Linux MySQL 备份与恢复 日志管理
数据库备份
备份策略
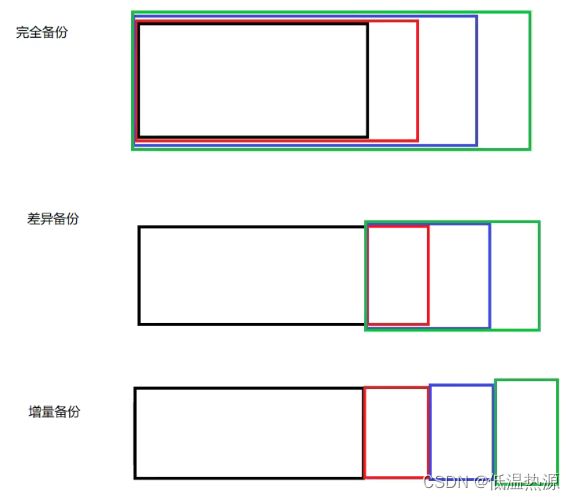
完全备份
每次备份都备份完整的数据库。
备份数据最大,每次都要完整备份。但是恢复最方便
差异备份只备份上一次完全备份后的更新数据。
第一次完整备份,之后备份第一次没有备份的内容
增量备份每次备份只备份上一次完全备份或增量备份后的最新数据。
第一次完整备份,后续备份数据小,但是恢复不如完整备份方便
备份方法
物理冷备份
备份时数据库处于关闭状态,直接对数据库的数据文件或者日志文件进行备份
●tar命令对文件进行压缩归档,直接在文件层面上进行恢复,速度快,最简单
逻辑备份对数据库的库或表对象进行备份
●专用备份工具mysqldump[最常用]、mysqlhotcopy[仅拥有备份myISAM和ARCHIVE表]生成SQL脚本
●启用二进制日志进行增量备份
●第三方工具,免费的数据库热备份软件XtraBackup[第三方常用]、Percona
你们公司怎么做数据库的备份?(面试题)
一般每周2/3/4凌晨 完成一次完整备份,其余每天做增量部分。
写个备份脚本,配合crontab定时执行。
crontab -e 30 0 * * 2 mysqldump -uXXX -pXXX --all-databases > XXX.sql 每周二0:30完全备份数据库 用户XXX 密码XXX 写入XXX.sql脚本文件
----------------------MySQL 完全备份与恢复--------------------------------
完全备份对整个数据库结构、文件内容备份
是差异备份和增量备份的基础
- 物理冷备份与恢复
- 关闭MySQL数据库
- tar命令打包数据库文件夹
- 直接替换现有MySQL目录
- mysqldumo备份与恢复(逻辑备份)
- MySQL自带的备份工具,将指定库、表导出为SQL脚本
- 使用MySQL命令导入备份的数据
----MySQL 完全备份----
use xue; create table if not exists info1 ( id int(4) not null auto_increment, name varchar(10) not null, sex char(10) not null, hobby varchar(50), primary key (id)); insert into info1 values(1,'user1','male','running'); insert into info1 values(2,'user2','female','singing');
InnoDB存储引擎的数据库在磁盘上存储成三个文件:db.opt(表属性文件)、表名.frm(表结构文件)、表名.ibd(表数据文件)。
1.物理冷备份与恢复
先关闭mysqld服务,使用tar 命令打包备份数据库的数据目录/文件 /usr/local/mysql/data/
tar zcvf 归档文件 原数据文件/目录 zcvf 压缩文件格式gzip jcvf jcvf 压缩文件格式bzip2 Jcvf Jcvf 压缩文件格式xz tar xf 解压关闭mysqld服务
systemctl stop mysqld压缩备份
tar czvf /opt/mysql_all_$(date +%F).tar.gz /usr/local/mysql/data/解压恢复
mv /usr/local/mysql/data/ ~ tar xf /opt/mysql_all_2023-06-19.tar.gz mv /opt/usr/local/mysql/data/ /usr/local/mysql/
2.mysqldump 备份与恢复
mysqldump -uXXX -pXXX --databases 库1 [库2] ... > XXX.sql 备份单库或多库 mysqldump -uXXX -pXXX --all-databases > XXX.sql 备份所有的库 mysqldump -uXXX -pXXX 库名 表1 表2 ... > XXX.sql 备份库中的一个或多个表数据(不包含创建库的操作) mysqldump -uXXX -pXXX 库名 > XXX.sql 备份库中的所有表数据(不包含创建库的操作)(1)完全备份一个或多个完整的库(包括其中所有的表)
mysqldump -u root -p[密码] --databases 库名1 [库名2] … > /备份路径/备份文件名.sql 导出的就是数据库脚本文件mysqldump -u root -pabc123 --databases xue > /opt/xue.sql 备份MySQL数据库 mysqldump -u root -pabc123 --databases mysql xue > /opt/mysql-xue.sql 备份MySQL和xue数据库
(2)完全备份 MySQL 服务器中所有的库mysqldump -u root -p[密码] --all-databases > /备份路径/备份文件名.sqlmysqldump -u root -p --all-databases > /opt/all.sql
(3.1)完全备份指定库中的部分表mysqldump -u root -p[密码] 库名 [表名1] [表名2] … > /备份路径/备份文件名.sqlmysqldump -u root -p [-d] xue info1 info2 > /opt/xue_info1.sql 使用“-d”选项,说明只保存数据库的表结构 不使用“-d”选项,说明表数据也进行备份(3.2)完全备份指定库中的所有表(只指定库名不指定表名就行。如果备份所有表,还不如直接用第1步,备份这个库)
mysqldump -u root -p[密码] 库名 … > /备份路径/备份文件名.sqlmysqldump -u root -p [-d] xue > /opt/xue_alltable.sql(4)查看备份文件
grep -v "^--" /opt/xue_info1.sql | grep -v "^/" | grep -v "^$" 去除了注释文件
----MySQL 完全恢复----
完全恢复有两种方法
- 可以先登录到mysql,再执行
source XXX.sql 注:如果XXX.sql是表数据文件那么需要先自行创建库并use切换库
- 也可以直接在登录命令后加上参数
- 使用重定向符号
mysql -uXXX -pXXX [库名] < XXX.sql- 或使用管道符号
cat XXX.sql | mysql -uXXX -pXXX [库名]
启动刚刚关闭的mysql服务
systemctl start mysqld(1)恢复数据库
mysql -u root -p -e 'drop database xue;' #“-e”选项,用于指定连接 MySQL 后执行的命令,命令执行完后自动退出 mysql -u root -p -e 'SHOW DATABASES;' mysql -u root -p < /opt/xue.sql mysql -u root -p -e 'SHOW DATABASES;'(2)恢复数据表
mysqldump -u root -p xue info1 > /opt/xue_info1.sql mysql -u root -p -e 'drop table xue.info1;' mysql -u root -p -e 'show tables from xue;' mysql -u root -p xue < /opt/xue_info1.sql /*由于这里使用命令,并不登录MySQL,所以自然也无法使用use选择数据库。在-p[密码选项]后跟上要使用的数据库名。*/ mysql -u root -p -e 'show tables from xue;'表恢复不在乎使用的是哪个库,但是如果
备份文件中只包含表的备份,而不包含创建的库的语句时,执行导入操作时必须指定库名,且目标库必须存在。
若库不存在,创建,并且使用
登录mysql后执行命令 mysql> create database xue; mysql> use xue; 或者 登录MySQL时加上参数运行命令 mysql -u root -p -e 'create database xue;'
你做数据库备份用什么工具 除了mysqldump还用过什么(面试题)
mysqldump、xtrabackup等工具来逻辑备份
补充 数据迁移常用方法
- 体量小 物理冷备 打包备份+恢复
- 体量中等 DTS数据传输服务 (阿里云工具,将机房数据迁移到阿里云)
- 体量超大 数据魔方 (阿里云服务,直接给你一个硬盘,数据库复制进去,直接邮寄)
----------------------MySQL 日志管理--------------------------------
MySQL 的日志默认保存位置为 /usr/local/mysql/data
数据库日志字段说明
vim /etc/my.cnf [mysqld] ##错误日志,用来记录当MySQL启动、停止或运行时发生的错误信息,默认已开启 log-error=/usr/local/mysql/data/mysql_error.log #指定日志的保存位置和文件名 ##通用查询日志,用来记录MySQL的所有连接和语句,默认是关闭的 general_log=ON general_log_file=/usr/local/mysql/data/mysql_general.log ##二进制日志(binlog),用来记录所有更新了数据或者已经潜在更新了数据的语句,记录了数据的更改,可用于数据恢复,默认已开启 log-bin=mysql-bin #制定二进制日志保存路径。这里仍然保存在/usr/local/mysql/data/。也可以 log_bin=mysql-bin ##慢查询日志,用来记录所有执行时间超过long_query_time秒的语句,可以找到哪些查询语句执行时间长,以便于优化,默认是关闭的 slow_query_log=ON slow_query_log_file=/usr/local/mysql/data/mysql_slow_query.log long_query_time=5 #设置超过5秒执行的语句被记录,缺省时为10秒systemctl restart mysqld慢查询日志 可以用来优化制定索引,但是不是所有的命select命令都适合制定索引,例如like这种只能全表查询的,运行时间如果过长直接让客户改进sql语句而不制定索引
查看数据库日志开启情况
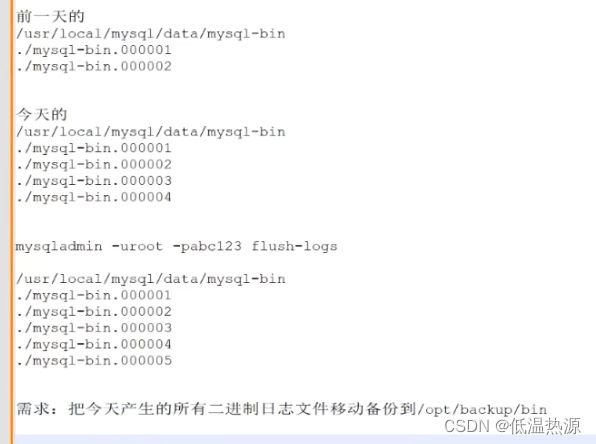
mysql -u root -p show variables like 'general%'; #查看通用查询日志是否开启 show variables like 'log_bin%'; #查看二进制日志是否开启 show variables like '%slow%'; #查看慢查询日功能是否开启 show variables like 'long_query_time'; #查看慢查询时间设置 set global slow_query_log=ON; #在数据库中设置开启慢查询的方法 show variables是查询当前会话设置,show global查看全局设置重启服务与执行mysqladmin -u root -p flush-logs方法均能创建新的二进制日志文件序列。
尾缀为index的二进制日志文件 记录所有二进制文件的序号,最下方即为最新文件。


----------------------MySQL 增量备份与恢复--------------------------------
----MySQL 增量备份----
MySQL没有直接的增量备份方法
但是可以通过MySQL提供的二进制日志间接增量备份
- 二进制日志保存了所有更新和可能更新数据库的操作
- 在启动MySQL服务器后就开始记录,并在max_binlog_size设置大小或接收到flush logs命令后创建新的日志文件
- 所以只需要执行mysqladmin -u root -p flush-logs方法创建新的日志,生成二进制日志文件序列,及时将这些日志保存到安全的地方就相当于完成了增量备份。(重启服务与flush logs均能创建新的二进制文件)
1.开启二进制日志功能
vim /etc/my.cnf [mysqld] ##二进制日志 log-bin=mysql-bin binlog_format = MIXED #可选,指定二进制日志(binlog)的记录格式为 MIXED server-id = 1 二进制日志(binlog)有3种不同的记录格式:STATEMENT(基于SQL语句)、ROW(基于行)、MIXED(混合模式),默认格式是STATEMENT STATEMENT(基于SQL语句) #记录下进行操作的SQL语句(速度快,高并发下记录顺序可能偏差) ROW(基于行) #影响哪几行记录哪几行的内容(更精准,但是资源占用量高[若一条SQL语句涉及更改6000行,则需要记录6000行]) MIXED(混合模式) #最好。一般情况下使用statement记录SQL语句(更快),高并发情况下使用ROW直接记录行(保证准确) ········································································ 下面这几个日志可加可不加,对增量恢复没有影响。 ##错误日志 log-error=/usr/local/mysql/data/mysql_error.log ##通用查询日志 general_log=ON general_log_file=/usr/local/mysql/data/mysql_general.log ##慢查询日志 slow_query_log=ON slow_query_log_file=/usr/local/mysql/data/mysql_slow_query.log long_query_time=5systemctl start mysqld ls -l /usr/local/mysql/data/mysql-bin.*
2.可每周对数据库或表进行完全备份。将完整备份文件移动到完整备份文件夹保存
mkdir /opt/full #创建完整备份文件夹(完整备份放完整备份文件夹,增量备份放增量备份文件夹) mysqldump -u root -p xue info1 > /opt/full/xue_info1_$(date +%F).sql /*备份xue库的info1表*/ mysqldump -u root -p --databases xue > /opt/full/xue_$(date +%F).sql /*备份xue库*/
3.刷新二进制日志文件。可每天进行增量备份操作,生成新的二进制日志文件(例如 mysql-bin.000002)
mysqladmin -u root -p flush-logs
4.插入新数据,以模拟数据的增加或变更
use xue; insert into info1 values(3,'user3','male','game'); insert into info1 values(4,'user4','female','reading');
5.再次生成新的二进制日志文件(例如 mysql-bin.000003)
生成后执行的命令记录到 这个新的日志文件。此时即可对更改记录了变动的文件(000002)进行移动、查看
mysqladmin -u root -p flush-logs
6.将旧的增量备份文件移动到增量保存文件夹保存(倒数第二个备份文件)
mkdir /opt/add #创建完整备份文件夹(完整备份放完整备份文件夹,增量备份放增量备份文件夹) mv /usr/local/mysql/data/mysql-bin.000002 /opt/add之前的步骤4的数据库操作会保存到mysql-bin.000002文件中,生成新日志之后数据库数据再发生变化则保存在mysql-bin.000003文件中
所以若要写脚本完成自动增量备份,生成新日志之后选取倒数第二个日志备份(这是先flush后备份的方法,更加保险)
若先移动备份二进制文件,再flush生成,则不需要选取倒数第二个日志(更方便,但是感觉不如上面那种方法保险。一般也够用了)
cat mysql-bin.index | tail -2 | head -1 | awk -F'/' '{print $2}' 选取日志文件的index记录文件内的日志文件编号,得到倒数第二行,去除相对路径的./得到文件名。 ./mysql-bin.000001 ./mysql-bin.000002 ./mysql-bin.000003 ./mysql-bin.000004 ./mysql-bin.000005 → mysql-bin.000004思考题
若前一天的日志超过了max_binlog_size设置大小,自动分割为了两个文件,如何确定备份哪几个文件?
在脚本中,flush生成新二进制日志文件后,使用对比index文件中新旧序号的方法查找出新增的文件。
(注意是先flush再备份二进制日志 还是先备份二进制日志再flush生成新日志 这两个写法些许差别)
cat mysql-bin.index | grep -v "$(cat mysql-bin.index_old)" | awk -F'/' '{print $2}' 先移动日志,再flush的写法。对比新旧文件选出不一样的 cat mysql-bin.index | grep -v "$(cat mysql-bin.index_old)" | head -1 | awk -F'/' '{print $2}' 先flush,再移动日志的写法。由于flush已经生成了新日志。所以要在差异文件中head -1去除最后一个选取其他的。
备份日志脚本
此备份脚本使用先备份再flush的方式,如果是先flush再备份,需要参考第六步中最后写的命令,在脚本中判断是否存在前一天日志索引文件的两个COUNT代码中 加上用head -1,在index索引文件中选取二进制日志索引时省略掉最后一条二进制日志序号(flush后新生成的)
另外在写入crontab做定时任务时,完整备份一周一次,增量备份一天一次。
注意日期(today yesterday),一般都是在凌晨2-3点备份,此时生成的日志备份文件的日期虽然是今天的,但是文件中内容大多都是昨天的操作。如果介意可以在设置变量的时候将(today yesterday)改为(yesterday,day_before_yesterday),再去脚本中将这两个变量对应全部替换。


7.查看二进制日志文件的内容
mysqlbinlog --no-defaults --base64-output=decode-rows -v /opt/add/mysql-bin.000002 #--base64-output=decode-rows:使用64位编码机制去解码并按行读取 #-v:显示详细内容
----MySQL 增量恢复----
1.一般恢复
(1)模拟丢失更改的数据的恢复步骤
use xue; delete from info1 where id=3; delete from info1 where id=4;增量恢复 二进制日志文件使用mysqlbinlog命令恢复
mysqlbinlog --no-defaults /opt/add/mysql-bin.000002 | mysql -u root -p #使用增量文件 管道符交给mysql命令用于执行恢复 cat /opt/add/mysql-bin.000002 | mysql -u root -p #不用解码直接cat输出管道符交给mysql命令也行。但是有时候因为有特殊字符爆错(2)模拟丢失所有数据的恢复步骤
use xue; drop table info1;完整恢复
恢复基础数据 mysql -u root -p xue < /opt/full/xue_info1_2023-6-19.sql #先使用完整备份文件的SQL脚本,恢复基础数据恢复增量数据 mysqlbinlog --no-defaults /opt/add/mysql-bin.000002 | mysql -u root -p #再使用增量文件 管道符交给mysql命令用于执行恢复增量数据
2.断点恢复
(1)基于操作ID恢复
使用mysqlbin命令查看二进制日志中记录的操作 mysqlbinlog --no-defaults --base64-output=decode-rows -v /opt/add/mysql-bin.000002 # at 302 #201122 16:41:16 插入了“user3”的用户数据 # at 623 #201122 16:41:24 插入了“user4”的用户数据(1)基于位置恢复mysqlbinlog --no-defaults --start-position="位置点" --stop-position="位置点" 二进制日志文件 | mysql -uXXX -pXXX #仅恢复到操作 ID 为“623”之前的数据,即不恢复“user4”的数据 mysqlbinlog --no-defaults --stop-position='623' /opt/mysql-bin.000002 | mysql -uroot -p #仅恢复“user4”的数据,跳过“user3”的数据恢复 mysqlbinlog --no-defaults --start-position='623' /opt/mysql-bin.000002 | mysql -uroot -p注意,当使用stop—position或者stop-datetime只恢复前面的usr3和上面的内容,位置不能写插入usr3上方的302,需要写插入操作下方的一个at或是time(这里是at 623和16:41:42)因为如果stop 302或16:41:16,在‘’at 302‘’和‘16:41:16’的位置就停止了, 并未包含插入usr3的操作(说人话就是 这个at或time并不是 一个at一个time对应一条操作 一块一块划分的,而是只相当于一个书签一个信标)
一般建议恢复到下一条命令前面一个恢复点(因为可能含有commit等操作)
(2)基于时间点恢复
mysqlbinlog --no-defaults --start-datetime="YYYY-mm-dd HH:MM:SS" --stop-datetime="YYYY-mm-dd HH:MM:SS" 二进制日志文件 | mysql -uXXX -pXXX #仅恢复到 16∶41∶24 之前的数据,即不恢复“user4”的数据 mysqlbinlog --no-defaults --stop-datetime='2023-6-19 16:41:24' /opt/mysql-bin.000002 |mysql -uroot -p #仅恢复“user4”的数据,跳过“user3”的数据恢复 mysqlbinlog --no-defaults --start-datetime='2023-6-19 16:41:24' /opt/mysql-bin.000002 |mysql -uroot -p如果恢复某条SQL语句之前的所有数据,就stop在这个语句的位置节点或者时间点
如果恢复某条SQL语句之前的所有数据(包含这条),就stop在下一条语句之前的位置节点或者时间点
如果恢复某条SQL语句以及之后的所有数据,就从这个语句的位置节点或者时间点start