【学习计划打卡-03Day】Database数据库基础/SQL初级题目解析-Leetcode题库/基础函数使用和归纳整理/实习常用任务代码
本章目录
- 1.DB基础概念
- 2.SQL初级
-
- 2.1连接两个表
- 2.2 表内员工工资超过经理
- 2.3 重复记录(电子邮箱+次数
- 2.4 两表找null-从不订购的人
- 2.5 删除重复(电子邮箱
- 2.6 日期数据的比较-cross join
-
- 2.6.1 时间计算函数-datediff
- 2.6.2 lag()窗口函数- 向前
- 2.7 每一个玩家首次登陆的设备名称- row_number()
- 2.8 连表的坑Null
- 2.9 排序取最大-订单最多的人-order by DESC
- 2.10 Union默认去重
- 2.11 超过5名学生的课-group by
- 2.12 两表计数相除-分母为0(ifnull)
- 2.13 连续-连表查看
- 2.14 where not in 反向筛选
- 2.15 判断三角形-case when
- 3.实习常用相关代码
-
- 3.1、多列字段指标合并为一列,生成指标名称和对应指标值
- 3.2 行列转置,行转列
- 3.3 求同比值
- 3.4 求条数count
- 参考资料
1.DB基础概念
Data: context, graphical data, data characteristics(包括type/ size/ values…),
数据可以被划分为结构数据和非结构数据(80%)
Problems: data dependence, sharing, time ,maintenance。当出现数据重复,数据独立/依赖问题,标准化格式form,储存管理repository and management问题。
在概念中要考虑的为两大因素: 实体和关系。Entities and relationships
Two Approaches to IS Development:
- SDLC
- Prototyping

发展阶段中:

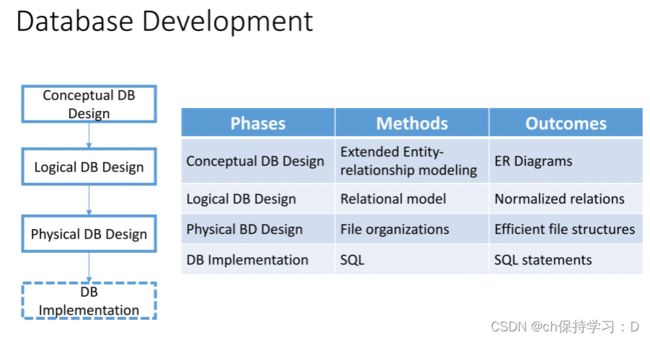
DB的优缺点:所解决的问题➕成本风险
(省略…)DB的组成元素/ 类别/ 框架
2.SQL初级
2.1连接两个表
select FirstName, LastName, City, State
from Person left join Address
on Person.PersonId = Address.PersonId
;
- A inner join B 交集
- A left join B 是left就取左边的全部值,即A,然后当B没有对应值时则为null
- A right join B同理,是right就取右边的全部值,即B的全部,A没有对应值则为null
- A full outer join B 并集,彼此都没有对应的则为null
关于表连接:
- 通过2+表连接返回记录时产生临时表,返回该临时表给用户,on时生产临时表的条件,不论on条件是否为真,都返回左边表
- where是对临时表的过滤,此时没有left join的要求,条件不符合的全部过滤
2.2 表内员工工资超过经理

SELECT
*
FROM
Employee AS a,
Employee AS b
WHERE
a.ManagerId = b.Id
AND a.Salary > b.Salary
;
select重复使用两个表然后用ID连接,产生4*4行记录。最终输出结果是如图

只需要雇员名字的筛选
SELECT
a.Name AS 'Employee'
FROM
Employee AS a,
Employee AS b
WHERE
a.ManagerId = b.Id
AND a.Salary > b.Salary
;
2.3 重复记录(电子邮箱+次数

重点记住优先顺序:where>group by>having>order by
select
Email
,count(Email) as num
from Person
group by Email
;
作为临时表,在从这个表里获取num>1的变量

在筛选的时候注意将临时表进行重命名为temp。然后只要求第一列里的value
select
Email
from
(
select
Email
,count(Email) as num
from Person
group by Email
) as temp
where num >1;
2.4 两表找null-从不订购的人
返回顾客名字

select
a.Name as Customers
from
Customers as a
left join Order as b
on a.Id=b.CustomerId
where b.CustomerId is null;
- 常见组合方式 left join / on / where
- 使用left join只是做了个笛卡尔积运算,不占内存。
2.5 删除重复(电子邮箱
DELETE
p1
FROM Person p1,Person p2
WHERE
p1.Email = p2.Email
AND p1.Id > p2.Id
删除p1中和p2匹配不上的记录(where
delete的写法有点类似u呀select,
此处的from直接就连接4*4的所有记录行,
依次取出记录然后对照右表进行查找满足条件的⬇️
delete 的具体实现过程见解析

2.6 日期数据的比较-cross join
某一天的数据比前一天的数据高:2015-01-02 的温度比前一天高(10 -> 25)
cross join
使用交叉联结会将两个表中所有的数据两两组合
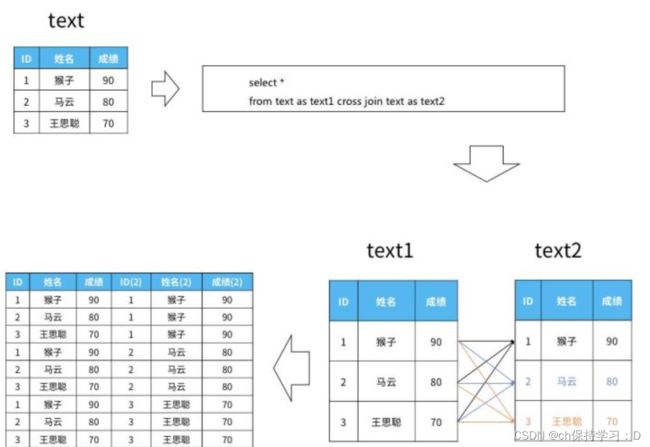
- 此处和直接select from相比的序列号不同,首ID是按顺序123123而次ID是重复的111222333
- 而select from的序列号则是首ID是111222对应的次ID是123123的形式
- 【因此左边是“当天”数据,右边是“前一天”的数据】

//最外面的select的东西为最后我们想要的变量
select
a.ID
,a.date
from
weather as a
cross join weather as b
on datediff(a.date, b.date) = 1
where a.temp > b.temp
2.6.1 时间计算函数-datediff
datediff(日期1, 日期2):
得到的结果是日期1与日期2相差的天数。
如果日期1比日期2大,结果为正;如果日期1比日期2小,结果为负。
timestampdiff(时间类型, 日期1, 日期2)
这个函数和上面diffdate的正、负号规则刚好相反。
日期1大于日期2,结果为负,日期1小于日期2,结果为正。
2.6.2 lag()窗口函数- 向前
lag(): last_date 是date列中的数值整体向下挪动一个空值,首行的数据为0
select
a.id
from
(
select
id
,temperature
,recordDate
,lag(recordDate,1) over(order by recordDate) as last_date
,lag(temperature,1) over(order by recordDate) as last_temperature
from
weather
)as a
where temperature > last_temperature AND
datediff(recordDate, last_date) = 1
2.7 每一个玩家首次登陆的设备名称- row_number()
1.find首次登入的时间
2.根绝首次登入的时间进行设备ID的查找

select
b.player_id as player_id
,b.decive_id as device)id
from
(
select
*
from
(
select
row_number() over(partition by player_id order by event_date) as rn
,player_id
,device_id
from
Activity
)as a
) as b
row_number()
主要用来计数的,也便于用此函数针对全部字段进行排序去重
2.8 连表的坑Null
坑!! 此处在连表的时候会常常忘记会出现有空值null的情况而缺少条件
以下为错误ERROR的代码书写!!!!!
select
c.name as name
,c.bonus as bouns
from
(select
*
from
Employee as a
left join Bonus as b
on a.empld = b.empld) as c
where c.bonus < 1000
注意存在null的值–**b.bonus is null。
**不等于 表示为 !=
select
e.name as name
,b.bouns as bouns
from
Employee as e
left join Bouns as b
on e.empID = b.empID
where b.bonus is null OR
b.bouns < 1000;
2.9 排序取最大-订单最多的人-order by DESC

使用 row_number的rn来作为排序,但是此处使用存在风险,谨慎使用
select
a.customer_number
from
(select
*
,row_number() over(partition by customer_number order by order_number) as rn
from
Orders) as a
order by a.rn desc
limit 1
直接order by desc从大到小的降序使用+group by
select
customer_number
from
orders
group by customer_number
order by count(order_number) desc
limit 1;
2.10 Union默认去重
多个筛选条件可以直接where 条件A or 条件B
直接union速度快且默认去重
SELECT
name, population, area
FROM
world
WHERE
area > 3000000
UNION
SELECT
name, population, area
FROM
world
WHERE
population > 25000000;
2.11 超过5名学生的课-group by
select
a.class as class
from
(
select
*
,count(class) as num
from
courses
group by class
)as a
where a.num >=5
2.12 两表计数相除-分母为0(ifnull)
1.考虑 重复项【distinct
2. 考虑被除的为0【分母为0的情况- if null
3. 总的count相除【两张表,请求表➕接受表
select
round(
ifnull
(
(select count(*) from (select distinct requester_id, accepter_id from requestaccepted) as A)
/
(select count(*) from (select distinct sender_id, send_to_id from friendrequest) as B)
,0)
, 2) as accept_rate;
ifnull(A,B):
如果A的值为null,则返回B,否则直接返回A
2.13 连续-连表查看
连续空余座位
1.free 字段是布尔类型(‘1’ 表示空余, ‘0’ 表示已被占据
2.连续空余座位: 大于等于 2 个连续空余的座位

1.笛卡尔乘积
2.筛选连续+空余
3.重复记录的筛除- distinct
//连续+空余座位,满足连续的条件
select
*
from
cinema as a
join cinema as b
on abs(a.seat_id - b.seat_id) = 1
AND a.free = true
AND b.free = true

//重复记录的筛除-distinct a.seat_id
select
distinct a.seat_id
from
cinema as a
join cinema as b
on abs(a.seat_id - b.seat_id) = 1
AND a.free = true
AND b.free = true
order by a.seat_id
2.14 where not in 反向筛选
Q : 没有向公司 ‘RED’ 销售任何东西的销售员
在面对 有/没有 的双面问题的时候,要想到反向思考意识
select
s.name
from
T3 as s
where s.id
not in
(select
id from T1 left join T2
on T1.id=T2.id
where T2.name='RED'
);
2.15 判断三角形-case when
case when相当于if else语法,此处返回的值单独产生新变量
select
x
,y
,z
,case when (x+y>z and x+z>y and z+y>x) then 'yes' else 'No' end as triangle
from T1;
3.实习常用相关代码
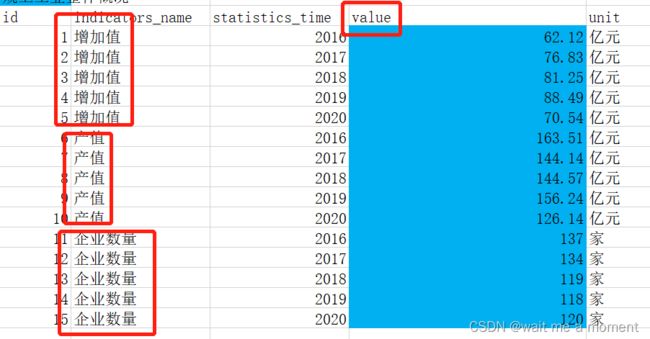
3.1、多列字段指标合并为一列,生成指标名称和对应指标值
如图,图一为源表,图二为目标表,将图一转换为图二。

UNION 操作符
用于合并两个或多个 SELECT 语句的结果集。
请注意,UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同。
union all 允许重复值
①UNION 语句:用于将不同表中相同列中查询的数据展示出来;(不包括重复数据)
②UNION ALL 语句:用于将不同表中相同列中查询的数据展示出来;(包括重复数据)
hive中解决代码:
使用union all进行多列指标合并一列
select
'增加值' as indicators_name
,year
,add_value as value
,id
,from_unixtime(unix_timestamp()) as etl_create_time
,etl_batch_no
from 表1
union all
select
'产值' as indicators_name
,year
,product_value
,id
,from_unixtime(unix_timestamp()) as etl_create_time
,etl_batch_no
from 表2
3.2 行列转置,行转列
如图,图一为源表,图二为目标表,将图一转换为图二。


解决代码如下
select
year
,agricultural_value
,forestry_value
,husbandry_value
,fishery_value
,id
,from_unixtime(unix_timestamp()) as etl_create_time
,etl_batch_no
from
(
select
year
,sum(case when name='农业' then add_value end ) over(partition by year) as agricultural_value
,sum(case when name='林业' then add_value end ) over(partition by year ) as forestry_value
,sum(case when name='牧业' then add_value end ) over(partition by year) as husbandry_value
,sum(case when name='渔业' then add_value end ) over(partition by year ) as fishery_value
,row_number() over(partition by year order by id desc)as rn
,id
,etl_create_time
,etl_batch_no
from
rj_ods.ODS_zxtb_83_jjfz_v3_industry1_pv where etl_batch_no = date_sub(CURRENT_DATE,1)
)where rn=1
3.3 求同比值
使用lag函数
lag(add_value) over( order by year asc) as qn_add_value
最后一列为Lag使用效果得到E列,故同比值用(D-E)/E
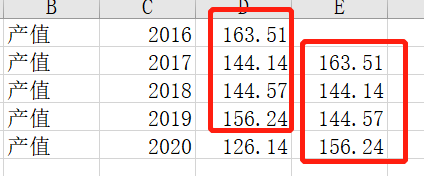
#DW【输出5年的4产业的之和+每年的同比值/5行数据】
insert overwrite table rj_dw.DW_zxtb_83_tjj_dycyzjzfx_20220106 partition(etl_batch_no)
select
year
,round(add_value,2) as add_value
,round(((add_value-qn_add_value)/qn_add_value*100),2) as period_compare
,id
,etl_create_time
,etl_batch_no
from
(select
lag(add_value) over( order by year asc) as qn_add_value
,*
from
(select
sum(add_value) over(partition by year order by id asc) as add_value
,row_number() over(partition by year order by id desc)as rn
,year
,primary_industry_type
,id
,template_id
,batch_id
,etl_create_time
,etl_batch_no
from rj_ods.ODS_zxtb_83_tjj_dycyzjzfx_20220106 where etl_batch_no = date_sub(CURRENT_DATE,1)
)where rn=1)
3.4 求条数count
如图,图一为源表,图二为目标表,将图一转换为图二。


select
type
,count(1) as value
from
rj_ods.ODS_wlzt_v3_scenic_detail
where etl_batch_no = date_sub(CURRENT_DATE,1)
group by type
参考资料
01-20题数分面试SQL,题目多来自与下面的题库
02-leetcode题库