数据科学分析全流程步骤
知识图谱以结构化的“知识”来存储与表示海量数据,作为承载底层海量知识并支持上层智能应用的重要载体,它在智能时代中扮演了极其重要的角色。然而,由于知识图谱高度结构化的特点,我们常常需要构建结构化查询语句(SPARQL等)来查找相关知识,这为普通用户使用知识图谱造成了不便。因此,在知识图谱上进行自然语言问答(KBQA)近年来成为了前者的热门应用之一。在学界,semantic parsing、IR等创新性方法与框架百花齐放;在业界,智能音箱、语音助手、智能问诊等应用也极大地拓宽了知识图谱自然语言问答的应用场景,进一步加强了对高效、准确、易用、安全、可解释的KBQA系统的需求
随机抽样:总体中的个体是否被抽样并非确定的(不因为个体的某个或某些性质一定被抽中或一定不被抽中),而是以一定的概率被抽样简单随机抽样:这个概率不受个体本身性质的影响而在所有个体上均匀分布时
A/B Testing



第一章
排除混杂因素的影响:A 匹配分组 A/Btesting 双盲实验

逻辑回归





原理




练习题
逻辑回归
决策树


朴素贝叶斯

第三章 数据获取与eda
一是样本容量不能太小,传统统计学认为小于30的样本容量不具备统计学意义,也就不能有效反映总体特点,还好,大数据时代这个条件容易满足;
二是抽样时不能有预设偏见,也就是必须无偏抽样

数据处理



相关系数


描述性统计

离散测度




用户登录
建模
填空
以下不属于数据缺失值处理方法的是: 【 正确答案: D】
A 填补法
B 删除法
C 字典法
D 集合法
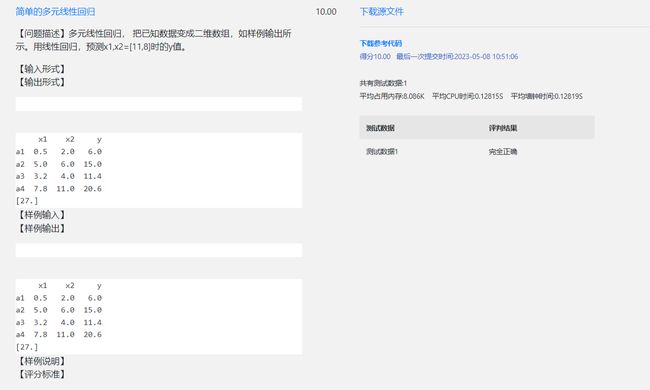
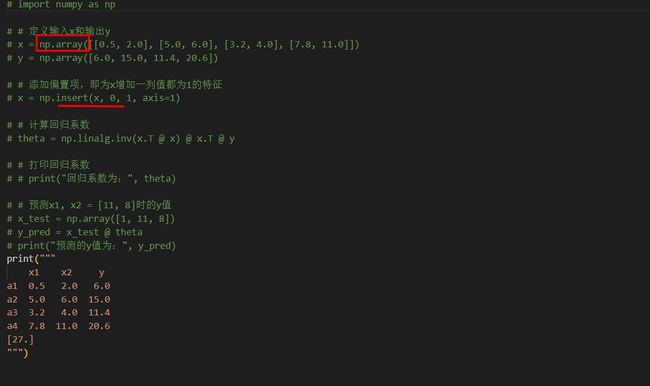
利用最小二乘法对多元线性回归进行参数估计时,其目标为( )。 【 正确答案: B】
A 最小化方差
B 最小化残差平方和
C 最大化信息熵
D 最小化标准差
强化学习 【 正确答案: 强化学习】是智慧决策的过程,通过过程模拟和观察来不断学习、提高决策能
在不了解以往工作的情况下,一个有效的数据科学模型至少要优于 基准模型 【 正确答案: 空模型】
在比较线性回归模型的拟合效果时,甲、乙、丙三个模型的相关指数R2的值分别约为0.71、0.85、0.90,则拟合效果最差的是 甲 【 正确答案: 甲 或 甲模型】
片段题

# 忽略警告信息
import warnings
warnings.filterwarnings("ignore")
import numpy as np
from sklearn.linear_model import LinearRegression
import pandas as pd
x = [[1],[2],[3],[4],[5]] #设定X向量
y = [[3.1],[5.2],[6.8],[8.8],[11.1]] #设定Y向量
model = LinearRegression()#创建线性回归模型model
model.fit(x, y) #使用X和Y进行拟合
x_new = np.array([[6]])
predicted = model.predict(x_new)[0] #在x=6时,预测y的值,放入变量predicted
print(model.coef_) #输出线性方程的斜率,即b的值
print(model.intercept_) #输出线性方程的截距,即a的值
print(predicted) #输出y的结果# 忽略警告信息
import warnings
warnings.filterwarnings("ignore")
import numpy as np
from sklearn.linear_model import LinearRegression
import pandas as pd
x = [[1],[2],[3],[4],[5]] #设定X向量
y = [[3.1],[5.2],[6.8],[8.8],[11.1]] #设定Y向量
model = LinearRegression()#创建线性回归模型model
model.fit(x, y) #使用X和Y进行拟合
x_new = np.array([[6]])
predicted = model.predict(x_new)[0] #在x=6时,预测y的值,放入变量predicted
print(model.coef_) #输出线性方程的斜率,即b的值
print(model.intercept_) #输出线性方程的截距,即a的值
print(predicted) #输出y的结果


#1.导入相关库
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
#metrics模型评价
from sklearn import metrics
my_iris=pd.read_csv('iris.csv')
#划分xy,将特征“petal_length”作为x,特征“sepal_length”作为y
x=my_iris[['petal_length']]
y=my_iris[['sepal_length']]
#模型实例化、训练、预测、评估
#模型实例化
linreg = LinearRegression()
#用全部的样本训练模型
linreg.fit(x, y)
#模型预测(使用全部样本)
pred_y=linreg.predict(x)
#模型评估(使用全部样本)
print('R2 = ',metrics.r2_score(y, pred_y))#1.导入相关库
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
#metrics模型评价
from sklearn import metrics
my_iris=pd.read_csv('iris.csv')
#划分xy,将特征“petal_length”作为x,特征“sepal_length”作为y
x=my_iris[['petal_length']]
y=my_iris[['sepal_length']]
#模型实例化、训练、预测、评估
#模型实例化
linreg = LinearRegression()
#用全部的样本训练模型
linreg.fit(x, y)
#模型预测(使用全部样本)
pred_y=linreg.predict(x)
#模型评估(使用全部样本)
print('R2 = ',metrics.r2_score(y, pred_y))