【python】一些常用的pandas技巧
有了gpt之后,确实很多代码都可以让gpt给改错。嘎嘎香
merge多个dateframe
https://stackoverflow.com/questions/44327999/how-to-merge-multiple-dataframes
data_net = [a,b,c,d]
net_merged = reduce(lambda left,right: pd.merge(left,right,on=['key column'],
how='outer'), data_net)
merge的参数细节
看过很多次的文章。基础但有用。
pandas数据合并之一文弄懂pd.merge()https://zhuanlan.zhihu.com/p/132579724
NAN值处理
移动全为NAN的行
dataframe.dropna(axis=0,how='any',inplace=True)
看各列里面NAN的数量
dataframe.isnull().sum()
把带NAN的dataframe以行显示
dataframe[dataframe.isnull().T.any()]
将NAN值替换为0并以整数显示
df.fillna(0, inplace=True)
df= df.astype(int)
保存csv
解决中文乱码
dataframe.to_csv(r"XXXXXX.csv",
header=True,encoding="utf_8_sig",index=False)
自定义名字
file.to_csv(r"XXXX/{}.csv".format(XXXXX),
header=True,encoding="utf_8_sig",index=False
pathlib读取文件夹内文件
from pathlib2 import Path
file_path=Path(r"XXXX")
for date in file_path.iterdir():
print(date.stem) #文件名
file=pd.read_csv(date)
print(file)
os读取文件夹
# 设置 CSV 文件所在的目录
csv_dir = "路径"
# 获取目录下所有的 CSV 文件名
csv_files = [f for f in os.listdir(csv_dir) if f.endswith('.csv')]
# 读取每个 CSV 文件,并将它们存储在一个列表中
dfs = []
for csv_file in csv_files:
df = pd.read_csv(os.path.join(csv_dir, csv_file))
split切割
file['XX'] = file['AA'].map(lambda x: x.split(' ')[0]) #保存空格前面的部分
file['YY'] = file['AA'].map(lambda x: x.split(' ')[1]) #保存空格后面的部分
统计一列里有多少变量
代码的意思是读取DF里面一列并进行个数统计,将结果保存为一共两列的DF
XXX=dataframe['列名'].value_counts(
).rename_axis('自定义列名').reset_index(name='自定义统计量列名')
举个结果例子:

对行进行操作
- 移除满足条件的行
df= df[df['列名'].astype(float) > 10]
- List item
strptime和strftime
涉及到时间序列的缩写表达
https://docs.python.org/3/library/datetime.html#strftime-and-strptime-behavior
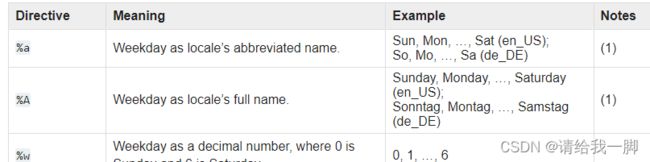
24小时制度的转换
file['XXX']=file['XXX'].apply(
# lambda x: datetime.datetime.strptime(x,"%H:%M").strftime("%H:%M"))
列名
删掉带有特定字符的列名
https://stackoverflow.com/questions/19071199/drop-columns-whose-name-contains-a-specific-string-from-pandas-dataframe
df = df[df.columns.drop(list(df.filter(regex='特定字符')))]
对含有特定字符的列名进行批量修改
举例:_x和_y被删掉了
df.rename(columns=lambda x: x.replace('_x', '').replace('_y', ''), inplace=True)
列值排序
df= df.sort_values(by=['XXX'], ascending=True)
merge how=outer
两张表=5296+6509=
![]()

how=outer的结果,左表5108+194=5302,右表6324+194=6518
??????????????????
