【LLM系列之GPT】GPT(Generative Pre-trained Transformer)生成式预训练模型
GPT模型简介
GPT(Generative Pre-trained Transformer)是由OpenAI公司开发的一系列自然语言处理模型,采用多层Transformer结构来预测下一个单词的概率分布,通过在大型文本语料库中学习到的语言模式来生成自然语言文本。GPT系列模型主要包括以下版本:
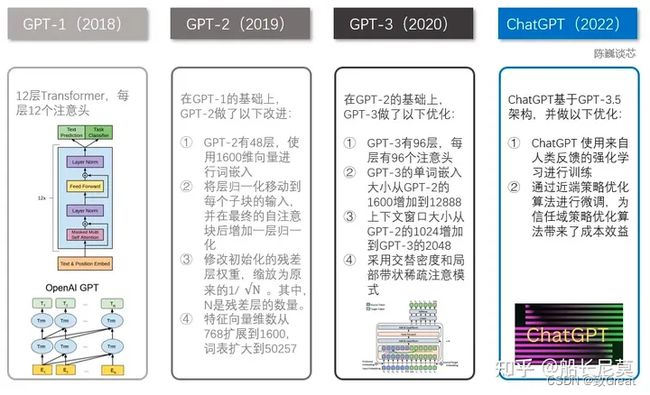
GPT-1
发布于2018年,参数规模为1.17亿。模型采用Transformer进行特征抽取,首次将Transformer应用于预训练语言模型。预训练的语料库包括英文维基百科、WebText等大规模文本数据。GPT-1是一个单向语言模型,即它只能根据上下文来生成接下来的文本。
GPT-2
发布于2019年,参数规模为15亿。与GPT-1相比,参数规模大了10倍以上,GPT-2生成的文本质量更高,更加自然和流畅,可以生成更长的文本段落。该模型在生成文本方面表现出色,能够编故事甚至生成假新闻,但由于其潜在的滥用风险,OpenAI公司选择不公开发布其完整参数和源代码。
GPT-3
发布于2020年,参数规模为1750亿。该模型在自然语言处理方面的表现十分出色,可以完成文本自动补全、将网页描述转换为相应代码、模仿人类叙事等多种任务。GPT-3可以通过少量的样本进行零样本学习,即在没有进行监督训练的情况下,可以生成合理的文本结果。
GPT-3的出现标志着语言模型的发展进入了一个新的阶段,其生成的文本质量已经接近人类水平,在众多领域具有应用潜力,隐藏的伦理安全问题需引起关注和重视。
GPT-4
发布于2023年。GPT-4是一个大型多模态模型,支持图像和文本输入,再输出文本回复。
虽然在许多场景中其表现与人类存在差距,但GPT-4在某些专业和学术测试中表现出拥有专业人士的水平:它通过了模拟美国律师资格考试,且成绩在应试者中排名前10%左右;在SAT阅读考试中得分排在前7%左右。
GPT系列模型核心知识点-人民邮电报

GPT-1模型
论文题目:《Improving Language Understanding by Generative Pre-Training》
论文链接:https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
模型结构
GPT 使用 Transformer 的 Decoder 结构,并对 Transformer Decoder 进行了一些改动,原本的 Decoder 包含了两个 Multi-Head Attention 结构,GPT 只保留了 Mask Multi-Head Attention,如下图所示:
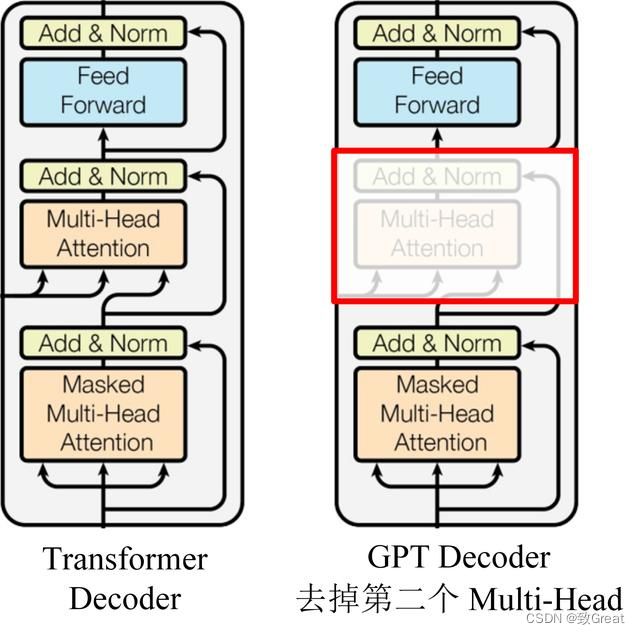
GPT 使用句子序列预测下一个单词,因此要采用 Mask Multi-Head Attention 对单词的下文遮挡,防止信息泄露。例如给定一个句子包含4个单词 [A, B, C, D],GPT 需要利用 A 预测 B,利用 [A, B] 预测 C,利用 [A, B, C] 预测 D。如果利用A 预测B的时候,需要将 [B, C, D] Mask 起来。
Mask 操作是在 Self-Attention 进行 Softmax 之前进行的,具体做法是将要 Mask 的位置用一个无穷小的数替换 -inf,然后再 Softmax,如下图所示。
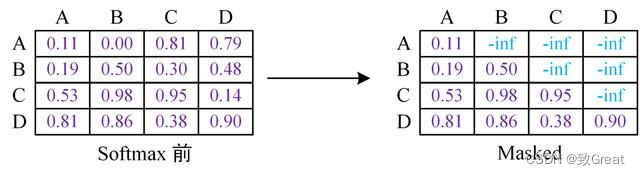
Softmax 之前需要 Mask
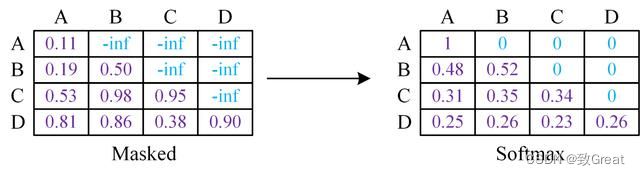
GPT Softmax
可以看到,经过 Mask 和 Softmax 之后,当 GPT 根据单词 A 预测单词 B 时,只能使用单词 A 的信息,根据 [A, B] 预测单词 C 时只能使用单词 A, B 的信息。这样就可以防止信息泄露。
下图是 GPT 整体模型图,其中包含了 12 个 Decoder。

- 使用字节对编码(byte pair encoding,BPE),共有40000个字节对;
- 词编码的长度为768;
- 位置编码也需要学习;
- 12层的transformer,每个transformer块有12个头;
- 位置编码的长度是3072;
- Attention, 残差,Dropout等机制用来进行正则化,drop比例为0.1 ; 激活函数为GLEU;
- 训练的batchsize为64,学习率为2.5e-4 ,序列长度为512,序列epoch为100;
- 模型参数数量为1.17亿。
无监督预训练
无监督的预训练(Pretraining),具体来说,给定一个未标注的预料库 U = { u 1 , u 2 , . . . , u n } U=\{u_{1},u_{2},...,u_{n}\} U={u1,u2,...,un},我们训练一个语言模型,对参数进行最大(对数)似然估计:
L 1 ( U ) = ∑ i l o g P ( u i ∣ u 1 , . . . , u k − 1 ; Θ ) L_{1}(U)=\sum_{i}log P(u_{i}|u_{1},...,u_{k-1};\Theta) L1(U)=i∑logP(ui∣u1,...,uk−1;Θ)
其中,k 是上下文窗口的大小,P 为条件概率, Θ \Theta Θ为条件概率的参数,参数更新采用随机梯度下降(GPT实验实现部分具体用的是Adam优化器,并不是原始的随机梯度下降,Adam 优化器的学习率使用了退火策略)。
训练的过程也非常简单,就是将 n 个词的词嵌入 W e W_{e} We加上位置嵌入 W p W_{p} Wp,然后输入到 Transformer 中,n 个输出分别预测该位置的下一个词
可以看到 GPT 是一个单向的模型,GPT 的输入用 h 0 h_{0} h0 表示,0代表的是输入层, h 0 h_{0} h0的计算公式如下
h 0 = U W e + W p h_{0}=UW_{e}+W_{p} h0=UWe+Wp
W e W_{e} We是token的Embedding矩阵, W p W_{p} Wp是位置编码的 Embedding 矩阵。用 voc 表示词汇表大小,pos 表示最长的句子长度,dim 表示 Embedding 维度,则 W p W_{p} Wp是一个 pos×dim 的矩阵, W e W_{e} We是一个 voc×dim 的矩阵。在GPT中,作者对position embedding矩阵进行随机初始化,并让模型自己学习,而不是采用正弦余弦函数进行计算。
得到输入 h 0 h_{0} h0 之后,需要将 h 0 h_{0} h0 依次传入 GPT 的所有 Transformer Decoder 里,最终得到 h n h_{n} hn。
h l = t r a n s f o r m e r _ b l o c k ( h l − 1 ) , ∀ l ∈ [ 1 , n ] h_{l}=transformer\_block(h_{l-1}), \forall l \in [1,n] hl=transformer_block(hl−1),∀l∈[1,n]
n 为神经网络的层数。最后得到 h n h_{n} hn再预测下个单词的概率。
P ( u ) = s o f t m a x ( h n W e T ) P(u)=softmax(h_{n}W_{e}^T) P(u)=softmax(hnWeT)
有监督微调
预训练之后,我们还需要针对特定任务进行 Fine-Tuning。假设监督数据集合 C C C的输入 X X X是一个序列 x 1 , x 2 , . . . , x m x^1,x^2,...,x^m x1,x2,...,xm,输出是一个分类y的标签 ,比如情感分类任务
我们把 x 1 , . . , x m x^1,..,x^m x1,..,xm输入 Transformer 模型,得到最上层最后一个时刻的输出 h l m h_{l}^m hlm,将其通过我们新增的一个 Softmax 层(参数为 W y W_{y} Wy)进行分类,最后用交叉熵计算损失,从而根据标准数据调整 Transformer 的参数以及 Softmax 的参数 W y W_{y} Wy。这等价于最大似然估计:
P ( y ∣ x 1 , . . . , x m ) = s o f t m a x ( h l m W y ) P(y|x^1,...,x^m)=softmax(h_{l}^mW_{y}) P(y∣x1,...,xm)=softmax(hlmWy)
W y W_{y} Wy表示预测输出时的参数,微调时候需要最大化以下函数:
L 2 ( C ) = ∑ x , y l o g P ( y ∣ x 1 , . . , x m ) L_{2}(C)=\sum_{x,y}log P(y|x^1,..,x^m) L2(C)=x,y∑logP(y∣x1,..,xm)
正常来说,我们应该调整参数使得 L 2 L_{2} L2最大,但是为了提高训练速度和模型的泛化能力,我们使用 Multi-Task Learning,GPT 在微调的时候也考虑预训练的损失函数,同时让它最大似然 L 1 L_{1} L1和 L 2 L_{2} L2
L 3 ( C ) = L 2 ( C ) + λ × L 1 ( C ) L_{3}(C)=L_{2}(C)+\lambda \times L_{1}(C) L3(C)=L2(C)+λ×L1(C)
这里使用的 L 1 L_{1} L1还是之前语言模型的损失(似然),但是使用的数据不是前面无监督的数据 U U U,而是使用当前任务的数据 C C C,而且只使用其中的 X X X,而不需要标签y。

针对不同任务,需要简单修改下输入数据的格式,例如对于相似度计算或问答,输入是两个序列,为了能够使用 GPT,我们需要一些特殊的技巧把两个输入序列变成一个输入序列,如下图,可以发现,对这些任务的微调主要是新增线性层的参数以及起始符、结束符和分隔符三种特殊符号的向量参数。
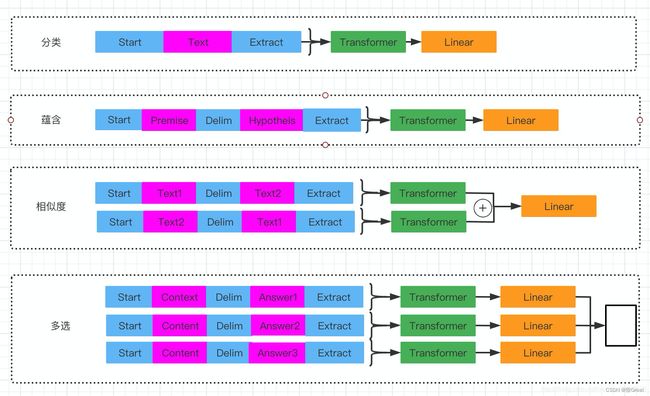
- Classification:对于分类问题,不需要做什么修改
- 文本蕴涵(Entailment):对于文本蕴涵任务,作者用一个“$”符号将文本和假设进行拼接,并在拼接后的文本前后加入开始符“start”和结束符“end”,然后将拼接后的文本直接传入预训练的语言模型,在模型再接一层线性变换和softmax即可。
- 文本相似度(Similarity):对于文本相似度任务,由于相似度不需要考虑两个句子的顺序关系,因此,为了反映这一点,作者将两个句子分别与另一个句子进行拼接,中间用$进行隔开,并且前后还是加上起始和结束符,然后分别将拼接后的两个长句子传入Transformer,最后分别得到两个句子的向量 h l m h_{l}^{m} hlm,将这两个向量进行元素相加,然后再接如线性层和softmax层。
- Multiple-Choice:对于问答和常识推理任务,首先将背景信息与问题进行拼接,然后再将拼接后的文本依次与每个答案进行拼接,最后依次传入Transformer模型,最后接一层线性层得多每个输入的预测值。
subword算法
原理
这里说一下GPT里面使用的subword算法:BPE(byte pair encoding,字节对编码)。作者使用BPE构建模型词表,这一点在GPT论文中被一句话带过,在GPT2论文中有较为详细的介绍为什么使用BPE。简单来说就是对于英文来说,单词特别多,使用word-level级别的词表可能会出现OOV(out of vocabulary)问题,也就是说可能会出现inference的时候某些单词不在词表中的情况。而使用byte-level字符级别的词表,英文只有26个字母,不会出现OOV问题,但是把每个单词拆成一个个字符会丧失语义信息,导致模型的性能不如使用word-level词表的模型。
为了解决这个问题,subword算法被提出,它是word-level和byte-level的折中,将单词拆成一个个子串,比如:greatest拆成 great 和 ##est 。
BPE(字节对)编码或二元编码是一种简单的数据压缩形式,其中最常见的一对连续字节数据被替换为该数据中不存在的字节[2]。 后期使用时需要一个替换表来重建原始数据。OpenAI GPT-2 与Facebook RoBERTa均采用此方法构建subword vector.
- 优点
可以有效地平衡词汇表大小和步数(编码句子所需的token数量)。
- 缺点
基于贪婪和确定的符号替换,不能提供带概率的多个分片结果。
算法
- 准备足够大的训练语料
- 确定期望的subword词表大小
- 将单词拆分为字符序列并在末尾添加后缀“ ”,统计单词频率。 本阶段的subword的粒度是字符。 例如,“ low”的频率为5,那么我们将其改写为“ l o w ”:5
- 统计每一个连续字节对的出现频率,选择最高频者合并成新的subword
- 重复第4步直到达到第2步设定的subword词表大小或下一个最高频的字节对出现频率为1
- 停止符"“的意义在于表示subword是词后缀。举例来说:“st"字词不加”“可以出现在词首如"st ar”,加了”“表明改字词位于词尾,如"wide st”,二者意义截然不同。
每次合并后词表可能出现3种变化:
- +1,表明加入合并后的新字词,同时原来的2个子词还保留(2个字词不是完全同时连续出现)
- +0,表明加入合并后的新字词,同时原来的2个子词中一个保留,一个被消解(一个字词完全随着另一个字词的出现而紧跟着出现)
- -1,表明加入合并后的新字词,同时原来的2个子词都被消解(2个字词同时连续出现) 实际上,随着合并的次数增加,词表大小通常先增加后减小。
例子
输入:
{'l o w ': 5, 'l o w e r ': 2, 'n e w e s t ': 6, 'w i d e s t ': 3}
Iter 1, 最高频连续字节对"e"和"s"出现了6+3=9次,合并成"es"。输出:
{'l o w ': 5, 'l o w e r ': 2, 'n e w es t ': 6, 'w i d es t ': 3}
Iter 2, 最高频连续字节对"es"和"t"出现了6+3=9次, 合并成"est"。输出:
{'l o w ': 5, 'l o w e r ': 2, 'n e w est ': 6, 'w i d est ': 3}
Iter 3, 以此类推,最高频连续字节对为"est"和"" 输出:
{'l o w ': 5, 'l o w e r ': 2, 'n e w est': 6, 'w i d est': 3}
……
Iter n, 继续迭代直到达到预设的subword词表大小或下一个最高频的字节对出现频率为1
GPT特点
优点
- 特征抽取器使用了强大的 Transformer,能够捕捉到更长的记忆信息,且较传统的 RNN 更易于并行化;
- 方便的两阶段式模型,先预训练一个通用的模型,然后在各个子任务上进行微调,减少了传统方法需要针对各个任务定制设计模型的麻烦。
缺点
- GPT 最大的问题就是传统的语言模型是单向的;我们根据之前的历史来预测当前词。但是我们不能利用后面的信息。比如句子 The animal didn’t cross the street because it was too tired。我们在编码 it 的语义的时候需要同时利用前后的信息,因为在这个句子中,it 可能指代 animal 也可能指代 street。根据 tired,我们推断它指代的是 animal。但是如果把 tired 改成 wide,那么 it 就是指代 street 了。Transformer 的 Self-Attention 理论上是可以同时关注到这两个词的,但是根据前面的介绍,为了使用 Transformer 学习语言模型,必须用 Mask 来让它看不到未来的信息,所以它也不能解决这个问题。
GPT 与 ELMo,BERT的区别
GPT 与 ELMo 的区别:
-
模型架构不同:ELMo 是浅层的双向 RNN;GPT 是多层的 Transformer encoder
-
针对下游任务的处理不同:ELMo 将词嵌入添加到特定任务中,作为附加功能;GPT 则针对所有任务微调相同的基本模型
GPT 与 BERT 的区别
-
预训练:GPT 预训练的方式和传统的语言模型一样,通过上文,预测下一个单词;GPT 预训练的方式是使用 Mask LM,可以同时通过上文和下文预测单词。例如给定一个句子 u 1 , u 2 , . . . , u n u_{1},u_{2},...,u_{n} u1,u2,...,un,GPT在预测单词 u i u_{i} ui的时候只会利用 u 1 , u 2 , . . . u i − 1 u_{1},u_{2},...u_{i-1} u1,u2,...ui−1的信息。而BERT会同时利用 u 1 , u 2 , . . . , u i − 1 , u i + 1 , . . . , u n u_{1},u_{2},...,u_{i-1},u_{i+1},...,u_{n} u1,u2,...,ui−1,ui+1,...,un的信息。
-
模型效果: GPT 因为采用了传统语言模型所以更加适合用于自然语言生成类的任务 (NLG),因为这些任务通常是根据当前信息生成下一刻的信息。而 BERT 更适合用于自然语言理解任务 (NLU)。
-
模型结构: 模型结构:GPT 采用了 Transformer 的 Decoder,而 BERT 采用了 Transformer 的 Encoder。GPT 使用 Decoder 中的 Mask Multi-Head Attention 结构,在使用 u 1 , u 2 , . . , u i − 1 u_{1},u_{2},..,u_{i-1} u1,u2,..,ui−1预测单词 u i u_{i} ui的时候,会将 u i u_{i} ui之后的单词 Mask 掉。
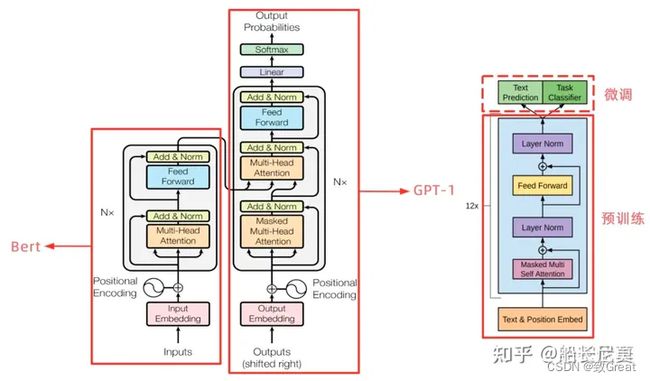
这张图快糊了…
实验结果
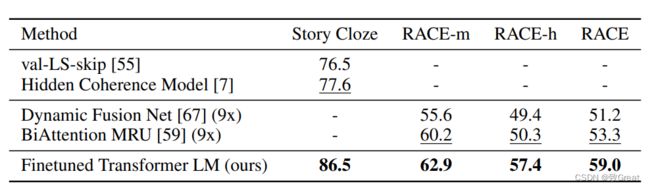
推理任务的实验结果:

问题回答和常识推理的实验结果:
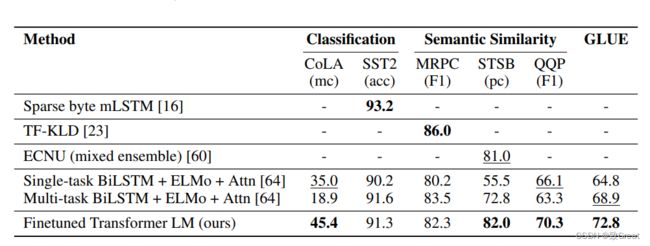
语义相似度和分类的实验结果:
下图左边展示的预训练语言模型中 Transformer 层数对结果的影响;右图展示了预训练不用 Fine-tuning 而直接使用预训练网络来解决多种类型任务的结果,横坐标为更新次数,纵坐标为模型相对表现:

参考资料
- GPT系列模型核心知识点
- NLP系列之预训练模型(三):GPT
- 深入理解NLP Subword算法:BPE、WordPiece、ULM
- GPT-1/GPT-2/GPT-3/GPT-3.5 语言模型详细介绍
- 预训练语言模型之GPT-1,GPT-2和GPT-3
- 【Pre-Training】GPT:通过生成式预训练改善语言理解
- 【自然语言处理】【大模型】BLOOM模型结构源码解析(张量并行版)