源。通过限制允许在叶队列中运行的应用程序的总数,可以很容易地防止这种情况的发生,或者可以控制Application master可以使用的叶队列资源的百分比。默认情况下,这个值通常相当大,超过10,000个应用程序(或叶资源的20%),如果需要,可以对每个叶进行配置,否则该值继承自叶的先前父队列。
Container Sizing
许多使用容量调度器的人不知道的是容器的大小是最小分配的几倍。例如,如果您的每个容器的最小调度器mb内存是1gb,而您请求的是4.5gb大小的容器,调度器将把这个请求舍入到5gb。如果最小值太高,这可能会造成很大的资源浪费问题,例如,如果最小值是4gb,如果我们要求5gb,我们将得到8gb的服务,从而提供我们从未计划使用的3gb !在配置容器大小的最小值和最大值时,最大值应能被最小值整除。
https://blog.cloudera.com/yarn-capacity-scheduler/
https://alstonwilliams.github.io/hadoop/2019/02/17/YARN%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90(6)-CapacityScheduler/