ClickHouse 源码阅读 SQL的前世今生
注:以下分析基于开源 v19.15.2.2-stable 版本进行,社区最新版本代码改动较大,但是总体思路是不变的。
用户提交一条查询SQL背后发生了什么?
在传统关系型数据库中,SQL处理器的组件主要包括以下几种:
• Query Parsing
负责进行词法和语法分析,把程序从人类高可读的格式(即SQL)转化成机器高可读的格式(AST,抽象语法树)。
词法分析指的是把SQL中的字符序列分解成一个个独立的词法单元——Token(<类型,值>)。
语法分析指的是从词法分析器输出的token中识别各类短语,并构造出一颗抽象语法树。而按照构造抽象语法树的方向,又可以把语法分析分成自顶向下和自底向上分析两种。而ClickHouse采用的则是手写一个递归下降的语法分析器。
• Query Rewrite
即通常我们说的"Logical Optimizer"或基于规则的优化器(Rule-Based Optimizer,即RBO)。
其负责应用一些启发式规则,负责简化和标准化查询,无需改变查询的语义。
常见操作有:谓词和算子下推,视图展开,简化常量运算表达式,谓词逻辑的重写,语义的优化等。
• Query Optimizer
即通常我们所说的"Physical Optimizer",负责把内部查询表达转化成一个高效的查询计划,指导DBMS如何去取表,如何进行排序,如何Join。如下图所示,一个查询计划可以被认为是一个数据流图,在这个数据流图中,表数据会像在管道中传输一样,从一个查询操作符(operator)传递到另一个查询操作符。
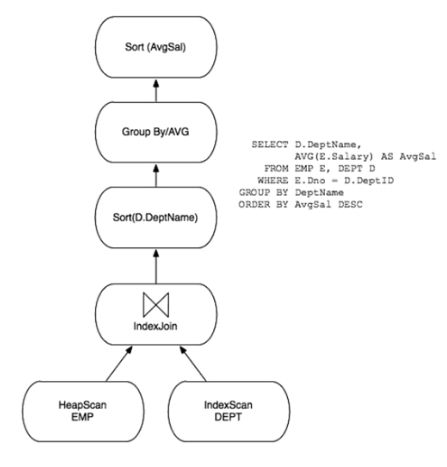
一个查询计划
• Query Executor
查询执行器,负责执行具体的查询计划,从存储引擎中获取数据并且对数据应用查询计划得到结果。
执行引擎也分为很多种,如经典的火山模型(Volcano Model),还有ClickHouse采用的向量化执行模型(Vectorization Model)。
(图来自经典论文 Architecture Of Database System)
但不管是传统的关系型数据库,还是非关系型数据库,SQL的解析和生成执行计划过程都是大同小异的,而纵览ClickHouse的源代码,可以把用户提交一条查询SQL背后的过程总结如下:
1.服务端接收客户端发来的SQL请求,具体形式是一个网络包,Server的协议层需要拆包把SQL解析出来
2.Server负责初始化上下文与Network Handler,然后 Parser 对Query做词法和语法分析,解析成AST
3.Interpreter的 SyntaxAnalyzer 会应用一些启发式规则对AST进行优化重写
4.Interpreter的 ExpressionAnalyzer 根据上下文信息以及优化重写后的AST生成物理执行计划
5.物理执行计划分发到本地或者分布式的executor,各自从存储引擎中获取数据,应用执行计划
6.Server把执行后的结果以Block流的形式输出到Socket缓冲区,Client从Socket中读取即可得到结果
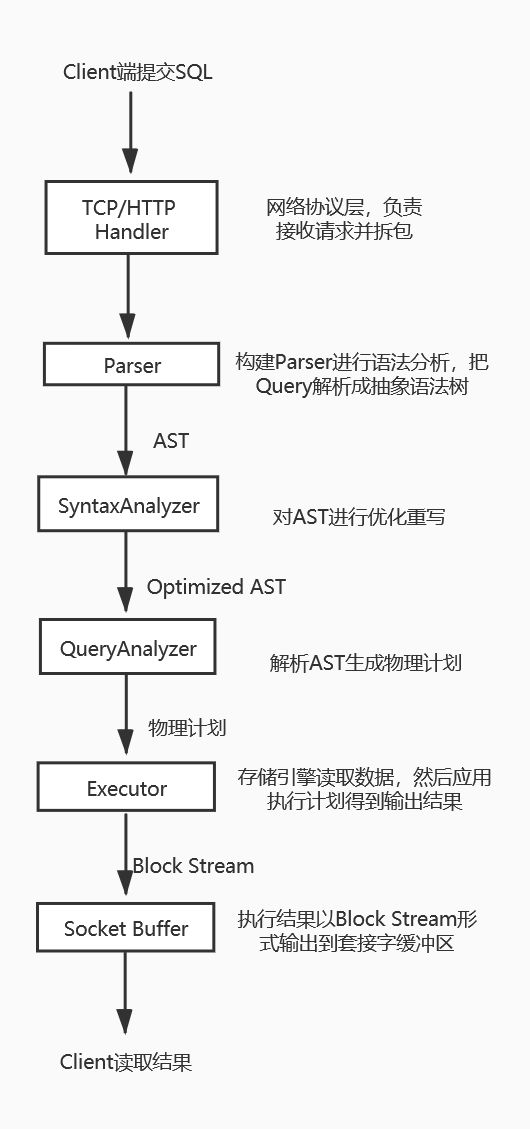
接收客户端请求
我们要以服务端的视角来出发,首先来看server.cpp大概做什么事情:
下面只挑选重要的逻辑:
• 初始化上下文
• 初始化Zookeeper(ClickHouse的副本复制机制需要依赖ZooKeeper)
• 常规配置初始化
• 绑定服务端的端口,根据网络协议初始化Handler,对客户端提供服务
int Server::main()
{
// 初始化上下文
global_context = std::make_unique(Context::createGlobal());
global_context->setApplicationType(Context::ApplicationType::SERVER);
// zk初始化
zkutil::ZooKeeperNodeCache main_config_zk_node_cache([&] { return global_context->getZooKeeper(); });
//其他config的初始化
//...
//绑定端口,对外提供服务
auto address = make_socket_address(host, port);
socket.bind(address, /* reuseAddress = */ true);
//根据网络协议建立不同的server类型
//现在支持的server类型有: HTTP,HTTPS,TCP,Interserver,mysql
//以TCP版本为例:
create_server("tcp_port", [&](UInt16 port)
{
Poco::Net::ServerSocket socket;
auto address = socket_bind_listen(socket, listen_host, port);
servers.emplace_back(std::make_unique(
new TCPHandlerFactory(*this),
server_pool,
socket,
new Poco::Net::TCPServerParams));
});
//启动server
for (auto & server : servers)
server->start();
} 客户端发来的请求是由各自网络协议所对应的 Handler 来进行的,server在启动的时候 Handler 会被初始化并绑定在指定端口中。我们以TCPHandler为例,看看服务端是如何处理客户端发来的请求的,重点关注 TCPHandler::runImpl 的函数实现:
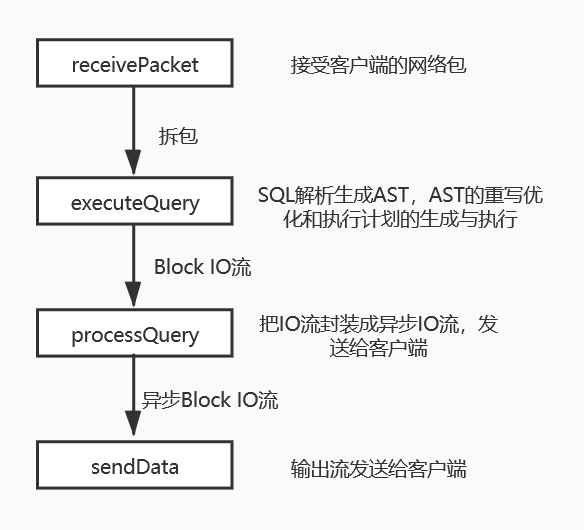
• 初始化输入和输出流的缓冲区
• 接受请求报文,拆包
• 执行Query(包括整个词法语法分析,Query重写,物理计划生成和生成结果)
• 把Query结果保存到输出流,然后发送到Socket的缓冲区,等待发送回客户端
void TCPHandler::runImpl()
{
//实例化套接字对应的输入和输出流缓冲区
in = std::make_shared(socket());
out = std::make_shared(socket());
while (1){
// 接收请求报文
receivePacket();
// 执行Query
state.io = executeQuery(state.query, *query_context, false, state.stage, may_have_embedded_data);
//根据Query种类来处理不同的Query
//处理insert Query
processInsertQuery();
//并发处理普通Query
processOrdinaryQueryWithProcessors();
//单线程处理普通Query
processOrdinaryQuery();
}
} 那CK处理客户端发送过来的Query的具体逻辑是怎样的呢?
我们可以在dbms/src/Interpreters/executeQuery.cpp 中一探究竟:
具体逻辑在 executeQueryImpl 函数中,挑选核心的逻辑进行讲解:
static std::tuple executeQueryImpl()
{
//构造Parser
ParserQuery parser(end, settings.enable_debug_queries);
ASTPtr ast;
//把Query转化为抽象语法树
ast = parseQuery(parser, begin, end, "", max_query_size);
//生成interpreter实例
auto interpreter = InterpreterFactory::get(ast, context, stage);
// interpreter解析AST,结果是BlockIO
res = interpreter->execute();
//返回结果是抽象语法树和解析后的结果组成的二元组
return std::make_tuple(ast, res);
} 该函数所做的事情:
• 构建Parser,把Query解析成AST(抽象语法树)
• InterpreterFactory根据AST生成对应的Interpreter实例
• AST是由Interpreter来解析的,执行结果是一个BlockIO,BlockIO是对 BlockInputStream 和 BlockOutputStream 的一个封装。
总结:
• 服务端调用 executeQuery 来处理client发送的Query,执行后的结果保存在state这个结构体的io成员中。
每一条Query都会对应一个state结构体,记录了这条Query的id,处理状态,压缩算法,Query的文本和Query所处理数据对应的IO流等元信息。
• 然后服务端调用 processOrdinaryQuery 等方法把输出流结果封装成异步的IO流,发送到回client。
解析请求(Parser)
CK选择采用手写一个递归下降的Parser来对SQL进行解析,生成的结果是这个SQL对应的抽象语法树(AST),抽象语法树由表示各个操作的节点(IAST)表示。而本节主要介绍Parser背后的核心逻辑:
词法分析和语法分析的核心逻辑可以在parseQuery.cpp的 tryParseQuery 中一览无余。
该函数利用lexer将扫描Query字符流,将其分割为一个个的Token, token_iterator 即一个Token流迭代器,然后parser再对Token流进行解析生成AST抽象语法树。
ASTPtr tryParseQuery()
{
//Token为lexer词法分析后的基本单位,词法分析后生成的是Token流
Tokens tokens(pos, end, max_query_size);
IParser::Pos token_iterator(tokens);
ASTPtr res;
//Token流经过语法分析生成AST抽象语法树
bool parse_res = parser.parse(token_iterator, res, expected);
return res;
}我们可以看到,语法分析的核心就在于parser执行的parse方法。parse 方法具体的实现在 ParserQuery.cpp 的 parseImpl 中。
bool ParserQuery::parseImpl(Pos & pos, ASTPtr & node, Expected & expected)
{
ParserQueryWithOutput query_with_output_p(enable_explain);
ParserInsertQuery insert_p(end);
ParserUseQuery use_p;
ParserSetQuery set_p;
ParserSystemQuery system_p;
bool res = query_with_output_p.parse(pos, node, expected)
|| insert_p.parse(pos, node, expected)
|| use_p.parse(pos, node, expected)
|| set_p.parse(pos, node, expected)
|| system_p.parse(pos, node, expected);
return res;
}我们可以看到,这个方法粗略地把Query分为了五种,但是本质上可以归纳为两种(第一种为有结果输出,对应show,select,create等语句;第二种为无结果输出,对应insert,use,set和与系统相关的语句(如exit))
• QueryWithOutput
• InsertQuery
• UseQuery
• SetQuery
• SystemQuery
每一种Query都自定义了其专属的Parser,所以代码逻辑是当接收到一个Query输入的时候,会尝试各种Query的Parser,直到成功为止。
我们可以select语句对应的parser进行分析:
核心逻辑可以总结为:
1.先给出select语句中可能出现的关键词
2.在词法分析生成的Token流中爬取这些关键词
3.如果成功爬取,则 setExpression 函数会组装该关键字对应的AST节点
每一种SQL语句(如select,drop,insert,create)都有对应的AST类,并且分别包含了这些语句中特有的关键字。
bool ParserSelectQuery::parseImpl(Pos & pos, ASTPtr & node, Expected & expected)
{
//创建AST树节点
auto select_query = std::make_shared();
node = select_query;
//select语句中会出现的关键词
ParserKeyword s_select("SELECT");
ParserKeyword s_distinct("DISTINCT");
ParserKeyword s_from("FROM");
ParserKeyword s_prewhere("PREWHERE");
ParserKeyword s_where("WHERE");
ParserKeyword s_group_by("GROUP BY");
ParserKeyword s_with("WITH");
ParserKeyword s_totals("TOTALS");
ParserKeyword s_having("HAVING");
ParserKeyword s_order_by("ORDER BY");
ParserKeyword s_limit("LIMIT");
ParserKeyword s_settings("SETTINGS");
ParserKeyword s_by("BY");
ParserKeyword s_rollup("ROLLUP");
ParserKeyword s_cube("CUBE");
ParserKeyword s_top("TOP");
ParserKeyword s_with_ties("WITH TIES");
ParserKeyword s_offset("OFFSET");
//...
//依次对Token流爬取上述关键字
ParserTablesInSelectQuery().parse(pos, tables, expected)
//根据语法分析结果设置AST的Expression属性,可以理解为如果SQL存在该关键字,这个关键字都会转化为AST上的一个节点
select_query->setExpression(ASTSelectQuery::Expression::WITH, std::move(with_expression_list));
select_query->setExpression(ASTSelectQuery::Expression::SELECT, std::move(select_expression_list));
select_query->setExpression(ASTSelectQuery::Expression::TABLES, std::move(tables));
select_query->setExpression(ASTSelectQuery::Expression::PREWHERE, std::move(prewhere_expression));
select_query->setExpression(ASTSelectQuery::Expression::WHERE, std::move(where_expression));
select_query->setExpression(ASTSelectQuery::Expression::GROUP_BY, std::move(group_expression_list));
select_query->setExpression(ASTSelectQuery::Expression::HAVING, std::move(having_expression));
select_query->setExpression(ASTSelectQuery::Expression::ORDER_BY, std::move(order_expression_list));
select_query->setExpression(ASTSelectQuery::Expression::LIMIT_BY_OFFSET, std::move(limit_by_offset));
select_query->setExpression(ASTSelectQuery::Expression::LIMIT_BY_LENGTH, std::move(limit_by_length));
select_query->setExpression(ASTSelectQuery::Expression::LIMIT_BY, std::move(limit_by_expression_list));
select_query->setExpression(ASTSelectQuery::Expression::LIMIT_OFFSET, std::move(limit_offset));
select_query->setExpression(ASTSelectQuery::Expression::LIMIT_LENGTH, std::move(limit_length));
select_query->setExpression(ASTSelectQuery::Expression::SETTINGS, std::move(settings));
} 整个Parser的流程图: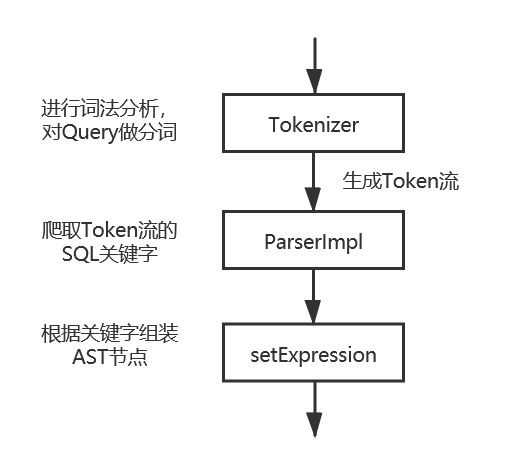
执行请求(Interpreter)
解释器(Interpreter)负责从抽象语法树中创建查询执行的流水线,整条流水线以 BlockInputStream 和 BlockOutputStream 进行组织。比方说"select"是基于"from"的Block输出流来进行选择的,选择后的结果也会以Block输出流的形式输出到结果。 首先我们来看:
dbms/src/Interpreters/InterpreterFactory.cpp
每一种Query都会有对应的Interpreter,这个工厂方法就是根据AST的种类来实例化其对应的Interpreter,由其来具体执行对应AST的执行计划:
std::unique_ptr InterpreterFactory::get(ASTPtr & query, Context & context, QueryProcessingStage::Enum stage)
{
//举个例子,如果该AST是由select语句转化过来,
if (query->as())
{
/// This is internal part of ASTSelectWithUnionQuery.
/// Even if there is SELECT without union, it is represented by ASTSelectWithUnionQuery with single ASTSelectQuery as a child.
return std::make_unique(query, context, SelectQueryOptions(stage));
}
} 我们就以 InterpreterSelectQuery 为例,了解其实例化的核心逻辑:
InterpreterSelectQuery::InterpreterSelectQuery()
{
//获取AST
auto & query = getSelectQuery();
//对AST做进一步语法分析,对语法树做优化重写
syntax_analyzer_result = SyntaxAnalyzer(context, options).analyze(
query_ptr, source_header.getNamesAndTypesList(), required_result_column_names, storage, NamesAndTypesList());
//每一种Query都会对应一个特有的表达式分析器,用于爬取AST生成执行计划(操作链)
query_analyzer = std::make_unique(
query_ptr, syntax_analyzer_result, context,
NameSet(required_result_column_names.begin(), required_result_column_names.end()),
options.subquery_depth, !options.only_analyze);
} 语法分析直接生成的AST转化成执行计划可能性能上并不是最优的,因此需要SyntaxAnalyzer 对其进行优化重写,在其源码中可以看到其涉及到非常多 基规则优化(rule based optimization) 的trick。
SyntaxAnalyzer 会逐个针对这些规则对查询进行检查,确定其是否满足转换规则,一旦满足就会对其进行转换。
SyntaxAnalyzerResultPtr SyntaxAnalyzer::analyze()
{
// 剔除冗余列
removeDuplicateColumns(result.source_columns);
// 根据settings中enable_optimize_predicate_expression配置判断是否进行谓词下移
replaceJoinedTable(node);
// 根据settings中distributed_product_mode配置重写IN 与 JOIN 表达式
InJoinSubqueriesPreprocessor(context).visit(query);
// 优化Query内部的布尔表达式
LogicalExpressionsOptimizer().perform();
// 创建一个从别名到AST节点的映射字典
QueryAliasesVisitor(query_aliases_data, log.stream()).visit(query);
// 公共子表达式的消除
QueryNormalizer(normalizer_data).visit(query);
// 消除select从句后的冗余列
removeUnneededColumnsFromSelectClause(select_query, required_result_columns, remove_duplicates);
// 执行标量子查询,并且用常量替代标量子查询结果
executeScalarSubqueries(query, context, subquery_depth);
// 如果是select语句还会做下列优化:
// 谓词下移优化
PredicateExpressionsOptimizer(select_query, settings, context).optimize();
/// GROUP BY 从句的优化
optimizeGroupBy(select_query, source_columns_set, context);
/// ORDER BY 从句的冗余项剔除
optimizeOrderBy(select_query);
/// LIMIT BY 从句的冗余列剔除
optimizeLimitBy(select_query);
/// USING语句的冗余列剔除
optimizeUsing(select_query);
}这里挑选几个简单介绍一下:
• 公共子表达式消除(Common Subexpression Elimination)
如果表达式 x op y 先前被计算过,并且从先前的计算到现在其计算表达式对应的值没有改变,那么 x op y 就称为公共子表达式。公共子表达式消除会搜索所有相同计算表达式的实例,并分析是否值得用保存计算值的单个变量来替换它们,以减少计算的开销。
• 标量子查询(Scala Subquery)的常量替换
标量子查询就是返回单一值的子查询,和公共子表达式消除相似,可以用常量来替换SQL中所有的标量子查询结果以减少计算开销。
• 谓词下移(Predicate Pushdown)
把外层查询块中的WHERE子句的谓词下移到较低层查询块如视图,以尽可能把过滤数据的操作移动到靠近数据源的位置。提前进行数据过滤能够大幅减少网络传输或者内存读取访问的数据量,以提高查询效率。
而 query_analyzer 的作用可以理解为解析优化重写后的AST,然后对所要进行的操作组成一条操作链,即物理执行计划,如:
ExpressionActionsChain chain;
analyzer.appendWhere(chain);
chain.addStep();
analyzer.appendSelect(chain);
analyzer.appendOrderBy(chain);
chain.finalize();上述代码把where,select,orderby操作都加入到操作链中,接下来就可以从Storage层读取Block,对Block数据应用上述操作链的操作。而执行的核心逻辑,就在对应Interpreter的 executeImpl 方法实现中,这里以select语句的Interpreter来了解下读取Block数据并且对block数据进行相应操作的流程。
void InterpreterSelectQuery::executeImpl(TPipeline & pipeline, const BlockInputStreamPtr & prepared_input)
{
// 对应Query的AST
auto & query = getSelectQuery();
AnalysisResult expressions;
// 物理计划,判断表达式是否有where,aggregate,having,order_by,litmit_by等字段
expressions = analyzeExpressions(
getSelectQuery(),
*query_analyzer,
QueryProcessingStage::FetchColumns,
options.to_stage,
context,
storage,
true,
filter_info);
// 从Storage读取数据
executeFetchColumns(from_stage, pipeline, sorting_info, expressions.prewhere_info, expressions.columns_to_remove_after_prewhere);
// eg:根据SQL的关键字在BlockStream流水线中执行相应的操作, 如where,aggregate,distinct都分别由一个函数负责执行
executeWhere(pipeline, expressions.before_where, expressions.remove_where_filter);
executeAggregation(pipeline, expressions.before_aggregation, aggregate_overflow_row, aggregate_final);
executeDistinct(pipeline, true, expressions.selected_columns);
}既然我们知道了执行计划AnalysisResult(即物理执行计划),接下来就需要从storage层中读取数据来执行对应的操作,核心逻辑在 executeFetchColumns 中: 核心操作就是从storage层读取所要处理列的Block,并组织成BlockStream。
void InterpreterSelectQuery::executeFetchColumns(
QueryProcessingStage::Enum processing_stage, TPipeline & pipeline,
const SortingInfoPtr & sorting_info, const PrewhereInfoPtr & prewhere_info, const Names & columns_to_remove_after_prewhere)
{
// 实例化Block Stream
auto streams = storage->read(required_columns, query_info, context, processing_stage, max_block_size, max_streams)
// 读取列对应的Block,并且组织成Block Stream
streams = {std::make_shared(storage->getSampleBlockForColumns(required_columns))};
streams.back() = std::make_shared(streams.back(), query_info.prewhere_info->remove_columns_actions);
} 读取完Block Stream之后就是对其执行各种execute操作如 executeAggregation , executeWhere 操作,详见 InterpreterSelectQuery::executeImpl 的代码。
因此Interpreter的处理过程可以总结为:
• 对AST进行优化重写
• 解析重写后的AST并生成操作链(执行计划)
• 从存储引擎中读取要处理的Block数据
• 对读取的Block数据应用操作链上的操作
那我们读取Block Stream并进行处理后,生成的结果如何写回到storage层呢? 我们这里以insert语句的Interpreter来了解下:
BlockIO InterpreterInsertQuery::execute()
{
// table为存储引擎接口
StoragePtr table = getTable(query);
BlockOutputStreamPtr out;
// 从存储引擎读取Block Stream
auto query_sample_block = getSampleBlock(query, table);
out = std::make_shared(
out, query_sample_block, out->getHeader(), table->getColumns().getDefaults(), context);
//执行结果封装成BlockIO
BlockIO res;
res.out = std::move(out);
} 上面代码中的StoragePtr实际上就是IStorage这个存储引擎的接口
using StoragePtr = std::shared_ptr; 无论是写入还是读取操作都是依靠底层存储引擎(如MergeTree)的write和read接口来实现的,关于存储引擎的细节实现这里暂时不赘述,这里我们只需要知道我们从存储引擎接口中以流方式读取Block数据,而结果组织成BlockIO流输出。Interpreter的流程总结如下: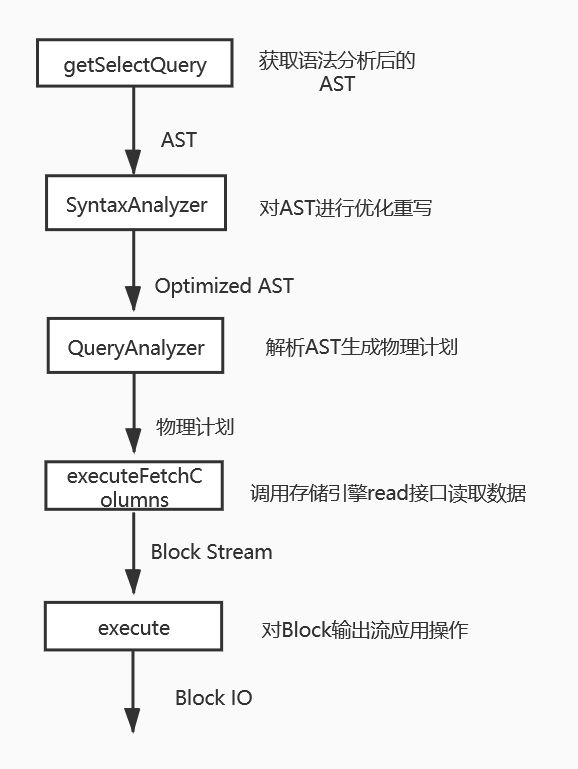
返回请求结果
TCPHandler::runImpl 中,执行完 executeQuery 之后需要调用各种processQuery的方法来给client返回执行SQL后的结果。
我们以 TCPHandler::processOrdinaryQuery 为例做简单分析:
void TCPHandler::processOrdinaryQuery()
{
//把BlockStream封装成异步的Stream,那么从流中读取数据将会是异步操作
AsynchronousBlockInputStream async_in(state.io.in);
while(true){
Block block;
//从IO流读取block数据
block = async_in.read();
//发送block数据
sendData(block);
}
}Server负责在 sendData 函数中把输出结果写入到套接字输出缓冲区中,client只要从这个输出缓冲区读取就能够得到结果。
void TCPHandler::sendData(const Block & block)
{
//初始化OutputStream的参数
initBlockOutput(block);
// 调用BlockOutputStream的write函数,把Block写到输出流
state.block_out->write(block);
state.maybe_compressed_out->next();
out->next();
}结语
了解ClickHouse背后SQL的查询整个流程,不仅能让数据库使用者更清晰地认识到如何编写最优化的SQL,也能够让数据库内核开发者加深对数据库体系结构的理解,提高开发效率。本文并没有涉及到太深入的技术细节,诸如向量化执行引擎,SIMD,基于llvm的动态代码生成,类MergeTree存储引擎等CK的技术细节也没有提及,只是从宏观角度给读者介绍了执行SQL背后内核到底发生了什么。后续我们会推出更多内核源码解读文章,敬请关注。
写在最后
阿里云已经率先推出了ClickHouse的云托管产品,产品首页地址:云数据库ClickHouse,目前正在免费公测中,欢迎大家点击链接申请免费试用。
我们也开通了阿里云ClickHouse钉钉交流群,通过专业的数据库专家为客户提供咨询、答疑服务。欢迎大家任选如下方式入群交流,我们将会定期推送ClickHouse最佳实践、操作指南、原理解读等深度文章。
• 方式一:使用钉钉搜索群号 23300515
上云就看云栖号,点此查看更多:https://yqh.aliyun.com/?utm_content=g_1000100940
本文为阿里云内容,未经允许不得转载。