python爬虫获取网站销售情况(内置源码)
在现在这个信息爆炸的时代,要想高效的获取数据,爬虫是非常好用的。而用python做爬虫也十分简单方便,下面通过一个简单的小爬虫程序来看一看写爬虫的基本过程:
注:此处猫咪销售网站中的内容本来就可以免费下载,所以爬虫只是简化了我们一个个点的流程。
编写爬虫程序
- 访问目标网站
- 找到爬取的内容并做循环
- 保存爬取的数据
一、找到目标网站并访问
首先肯定要通过python访问这个网站,代码如下
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:97.0) Gecko/20100101 Firefox/97.0"}
respones = requests.get(url=url,headers=headers)
二、找到爬取的内容代码如下:(具体问题具体分析)
shop = selector_1.css('.dinming::text').get().strip() #店名
price = selector_1.css('.info1 div:nth-child(1) span.red.size_24::text').get() #价格
views = selector_1.css('.info1 div:nth-child(1) span:nth-child(4)::text').get() #浏览次数
num = selector_1.css('.info2 div:nth-child(1) div.red::text').get() #在售只数
age = selector_1.css('.info2 div:nth-child(2) div.red::text').get() #年龄
kind = selector_1.css('.info2 div:nth-child(3) div.red::text').get() #品种
prevention = selector_1.css('.info2 div:nth-child(4) div.red::text').get() #预防
person = selector_1.css('div.detail_text .user_info div:nth-child(1) .c333::text').get()#联系人
postage = selector_1.css('div.detail_text .user_info div:nth-child(3) .c333::text').get().strip()#//邮费
purebred = selector_1.css('.xinxi_neirong div:nth-child(1) .item_neirong div:nth-child(1) .c333::text').get().strip() #//纯种
sex = selector_1.css('.xinxi_neirong div:nth-child(1) .item_neirong div:nth-child(4) .c333::text').get().strip() #//性别
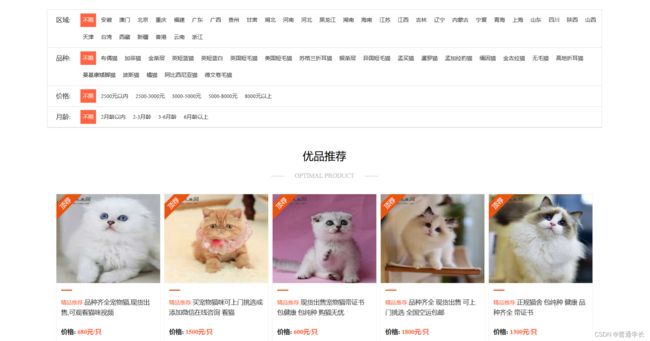
(1)目标网页猫咪销售网站
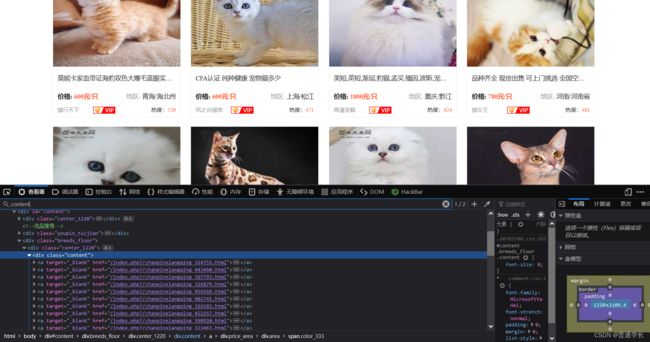
(2)通过发现信息都在a标签内那么找到a标签
(3)定位.content找到有二个取上面那个
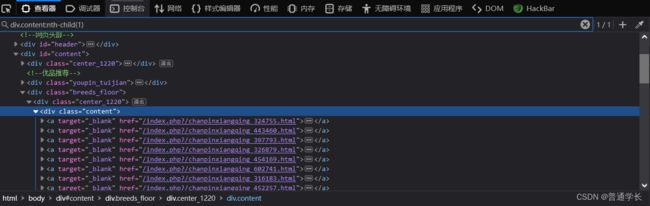 通过选着定位第一个div.content:nth-child(1)
通过选着定位第一个div.content:nth-child(1)
(4)定位到我们想要获取到位置信息
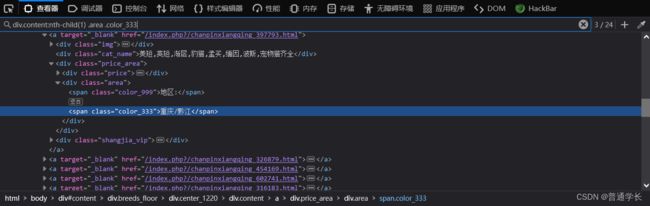 其他信息也是类似的方式进行选择过滤
其他信息也是类似的方式进行选择过滤
三、保存爬取的数据代码如下:
f = open('momi1.csv',mode='a',encoding='utf-8',newline='')
csv_writer = csv.DictWriter(f,fieldnames=['地区','店名','标题','价格','浏览次数','在售只数',
'年龄','品种','预防','联系人','邮费','纯种','性别'])
csv_writer.writeheader()#写入表头
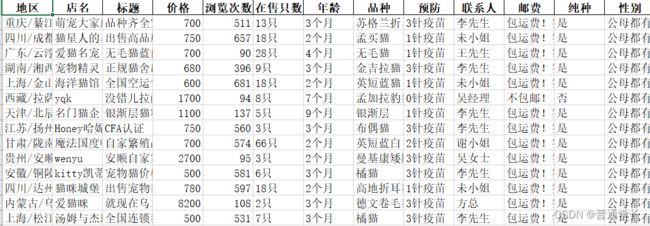
源代码如下:
import requests
import parsel
import csv
f = open('momi1.csv',mode='a',encoding='utf-8',newline='')
csv_writer = csv.DictWriter(f,fieldnames=['地区','店名','标题','价格','浏览次数','在售只数',
'年龄','品种','预防','联系人','邮费','纯种','性别'])
csv_writer.writeheader()#写入表头
for page in range(1,500):
print(f"============正在爬去{page}页内容============")
url = f'http://maomijiaoyi.com/index.php?/chanpinliebiao_c_2_{page}--24.html'
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:97.0) Gecko/20100101 Firefox/97.0"}
respones = requests.get(url=url,headers=headers)
#print(respones.text)
#数据解析 re正则表达式(html字符串数据)CSS选择器 Xpath(我们获取到的html字符串数据进行selector)
selector = parsel.Selector(respones.text)
#CSS选择器 根据标签属性内容 提取数据
href = selector.css('div.content:nth-child(1) a::attr(href)').getall()
areas = selector.css('div.content:nth-child(1) .area .color_333::text').getall()
#strip()字符串方法 把字符串两端空格去掉
areas = [i.strip() for i in areas]
for index in zip(href,areas):
index_url = 'http://maomijiaoyi.com' + index[0]
areas = index[1]
respones_1= requests.get(url=index_url,headers=headers)
selector_1 = parsel.Selector(respones_1.text)
title = selector_1.css('.detail_text .title::text').get().strip()
shop = selector_1.css('.dinming::text').get().strip() #店名
price = selector_1.css('.info1 div:nth-child(1) span.red.size_24::text').get() #价格
views = selector_1.css('.info1 div:nth-child(1) span:nth-child(4)::text').get() #浏览次数
num = selector_1.css('.info2 div:nth-child(1) div.red::text').get() #在售只数
age = selector_1.css('.info2 div:nth-child(2) div.red::text').get() #年龄
kind = selector_1.css('.info2 div:nth-child(3) div.red::text').get() #品种
prevention = selector_1.css('.info2 div:nth-child(4) div.red::text').get() #预防
person = selector_1.css('div.detail_text .user_info div:nth-child(1) .c333::text').get()#联系人
postage = selector_1.css('div.detail_text .user_info div:nth-child(3) .c333::text').get().strip()#//邮费
purebred = selector_1.css('.xinxi_neirong div:nth-child(1) .item_neirong div:nth-child(1) .c333::text').get().strip() #//纯种
sex = selector_1.css('.xinxi_neirong div:nth-child(1) .item_neirong div:nth-child(4) .c333::text').get().strip() #//性别
dit = {
'地区':areas,
'店名':shop,
'标题':title,
'价格':price,
'浏览次数':views,
'在售只数':num,
'年龄':age,
'品种':kind,
'预防':prevention,
'联系人':person,
'邮费':postage,
'纯种':purebred,
'性别':sex,
}
csv_writer.writerow(dit)
print(areas,shop,title,price,views,num,age,kind,prevention,person,postage,purebred,sex)
运行如图:
