ClickHouse-OLAP列式数据库黑马
ClickHouse-OLAP列式数据库黑马
- ClickHouse概述
- 发展历程
- 社区发展
- 适用场景
- 优缺点
- 总结
ClickHouse是一个面向列的数据库管理系统(DBMS),用于在线分析处理查询(OLAP)。
ClickHouse官网:https://clickhouse.tech/
ClickHouse中文社区:http://www.clickhouse.com.cn/

ClickHouse概述
ClickHouse 是俄罗斯搜索巨头 Yandex 公司早 2016年 开源的一个极具 " 战斗力 " 的实时数据分析数据 库,是一个用于联机分析 (OLAP:Online Analytical Processing) 的列式数据库管理系统 (DBMS:Database Management System),简称 CK,工作速度比传统方法快100-1000倍,ClickHouse 的性能超过了目前市场上可比的面向列的DBMS。 每秒钟每台服务器每秒处理数亿至十亿多行和数十千 兆字节的数据。它允许在运行时创建表和数据库,加载数据和运行查询,而无需重新配置和重新启动服 务器,支持线性扩展,简单方便,高可靠性,容错。
ClickHouse 作为一个高性能 OLAP 数据库,虽然OLAP能力逆天但也不应该把它用于任何OLTP事务性 操作的场景,相比OLTP:不支持事务、不擅长根据主键按行粒度的查询、不擅长按行删除数据,目前 市场上的其他同类高性能 OLAP 数据库同样也不擅长这些方面。因为对于一款OLAP数据库而言,OLTP 能力并不是重点。
ClickHouse从OLAP场景需求出发,定制开发了一套全新的高效列式存储引擎,并且实现了数据有序存 储、主键索引、稀疏索引、数据Sharding、数据Partitioning、TTL、主备复制等丰富功能。这些功能共 同为ClickHouse极速的分析性能奠定了基础。
ClickHouse适合流式或批次入库的时序数据。ClickHouse不应该被用作通用数据库,而是作为超高性能 的海量数据快速查询的分布式实时处理平台,在数据汇总查询方面(如GROUP BY),ClickHouse的查询 速度非常快。
典型特点总结:
ROLAP、在线实时查询、完整的DBMS、列式存储、不需要任何数据预处理、支持批量 更新、具有非常完善的SQL支持和函数、支持高可用、不依赖Hadoop复杂生态、开箱即用
简单的说,ClickHouse作为分析型数据库,有三大特点:一是跑分快, 二是功能多 ,三是文艺范
1、跑分快: ClickHouse跑分是Vertica的5倍快:
clickHouse性能超过了市面上大部分的列式存储数据库,相比传统的数据ClickHouse要快100-1000X, ClickHouse还是有非常大的优势:
–100Million 数据集:ClickHouse比Vertica约快5倍,比Hive快279倍,比MySQL快801倍
–1Billion 数据集:ClickHouse比Vertica约快5倍,MySQL和Hive已经无法完成任务了
2、功能多:ClickHouse支持数据统计分析各种场景
–支持类SQL查询, 支持繁多库函数(例如IP转化,URL分析等,预估计算/HyperLoglog等)
–支持数组(Array)和嵌套数据结构(Nested Data Structure)
–支持数据库异地复制部署+支持分布式
3、文艺范:目前ClickHouse的限制很多,生来就是为小资服务的
—相对较缺乏的文档,社区刚开始活跃,只有开源的C++源码
–不理睬Hadoop生态,走自己的路
发展历程

社区发展
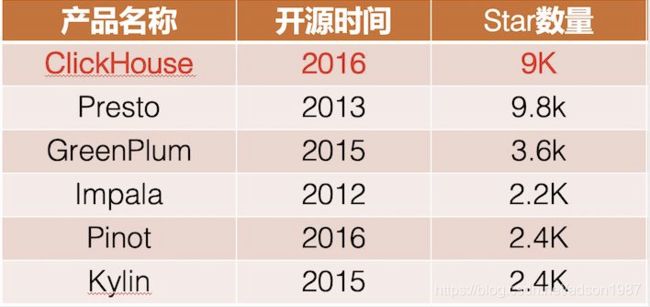
适用场景
适用场景:
1、Web和App数据分析
2、广告网络和RTB
3、电信
4、电子商务和金融
5、信息安全
6、监测和遥测
7、时序数据
8、商业智能
9、在线游戏
10、物联网
不适用场景:
1、事务性工作(OLTP)
2、高并发的键值访问
3、Blob或者文档存储
4、超标准化的数据
优缺点
与 Hadoop、Spark 这些巨无霸组件相比,ClickHouse 具有轻量级的优点,它的特点包括以下内容:
1、真正的面向列的 DBMS
ClickHouse 是一个 DBMS,而不是一个单一的数据库。它允许在运行时创建表和数据库、加载数据和运行 查询,而无需重新配置和重新启动服务器。
2、数据压缩
一些面向列的 DBMS(InfiniDB CE 和 MonetDB)不使用数据压缩。但是,数据压缩确实提高了性能。
3、磁盘存储的数据
许多面向列的 DBMS(SAP HANA 和 GooglePowerDrill)只能在内存中工作。但即使在数千台服务器 上,内存也太小,无法在 Yandex.Metrica 中存储所有浏览量和会话。
4、多核并行处理 多核多节点并行化大型查询。
5、在多个服务器上分布式处理
在 ClickHouse 中,数据可以驻留在不同的分片上。每个分片都可以用于容错的一组副本,查询会在所有分 片上并行处理。
6、SQL支持
ClickHouse SQL 跟真正的 SQL 有不一样的函数名称。不过语法基本跟 SQL 语法兼容,支持 JOIN、 FROM、IN 和 JOIN 子句以及标量子查询支持子查询。
7、向量化引擎
数据不仅按列存储,而且由矢量 - 列的部分进行处理,这使开发者能够实现高 CPU 性能。
8、实时数据更新
ClickHouse 支持主键表。为了快速执行对主键范围的查询,数据使用合并树 (MergeTree) 进行递增排 序。由于这个原因,数据可以不断地添加到表中。
9、支持近似计算(很多组件不具备的)统计全中国到底有多少人?1434567654 14.3E PV 近似计算 UV 具体的值 该库支持为有限数量的随机密钥(而不是所有密钥)运行聚合。在数据中密钥分发的特定条件下,这提供了相 对准确的结果,同时使用较少的资源。
10、数据复制和对数据完整性的支持。
ClickHouse 使用异步多主复制。写入任何可用的副本后,数据将分发到所有剩余的副本。系统在不同的副 本上保持相同的数据。数据在失败后自动恢复。 扩展成为分布式的数据库OLAP引擎,严重依赖于zookeeper
缺点:
ClickHouse 作为一个被设计用来在实时分析的 OLAP 组件,只是在高效率的分析方面性能发挥到极 致,那必然就会在其他方面做出取舍:
1、没有完整的事务支持,不支持Transaction:想快就别想Transaction
2、缺少完整的Update/Delete操作,缺少高频率、低延迟的修改或删除已存在数据的能力,仅能用于批量删
除或修改数据。
3、聚合结果必须小于一台机器的内存大小:不是大问题
4、支持有限操作系统,正在慢慢完善 (windows暂不支持)
5、开源社区刚刚启动,主要是俄语为主,中文社区:http://www.clickhouse.com.cn
6、不适合key-value存储,不支持 Blob 等文档型数据库
总结
近年来ClickHouse发展趋势迅猛,社区和大厂都纷纷跟进使用。ClickHouse实现了大多数当前主流的数 据分析技术,具有明显的技术优势:
相比于开源社区的其他几项分析型技术,如 Druid、Presto、Impala、Kylin、ElasticSearch 等, ClickHouse 更是一整套完善的解决方案,它自包含了存储和计算能力(无需额外依赖其他存储组 件),完全自主实现了高可用,而且支持完整的 SQL 语法包括 JOIN 等,技术上有着明显优势。
相比于 Hadoop体系,以数据库的方式来做大数据处理更加简单易用,学习成本低且灵活度高。当前社 区仍旧在迅猛发展中,相信后续会有越来越多好用的功能出现。