chatgpt科普
引言
chatgpt没有国内开放,为什么如此重要。抛开技术细节,少用专业名词,在整体功能上讲解 ChatGPT 的工作原理、制造过程、涌现的能力、未来的影响以及如何应对。让大家明白:
ChatGPT是如何回答问题的。
它是怎么被制造的,为什么它不是搜索引擎。
它有哪些惊人能力,为什么它不只是聊天机器人。
它将给社会带来什么样的冲击。
我们该如何维持未来的竞争力。
- 底层原理
实质功能、训练方式、长板、短板。没有意识
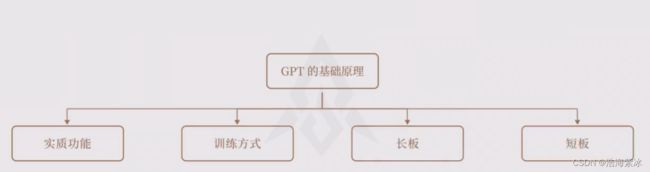
2.1 实质功能
单字接龙。任意长文用自己的模型生成下一个字。

怎么生成长内容,自回归生成。


2.2 训练方式
影响因素两个:上文和模型。
为了让ChatGPT生成我们想要的结果,而非胡乱生成,就要提前训练ChatGPT的模型。训练方式是:让它遵照所给的学习材料来做单字接龙。通过不断调整模型,使得给模型学习材料的上文后,模型能生成对应的下一个字。
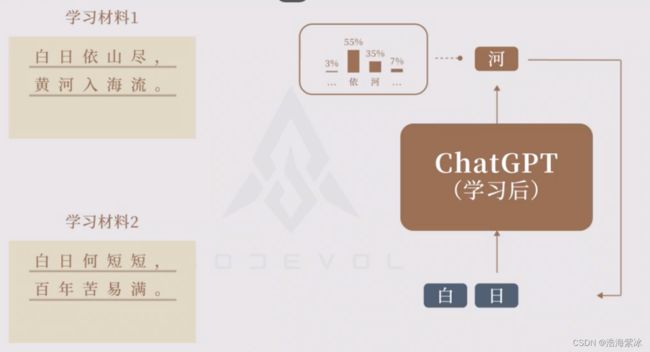
如果同时训练了“白日依山尽,黄河入海流”和“白日何短短,百年苦易满”,再遇到“白日”时,会怎么生成下一个字?
按照概率来抽样。有可能会生成“依”,也有可能生成“何”. 抽样结果随机性,每次回答不一样。
2.3长板
提问没见过怎么解决? 泛化。
训练的主要目的不是记忆,而是学习。不论面对哪个提问,ChatGPT都会被要求生成“白日依山尽的下一句是黄河入海流”,这会驱使 ChatGPT 去建构三个提问的通用规律,将自己的模型调整为适用于三个提问的通用模型。

| 对比 |
底层系统 |
输出形式 |
| 搜索引擎 |
数据库 |
查找搜索最接近的内容,检索信息。s |
| chatgpt |
生成模型 |
根据上文逐字生成,创造文本。 |
2.4短板
- 混淆信息,存在胡说八道的回答。
问“三体人为什么害怕大脸猫的威慑,62年都不敢殖民地球?”,这个问题并不存在,但又刚好符合它曾训练过的科幻材料中的规律,于是它就用科幻材料中所学到的规律开始混合捏造。
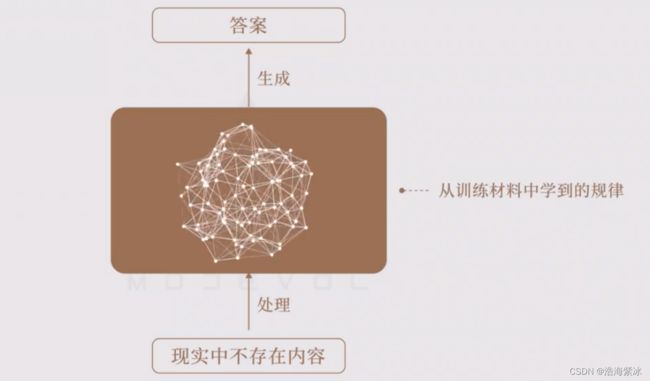
- 无法直接操作
内容无法增删改查,同一个模型生成,与数据库不一样。模型构建的规律很难理解,因此输出无法预测。更新效率,再次训练模型,更新回答结果。
- 回答不存在
- 依赖数据: 足够多、质量足够多的学习材料。
- 学不到规律: 材料少模型学不到规律。
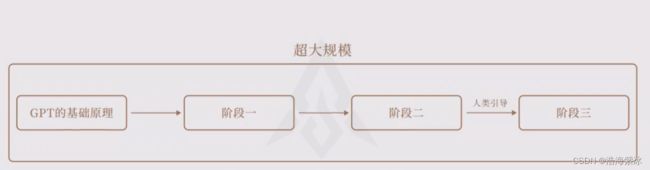
上面是gpt的基本原理,当扩展到超大规模后的效果,展现的能力。
3三步训练
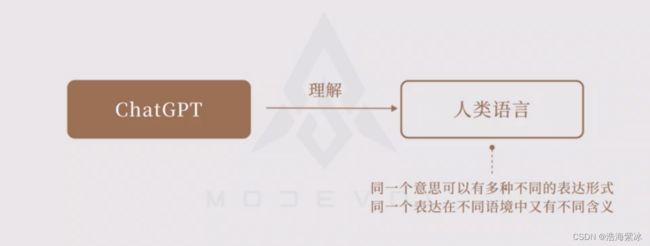
让机器理解人类语言的一大难点在于:同一个意思可以有多种不同的表达形式,可以用一个词,也可以用一段描述,而同一个表达在不同语境中又有不同含义。
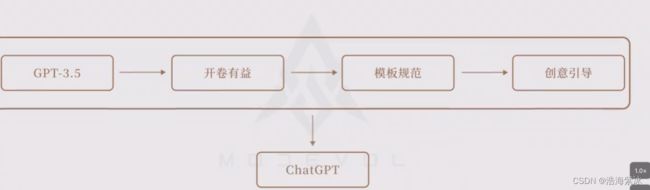
3.1开卷有益
GPT 的办法是:让模型看到尽可能多、尽可能丰富的语言范例(学习材料),使其有更多机会建构出能举一反三的语言规律,来应对无数从未见过的语言。
GPT历史开发版本
| OPenAI |
学习材料 |
参数 |
解释 |
| GPT-1 |
5GB |
1.17亿 |
2018.6,不如bert |
| GPT-2 |
40GB |
15亿 |
2019.2,反应平凡 |
| GPT-3 |
45TB |
1750亿 |
2020.5 ,维基百科...语言材料。同一个意思不同表达,编程语言,翻译。 |
它就像一只脑容量超级大的鹦鹉,已经听过了海量的电视节目,会不受控制地乱说,丑闻、脏话等全都有可能蹦出,难以跟人类合理对话。
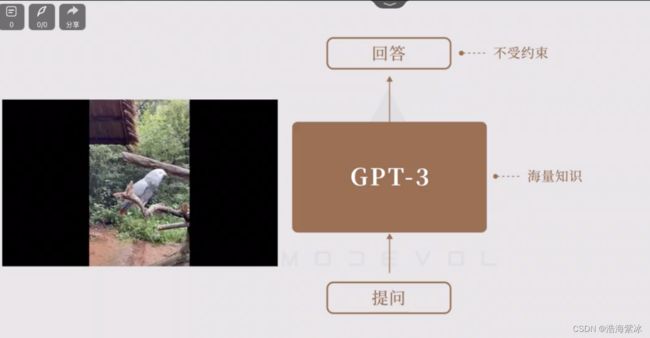
回答形式和内容不受约束,很难指挥控制,如何指挥chatgpt。
3.2 模板规范
不再用随便的互联网文本,而把人工专门写好的优质对话范例给GPT-3,让它再去做单字接龙,从而学习如何组织符合人类规范的回答。
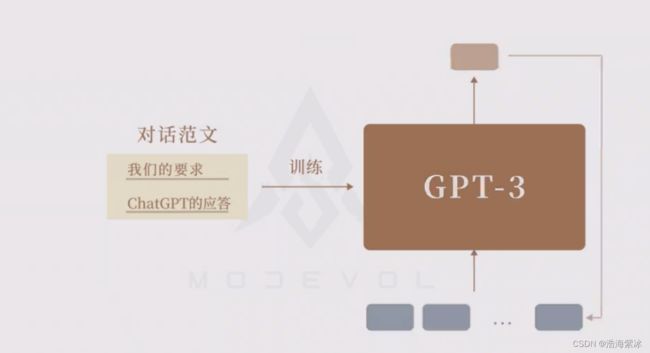
模板规范如下
答不知道:ChatGPT 无法联网,只知道训练数据中的新闻,那么当用户问到最新新闻时,就不应该让它接着续写,而要让它回复“不知道该信息”。
指出错误:当用户的提问有错误时,也不应该让它顺着瞎编,而要让它指出错误。
回答原因:当提问它是不是的问题时,我们不希望它只回复“是”或“不是”,还应把原因一起回复出来。因此也要给它提供这种“提问-回答-原因”的对话模板。
什么不该说:除了矫正对话方式之外,我们还要防止 GPT-3 补全和续写在“开卷有益”时所学到的有害内容,也就是要教它什么该说,什么不该说。
预训练好处,任何任务对话交给chatgpt
在“模板规范”阶段,我们可以将任何任务以对话的形式,教给 ChatGPT,不仅仅是聊天,还可以包括识别态度、归纳思想、拆分结构、仿写风格、润色、洗稿和比对等等。
因为不管什么任务,我们的要求和ChatGP的应答都是由文字所表达的,因此只要这个任务可以写成文字,我们就可以把该任务的要求+应答组合成一个对话范文,让 ChatGPT 通过单字接龙来学习。
经过这种“模版规范”后的超大模型,还掌握了两个意外能力:“理解”指令要求的能力和“理解”例子要求的能力。
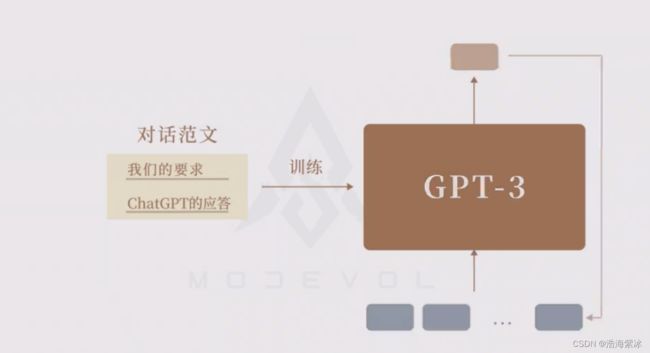
理解指令要求:根据不同对话学习,学会翻译能力。
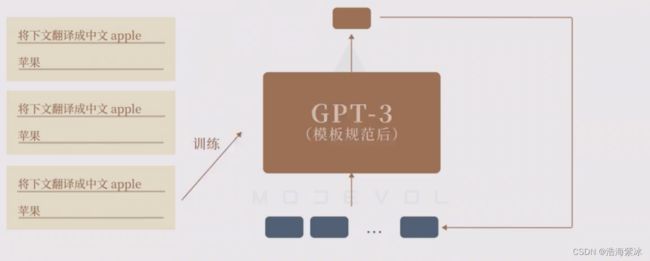
理解例子: 不知道如何提问,可以通过给它几个例子,明白提问的意图。通过例子来学习,语境内学习。
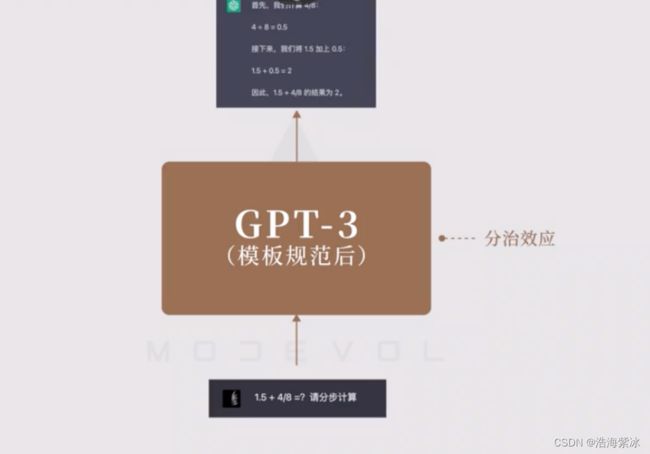
分治效应:
复杂问题,分步骤提问,最后能达到解决问题。超大模型出现“思维链”。
3.3创意模板
创造受限,经过“开卷有益”和“模版规范”这两个训练阶段后,超大单字接龙模型已经变得极其强大了。但“模板规范”的训练阶段也存在不足,那就是:可能导致 ChatGPT 的回答过于模板化,限制其创造力。
科学领域的问题有标准答案,可以用“模版规范”的训练方式来满足需求。但人文领域的问题没有标准答案,持续使用“模版规范”可能会让 ChatGPT 成为“高分范文的模板复刻机”,无法满足人们的需求。阅卷老师会给跳出模版的好文打高分一样,我们也希望能让 ChatGPT 提供一些超越模板、但仍符合人类对话模式和价值取向的创新性回答。
提问如何合规创造,提高 ChatGPT 的创新性呢?
奖励鹦鹉:可以联想一下鹦鹉是怎么被训练的。当我们教会鹦鹉一些基本对话后,就可以让鹦鹉自由发挥,有时鹦鹉会蹦出一些非常有意思的对话,这时我们就可以给它吃的,强化它在该方向的行为。
在训练 ChatGPT 的第三阶段,也是类似的过程。 不再要求它按照我们提供的对话范例做单字接龙,而是直接向它提问,再让它自由回答。如果回答得妙,就给予奖励,如果回答不佳,就降低奖励。然后利用这些人类评分去调整 ChatGPT 的模型。
在这种训练中,我们既不会用现有的模板来限制它的表现,又可以引导它创造出符合人类认可的回答。我把这一阶段称为“创意引导”。
ChatGPT 正是在 GPT-3.5 的基础上,先后经历了“开卷有益”、“模板规范”和“创意引导”,三个阶段的训练后,得到的生成语言模型。
对应机器学习模型

本节讲了 ChatGPT 的三个训练阶段:
1.“开卷有益”阶段:让ChatGPT对海量互联网文本做单字接龙,以扩充模型的词汇量、语言知识、世界的信息与知识。使ChatGPT从“哑巴鹦鹉”变成“脑容量超级大的懂王鹦鹉”。
2.“模板规范”阶段:让ChatGPT对优质对话范例做单字接龙,以规范回答的对话模式和对话内容。使ChatGPT变成“懂规矩的博学鹦鹉”。
3.“创意引导”阶段:让ChatGPT根据人类对它生成答案的好坏评分来调节模型,以引导它生成人类认可的创意回答。使ChatGPT变成“既懂规矩又会试探的博学鹦鹉”。

4.未来影响
从产品形态和技术创新上来看,ChatGPT 确实不够完善,核心模型结构来自2017年论文attention is you need。创意引导方法2020年论文。它的意义并不在于产品和创新,而在于完成了一次验证,让全球看到了大语言模型的可行性。
4.1应用价值
精通语言:既然是语言模型,那它自然精通语言,可以校对拼写、检查语法、转换句式、翻译外语,对语言组织规则的遵守已经超越了绝大多数人。真正有价值的地方在于:在精通语言的基础上,还能存储人类从古至今积累的世界知识。
语言处理需求:人类步入文明社会后,尽管已不必在野外求生,但仍然需要群体协作地创造知识、继承知识和应用知识,满足社会的需求,来维持自己的生计,而这三个环节全都是依靠语言来实现的。
语言处理繁重:过去人类使用的是口头和纸质文件,协作效率不高。可随着知识的爆炸式增长,语言处理的成本也相应地飙升。无论是医院、学校、法院、银行、出版社、研究所,都有繁重的信息分类、会议总结、格式排版、进程报告等工作。需要阅读和书写的内容数量和复杂度,不断超出人们的处理能力。
4.2社会影响
大语言模型所能改善的是:群体协作过程中创造、继承、应用知识时的语言处理效率。所以随着技术的发展,大语言模型对社会的影响范围将和当初电脑的影响范围一样,即全社会。
大语言模型相结合场景:
1.搜索引擎 结合:帮助用户精准寻找和筛选信息,比如,微软的 new bing。
2.笔记工具 结合:辅助阅读和写作,比如,notion,Flow us,wolai。
3.办公软件 结合:辅助文字处理、数据分析和演示制作,比如,office的下一步动作。
4.教育培训 结合:定制个人的学习计划和学习材料,全天家教。
5.开发工具 结合:辅助编写业务代码、调试纠错。
6.动画小说 结合:辅助小说配图、配乐。
7.客服系统 结合:7x24小时随便问,没有任何情绪。
8.视频会议 结合:多语翻译、会议记录与总结、谈话查找。
9.评论审核 结合:筛选评论、统计舆论、给出提醒。
10.行业顾问 结合:提供法律、医疗、健身等指导。
11.社交媒体 结合:帮助找到兴趣相投的用户和话题 。
12.视频娱乐 结合:个性化推荐音乐、电影、小说、动漫。
13游戏剧情 结合:让 NPC 给玩家带来更灵活的对话体验。
影响行业:新闻界、学术界、教育界、商业界和内容生产行业。
教育模式影响:现有人才培养模式挑战。
网络安全影响:回答的问题是否被泄露。
- 如何应对
人类的一大优势就在于善于利用工具:会先了解工具的优点和缺点,然后避开其缺点,将其优点用在适合的地方。
5.1克服抵触心理
工具无法取代人,只有会用工具的人取代不会工具的人。
5.2个人学习力
资料链接
- 资料来源:
【渐构】万字科普GPT4为何会颠覆现有工作流;为何你要关注微软Copilot、文心一言等大模型_哔哩哔哩_bilibili
2.up主:YJango