模型无关的时间序列度量方法及特征
文章目录
- 模型无关的时间序列度量方法及特征
-
- 模型无关的方法(Model-free approaches)
-
- 常用方法介绍
-
- 闵可夫斯基距离(Minkowski distance)
- 弗雷歇距离(Fréchet distance)
- 动态时间规整DTW(Dynamic time warping distance)
- 一个自适应的涵盖了价值和行为上的接近度的不同的指标(An adaptive dissimilarity index covering both proximity on values and on behavior)
-
- 皮尔森相关系数(Pearson correlation coefficient)
- 基于相关性的距离(Correlation-based distances)
- 基于自相关性的距离(Autocorrelation-based distances)
- 基于周期图的距离(Periodogram-based distances)
- 基于离散小波变换的不同度量(A dissimilarity measure based on the discrete wavelet transform)
- 基于SAX的符号表示的不同测度(Dissimilarity based on the symbolic representation SAX)
基于《TSclust: An R Package for Time Series Clustering》论文总结的一些时间序列度量方法
TSclust是一个处理时间序列的R语言的包,是一个在时间序列聚类方面使用较早的工具包,里面包括时间序列聚类的基本步骤和思路,以及时间序列聚类的不同度量方法和选择不同度量方法的指标。
模型无关的时间序列度量方法及特征
时间序列度量就是对时间序列相似性的探究,对相似性的定义可以分为两个方面,一方面为距离近,另一方面为形状相似。
举个例子:
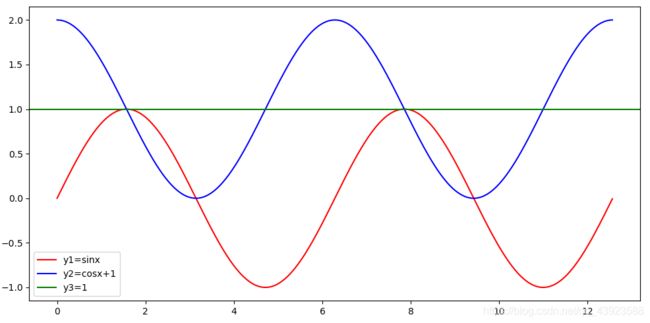
肉眼可见:
如果按照距离作为度量标准,则y2和y3更为相似
如果按照形状作为度量标准,则y2和y1更为相似
现实中的时间序列不会是这么简单的,那么,如何去计算两个序列之间的距离,如何去看两个序列的形状就是两个值得探讨的问题。
模型无关的方法(Model-free approaches)
常用方法介绍
闵可夫斯基距离(Minkowski distance)
闵可夫斯基距离比较简单,但是很常用
闵可夫斯基距离不是一种距离,而是一组距离的定义,是对多个距离度量公式的概括性的表述。
闵可夫斯基距离可定义为:
d L q ( X T , Y T ) = ( ∑ t = 1 T ( X t − Y t ) q ) 1 / q d_{Lq}(X_T,Y_T)=(\sum_{t=1}^T(X_t-Y_t)^q)^{1/q} dLq(XT,YT)=(t=1∑T(Xt−Yt)q)1/q
当p=2时,闵可夫斯基距离即欧氏距离(Euclidean distance) :
d L q ( X T , Y T ) = ( ∑ t = 1 T ( X t − Y t ) 2 ) 1 / 2 d_{Lq}(X_T,Y_T)=(\sum_{t=1}^T(X_t-Y_t)^2)^{1/2} dLq(XT,YT)=(t=1∑T(Xt−Yt)2)1/2
当p=1时,闵可夫斯基距离即曼哈顿距离(Manhattan distance):
d L q ( X T , Y T ) = ∑ t = 1 T ∣ X t − Y t ∣ d_{Lq}(X_T,Y_T)=\sum_{t=1}^T|X_t-Y_t| dLq(XT,YT)=t=1∑T∣Xt−Yt∣
特点:闵可夫斯基距离对信号变换非常敏感,如移动或时间缩放(时间轴的拉伸或收缩)。另一方面,接近的概念依赖于在相应的时间点上观察到的值的接近度,使观察值被视为是独立的。特别是,距离的计算不随时间变化而变化。
弗雷歇距离(Fréchet distance)
这个距离由Fréchet(1906)引入,用来测量连续曲线之间的接近程度,但它已被广泛应用于离散情况和时间序列框架。
直观的理解,Fréchet distance就是狗绳距离:主人走路径A,狗走路径B,各自走完这两条路径过程中所需要的最短狗绳长度。即图中绿框所示位置。
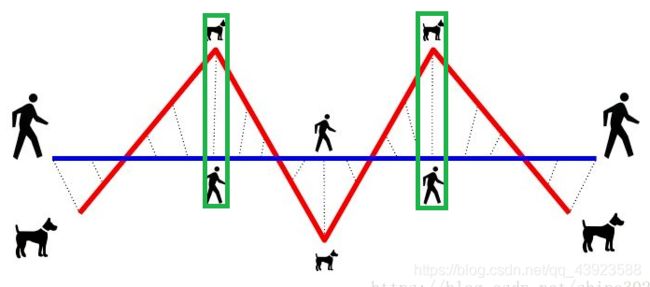
弗雷歇距离的定义:
设M是m对的所有可能序列的集合,保持观测顺序的形式:
r = ( ( X a 1 , Y b 1 ) , … , ( X a m , Y b m ) ) r=((X_{a1},Y_{b1}),…,(X_{am},Y_{bm})) r=((Xa1,Yb1),…,(Xam,Ybm))
有
a i , b j ∈ { 1 , … , T } a_i,b_j\in\{1,…,T\} ai,bj∈{1,…,T}
对于
a 1 = b 1 = 1 , a m = b m = T , a i + 1 = a i 或 a i + 1 , b i + 1 = b i 或 b i + 1 a_1=b_1=1,a_m=b_m=T,a_{i+1}=a_i或a_i+1,b_{i+1}=b_i或 b_i+1 a1=b1=1,am=bm=T,ai+1=ai或ai+1,bi+1=bi或bi+1
当
i ∈ { 1 , . . . , m − 1 } i\in \{1,...,m-1\} i∈{1,...,m−1}
时,弗雷歇距离定义为
d F ( X T , Y T ) = min r ∈ m ( max i = 1 , . . . , m ∣ X a i − Y b i ∣ ) d_F(X_T,Y_T)=\min_{r\in m}\left(\max_{i=1,...,m}|X_{ai}-Y_{bi}|\right) dF(XT,YT)=r∈mmin(i=1,...,mmax∣Xai−Ybi∣)
算法描述:
Function dF(P,Q):real;
input: P=(u1,...,up),Q=(v1,...,vq)
return:δdF(P,Q)
ca: array [1..p,1..q] of real;
function c(i,j):real;
begin
if ca(i,j)>−1 then return ca(i,j)
elseif i=1 and j=1 then ca(i,j):=d(u1,v1)
elseif i>1 and j=1 then ca(i,j):=max{c(i−1,1),d(ui,v1)}
elseif i=1 and j>1 then ca(i,j):=max{c(1,j−1),d(u1,vi)}
elseif i>1 and j>1 then ca(i,j):=
max{min(c(i−1,j),c(i−1,j−1),c(i,j−1)),d(ui,vi)}
else ca(i,j)=∞
return ca(i,j);
end;
begin
for i=1 to p do for j=1 to q do ca(i,j):=−1.0;
return c(p,q);
end.
特点:与闵可夫斯基距离不同,Fréchet 距离不仅将级数视为两个点集,而且考虑到了观测值的顺序。同时,Fréchet距离可以在不同长度的序列上计算。
动态时间规整DTW(Dynamic time warping distance)
在时间序列中,需要比较相似性的两段时间序列的长度可能并不相等,在语音识别领域表现为不同人的语速不同。而且同一个单词内的不同音素的发音速度也不同,比如有的人会把“A”这个音拖得很长,或者把“i”发的很短。另外,不同时间序列可能仅仅存在时间轴上的位移,亦即在还原位移的情况下,两个时间序列是一致的。在这些复杂情况下,使用传统的欧几里得距离无法有效地求的两个时间序列之间的距离(或者相似性)。
DTW通过把时间序列进行延伸和缩短,来计算两个时间序列性之间的相似性:
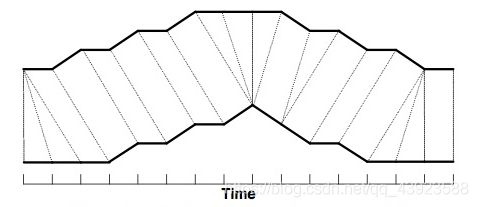
如上图所示,上下两条实线代表两个时间序列,时间序列之间的虚线代表两个时间序列之间的相似的点。DTW使用所有这些相似点之间的距离的和,称之为归整路径距离(Warp Path Distance)来衡量两个时间序列之间的相似性。
DWT的定义:
作为Fréchet距离,DTW距离旨在找到序列之间的映射r,使耦合观测(Xai, Ybi)之间的特定距离测量值最小化。
d D T W ( X T , Y T ) = min r ∈ M ( ∑ i = 1 , . . . , m ∣ X a i − Y b i ∣ ) d_{DTW}(X_T,Y_T)=\min_{r\in M}\left(\sum_{i=1,...,m}|X_{ai}-Y_{bi}| \right) dDTW(XT,YT)=r∈Mmin(i=1,...,m∑∣Xai−Ybi∣)
DTW算法中的趋势度量:
即两个序列的相似度度量规则;
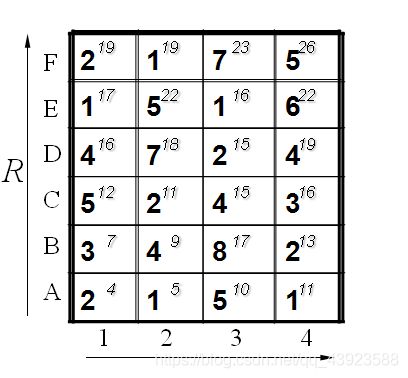
假设标准模板R为字母ABCDEF(6个),测试模板T为1234(4个)。R和T中各元素之间的距离已经给出。如下:
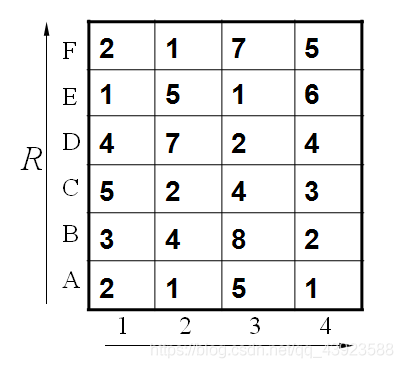
既然是模板匹配,所以各分量的先后匹配顺序已经确定了,虽然不是一一对应的。现在题目的目的是要计算出测试模板T和标准模板R之间的距离。因为2个模板的 长度不同,所以其对应匹配的关系有很多种,我们需要找出其中距离最短的那条匹配路径。现假设题目满足如下的约束:当从一个方格((i-1,j-1)或者 (i-1,j)或者(i,j-1))中到下一个方格(i,j),如果是横着或者竖着的话其距离为d(i,j),如果是斜着对角线过来的则是 2d(i,j).其约束条件如下图像所示:
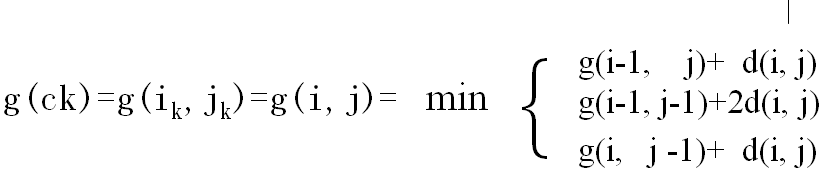
其中g(i,j)表示2个模板都从起始分量逐次匹配,已经到了M中的i分量和T中的j分量,并且匹配到此步是2个模板之间的距离。并且都是在前一次匹配的结果上加d(i,j)或者2d(i,j),然后取最小值。
比如说g(1,1)=4, 当然前提都假设是g(0,0)=0,就是说g(1,1)=g(0,0)+2d(1,1)=0+2*2=4.
g(2,2)=9是一样的道理。首先如果从g(1,2)来算的话是g(2,2)=g(1,2)+d(2,2)=5+4=9,因为是竖着上去的。
如果从g(2,1)来算的话是g(2,2)=g(2,1)+d(2,2)=7+4=11,因为是横着往右走的。
如果从g(1,1)来算的话,g(2,2)=g(1,1)+2d(2,2)=4+24=12.因为是斜着过去的。
综上所述,取最小值为9. 所有g(2,2)=9.
当然在这之前要计算出g(1,1),g(2,1),g(1,2).因此计算g(I,j)也是有一定顺序的。
所以我们将所有的匹配步骤标注后如下:
路径如图所示:
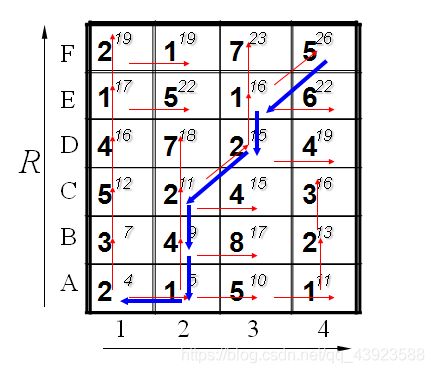
一些理解:DTW常用于已知两个序列相似,去衡量这两个序列到底有多相似,根据两条序列的变换趋势去匹配趋势相同的点。
特点:已知两条序列相似为前提,衡量相似度。可以用于解决长度不同的时间序列之间的相似性问题。
一个自适应的涵盖了价值和行为上的接近度的不同的指标(An adaptive dissimilarity index covering both proximity on values and on behavior)
皮尔森相关系数(Pearson correlation coefficient)
皮尔森相关系数也称皮尔森积矩相关系数(Pearson product-moment correlation coefficient) ,是一种线性相关系数,是最常用的一种相关系数。记为r,用来反映两个变量X和Y的线性相关程度,r值介于-1到1之间,绝对值越大表明相关性越强
定义:
总体相关系数ρ定义为两个变量X、Y之间的协方差和两者标准差乘积的比值,如下:
ρ X , Y = c o v ( X , Y ) σ x σ Y = E ∣ ( X − μ X ) ( Y − μ X ) ∣ σ X σ Y \rho_{X,Y}=\frac{cov(X,Y)}{\sigma_x\sigma_Y}=\frac{E\left|(X-\mu_X)(Y-\mu_X)\right|}{\sigma_X\sigma_Y} ρX,Y=σxσYcov(X,Y)=σXσYE∣(X−μX)(Y−μX)∣
估算样本的协方差和标准差,可得到样本相关系数(即样本皮尔森相关系数),常用r表示:
r = ∑ i = 1 n ( X i − X ‾ ) ( Y i − Y ‾ ) ∑ i = 1 n ( X i − X ‾ ) 2 ∑ i = 1 n ( ( Y i − Y ‾ ) 2 r=\frac{\sum_{i=1}^{n}(X_i-\overline X)(Y_i-\overline Y)}{\sqrt{\sum_{i=1}^{n}(X_i-\overline X)^2}{\sqrt{\sum_{i=1}^{n}((Y_i-\overline Y)^2}}} r=∑i=1n(Xi−X)2∑i=1n((Yi−Y)2∑i=1n(Xi−X)(Yi−Y)
皮尔森相关系数反映了两个变量的线性相关性的强弱程度,r的绝对值越大说明相关性越强。
- 当r>0时,表明两个变量正相关,即一个变量值越大则另一个变量值也会越大;
- 当r<0时,表明两个变量负相关,即一个变量值越大则另一个变量值反而会越小;
- 当r=0时,表明两个变量不是线性相关的(注意只是非线性相关),但是可能存在其他方式的相关性(比如曲线方式);
- 当r=1和-1时,意味着两个变量X和Y可以很好的由直线方程来描述,所有样本点都很好的落在一条直线上。
Pearson 系数的性质如下:
- 如果两条时间序列 X T = Y T X_{T} = Y_{T} XT=YT,则 COR ( X T , Y T ) = 1 \text{COR}(X_{T},Y_{T}) =1 COR(XT,YT)=1 表是它们是完全一致的,如果两条时间序列 X T = − Y T X_{T} = -Y_{T} XT=−YT,则 COR ( X T , Y T ) = − 1 \text{COR}(X_{T},Y_{T}) = -1 COR(XT,YT)=−1表示它们之间是负相关的。
- − 1 ≤ COR ( X T , Y T ) ≤ 1 -1\leq \text{COR}(X_{T},Y_{T})\leq 1 −1≤COR(XT,YT)≤1
皮尔森距离通过皮尔森系数定义:
d X , Y = 1 − ρ X , Y d_{X,Y}=1-\rho_{X,Y} dX,Y=1−ρX,Y
基于相关性的距离(Correlation-based distances)
基于皮尔森相关系数的时间序列度量,详细解释(https://www.oalib.com/paper/4017681)
该方法涵盖了观测上的邻近性的常规测量方法和行为邻近性估计的时间相关性。利用一阶时间相关系数来评估序列动态特性之间的邻近性,该系数由:
C O R ( X T , Y T ) = ∑ t = 1 T ( X t − X ‾ T ) ( Y t − Y ‾ T ) ∑ t = 1 T ( X t − X ‾ T ) 2 ∑ t = 1 T ( ( Y t − Y ‾ T ) 2 COR(X_T,Y_T)=\frac{\sum_{t=1}^{T}(X_t-\overline X_T)(Y_t-\overline Y_T)}{\sqrt{\sum_{t=1}^{T}(X_t-\overline X_T)^2}{\sqrt{\sum_{t=1}^{T}((Y_t-\overline Y_T)^2}}} COR(XT,YT)=∑t=1T(Xt−XT)2∑t=1T((Yt−YT)2∑t=1T(Xt−XT)(Yt−YT)
Golay, Kollias, Stoll, Meier, Valavanis和Boesiger使用以下两种基于互相关联的距离构造了一个模糊k-means算法:
d C O R . 1 ( X T , Y T ) = 2 ( 1 − C O R ( X T , Y T ) ) d_{COR.1}(X_T,Y_T)=\sqrt{2(1-COR(X_T,Y_T))} dCOR.1(XT,YT)=2(1−COR(XT,YT))
d C O R . 2 ( X T , Y T ) = ( 1 − C O R ( X T , Y T ) 1 + C O R ( X T , Y T ) ) β , β ≥ 0 d_{COR.2}(X_T,Y_T)=\sqrt{\left(\frac{1-COR(X_T,Y_T)}{1+COR(X_T,Y_T)}\right)^\beta}, \beta\ge0 dCOR.2(XT,YT)=(1+COR(XT,YT)1−COR(XT,YT))β,β≥0
当COR (XT,YT) =−1时,2式变为无穷大,且参数β允许调节距离的快速减小。对于β的某些值,如图所示。

基于自相关性的距离(Autocorrelation-based distances)
详细理解(https://xueshu.baidu.com/usercenter/paper/show?paperid=32bf19da6607b0d2c765957fc071aa1b&site=xueshu_se)
假设时间序列是
X T = { x 1 , ⋯ , x T } X_{T} = \{x_{1},\cdots,x_{T}\} XT={x1,⋯,xT}
,对于任意的 k
其中 μ , σ 2 \mu, \sigma^{2} μ,σ2分别表示该时间序列的均值和方差。该公式相当于是比较整个时间序列
X T = { x 1 , ⋯ , x T } X_{T}=\{x_{1},\cdots,x_{T}\} XT={x1,⋯,xT}
的两个子序列的相似度(Pearson 系数),这两个子序列分别是
{ x 1 , ⋯ , x T − k } , { x k + 1 , ⋯ , x T } \{x_{1},\cdots,x_{T-k}\}, \{x_{k+1},\cdots,x_{T}\} {x1,⋯,xT−k},{xk+1,⋯,xT}
于是,通过给定一个正整数 L
对于 i>L的情况,可以假定
ρ ^ i , X T = 0 , ρ ^ i , Y T = 0 \hat{\rho}_{i,X_{T}} = 0,\hat{\rho}_{i,Y_{T}} = 0 ρ^i,XT=0,ρ^i,YT=0
于是,可以定义时间序列之间的距离如下:
d A C F ( X T , Y T ) = ( ρ ^ X T − ρ ^ Y T ) T Ω ( ρ ^ X T − ρ ^ Y T ) d_{ACF}(X_{T},Y_{T}) = \sqrt{(\hat{\rho}_{X_{T}}-\hat{\rho}_{Y_{T}})^{T}\Omega(\hat{\rho}_{X_{T}}-\hat{\rho}_{Y_{T}})} dACF(XT,YT)=(ρ^XT−ρ^YT)TΩ(ρ^XT−ρ^YT)
其中的 Ω \Omega Ω 表示一个 L × L L\times L L×L的矩阵。它有着很多种选择,例如:
(1) Ω = I L \Omega = I_{L} Ω=IL 表示单位矩阵。用公式表示就是 d A C F U ( X T , Y T ) = ∑ i = 1 L ( ρ ^ i , X T − ρ ^ i , Y T ) 2 d_{ACFU}(X_{T},Y_{T}) =\sqrt{\sum_{i=1}^{L}(\hat{\rho}_{i,X_{T}}-\hat{\rho}_{i,Y_{T}})^{2}} dACFU(XT,YT)=∑i=1L(ρ^i,XT−ρ^i,YT)2
(2) Ω = d i a g { p ( 1 − p ) , p ( 1 − p ) 2 , ⋯ , p ( 1 − p ) L } \Omega = diag\{p(1-p),p(1-p)^{2},\cdots,p(1-p)^{L}\} Ω=diag{p(1−p),p(1−p)2,⋯,p(1−p)L} 表示一个 L × L L\times L L×L的对角矩阵,其中 0 < p < 1 0
d A C F U ( X T , Y T ) = ∑ i = 1 L p ( 1 − p ) i ( ρ ^ i , X T − ρ ^ i , Y T ) 2 d_{ACFU}(X_{T},Y_{T}) =\sqrt{\sum_{i=1}^{L}p(1-p)^{i}(\hat{\rho}_{i,X_{T}}-\hat{\rho}_{i,Y_{T}})^{2}} dACFU(XT,YT)=i=1∑Lp(1−p)i(ρ^i,XT−ρ^i,YT)2
除了自相关系数(Autocorrelation Coefficients)之外,也可以考虑偏自相关系数(Partial Autocorrelation Coefficients),使用 PACFs 来取代 ACFs。这样,使用同样的定义方式就可以得到 d P A C F U d_{PACFU} dPACFU 和 d P A C F G d_{PACFG} dPACFG两个距离公式。
基于周期图的距离(Periodogram-based distances)
详细理解(https://xueshu.baidu.com/usercenter/paper/show?paperid=9035c17e46af1b590f2511417b7819e9&site=xueshu_se)
这里会介绍基于周期图表(Periodogram-based)的距离计算方法。其大体思想就是通过 Fourier 变换得到一组参数,然后通过这组参数来反映原始的两个时间序列时间的距离。用数学公式来描述就是:
I X T ( λ k ) = T − 1 ∣ ∑ t = 1 T x t e − i λ k t ∣ 2 I_{X_{T}}(\lambda_{k}) = T^{-1}|\sum_{t=1}^{T}x_{t}e^{-i\lambda_{k}t}|^{2} IXT(λk)=T−1∣t=1∑Txte−iλkt∣2
I Y T ( λ k ) = T − 1 ∣ ∑ t = 1 T y t e − i λ k t ∣ 2 I_{Y_{T}}(\lambda_{k}) = T^{-1}|\sum_{t=1}^{T}y_{t}e^{-i\lambda_{k}t}|^{2} IYT(λk)=T−1∣t=1∑Tyte−iλkt∣2
其中 λ k = 2 π k / T \lambda_{k} = 2\pi k/T λk=2πk/T, k = 1 , ⋯ , n k = 1,\cdots,n k=1,⋯,n, n = [ ( T − 1 ) / 2 ] n=[(T-1)/2] n=[(T−1)/2]。这里的 [ ⋅ ] [\cdot] [⋅]表示 Gauss 取整函数。
(1)用原始的特征来表示距离:
d P ( X T , Y T ) = 1 n ∑ k = 1 n ( I X T ( λ k ) − I Y T ( λ k ) ) 2 d_{P}(X_{T},Y_{T}) = \frac{1}{n}\sqrt{\sum_{k=1}^{n}(I_{X_{T}}(\lambda_{k})-I_{Y_{T}}(\lambda_{k}))^{2}} dP(XT,YT)=n1k=1∑n(IXT(λk)−IYT(λk))2
(2)用正则化之后的特征来描述就是:
d P ( X T , Y T ) = 1 n ∑ k = 1 n ( N I X T ( λ k ) − N I Y T ( λ k ) ) 2 d_{P}(X_{T},Y_{T}) = \frac{1}{n}\sqrt{\sum_{k=1}^{n}(NI_{X_{T}}(\lambda_{k})-NI_{Y_{T}}(\lambda_{k}))^{2}} dP(XT,YT)=n1k=1∑n(NIXT(λk)−NIYT(λk))2
其中 N I X T ( λ k ) = I X T ( λ k ) / γ ^ 0 , X T NI_{X_{T}}(\lambda_{k})=I_{X_{T}}(\lambda_{k})/\hat{\gamma}_{0,X_{T}} NIXT(λk)=IXT(λk)/γ^0,XT, N I Y T ( λ k ) = I Y T ( λ k ) / γ ^ 0 , Y T NI_{Y_{T}}(\lambda_{k})=I_{Y_{T}}(\lambda_{k})/\hat{\gamma}_{0,Y_{T}} NIYT(λk)=IYT(λk)/γ^0,YT, γ ^ 0 , X T \hat{\gamma}_{0,X_{T}} γ^0,XT 和 γ ^ 0 , Y T \hat{\gamma}_{0,Y_{T}} γ^0,YT表示 X T , Y T X_{T}, Y_{T} XT,YT 的标准差(sample variance)。
(3)用取对数之后的特征表示:
d L N P ( X T , Y T ) = 1 n ∑ k = 1 n ( ln N I X T ( λ k ) − ln N I Y T ( λ k ) ) 2 d_{LNP}(X_{T},Y_{T}) = \frac{1}{n}\sqrt{\sum_{k=1}^{n}(\ln NI_{X_{T}}(\lambda_{k})-\ln NI_{Y_{T}}(\lambda_{k}))^{2}} dLNP(XT,YT)=n1k=1∑n(lnNIXT(λk)−lnNIYT(λk))2
基于离散小波变换的不同度量(A dissimilarity measure based on the discrete wavelet transform)
详细理解(https://xueshu.baidu.com/usercenter/paper/show?paperid=27edf6bf617081281133946c3a80f6c9&site=xueshu_se)
离散小波变换DWT(Discrete Wavelet Transform)
离散小波变换是对基本小波的尺度和平移进行离散化。在图像处理中,常采用二进小波作为小波变换函数,即使用2的整数次幂进行划分。
基于SAX的符号表示的不同测度(Dissimilarity based on the symbolic representation SAX)
SAX(Symbolic Aggregate Approximation )是一种时间序列的新型符号化方法
详细理解(https://xueshu.baidu.com/usercenter/paper/show?paperid=e6c37aa7c2058ecfa4acd6dd80ae13a5&site=xueshu_se)