Speech | 提取语音(数据集)的语音特征合集
本文主要讲解了提取数据集的一些主要工具,以及如何使用这些工具,包含安装以及运行命令。
提取语音(数据集)的语音特征工具(Extract audio features toolkits)
1.openSMILE
Linux 上安装。环境:Ubuntu 20.04.(docker 容器)
opensmile安装方法一及使用
# 安装
pip install opensmile
#安装版本2.4.2
#单个wav文件使用
# opensmile v 2.4.2
import opensmile
path = '/workspace/dataset/mer1/audio/KETI_MULTIMODAL_0000000012_00.wav'
smile = opensmile.Smile(
feature_set=opensmile.FeatureSet.eGeMAPSv02,
feature_level=opensmile.FeatureLevel.Functionals,
)
y = smile.process_file(path)
print(y.shape)
print(y)opensmile.FeatureSet.后的特征可查看
目前有的(不是很全)
| Name | #features |
|---|---|
| ComParE_2016 | 65 / 65 / 6373 |
| GeMAPSv01a | 5 / 13 / 62 |
| GeMAPSv01b | 5 / 13 / 62 |
| eGeMAPSv01a | 10 / 13 / 88 |
| eGeMAPSv01b |
10 / 13 / 88 |
FeatureSet — Documentation (audeering.github.io)
结果(这里eGenMAPSv02是1×88维的)

opensmile安装方法2及使用
git clone https://github.com/audeering/opensmile
cd opensmile
sh build.sh
将 smilextract 路径 加入系统目录
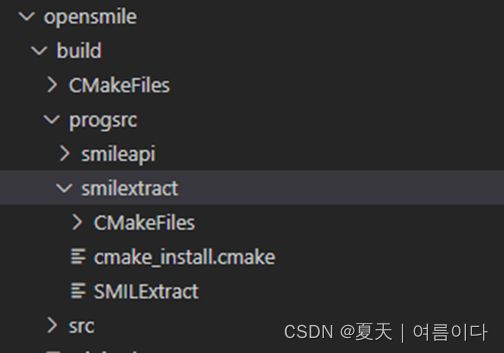
加入系统目录
source /etc/profile
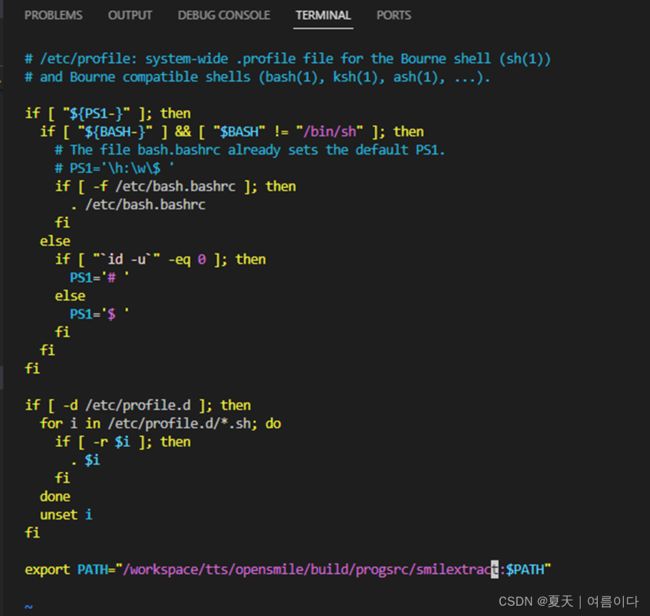
版本不同,可能路径不同,找自己电脑的smilextract路径。我的是:
export PATH="/workspace/tts/opensmile/build/progsrc/smilextract:$PATH"
(快捷键Esc+:+wq)保存并退出,然后执行:
source /etc/profile
查看版本信息
SMILExtract -h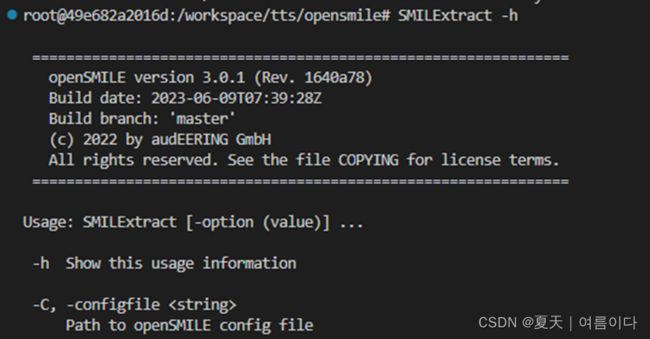
成功则会显示版本等相关信息~
调用命令行运行opensmile
SMILExtract -C(配置文件) -I(后面加输入的音频文件) -O(后面加输出的路径)
(单个音频)实例:
SMILExtract -C ./config/is09-13/IS09_emotion.conf -I /workspace/dataset/emoko/audio/000-001.wav -O /workspace/dataset/emoko/opensmile-file/1.txt
需要根据自身的需求,更换下面命令中的conf文件名(配置文件)即可,注意音频文件必须是无损的wav格式。
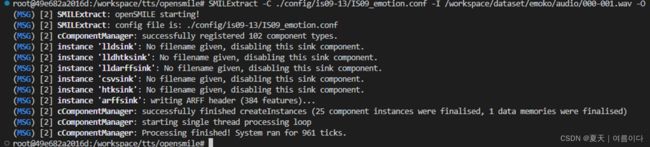
输出文件1.txt如下
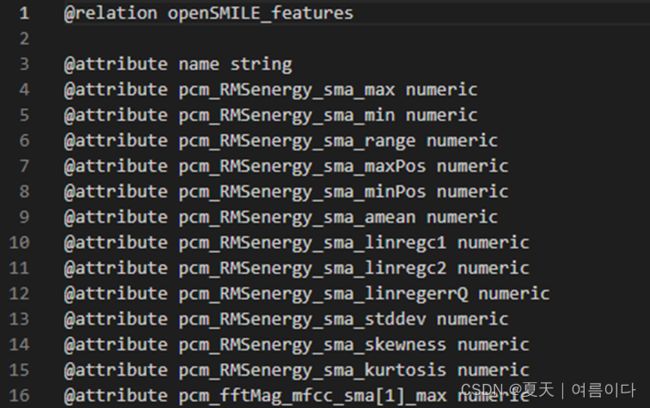
最后一行为具体的特征数据:

用python批量调用命令行
如果有很多个音频需要去提取特征,那么一个个用dos界面敲命令会非常麻烦。用python批量调用命令行源代码如下:(俩种方法只选一个)
opensmile-feature01.py
方法一
import os
path = '/workspace/dataset/emoko'
for root,dir,files in os.walk(path):
for i in files:
os.system('SMILExtract -C /workspace/tts/opensmile/config/is09-13/IS09_emotion.conf -I ' + path + '/audio/' + i + ' -O ' + '/emoko' + i[:-4] + '.csv')
方法二
import os
audio_path = '/workspace/dataset/emoko/audio' # .wav file path
output_path='/workspace/dataset/emoko/opensmile-pro' # feature file path
audio_list=os.listdir(audio_path)
features_list=[]
for audio in audio_list: # 遍历指定文件夹下的所有文件
if audio[-4:]=='.wav':
this_path_input=os.path.join(audio_path, audio) # 打开一个具体的文件,audio_path+audio
this_path_output=os.path.join(output_path,audio[:-4]+'.csv') # .txt/.csv
# 进入opensmile中要执行的文件的目录下;执行文件 -C 配置文件 -I 语音文件 -O 输出到指定文件
os.system( 'SMILExtract -C /workspace/tts/opensmile/config/is09-13/IS09_emotion.conf -I ' + this_path_input + ' -O ' + this_path_output)
print('over~')
*注意方法二中:这里需要三个路径
①.wav文件文件夹路径
②前面处理语音文件提取的csv文件或txt文件存放的文件路径
③opensmile的情感特征配置文件
运行这个py文件时,要在opensmile文件夹下运行。
提取的文件可保存为.txt/.csv文件
输出(每一个.wav文件对应的特征文件,且与wav文件名字相同)
提取文件后,对csv文件进行处理,提取数据特征向量部分
批量处理生成特征的文本文件,提取组合出可以用来学习处理的矩阵文件。代码如下
opensmile-pro-csv02.py
import os
audio_path = '/workspace/dataset/emoko/audio' # .wav file path
output_path='/workspace/dataset/emoko/opensmile-pro' # feature file path
audio_list=os.listdir(audio_path)
features_list=[]
for audio in audio_list: # 遍历指定文件夹下的所有文件
if audio[-4:]=='.wav':
this_path_input=os.path.join(audio_path, audio) # 打开一个具体的文件,audio_path+audio
this_path_output=os.path.join(output_path,audio[:-4]+'.csv') # .txt/.csv
# 进入opensmile中要执行的文件的目录下;执行文件 -C 配置文件 -I 语音文件 -O 输出到指定文件
os.system( 'SMILExtract -C /workspace/tts/opensmile/config/is09-13/IS09_emotion.conf -I ' + this_path_input + ' -O ' + this_path_output)
print('over~')
*注意:这里需要三个路径
①.wav文件文件夹路径
②前面处理语音文件提取的csv文件或txt文件存放的文件路径
③opensmile的情感特征配置文件
运行这个py文件时,要在opensmile文件夹下运行。
可以通过如下Python代码进行特征解析:
def feature_file_reader(feature_fp):
"""
读取生成的ARFF格式csv特征文件中特征值
:param feature_fp: csv特征文件路径
:return: np.array
"""
with open(feature_fp) as f:
last_line = f.readlines()[-1] # ARFF格式csv文件最后一行包含特征数据
features = last_line.split(",")
features = np.array(features[1:-1], dtype="float64") # 第2~倒数第二个为特征数据
return features保存为一个npy文件
import os
import numpy as np
txt_path='输出文件夹路径'
txt_list=os.listdir(txt_path)
features_list=[]
for txt in txt_list:
if txt[-4:]=='.txt':
this_path=os.path.join(txt_path,txt)
f=open(this_path)
last_line=f.readlines()[-1]
f.close()
features=last_line.split(',')
features=features[1:-1]
features_list.append(features)
features_array=np.array(features_list)
np.save('保存文件的路径/opensmile_features.npy',features_array)创建自己的配置文件
可参考audio - How to create custom config files in OpenSMILE - Stack Overflow
openSMILE 3.0 - audEERING
opensmile 参数详解
01.运行命令参数
更多可查看Reference section — openSMILE Documentation
首先是处理数据时
'lldsink','lldhtksink','lldarffsink','csvsink','htksink',cArffSink ,'arffsink'具体可查看opensmile/standard_data_output.conf.inc at master · naxingyu/opensmile · GitHub
opensmile自带的配置文件:
config/对于音乐信息检索和语音处理领域的常见任务,我们在目录中为以下常用功能集提供了一些示例配置文件 。这些还包含 2009-2013 年 INTERSPEECH 影响和副语言学挑战的基线声学特征集:
-
用于键和弦识别的色度特征
-
用于语音识别的 MFCC
-
用于语音识别的 PLP
-
韵律(音调和响度)
-
INTERSPEECH 2009 情感挑战赛功能集
-
INTERSPEECH 2010 副语言挑战赛功能集
-
INTERSPEECH 2011 演讲者状态挑战功能集
-
INTERSPEECH 2012 演讲者特质挑战赛功能集
-
INTERSPEECH 2013 ComParE 功能集
-
用于暴力场景检测的 MediaEval 2012 TUM 功能集。
-
用于情感识别的三个参考特征集(旧集,被新的 INTERSPEECH 挑战集淘汰)
-
基于 INTERSPEECH 2010 副语言挑战音频功能的视听功能。
ESPnet
Linux(Ubuntu20.04)安装
apt-get install cmake
apt-get install sox
apt-get install flac
git clone https://github.com/espnet/espnet
cd espnet/tools
#python环境下
bash setup_python.sh $(command -v python3)
make
#根据make后出来的值复制 TH_VERSION 和 CUDA_VERSION 版本
make TH_VERSION=1.13.1 CUDA_VERSION=11.4其他请参考Installation — ESPnet 202304 documentation
检查安装
bash -c ". ./activate_python.sh; . ./extra_path.sh; python3 check_install.py"【PS1】bash: SMILExtract: command not found
https://fxburk.medium.com/machine-classification-of-emotional-speech-with-emodb-and-python-25a67753210e
apt install automake
apt install autoconf
apt install libtool
apt install m4
apt install gcc
apt update尝试1
./SMILExtract -h出现bash: ./SMILExtract: No such file or directory
尝试2
strace ./SMILExtract出现strace: Can't stat './SMILExtract': No such file or directory
参考文献
[1]opensmile/INSTALL at master · naxingyu/opensmile · GitHub