pytorch分布式训练
基础知识像rank,local_rank之类的就不讲了,自行百度吧。
总论:pytorch分布式训练中,数据并行主要依赖于multiprocessing和distributed。可以简单理解为multiprocessing用于开启多进程,distributed用于进程间通信。
另外,需要说明一点multiprocessing只是用于开启多进程,并不负责把张量分发到各个GPU,所以,一般在代码里面需要根据rank的变化,自行设定不同的GPU,并把张量放上去。
目录:
一:分布式训练的原理
1:多进程运行:torch.multiprocessing
补充知识点:multiprocessing.Queue;multiprocessing.Value
2:进程间通信:torch.distributed
第一部分主要参考自:PyTorch单机多卡分布式训练教程及代码示例_zzxxxaa1的博客-CSDN博客_分布式训练代码
Pytorch多进程最佳实践
二:pytorch自带的分布式训练封装包
三:最后的一点实验小补充(彩蛋)
一:分布式训练的原理
1:多进程运行:torch.multiprocessing
python文件可以通过引入这个模块来开启多个进程,方法如下:
#run_multiprocess.py
#运行命令:python run_multiprocess.py
import torch.multiprocessing as mp
def run(rank, size):
print("world size:{}. I'm rank {}.".format(size,rank))
if __name__ == "__main__":
world_size = 4
mp.set_start_method("spawn")
#创建进程对象
#target为该进程要运行的函数,args为target函数的输入参数
p0 = mp.Process(target=run, args=(0, world_size))
p1 = mp.Process(target=run, args=(1, world_size))
p2 = mp.Process(target=run, args=(2, world_size))
p3 = mp.Process(target=run, args=(3, world_size))
#启动进程
p0.start()
p1.start()
p2.start()
p3.start()
#当前进程会阻塞在join函数,直到相应进程结束。
p0.join()
p1.join()
p2.join()
p3.join()具体过程如下:
①:mp.set_start_method("spawn") :设定multiprocessing启动进程的方式,一般在主模块的if __name__ == '__ main__’语句后就要设置好;multiprocessing支持三种启动进程的方法:spawn/fork/forkserver。一般我们都用spawn,三者具体的内容,参考:
python mutilprocessing多进程编程_jeffery0207的博客-CSDN博客_set_start_method
②:p = mp.Process(target=func, args=(args)):开启一个进程,进程运行程序func,函数参数为args。
③:p.start():启动进程
④:p.join():当前进程阻塞,直到相应进程结束。主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)
阻塞/非阻塞;同步/异步:参考自:
同步和阻塞_树上的疯子^的博客-CSDN博客_同步和阻塞
同步与堵塞_鹿几三三的博客-CSDN博客_同步和阻塞同步异步以及阻塞和非阻塞的区别_格城先生的博客-CSDN博客_阻塞和非阻塞区别
首先:要明确,
同步和异步是相对于操作结果来说,会不会等待结果返回;
阻塞和非阻塞是相对于线程是否被阻塞;




补充知识点:
补充1:队列 multiProcess.Queue
可以使用来实现多进程之间的数据传递。参考自:
python mutilprocessing多进程编程_jeffery0207的博客-CSDN博客_set_start_methodPython进程间通信 multiProcessing Queue队列实现详解_python_脚本之家 (jb51.net)
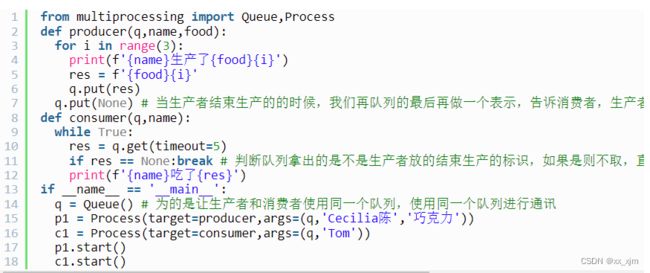
补充2:进程共享状态: multiprocessing.Value, multiprocessing.Array
参考自:python mutilprocessing多进程编程_jeffery0207的博客-CSDN博客_set_start_method
2:进程间通信:torch.distributed
参考自:PyTorch单机多卡分布式训练教程及代码示例_zzxxxaa1的博客-CSDN博客_分布式训练代码
上面的torch.multiprocessing主要是用来启动多进程的,虽然我们上面补充了几个知识点,用以说明其本身也可以用于通信,但太麻烦了,pytoch给我们设计了专门用于通信的包,也就是torch.distributed。
使用torch.distributed最主要就是初始化,建立进程间的通信:
dist.init_process_group(backend, init_method, rank, world_size)
backend:指定通信所用的后端,可以是nccl或者是gloo或者是mpi,nccl用于GPU,gloo用于CPU。
init_method:指定如何初始化互相通讯的进程,可以选择tcp方式或者共享文档的方式;默认为 env://,表示使用读取环境变量的方式进行初始化,该参数与store互斥。这里格外说一点,我们在分布式训练中常用的os.environ['MASTER_ADDR'] = 'localhost'和os.environ['MASTER_PORT'] = '12355':主节点的地址和端口,就是用来供给init_method使用的。
参考自:PyTorch分布式DPP涉及的基本概念与问题_9eKY的博客-CSDN博客
rank:就是当前进程的rank号,对于单机多卡来说,rank = local_rank;而对于多机多卡来说,这里的rank不等于local_rank。也就是说,rank就是0-world_size-1;顺序上去,因为多机多卡的情况下,你在非主机的代码上运行的时候,不同主机的rank不需要你手动设置。
world_size: 就是总的进程数量。
还值得注意的点在于,不同进程运行到dist.init_process_group(backend, init_method, rank, world_size)的时候,会阻塞,直到确定所有进程都可以通信为止。
二:pytorch自带的分布式训练启动函数
像上面这样,先用mp.Process启动进程,再用dist.init_process_group()来建立进程间的通信,其实就已经完成了单机多卡的分布式训练(如果是多级多卡,其实只需要设置一下dist.init_process_group()就可以了),但大家也可以看出,这样真的太麻烦了,而且mp.Process就有点类似于我在终端执行多次python train.py。
其实这里我们说的自带的分布式训练启动函数也来源于torch.distributed和torch.multiprocessing。
分别为torch.distributed.launch和torch.multiprocessing.spawn()
其中torch.distributed.launch是通过python的subprocess来实现多进程,必须命令行启动,不方便pycharm进行debug,并且最新的官方给出,可能会把这条命令替换掉,所以不建议使用。
而torch.multiprocessing.spawn()则是通过nn.Process的模块来实现多进程,且强制要求start_method=spawn。
以上两者的区别在于spawn的启动效率非常低,但是接口比较友好,跨平台也比较方便,spawn还有一个问题是会将运行时序列化,如果有有很大的对象的话(如>4GB)则会运行失败,但是subprocess就不会有这样的问题。
参考自:【机器学习】Pytoch分布式多机多卡的启动方式详解 - 知乎 (zhihu.com)
还有一点值得注意的是这两者会自动给函数赋值rank,所以,对于函数main需要多设置一个参数
形式如def main(rank, args)
则调用的时候为mp.spawn(fn, args, nprocs, join, daemon):
- fn:派生程序入口;
- nprocs: 派生进程个数;
- join: 是否加入同一进程池;
- daemon:是否创建守护进程;
最后的一点实验小补充:
1:torch.distributed函数自带的点对点通信原语:dist.send,dist.recv,dist.isend,dist.irecv等通信的时候,是对通信的张量进行替换,而不是加和。
2:dist.send和dist.recv以及dist.isend,dist.irecv都要考虑到一个通信的先后问题,因为没办法保证哪一个进程更快,所以通信的时候要设置号先后顺序。尤其是在一个进程,既需要接收,也需要发送的时候。比如下面这里,因为没法确定哪个进程更快,所以我让每个进程的接收都比发送慢一点,这样保证另外一个进程已经完成发送。
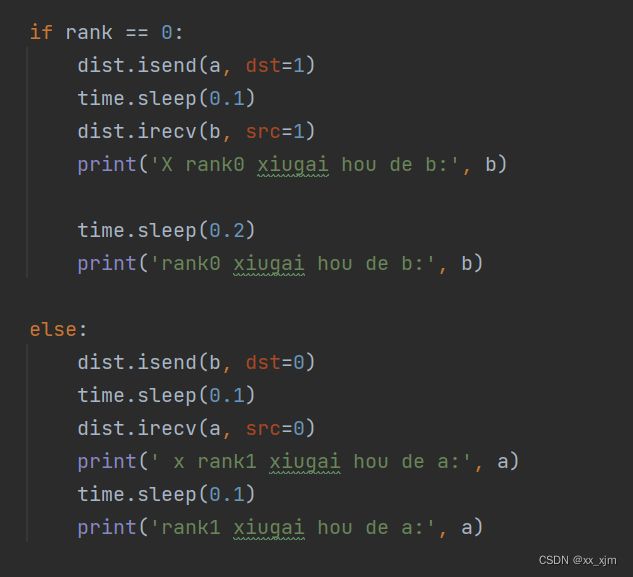
3: 这一点就是非常奇怪的一点,暂时没弄明白原因,只是实验结果,记住就好,有大佬看到这里的话,希望能指条明路:
如下,在只设置
os.environ['CUDA_VISIBLE_DEVICES'] = str(rank)
的时候,因为不同进程rank肯定不一样,按理来说,应该不同进程在不同GPU,但实验结果表明这样无法成功将张量转移到GPU。
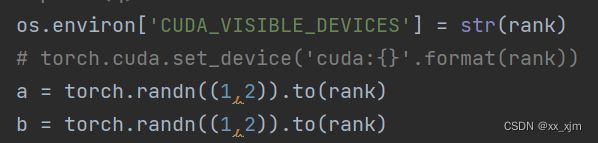
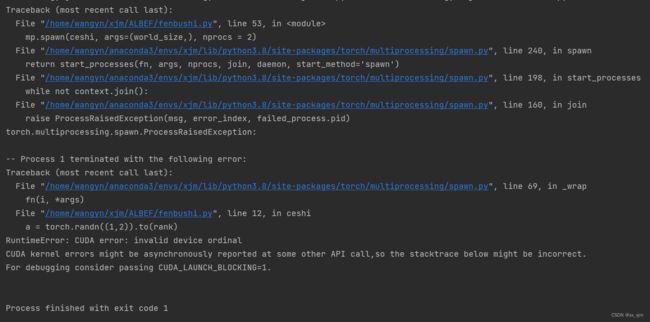
但是在加上一句:
q = torch.cuda.device_count()
以后,程序可以正常运行了,不知道是为什么。贴一段完整代码
import torch.multiprocessing as mp
import torch.distributed as dist
import torch
import os
import time
def ceshi(rank,world_size):
#
q = torch.cuda.device_count()
# print(q)
os.environ['CUDA_VISIBLE_DEVICES'] = str(rank)
# torch.cuda.set_device('cuda:{}'.format(rank))
a = torch.randn((1,2)).to(rank)
b = torch.randn((1,2)).to(rank)
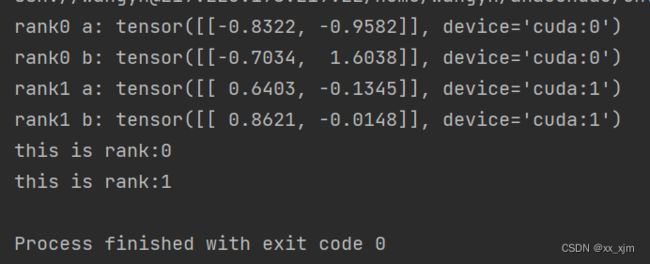
print('rank{} a:'.format(rank), a)
print('rank{} b:'.format(rank), b)
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
dist.init_process_group(backend = 'nccl', rank = rank,world_size = world_size)
print('this is rank:{}'.format(rank))
# if rank == 0:
# dist.isend(a, dst=1)
# time.sleep(0.1)
# dist.irecv(b, src=1)
# print('X rank0 xiugai hou de b:', b)
#
# time.sleep(0.2)
# print('rank0 xiugai hou de b:', b)
#
# else:
# dist.isend(b, dst=0)
# time.sleep(0.1)
# dist.irecv(a, src=0)
# print(' x rank1 xiugai hou de a:', a)
# time.sleep(0.1)
# print('rank1 xiugai hou de a:', a)
# if rank == 0:
# dist.recv(a, src=1)
# dist.send(b, dst=1)
# print('rank0 xiugai hou de a:',a)
# else:
# dist.recv(a, src=0)
# dist.send(b, dst=0)
# print('rank1 xiugai hou de a:', a)
if __name__ == '__main__':
world_size = 2
mp.spawn(ceshi, args=(world_size,), nprocs = 2)
# help(torch.multiprocessing.spawn)结果如下: