Java常用类库与技巧
1、String,StringBuffer,StringBuilder的区别?
2、Java异常
异常处理机制主要回答了三个问题
- What:异常类型回答了什么被抛出?
- Where:异常堆栈跟踪回答了在哪抛出?
- Why:异常信息回答了为什么被抛出?
Java的异常体系
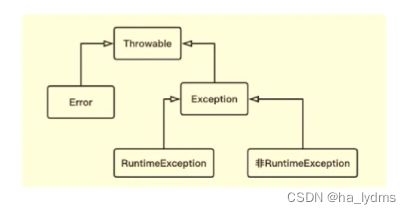
从概念角度解析Java的异常处理机制
- Eror:程序无法处理的系统错误,编译器不做检査。
- Exception:程序可以处理的异常,捕获后可能恢复。
- 总结:前者是程序无法处理的错误,后者是可以处理的异常。
- RuntimeException:不可预知的,程序应当自行避免。
- 非RuntimeEXception:可预知的,从编译器校验的异常。
从责任角度看:
- Error属于JVM需要负担的责任;
- RuntimeException是程序应该负担的责任;
- Checked Exception可检查异常是Java编译器应该负担的责任
常见的Error以及Exception
RuntimeException
- NullPointerException-空指针引用异常
- ClassCastException-类型强制转换异常
- IllegalArgumentException-传递非法参数异常
- IndexoutofBounds Exception-下标越界异常
- NumberFormatException-数字格式异常
非 RuntimeException
- ClassNotFoundException-找不到指定ClassE的异常
- IOException-IO操作异常
Error
- NoClassDefFoundError-找不到cass定义的异常的das
- StackOverflowError-深递归导致栈被耗尽而抛出的异常
- OutofMemoryError-内存溢出异常
NoclassDefFoundError的成因
- 类依赖的cas或者ja不存在。
- 类文件存在,包是存在不同的域中。
- 大小写问题,javac编译的时候是无枧大小写的,很有可能编译出来的dass文件就与想要的不一样。
3、Java的异常处理机制
- 抛出异常:创建异常对象,交由运行时系统处理。
- 捕获异常:寻找合适的异常处理器处理异常,否则终止运行。
Java异常的处理原则
- 具体明确:抛出的异常应能通过异常类名和 message准确说明异常的类型和产生异常的原因;
- 提早抛出:应尽可能早的发现并抛出异常,便于精确定位问题;
- 延迟捕获:异常的捕获和处理应尽可能延迟,让掌握更多信息的作用域来处理异常。
高效主流的异常处理框架
在用户看来,应用系统发生的所有异常都是应用系统內部的异常
- 设计一个通用的继承自 RuntimeEXception的异常来统一处理。
- 其余异常都统一转译为上述异常 AppException。
- 在 catch之后,抛出上述异常的子类,并提供足以定位的信息。
- 由前端接收 AppEXception做统一处理。
Java异常处理消耗性能的地方
- try-catch块影响MM的优化。
- 异常对象实例需要保存栈快照等信息,开销较大。
尽量少的try-catch代码行,只包住有异常的代码。
不要利用try-catch,控制业务的流程。
4、数据结构和算法
数据结构考点
- 数组和链表的区别;
- 链表的操作,如反转,链表环路检测,双向链表,循环链表相关操作;
- 队列,栈的应用;
- 二叉树的遍历方式及其递归和非递归的实现;
- 红黑树的旋转
算法考点
- 内部排序∶如递归排序、交换排序(冒泡、快排)、选择排序、插入排序。
- 外部排序:应掌握如何利用有限的内存配合海量的外部存储来处理超大的数据集,写不出来也要有相关的思路。
考点扩展:
- 哪些排序是不稳定的,稳定意味着什么?
- 不同数据集,各种排序最好或最差的情况?
- 如何优化算法?(以空间换时间)

5、Java集合框架
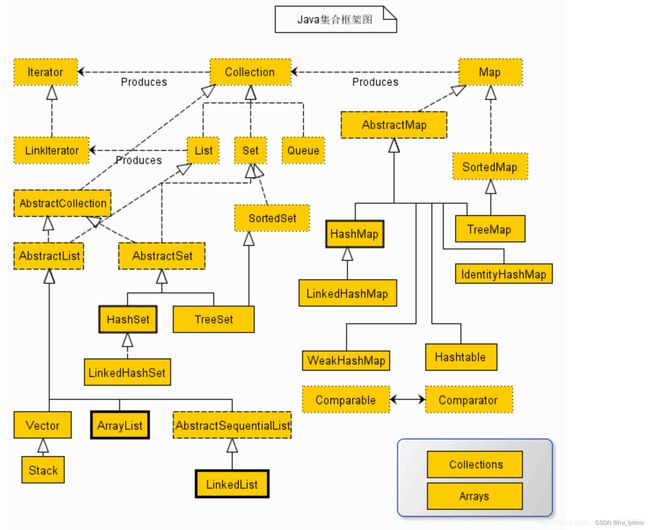

compare和自定义的compare
6、Map集合
HashMap、HashTable、ConccurentHashMap的区别?
HashMap:(Java8以前):数组+链表,非synchronized,速度快。
(Java8后):数组+链表+红黑树

某个桶上高于8,则转为红黑树,小于6则转为链表。
HashMap在使用的时候,才会被初始化。
首次使用才会创建(延迟加载策略)
HashMap中的put方法逻辑:


计算HashCode方法

扩容resize()
负载因子
transient Node<K,V>[] table;
![]()
达到0.75以后,扩大为原来2倍。
树(Node
static final int TREEIFY_THRESHOLD = 8;(树转化为红黑树)
HashMap:扩容的问题
- 多线程环境下,调整大小会存在条件竟争,容易造成死锁
- rehashing是一个比较耗时的过程
HashMap知识点
- 成员变量:数据结构,树化阈值
- 构造函数:延迟创建
- put和get的流程
- 哈希算法,扩容,性能
互斥Object对象mutex,使用synchronized对mutex进行加锁。
HashTable,给public方法进行加锁、
7、ConccurentHashMap
HashMap进行,线程安全操作
互斥Object对象mutex,使用synchronized对mutex进行加锁。
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;
public class test001 {
public static void main(String[] args) {
// 创建HashMap
HashMap hashMap = new HashMap<>();
// 将HashMap(不安全)转为线程安全的
Map safeHashMap = Collections.synchronizedMap(hashMap);
safeHashMap.put("aa","1");
safeHashMap.put("bb","2");
System.out.println(safeHashMap.get("bb"));
}
}
HashTable,给public方法进行加锁、
线性执行,效率低(HashTable、HashMap)
ConcurrentHashMap的使用(JUC包java.util.cuncurrent)
早期的 ConcurrentHashMap:通过分段锁 Segmen来实现
当前 ConcurrentHashMap:CAS+ synchronized使锁更细化
数据结构进行优化:数组+链表+红黑树
synchronized只锁定链表和红黑树的首节点。
大小控制标识符,Hash初始化,扩容表示
private transient volatile int sizeCtl;
-1:正在进行初始化。
负数:正在进行初始化或扩容操作。
-n:有n个线程正在进行初始化或扩容操作。
正数/0:Hash表还未被初始化

ConcurrentHashMap总结:比Segment(分段锁),锁拆的更细。
- 首先使用无锁操作CAS插入头节点,失败则循环重试。
- 若头节点已存在,则尝试获取头节点的同步锁,再进行操作。
ConcurrentHashMap:别的需要注意的点
- size( )方法和 mapping Count( )方法的异同,两者计算是否准确?
- 多线程环境下如何进行扩容?
Hash Map、 Hashtable、 ConccurentHashMap三者区别
- Hash Map线程不安全,数组+链表+红黑树。
- Hashtable线程安全,锁住整个对象,数组+链表。
- ConccurentHashMap线程安全,CAS+同步锁,数组+链表+红黑树。
- HashMap的key、value均可为null,而其他的两个类不支持。
8、J.U.C知识点(java.util.conccurent)
java.util.concurrent:提供了并发编程的解决方案
- CAS是 java.util.concurrent.atomic包的基础.
- AQS是 java.util.concurrent.locks包以及一些常用类比如Semophore,Reentrantlock等类的基础。
JUC包的分类
- 线程执行器 executor
- 锁 locks
- 原子变量类 atomIc
- 并发工具类 tools
- 并发集合 collections

并发工具类(tools)
- 闭锁(CountDownLatch)
- 栅栏(CyclicBarrier)
- 信号量(Semaphore)
- 交换器(Exchanger)
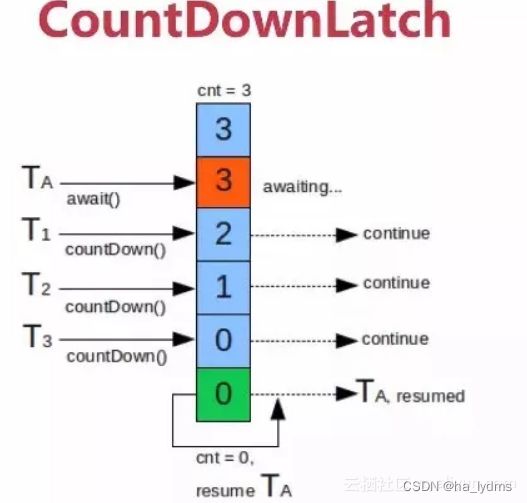
闭锁(CountDownLatch):让主线程等待一组事件发生后继续执行
- 事件指的是CountDownLatch里的countDown( )方法
- cnt为计数器

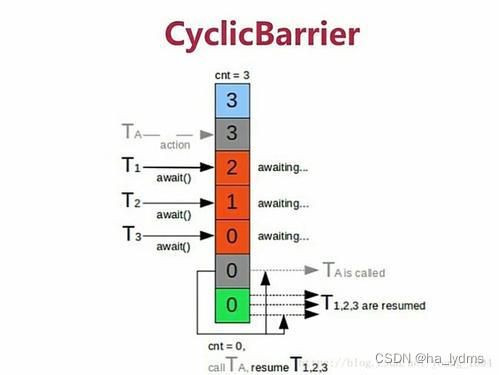
栅栏(CyclicBarrier):阻塞当前线程,等待其他线程
- 等待其它线程,且会阻塞自己当前线程,所有线程必须同时到达栅栏位置后,才能继续执行;
- 所有线程到达栅栏处,可以触发执行另外—个预先设置的线程.
- cnt为计数器
信号量(Semaphore):控制某个资源可被同时访问的线程个数


交换器(Exchanger):两个线程到达同步点后,相互交换数据。

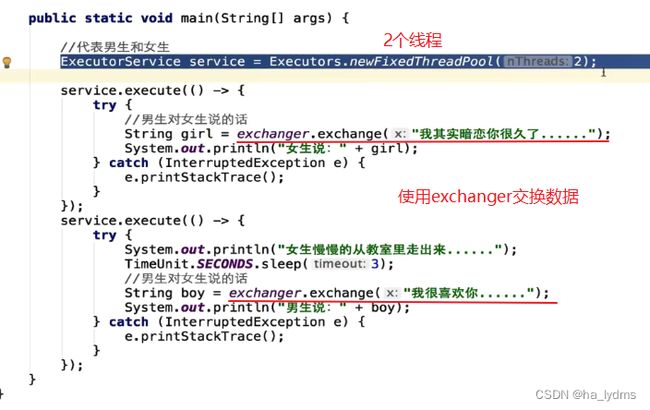
数据进行了交换:

9、Collections并发集合
Blocking Queue:提供可阻塞的入队和出队操作

尾插,成功true,失败抛异常
boolean add(E e);
尾插,满了则阻塞,直到添加成功
void put(E e) throws InterruptedException;
尾插,成功true,失败fal se
boolean offer (E e);
尾插,等待timeout时间添加数据
boolean offer(E e,long timeout,TimeUnit unit)throws InterruptedException;
从头获取数据,为空,则一直等待有元素再返回。
take(E e )throws InterruptedException;
从头部取数据,等待一段时间获取数据
poll(long timeout,TimeUnit unit)throws InterruptedException;
Blocking Queue
主要用于生产者-消费者模式,在多线程场景时生产者线程在队列尾部添加元素,而消费者线程则在队列头部消费元素,通过这种方式能够达到将任务的生产和消费进行隔离的目的
- Array Blocking Queue:一个由数组结构组成的有界阻塞队列;
- Linked Blocking Queue:一个由链表结构组成的有界/无界阻塞队列;
- Priority Blocking Queue:一个支持优先级排序的无界阻塞队列;
- DealyQueue:一个使用优先级队列实现的无界阻塞队列;
- SynchronousQueue:-个不存储元素的阻塞队列;
- Linked TransferQueue:一个由链表结构组成的无界阻塞队列;
- Linked Blocking Deque:一个由链表结构组成的双向阻塞队列;
10、Java的I/O机制
BIO、NIO、AIO区别
BIO:Block-I0: InputStream和outputStream, Reader和Writer
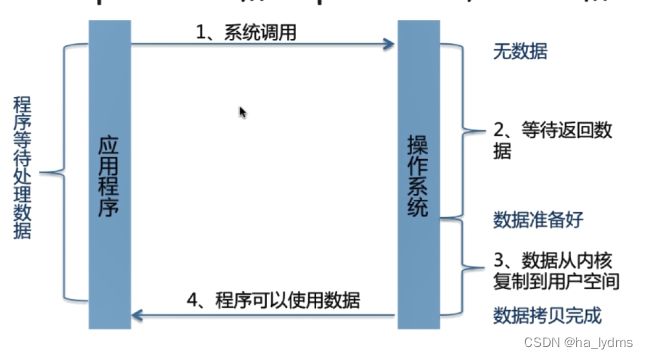
IO执行的阶段,线程是被阻塞的。
NIO:Non Block-Io:构建多路复用的、同步非阻塞的IO操作

NIO的核心
- Channels(通道)
- Buffers(缓冲)
- Selectors( 选择器)
Channels的下级分类
- Filechannel(文件通道)
transferTo:把 Filechannel中的数据拷贝到另外一个 Channel
transfer From:把另外一个 Channe中的数据拷贝到 Filechannel
避免了两次用户态和内核态间的上下文切换,即”零拷贝”,效率较高
- Datagram Channel
- Socketchannel(连接通道)
- Server Socketchanne↓
Buffers(缓冲)
- Byte Buffer
- Char Buffer
- Double Buffer
- FloatBuffer
- IntBuffer
- Long Buffer
- Short Buffer
- Mapped Byte Buffer(内存映射主键)
Selectors( 选择器)

IO多路复用:调用系统级别的 select、poll、epoll
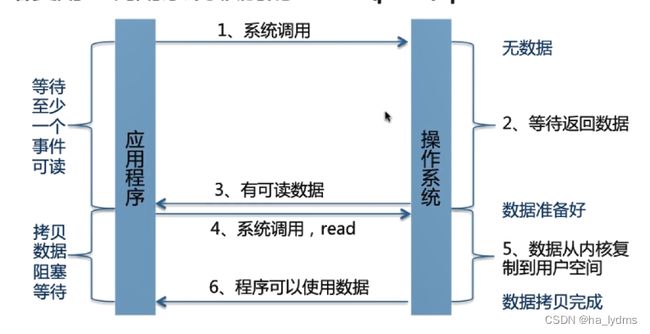
select、poll,epol的区别
支持一个进程所能打开的最大连接数
| select | 单个进程所能打开的最大连接数由FD_SETSIZE宏定义,其大小是32个整数的大小(在32位的机器上,大小是3232,64位机器上FD (SETSIZE为3264),我们可以对其进行修改,然后重新编译內核,但是性能无法保证,需要做进一步测试 |
|---|---|
| poll | 本质上与select没有区别,但是它没有最大连接数的限制,原因是它是基于链表来存储的 |
| epoll | 虽然连接数有上限,但是很大,1G内存的机器上可以打开10万左右的连接 |
FD(文件句柄)剧增后带来的IO效率问题
| select | 因为每次调用时都会对连接进行线性遍历,所以随着FD的增加会造成遍历速度的"线性下降"的性能问题 |
|---|---|
| poll | 同上 |
| epoll | 由于epoll是根据每个FD上的 callback函数来实现的,只有活跃的 socket才会主动调用 callback,所以在活跃 socket较少的情况下,使用epoll不会有"线性下降"的性能问题,但是所有 socket都很活跃的情况下,可能会有性能问题 |
消息传递方式
| select | 内核需要将消息传递到用户空间,需要內核的拷贝动作 |
|---|---|
| poll | 同上 |
| epoll | 通过内核和用户空间共享一块内存来实现,性能较高 |
AIO异步IO(Asynchronous IO:基于事件和回调机制)
AIO如何进一步加工处理结果
- 基于回调:实现 CompletionHandler接口,调用时触发回调函数。
- 返回 Future:通过idDone( )查看是否准备好,通过get( )等待返回数据
BO、NIO、AIO对比
| 属性\模型 | 阻塞BIO | 非阻塞NIO | 异步AIO |
|---|---|---|---|
| blocking | 阻塞并同步 | 非阻塞但同步 | 非阻塞并异步 |
| 线程数(server:client) | 1:1 | 1:N | 0:N |
| 复杂度 | 简单 | 较复杂 | 复杂 |
| 吞吐量 | 低 | 高 | 高 |