ANTLR实战
ANTLR(Another Tool for Language Recognition)是目前非常活跃的语法生成工具,用Java语言编写,基于LL(∗)解析方式,使用自上而下的递归下降分析方法。ANTLR可以用来产生词法分析器、语法分析器和树状分析器(Tree Parser)等各个模块,其文法定义使用类似EBNF(Extended Backus-Naur Form)的方式,简洁直观。ANTLR本身使用switch-case逻辑来匹配字符(Token),形成记号序列流。从20世纪80年代末发展至今,ANTLR已经升级到ANTLR 4,并形成了较为成熟的生态链。
使用Antlr4创建一个简单计算器
- 使用idea创建一个Maven项目,路径:File -> New -> Project… -> Maven
- 在项目的pom文件中添加antlr4依赖
<dependency>
<groupId>org.antlrgroupId>
<artifactId>antlr4-runtimeartifactId>
<version>4.9.2version>
dependency>
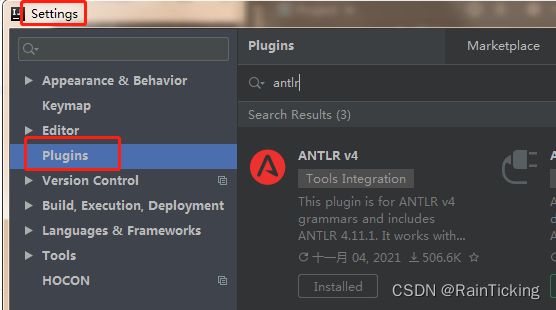
- 安装antlr插件, 路径:File -> Settings -> Plugins
- 创建计算器文法文件Calculator.g4
grammar Calculator;
prog : stat+;
stat:
expr NEWLINE # print
| ID '=' expr NEWLINE # assign
| NEWLINE # blank
;
expr:
expr op=('*'|'/') expr # MulDiv
| expr op=('+'|'-') expr # AddSub
| INT # int
| ID # id
| '(' expr ')' # parenthese
;
MUL : '*' ;
DIV : '/' ;
ADD : '+' ;
SUB : '-' ;
ID : [a-zA-Z]+ ;
INT : [0-9]+ ;
NEWLINE :'\r'? '\n' ;
DELIMITER : ';';
WS : [ \t]+ -> skip;
- 检验文法是否正确,右击首个规则(prog:stat+;),选择Test Rule prog,在ANTLR Preview的输入框中输入计算公式,右侧会自动生成解析树等。

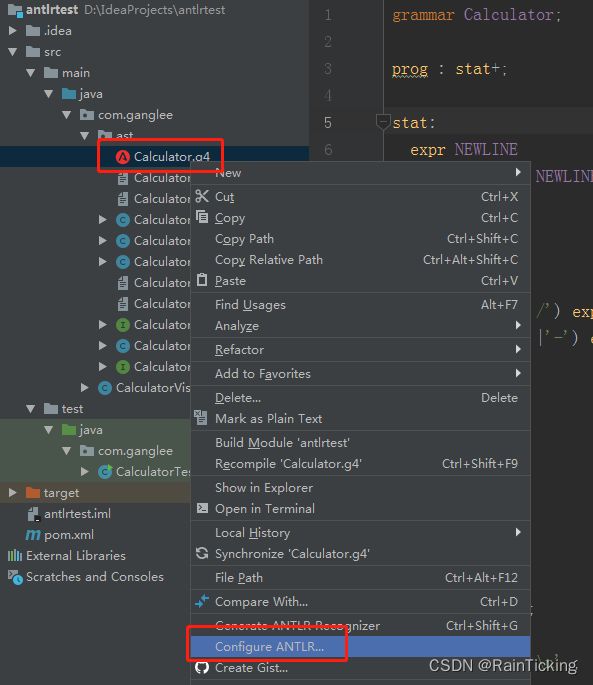
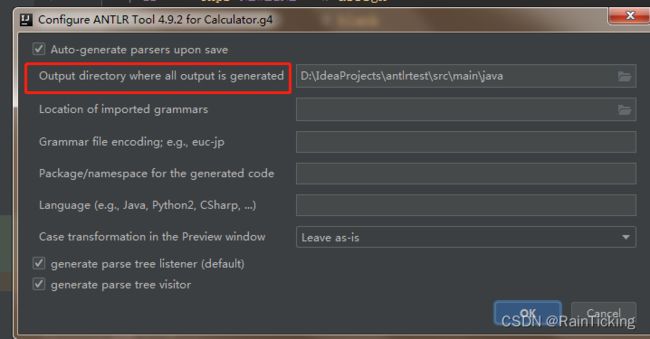
- 右击Calculator.g4,点击Configure ANTLR…,在输出路径中选择合适的路径,默认在主项目下创建gen文件夹并生成Antlr程序文件。
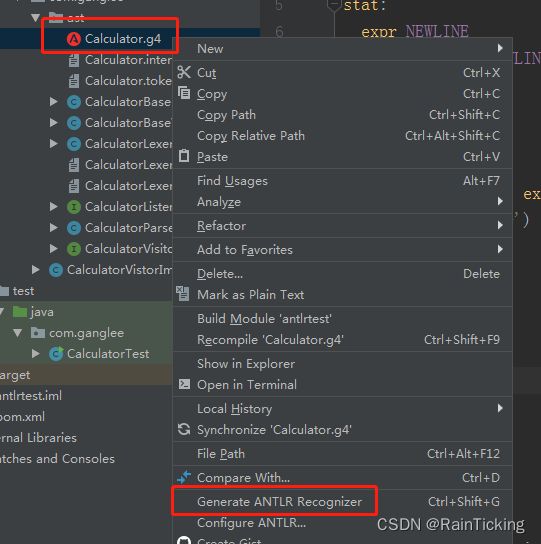
- 右击Calculator.g4,点击Generate ANTLR Recognizer,生成Antlr程序文件。
- 新建一个实现类CalculatorVistorImp继承CalculatorBaseVisitor,实现对抽象语法树节点的遍历,实现计算的功能。
package com.ganglee;
import com.ganglee.ast.CalculatorBaseVisitor;
import com.ganglee.ast.CalculatorParser;
import java.util.HashMap;
public class CalculatorVistorImp extends CalculatorBaseVisitor<Integer> {
//存储变量的值
private HashMap<String, Integer> variable = new HashMap<>();
public CalculatorVistorImp() {
this.variable = variable;
}
//遇到print节点,计算结果,打印出来
@Override
public Integer visitPrint(CalculatorParser.PrintContext ctx) {
Integer result = ctx.expr().accept(this);
System.out.println(result);
return null;
}
//分别获取expr节点的值,并计算乘除结果
@Override
public Integer visitMulDiv(CalculatorParser.MulDivContext ctx) {
Integer param1 = ctx.expr(0).accept(this);
Integer param2 = ctx.expr(1).accept(this);
if(ctx.op.getType() == CalculatorParser.MUL){
return param1 * param2;
}
if(ctx.op.getType() == CalculatorParser.DIV){
return param1 / param2;
}
return null;
}
//分别获取expr节点的值,并计算结果
@Override
public Integer visitAddSub(CalculatorParser.AddSubContext ctx) {
Integer param1 = ctx.expr(0).accept(this);
Integer param2 = ctx.expr(1).accept(this);
if(ctx.op.getType() == CalculatorParser.ADD){
return param1 + param2;
}
if(ctx.op.getType() == CalculatorParser.SUB){
return param1 - param2;
}
return null;
}
//当遇到Id时从变量表获取数据
@Override
public Integer visitId(CalculatorParser.IdContext ctx) {
return variable.get(ctx.getText());
}
//当遇到Int节点时直接返回数据
@Override
public Integer visitInt(CalculatorParser.IntContext ctx) {
return Integer.parseInt(ctx.getText());
}
//当遇到赋值语句时,获取右边expr的值存储到变量表中
@Override
public Integer visitAssign(CalculatorParser.AssignContext ctx) {
String name = ctx.ID().getText();
Integer value = ctx.expr().accept(this);
variable.put(name, value);
return super.visitAssign(ctx);
}
//当遇到括号,返回括号内expr的结果
@Override
public Integer visitParenthese(CalculatorParser.ParentheseContext ctx) {
Integer integer = ctx.expr().accept(this);
return integer;
}
}
- 创建一个测试类,执行后检验计算结果。
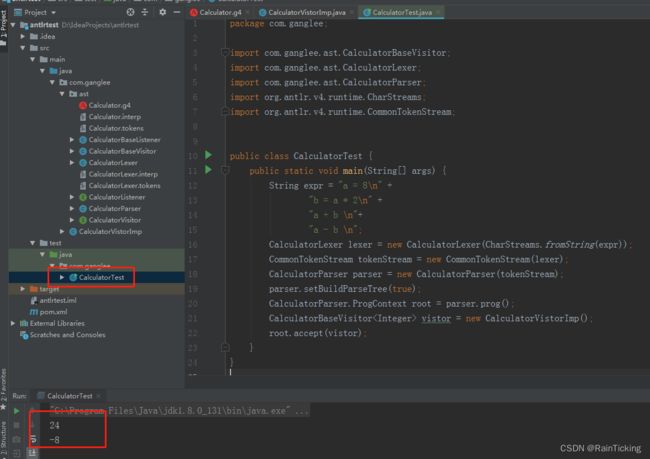
package com.ganglee;
import com.ganglee.ast.CalculatorBaseVisitor;
import com.ganglee.ast.CalculatorLexer;
import com.ganglee.ast.CalculatorParser;
import org.antlr.v4.runtime.CharStreams;
import org.antlr.v4.runtime.CommonTokenStream;
public class CalculatorTest {
public static void main(String[] args) {
String expr = "a = 8\n" +
"b = a * 2\n" +
"a + b \n"+
"a - b \n";
CalculatorLexer lexer = new CalculatorLexer(CharStreams.fromString(expr));
CommonTokenStream tokenStream = new CommonTokenStream(lexer);
CalculatorParser parser = new CalculatorParser(tokenStream);
parser.setBuildParseTree(true);
CalculatorParser.ProgContext root = parser.prog();
CalculatorBaseVisitor<Integer> vistor = new CalculatorVistorImp();
root.accept(vistor);
}
}
探索规则生成的节点类
- 计算器语法中定义了三条语法规则:prog, stat, expr。antlr4会为每条规则生成一个ParserRuleContext的子类。如果这个语法规则添加了产生式标签(“#”后面的标签),那么为每个标签也生成一个ParserRuleContext的子类,这些类之间的关系,如下图所示

各个类之间的继承关系如下图所示:
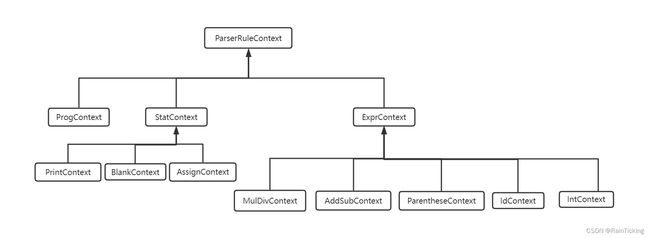
- 这些类是如何联系起来的呢?以 prog 规则为例,它对应 ProgContext 类。因为 prog 规则 可以包含多个 stat 规则,所以它必须提供访问子节点 StatContext 的方法。
public class CalculatorParser extends Parser {
public static class ProgContext extends ParserRuleContext {
//返回子节点stat列表
public List<StatContext> stat() {
return getRuleContexts(StatContext.class);
}
//返回第几个stat规则
public StatContext stat(int i) {
return getRuleContext(StatContext.class,i);
}
public ProgContext(ParserRuleContext parent, int invokingState) {
super(parent, invokingState);
}
//返回该规则的id号, RULE_prog是一个常量
@Override public int getRuleIndex() { return RULE_prog; }
@Override
public void enterRule(ParseTreeListener listener) {
if ( listener instanceof CalculatorListener ) ((CalculatorListener)listener).enterProg(this);
}
@Override
public void exitRule(ParseTreeListener listener) {
if ( listener instanceof CalculatorListener ) ((CalculatorListener)listener).exitProg(this);
}
@Override
public <T> T accept(ParseTreeVisitor<? extends T> visitor) {
if ( visitor instanceof CalculatorVisitor ) return ((CalculatorVisitor<? extends T>)visitor).visitProg(this);
else return visitor.visitChildren(this);
}
}
}
- 继续看stat规则,它对应着StateContext类。因为它为每种情况添加了标签,所以也为每个标签生成了对应的类,这些类都是StateContext的子类。
public class CalculatorParser extends Parser {
public static class StatContext extends ParserRuleContext {
public StatContext(ParserRuleContext parent, int invokingState) {
super(parent, invokingState);
}
//返回规则的id
@Override
public int getRuleIndex() { return RULE_stat; }
public StatContext() { }
public void copyFrom(StatContext ctx) {
super.copyFrom(ctx);
}
}
public static class PrintContext extends StatContext {
//返回expr节点
public ExprContext expr() {
return getRuleContext(ExprContext.class,0);
}
//返回NEWLINE叶子节点
public TerminalNode NEWLINE() { return getToken(CalculatorParser.NEWLINE, 0); }
public PrintContext(StatContext ctx) { copyFrom(ctx); }
@Override
public void enterRule(ParseTreeListener listener) {
if ( listener instanceof CalculatorListener ) ((CalculatorListener)listener).enterPrint(this);
}
@Override
public void exitRule(ParseTreeListener listener) {
if ( listener instanceof CalculatorListener ) ((CalculatorListener)listener).exitPrint(this);
}
//accept方法调用了visitor的visitPrint方法
@Override
public <T> T accept(ParseTreeVisitor<? extends T> visitor) {
if ( visitor instanceof CalculatorVisitor ) return ((CalculatorVisitor<? extends T>)visitor).visitPrint(this);
else return visitor.visitChildren(this);
}
//BlankContext AssignContext 原理类似
}
public static class BlankContext extends StatContext {
public TerminalNode NEWLINE() { return getToken(CalculatorParser.NEWLINE, 0); }
public BlankContext(StatContext ctx) { copyFrom(ctx); }
@Override
public void enterRule(ParseTreeListener listener) {
if ( listener instanceof CalculatorListener ) ((CalculatorListener)listener).enterBlank(this);
}
@Override
public void exitRule(ParseTreeListener listener) {
if ( listener instanceof CalculatorListener ) ((CalculatorListener)listener).exitBlank(this);
}
//accpet方法调用了visitor的visitBlank方法。
@Override
public <T> T accept(ParseTreeVisitor<? extends T> visitor) {
if ( visitor instanceof CalculatorVisitor ) return ((CalculatorVisitor<? extends T>)visitor).visitBlank(this);
else return visitor.visitChildren(this);
}
}
}
- 这里只分析了prog 和stat规则, 其余的规则的原理是一样的。
节点类的访问方法
上面生成的节点类,都是ParserRuleContext的子类,都实现accept方法。每个类实现方法都不一样,比如ProgContext类,它的accept方法调用了访问者的visitProg方法。而PrintContext类的accept方法对应于访问者的visitPrint方法。
CalculatorBaseVisitor提供了访问不同节点的方法,默认实现都是调用visitChildren方法。它的泛型T表示返回的结果类型。使用者一般继承CaculatorBaseVisitor类,复写一些方法,来实现自定义的功能(比如上面的四则运算的例子)
public class CalculatorBaseVisitor<T> extends AbstractParseTreeVisitor<T> implements CalculatorVisitor<T> {
/**
* {@inheritDoc}
*
* The default implementation returns the result of calling
* {@link #visitChildren} on {@code ctx}.
*/
@Override public T visitProg(CalculatorParser.ProgContext ctx) { return visitChildren(ctx); }
/**
* {@inheritDoc}
*
* The default implementation returns the result of calling
* {@link #visitChildren} on {@code ctx}.
*/
@Override public T visitPrint(CalculatorParser.PrintContext ctx) { return visitChildren(ctx); }
/**
* {@inheritDoc}
*
* The default implementation returns the result of calling
* {@link #visitChildren} on {@code ctx}.
*/
@Override public T visitAssign(CalculatorParser.AssignContext ctx) { return visitChildren(ctx); }
/**
* {@inheritDoc}
*
* The default implementation returns the result of calling
* {@link #visitChildren} on {@code ctx}.
*/
@Override public T visitBlank(CalculatorParser.BlankContext ctx) { return visitChildren(ctx); }
/**
* {@inheritDoc}
*
* The default implementation returns the result of calling
* {@link #visitChildren} on {@code ctx}.
*/
@Override public T visitMulDiv(CalculatorParser.MulDivContext ctx) { return visitChildren(ctx); }
/**
* {@inheritDoc}
*
* The default implementation returns the result of calling
* {@link #visitChildren} on {@code ctx}.
*/
@Override public T visitAddSub(CalculatorParser.AddSubContext ctx) { return visitChildren(ctx); }
/**
* {@inheritDoc}
*
* The default implementation returns the result of calling
* {@link #visitChildren} on {@code ctx}.
*/
@Override public T visitParenthese(CalculatorParser.ParentheseContext ctx) { return visitChildren(ctx); }
/**
* {@inheritDoc}
*
* The default implementation returns the result of calling
* {@link #visitChildren} on {@code ctx}.
*/
@Override public T visitId(CalculatorParser.IdContext ctx) { return visitChildren(ctx); }
/**
* {@inheritDoc}
*
* The default implementation returns the result of calling
* {@link #visitChildren} on {@code ctx}.
*/
@Override public T visitInt(CalculatorParser.IntContext ctx) { return visitChildren(ctx); }
}
Antlr4基础类
- antlr4会将语句解析成一棵树,让我们先来了解一下树的节点,树的节点主要分为叶子节点和非叶子节点两类,下面是Antlr4文件夹中的类和接口
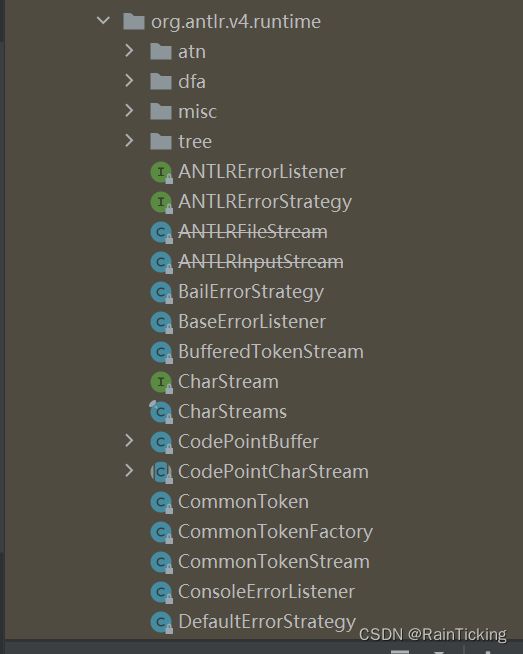

- 再看一下类的继承关系
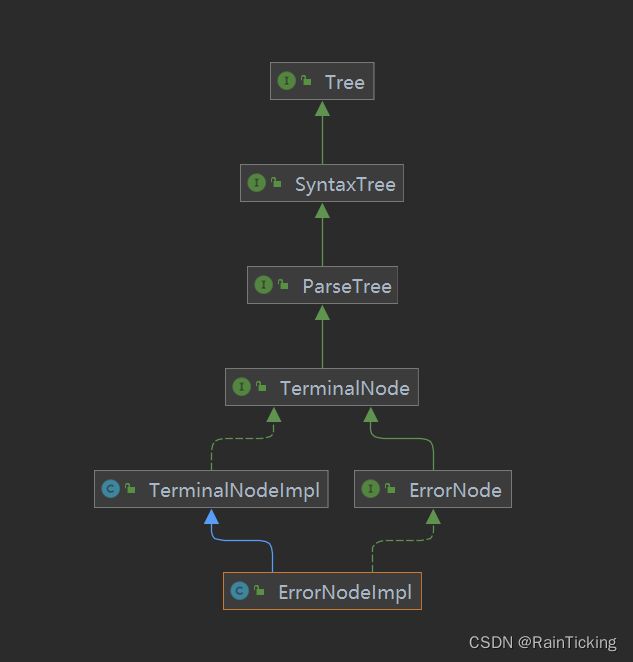
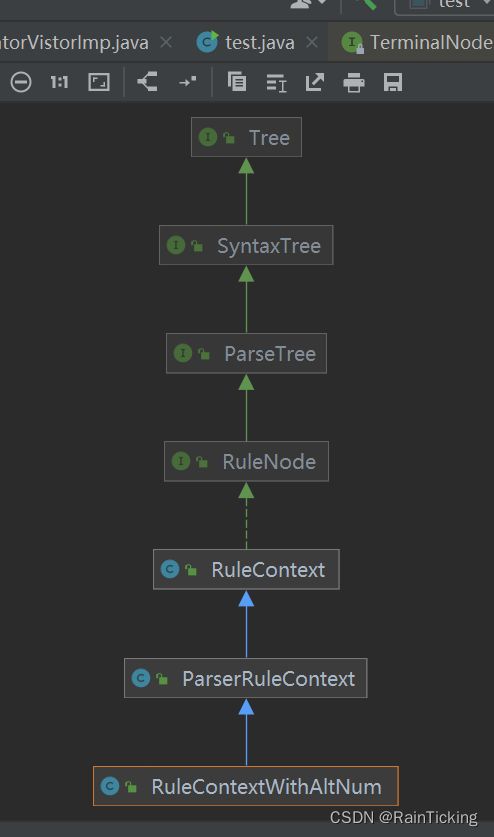
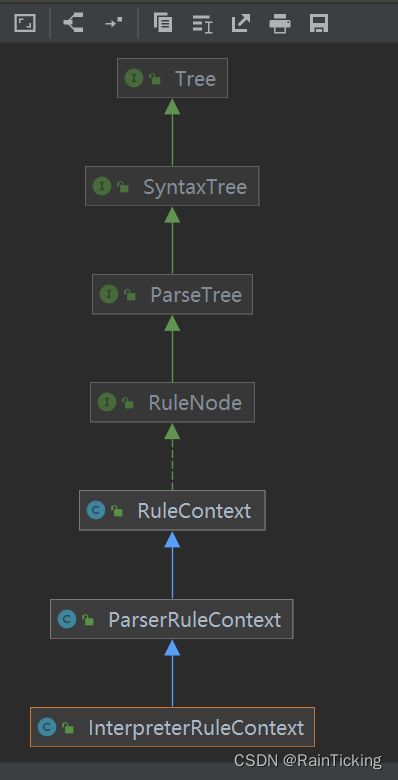
- 以上各个类的解释如下:
Tree 接口,是所有节点的接口。它定义了获取父节点,子节点,节点数据的接口
SyntaxTree 接口,增加了获取当前节点涉及到的分词范围(antlr4会先将语句分词,然后才将分词解析成树)
ParserTree 接口,增加了支持Visitor遍历树的接口
TerminalNode 接口,表示叶子节点,增加了获取当前节点的分词(叶子节点表示字符常量,或者在antlr4为文件中的lexer)
TerminalNodeImpl 类, 实现了TerminalNode接口,表示正常的叶子节点
ErrorNodeImpl类,继承TerminalNodeImpl类,表示错误的叶子节点
RuleNode 接口,非叶子节点,表示一个句子的语法, 对应antlr4文件中的parser rule
RuleContext 类,实现了RuleNode 接口
ParserRuleContext 类,在RuleContext 的基础上实现了查询子节点的方法,并且支持Listener遍历
InterpreterRuleContext 和RuleContextWithAltNum 是用于特殊用途的
在使用的过程中,我们主要使用 TerminalNodeImpl(叶子节点)和 ParserRuleContext(非叶子节点)两个类
Visitor遍历类
ANTLR 4除能够自动构建语法分析树外,还支持生成基于监听器(Listener)模式和访问者(Visitor)模式的树遍历器。访问者模式遍历语法树是一种更加灵活的方式,可以避免在文法文件中嵌入烦琐的动作(Action),使解析与应用代码分离,这样不但文法的定义更加简洁清晰,而且可以在不重新编译生成语法分析器的情况下复用相同的语法,甚至能够采用不同的程序语言来实现这些动作。
ANTLR 4提供的visitor遍历方式是典型的访问者设计模式。访问者为每个不同类型的节点,实现不同的访问方法。而每个节点实现统一的访问入口。ParseTree接口代表着节点,它的统一访问入口是accept方法,T accept(ParseTreeVisitor visitor);
public interface ParseTree extends SyntaxTree {
ParseTree getParent();
ParseTree getChild(int i);
void setParent(RuleContext parent);
<T> T accept(ParseTreeVisitor<? extends T> visitor);
String getText();
String toStringTree(Parser parser);
}
ParseTree的子类会实现accept方法,比如叶子节点TerminalNodeImpl,它是调用了访问者的visitTerminal方法,非叶子节点,调用了访问者的visitChildren方法。
public class TerminalNodeImpl implements TerminalNode {
public <T> T accept(ParseTreeVisitor<? extends T> visitor) {
return visitor.visitTerminal(this);
}
}
public class RuleContext implements RuleNode {
public <T> T accept(ParseTreeVisitor<? extends T> visitor) {
return visitor.visitChildren(this);
}
}
ParseTreeVisitor接口,定义了对于不同类型节点的访问接口。
public interface ParseTreeVisitor<T> {
//访问数据节点,不区分类型
T visit(ParseTree tree);
//访问非叶子节点
T visitChildren(RuleNode node);
//访问叶子节点
T visitTerminal(TerminalNode node);
//访问出错节点
T visitErrorNode(ErrorNode node);
}
AbstractParserTreeVistor 类实现了上述接口,它的visit方法,只是简单的调用了节点的accept方法
public abstract class AbstractParseTreeVisitor<T> implements ParseTreeVisitor<T> {
public AbstractParseTreeVisitor() {
}
//节点的accpet方法会根据节点的类型,调用visitor的不同方法
public T visit(ParseTree tree) {
return tree.accept(this);
}
//对于非叶子节点,会遍历各个节点,然后将结果聚合整理。访问非叶子节点涉及到递归,它是依照深度优先遍历
public T visitChildren(RuleNode node) {
//生成默认值
T result = this.defaultResult();
int n = node.getChildCount();
//检测是否继续遍历子节点 this.shouldVisitNextChild(node, result)
for(int i = 0; i < n && this.shouldVisitNextChild(node, result); ++i) {
//获取子节点
ParseTree c = node.getChild(i);
//遍历子节点,返回子节点的结果
T childResult = c.accept(this);
//合并子节点的结果
result = this.aggregateResult(result, childResult);
}
return result;
}
//对于叶子节点和出错节点,仅仅是返回一个默认值
public T visitTerminal(TerminalNode node) {
return this.defaultResult();
}
public T visitErrorNode(ErrorNode node) {
return this.defaultResult();
}
protected T defaultResult() {
return null;
}
//合并结果,这里只是返回子节点的结果
protected T aggregateResult(T aggregate, T nextResult) {
return nextResult;
}
//默认继续访问
protected boolean shouldVisitNextChild(RuleNode node, T currentResult) {
return true;
}
}