Apache Superset产品调研
Apache Superset产品调研
调研报告:Apache Superset
一、概述
Apache Superset是一个开源的数据可视化和数据探索平台,它提供了一个用户友好的界面,可以轻松地创建和分享仪表板。它支持多种数据源,包括SQLAlchemy兼容的数据库、CSV文件、Apache Druid、Elasticsearch等。Apache Superset是一个基于Python编写的Web应用程序,使用Flask作为Web框架,使用React和Bootstrap作为前端UI库。后端使用SQLAlchemy进行数据库访问,支持多种关系型数据库。同时,Apache Superset使用Celery作为任务队列,支持异步任务处理。Apache Superset是一个开源项目,得到了广泛的社区支持。目前它在GitHub上有2800+的Star和1000+的Fork,有数百名开发者和用户参与了项目的开发和使用。同时,Apache Superset还有一个活跃的邮件列表和Slack频道,用户可以在这里获得技术支持和交流。
二、功能特点
1. 强大的可视化工具
Apache Superset提供了多种可视化工具,包括Bar Chart、Box Plot、Heatmap、Pie Chart、Sankey Diagram等。这些可视化工具可以帮助用户更好地理解数据,发现数据中的规律和趋势。

2. 灵活的数据源接入
Apache Superset支持多种数据源接入,包括SQLAlchemy兼容的数据库、Apache Druid、Elasticsearch等。用户可以轻松地将数据源接入Apache Superset,进行数据探索和数据可视化。
Apache Superset支持的数据库列如下:

| MySQL | Apache Kylin | Exasol | MonetDB | Druid (Apache) |
| PostgreSQL | Apache Pinot | MemSQL | Greenplum | Elasticsearch |
| SQLite | Apache Solr | MariaDB | SAP ASE | Google Cloud Spanner |
| Microsoft SQL Server | Apache Spark | CockroachDB | Amazon Athena | MapD |
| Oracle | Apache HBase | YugabyteDB | Amazon EMR | MongoDB |
| Amazon Redshift | Snowflake | Presto | Apache Flink | Neo4j |
| Google BigQuery | Teradata | ClickHouse | Apache NiFi | SAP IQ |
| Apache Druid | Vertica | InfluxDB | Apache Pulsar | ScyllaDB |
| Apache Hive | IBM DB2 | TimescaleDB | Apache Samza | TiDB |
| Apache Cassandra | SAP HANA | CrateDB | Apache ZooKeeper | TIBCO Spotfire |
在连接各数据库前,需要先下载对应数据库的driver,详情参见官网:https://superset.apache.org/docs/databases/installing-database-drivers/
注:SQLAlchemy [ˈælkəmi] 是一个Python SQL工具包和对象关系映射(ORM)库,它允许Python开发人员在应用程序中使用SQL。SQLAlchemy提供了一种Pythonic的方式来操作关系型数据库,同时也提供了一个强大的ORM框架,使得开发人员可以把数据库模型表示为Python类,从而可以更容易地进行数据库操作和数据访问。 SQLAlchemy还支持多种数据库后端,包括MySQL、PostgreSQL、Oracle、SQLite等。
3. 用户友好的界面
Apache Superset提供了一个直观、易用的用户界面,用户可以通过拖放来创建仪表板。用户可以根据自己的需求,自由地设计和组织仪表板。
4. 全面的安全性
Apache Superset支持多租户,可以为不同的用户组提供不同的权限。这样可以保障每个用户组的数据安全性和隐私性。用户可以通过多种方式来保障数据的安全性,包括访问控制、数据加密等。
三、使用场景
1. 数据探索
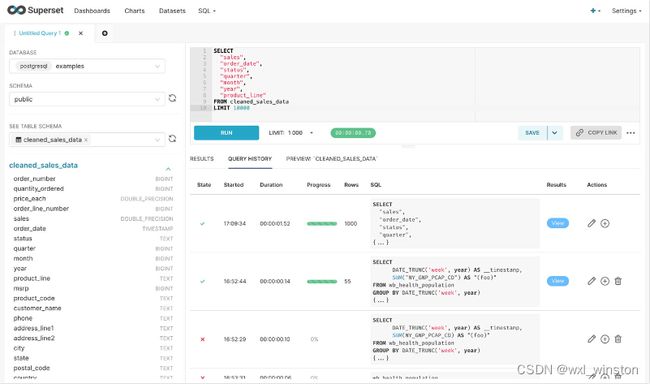
Superset具有“SQL Lab”模块,可作为一个数据库管理工具,SQL查询面板可以对已连接的数据源进行数据查询,对数据源进行配置选择后也可实现数据库表的创建、修改和删除。
2. 数据可视化
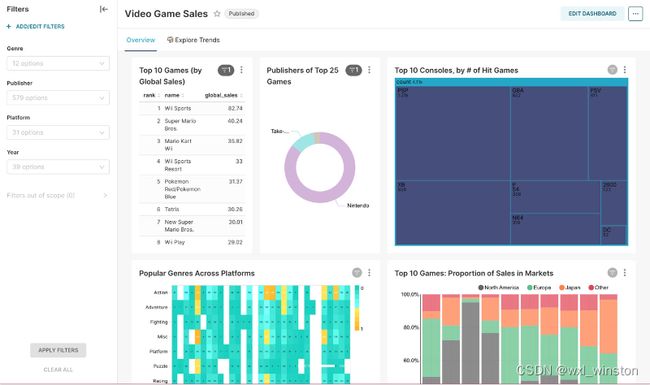
Superset可用于数据可视化成果共享,实现团队协同,使用者可将制作好的图表或发布的dashboard可见于团队成员,并通过权限配置控制团队成员对它们的可编辑性,各成员可发挥各自的想法,实现迭代化更新。用户可以通过Apache Superset来创建各种可视化图表,包括Bar Chart(柱状图)、Box Plot(箱线图)、Heatmap(热力图)、Pie Chart(饼图)、Sankey Diagram(桑基图)等。
3. 数据分析
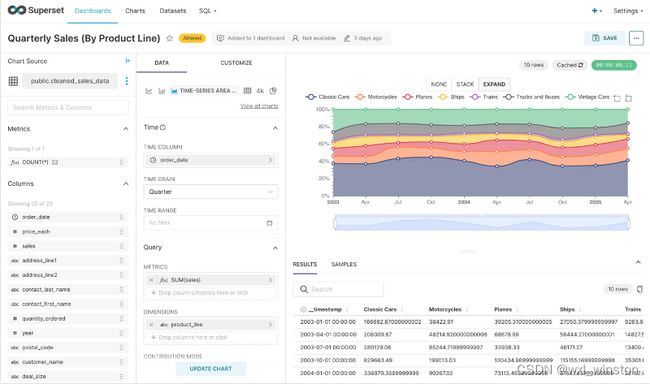
Superset是一款自助式的BI工具,可利用于探索式的日常数据分析中,它能够对接常用的大数据分析工具、能够连接主流数据库或直接上传CSV数据文件,内含多类型展示图表样式,使用者通过自定义图表或dashboard可以直观地发现、分析、预警数据中所隐藏的问题,及时应对业务中的风险或发现增长点。
四、优劣分析
1. 优点
(1)Apache Superset提供了多种可视化工具,可以帮助用户更好地理解数据。 (2)Apache Superset支持多种数据源接入,包括SQLAlchemy兼容的数据库、Apache Druid、Elasticsearch等。 (3)Apache Superset提供了一个直观、易用的用户界面,用户可以通过拖放来创建仪表板。 (4)Apache Superset支持多租户,可以为不同的用户组提供不同的权限,保障数据的安全性和隐私性。
2. 缺点
(1)Apache Superset的可视化工具相对比较简单,不适用于一些复杂的数据可视化需求。 (2)Apache Superset对于大数据量的数据处理能力有限,不适用于一些大数据处理需求。
五、安装部署
关于Apache Superset的安装部署,可参见:
https://superset.apache.org/docs/databases/installing-database-drivers/
https://www.cnblogs.com/gkmin/p/16616140.html
六、实战入门
在该部分将通过疫情dashboard、企业客户dashboard这两个dashboard实例制作来了解Superset的功能,dashboard的制作可分为四步:连接数据源、添加及设置table、制作charts、制作dashboard;同时可在“SQL Lab”对数据库表的数据进行查询及结果可视化。首先基于Docker在内网环境成功安装了Superset应用,并通过浏览器访问登陆,登陆界面如下:
-
连接数据源
按照示例新建数据库、连接数据源,
选择“Sources_Databases”点击“+”按钮添加数据源
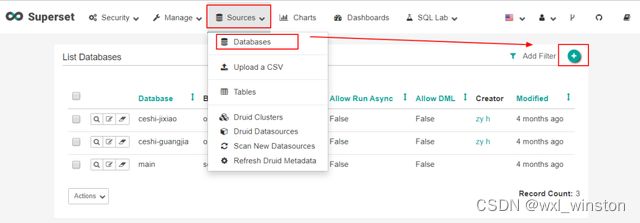
填写好Database的基础信息后,点击“Test Connection”,若弹出框显示“Seems OK!”则表示成功连接数据源。其中,Oracle数据源的“SQL Alchemy URL”编辑形式为:“oracle://用户名:密码@ip地址:端口/实例名”,其它数据源URI形式可参考:https://docs.sqlalchemy.org/en/13/core/engines.html#database-urls。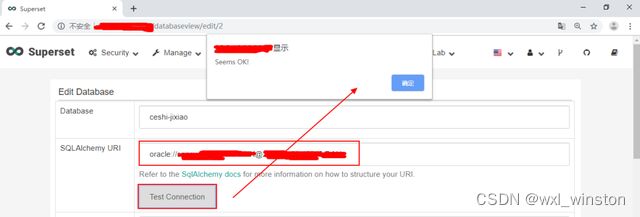
-
table添加及设置
成功连接数据源后按以下步骤添加可视化数据tables,
选择“Sources_Tables”点击“+”按钮添加可视化数据表
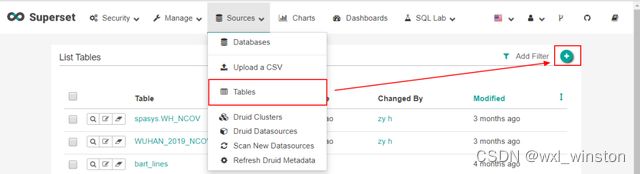
选择需要的数据库及数据表,点击“Save”按钮进行保存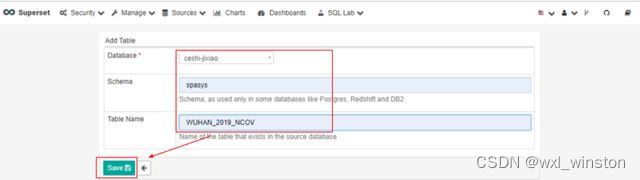
对添加的table进行基础设置,包括三部分:Details(设置表基础信息);List Columns(设置数据属性,groupable/filterable/istemporal);List mertics(预设数据过滤,sum/count等)
-
制作charts
制作疫情情况dashboard的基础是制作一个个的charts图表,
在tables列表中双击要制作chart的表名,进入绘图区域
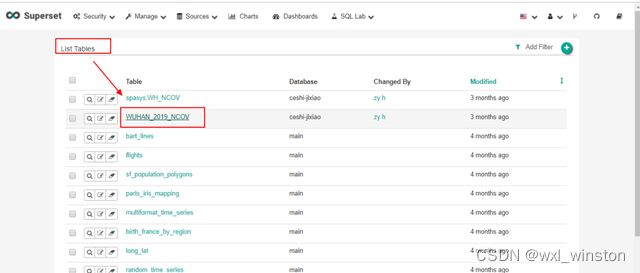
点击visualization type,在弹出框选择需要可视化的图表类型
对要进行可视化的图表进行参数设置,Time/Metric/filter等,设置好后点击“Save”进行保存,同时页面跳转至charts列表页
点击“View Query”可在弹出框查看可视化数据SQL
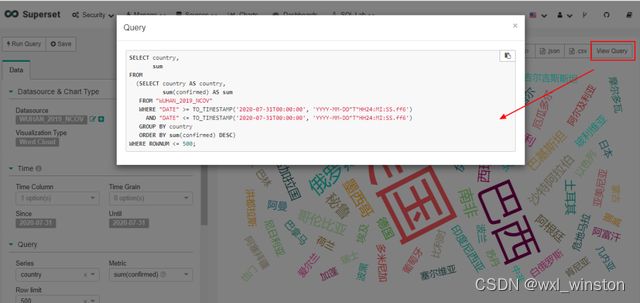
做好的chart将依次罗列于charts列表页,在该页双击图表名可跳转至绘图区域,并对已编辑的chart进行修改
-
制作dashboard
当制作dashboard的charts准备就绪后,就可以开始制作dashboard,
选择“dashboard”点击“+”按钮添加可视化面板,双击dashboard名进入编辑区域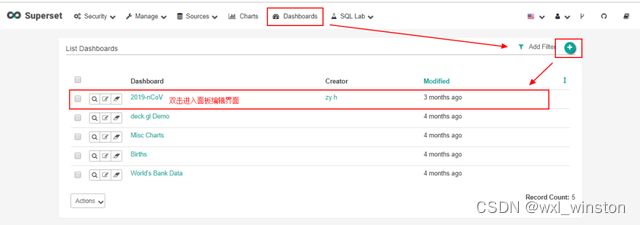
点击“Edit dashboard → Action”下拉列表选择“Add Slices”即可为面板添加charts素材,各charts组件的大小及位置可以拖动调整,也可对已添加的chart进行更名、强制更新、编辑、重绘图、移除等。Dashboard中的charts添加调整好后点击“Save”进行保存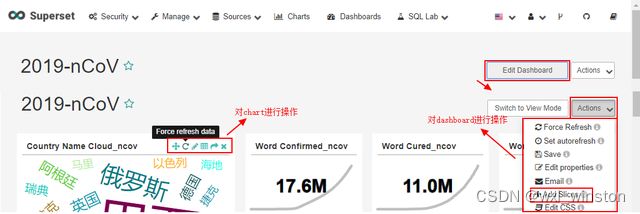
-
SQL查询面板
在Superset的SQL Lab中可以实现对已连接连数据源进行数据查询,同时也可对查询到的结果进行图表展示,
选择“Sources_Databases”进入数据库列表页,选中需要展示在SQL Lab中的数据库,点击编辑图标进入Edit Databases页,将“Expose in SQL Lab、Allow Run Sync”勾选上即可在SQL查询面板对数据库表进行查询,若想对库表进行创建、修改、删除等操作则需选择性的勾选“Allow CREATE TABLES或Allow DML”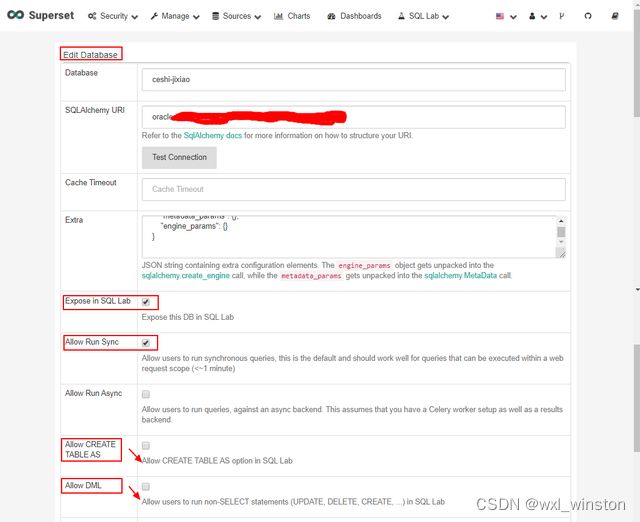
选择“SQL Lab_SQL Editor”就可以进入SQL查询页面,在编辑区写好查询sql后点击“Run Query”即显示查询结果
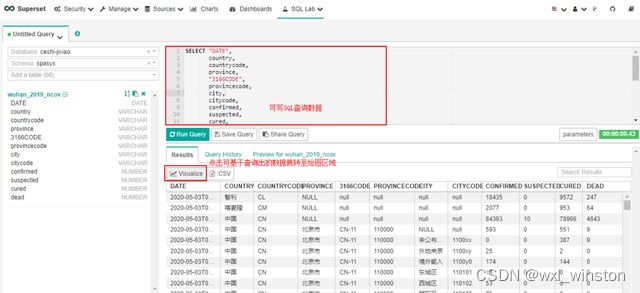
针对查询到的sql结果,点击“Visualize”按钮,在弹出框设置好相应信息后点击弹出框中的“Visualize”按钮即可跳转至绘图页面,随后可基于查询出的数据进行可视化图表制作
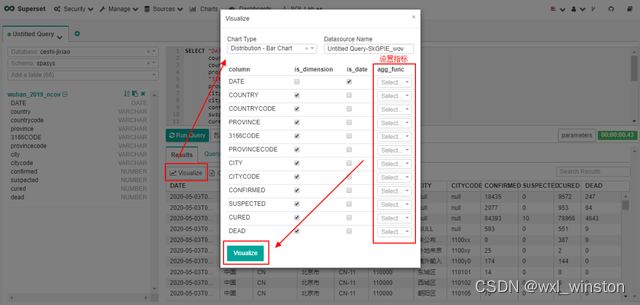
-
dashboard实例介绍
-
疫情dashboard
2019年12月底在中国武汉发现了首例新冠肺炎,2020年2月中旬全球其它国家相继发现了新冠病例并且其数量呈爆发式增长,疫情dashboard是基于全球新冠疫情数据制作的(19年12月20日-20年7月31日),数据来源于github的一个爬虫项目,它会定期去抓丁香医生的疫情数据信息,包括各国各区域的新冠肺炎的确诊人数、治愈人数和死亡人数。疫情数据文件准备就绪后,按照“四步走步骤”即可制作疫情dashboard。
疫情dashboard包括以下7类图表:
词云图Word Cloud,直观展示各国确诊人数的多少情况;
数值趋势图Big Number with Trendline,数值直接展示某个时间点的全球确诊、治愈及死亡总人数;同时附带趋势图,可查看各时间的疫情数值情况;
分布柱形图Distribution-Bar Chart,详细展示某个时间点的各国确诊、治愈及死亡人数,可作横向国家疫情对比;
时间线性趋势图Time Series-Line Chart,一图展示各时间点的各国确诊人数趋势情况,可做横向国家对比、纵向时间线对比;一图展示各时间点的中国确诊、治愈及死亡人数趋势情况;
国家地图Country Map,展示某个时间点的中国各省的确诊人数情况;
强度拉力图Directed Force Layout,展示某个时间点的中国各省各市的确诊人数情况,圆点代表省或市,圆点大小代表该省或市确诊人数的多少;
太阳图Sunburst,该图包括两个层级维度,直观展示某个时间点的中国各省各市的确诊人数占比及数值情况
下图为制作好的疫情dashboard:

-
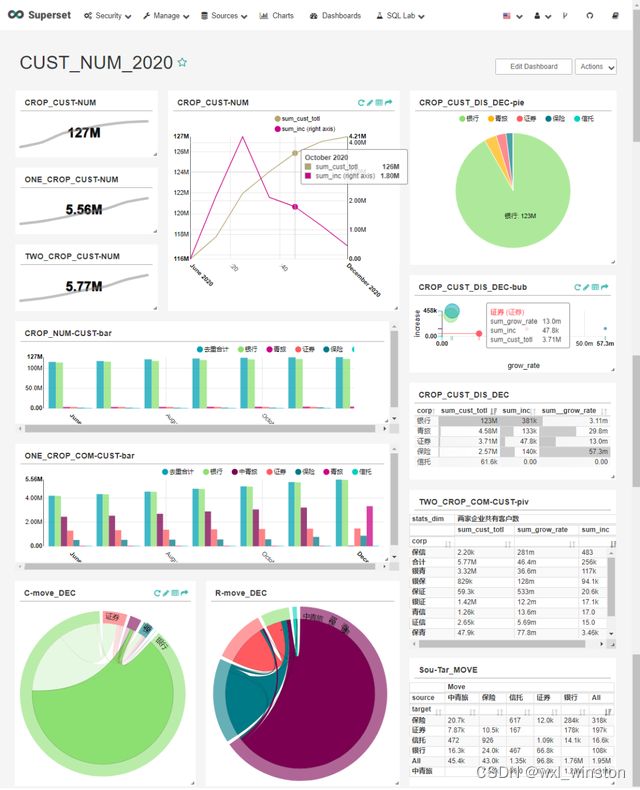
企业客户dashboard
企业客户dashboard,主要展示各子公司的客户情况,包括:企业客户数、单一企业共同客户数、两家企业共同客户数和客户迁徙数,其分析数据为某企业的5个子企业的半年客户数据(20年6月-20年12月)。同样,数据准备就绪后,按照“四步走步骤”制作企业客户dashboard。
企业客户dashboard包括以下8类图表:
数值趋势图Big Number with Trendline,数值直接展示某个时间点的企业客户总数、单一企业共同客户总数及两家企业共同客户总数;同时附带趋势图,可查看各时间点的客户总数情况;
双轴线图Dual Axis Line Chart,展示各时间点的企业客户总数及客户总数增量情况;
饼图Pie Chart,展示某个时间点的各企业客户数及占比情况;
气泡图Bubble Chart,展示某个时间点的各企业的客户数及其环比增量、环比增幅三者的关系,气泡大小表示各企业的客户数,X轴Y轴分别标识其环比增量和增幅;
视图表Table View,直接罗列某时间点的各企业客户数情况,另外单元格内的进度条将数值情况更加直观化;
时间线性趋势图Time Series-Line Chart,一图展示各时间点的各企业客户数趋势情况;一图展示各时间点的单一企业共同客户数趋势情况;
透视表Pivot Table,一图展示某时间点的两家企业共同客户数情况;一图展示某时间点的企业间客户迁徙(迁入和迁出)情况;
和弦图Chord Diagram,一图展示企业间的迁入客户情况;一图展示企业间的迁出客户情况下图为制作好的企业客户dashboard:
七、总结
Apache Superset是一个开源的数据可视化和数据探索平台,它提供了多种可视化工具和数据源接入方式,可以帮助用户更好地理解数据、探索数据和分析数据。Apache Superset提供了一个直观、易用的用户界面、多租户支持和完善的安全性机制,保障了数据的安全性和隐私性。但是Apache Superset的可视化工具相对比较简单,不适用于一些复杂的数据可视化需求,而且对于大数据量的数据处理能力有限,不适用于一些大数据处理需求。但是Superset只是一款轻量级的BI应用,复杂的数据关联可以在ETL过程中完成,而Superset读取最终的结果表,另外它完全可以支撑起TB级的数据源读取。总而言之,Apache Superset是一款免费且操作简便的自助式数据分析工具,能够满足企业的多样化可视化需求,而且最新版本支持嵌入Echarts页面,功能更加强大,使用更加方便。