1 前言
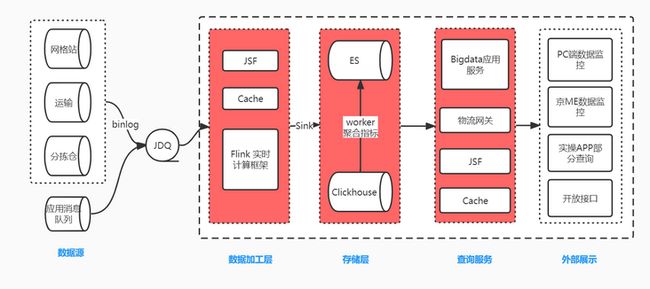
京喜达技术部在社区团购场景下采用JDQ+Flink+Elasticsearch架构来打造实时数据报表。随着业务的发展 Elasticsearch开始暴露出一些弊端,不适合大批量的数据查询,高频次深度分页导出导致ES宕机、不能精确去重统计,多个字段聚合计算时性能下降明显。所以引入ClickHouse来处理这些弊端。
数据写入链路是业务数据(binlog)经过处理转换成固定格式的MQ消息,Flink订阅不同Topic来接收不同生产系统的表数据,进行关联、计算、过滤、补充基础数据等加工关联汇总成宽表,最后将加工后的DataStream数据流双写入ES和ClickHouse。查询服务通过JSF和物流网关对外暴露提供给外部进行展示,由于ClickHouse将所有计算能力都用在一次查询上,所以不擅长高并发查询。我们通过对部分实时聚合指标接口增加缓存,或者定时任务查询ClickHosue计算指标存储到ES,部分指标不再实时查ClickHouse而是查ES中计算好的指标来抗住并发,并且这种方式能够极大提高开发效率,易维护,能够统一指标口径。
在引入ClickHouse过程中经历各种困难,耗费大量精力去探索并一一解决,在这里记录一下希望能够给没有接触过ClickHouse的同学提供一些方向上的指引避免多走弯路,如果文中有错误也希望多包含给出指点,欢迎大家一起讨论ClickHouse相关的话题。本文偏长但全是干货,请预留40\~60分钟进行阅读。
[]()2 遇到的问题
前文说到遇到了很多困难,下面这些遇到的问题是本文讲述的重点内容。
- 我们该使用什么表引擎
- Flink如何写入到ClickHouse
- 查询ClickHouse为什么要比查询ES慢1\~2分钟
- 写入分布式表还是本地表
- 为什么只有某个分片CPU使用率高
- 如何定位是哪些SQL在消耗CPU,这么多慢SQL,我怎么知道是哪个SQL引起的
- 找到了慢SQL,如何进行优化
- 如何抗住高并发、保证ClickHouse可用性
[]()3 表引擎选择与查询方案
在选择表引擎以及查询方案之前,先把需求捋清楚。前言中说到我们是在Flink中构造宽表,在业务上会涉及到数据的更新的操作,会出现同一个业务单号多次写入数据库。ES的upsert支持这种需要覆盖之前数据的操作,ClickHouse中没有upsert,所以需要探索出能够支持upsert的方案。带着这个需求来看一下ClickHouse的表引擎以及查询方案。
ClickHouse有很多表引擎,表引擎决定了数据以什么方式存储,以什么方式加载,以及数据表拥有什么样的特性。目前ClickHouse表引擎一共分为四个系列,分别是Log、MergeTree、Integration、Special。
- Log系列:适用于少量数据(小于一百万行)的场景,不支持索引,所以对于范围查询效率不高。
- Integration系列:主要用于导入外部数据到ClickHouse,或者在ClickHouse中直接操作外部数据,支持Kafka、HDFS、JDBC、Mysql等。
- Special系列:比如Memory将数据存储在内存,重启后会丢失数据,查询性能极好,File直接将本地文件作为数据存储等大多是为了特定场景而定制的。
- MergeTree系列:MergeTree家族自身拥有多种引擎的变种,其中MergeTree作为家族中最基础的引擎提供主键索引、数据分区、数据副本和数据采样等能力并且支持极大量的数据写入,家族中其他引擎在MergeTree引擎的基础上各有所长。
Log、Special、Integration主要用于特殊用途,场景相对有限。其中最能体现ClickHouse性能特点的是MergeTree及其家族表引擎,也是官方主推的存储引擎,几乎支持所有ClickHouse核心功能,在生产环境的大部分场景中都会使用此系列的表引擎。我们的业务也不例外需要使用主键索引,日数据增量在2500多万的增量,所以MergeTree系列是我们需要探索的目标。
MergeTree系列的表引擎是为插入大量数据而生,数据是以数据片段的形式一个接一个的快速写入,ClickHouse为了避免数据片段过多会在后台按照一定的规则进行合并形成新的段,相比在插入时不断的修改已经存储在磁盘的数据,这种插入后合并再合并的策略效率要高很多。这种数据片段反复合并的特点,也正是MergeTree系列(合并树家族)名称的由来。为了避免形成过多的数据片段,需要进行批量写入。MergeTree系列包含MergeTree、ReplacingMergeTree、CollapsingMergeTree、VersionedCollapsingMergeTree、SummingMergeTree、AggregatingMergeTree引擎,下面就介绍下这几种引擎。
[]()3.1 MergeTree:合并树
MergeTree支持所有ClickHouse SQL语法。大部分功能点和我们熟悉的MySQL是类似的,但是有些功能差异比较大,比如主键,MergeTree系列的主键并不用于去重,MySQL中一个表中不能存在两条相同主键的数据,但是ClickHouse中是可以的。
下面建表语句中,定义了订单号,商品数量,创建时间,更新时间。按照创建时间进行数据分区,orderNo作为主键(primary key),orderNo也作为排序键(order by),默认情况下主键和排序键相同,大部分情况不需要再专门指定primary key,这个例子中指定只是为了说明下主键和排序键的关系。当然排序键可以与的主键字段不同,但是主键必须为排序键的子集,例如主键(a,b), 排序键必须为(a,b, , ),并且组成主键的字段必须在排序键字段中的最左侧。
CREATE TABLE test_MergeTree ( orderNo String, number Int16, createTime DateTime, updateTime DateTime) ENGINE = MergeTree()PARTITION BY createTimeORDER BY (orderNo)PRIMARY KEY (orderNo);insert into test_MergeTree values('1', '20', '2021-01-01 00:00:00', '2021-01-01 00:00:00');insert into test_MergeTree values('1', '30', '2021-01-01 00:00:00', '2021-01-01 01:00:00');
注意这里写入的两条数据主键orderNo都是1的两条数据,这个场景是我们先创建订单,再更新了订单的商品数量为30和更新时间,此时业务实际订单量为1,商品件量是30。
插入主键相同的数据不会产生冲突,并且查询数据两条相同主键的数据都存在。下图是查询结果,由于每次插入都会形成一个part,第一次insert生成了1609430400\_1\_1\_0 数据分区文件,第二次insert生成了1609430400\_2\_2\_0 数据分区文件,后台还没触发合并,所以在clickhouse-client上的展示结果是分开两个表格的(图形化查询工具DBeaver、DataGrip不能看出是两个表格,可以通过docker搭建ClickHouse环境通过client方式执行语句,文末有搭建CK环境文档)。
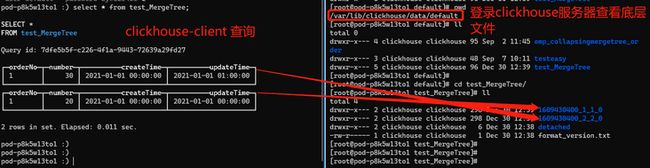
预期结果应该是number从20更新成30,updateTime也会更新成相应的值,同一个业务主键只存在一行数据,可是最终是保留了两条。Clickhouse中的这种处理逻辑会导致我们查询出来的数据是不正确的。比如去重统计订单数量,count(orderNo),统计下单件数sum(number)。
下面尝试将两行数据进行合并。
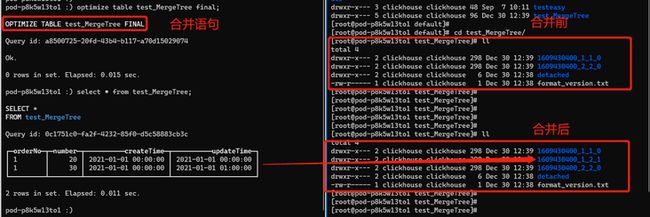
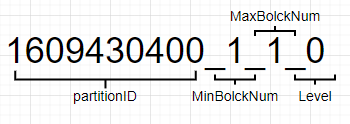
进行强制的分段合并后,还是有两条数据,并不是我们预期的保留最后一条商品数量为30的数据。但是两行数据合并到了一个表格中,其中的原因是1609430400\_1\_1\_0,1609430400\_2\_2\_0 的partitionID相同合并成了1609430400\_1\_2\_1这一个文件。合并完成后其中1609430400\_1\_1\_0,1609430400\_2\_2\_0会在一定时间(默认8min)后被后台删除。下图是分区文件的命名规则,partitionID:1609430400 = 2021-01-01 00:00:00,MinBolckNum、MaxBolckNum:是最小数据块最大数据块,是一个整形自增的编号。Level:0可以理解为分区合并过的次数,默认值是0,每次合并过后生成的新的分区后会加1。
综合上述,可以看出MergeTree虽然有主键,但并不是类似MySQL用来保持记录唯一的去重作用,只是用来查询加速,即使在手动合并之后,主键相同的数据行也仍旧存在,不能按业务单据去重导致count(orderNo),sum(number)拿到的结果是不正确的,不适用我们的需求。
[]()3.2 ReplacingMergeTree:替换合并树
MergeTree虽然有主键,但是不能对相同主键的数据进行去重,我们的业务场景不能有重复数据。ClickHouse提供了ReplacingMergeTree引擎用来去重,能够在合并分区时删除重复的数据。我理解的去重分两个方面,一个是物理去重,就是重复的数据直接被删除掉,另一个是查询去重,不处理物理数据,但是查询结果是已经将重复数据过滤掉的。
示例如下,ReplacingMergeTree建表方法和MergeTree没有特别大的差异,只是ENGINE 由MergeTree更改为ReplacingMergeTree([ver]),其中ver是版本列,是一个选填项,官网给出支持的类型是UInt ,Date或者DateTime,但是我试验Int类型也是可以支持的(ClickHouse 20.8.11)。ReplacingMergeTree在数据合并时物理数据去重,去重策略如下。
- 如果ver版本列未指定,相同主键行中保留最后插入的一行。
- 如果ver版本列已经指定,下面实例就指定了version列为版本列,去重是将会保留version值最大的一行,与数据插入顺序无关。
CREATE TABLE test_ReplacingMergeTree ( orderNo String, version Int16, number Int16, createTime DateTime, updateTime DateTime) ENGINE = ReplacingMergeTree(version)PARTITION BY createTimeORDER BY (orderNo)PRIMARY KEY (orderNo);1) insert into test_ReplacingMergeTree values('1', 1, '20', '2021-01-01 00:00:00', '2021-01-01 00:00:00');2) insert into test_ReplacingMergeTree values('1', 2, '30', '2021-01-01 00:00:00', '2021-01-01 01:00:00');3) insert into test_ReplacingMergeTree values('1', 3, '30', '2021-01-02 00:00:00', '2021-01-01 01:00:00');-- final方式去重select * from test_ReplacingMergeTree final;-- argMax方式去重select argMax(orderNo,version) as orderNo, argMax(number,version) as number,argMax(createTime,version),argMax(updateTime,version) from test_ReplacingMergeTree;
下图是在执行完前两条insert语句后进行三次查询的结果,三种方式查询均未对物理存储的数据产生影响,final、argMax方式只是查询结果是去重的。
- 普通查询:查询结果未去重,物理数据未去重(未合并分区文件)
- final去重查询:查询结果已去重,物理数据未去重(未合并分区文件)
- argMax去重查询:查询结果已去重,物理数据未去重(未合并分区文件)
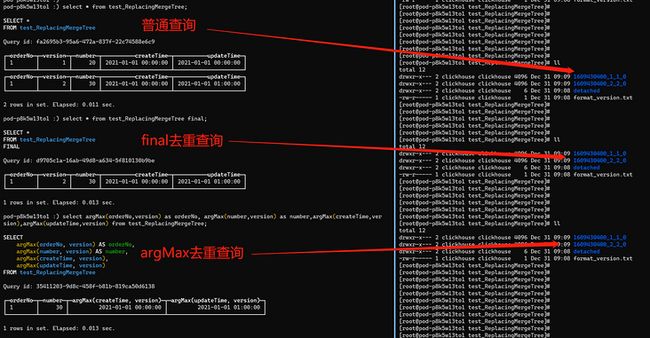
其中final和argMax查询方式都过滤掉了重复数据。我们的示例都是基于本地表做的操作,final和argMax在结果上没有差异,但是如果基于分布式表进行试验,两条数据落在了不同数据分片(注意这里不是数据分区),那么final和argMax的结果将会产生差异。final的结果将是未去重的,原因是final只能对本地表做去重查询,不能对跨分片的数据进行去重查询,但是argMax的结果是去重的。argMax是通过比较第二参数version的大小,来取出我们要查询的最新数据来达到过滤掉重复数据的目的,其原理是将每个Shard的数据搂到同一个Shard的内存中进行比较计算,所以支持跨分片的去重。
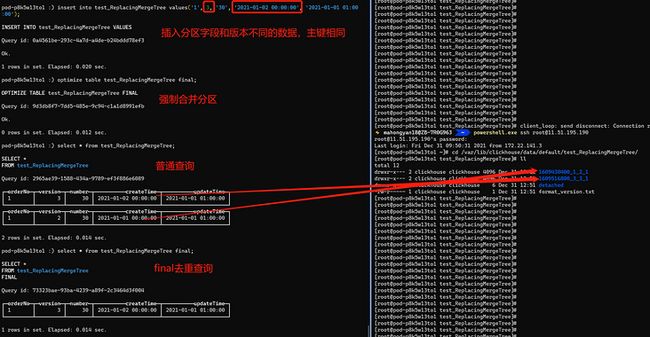
由于后台的合并是在不确定时间执行的,执行合并命令,然后再使用普通查询,发现结果已经是去重后的数据,version=2,number=30 是我们想保留的数据。

执行第三条insert语句,第三条的主键和前两条一致,但是分区字段createTime字段不同,前两条是2021-01-01 00:00:00,第三条是2021-01-02 00:00:00,如果按照上述的理解,在强制合并会后将会保留version = 3的这条数据。我们执行普通查询之后发现,version = 1和2的数据做了合并去重,保留了2,但是version=3的还是存在的,这其中的原因ReplacingMergeTree是已分区为单位删除重复数据。前两个insert的分区字段createTime字段相同,partitionID相同,所以都合并到了1609430400\_1\_2\_1分区文件,而第三条insert与前两条不一致,不能合并到一个分区文件,不能做到物理去重。最后通过final去重查询发现可以支持查询去重,argMax也是一样的效果未作展示。
ReplacingMergeTree具有如下特点
- 使用主键作为判断重复数据的唯一键,支持插入相同主键数据。
- 在合并分区的时候会触发删除重复数据的逻辑。但是合并的时机不确定,所以在查询的时候可能会有重复数据,但是最终会去重。可以手动调用optimize,但是会引发对数据大量的读写,不建议生产使用。
- 以数据分区为单位删除重复数据,当分区合并时,同一分区内的重复数据会被删除,不同分区的重复数据不会被删除。
- 可以通过final,argMax方式做查询去重,这种方式无论有没有做过数据合并,都可以得到正确的查询结果。
ReplacingMergeTree最佳使用方案
- 普通select查询:对时效不高的离线查询可以采用ClickHouse自动合并配合,但是需要保证同一业务单据落在同一个数据分区,分布式表也需要保证在同一个分片(Shard),这是一种最高效,最节省计算资源的查询方式。
- final方式查询:对于实时查询可以使用final,final是本地去重,需要保证同一主键数据落在同一个分片(Shard),但是不需要落在同一个数据分区,这种方式效率次之,但是与普通select相比会消耗一些性能,如果where条件对主键索引,二级索引,分区字段命中的比较好的话效率也可以完全可以使用。
- argMax方式查询:对于实时查询可以使用argMax,argMax的使用要求最低,咋查都能去重,但是由于它的实现方式,效率会低很多,也很消耗性能,不建议使用。后面9.4.3会配合压测数据与final进行对比。
上述的三种使用方案中其中ReplacingMergeTree配合final方式查询,是符合我们需求的。
[]()3.3 CollapsingMergeTree/VersionedCollapsingMergeTree:折叠合并树
折叠合并树不再通过示例来进行说明。可参考官网示例。
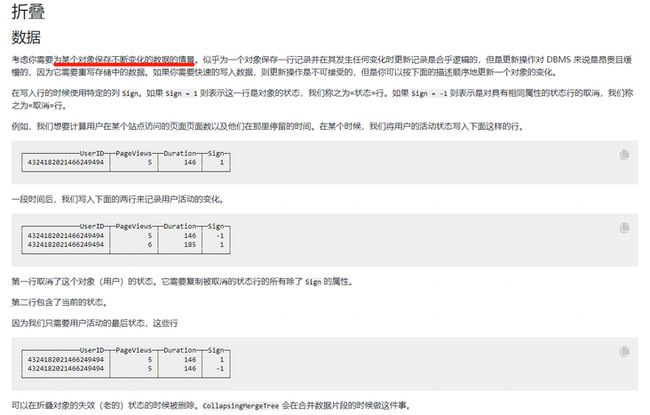
CollapsingMergeTree通过定义一个sign标记位字段,记录数据行的状态。如果sign标记位1(《状态》行), 则表示这是一行有效的数据, 如果sign标记位为 -1(《取消》行),则表示这行数据需要被删除。需要注意的是数据主键相同才可能会被折叠。
- 如果sign=1比sign=-1的数据多至少一行,则保留最后一行sign=1的数据。
- 如果sign=-1比sign=1多至少一行,则保留第一行sign=-1的行。
- 如果sign=1与sign=-1的行数一样多,最后一行是sign=1,则保留第一行sign=-1和最后一行sign=1的数据。
- 如果sign=1与sign=-1的行数一样多,最后一行是sign=-1,则什么都不保留。
- 其他情况ClickHouse不会报错但会打印告警日志,这种情况下,查询的结果是不确定不可预知的。
在使用CollapsingMergeTree时候需要注意
1)与ReplacingMergeTree一样,折叠数据不是实时触发的,是在分区合并的时候才会体现,在合并之前还是会查询到重复数据。解决方式有两种
- 使用optimize强制合并,同样也不建议在生产环境中使用效率极低并且消耗资源的强制合并。
- 改写查询方式,通过group by 配合有符号的sign列来完成。这种方式增加了使用的编码成本

2)在写入方面通过《取消》行删除或修改数据的方式需要写入数据的程序记录《状态》行的数据,极大的增加存储成本和编程的复杂性。Flink在上线或者某些情况下会重跑数据,会丢失程序中的记录的数据行,可能会造成sign=1与sign=-1不对等不能进行合并,这一点是我们无法接受的问题。
CollapsingMergeTree还有一个弊端,对写入的顺序有严格的要求,如果按照正常顺序写入,先写入sign=1的行再写入sign=-1的行,能够正常合并,如果顺序反过来则不能正常合并。ClickHouse提供了VersionedCollapsingMergeTree,通过增加版本号来解决顺序问题。但是其他的特性与CollapsingMergeTree完全一致,也不能满足我们的需求
[]()3.4 表引擎总结
我们详细介绍了MergeTree系列中的MergeTree、ReplacingMergeTree、CollapsingMergeTree、VersionedCollapsingMergeTree四种表引擎,还有SummingMergeTree、AggregatingMergeTree没有介绍,SummingMergeTree是为不关心明细数据,只关心汇总数据设计的表引擎。MergeTree也能够满足这种只关注汇总数据的需求,通过group by配合sum,count聚合函数就可以满足,但是每次查询都进行实时聚合会增加很大的开销。我们既有明细数据需求,又需要汇总指标需求,所以SummingMergeTree不能满足我们的需求。AggregatingMergeTree是SummingMergeTree升级版,本质上还是相同的,区别在于:SummingMergeTree对非主键列进行sum聚合,而AggregatingMergeTree则可以指定各种聚合函数。同样也满足不了需求。

最终我们选用了ReplacingMergeTree引擎,分布式表通过业务主键sipHash64(docId)进行shard保证同一业务主键数据落在同一分片,同时使用业务单据创建时间按月/按天进行分区。配合final进行查询去重。这种方案在双十一期间数据日增3000W,业务高峰数据库QPS93,32C 128G 6分片 2副本的集群CPU使用率最高在60%,系统整体稳定。下文的所有实践优化也都是基于ReplacingMergeTree引擎。
[]()4 Flink如何写入ClickHouse
[]()4.1 Flink版本问题
Flink支持通过JDBC Connector将数据写入JDBC数据库,但是Flink不同版本的JDBC connector写入方式有很大区别。因为Flink在1.11版本对JDBC Connector进行了一次较大的重构:
- 1.11版本之前包名为flink-jdbc
- 1.11版本(包含)之后包名为flink-connector-jdbc
两者对Flink中以不同方式写入ClickHouse Sink的支持情况如下:
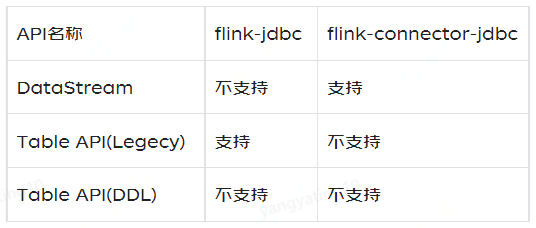
起初我们使用1.10.3版本的Flink,flink-jdbc不支持使用DataStream流写入,需要升级Flink版本至1.11.x及以上版本来使用flink-connector-jdbc来写入数据到ClickHouse。
[]()4.2 构造ClickHouse Sink
/** * 构造Sink * @param clusterPrefix clickhouse 数据库名称 * @param sql insert 占位符 eq:insert into demo (id, name) values (?, ?) */public static SinkFunction getSink(String clusterPrefix, String sql) { String clusterUrl = LoadPropertiesUtil.appInfoProcessMap.get(clusterPrefix + CLUSTER_URL); String clusterUsername = LoadPropertiesUtil.appInfoProcessMap.get(clusterPrefix + CLUSTER_USER_NAME); String clusterPassword = LoadPropertiesUtil.appInfoProcessMap.get(clusterPrefix + CLUSTER_PASSWORD); return JdbcSink.sink(sql, new CkSinkBuilder<>(), new JdbcExecutionOptions.Builder().withBatchSize(200000).build(), new JdbcConnectionOptions.JdbcConnectionOptionsBuilder() .withDriverName("ru.yandex.clickhouse.ClickHouseDriver") .withUrl(clusterUrl) .withUsername(clusterUsername) .withPassword(clusterPassword) .build());}
使用flink-connector-jdbc的JdbcSink.sink() api来构造Flink sink。JdbcSink.sink()入参含义如下
- sql:占位符形式的sql语句,例如:insert into demo (id, name) values (?, ?)
- new CkSinkBuilder<>():org.apache.flink.connector.jdbc.JdbcStatementBuilder接口的实现类,主要是将流中数据映射到java.sql.PreparedStatement 来构造PreparedStatement ,具体不再赘述。
- 第三个入参:flink sink的执行策略。
- 第四个入参:jdbc的驱动,连接,账号与密码。

- 使用时直接在DataStream流中addSink即可。
[]()5 Flink写入ClickHouse策略
Flink同时写入ES和Clikhouse,但是在进行数据查询的时候发现ClickHouse永远要比ES慢一些,开始怀疑是ClickHouse合并等处理会耗费一些时间,但是ClickHouse这些合并操作不会影响查询。后来查阅Flink写入策略代码发现是我们使用的策略有问题。
上段(4.2)代码中new JdbcExecutionOptions.Builder().withBatchSize(200000).build()为写入策略,ClickHouse为了提高写入性能建议进行不少于1000行的批量写入,或每秒不超过一个写入请求。策略是20W行记录进行写入一次,Flink进行Checkpoint的时候也会进行写入提交。所以当数据量积攒到20W或者Flink记性Checkpoint的时候ClickHouse里面才会有数据。我们的ES sink策略是1000行或5s进行写入提交,所以出现了写入ClickHouse要比写入ES慢的现象。
到达20W或者进行Checkpoint的时候进行提交有一个弊端,当数据量小达不到20W这个量级,Checkpoint时间间隔t1,一次checkpoint时间为t2,那么从接收到JDQ消息到写入到ClickHouse最长时间间隔为t1+t2,完全依赖Checkpoint时间,有时候有数据积压最慢有1\~2min。进而对ClickHouse的写入策略进行优化,new JdbcExecutionOptions.Builder().withBatchIntervalMs(30 * 1000).build() 优化为没30s进行提交一次。这样如果Checkpoint慢的话可以触发30s提交策略,否则Checkpoint的时候提交,这也是一种比较折中的策略,可以根据自己的业务特性进行调整,在调试提交时间的时候发现如果间隔过小,zookeeper的cpu使用率会提升,10s提交一次zk使用率会从5%以下提升到10%左右。
Flink中的org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat#open处理逻辑如下图。

[]()6 写入分布式表还是本地表
先说结果,我们是写入分布式表。\
网上的资料和ClickHouse云服务的同事都建议写入本地表。分布式表实际上是一张逻辑表并不存储真实的物理数据。如查询分布式表,分布式表会把查询请求发到每一个分片的本地表上进行查询,然后再集合每个分片本地表的结果,汇总之后再返回。写入分布式表,分布式表会根据一定规则,将写入的数据按照规则存储到不同的分片上。如果写入分布式表也只是单纯的网络转发,影响也不大,但是写入分布式表并非单纯的转发,实际情况见下图。
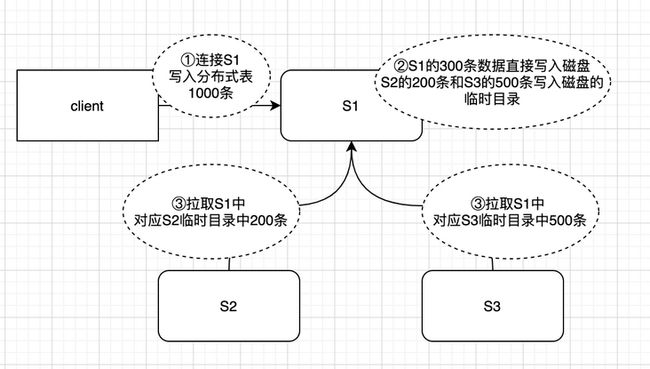
有三个分片S1、S2、S3,客户端连接到S1节点,进行写入分布式表操作。
- 第一步:写入分布式表1000条数据,分布式表会根据路由规则,假设按照规则300条分配到S1,200条到S2,500条到S3
- 第二步:client给过来1000条数据,属于S1的300条数据直接写入磁盘,数据S2,S3的数据也会写入到S1的临时目录
- 第三步:S2,S3接收到zk的变更通知,生成拉取S1中当前分片对应的临时目录数据的任务,并且将任务放到一个队列,等到某个时机会将数据拉到自身节点。
从分布式表的写入方式可以看到,会将所有数据落到client连接分片的磁盘上。如果数据量大,磁盘的IO会造成瓶颈。并且MergeTree系列引擎存在合并行为,本身就有写放大(一条数据合并多次),占用一定磁盘性能。在网上看到写入本地表的案例都是日增量百亿,千亿。我们选择写入分布式表主要有两点,一是简单,因为写入本地表需要改造代码,自己指定写入哪个节点,另一个是开发过程中写入本地表并未出现什么严重的性能瓶颈。双十一期间数据日增3000W(合并后)行并未造成写入压力。如果后续产生瓶颈,可能会放弃写入分布式表。
[]()7 为什么只有某个分片CPU使用率高
[]()7.1 数据分布不均匀,导致部分节点CPU高
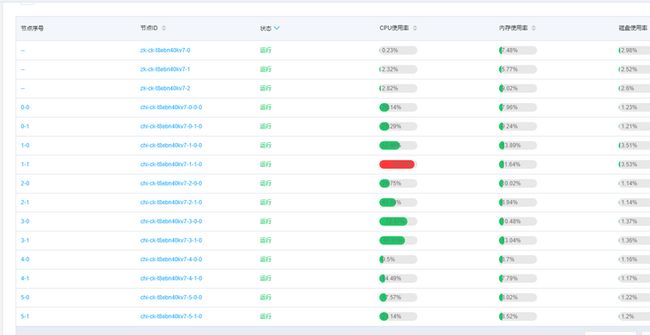
上图是在接入ClickHouse过程中遇到的一个问题,其中7-1节点CPU使用率非常高,不同节点的差异非常大。后来通过SQL定位发现不同节点上的数据量差异也非常大,其中7-1节点数据量是最多的,导致7-1节点相比其他节点需要处理的数据行数非常多,所以CPU相对会高很多。因为我们使用网格站编码,分拣仓编码hash后做分布式表的数据分片策略,但是分拣仓编码和网站编码的基数比较小,导致hash后不够分散造成这种数据倾斜的现象。后来改用业务主键做hash,解决了这种部分节点CPU高的问题。
[]()7.2 某节点触发合并,导致该节点CPU高

7-4节点(主节点和副本),CPU毫无征兆的比其他节点高很多,在排除新业务上线、大促等突发情况后进行慢SQL定位,通过query\_log进行分析每个节点的慢查询,具体语句见第8小节。
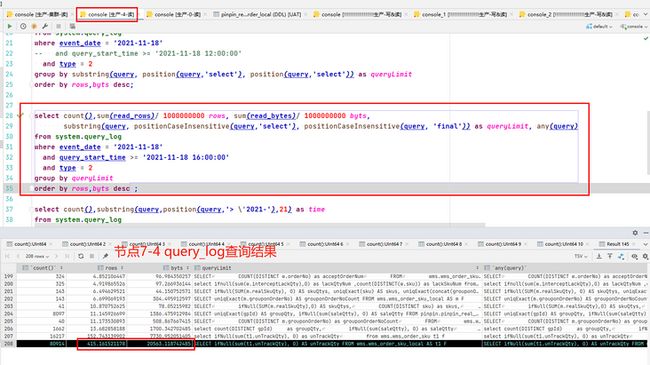
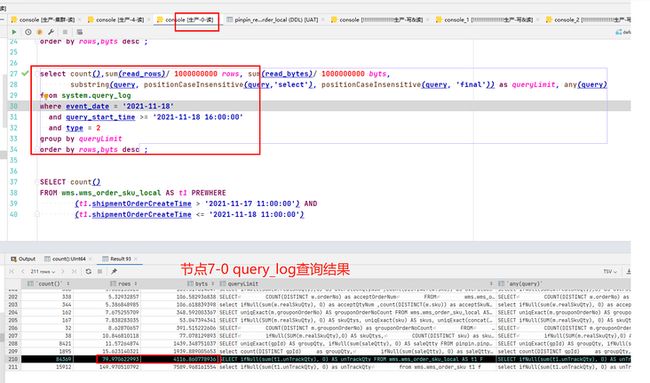
通过两个节点的慢SQL进行对比,发现是如下SQL的查询情况有较大差异。
SELECT ifNull(sum(t1.unTrackQty), 0) AS unTrackQtyFROM wms.wms_order_sku_local AS t1 FINAL PREWHERE t1.shipmentOrderCreateTime > '2021-11-17 11:00:00' AND t1.shipmentOrderCreateTime <= '2021-11-18 11:00:00' AND t1.gridStationNo = 'WG0000514' AND t1.warehouseNo NOT IN ('wms-6-979', 'wms-6-978', '6_979', '6_978') AND t1.orderType = '10'WHERE t1.ckDeliveryTaskStatus = '3'
但是我们有个疑惑,同样的语句,同样的执行次数,而且两个节点的数据量,part数量都没有差异,为什么7-4节点扫描的行数是7-0上的5倍,把这个原因找到,应该就能定位到问题的根本原因了。\
接下来我们使用clickhouse-client进行SQL查询,开启trace级别日志,查看SQL的执行过程。具体执行方式以及查询日志分析参考下文9.1小节,这里我们直接分析结果。
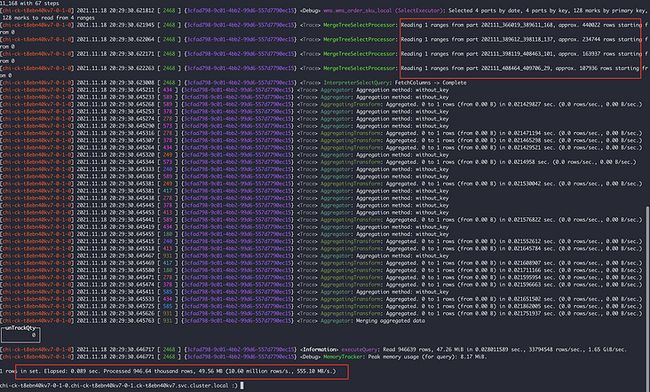
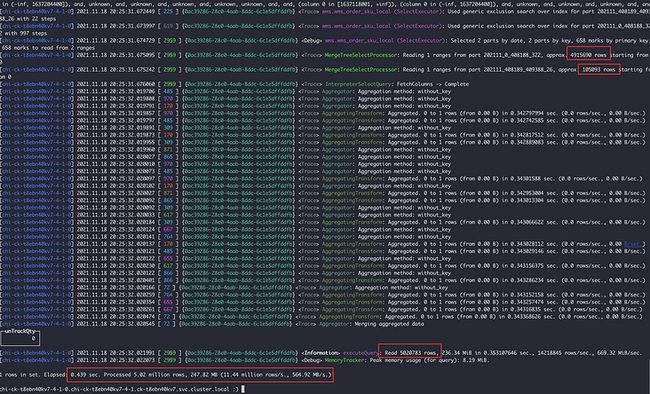
上面两张图可以分析出
- 7-0节点:扫描了4个part分区文件,共计94W行,耗时0.089s
- 7-4节点:扫描了2个part分区文件,其中有一个part491W行,共计502W行,耗时0.439s
很明显7-4节点的202111\_0\_408188\_322这个分区比较异常,因为我们是按月分区的,7-4节点不知道什么原因发生了分区合并,导致我们检索的11月17号的数据落到了这个大分区上,所以但是查询会过滤11月初到18号的所有数据,和7-0节点产生了差异。上述的SQL通过 gridStationNo = ‘WG0000514’ 条件进行查询,所以在对gridStationNo 字段进行创建二级索引后解决了这个问题。
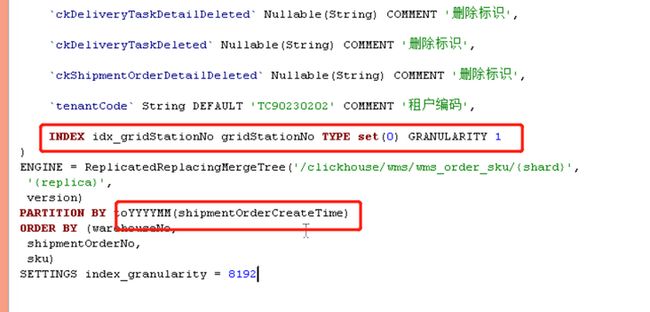
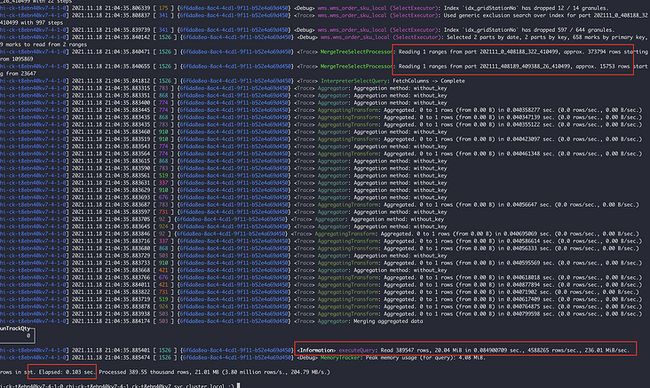
在增加加二级索引后7-4节点:扫描了2个part分区文件,共计38W行,耗时0.103s。
[]()7.3 物理机故障
这种情况少见,但是也遇到过一次
[]()8 如何定位是哪些SQL在消耗CPU
我认为可以通过两个方向来排查问题,一个是SQL执行频率是否过高,另一个方向是判断是否有慢SQL在执行,高频执行或者慢查询都会大量消耗CPU的计算资源。下面通过两个案例来说明一下排查CPU偏高的两种有效方法,下面两种虽然操作上是不同的,但是核心都是通过分析query\_log来进行分析定位的。
[]()8.1 grafana定位高频执行SQL
在12月份上线了一些需求,最近发现CPU使用率对比来看使用率偏高,需要排查具体是哪些SQL导致的。
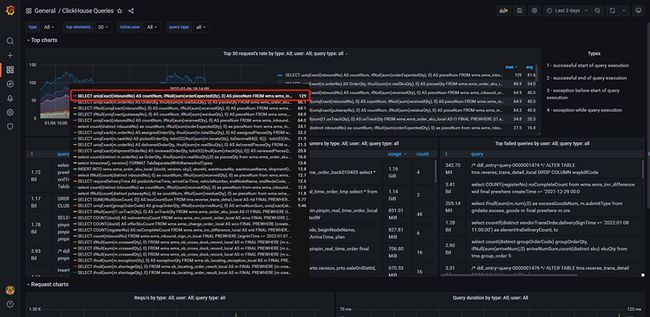
通过上图自行搭建的grafana监控可以看出(搭建文档),有几个查询语句执行频率非常高,通过SQL定位到查询接口代码逻辑,发现一次前端接口请求后端接口会执行多条相似条件的SQL语句,只是业务状态不相同。这种需要统计不同类型、不同状态的语句,可以进行条件聚合进行优化,9.4.1小节细讲。优化后语句执行频率极大的降低。

[]()8.2 扫描行数高/使用内存高:query\_log\_all分析
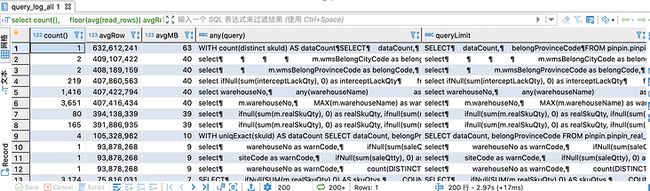
上节说SQL执行频率高,导致CPU使用率高。如果SQL频率执行频率很低很低,但是CPU还是很高该怎么处理。SQL执行频率低,可能存在扫描的数据行数很大的情况,消耗的磁盘IO,内存,CPU这些资源很大,这种情况下就需要换个手段来排查出来这个很坏很坏的SQL(T⌓T)。
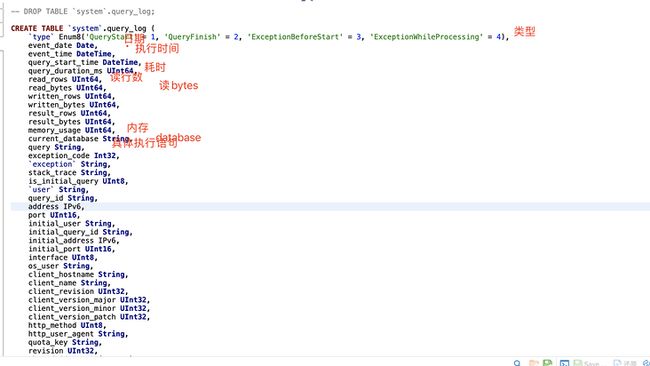
ClickHouse自身有system.query\_log表,用于记录所有的语句的执行日志,下图是该表的一些关键字段信息
-- 创建query_log分布式表CREATE TABLE IF NOT EXISTS system.query_log_allON CLUSTER defaultAS system.query_logENGINE = Distributed(sht_ck_cluster_pro,system,query_log,rand());-- 查询语句select -- 执行次数 count(), -- 平均查询时间 avg(query_duration_ms) avgTime, -- 平均每次读取数据行数 floor(avg(read_rows)) avgRow, -- 平均每次读取数据大小 floor(avg(read_rows) / 10000000) avgMB, -- 具体查询语句 any(query), -- 去除掉where条件,用户group by归类 substring(query, positionCaseInsensitive(query, 'select'), positionCaseInsensitive(query, 'from')) as queryLimitfrom system.query_log_all/system.query_logwhere event_date = '2022-01-21' and type = 2group by queryLimitorder by avgRow desc;
query\_log是本地表,需要创建分布式表,查询所有节点的查询日志,然后再执行查询分析语句,执行效果见下图,图中可以看出有几个语句平均扫秒行数已经到了亿级别,这种语句可能就存在问题。通过扫描行数可以分析出索引,查询条件等不合理的语句。7.2中的某个节点CPU偏高就是通过这种方式定位到有问题的SQL语句,然后进一步排查从而解决的。
[]()9 如何优化慢查询
ClickHouse的SQL优化比较简单,查询的大部分耗时都在磁盘IO上,可以参考下这个小实验来理解。核心优化方向就是降低ClickHouse单次查询处理的数据量,也就是降低磁盘IO。下面介绍下慢查询分析手段、建表语句优化方式,还有一些查询语句优化。
[]()9.1 使用服务日志进行慢查询分析
虽然ClickHouse在20.6版本之后已经提供查看查询计划的原生EXPLAIN,但是提供的信息对我们进行慢SQL优化提供的帮助不是很大,在20.6版本前借助后台的服务日志,可以拿到更多的信息供我们分析。与EXPLAIN相比我更倾向于使用查看服务日志这种方式进行分析,这种方式需要使用clickhouse-client进行执行SQL语句,文末有通过docker搭建CK环境文档。高版本的EXPLAIN提供了ESTIMATE可以查询到SQL语句扫描的part数量、数据行数等细粒度信息,EXPLAIN使用方式可以参考官方文档说明。\
用一个慢查询来进行分析,通过8.2中的query\_log\_all定位到下列慢SQL。
select ifNull(sum(interceptLackQty), 0) as interceptLackQtyfrom wms.wms_order_sku_local final prewhere productionEndTime = '2022-02-17 08:00:00' and orderType = '10'where shipmentOrderDetailDeleted = '0' and ckContainerDetailDeleted = '0'
使用clickhouse-client,send\_logs\_level参数指定日志级别为trace。
clickhouse-client -h 地址 --port 端口 --user 用户名 --password 密码 --send_logs_level=trace
在client中执行上述慢SQL,服务端打印日志如下,日志量较大,省去部分部分行,不影响整体日志的完整性。
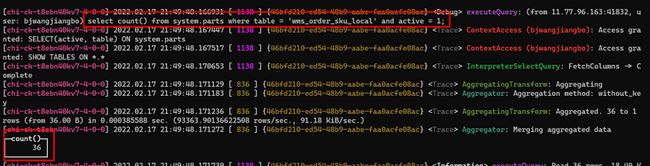
[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.036317 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} executeQuery: (from 11.77.96.163:35988, user: bjwangjiangbo) select ifNull(sum(interceptLackQty), 0) as interceptLackQty from wms.wms_order_sku_local final prewhere productionEndTime = '2022-02-17 08:00:00' and orderType = '10' where shipmentOrderDetailDeleted = '0' and ckContainerDetailDeleted = '0'[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.037876 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} ContextAccess (bjwangjiangbo): Access granted: SELECT(orderType, interceptLackQty, productionEndTime, shipmentOrderDetailDeleted, ckContainerDetailDeleted) ON wms.wms_order_sku_local[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.038239 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} wms.wms_order_sku_local (SelectExecutor): Key condition: unknown, unknown, and, unknown, unknown, and, and, unknown, unknown, and, and[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.038271 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} wms.wms_order_sku_local (SelectExecutor): MinMax index condition: unknown, unknown, and, unknown, unknown, and, and, unknown, unknown, and, and[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.038399 [ 1340 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} wms.wms_order_sku_local (SelectExecutor): Not using primary index on part 202101_0_0_0_3[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.038475 [ 1407 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} wms.wms_order_sku_local (SelectExecutor): Not using primary index on part 202103_0_17_2_22[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.038491 [ 111 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} wms.wms_order_sku_local (SelectExecutor): Not using primary index on part 202103_18_20_1_22..................................省去若干行(此块含义为:在分区内检索有没有使用索引).................................................[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.039041 [ 1205 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} wms.wms_order_sku_local (SelectExecutor): Not using primary index on part 202202_1723330_1723365_7[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.039054 [ 159 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} wms.wms_order_sku_local (SelectExecutor): Not using primary index on part 202202_1723367_1723367_0[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.038928 [ 248 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} wms.wms_order_sku_local (SelectExecutor): Not using primary index on part 202201_3675258_3700711_1054[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.039355 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} wms.wms_order_sku_local (SelectExecutor): Selected 47 parts by date, 47 parts by key, 9471 marks by primary key, 9471 marks to read from 47 ranges[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.039495 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} MergeTreeSelectProcessor: Reading 1 ranges from part 202101_0_0_0_3, approx. 65536 rows starting from 0[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.039583 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} MergeTreeSelectProcessor: Reading 1 ranges from part 202101_1_1_0_3, approx. 16384 rows starting from 0[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.040291 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} MergeTreeSelectProcessor: Reading 1 ranges from part 202102_0_2_1_4, approx. 146850 rows starting from 0..................................省去若干行(每个分区读取的数据行数信息).................................................[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.043538 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} MergeTreeSelectProcessor: Reading 1 ranges from part 202202_1723330_1723365_7, approx. 24576 rows starting from 0[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.043604 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} MergeTreeSelectProcessor: Reading 1 ranges from part 202202_1723366_1723366_0, approx. 8192 rows starting from 0[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.043677 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} MergeTreeSelectProcessor: Reading 1 ranges from part 202202_1723367_1723367_0, approx. 8192 rows starting from 0..................................完成数据读取,开始进行聚合计算.................................................[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.047880 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} InterpreterSelectQuery: FetchColumns -> Complete[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.263500 [ 1377 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} AggregatingTransform: Aggregating[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.263680 [ 1439 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} Aggregator: Aggregation method: without_key..................................省去若干行(数据读取完成后做聚合操作).................................................[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.263840 [ 156 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} AggregatingTransform: Aggregated. 12298 to 1 rows (from 36.03 KiB) in 0.215046273 sec. (57187.69187876137 rows/sec., 167.54 KiB/sec.)[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.264283 [ 377 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} AggregatingTransform: Aggregated. 12176 to 1 rows (from 35.67 KiB) in 0.215476999 sec. (56507.191284950095 rows/sec., 165.55 KiB/sec.)[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.264307 [ 377 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} Aggregator: Merging aggregated data..................................完成聚合计算,返回最终结果.................................................┌─interceptLackQty─┐│ 563 │└──────────────────┘...................................数据处理耗时,速度,信息展示................................................[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.265490 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} executeQuery: Read 73645604 rows, 1.20 GiB in 0.229100749 sec., 321455099 rows/sec., 5.22 GiB/sec.[chi-ck-t8ebn40kv7-3-0-0] 2022.02.17 21:21:54.265551 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} MemoryTracker: Peak memory usage (for query): 60.37 MiB.1 rows in set. Elapsed: 0.267 sec. Processed 73.65 million rows, 1.28 GB (276.03 million rows/s., 4.81 GB/s.)
现在分析下,从上述日志中能够拿到什么信息,首先该查询语句没有使用主键索引,具体信息如下
2022.02.17 21:21:54.038239 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} wms.wms\_order\_sku\_local (SelectExecutor): Key condition: unknown, unknown, and, unknown, unknown, and, and, unknown, unknown, and, and
同样也没有使用分区索引,具体信息如下
2022.02.17 21:21:54.038271 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} wms.wms\_order\_sku\_local (SelectExecutor): MinMax index condition: unknown, unknown, and, unknown, unknown, and, and, unknown, unknown, and, and
此次查询一共扫描36个parts,9390个MarkRange,通过查询system.parts系统分区信息表发现当前表一共拥有36个活跃的分区,相当于全表扫描。
2022.02.17 21:44:58.012832 [ 1138 ] {f1561330-4988-4598-a95d-bd12b15bc750} wms.wms\_order\_sku\_local (SelectExecutor): Selected 36 parts by date, 36 parts by key, 9390 marks by primary key, 9390 marks to read from 36 ranges
此次查询总共读取了73645604 行数据,这个行数也是这个表的总数据行数,读取耗时0.229100749s,共读取1.20GB的数据。
2022.02.17 21:21:54.265490 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} executeQuery: Read 73645604 rows, 1.20 GiB in 0.229100749 sec., 321455099 rows/sec., 5.22 GiB/sec.
此次查询语句消耗的内存最大为60.37MB
2022.02.17 21:21:54.265551 [ 618 ] {ea8f56fe-cf2b-4260-8f44-a006458bdab3} MemoryTracker: Peak memory usage (for query): 60.37 MiB.
最后汇总了下信息,此次查询总共耗费了0.267s,处理了7365W数据,共1.28GB,并且给出了数据处理速度。
1 rows in set. Elapsed: 0.267 sec. Processed 73.65 million rows, 1.28 GB (276.03 million rows/s., 4.81 GB/s.)
通过上述可以发现两点严重问题
- 没有使用主键索引:导致全表扫描
- 没有使用分区索引:导致全表扫描
所以需要再查询条件上添加主键字段或者分区索引来进行优化。
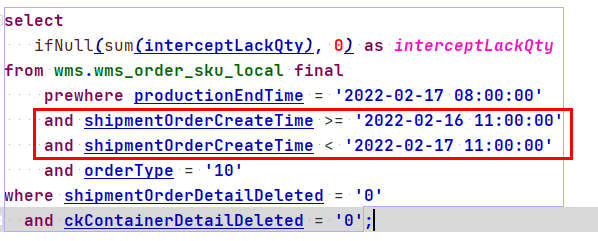
shipmentOrderCreateTime为分区键,在添加这个条件后再看下效果。
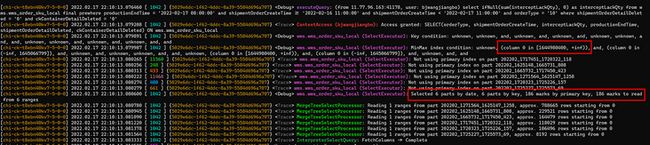
![]()
通过分析日志可以看到没有使用主键索引,但是使用了分区索引,扫描分片数为6,MarkRange 186,共扫描1409001行数据,使用内存40.76MB,扫描数据大小等大幅度降低节省大量服务器资源,并且提升了查询速度,0.267s降低到0.18s。
[]()9.2 建表优化
[]()9.2.1 尽量不使用Nullable类型
从实践上看,设置成Nullable对性能影响也没有多大,可能是因为我们数据量比较小。不过官方已经明确指出尽量不要使用Nullable类型,因为Nullable字段不能被索引,而且Nullable列除了有一个存储正常值的文件,还会有一个额外的文件来存储Null标记。
Using Nullable almost always negatively affects performance, keep this in mind when designing your databases.
CREATE TABLE test_Nullable( orderNo String, number Nullable(Int16), createTime DateTime) ENGINE = MergeTree()PARTITION BY createTimeORDER BY (orderNo)PRIMARY KEY (orderNo);
上述建表语句为例,number 列会生成number.null.*两个额外文件,占用额外存储空间,而orderNo列则没有额外的null标识的存储文件。
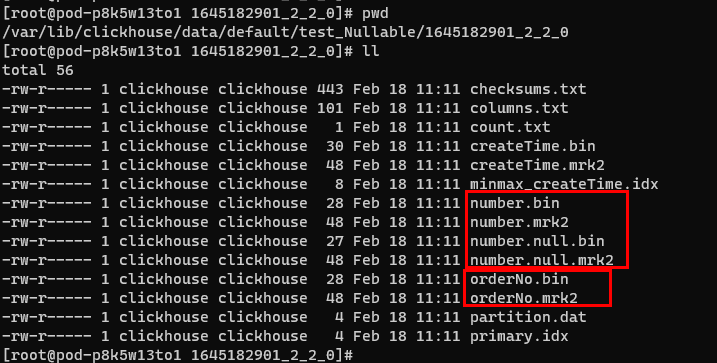
我们实际应用中建表,难免会遇到这种可能为null的字段,这种情况下可以使用不可能出现的一个值作为默认值,例如将状态字段都是0及以上的值,那么可以设置为-1为默认值,而不是使用nullable。
[]()9.2.2 分区粒度
分区粒度根据业务场景特性来设置,不宜过粗也不宜过细。我们的数据一般都是按照时间来严格划分,所以都是按天、按月来划分分区。如果索引粒度过细按分钟、按小时等划分会产生大量的分区目录,更不能直接PARTITION BY create\_time ,会导致分区数量惊人的多,几乎每条数据都有一个分区会严重的影响性能。如果索引粒度过粗,会导致单个分区的数据量级比较大,上面7.2节的问题和索引粒度也有关系,按月分区,单个分区数据量到达500W级,数据范围1号到18号,只查询17号,18号两天的数据量,但是优化按月分区,分区合并之后不得不处理不相关的1号到16号的额外数据,如果按天分区就不会产生CPU飙升的现象。所以要根据自己业务特性来创建,保持一个原则就是查询只处理本次查询条件范围内的数据,不额外处理不相关的数据。
[]()9.2.3 分布式表选择合适的分片规则
以上文7.1中为例,分布式表选择的分片规则不合理,导致数据倾斜严重落到了少数几个分片中。没有发挥出分布式数据库整个集群的计算能力,而是把压力全压在了少部分机器上。这样整体集群的性能肯定是上不来的,所以根据业务场景选择合适的分片规则,比如我们将sipHash64(warehouseNo)优化为sipHash64(docId),其中docId是业务上唯一的一个标识。
[]()9.3 性能测试,对比优化效果
在聊查询优化之前先说一个小工具,clickhouse提供的一个clickhouse-benchmark性能测试工具,环境和前文提到的一样通过docker搭建CK环境,压测参数可参考官方文档,这里我举一个简单的单并发测试示例。
clickhouse-benchmark -c 1 -h 链接地址 --port 端口号 --user 账号 --password 密码 <<< "具体SQL语句"
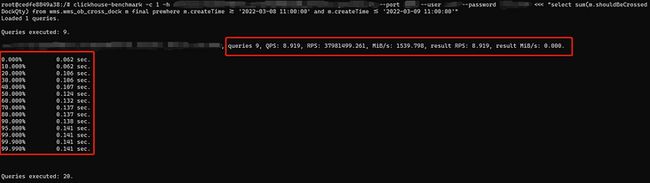
通过这种方式可以了解SQL级别的QPS和TP99等信息,这样就可以测试语句优化前后的性能差异。
[]()9.4 查询优化
[]()9.4.1 条件聚合函数降低扫描数据行数
假设一个接口要统计某天的”入库件量”,”有效出库单量”,”复核件量”。
-- 入库件量select sum(qty) from table_1 final prewhere type = 'inbound' and dt = '2021-01-01';-- 有效出库单量select count(distinct orderNo) final from table_1 prewhere type = 'outbound' and dt = '2021-01-01' where and status = '1' ;-- 复核件量select sum(qty) from table_1 final prewhere type = 'check' and dt = '2021-01-01';
一个接口出三个指标需要上述三个SQL语句查询table\_1 来完成,但是我们不难发现dt是一致的,区别在于type和status两个条件。假设dt = ‘2021-01-1’ 每次查询需要扫描100W行数据,那么一次接口请求将会扫描300W行数据。通过条件聚合函数优化后将三次查询改成一次,那么扫描行数将降低为100W行,所以能极大的节省集群的计算资源。
select sumIf(qty, type = 'inbound'), -- 入库件量countIf(distinct orderNo, type = 'outbound' and status = '1'), -- 有效出库单量sumIf(qty, type = 'check') -- 复核件量prewhere dt = '2021-01-01';
条件聚合函数是比较灵活的,可根据自己业务情况自由发挥,记住一个宗旨就是减少整体的扫描量,就能到达提升查询性能的目的。
[]()9.4.2 二级索引
MergeTree 系列的表引擎可以指定跳数索引。\
跳数索引是指数据片段按照粒度(建表时指定的index\_granularity)分割成小块后,将granularity\_value数量的小块组合成一个大的块,对这些大块写入索引信息,这样有助于使用where筛选时跳过大量不必要的数据,减少SELECT需要读取的数据量。
CREATE TABLE table_name( u64 UInt64, i32 Int32, s String, ... INDEX a (u64 * i32, s) TYPE minmax GRANULARITY 3, INDEX b (u64 * length(s)) TYPE set(1000) GRANULARITY 4) ENGINE = MergeTree()...
上例中的索引能让 ClickHouse 执行下面这些查询时减少读取数据量。
SELECT count() FROM table WHERE s < 'z'SELECT count() FROM table WHERE u64 * i32 == 10 AND u64 * length(s) >= 1234
支持的索引类型
- minmax:以index granularity为单位,存储指定表达式计算后的min、max值;在等值和范围查询中能够帮助快速跳过不满足要求的块,减少IO。
- set(max\_rows):以index granularity为单位,存储指定表达式的distinct value集合,用于快速判断等值查询是否命中该块,减少IO。
- ngrambf\_v1(n, size\_of\_bloom\_filter\_in\_bytes, number\_of\_hash\_functions, random\_seed):将string进行ngram分词后,构建bloom filter,能够优化等值、like、in等查询条件。
- tokenbf\_v1(size\_of\_bloom\_filter\_in\_bytes, number\_of\_hash\_functions, random\_seed): 与ngrambf\_v1类似,区别是不使用ngram进行分词,而是通过标点符号进行词语分割。
- bloom\_filter([false\_positive]):对指定列构建bloom filter,用于加速等值、like、in等查询条件的执行。
创建二级索引示例
Alter table wms.wms_order_sku_local ON cluster default ADD INDEX belongProvinceCode_idx belongProvinceCode TYPE set(0) GRANULARITY 5;Alter table wms.wms_order_sku_local ON cluster default ADD INDEX productionEndTime_idx productionEndTime TYPE minmax GRANULARITY 5;
重建分区索引数据:在创建二级索引前插入的数据,不能走二级索引,需要重建每个分区的索引数据后才能生效
-- 拼接出所有数据分区的MATERIALIZE语句select concat('alter table wms.wms_order_sku_local on cluster default ', 'MATERIALIZE INDEX productionEndTime_idx in PARTITION '||partition_id||',')from system.partswhere database = 'wms' and table = 'wms_order_sku_local'group by partition_id-- 执行上述SQL查询出的所有MATERIALIZE语句进行重建分区索引数据
[]()9.4.3 final替换argMax进行去重
对比下final和argMax两种方式的性能差距,如下SQL
-- final方式select count(distinct groupOrderCode), sum(arriveNum), count(distinct sku) from tms.group_order final prewhere siteCode = 'WG0001544' and createTime >= '2022-03-14 22:00:00' and createTime <= '2022-03-15 22:00:00' where arriveNum > 0 and test <> '1'-- argMax方式select count(distinct groupOrderCode), sum(arriveNumTemp), count(distinct sku) from (select argMax(groupOrderCode,version) as groupOrderCode, argMax(arriveNum,version) as arriveNumTemp, argMax(sku,version) as sku from tms.group_order prewhere siteCode = 'WG0001544' and createTime >= '2022-03-14 22:00:00' and createTime <= '2022-03-15 22:00:00' where arriveNum > 0 and test <> '1' group by docId)
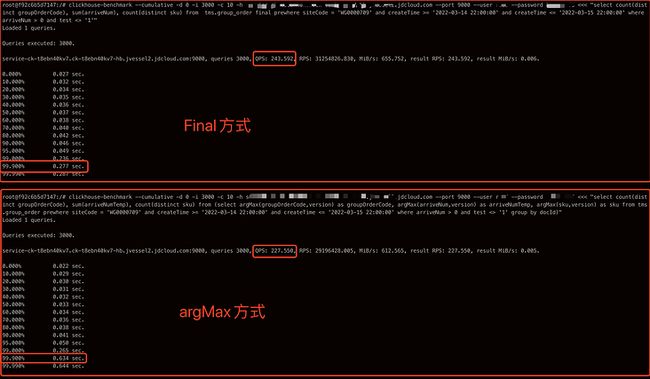
final方式的TP99明显要比argMax方式优秀很多
[]()9.4.4 prewhere替代where
ClickHouse的语法支持了额外的prewhere过滤条件,它会先于where条件进行判断,可以看做是更高效率的where,作用都是过滤数据。当在sql的filter条件中加上prewhere过滤条件时,存储扫描会分两阶段进行,先读取prewhere表达式中依赖的列值存储块,检查是否有记录满足条件,在把满足条件的其他列读出来,以下述的SQL为例,其中prewhere方式会优先扫描type,dt字段,将符合条件的列取出来,当没有任何记录满足条件时,其他列的数据就可以跳过不读了。相当于在Mark Range的基础上进一步缩小扫描范围。prewhere相比where而言,处理的数据量会更少,性能会更高。看这段话可能不太容易理解,
-- 常规方式select count(distinct orderNo) final from table_1 where type = 'outbound' and status = '1' and dt = '2021-01-01';-- prewhere方式select count(distinct orderNo) final from table_1 prewhere type = 'outbound' and dt = '2021-01-01' where and status = '1' ;
上节我们说了使用final进行去重优化。通过final去重,并且使用prewhere进行查询条件优化时有个坑需要注意,prewhere会优先于final进行执行,所以对于status这种值可变的字段处理过程中,能够查询到中间状态的数据行,导致最终数据不一致。

如上图所示,docId:123\_1的业务数据,进行三次写入,到version=103的数据是最新版本数据,当我们使用where过滤status这个可变值字段时,语句1,语句2结果如下。
--语句1:使用where + status=1 查询,无法命中docId:123_1这行数据select count(distinct orderNo) final from table_1 where type = 'outbound' and dt = '2021-01-01' and status = '1';--语句2:使用where + status=2 查询,可以查询到docId:123_1这行数据select count(distinct orderNo) final from table_1 where type = 'outbound' and dt = '2021-01-01' and status = '2';
当我们引入prewhere后,语句3写法:prewhere过滤status字段时将status=1,version=102的数据会过滤出来,导致我们查询结果不正确。正确的写法是语句2,将不可变字段使用prewhere进行优化。
-- 语句3:错误方式,将status放到prewhereselect count(distinct orderNo) final from table_1 prewhere type = 'outbound' and dt = '2021-01-01' and status = '1';-- 语句4:正确prewhere方式,status可变字段放到where上select count(distinct orderNo) final from table_1 prewhere type = 'outbound' and dt = '2021-01-01' where and status = '1' ;
其他限制:prewhere目前只能用于MergeTree系列的表引擎
[]()9.4.5 列裁剪,分区裁剪
ClickHouse 非常适合存储大数据量的宽表,因此我们应该避免使用 SELECT * 操作,这是一个非常影响的操作。应当对列进行裁剪,只选择你需要的列,因为字段越少,消耗的 IO 资源就越少,从而性能就越高。\
而分区裁剪就是只读取需要分区,控制好分区字段查询范围。
[]()9.4.6 where、group by 顺序
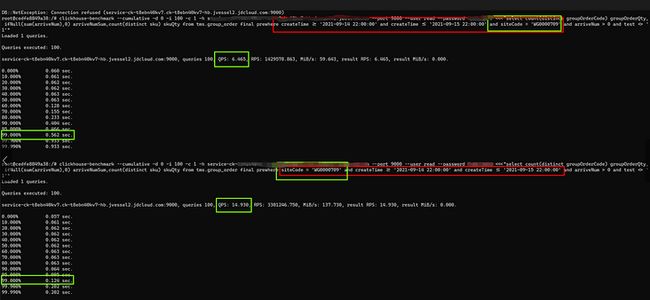
where和group by中的列顺序,要和建表语句中order by的列顺序统一,并且放在最前面使得它们有连续不间断的公共前缀,否则会影响查询性能。
-- 建表语句create table group_order_local( docId String, version UInt64, siteCode String, groupOrderCode String, sku String, ... 省略非关键字段 ... createTime DateTime) engine = ReplicatedReplacingMergeTree('/clickhouse/tms/group_order/{shard}', '{replica}', version)PARTITION BY toYYYYMM(createTime)ORDER BY (siteCode, groupOrderCode, sku);--查询语句1select count(distinct groupOrderCode) groupOrderQty, ifNull(sum(arriveNum),0) arriveNumSum,count(distinct sku) skuQtyfrom tms.group_order finalprewhere createTime >= '2021-09-14 22:00:00' and createTime <= '2021-09-15 22:00:00'and siteCode = 'WG0000709'where arriveNum > 0 and test <> '1'--查询语句2 (where/prewhere中字段)select count(distinct groupOrderCode) groupOrderQty, ifNull(sum(arriveNum),0) arriveNumSum,count(distinct sku) skuQtyfrom tms.group_order finalprewhere siteCode = 'WG0000709' and createTime >= '2021-09-14 22:00:00' and createTime <= '2021-09-15 22:00:00'where arriveNum > 0 and test <> '1'
建表语句 ORDER BY (siteCode, groupOrderCode, sku),语句1没有符合要求经过压测QPS6.4,TP99 0.56s,语句2符合要求经过压测QPS 14.9,TP99 0.12s
[]()10 如何抗住高并发、保证ClickHouse可用性
1)降低查询速度,提高吞吐量
max\_threads:位于 users.xml 中,表示单个查询所能使用的最大 CPU 个数,默认是 CPU 核数,假如机器是32C,则会起32个线程来处理当前请求。可以把max\_threads调低,牺牲单次查询速度来保证ClickHouse的可用性,提升并发能力。可通过jdbc的url来配置
![]()
下图是基于32C128G配置,在保证CK集群能够提供稳定服务CPU使用率在50%的情况下针对max\_threads做的一个压测,接口级别压测,一次请求执行5次SQL,处理数据量508W行。可以看出max\_threads越小,QPS越优秀TP99越差。可根据自身业务情况来进行调整一个合适的配置值。

2)接口增加一定时间的缓存\
3)异步任务执行查询语句,将聚合指标结果落到ES中,应用查询ES中的聚合结果\
4)物化视图,通过预聚合方式解决这种问题,但是我们这种业务场景不适用
11 资料集合
•更改ORDER BY字段,PARTITION BY,备份数据,单表迁移数据等操作
•基于docker搭建clickhouse-client链接ck集群
作者:京东物流 马红岩
内容来源:京东云开发者社区