python笔记
python学习
目录
Python基础语法
flask本地部署
flask vmware-linux部署
django
Python基础语法
1,数据类型
python3中有六个标准的 数据类型:
Number(数字)
String(字符串)
List(列表)
Tuple(元组)
Set(集合)
Dictionary(字典)


语法:
1. int(): 将其他数据类型转换为整型
str1 = "12"
print(int(str1)) # 12
print(int(str1,base=16)) # 18 表示将字符串12以16进制的形式转换为整型.
2.str(): 将其他数据类型转换为字符串
num = 12
num1 = 87
# print(num1 + num) # 99
# print(type(num)) #
# print(type(num1)) #
str1 = str(num)
str2 = str(num1)
3.float(): 将其他数据类型转换为浮点型
float1 = "12.34"
# print(type(float1)) #
# print(type(float(float1))) #
float2 = "hello123" # 不能转换为浮点型
print(float(float2)) # 报错
4.bool() : 用于将给定参数转换为布尔类型.如果没有参数,返回False
# 布尔类型: True 和 False
# bool(): 将其他数据类型转换为布尔类型
print(bool(100)) # True
print(bool(3.12)) # True
print(bool(0)) # False
print(bool("hello")) # True
print(bool('')) # False
print(bool("")) # False
print(bool(' ')) # True
print(bool([12,34,7])) # True
5.list() : 用于将其他数据类型转换为列表.
tup = (12,34,678,9)
# print(tup)
# print(type(tup)) #
# print(type(list(tup))) #
list1 = list(tup)
# print(list1) # [12, 34, 678, 9]
str = "hello"
list2 = list(str)
# print(list2) # ['h', 'e', 'l', 'l', 'o']
num = 12
# print(list(num)) 报错
注意:
一般情况下,是字符串和元组类型的数据转换为列表类型居多
6.tuple() : 用于将其他类型的数据转换为元组
print(bool([])) # False
print(bool((32,45,67))) # True
print(bool({"name":"三哥","age":18})) # True
print(bool(())) #False
print(bool({})) # False
print(bool(None)) # False
# 数字0,空字符串""或者'',空列表[],空元组(),空字典{},空集合set(),None这些数据转换为bool类型
时是False.
# 隐式类型转换 一般用于条件表达式 if if..else.
print(3 > 2) # True
print(98 < 87) # False
num = 12
if num: # num在这里隐式转换为True
print("num是一个数字")
7.list() : 用于将其他数据类型转换为列表
tup = (12,34,678,9)
# print(tup)
# print(type(tup)) #
# print(type(list(tup))) #
list1 = list(tup)
# print(list1) # [12, 34, 678, 9]
str = "hello"
list2 = list(str)
# print(list2) # ['h', 'e', 'l', 'l', 'o']
num = 12
# print(list(num)) 报错
注意:
一般情况下,是字符串和元组类型的数据转换为列表类型居多.
8.1str(字符串)
# 创建字符串
str = "apple"
str1 = 'orange'
print(type(str),type(str1))
# \ 转义字符 作用:让一些符号失去原有的意义
str2 = "\"吴亦凡\""
str3 = '\'都美竹\''
print(str2,str3)
# 定义字符串的时候,单双引号可以互相嵌套
str4 = "凡哥,'这次车翻的有点厉害'"
print(str4)
8.2字符串特殊处理:
字符串前加 r
r"" 的作用是去除转义字符.
即如果是“\n”那么表示一个反斜杠字符,一个字母n,而不是表示换行了。
以r开头的字符,常用于正则表达式,对应着re模块。
字符串前加f
# 以 f开头表示在字符串内支持大括号内的python 表达式
print(f'{name} done in {time.time() - t0:.2f} s')
字符串前加b
b" "前缀表示:后面字符串是bytes 类型。网络编程中,服务器和浏览器只认bytes 类型数据。
字符串前加u
例:u"我是含有中文字符组成的字符串。"
后面字符串以 Unicode 格式 进行编码,一般用在中文字符串前面,防止因为源码储存格式问题,导致再次
使用时出现乱码。
8.3字符串的下标和切片
下标:也叫索引,表示第几个数据
在程序中,下标一般从0开始,可以通过下标获取指定位置的数据
str1 = "welcome"
print(str1[0]) # w
print(str1[3]) # c
切片:从字符串中复制一段指定的内容,生成一个新的字符串
str2 = "welcome to beijing"
'''
切片的语法:
字符串[start:end:step]
start 表示开始下标 截取的字符串包含开始下标对应的字符串
end表示结束下标
step表示步长
'''
print(str2[0:3]) # wel 包含start 不包含end
print(str2[1:] # 若只设置了start 表示从开始下标一直截取到最后
print(str2[:4]) # 若只设置了end 表示从第一个字符开始一直截取到指定结束的位置
print(str2[1:4:2]) # ec
print(str2[1:4:0]) # 在切片的时候,步长不能设置为0
print(str2[::]) # 若未设置开始和结束,表示复制字符串
print(str2[::-1]) # 表示翻转字符串
print(str2[-9:-3]) #start和end若都为负数,表示从右边开始数
11获取长度和次数
str3 = "凡哥,'这次车翻的有点厉害'"
# 获取字符串的长度 len()
print(len(str3))
# count() 在整个字符串中查找子字符串出现的次数
str = "电脑卡了,ss电脑呢?"
print(str.count("电脑")) # 3
#在指定区间内查找出现的次数
print(str.count("电脑",5,30)) # 2
8.4字符串查找:
# find() 查找子串在字符串中第一次出现的位置, 返回的是下标,若未找到返回-1
ss3 = "123asdfASDCXaZ8765sahbzcd6a79"
print(ss3.find("a")) # 3
print(ss3.find("y")) # -1 未找到子串,返回-1
# 在指定区间内查找
print(ss3.find("a",5,20)) # 12
# rfind 查找子串在字符串中最后一次出现的位置,返回的是下标,若未找到返回-1
print(ss3.rfind("a")) # 25
print(ss3.rfind("y")) # -1
# index() 功能和find类似 在字符串中未找到的时候,直接报错
print(ss3.index("d")) # 5
# print(ss3.index("y")) # ValueError: substring not found
#
# max() min() 依据ASCII 码进行的获取
print(max(ss3)) # z
print(min(ss3)) # 1
8.5大小写转换
# 2.字符串大小写转换 upper() lower()
# upper()将字符串中的小写字母转换为大写
str1 = "i Miss you Very Much!"
print(str1.upper()) # I MISS YOU VERY MUCH!
# lower() 将字符串中的大写字母转化为小写
print(str1.lower()) # i miss you very much!
# swapcase 将字符串中的大写转换为小写,将小写转换为大写
print(str1.swapcase()) # I mISS YOU vERY mUCH!
# title() 将英文中每个单词的首字母转换为大写
str2 = "i love you forever!"
print(str2.title()) # I Love You Forever!
8.6提取
# strip() 去除字符串两边的指定字符(默认去除的是空格)
ss4 = " today is a nice day "
ss5 = "***today is a nice day****"
print(ss4)
print(ss4.strip())
print(ss5)
print(ss5.strip("*"))
x
# lstrip 只去除左边的指定字符(默认去除的是空格)
# print(ss5.lstrip("*"))
# rstrip 只去除右边的指定字符(默认去除的是空格)
print(ss5.rstrip("*"))
8.7分割和合并
# split() 以指定字符对字符串进行分割(默认是空格)
ss6 = "this is a string example.....wow!"
print(ss6.split()) # 以空格进行分割 ['this', 'is', 'a', 'string',
'example.....wow!']
print(ss6.split("i"))
# splitlines() 按照行切割
ss7 = '''将进酒
君不见黄河之水天上来,
奔流到海不复回.
君不见高堂明镜悲白发,
************.
'''
print(ss7)
print(ss7.splitlines())
# join 以指定字符进行合并字符串
ss8 = "-"
tuple1 = ("hello","every","body")
print(tuple1)
print(ss8.join(tuple1)) # hello-every-body
8.8替换
# 替换
replace() 对字符串中的数据进行替换
ss9 = "AAAAAAAAAAAAAAAAAAAABBBBBBBBBBBBBBBBBBBBBBB"
print(ss9)
print(ss9.replace("AAAAA","***"))
# 控制替换的字符的次数
print(ss9.replace("AAAAA","***",2))
8.9判断
# 字符串判断
# isupper() 检测字符串中的字母是否全部大写
print("ASDqwe123".isupper()) # False
print("ASD123".isupper()) # True
# islower() 检测字符串中的字母是否全部小写
print("ASDqwe123".islower()) # False
print("qwe123".islower()) # True
# isdigit() 检测字符串是否只由数字组成
print("1234".isdigit()) #True
print("1234asd".isdigit()) # False
#istitle() 检测字符串中的首字母是否大写
print("Hello World".istitle()) # True
print("hello everybody".istitle()) # False
# isalpha() 检测字符串是否只由字母和文字组成
print("你好everyone".isalpha()) # True
print("你好everyone123".isalpha()) # False
# isalnum()
8.10前缀和后缀(重点)
# 前缀和后缀 判断字符串是否以指定字符开头或者以指定字符结束
# startswith() 判断字符串是否以指定字符开头
# endwith() 判断字符串是否以指定字符结束
s1 = "HelloPython"
print(s1.startswith("Hello")) # True
print(s1.endswith("thon")) # True
8.11编解码
# encode() 编码
# decode() 解码
s2 = "hello 千锋教育"
print(s2.encode()) # b'hello
\xe5\x8d\x83\xe9\x94\x8b\xe6\x95\x99\xe8\x82\xb2'
print(s2.encode("utf-8")) # b'hello
\xe5\x8d\x83\xe9\x94\x8b\xe6\x95\x99\xe8\x82\xb2'
print(s2.encode("gbk")) # b'hello \xc7\xa7\xb7\xe6\xbd\xcc\xd3\xfd'
# 解码
s3 = b'hello \xe5\x8d\x83\xe9\x94\x8b\xe6\x95\x99\xe8\x82\xb2'
print(s3.decode()) #
8.12ASCII码转换
chr() 将对应的ASCII码的值转换为对应的字符
ord() 获取对应字符的ASCII的值
print(chr(68)) # D
print(ord("a")) # 97
8.13格式化输出
# 字符串格式化输出
'''
% 占位符
%d 表示整数
%f 表示小数
%s 表示字符串
%.3f (表示保留3位小数,保留的小数数位自己可以控制)
'''
name = "畅总"
sex = "型男"
money = 198987932.787532
print("我的姓名是:%s"%name)
print("我的大号是%s,性别是%s,我的财富是%.2f"%(name,sex,money))
# 还可以通过 f"{}{}"这种方式实现格式化输出
print(f"我的大号是:{name},性别是:{sex},我的财富是{money}")
9.1.list(列表)
list1 = ["幻影","兰博基尼","迈巴赫","玛莎拉蒂","布加迪威龙","红
旗","唐","宋","元","汉","秦",123,True]
print(list1)
9.2创建列表
1.创建列表
list1 = [] 空列表
2.带元素的列表
list2 = ["五菱宏光","哈弗H6","大狗","欧拉",True]
3.列表中的元素可以是不同的数据类型
list3 = [12,3.13,True,False,"hello","米西米西"]
注意: 将数据保存到列表的时候,不用考虑列表的大小,如果数据很大的话,底层会进行自动扩容.
9.3获取元素
访问方式:通过索引访问列list2 = ["五菱宏光","哈弗H6","大狗","欧拉",True]
list2[0] 表示第一个元素
list2[-1] 表示最后一个元素
len(list2) 表示获取列表元素的个数
list2[11]
表中的元素【有序,索引:决定了元素在内存中的位置】
9.4替换元素(修改元素的值)
list2 = ["五菱宏光","哈弗H6","大狗","欧拉",True]
# 修改列表元素 语法:列表名[索引] = 值
print(list2)
list2[2] = "天狗"
print(list2)
9.5遍历列表
list3 = ["肠粉","佛跳墙","白切鸡","云吞"]
'''
# 第一种方式:
for i in list3:
print(i)
# 第二种方式: 通过索引的方式访问元素
for i in range(len(list3)):
print(list3[i])
'''
# 第三种方式:enumrate() 同时遍历索引和元素
for index,value in enumerate(list3):
print(index,value)
9.6列表元素组合
合并列表: 通过 + 实现
list = [12,34,6,8,3.13]
list1 = ["荔枝","龙眼","桂圆","榴莲","芒果"]
print(list,list1)
# 通过 + 实现列表的合并 list + list1
list2 = list + list1
print(list2)
9.7列表元素重复
重复输出列表中的元素: 通过 * 实现
list = [1,2,3]
list1 = list * 4
print(list1)
9.10判断元素是否在列表中
判断指定元素是否在列表中,使用成员运算符检查 in 和 not in 返回值是一个布尔类型
True和False
list1 = [12,34,4.12,"haha","lele","hehe"]
print(12 in list1) # True
if "haha" in list1:
print("字符串在列表中")
else:
print("不在列表中")
9.11列表截取【切片】
list2 = [13,45,2,35,7,9]
# 语法: 列表名[开始下标:结束下标] 特点: 前闭后开 包含开始下标的元素不包含结束下标的元
素
print(list2[1:6])
print(list2[:4]) # [13, 45, 2, 35]
print(list2[1:]) # [45, 2, 35, 7, 9]
print(list2[:]) # [13, 45, 2, 35, 7, 9]
print(list2[-2:]) # [7, 9]
9.12列表的功能【掌握】
# 1.添加元素
'''
# a. append() 向列表的尾部追加元素
list1 = ["香妃","妲己","赵飞燕","杨贵妃","东施"]
print(list1)
# 追加单个元素
list1.append("西施")
# 追加多个元素的时候,不能直接追加,必须使用列表的方式追加,原列表变成了二维列表
list1.append(["王昭君","貂蝉","大小乔"])
print(list1)
# b.extend 用于在列表末尾一次追加另一个列表中的多个元素
list1 = ["香妃","妲己","赵飞燕","杨贵妃","东施"]
list1.extend(["乾隆","商纣王","汉昭帝","唐玄宗","解博超"])
list1.extend("秦始皇") # "秦" "始" "皇"
print(list1)
# c.insert() 在列表中指定的索引处插入元素,后面的其他的元素依次后延
list2 = ["秦始皇","汉武帝","曹操","刘备","孙权"]
list2.insert(1,"刘邦")
# 若想一次性插入多个元素使用列表的形式插入 原列表会变为二维列表
list2.insert(3,["诸葛亮","马超"])
print(list2)
'''
#2. 删除元素
list2 = ["秦始皇","汉武帝","曹操","刘备","孙权"]
'''
# pop() 传输的参数是下标 不传参数的时候,默认移除最后一个元素,返回的是原列表
print(list2)
# list2.pop() ["秦始皇","汉武帝","曹操","刘备"]
list2.pop(2) # ['秦始皇', '汉武帝', '刘备', '孙权']
print(list2)
'''
'''
# remove() 传输的参数是指定移除的元素
list2.remove("刘备")
print(list2)
'''
# clear() 清空列表
print(list2)
list2.clear()
print(list2) # []
3.获取元素
list = [12,34,2,5.23,True,False,"hello"]
# print(len(list)) # len 获取列表的长度
# 获取列表中的最大值 max()
list1 = [12,3,4,32,98,14,3,78,3,34,3]
# print(max(list1))
# 获取列表中的最大值 min()
# print(min(list1))
# 获取指定元素的索引 index(元素名称)
# print(list1.index(98))
4.其他用法
# 列表的其他用法
list = [12,42,34,16,87]
# print(list)
# reverse 翻转列表元素 注意:在原列表的内部进行翻转,不会生成新列表
# list.reverse()
# print(list)
# sort() 对原列表元素进行排序 默认是升序 不会生成一个新的列表
# 升序
# list.sort()
# 降序 在sort函数中传入reverse=True 实现降序
# list.sort(reverse=True)
# print(list)
# sorted() 对列表元素进行排序,默认是升序, 排序的结果会生成一个新列表
# 升序
# list1 = sorted(list)
# 降序 传入reverse=True
list1 = sorted(list,reverse=True)
#print(list1)
list2 = ["a","hello","abe","bc","everyone"]
# 按照元素的长度进行排序
list3 = sorted(list2,key=len)
print(list3)
9.13二维列表
list = [12,34,6,7,"boy",True] # 一维列表
list1 = [32,14,"girl",False,[16,31,9.12,"haha"]] #二维列表
print(list1[1]) # 14
print(list1[4][2]) # 9.12
9.14列表生成式
list comprehension
系统内置的用于创建list的方式
range(start,end,step)缺点:生成的列表一般情况下都是等差数列
# 最基本的列表
# 1.生成1-10之间所有的数字
list1 = list(range(1,11))
print(list1)
# 需求:通过程序的方式生成列表 [1,4,9,16,25]
#第一种方法:使用原始的方式生成
list2 = []
for i in range(1,6):
list2.append(i ** 2)
print(list2)
# 第二种方法:使用列表生成式
list3 = [i**2 for i in range(1,6)]
print(list3) # [1, 4, 9, 16, 25]
# 使用列表生成式 生成1-10之间所有的奇数
list4 = [i for i in range(1,11) if i % 2 == 1]
print(list4)
# 使用列表生成式 生成1-10之间所有的奇数并且能被3整除的数字
list5 = [i for i in range(1,11) if i % 2 == 1 and i % 3 == 0]
print(list5)
# 列表生成式中使用双重循环
list6 = [i + j for i in "xyz" for j in "987"]
print(list6)
# 字典生成式:(了解)
dict1 = {i:i*i for i in range(1,6)}
print(dict1)
# 集合生成式:(了解)
set1 = {i*i for i in range(1,6)}
print(set1)
10.1.dict(字典)
列表和元组的使用缺点:当存储的数据要动态添加、删除的时候,我们一般使用列表,但是列表
有时会遇到一些麻烦
解决方案:既能存储多个数据,还能在访问元素的很方便的定位到需要的元素,采用字典
语法: {键1: 值1, 键2: 值2, 键3: 值3, ..., 键n: 值n}
说明:键值对: key-value
字典和列表类似,都可以用来存储多个数据
在列表中查找某个元素时,是根据下标进行的;字典中找某个元素时,是根据'名字'(就是
冒号:前面的那个值,例如上面代码中的'name'、'id'、'sex')
字典中的每个元素都由2部分组成,键:值。例如 'name':'班长' ,'name'为键,'班长'为值
键可以使用数字、布尔值、元组,字符串等不可变数据类型,但是一般习惯使用字符串,切
记不能使用列表等可变数据类型
每个字典里的key都是唯一的,如果出现了多个相同的key,后面的value会覆盖之前的value
习惯使用场景:
列表更适合保存相似数据,比如多个商品、多个姓名、多个时间
字典更适合保存不同数据,比如一个商品的不同信息、一个人的不同信息
10.2定义字典
# 1.定义空字典 {}
dict1 = {}
print(type(dict1)) #
#2.定义非空字典
# 第一种定义字典的方式
dict2 = {"name":"小解","age":25,"love":"女","sex":"**"} # 最常用
print(dict2)
print(type(dict2))
print(dict2["name"],dict2["love"]) # 访问字典
# 第二种定义字典的方式 dict(key=value,key1=value1,...) key表示键 value表示值
dict3 = dict(num1 = "123",num2 = "987")
print(dict3)
# 第三种定义字典的方式
# dict(zip([key1,key2,key3....],[value1,value2,value3......]))
# 注意:key和value的数量不一致时,以数量少的为基准
dict4 = dict(zip(['n1','n2','n3'],[12,34,56]))
dict5 = dict(zip(['n1','n2','n3'],[12,34,56,45,67,89]))
print(dict4)
print(dict5)
# 第四种方式:
dict6 = dict([("a",10),("b","98"),("c",67),("d",34)])
print(dict6) # {'a': 10, 'b': '98', 'c': 67, 'd': 34}
10.3字典的操作
# 1.访问字典中的元素
# 第一种方式: 直接通过下标访问
dict1 = {"name":"中国医生","author":"刘伟强","person":"张涵予"}
print(dict1['author'])
# print(dict1['money']) # 访问字典中不存在的key时,直接报错
# 第二种方式:通过get()方法获取
print(dict1.get('name'))
print(dict1.get('money')) # None 访问字典中不存在的key时,返回None
print(dict1.get('money',10000000)) # 访问字典中不存在的key时,若传递了第二个参数,第二个
参数会设置为默认值,
#2. 获取字典的长度 len()
print(len(dict1))
# 3.获取字典中所有的key
print(dict1.keys()) # dict_keys(['name', 'author', 'person'])
# 4.获取字典中所有的value
print(dict1.values()) # dict_values(['中国医生', '刘伟强', '张涵予'])
# 5.获取字典中的所有的key和value items()
print(dict1.items()) # dict_items([('name', '中国医生'), ('author', '刘伟强'),
('person', '张涵予')])
# 6.遍历字典
'''
# 第一种方式: for in
for i in dict1: # 遍历字典中所有的key
print(i)
# 第二种方式:enumrate() 遍历字典中所有的key
for k,v in enumerate(dict1):
print(k,'----',v)
# 第三种方式: items 遍历字典中所有的key和value
for k,v in dict1.items():
print(k,'----',v)
# 第四种方式:遍历 字典中所有的值
for v in dict1.values():
print(v)
# 合并字典 update()
dict2 = {"name":"袁建鑫","money":"1999999","age":23}
dict3 = {"sex":"猛男"}
dict2.update(dict3)
print(dict2)
'''
dict4 = {"name":"iPhone13","money":20000,"color":"土豪金"}
# 增
dict4["size"] = 6.5
print(dict4)
# 改
dict4['color'] = "骚粉"
print(dict4)
# 删
# 第一种:pop() 删除指定的元素
#dict4.pop("color")
print(dict4)
# 第二种:popitem() 随机返回并删除字典中的最后一对key和value
dict4.popitem()
print(dict4)
# clear() 清空字典
dict4.clear()
print(dict4)
11.1set集合
和数学上的集合基本是一样的,
特点:不允许有重复元素,可以进行交集,并集,差集的运算
本质:无序,无重复元素的集合
11.22创建
# 创建空集合
set1 = set()
print(set1)
print(type(set1)) #
# 创建包含元素的集合
set2 = {12,345,633,21}
set3 = {"hello","world","everyone"}
print(set2,set3)
print(type(set2)) #
11.3操作
# 获取集合的长度 len()
print(len(set2)) # 4
# 集合不能通过下标访问元素
# print(set2[3])
11.4添加
set2 = {12,345,633,21}
# 向集合中添加一个元素 add()
set2.add(98)
print(set2)
# 通过update() 向集合中添加多个元素 追加的元素以列表的形式出现
set2.update([1,2,3])
print(set2)
11.5删除
set2 = {12,345,633,21}
# pop() 随机删除一个
set2.pop()
print(set2)
# remove() 删除指定的元素,传入的参数是要删除的元素,如果删除的元素不存在,会报错
# set2.remove(22)
set2.remove(2)
print(set2)
# discard()删除指定的元素,传入的参数是要删除的元素,如果删除的元素不存在,不会报错
set2.discard(21)
# set2.discard(22)
print(set2)
# clear() 清空集合
set2.clear()
#print(set2)
11.6遍历
set2 = {12,345,633,21}
for i in set2:
print(i)
11.7交集和并集
# 集合之间的关系
set5 = {12,34,56,23,86s}
set4 = {23,45,25,12,41}
print(set5 & set4) # 交集
print(set5 - set4) # 差集
print(set5 | set4) # 并集
print(set4 > set5) # set4是否包含set5
print(set4 < set5) # set5是否包含set4
12.1元组(tuple)
a.列表:[ ] 元组:( )
b.列表中的元素可以进行增加和删除操作,但是,元组中的元素不能修改【元素:一旦被初始化,将不
能发生改变】
12.2创建元组
创建空列表:list1 = [ ]
创建有元素的列表:list1 = [元素1,元素2,。。。。。]
创建空元组:tuple1 = ( )
创建有元素的元组:tuple1 = (元素1,元素2,。。。。)
# 1.创建空元组
tuple1 = ()
print(type(tuple1)) #
# 2.创建带有元素的元组
tuple2 = (12,34,6,87)
print(tuple2)
print(type(tuple2)) #
# 3.元组中的元素可以是各种类型
tuple3 = (12,34,4.12,"lala",True,m)
print(tuple3)
# 注意:创建的元组只有一个元素时, 会在元素的后面加上一个逗号 ,
tuple4 = (2)
print(tuple4)
print(type(tuple4)) #
tuple5 = (3,)
print(tuple5)
print(type(tuple5)) #
12.3元组元素的访问
tuple1 = (14,32,35,7,87)
# 1.访问元组的元素,使用下标访问,下标默认从0开始
print(tuple1[1])
# print(tuple1[5]) # tuple index out of range 索引越界
print(tuple1[-1]) # 87 访问元组的最后一个元素 下标是-1
print(tuple1[-3]) # 35
# 2. 元组的元素的值不能进行修改
# tuple1[2] = 99
# print(tuple1) # 'tuple' object does not support item assignment
# 3.删除元组 del
# del tuple1
print(tuple1) # name 'tuple1' is not defined
12.4元组操作
# 1.合并元组 +
tuple1 = (12,34,56)
tuple2 = (3.12,56,"hello")
print(tuple1 + tuple2)
# 2.重复元组中的元素 *
tuple3 = (23,45,67)
print(tuple3 * 4)
# 3.判断指定元素是否在元组中 使用成员运算符 in 和 not in
print(56 in tuple2)
if "hello" in tuple2:
print("终于找到你")
else:
print("你在哪里呢!")
# 4.元组的截取(切片)
tuple4 = (12,3,5,7,98)
print(tuple4[1:4]) # (3, 5, 7)
print(tuple4[-1:]) # (98,)
print(tuple4[:2]) # (12, 3)
12.5元组功能
# 元组常见的功能
#1.len 获取元组的长度
print(len(tuple4)) # 5
# 2.获取元组中的最大值max()和最小值min()
print(max(tuple4)) # 98
print(min(tuple4)) # 3
# 3.其他数据类型转换为元组 tuple()
list1 = [12,34,57,89]
print(type(list1)) #
print(type(tuple(list1))) #
# 4.遍历元组
# 第一种方式: for in
for i in tuple4:
print(i)
# 第二种方式: 通过下标访问
for i in range(len(tuple4)):
print(tuple4[i])
# 第三种方式: enumrate() 返回索引和元素
for key,value in enumerate(tuple4):
print(key,value)
12.6二维元组
# 二维元组
tuple2 = (12,34,5,6,(763,341,23),980,89)
print(tuple2)
print(tuple2[3]) # 6
print(tuple2[4][1]) # 二维元组的访问
12.7赋值 深拷贝 浅拷贝
#深浅拷贝的可视化视图
http://pythontutor.com/live.html#mode=edit
# 赋值: 其实就是对象的引用(别名)
list = [12,34,57,9]
list1 = list
list[1] = 78
# print(list,list1)
# 浅拷贝: 拷贝父对象,不会拷贝对象内部的子对象.浅拷贝一维列表的时候,前后两个列表是独立的.
import copy
a = [12,35,98,23] # 一维列表
b = a.copy()
a[1] = 67
# print(a,b)
# 浅拷贝在拷贝二维列表的时候,只能拷贝最外层列表,不能拷贝父对象中的子对象,当修改子对象中的值的时
候,新拷贝的对象也会发生变化
c = [14,53,25,[31,89,26],42] # 二维列表
d = c.copy()
c[3][1] = 11
print(c,d)
# 若要解决浅拷贝处理二维列表时的问题,需要使用深拷贝解决
e = [14,53,25,[31,89,26],42] # 二维列表
f = copy.deepcopy(e)
e[3][1] = 11
print(e,f)
13.1匿名函数
# 匿名函数: lambda
def fn(n):
return n**2
print(fn(3))
# 匿名函数
f1 = lambda n: n**2
print(f1(3))
#匿名函数
f2 = lambda x,y:x*y
print(f2(12,3))
#有名字的函数的写法
def ji(x,y):
return x*y
13.2回调函数
def fn(a,b):
print(a + b)
fn(12,34) # 46
test = fn # 将函数fn赋值给一个变量test, 那这个变量test能够实现和函数fn一样的功能
print(type(test),type(fn)) #
test(12,34) # 46
# 函数名: fn既是函数的名称,同时也指向了该函数的对象(变量)
# 函数调用的格式: 函数名()====>变量名()
# 回调函数: 把一个函数(a)作为一个参数传递到另外一个函数(b)中去,那么函数a就叫做回调函数.
def add(x,y):
print(x+y)
def cha(x,y):
print(x-y)
def ji(x,y):
print(x*y)
def shang(x,y):
print(x/y)
add(56,23)
cha(78,21)
# 封装一个函数,实现加减乘除运算.
def demo(x,y,func):
func(x,y)
demo(56,23,add) # 此时add函数就是一个回调函数
demo(78,12,cha)
13.3闭包和装饰器【掌握】
如果在一个函数的内部定义另外一个函数,外部的函数叫做外函数,内部的函数叫做内函数
如果在一个外部函数中定义一个内部函数,并且外部函数的返回值是内部函数,就构成了一个闭
包,则这个内部函数就被称为闭包【closure】
实现函数闭包的条件:
1.必须是函数嵌套函数
2.内部函数必须引用一个定义在闭合范围内的外部函数的变量,----内部函数引用外部变量
3.外部函数必须返回内部的函数
# 闭包: 如果在一个外部函数中定义一个内部函数,并且外部函数的返回值是内部函数,就构成了一个
闭包,则这个内部函数就被称为闭包【closure】
# 最简单的闭包
# 外部函数
def outer():
# 内部函数
def inner():
print("lala")
return inner # 将内部函数返回
fn = outer() # fn =====> inner函数
fn() # 相当于调用了inner函数 输出 lala
# 内部函数使用外部函数的变量
def outer1(b):
a = 10
def inner1():
# 内部函数可以使用外部函数的变量
print(a + b)
return inner1
fun1 = outer1(12)
fun1()
'''
注意:
1.当闭包执行完毕后,仍然能够保存住当前的运行环境
2.闭包可以根据外部作用域的局部变量得到不同的效果,类似于配置功能,类似于我们可以通过修改外部
变量,闭包根据变量的改变实现不同的功能.
应用场景: 装饰器
'''
13.4装饰器
def test():
print("你好啊!")
# test()
# 需求: 给上面的函数test增加一个功能, 输出 我很好
# 第一种方式: 修改了原来的函数
'''
def test():
print("你好啊!")
print("我很好")
test()
# 第二种方式: 定义一个新函数,在新函数中调用原函数,然后追加功能
def test1():
test()
print("我很好")
test1()
'''
13.5简单装饰器
# 原函数
def test():
print("你好啊!")
# 需求: 给上面的函数test增加一个功能, 输出 我很好
# 第三种方式: 通过装饰器的方式给函数追加功能 装饰器使用闭包实现
'''
闭包函数:
1.函数嵌套函数
2.内部函数使用外部函数的变量
3.外部函数中返回内部函数
'''
#a.书写闭包函数 此处的outer函数就是装饰器函数
def outer(fn): #b. fn表示形参, 实际调用的时候传递的是原函数的名字
def inner():
fn() #c.调用原函数
#d. 给原函数添加功能, 注意:添加的功能可以写在原函数的上面也可以写在原函数的下面
print("我很好")
return inner
print("添加装饰器之前:",test,__name__) #
test = outer(test)
print("添加装饰器之后:",test,__name__) # .inner at
0x00000223ED793510>
test()
总结:
1.在装饰器中,给原函数添加的功能,可以写在原函数的上面,也可以写在原函数的下面
2.outer 函数就是我们的装饰器函数
13.6系统的简写
#a.书写闭包函数 此处的outer函数就是装饰器函数
def outer(fn): #b. fn表示形参, 实际调用的时候传递的是原函数的名字
def inner():
fn() #c.调用原函数
#d. 给原函数添加功能, 注意:添加的功能可以写在原函数的上面也可以写在原函数的下面
print("我很好")
return inner
# test = outer(test)
# 装饰器的简写方式 @ + 装饰器名称
@outer # 等价于 =====>test = outer(test)
def test():
print("你好啊!")
test()
'''
注意:
1.在使用装饰器的简写方式的时候,原函数必须在装饰器函数的下面
2.outer就是装饰器函数. @outer等价于 test = outer(test)
'''
13.7不定长参数的装饰器(通用装饰器)
# 同一个装饰器装饰多个函数
def jisuan(fn):
def inner(*args):
print("数学运算的结果是:",end=" ")
fn(*args)
return inner
@jisuan
def add(a,b):
print(a+b)
add(12,34)
@jisuan
def cha(a,b,c):
print(a-b-c)
cha(100,23,26)
13.8带返回值的装饰器
def outer(fn):
def inner():
print("我的爱好是:",end = " ")
return fn() # fn() ===> swim() ===> "i like swimming(这句话返回到了第4
行)
return inner
@outer
def swim():
return "i like swimming!"
love = swim()
print(love)
13.9多个装饰器作用同一个函数
# 多个装饰器作用域一个函数
def outer1(fn):
def inner():
print("~~~~~~~1111")
fn()
return inner
def outer2(fn):s
def inner():
print("~~~~~~~2222")
fn()
return inner
# 原函数
@outer2
@outer1
def show():
print("今晚我的好基友从广州过来了,好开心!....")
show()
'''
当多个装饰器修饰一个函数的时候,装饰器从上往下依次执行. 并且原函数只执行一次.
'''
14.1global和nonlocal关键字的使用
global
num = 11
def test():
num = 78
print(num)
test() # 78
print(num) # 11
# 若想在函数的内部,对全局变量进行修改,需要使用global关键字
num1 = 11
def test1():
# 通过global关键字将函数内部声明变量变为了全局变量
global num1
num1 = 75
print(num1)
test1() # 75
print(num1) # 75
.nonlocal
# nolocal 关键字主要用于闭包函数中
# nolocal关键字用于闭包函数中
x = 15 # 全局变量
def outer():
x = 19
def inner():
# x = 23
# global x # 使用的是 x = 15
nonlocal x # 这时候使用的变量是 x = 19
x += 1
print("inner:",x)
return inner
# 闭包会保存住当前的运行环境
test = outer()
test() # 20
test() # 21
test() # 22
num = 11
def demo():
print(num)
demo() # 11
demo() # 11
demo() # 11
15.fifilter和map函数
filter是一个内置类 主要做数据的筛选.第一个参数是一个函数,第二个参数是一个可迭代对象
ages = [12,34,5,21,44,98]
# 将ages列表中数值大于30的数字筛选出来
# 返回值是一个filter类型的对象
list1 = filter(lambda ele:ele > 30,ages)
print(list1)
map() 主要是用于数据的处理 第一个参数是一个函数 第二个参数是一个可迭代对象
# 返回值:是一个map类型的对象
list2 = map(lambda ele:ele + 3,list1)
print(lsit2)
16.time时间模块
import time
# 获取时间戳 从1970年1月1日0时0分0秒到现在经过的秒数
time.time()
# 延迟程序多长时间执行一次
time.sleep()
17.datetime日期模块【掌握】
import datetime
# 获取当前的日期对象
date = datetime.datetime.now()
print(date)
# 设置日期对象
date1 = datetime.datetime(year=2022,month=11,day=10,hour=10,minute=23,second=11)
print(date1)
print(type(date1)) #
print(date1.year,date1.month,date1.day) # 年 月 日
print(date1.hour,date1.minute,date1.second) # 时 分 秒
print(date1.date()) # 2022-11-10
print(date1.time()) # 10:23:11
# 将datetime.datetime类型转换为字符串
# strftime() 将日期对象转换为字符串
print(type(date1.strftime("%Y-%m-%d %H:%M:%S"))) #
print(date1.strftime("%Y{}%m{}%d{}").format("年","月","日")) #2022年11月10日
# strptime() 将字符串转换为日期对象
str1 = "2021-07-27 10:40:21"
print(type(datetime.datetime.strptime(str1,'%Y-%m-%d %H:%M:%S'))) #
# timestamp() 日期对象转换为时间戳da daimestamp()) # 1668046991.0
# fromtimestamp() 时间戳转换为日期对象
print(datetime.datetime.fromtimestamp(1668046991.0)) # 2022-11-10 10:23:11
# 时间差
d1 = datetime.datetime(2022,1,13)
d2 = datetime.datetime(2021,10,1)
print(d1 - d2)
print(d2 - d1)
# timedelta 代表两个日期之间的时间差
dt = datetime.timedelta(days=5,hours=8)
print(d1 + dt) # 2022-01-18 08:00:00
print(d1 - dt) # 2022-01-07 16:00:00
'''
# %y 两位数的年份表示(00-99)
# %Y 四位数的年份表示(000-9999)
# %m 月份(01-12)
# %d 月内中的一天(0-31)
# %H 24小时制小时数(0-23)
# %I 12小时制小时数(01-12)
# %M 分钟数(00-59)
# %S 秒(00-59)
# %a 本地简化星期名称
# %A 本地完整星期名称
# %b 本地简化的月份名称
# %B 本地完整的月份名称
# %c 本地相应的日期表示和时间表示
# %j 年内的一天(001-366)
# %p 本地A.M.或P.M.的等价符
# %U 一年中的星期数(00-53)星期天为星期的开始
# %w 星期(0-6),星期天为星期的开始
# %W 一年中的星期数(00-53)星期一为星期的开始
# %x 本地相应的日期表示
# %X 本地相应的时间表示
# %% %号本身
'''
18.1os模块
用于获取系统的功能,主要用于操作文件或者文件夹
import os
# listdir 查看指定目录下面所有的文件夹和文件
# r"" 将字符串中的特殊字符进行转义
print(os.listdir(r"C:\Users\chenbingjie\Desktop\python2105\day11")) #
['test.py', '代码', '作业', '昨日作业', '笔记', '视频']
# 当前目录 .
# 上级目录 ..
# curdir 表示当前目录
print(os.curdir) # .
# getcwd() 获取当前路径
print(os.getcwd()) # C:\Users\chenbingjie\Desktop\python2105\day11\代码
# mkdir() 创建文件夹 (不能创建已经存在的文件夹)
# os.mkdir("测试")
# makedirs() 创建多层文件夹
# os.makedirs("a/b/c")
# rmdir() 删除文件夹 (只能删除空文件夹)
# os.rmdir("demo")
# rename() 重命名文件夹或者重命名文件
# os.rename("a","a11")
# ./表示当前目录 ../表示上级目录
# os.rename("../test.py","../demo.py")
# remove() 删除文件
# os.remove("demo.py")
# os.path.join() 拼接路径
print(os.path.join(r"C:\Users\chenbingjie\Desktop\python2105\day11\代
码","func.py"))
# os.path.split() 拆分路径
path = r"C:\Users\chenbingjie\Desktop\python2105\day11\代码\1栈和队列.py"
print(os.path.split(path))
# os.path.splitext() 拆分文件和扩展名
print(os.path.splitext(path))
# os.path.abspath 获取绝对路径
print(os.path.abspath("func.py"))
# os.path.getsize() 获取文件大小
print(os.path.getsize("func.py"))
# os.path.isfile() 判断是否是文件,若是文件返回True 若不是文件 返回False
print(os.path.isfile("func.py")) # True
# os.path.isdir() 判断是否是文件夹, 若是文件夹 返回True 若不是文件夹 返回False
print(os.path.isdir("a11")) # True
# os.path.exists() 判断文件或者文件夹是否存在 若存在返回True 若不存在 返回False
print(os.path.exists("demo.py")) #False
# os.path.dirname 获取路径的文件夹部分
print(os.path.dirname(path))
# os.path.basename 获取路径的文件名部分
print(os.path.basename(path))
重点掌握:
1.os.listdir() 获取指定路径下的文件夹和文件 (是一个列表)
2.os.mkdir() 创建目录(目录存在,不能创建)
3.os.makedirs() 创建多层目录
4.os.rmdir() 删除目录
5.os.remove() 删除文件
6.os.rename() 重命名文件或者重命名文件夹
7.os.path.join() 拼接路径
8.os.path.split() 拆分路径
9.os.path.splitext() 拆分文件名和扩展名
10.os.path.isfile() 判断是否是文件
11.os.path.isdir() 判断是否是目录
12.os.path.exists() 判断文件或者文件夹是否存在
13.os.path.getsize() 获取文件大小
18.2递归遍历目录
# 需求: 查找当前目录下面的所有的 .py文件和 .txt文件
# 提示: listdir() endwith()
path = r"C:\Users\chenbingjie\Desktop\python2105\day11\代码"
import os
def get_file(path):
# 判断路径是否存在
if not os.path.exists(path):
print("路径不存在")
return
file_list = os.listdir(path)
# print(file_list)
for file in file_list:
if file.endswith(".py") or file.endswith(".txt"):
print(file)
get_file(path)
import os
# 需求: 使用递归的方式遍历newdir文件夹下面的所有文件和文件夹
path = r"C:\Users\chenbingjie\Desktop\python2105\day11\代码\newdir"
def search_dir(path):
# 判断路径是否合法
if not os.path.exists(path):
print("路径不存在")
return
file_list = os.listdir(path) # ['dir1', 'dir2', 'os.py']
for file in file_list:
# dir1 = "C:\Users\chenbingjie\Desktop\python2105\day11\代码\newdir\dir1"
# 获取文件或者文件夹的绝对路径
file_path = os.path.join(path,file)
# print(file_path)
# 判断file_path是否是文件,若是文件直接输出,若是文件夹通过递归方式继续遍历
if os.path.isfile(file_path):
print("---",file,"是文件")
# 否则是文件夹
else:
print(file,"是文件夹")
# 递归
search_dir(file_path)
search_dir(path) 19.面向对象
python中的面向对象的学习主要是类和对象。
类:多个具有特殊功能的个体的集合 例如: 人类 狗 猫
对象:在一个类中,一个具有特殊功能的个体,能够帮忙解决某件特定的事情,也被称为实例
【instance】
比如: 左韬 左韬家的黑毛猪 陈冰杰家的狼青
两者之间的关系:类用于描述某一类对象的共同特征,而对象是类的具体的存在
思考问题:先有类还是先有对象?
类的定义
语法:
class 类名( ):
说明:
代码演示:
# dir1 = "C:\Users\chenbingjie\Desktop\python2105\day11\代码\newdir\dir1"
# 获取文件或者文件夹的绝对路径
file_path = os.path.join(path,file)
# print(file_path)
# 判断file_path是否是文件,若是文件直接输出,若是文件夹通过递归方式继续遍历
if os.path.isfile(file_path):
print("---",file,"是文件")
# 否则是文件夹
else:
print(file,"是文件夹")
# 递归
search_dir(file_path)
search_dir(path)类体
a.Python中使用class关键字定义类
b.类名只要是一个合法的标识符即可,但是要求:遵循大驼峰命名法则【首单词的首字母大写,不同单词之间首字母大写】
c.通过缩进区分类体
d.类体一般包含两部分内容:属性和方法(属性就是描述一些静态信息的,比如人的姓名\年龄\性别等 等, 方法:一般用函数表示,用来实现具体的功能)
代码演示:
class Dog():
# 类属性
name = "局长"
sex = "公"
# 类方法
def eat(self):
print(self.name,"吃肉!")
def say(self):
print("我是吼的方法")类中的方法和变量的定义
类中的方法和变量是为了描述事物的行为和特征
类中定义的方法被称为成员方法
类中定义的变量被称为成员变量,也被称为属性 [os.name]
成员变量:类具有的特征
成员方法:类具有的行为
类存在的意义:拥有相同特征和行为的对象可以抽取出来一个类,类的存在是为了创建一个具体 的对象
代码演示:
class Dog():
# 类属性
name = "局长"
sex = "公"
# 类方法
def eat(self):
print(self.name,"吃肉!")
def say(self):
print("我是吼的方法")类中方法和属性的使用
1.创建对象【实例化对象】
已知类,通过类创建对象
对象的创建过程被对象的实例化过程
语法:变量名 = 值
对象名 = 类名()
代码演示:
# 定义Dog类
class Dog():
# 类属性
name = "局长"
sex = "公"
# 类方法
def eat(self):
print(self.name, "吃肉!")
def say(self):
print("我是吼的方法")
# 通过Dog类创建对象
labuladuo = Dog()
#通过对象访问方法
labuladuo.eat()
labuladuo.say()
# 通过对象访问属性
print(labuladuo.name)
print(labuladuo.sex)总结:
访问变量采用:对象名.属性名
访问方法采用:对象名.方法名(参数列表)
构造函数和析构函数
1.构造函数
采用上面的方式创建对象【直接给成员变量赋值】,很多的类一般倾向于创建成有初始状态的
__init__:构造函数【作用:创建对象,给对象的成员变量赋初始值】
构造函数:构造器
调用的时机:当一个对象被创建的时候,第一个被自动调用的函数
per = Person()
语法:
def __init__(self,args1,args2....)
函数体
说明:
a.之前的写法中并没有显式的定义__init__函数,说明系统默认提供了一个无参的构造函数
b.args1,args2...一般设置的形参列表和成员变量有关
代码演示:
class GirlFriend():
'''
类属性:(不推荐这么写)
name = "王凡老表"
age = 22
'''
# 构造函数 参数是对象相关的属性
def __init__(self,name,age):
# 对象属性
self.name = name
self.age = age
print("构造函数的触发时机是:当创建对象的时候自动触发")
# 对象方法
def say(self):
print(self.name,"喊大源,来啊来啊!")
def sing(self):
print("唱歌给大源听,喝了吧!")
# 当创建对象的时候,会自动调用__init__()
wangfanlaobiao = GirlFriend("王小妹",22)
wangfanlaobiao.say()析构函数
与构造函数正好相反,当对象被销毁的时候自动调用的函数,被称为析构函数
__del__:
删除变量: del 变量名,此时可以触发析构函数的调用
使用情景:清理工作,比如关闭数据库,关闭文件等
代码演示:
class GirlFriend():
'''
类属性:(不推荐这么写)
name = "王凡老表"
age = 22
'''
# 对象方法
def sing(self):
print("唱歌给大源听,喝了吧!")
# 析构函数:触发时机是当对象被删除时,会被自动调用,释放内存
def __del__(self):
print("脚本运行结束,释放内存")
# 当创建对象的时候,会自动调用__init__()
wangfanlaobiao = GirlFriend()
wangfanlaobiao.sing()
print("我是最后执行的一句代码了!")
'''析构函数的应用场景:
关闭数据库 保存文件
内存回收的方式:
1.当对象在某个作用域中调用完毕,在跳出其作用域的同时析构函数会被调用一次,这样可以用来释放内存空
间.
2.当使用del删除对象的时候,也会调用该对象的析构函数,相当于手动释放内存
'''
封装
1.概念
广义的封装:函数和类的定义本身,就是封装的体现
狭义的封装:一个类的某些属性,在使用的过程 中,不希望被外界直接访问,而是把这个属性给
作为私有的【只有当前类持有】,然后暴露给外界一个访问的方法即可【间接访问属性】
封装的本质:就是属性私有化的过程
封装的好处:提高了数据的安全性,提高了数据的复用性
属性私有化和方法私有化
如果想让成员变量不被外界直接访问,则可以在属性名称的前面添加两个下划线__,成员变量则被
称为私有成员变量
私有属性的特点:只能在类的内部直接被访问,在外界不能直接访问
代码演示:
class Girl():
def __init__(self,name,sex,height):
self.name = name
self.sex = sex
self.height = height
# 比如女孩的年龄是秘密,在外面不能轻易的访问,需要把年龄设置为私有属性
self.__age = 18
def say(self):
print("帅哥,帮个忙呗!")
# 在类的内部可以访问私有属性
def sayAge(self,boyFriend):
if boyFriend == "大源":
print(f"{self.name}偷偷的告诉{boyFriend}说:老娘今年88了!")
else:
print("女孩的年龄是秘密,不知道吗?上来就问,活该你单身,傻狗!")
# 私有方法
# 接吻
def __kiss(self):
print("一吻定终身!")
# 类中可以访问私有方法
def love(self,relationship):
if relationship == "情侣关系":
self.__kiss()
else:
print("不能随便kiss,小心中毒!")
xiaohong = Girl("小红","美女",165)
print(xiaohong.name)
print(xiaohong.sex)
print(xiaohong.height)
# print(xiaohong.age) # 将age设置为私有属性后,外部不能直接访问
xiaohong.say()
xiaohong.sayAge("大源")
xiaohong.love("情侣关系")
'''私有属性:
1.写法:在属性的前面加两个下划线 __age
2.用法:只能在类的内部访问,不能在类的外部访问 可以在类的内部设置一个外部访问的接口(这个接
口一般会做各种条件判断,满足后才能访问),让外部获取私有属性的值
私有方法:
1.写法:在方法的前面加两个下划线 __kiss()
2.用法:只能在类的内部访问,不能在类的外部访问. 私有方法一般是用来在类的内部实现某些功能
的,对于外部来说没有实质的意义.这种方法一般定义为私有方法.
'''
get函数和set函数
get函数和set函数并不是系统的函数,而是自定义的,为了和封装的概念相吻合,起名为getXxx
和setXxx
get函数:获取值
set函数:赋值【传值】
代码演示:
上面的访问和设置私有属性的命名规则不推荐.
# 第一种访问和设置 私有属性的方式 get和set函数
class Girl():
def __init__(self,name,age):
self.name = name
self.__age = age
# 访问私有属性 命名规则: get + 私有属性名(属性名单词首字母大写)
def getAge(self):
return self.__age
# 设置私有属性 命名规则:set + 私有属性名(属性名单词首字母大写)
def setAge(self,age):
self.__age = age
lan = Girl("小兰",21)
print(lan.name)
# print(lan.__age)
# 访问私有属性
age = lan.getAge()
print(age)
# 设置私有属性
lan.setAge(18)
print(lan.getAge())
.@property装饰器
装饰器的作用:可以给函数动态添加功能,对于类的成员方法,装饰器一样起作用
Python内置的@property装饰器的作用:将一个函数变成属性使用
@property装饰器:简化get函数和set函数
使用:
@property装饰器作用相当于get函数,同时,会生成一个新的装饰器
@属性名.settter,相当于set函数的作用
作用:使用在类中的成员函数中,可以简化代码,同时可以保证对参数做校验
代码演示:
# 第一种访问和设置 私有属性的方式 get和set函数
class Girl():
def __init__(self,name,age):
self.name = name
self.__age = age
'''
# 访问私有属性 命名规则: get + 私有属性名(属性名单词首字母大写)
def getAge(self):
return self.__age
# 设置私有属性 命名规则:set + 私有属性名(属性名单词首字母大写)
def setAge(self,age):
self.__age = age
'''
# 通过装饰器@property 获取私有属性age 相当于getAge()
@property
def age(self):
return self.__age
# 通过装饰器设置私有属性 @ + 私有属性名 + setter 相当于 setAge()
@age.setter
def age(self,age):
self.__age = age
lan = Girl("小兰",21)
print(lan.name)
print(lan.age) # 通过装饰器修访问私有属性,访问格式: 对象名.私有属性名
lan.age = 19 # 通过装饰器设置私有属性,格式: 对象名.私有属性名 = 值
print(lan.age)
类方法和静态方法
类方法:使用@classmethod装饰器修饰的方法,被称为类方法,可以通过类名调用,也可以通
过对象调用,但是一般情况下使用类名调用
静态方法:使用@staticmethod装饰器修饰的方法,被称为静态方法,可以通过类名调用,也可
以通过对象调用,但是一般情况下使用类名调用
代码演示:
class Animal():
# 类属性
name = "牧羊犬"
# 对象属性
def __init__(self,name,sex):
self.name = name
self.sex = sex
'''
类方法:
1.通过@classmethod装饰器修饰的方法就是类方法
2.类方法可以使用类名或者对象调用. 但是一般情况下使用类名调用类方法(节省内存)
3.没有self,在类方法中不可以使用其他对象的属性和方法(包括私有属性和私有方法)
4.可以调用类属性和其他的类方法, 通过cls来调用
5.形参的名字cls是class的简写,可以更换,只不过是约定俗成的写法而已
6.cls表示的是当前类
'''
@classmethod
def run(cls):
print("我是类方法")
print(cls.name)
print(cls == Animal) # cls表示的是当前类
'''
静态方法:
1.通过@staticmethod装饰器修饰的方法就是静态方法
2.通过类名或者对象名都可以调用静态方法 (推荐使用类名调用)
3.静态方法形式参数中没有cls, 在静态方法中不建议调用(类属性\类方法\静态方法)
4.静态方法一般是一个单独的方法,只是写在类中
'''
# 静态方法
@staticmethod
def eat():
print("我是静态方法")
Animal.run() # 类名调用类方法
Animal.eat() # 类调用静态方法
# 创建对象
dog = Animal('中华土狗','公')
# dog.run() # 对象调用类方法
总结:实例方法【成员方法】、类方法以及静态方法之间的区别
a.语法上
实例方法:第一个参数一般为self,在调用的时候不需要传参,代表的是当前对象【实例】
静态方法:没有特殊要求
类方法:第一个参数必须为cls,代表的是当前类
在调用上
实例方法:只能对象
静态方法:对象 或者 类
类方法:对象 或者 类
在继承上【相同点】
实例方法、静态方法、类方法:当子类中出现和父类中重名的函数的时候,子类对象调用的是子类中的方法
【重写】
注意:注意区分三种函数的书写形式,在使用,没有绝对的区分
类中的常用属性
__name__
通过类名访问,获取类名字符串
不能通过对象访问,否则报错
__dict__
通过类名访问,获取指定类的信息【类方法,静态方法,成员方法】,返回的是一个字典
通过对象访问,获取的该对象的信息【所有的属性和值】,,返回的是一个字典
__bases__
通过类名访问,查看指定类的所有的父类【基类】
代码演示:
class Animal(object):
def __init__(self,name,sex):
self.name = name
self.sex = sex
def eat(self):
print("吃")
animal = Animal("二哈","公狗")
# __name__ 通过类名访问获取当前类的类名,不能通过对象访问
print(Animal.__name__) # Animal
# __dict__以字典的形式返回类的属性和方法 以及 对象的属性
print(Animal.__dict__) # 以字典的形式显示类的属性和方法
print(animal.__dict__) # 以字典的形式显示对象的属性
# __bases__ 获取指定类的父类 返回的是一个元组
print(Animal.__bases__) # (
魔术方法: __str__() 和 __repr__()
class Person(object):
def __init__(self,name,age):
self.name = name
self.age = age
def swim(self):
print("游泳的方法")
# __str__() 触发时机: 当打印对象的时候,自动触发. 一般用它来以字符串的形式返回对象的相关
信息,必须使用return返回数据
'''
def __str__(self):
return f"姓名是:{self.name},年龄是:{self.age}"
# print("姓名是:{self.name},年龄是:{self.age}")
'''
# __repr__()作用和 __str__()类似,若两者都存在,执行 __str__()
def __repr__(self):
return f"姓名是:{self.name},年龄是:{self.age}"
# print("姓名是:{self.name},年龄是:{self.age}")
xiaohong = Person("小红",18)
print(xiaohong)
继承
概念
如果两个或者两个以上的类具有相同的属性或者成员方法,我们可以抽取一个类出来,在抽取的
类中声明公共的部分
被抽取出来的类:父类,基类,超类,根类
两个或者两个以上的类:子类,派生类
他们之间的关系:子类 继承自 父类
父类的属性和方法子类可以直接使用。
注意:a. object是所有类的父类,如果一个类没有显式指明它的父类,则默认为object
b.简化代码,提高代码的复用性
.单继承
2.1使用
简单来说,一个子类只能有一个父类,被称为单继承
语法:
父类:
class 父类类名(object):
类体【所有子类公共的部分】
子类:
class 子类类名(父类类名):
类体【子类特有的属性和成员方法】
说明:一般情况下,如果一个类没有显式的指明父类,则统统书写为object
代码演示:
最简单的继承
# 父类
class Person(object):
def say(self):
print("说话的方法")
# 子类
class Boy(Person): # 定义一个子类 将父类的类名传进去 子类就继承了父类
def eat(self):
print("子类自己的吃饭的方法")
boy = Boy()
boy.eat() # 子类调用自己的方法
boy.say() # 子类调用父类的方法
有构造函数的单继承
# 父类
class Animal(object):
def __init__(self,name,sex):
self.name = name
self.sex = sex
def eat(self):
print("所有的动物都有捕食的技能")
# 子类
class Cat(Animal):
def __init__(self,name,sex,tail): # 先继承父类的属性,再重构
# 1.经典的写法
# Animal.__init__(self,name,sex) # 继承父类的构造方法
# 2.隐式的继承父类的构造函数
super(Cat,self).__init__(name,sex)
self.tail = tail # 定义子类自己的属性
def catchMouse(self):
print("猫抓老鼠")
cat = Cat("波斯猫","母","揪尾巴")
print(cat.name)
print(cat.sex)
print(cat.tail)
cat.eat()
cat.catchMouse()
总结:
继承的特点:
a.子类对象可以直接访问父类中非私有化的属性
b.子类对象可以调用父类中非私有化的成员方法
c.父类对象不能访问或者调用子类 中任意的内容
继承的优缺点:
优点:
a.简化代码,减少代码的冗余
b.提高代码的复用性
c.提高了代码的可维护性
d.继承是多态的前提
缺点:
通常使用耦合性来描述类与类之间的关系,耦合性越低,则说明代码的质量越高
但是,在继承关系中,耦合性相对较高【如果修改父类,则子类也会随着发生改变】
多继承
一个子类可以有多个父类
语法:
class 子类类名(父类1,父类2,父类3.。。。):
类体
代码演示:
# 父亲类
class Father(object):
def __init__(self,surname):
self.surname = surname
def make_money(self):
print("钱难挣,屎难吃!")
# 母亲类
class Mother(object):
def __init__(self,height):
self.height = height
def eat(self):
print("一言不合,就干饭!")
# 子类
class Son(Father,Mother): # 子类继承多个父类时,在括号内写多个父类名称即可
def __init__(self,surname,height,weight):
# 继承父类的构造函数
Father.__init__(self,surname)
Mother.__init__(self,height)
self.weight = weight
def play(self):
print("就这这么飞倍爽!")
son = Son("卢","178",160)
print(son.surname)
print(son.height)
print(son.weight)
son.make_money()
son.eat()
son.play()
多态【了解】
一种事物的多种体现形式,函数的重写其实就是多态的一种体现
在Python中,多态指的是父类的引用指向子类的对象
代码演示:
# 多态: 在继承的基础上,(多个子类继承一个父类,并且重写父类的一个方法),去调用子类的方法可以
实现不同的功能.
# 父类
class Animal():
def eat(self):
print("吃的发方法")
# 子类
class Fish(Animal):
def eat(self):
print("大鱼吃小鱼,小鱼吃虾米")
class Dog(Animal):
def eat(self):
print("狼行千里吃肉,狗走万里吃粑粑!")
class Cat(Animal):
def eat(self):
print("猫爱吃鱼!")
# 严格意义的多态:使用对象调用eat方法
class Person():
def feed(self,animal):
animal.eat()
'''
在父类和子类中出现了函数重名的情况,会调用子类的函数, 子类和父类函数重名的现象叫做重载
(重写)
不同的子类之间调用和父类相同的方法,调用的都是自己的方法, 这就是多态的一种体现.
'''
fish = Fish()
dog = Dog()
cat = Cat()
# 最简单的多态的体现
fish.eat()
dog.eat()
cat.eat()
# 严格意义的多态的体现
Person().feed(dog)
Person().feed(cat)
总结:
简化代码,提高代码的可读性,可维护性
单例设计模式
1.概念
什么是设计模式
经过已经总结好的解决问题的方案
23种设计模式,比较常用的是单例设计模式,工厂设计模式,代理模式,装饰模式
什么是单例设计模式
单个实例【对象】
在程序运行的过程中,确保某一个类只能有一个实例【对象】,不管在哪个模块中获取对象,获取到的
都是同一个对象
单例设计模式的核心:一个类有且仅有一个实例,并且这个实例需要应用在整个工程中
应用场景
实际应用:数据库连接池操作-----》应用程序中多处需要连接到数据库------》只需要创建一个连接
池即可,避免资源的浪费
.实现
模块
Python的模块就是天然的单例设计模式
模块的工作原理:
import xxx,模块被第一次导入的时候,会生成一个.pyc文件,当第二次导入的时候,会直接加
载.pyc文件,将不会再去执行模块源代码
使用new
__new__():实例从无到有的过程【对象的创建过程】
代码演示:
class Person(object):
# __init__ 对象初始化属性时,自动触发
def __init__(self,name):
print("__init__")
self.name = name
# 定义一个类属性,接收创建好的对象
instance = None
@classmethod
def __new__(cls,*args,**kwargs):
print("__new__")
# 如果类属性的instance == None表示 该类未创建过对象
if cls.instance == None:
cls.instance = super().__new__(cls)
return cls.instance
p = Person("陈梦")
p1 = Person("陈梦")
p2 = Person("陈梦")
print(p == p1 == p2)
__new__():在创建对象的时候自动触发
__init__():在给创建的对象赋值属性的时候触发.
20正则表达式
引入案例
代码演示:
#需求:判断一个手机号码是否合法.
""
import re #regular Expession
#使用正则表达式实现上面的需求
# 需求:封装一个函数,判断手机号是否合法?
def checkPhone(phone):
if len(phone) != 11:
return "手机号码长度不符合要求!"
if phone[0] != "1":
return "手机号码不是1开头!"
if not phone.isdigit():
return "手机号码不是全部是数字"
return "手机号码格式正确"
# print(checkPhone("28617767023"))
# 正则验证手机号码是否正确
import re
result= re.search("^1\d{10}$","28617767024"))
if(result):
return "手机号码合法"
else:
return "手机号码不合法"
概述
正则表达式【Regular Expression】,简写为regex,RE,使用单个字符串来描述一系列具有特殊
格式的字符串
功能:
a.搜索
b.替换
c.匹配
使用情景:
爬虫
验证手机号,验证邮箱,密码【用户名】
常用的函数
# 1.re.match() 匹配字符串是否以指定的正则内容开头,匹配成功返回对象, 匹配失败返回None
'''
第一个参数: 正则表达式
第二个参数: 要验证的字符串
第三个参数: 可选参数,正则表达式修饰符
'''
# \d: 0-9
# +:表示出现1次或者多次
print(re.match("\d+","12345esd")) #
match='12345'>
print(re.match("\d+","as12345esd")) # None
# #2.re.search() 匹配字符串中是否包含指定的正则内容,匹配成功返回对象,匹配失败返回
None
'''
第一个参数: 正则表达式
第二个参数: 要验证的字符串
第三个参数: 可选参数,正则表达式修饰符
'''
# 3.re.findall() 获取所有匹配的内容,会得到一个列表
'''
第一个参数: 正则表达式
第二个参数: 要验证的字符串
使用规则
匹配单个数字或者字符
代码演示:
import re
"""
----------匹配单个字符与数字---------
. 匹配除换行符以外的任意字符
[0123456789] []是字符集合,表示匹配方括号中所包含的任意一个字符
[good] 匹配good中任意一个字符
[a-z] 匹配任意小写字母
[A-Z] 匹配任意大写字母
[0-9] 匹配任意数字,类似[0123456789]
[0-9a-zA-Z] 匹配任意的数字和字母
[0-9a-zA-Z_] 匹配任意的数字、字母和下划线
[^good] 匹配除了good这几个字母以外的所有字符,中括号里的^称为脱字符,表示不匹
配集合中的字符
[^0-9] 匹配所有的非数字字符
\d 匹配数字,效果同[0-9]
\D 匹配非数字字符,效果同[^0-9]
\w 匹配数字,字母和下划线,效果同[0-9a-zA-Z_]
\W 匹配非数字,字母和下划线,效果同[^0-9a-zA-Z_]
\s 匹配任意的空白符(空格,回车,换行,制表,换页),效果同[ \r\n\t\f]
\S 匹配任意的非空白符,效果同[^ \f\n\r\t]
"""
#[] :只匹配其中的一位
# - :表示一个区间
print(re.search("he[0-9]llo","he9llo")) #
match='he9llo'>
print(re.search("go[zxc]od","goxod")) #
match='goxod'>
print(re.search("he[a-z]llo","hepllo")) #
match='hepllo'>
print(re.search("hello[0-9a-zA-Z_]","hello9"))
print(re.search("hello\d","hello2")) #
match='hello2'>
print(re.search("hello\D","helbwklo_")) #
match='hello_'>
print(re.search("hello\w","hello1")) #
match='hello1'>
print(re.search("hello\W","hello!")) #
match='hello!'>
print(re.search("mone\sy","mone\ny")) #
match='mone\ny'>
print(re.search("money[^0-9]","money!")) #
match='money!'>
模式修饰符(可选参数)
模式修饰符: 修饰我们写的正则表达式(可选参数)
. : 表示匹配除了换行以外的任意单个字符 \n 表示换行
re.S: 可以通过 . 匹配到\n(换行)
re.I: 忽略字母大小写
'''
print(re.search("shenzhen.","shenzhen9")) #
match='shenzhen9'>
print(re.search("shenzhen.","shenzhen\n")) #None
print(re.search("shenzhen.","shenzhen\n",re.S)) #
match='shenzhen\n'>
print(re.search("shenzhen[a-z]","shenzhenS")) # None
print(re.search("shenzhen[a-z]","shenzhenS",re.I)) #
9), match='shenzhenS'>
匹配多个字符
import re
"""
-------------------匹配多个字符------------------------
说明:下方的x、y、z均为假设的普通字符,n、m(非负整数),不是正则表达式的元字符
(xyz) 匹配小括号内的xyz(作为一个整体去匹配)
x? 匹配0个或者1个x
x* 匹配0个或者任意多个x(.* 表示匹配0个或者任意多个字符(换行符除外))
x+ 匹配至少一个x
x{n} 匹配确定的n个x(n是一个非负整数)
x{n,} 匹配至少n个x
x{,n} 匹配最多n个x
x{n,m} 匹配至少n个最多m个x。注意:n <= m
"""
import re
# 匹配多个字符
'''
?: 表示 前面的字符可以出现0次或者1次 非贪婪模式
+: 表示 前面的字符可以出现1次或者多次 贪婪模式
*: 表示 前面的字符可以出现0次或者多次 贪婪模式
{}: 表示前面的字符可以出现指定的次数或者次数的范围 贪婪模式
{3}: 表示前面的字符只能出现3次
{3,6}: 表示前面的字符可以出现3-6次
{3,}: 表示前面的字符至少出现3次
{,3}: 表示前面的字符最多出现3次
'''
print(re.search("goog?le","goole")) #
match='goole'> 0次的情况
print(re.search("goog?le","google")) #
match='goole'> 1次的情况
print(re.search("goog?le","googggggle")) # None g出现多次的情况
print(re.search("goog+le","goole")) # None
print(re.search("goog+le","google")) #
match='google'>
print(re.search("goog+le","googgggggggggggle")) #
17), match='googgggggggggggle'>
print(re.search("goog*le","goole")) #
match='goole'>
print(re.search("goog*le","googgggggggggggle")) #
17), match='googgggggggggggle'>
print(re.search("goog{3}le","goole")) # None
print(re.search("goog{3}le","google")) # None
print(re.search("goog{3}le","googgggggggggle")) # None
print(re.search("goog{3}le","googggle")) #
match='googggle'>
print(re.search("goog{3,6}le","goole")) # None
print(re.search("goog{3,6}le","googgle")) # None
print(re.search("goog{3,6}le","googgggle")) #
match='googgggle'>
# {3,}: 表示前面的字符至少出现3次
print(re.search("goog{3,}le","goole")) # None
print(re.search("goog{3,}le","google")) # None
print(re.search("goog{3,}le","googggle")) #
match='googggle'>
print(re.search("goog{3,}le","googgggggggggggggggle")) #
(0, 21), match='googgggggggggggggggle'>
# {,3}: 表示前面的字符最多出现3次
print(re.search("goog{,3}le","googgggle")) # None
print(re.search("goog{,3}le","googgle")) #
match='googgle'>
print(re.search("goog{,3}le","goole")) #
match='goole'>
匹配边界字符
代码演示:
import re
"""
--------------锚字符(边界字符)-------------
^ 行首匹配(以指定字符开头),和在[]里的^不是一个意思 startswith
$ 行尾匹配 endswith
^文本$: 完全匹配
print(re.search("^world","world")) #
match='world'>
print(re.search("^world","hworld")) # None
print(re.search("world$","12world")) #
match='world'>
print(re.search("world$","worlds")) # None
print(re.search("^world$","1worlds")) # None
print(re.search("^world$","world")) #
match='world'>
print(re.search("^world$","worldworld")) # None
print(re.search("^worl+d$","worlllllllld")) #
12), match='worlllllllld'>
# 词边界
\b 匹配一个单词的边界,也就是值单词和空格间的位置 bounds(了解)
\B 匹配非单词边界(了解)
print(re.search(r"google\b","abcgoogle 123google xcvgoogle456")) #
print(re.search(r"google\B","abcgoogle 123google xcvgoogle456")) #
# 转义 \ 让正则表达式中的一些字符失去原有的意义
# \.表示一个单纯的 . 不是正则中的除了换行以外任意一个字符
print(re.search("goog\.le","goog.le"))
# 或者 | 正则表达式1 | 正则表达式2 只要满足其中一个正则表达式就能被匹配成功
print(re.search("ef|cd","123ef567")) #
match='ef'>
"""
匹配分组
() : 表示一个整体, 表示分组,然后捕获
代码演示:
tel = "0755-88988888"
pattern = '(\d{4})-(\d{8})'
result = re.search(pattern,tel)
print(result) #
print(result.group()) # 0755-88988888
print(result.group(1)) # 0755
print(result.group(2)) # 88988888
print(result.groups()) # ('0755', '88988888')
贪婪和非贪婪
代码演示:
# 正则表达式中的贪婪和非贪婪 [就是匹配一位还是匹配多位的区别]
# + * : 多次匹配 (贪婪匹配)
# 在 + 或者 * 的后面加上了 ? ,表示改成了非贪婪匹配
result1 = re.findall(r"abc(\d+)","abc2345678vf")
print(result1) # ['2345678']
result2 = re.findall(r"abc(\d+?)","abc2345678vf")
print(result2) # ['2']
.re模块中常用功能函数
代码演示:
# 1.re.match() 匹配字符串是否以指定的正则内容开头,匹配成功返回对象, 匹配失败返回None
'''
第一个参数: 正则表达式
第二个参数: 要验证的字符串
第三个参数: 可选参数,正则表达式修饰符
# #2.re.search() 匹配字符串中是否包含指定的正则内容,匹配成功返回对象,匹配失败返回
None
'''
第一个参数: 正则表达式
第二个参数: 要验证的字符串
第三个参数: 可选参数,正则表达式修饰符
'''
# 3.re.findall() 获取所有匹配的内容,会得到一个列表
'''
第一个参数: 正则表达式
第二个参数: 要验证的字符串
# 4.re.compile() 编译正则表达式,提高正则匹配的效率
import re
string = "0755-89787654"
com = re.compile('(\d{4})-(\d{8})')
sprint(com.findall(string)) # [('0755', '89787654')]
# 5.拆分 re.split()
print(re.split("\d","sdf1234mkj543lkm")) # ['sdf', '', '', '', 'mkj', '',
'', 'lkm']
# 6.替换 re.sub() 或者 re.subn()
str1 = "最新新闻 吴亦凡被 刑拘了 难以掩盖内心的心情"
print(re.sub("\s+","...",str1)) # 最新新闻...吴亦凡被...刑拘了...难以掩盖内心的
心情
print(re.subn("\s+","...",str1)) # ('最新新闻...吴亦凡被...刑拘了...难以掩盖内
心的心情', 3)
# 7.匹配中文
chinese = "[\u4e00-\u9fa5]+"
print(re.search(chinese,"hello 大源! world 345")) #
(6, 8), match='大源'>
21.python操作excel
Excel是Microsoft(微软)为使用Windows和macOS操作系统开发的一款电子表格软件。Excel凭借其
直观的界面、出色的计算功能和图表工具,再加上成功的市场营销,一直以来都是最为流行的个人计算
机数据处理软件。当然,Excel也有很多竞品,例如Google Sheets、LibreOffiffiffice Calc、Numbers等,
这些竞品基本上也能够兼容Excel,至少能够读写较新版本的Excel文件,当然这些不是我们讨论的重
点。掌握用Python程序操作Excel文件,可以让日常办公自动化的工作更加轻松愉快,而且在很多商业
项目中,导入导出Excel文件都是特别常见的功能。
Python操作Excel需要三方库的支持,如果要兼容Excel 2007以前的版本,也就是 xls 格式的Excel文
件,可以使用三方库 xlrd 和 xlwt ,前者用于读Excel文件,后者用于写Excel文件。如果使用较新版本
的Excel,即操作 xlsx 格式的Excel文件,可以使用 openpyxl 库,当然这个库不仅仅可以操作Excel,
还可以操作其他基于Offiffiffice Open XML的电子表格文件。
本章我们先讲解基于 xlwt 和 xlrd 操作Excel文件,大家可以先使用下面的命令安装这两个三方库以及
配合使用的工具模块 xlutils 。
pip install xlwt xlrd xlutils
xlwt和xlrd
读Excel文件
例如在当前文件夹下有一个名为“阿里巴巴2020年股票数据.xls”的Excel文件,如果想读取并显示该文件
的内容,可以通过如下所示的代码来完成。
import xlrd
# 使用xlrd模块的open_workbook函数打开指定Excel文件并获得Book对象(工作簿)
wb = xlrd.open_workbook('阿里巴巴2020年股票数据.xls')
# 通过Book对象的sheet_names方法可以获取所有表单名称
sheetnames = wb.sheet_names()
print(sheetnames)
# 通过指定的表单名称获取Sheet对象(工作表)
sheet = wb.sheet_by_name(sheetnames[0])
# 通过Sheet对象的nrows和ncols属性获取表单的行数和列数
print(sheet.nrows, sheet.ncols)
for row in range(sheet.nrows):
for col in range(sheet.ncols):
# 通过Sheet对象的cell方法获取指定Cell对象(单元格)
# 通过Cell对象的value属性获取单元格中的值
value = sheet.cell(row, col).value
# 对除首行外的其他行进行数据格式化处理
if row > 0:
# 第1列的xldate类型先转成元组再格式化为“年月日”的格式
if col == 0:
# xldate_as_tuple函数的第二个参数只有0和1两个取值
# 其中0代表以1900-01-01为基准的日期,1代表以1904-01-01为基准的日期
value = xlrd.xldate_as_tuple(value, 0)
value = f'{value[0]}年{value[1]:>02d}月{value[2]:>02d}日'
# 其他列的number类型处理成小数点后保留两位有效数字的浮点数
else:
value = f'{value:.2f}'
print(value, end='\t')
print()
# 获取最后一个单元格的数据类型
# 0 - 空值,1 - 字符串,2 - 数字,3 - 日期,4 - 布尔,5 - 错误
last_cell_type = sheet.cell_type(sheet.nrows - 1, sheet.ncols - 1)
print(last_cell_type)
# 获取第一行的值(列表)
print(sheet.row_values(0))
# 获取指定行指定列范围的数据(列表)
# 第一个参数代表行索引,第二个和第三个参数代表列的开始(含)和结束(不含)索引
print(sheet.row_slice(3, 0, 5))
写Excel文件
写入Excel文件可以通过 xlwt 模块的 Workbook 类创建工作簿对象,通过工作簿对象的 add_sheet 方 法可以添加工作表,通过工作表对象的 write 方法可以向指定单元格中写入数据,最后通过工作簿对象
的 save 方法将工作簿写入到指定的文件或内存中。下面的代码实现了将 5 个学生 3 门课程的考试成绩
写入Excel文件的操作。
import random
import xlwt
student_names = ['关羽', '张飞', '赵云', '马超', '黄忠']
scores = [[random.randrange(50, 101) for _ in range(3)] for _ in range(5)]
# 创建工作簿对象(Workbook)
wb = xlwt.Workbook()
# 创建工作表对象(Worksheet)
sheet = wb.add_sheet('一年级二班')
# 添加表头数据
titles = ('姓名', '语文', '数学', '英语')
for index, title in enumerate(titles):
sheet.write(0, index, title)
# 将学生姓名和考试成绩写入单元格
for row in range(len(scores)):
sheet.write(row + 1, 0, student_names[row])
for col in range(len(scores[row])):
sheet.write(row + 1, col + 1, scores[row][col])
# 保存Excel工作簿
wb.save('考试成绩表.xls')
调整单元格样式
在写Excel文件时,我们还可以为单元格设置样式,主要包括字体(Font)、对齐方式(Alignment)、
边框(Border)和背景(Background)的设置, xlwt 对这几项设置都封装了对应的类来支持。要设
置单元格样式需要首先创建一个 XFStyle 对象,再通过该对象的属性对字体、对齐方式、边框等进行设
定,例如在上面的例子中,如果希望将表头单元格的背景色修改为黄色,可以按照如下的方式进行操
作。
header_style = xlwt.XFStyle()
pattern = xlwt.Pattern()
pattern.pattern = xlwt.Pattern.SOLID_PATTERN
# 0 - 黑色、1 - 白色、2 - 红色、3 - 绿色、4 - 蓝色、5 - 黄色、6 - 粉色、7 - 青色
pattern.pattern_fore_colour = 5
header_style.pattern = pattern
titles = ('姓名', '语文', '数学', '英语')
for index, title in enumerate(titles):
sheet.write(0, index, title, header_style)
如果希望为表头设置指定的字体,可以使用 Font 类并添加如下所示的代码。
font = xlwt.Font()
# 字体名称
font.name = '华文楷体'
# 字体大小(20是基准单位,18表示18px)
font.height = 20 * 18
# 是否使用粗体
font.bold = True
# 是否使用斜体
font.italic = False
# 字体颜色
font.colour_index = 1
header_style.font = font
注意:上面代码中指定的字体名( font.name )应当是本地系统有的字体,例如在我的电脑上有
名为“华文楷体”的字体。
如果希望表头垂直居中对齐,可以使用下面的代码进行设置。
align = xlwt.Alignment()
# 垂直方向的对齐方式
align.vert = xlwt.Alignment.VERT_CENTER
# 水平方向的对齐方式
align.horz = xlwt.Alignment.HORZ_CENTER
header_style.alignment = align
如果希望给表头加上黄色的虚线边框,可以使用下面的代码来设置
borders = xlwt.Borders()
props = (
('top', 'top_colour'), ('right', 'right_colour'),
('bottom', 'bottom_colour'), ('left', 'left_colour')
)
# 通过循环对四个方向的边框样式及颜色进行设定
for position, color in props:
# 使用setattr内置函数动态给对象指定的属性赋值
setattr(borders, position, xlwt.Borders.DASHED)
setattr(borders, color, 5)
header_style.borders = borders
如果要调整单元格的宽度(列宽)和表头的高度(行高),可以按照下面的代码进行操作。
# 设置行高为40px
sheet.row(0).set_style(xlwt.easyxf(f'font:height {20 * 40}'))
titles = ('姓名', '语文', '数学', '英语')
for index, title in enumerate(titles):
# 设置列宽为200px
sheet.col(index).width = 20 * 200
# 设置单元格的数据和样式
sheet.write(0, index, title, header_style)
openpyxl
本章我们继续讲解基于另一个三方库 openpyxl 如何进行Excel文件操作,首先需要先安装它。
pip install openpyxl
openpyxl 的优点在于,当我们打开一个Excel文件后,既可以对它进行读操作,又可以对它进行写操
作,而且在操作的便捷性上是优于 xlwt 和 xlrd 的。此外,如果要进行样式编辑和公式计算,使用
openpyxl 也远比上一个章节我们讲解的方式更为简单,而且 openpyxl 还支持数据透视和插入图表等
操作,功能非常强大。有一点需要再次强调, openpyxl 并不支持操作Offiffiffice 2007以前版本的Excel文
件。
openpyxl读取Excel文件
例如在当前文件夹下有一个名为“阿里巴巴2020年股票数据.xlsx”的Excel文件,如果想读取并显示该文
件的内容,可以通过如下所示的代码来完成。
import datetime
import openpyxl
# 加载一个工作簿 ---> Workbook
wb = openpyxl.load_workbook('阿里巴巴2020年股票数据.xlsx')
# 获取工作表的名字
print(wb.sheetnames)
# 获取工作表 ---> Worksheet
sheet = wb.worksheets[0]
# 获得单元格的范围
print(sheet.dimensions)
# 获得行数和列数
print(sheet.max_row, sheet.max_column)
# 获取指定单元格的值
print(sheet.cell(3, 3).value)
print(sheet['C3'].value)
print(sheet['G255'].value)
# 获取多个单元格(嵌套元组)
print(sheet['A2:C5'])
# 读取所有单元格的数据
for row_ch in range(2, sheet.max_row + 1):
for col_ch in 'ABCDEFG':
value = sheet[f'{col_ch}{row_ch}'].value
if type(value) == datetime.datetime:
print(value.strftime('%Y年%m月%d日'), end='\t')
elif type(value) == int:
print(f'{value:<10d}', end='\t')
elif type(value) == float:
print(f'{value:.4f}', end='\t')
else:
print(value, end='\t')
print()
需要提醒大家一点, openpyxl 获取指定的单元格有两种方式,一种是通过 cell 方法,需要注意,该
方法的行索引和列索引都是从 1 开始的,这是为了照顾用惯了Excel的人的习惯;另一种是通过索引运
算,通过指定单元格的坐标,例如 C3 、 G255 ,也可以取得对应的单元格,再通过单元格对象的
value 属性,就可以获取到单元格的值。通过上面的代码,相信大家还注意到了,可以通过类似
sheet['A2:C5'] 或 sheet['A2':'C5'] 这样的切片操作获取多个单元格,该操作将返回嵌套的元组,
相当于获取到了多行多列。
openpyxl写Excel文件
openpyxl写Excel文件
import random
import openpyxl
# 第一步:创建工作簿(Workbook)
wb = openpyxl.Workbook()
# 第二步:添加工作表(Worksheet)
sheet = wb.active
sheet.title = '期末成绩'
titles = ('姓名', '语文', '数学', '英语')
for col_index, title in enumerate(titles):
sheet.cell(1, col_index + 1, title)
names = ('关羽', '张飞', 'c赵云', '马超', '黄忠')
for row_index, name in enumerate(names):
sheet.cell(row_index + 2, 1, name)
for col_index in range(2, 5):
sheet.cell(row_index + 2, col_index, random.randrange(50, 101))
# 第四步:保存工作簿
wb.save('考试成绩表.xlsx')
openpyxl调整样式和公式计算
在使用 openpyxl 操作Excel时,如果要调整单元格的样式,可以直接通过单元格对象( Cell 对象)的
属性进行操作。单元格对象的属性包括字体( font )、对齐( alignment )、边框( border )等,
具体的可以参考 openpyxl 的官方文档。在使用 openpyxl 时,如果需要做公式计算,可以完全按照
Excel中的操作方式来进行,具体的代码如下所示。
import openpyxl
from openpyxl.styles import Font, Alignment, Border, Side
# 对齐方式
alignment = Alignment(horizontal='center', vertical='center')
# 边框线条
side = Side(color='ff7f50', style='mediumDashed')
wb = openpyxl.load_workbook('考试成绩表.xlsx')
sheet = wb.worksheets[0]
# 调整行高和列宽
sheet.row_dimensions[1].height = 30
sheet.column_dimensions['E'].width = 120
sheet['E1'] = '平均分'
# 设置字体
sheet.cell(1, 5).font = Font(size=18, bold=True, color='ff1493', name='华文楷体')
# 设置对齐方式
sheet.cell(1, 5).alignment = alignment
# 设置单元格边框
sheet.cell(1, 5).border = Border(left=side, top=side, right=side, bottom=side)
for i in range(2, 7):
# 公式计算每个学生的平均分
sheet[f'E{i}'] = f'=average(B{i}:D{i})'
sheet.cell(i, 5).font = Font(size=12, color='4169e1', italic=True)
sheet.cell(i, 5).alignment = alignment
wb.save('考试成绩表.xlsx')
openpyxl生成统计图表
通过 openpyxl 库,可以直接向Excel中插入统计图表,具体的做法跟在Excel中插入图表大体一致。我
们可以创建指定类型的图表对象,然后通过该对象的属性对图表进行设置。当然,最为重要的是为图表
绑定数据,即横轴代表什么,纵轴代表什么,具体的数值是多少。最后,可以将图表对象添加到表单
中,具体的代码如下所示。
from openpyxl import Workbook
from openpyxl.chart import BarChart, Reference
wb = Workbook(write_only=True)
sheet = wb.create_sheet()
rows = [
('类别', '销售A组', '销售B组'),
('手机', 40, 30),
('平板', 50, 60),
('笔记本', 80, 70),
('外围设备', 20, 10),
]
# 向表单中添加行
for row in rows:
sheet.append(row)
# 创建图表对象
chart = BarChart()
chart.type = 'col'
chart.style = 10
# 设置图表的标题
chart.title = '销售统计图'
# 设置图表纵轴的标题
chart.y_axis.title = '销量'
# 设置图表横轴的标题
chart.x_axis.title = '商品类别'
# 设置数据的范围
data = Reference(sheet, min_col=2, min_row=1, max_row=5, max_col=3)
# 设置分类的范围
cats = Reference(sheet, min_col=1, min_row=2, max_row=5)
# 给图表添加数据
chart.add_data(data, titles_from_data=True)
# 给图表设置分类
chart.set_categories(cats)
chart.shape = 4
# 将图表添加到表单指定的单元格中
sheet.add_chart(chart, 'A10')
wb.save('demo.xlsx')
运行上面的代码,打开生成的Excel文件,效果如下图所示。

简单的总结
掌握了Python程序操作Excel的方法,可以解决日常办公中很多繁琐的处理Excel电子表格工作,最常见
就是将多个数据格式相同的Excel文件合并到一个文件以及从多个Excel文件或表单中提取指定的数据。
如果数据体量较大或者处理数据的方式比较复杂,我们还是推荐大家使用Python数据分析神器之一的
pandas 库。
22.Python操作Word
在日常工作中,有很多简单重复的劳动其实完全可以交给Python程序,比如根据样板文件(模板文件)
批量的生成很多个Word文件或PowerPoint文件。Word是微软公司开发的文字处理程序,相信大家都
不陌生,日常办公中很多正式的文档都是用Word进行撰写和编辑的,目前使用的Word文件后缀名一般
为 .docx 。PowerPoint是微软公司开发的演示文稿程序,是微软的Offiffiffice系列软件中的一员,被商业人
士、教师、学生等群体广泛使用,通常也将其称之为“幻灯片”。在Python中,可以使用名为 python
docx 的三方库来操作Word,可以使用名为 python-pptx 的三方库来生成PowerPoint。
操作Word文档
我们可以先通过下面的命令来安装 python-docx 三方库。
高版本lxml没有etree模块。有网友确定lxml4.2.5版本带有etree模块,且该版本lxml支持
python3.7.4版本。安装命令:
pip install lxml==4.2.5
pip install
我们在安装此模块儿使用的是pip install python-docx,但是在导入的时候是 docx;
from docx import Document
# docx.shared 用于设置大小(图片等)
from docx.shared import Cm, Pt
from docx.document import Document as Doc
# 创建代表Word文档的Doc对象
document = Document() # type: Doc
# 添加大标
document.add_heading('快快乐乐学Python', 0)
# 添加段落
p = document.add_paragraph('Python是一门非常流行的编程语言')
run = p.add_run('very easy')
run.bold = True
run.font.size = Pt(18)
p.add_run('hello')
run = p.add_run('非常棒')
run.font.size = Pt(18)
run.underline = False
p.add_run('。')
# 添加一级标题
document.add_heading('Heading, level 1', level=1)
# 添加带样式的段落
document.add_paragraph('Intense quote', style='Intense Quote')
# 添加无序列表
document.add_paragraph(
'first item in unordered list', style='List Bullet'
)
document.add_paragraph(
'second item in ordered list', style='List Bullet'
)
# 添加有序列表
document.add_paragraph(
'first item in ordered list', style='List Number'
)
document.add_paragraph(
'second item in ordered list', style='List Number'
)
# 添加图片(注意路径和图片必须要存在)
document.add_picture('resources/guido.jpg', width=Cm(5.2))
# 添加分节符
document.add_section()
records = (
('亚瑟', '战士英雄'),
('白起', '坦克英雄'),
('赵云', '刺客英雄'),
('女娲', '法师英雄'),
)
# 添加表格
table = document.add_table(rows=1, cols=3)
table.style = 'Dark List'
hdr_cells = table.rows[0].cells
hdr_cells[0].text = '姓名'
hdr_cells[1].text = '类别'rc#
# 为表格添加行
for name, sex, birthday in records:
row_cells = table.add_row().cells
row_cells[0].text = name
row_cells[1].text = sex
row_cells[2].text = birthday
# 添加分页符
document.add_page_break()
# 保存文档
document.save('demo.docx')提示:上面代码第7行中的注释 # type: Doc 是为了在PyCharm中获得代码补全提示,因为如果
不清楚对象具体的数据类型,PyCharm无法在后续代码中给出 Doc 对象的代码补全提示。
执行上面的代码,打开生成的Word文档,效果如下图所示。

对于一个已经存在的Word文件,我们可以通过下面的代码去遍历它所有的段落并获取对应的内容。
from docx import Document
#from docx.document import Document as Doc
doc = Document('resources/离职证明.docx') # type: Doc
for no, p in enumerate(doc.paragraphs):
print(no, p.text)
读取到的内容如下所示

讲到这里,相信很多读者已经想到了,我们可以把上面的离职证明制作成一个模板文件,把姓名、身份
证号、入职和离职日期等信息用占位符代替,这样通过对占位符的替换,就可以根据实际需要写入对应
的信息,这样就可以批量的生成Word文档。
按照上面的思路,我们首先编辑一个离职证明的模板文件,如下图所示。

接下来我们读取该文件,将占位符替换为真实信息,就可以生成一个新的Word文档,如下所示。
from docx import Document
from docx.document import Document as Doc
# 将真实信息用字典的方式保存在列表中
employees = [
{
'name': '骆昊',
'id': '100200198011280001',
'sdate': '2008年3月1日',
'edate': '2012年2月29日',
'department': '产品研发',
'position': '架构师',
'company': '成都华为技术有限公司'
},
{
'name': '王大锤',
'id': '510210199012125566',
'sdate': '2019年1月1日',
'edate': '2021年4月30日',
'department': '产品研发',
'position': 'Python开发工程师',
'company': '成都谷道科技有限公司'
},
{
'name': '李元芳',
'id': '2102101995103221599',
'sdate': '2020年5月10日',
'edate': '2021年3月5日',
'department': '产品研发',
'position': 'Java开发工程师',
'company': '同城企业管理集团有限公司'
},
]
# 对列表进行循环遍历,批量生成Word文档
for emp_dict in employees:
# 读取离职证明模板文件
doc = Document('resources/离职证明模板.docx') # type: Doc
# 循环遍历所有段落寻找占位符
for p in doc.paragraphs:
if '{' not in p.text:
continue
# 不能直接修改段落内容,否则会丢失样式
# 所以需要对段落中的元素进行遍历并进行查找替换
for run in p.runs:
if '{' not in run.text:
continue
# 将占位符换成实际内容
start, end = run.text.find('{'), run.text.find('}')
key, place_holder = run.text[start + 1:end], run.text[start:end + 1]
run.text = run.text.replace(place_holder, emp_dict[key])
# 每个人对应保存一个Word文档
doc.save(f'{emp_dict["name"]}离职证明.docx')执行上面的代码,会在当前路径下生成三个Word文档,如下图所示

23.python操作PowerPoint
首先我们需要安装名为 python-pptx 的三方库,命令如下所示。
pip install python-pptx
示例
import pptx
from pptx import Presentation
# 创建幻灯片对象sasls
pres = Presentation()
# 选择母版添加一页
title_slide_layout = pres.slide_layouts[0]
slide = pres.slides.add_slide(title_slide_layout)
# 获取标题栏和副标题栏
title = slide.shapes.title
subtitle = slide.placeholders[1]
# 编辑标题和副标题
title.text = "Welcome to Python"
subtitle.text = "Life is short, I use Python"
# 选择母版添加一页
bullet_slide_layout = pres.slide_layouts[1]
slide = pres.slides.add_slide(bullet_slide_layout)
# 获取页面上所有形状
shapes = slide.shapes
# 获取标题和主体
title_shape = shapes.title
body_shape = shapes.placeholders[1]
# 编辑标题
title_shape.text = 'Introduction'
# 编辑主体内容
tf = body_shape.text_frame
tf.text = 'History of Python'
# 添加一个一级段落
p = tf.add_paragraph()
p.text = 'X\'max 1989'
p.level = 1
# 添加一个二级段落
p = tf.add_paragraph()
p.text = 'Guido began to write interpreter for Python.'
p.level = 2
# 保存幻灯片
pres.save('test.pptx')运行上面的代码,生成的PowerPoint文件如下图所示。

简单的总结
用Python程序解决办公自动化的问题真的非常酷,它可以将我们从繁琐乏味的劳动中解放出来。写这类
代码就是去做一件一劳永逸的事情,写代码的过程即便不怎么愉快,使用这些代码的时候应该是非常开
心的。
24用Python操作PDF文件
从PDF中提取文本
在Python中,可以使用名为 PyPDF2 的三方库来读取PDF文件,可以使用下面的命令来安装它。
pip install PyPDF2
PyPDF2 没有办法从PDF文档中提取图像、图表或其他媒体,但它可以提取文本,并将其返回为Python
字符串。
import PyPDF2
reader = PyPDF2.PdfFileReader('test.pdf')
page = reader.getPage(0)
print(page.extractText())
要从PDF文件中提取文本也可以直接使用三方的命令行工具,具体的做法如下所示
pip install pdfminer.six
pdf2text.py test.pdf
旋转和叠加页面
上面的代码中通过创建 PdfFileReader 对象的方式来读取PDF文档,该对象的 getPage 方法可以获得
PDF文档的指定页并得到一个 PageObject 对象,通过 PageObject 对象的 rotateClockwise 和
rotateCounterClockwise 方法可以实现页面的顺时针和逆时针方向旋转,通过 PageObject 对象的
addBlankPage 方法可以添加一个新的空白页,代码如下
import PyPDF2
from PyPDF2.pdf import PageObject
# 创建一个读PDF文件的Reader对象
reader = PyPDF2.PdfFileReader('resources/XGBoost.pdf')
# 创建一个写PDF文件的Writer对象
writer = PyPDF2.PdfFileWriter()
# 对PDF文件所有页进行循环遍历
for page_num in range(reader.numPages):
# 获取指定页码的Page对象
current_page = reader.getPage(page_num) # type: PageObject
if page_num % 2 == 0:
# 奇数页顺时针旋转90度
current_page.rotateClockwise(90)
else:
# 偶数页反时针旋转90度
current_page.rotateCounterClockwise(90)
writer.addPage(current_page)
# 最后添加一个空白页并旋转90度
page = writer.addBlankPage() # type: PageObject
page.rotateClockwise(90)
# 通过Writer对象的write方法将PDF写入文件
with open('resources/XGBoost-modified.pdf', 'wb') as file:
writer.write(file)加密PDF文件
使用 PyPDF2 中的 PdfFileWrite 对象可以为PDF文档加密,如果需要给一系列的PDF文档设置统一的
访问口令,使用Python程序来处理就会非常的方便。
import PyPDF2
reader = PyPDF2.PdfFileReader('resources/XGBoost.pdf')
writer = PyPDF2.PdfFileWriter()
for page_num in range(reader.numPages):
writer.addPage(reader.getPage(page_num))
# 通过encrypt方法加密PDF文件,方法的参数就是rre
设置的密码
writer.encrypt('foobared')
with open('resources/XGBoost-encrypted.pdf', 'wb') as file:
writer.write(file)
批量添加水印
上面提到的 PageObject 对象还有一个名为 mergePage 的方法,可以两个PDF页面进行叠加,通过这个
操作,我们很容易实现给PDF文件添加水印的功能。例如要给上面的“XGBoost.pdf”文件添加一个水
印,我们可以先准备好一个提供水印页面的PDF文件,然后将包含水印的 PageObject 读取出来,然后
再循环遍历“XGBoost.pdf”文件的每个页,获取到 PageObject 对象,然后通过 mergePage 方法实现水
印页和原始页的合并,代码如下所示。
import PyPDF2
from PyPDF2.pdf import PageObject
reader1 = PyPDF2.PdfFileReader('resources/XGBoost.pdf')
reader2 = PyPDF2.PdfFileReader('resources/watermark.pdf')
writer = PyPDF2.PdfFileWriter()
# 获取水印页
watermark_page = reader2.getPage(0)
for page_num in range(reader1.numPages):
current_page = reader1.getPage(page_num) # type: PageObject
current_page.mergePage(watermark_page)
# 将原始页和水印页进行合并
writer.addPage(current_page)
# 将PDF写入文件
with open('resources/XGBoost-watermarked.pdf', 'wb') as file:
writer.write(file)创建PDF文件
创建PDF文档需要三方库 reportlab 的支持,安装的方法如下所示。
pip install reportlab
pip install reportlab
from reportlab.lib.pagesizes import A4
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
from reportlab.pdfgen import canvas
pdf_canvas = canvas.Canvas('resources/demo.pdf', pagesize=A4)
width, height = A4
# 绘图
image = canvas.ImageReader('resources/guido.jpg')
pdf_canvas.drawImage(image, 20, height - 395, 250, 375)
# 显示当前页
pdf_canvas.showPage()
# 注册字体文件
pdfmetrics.registerFont(TTFont('Font1', 'resources/fonts/Vera.ttf'))
pdfmetrics.registerFont(TTFont('Font2', 'resources/fonts/青呱石头体.ttf'))
# 写字
pdf_canvas.setFont('Font2', 40)
pdf_canvas.setFillColorRGB(0.9, 0.5, 0.3, 1)
pdf_canvas.drawString(width // 2 - 120, height // 2, '你好,世界!')
pdf_canvas.setFont('Font1', 40)
pdf_canvas.setFillColorRGB(0, 1, 0, 0.5)
pdf_canvas.rotate(18)
pdf_canvas.drawString(250, 250, 'hello, world!')
# 保存
pdf_canvas.save()25.字符串
a = "I'm Tom" # 一对双引号
b = 'Tom said:"I am Tom"' # 一对单引号
c = 'Tom said:"I\'m Tom"' # 转义字符
d = '''Tom said:"I'm Tom"''' # 三个单引号
e = """Tom said:"I'm Tom" """ # 三个双引号
name = 'abcdef'
print(name[0])
print(name[1])
print(name[2])
a
b
c
while语句遍历
msg = 'hello world'
i = 0while i < len(msg):
print(msg[i])
i += 1
for语句遍历:
msg = 'hello world'for x in msg:
print(x)
切片是指对操作的对象截取其中一部分的操作。字符串、列表、元组都支持切片操作。
切片的语法:[起始:结束:步长],也可以简化使用 [起始:结束]
注意:选取的区间从"起始"位开始,到"结束"位的前一位结束(不包含结束位本身),步长表示选取间隔。
# 索引是通过下标取某一个元素# 切片是通过下标去某一段元素
s = 'Hello World!'
print(s)
print(s[4]) # o 字符串里的第4个元素
print(s[3:7]) # lo W 包含下标 3,不含下标 7
print(s[:]) # Hello World! 取出所有元素(没有起始位和结束位之分),默认步长为1
print(s[1:]) # ello World! 从下标为1开始,取出 后面所有的元素(没有结束位)
print(s[:4]) # Hell 从起始位置开始,取到 下标为4的前一个元素(不包括结束位本身)
print(s[:-1]) # Hello World 从起始位置开始,取到 倒数第一个元素(不包括结束位本身)
print(s[-4:-1]) # rld 从倒数第4个元素开始,取到 倒数第1个元素(不包括结束位本身)
print(s[1:5:2]) # el 从下标为1开始,取到下标为5的前一个元素,步长为2(不包括结束位本身)
print(s[7:2:-1]) # ow ol 从下标为7的元素开始(包含下标为7的元素),倒着取到下标为2的元素(不包括下标为2的元素)
# python 字符串快速逆置
print(s[::-1]) # !dlroW olleH 从后向前,按步长为1进行取值
len函数可以获取字符串的长度。
mystr = '今天天气好晴朗,处处好风光呀好风光'
print(len(mystr)) # 17 获取字符串的长度
find
查找指定内容在字符串中是否存在,如果存在就返回该内容在字符串中第一次出现的开始位置索引值,如果不存在,则返回-1.
语法格式:
S.find(sub[, start[, end]]) -> int
示例:
mystr = '今天天气好晴朗,处处好风光呀好风光'
print(mystr.find('好风光')) # 10 '好风光'第一次出现时,'好'所在的位置
print(mystr.find('你好')) # -1 '你好'不存在,返回 -1
print(mystr.find('风', 12)) # 15 从下标12开始查找'风',找到风所在的位置试15
print(mystr.find('风光',1,10)) # -1 从下标1开始到12查找"风光",未找到,返回 -1
rfind
类似于 find()函数,不过是从右边开始查找。
mystr = '今天天气好晴朗,处处好风光呀好风光'
print(mystr.rfind('好')) # 14
index
跟find()方法一样,只不过,find方法未找到时,返回-1,而str未找到时,会报一个异常。
语法格式:
S.index(sub[, start[, end]]) -> int
rindex
类似于 index(),不过是从右边开始。
startswith
判断字符串是否以指定内容开始。 语法格式:
S.startswith(prefix[, start[, end]]) -> bool
示例:
mystr = '今天天气好晴朗,处处好风光呀好风光'
print(mystr.startswith('今')) # True
print(mystr.startswith('今日')) # False
endswith
判断字符串是否以指定内容结束。
mystr = '今天天气好晴朗,处处好风光呀好风光'
print(mystr.endswith('好风光')) #True
print(mystr.endswith('好日子')) #False
isalpha
判断字符串是否是纯字母。
mystr = 'hello'
print(mystr.isalpha()) # True
mystr = 'hello world'
print(mystr.isalpha()) # False 因为中间有空格
isdigit
判断一个字符串是否是纯数字,只要出现非0~9的数字,结果就是False.
mystr = '1234'
print(mystr.isdigit()) # True
mystr = '123.4'
print(mystr.isdigit()) # False
mystr = '-1234'
print(mystr.isdigit()) # False
isalnum
判断是否由数字和字母组成。只要出现了非数字和字母,就返回False.
mystr = 'abcd'
print(mystr.isalnum()) # True
mystr = '1234'
print(mystr.isalnum()) # True
mystr = 'abcd1234'
print(mystr.isalnum()) # True
mystr = 'abcd1234_'
print(mystr.isalnum()) # False
isspace
如果 mystr 中只包含空格,则返回 True,否则返回 False.
mystr = ''
print(mystr.isspace()) # False mystr是一个空字符串
mystr = ' '
print(mystr.isspace()) # True 只有空格
mystr = ' d'
print(mystr.isspace()) # False 除了空格外还有其他内容
count
返回 str在start和end之间 在 mystr里面出现的次数。
语法格式:
S.count(sub[, start[, end]]) -> int
示例:
mystr = '今天天气好晴朗,处处好风光呀好风光'
print(mystr.count('好')) # 3. '好'字出现三次
替换
替换字符串中指定的内容,如果指定次数count,则替换不会超过count次。
mystr = '今天天气好晴朗,处处好风光呀好风光'
newstr = mystr.replace('好', '坏')
print(mystr) # 今天天气好晴朗,处处好风光呀好风光 原字符串未改变!
print(newstr) # 今天天气坏晴朗,处处坏风光呀坏风光 得到的新字符串里,'好'被修改成了'坏'
newstr = mystr.replace('好','坏',2) # 指定了替换的次数
print(newstr) # 今天天气坏晴朗,处处坏风光呀好风光 只有两处的'好'被替换成了'坏'
内容分隔
内容分隔主要涉及到split,splitlines,partition和rpartition四个方法。
split
以指定字符串为分隔符切片,如果 maxsplit有指定值,则仅分隔 maxsplit+1 个子字符串。返回的结果是一个列表。
mystr = '今天天气好晴朗,处处好风光呀好风光'
result = mystr.split() # 没有指定分隔符,默认使用空格,换行等空白字符进行分隔
print(result) #['今天天气好晴朗,处处好风光呀好风光'] 没有空白字符,所以,字符串未被分隔
result = mystr.split('好') # 以 '好' 为分隔符
print(result) # ['今天天气', '晴朗,处处','风光呀,'风光']
result = mystr.split("好",2) # 以 '好' 为分隔符,最多切割成3份
print(result) # ['今天天气', '晴朗,处处', '风光呀好风光']
rsplit
用法和split基本一致,只不过是从右往左分隔。
mystr = '今天天气好晴朗,处处好风光呀好风光'
print(mystr.rsplit('好',1)) #['今天天气好晴朗,处处好风光呀', '风光']
splitlines
按照行分隔,返回一个包含各行作为元素的列表。
mystr = 'hello \nworld'
print(mystr.splitlines())
partition
把mystr以str分割成三部分,str前,str和str后,三部分组成一个元组
mystr = '今天天气好晴朗,处处好风光呀好风光'
print(mystr.partition('好')) # ('今天天气', '好', '晴朗,处处好风光呀好风光')
rpartition
类似于 partition()函数,不过是从右边开始.
mystr = '今天天气好晴朗,处处好风光呀好风光'
print(mystr.rpartition('好')) # ('今天天气好晴朗,处处好风光呀', '好', '风光')
修改大小写
修改大小写的功能只对英文有效,主要包括,首字母大写capitalize,每个单词的首字母大写title,全小写lower,全大写upper.
capitalize
第一个单词的首字母大写。
mystr = 'hello world'
print(mystr.capitalize()) # Hello world
title
每个单词的首字母大写。
mystr = 'hello world'
print(mystr.title()) # Hello World
lower
所有都变成小写。
mystr = 'hElLo WorLD'
print(mystr.lower()) # hello world
upper
所有都变成大写。
mystr = 'hello world'
print(mystr.upper()) #HELLO WORLD
空格处理
Python为我们提供了各种操作字符串里表格的方法。
ljust
返回指定长度的字符串,并在右侧使用空白字符补全(左对齐)。
str = 'hello'
print(str.ljust(10)) # hello 在右边补了五个空格
rjust
返回指定长度的字符串,并在左侧使用空白字符补全(右对齐)。
str = 'hello'
print(str.rjust(10)) # hello在左边补了五个空格
center
返回指定长度的字符串,并在两端使用空白字符补全(居中对齐)
str = 'hello'
print(str.center(10)) # hello 两端加空格,让内容居中
lstrip
删除 mystr 左边的空白字符。
mystr = ' he llo '
print(str.lstrip()) #he llo 只去掉了左边的空格,中间和右边的空格被保留
rstrip
删除 mystr 右边的空白字符。
mystr = ' he llo '
print(str.rstrip()) # he llo右边的空格被删除
strip
删除两断的空白字符。
str = ' he llo '
print(str.strip()) #he llo
字符串拼接
把参数进行遍历,取出参数里的每一项,然后再在后面加上mystr
语法格式:
S.join(iterable)
示例:
mystr = 'a'
print(mystr.join('hxmdq')) #haxamadaq 把hxmd一个个取出,并在后面添加字符a. 最后的 q 保留,没有加 a
print(mystr.join(['hi','hello','good'])) #hiahelloagood
作用:可以把列表或者元组快速的转变成为字符串,并且以指定的字符分隔。
txt = '_'
print(txt.join(['hi','hello','good'])) #hi_hello_good
print(txt.join(('good','hi','hello'))) #good_hi_hello
字符串运算符
字符串和字符串之间能够使用加法运算符,作用是将两个字符串拼接成为一个字符串。例如:'hello' + 'world'的结果是 'helloworld'
字符串和数字之间可以做乘法运算,结果是将指定的字符串重复多次。例如:'hello'*2的结果是hellohello
字符串和字符串之间,如果使用比较运算符进行计算,会获取字符对应的编码,然后进行比较。
除上述几种运算符以外,字符串默认不支持其他运算符。
字符集
计算机只能处理数字(其实就是数字0和数字1),如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),0 - 255被用来表示大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码。
ASCII码表使用7位二进制表示一个字符,它的区间范围时0~127,一共只能表示128个字符,仅能支持英语。随着计算机科学的发展,西欧语言、希腊语、泰语、阿拉伯语、希伯来语等语言的字符也被添加到码表中,形成了一个新的码表ISO8859-1(又被称为Latin1)码表。ISO8859-1使用8位二进制表示一个字符串,完全兼容ASCII码表。
Unicode(统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
字符和编码相互转换
使用chr和ord方法,可以实现字符和编码之间的相互转换。
print(ord('a')) # 使用ord方法,可以获取一个字符对应的编码
print(chr(100)) # 使用chr方法,可以获取一个编码对应的字符
编码规则
使用Unicode为每种语言的每个字符都设定了唯一的二进制编码,但是它还是存在一定的问题,不够完美。
例如,汉字 “你” 转换成为一个字符结果是0x4f60,转换成为二进制就是 01001111 01100000,此时就有两个问题:
1001111 01100000 到底是一个汉字 “你” ,还是两个 Latin1 字符?
如果Unicode进行了规定,每个字符都使用n个八位来表示,对于Latin1字符来说,又会浪费很多存储空间。
为了解决这个问题,就出现了一些编码规则,按照一定的编码规则对Unicode数字进行计算,得出新的编码。在中国常用的字符编码有 GBK,Big5和utf8这三种编码规则。
使用字符串的encode方法,可以将字符串按照指定的编码格式转换称为二进制;使用decode方法,可以将一个二进制数据按照指定的编码格式转换成为字符串。
s1 = '你'.encode('utf8') # 将字符 你 按照utf8格式编码称为二进制
print(type(s1)) #
print(s1) # b'\xe4\xbd\xa0'
s2 = s1.decode('utf8') # 将二进制按照utf8格式解码称为字符串
print(s2)
s3 = '你'.encode('gbk') # 将字符 你 按照gbk格式转换称为二进制
print(s3) # b'\xc4\xe3'
s4 = s3.decode('gbk') # 将二进制按照gbk格式解码称为字符
print(s4)
字符串的format方法
概念:
str.format() 方法通过字符串中的大括号{} 来识别替换字段 replacement field,从而完成字符串的格式化。
替换字段 由字段名 field name 和转换字段 conversion field 以及格式说明符 format specifier 组成,即一般形式为 {字段名!转换字段:格式说明符}。
字段名分为简单字段名 simple field name 和复合字段名 compound field name。而转换字段和格式说明符都是可选的。
字段名
form的完整格式是{字段名!转换字符:格式说明符}。其中字段名师必须的,而且可以分为简单字段名和复合字段名。
简单字段名
简单字段名由三中写法:
省略字段名:{}
使用非负十进制整数{0}
变量名{name}
省略字段名
大括号内省略字段名,传递位置参数。
替换字段形式: {}
注意:大括号个数可以少于位置参数的个数,反之不然。
# 省略字段名传递位置参数
print('我叫{},今年{}岁。'.format('小明', 18))"""
我叫小明,今年18岁。
"""
# 大括号个数可以少于位置参数的个数
print('我爱吃{}和{}。'.format('香蕉', '苹果', '大鸭梨'))"""
我爱吃香蕉和苹果。
"""
# 大括号个数多于位置参数的个数则会报错# print('我还吃{}和{}。'.format('西红柿'))"""
IndexError: tuple index out of range
"""
数字字段名
可以通过数字形式的简单字段名传递位置参数。
数字必须是大于等于 0 的整数。
带数字的替换字段可以重复使用。
数字形式的简单字段名相当于把 format 中的所有位置参数整体当作一个元组,通过字段名中的数字进行取值。即 {0} 等价于 tuple[0],所以大括号内的数字不能越界。
# 通过数字形式的简单字段名传递位置参数
print('身高{0},家住{1}。'.format(1.8, '铜锣湾'))"""
身高1.8,家住铜锣湾
"""
# 数字形式的简单字段名可以重复使用。
print('我爱{0}。\n她今年{1}。\n我也爱{0}。'.format('阿香', 17))"""
我爱阿香。
她今年17。
我也爱阿香。
"""
# 体会把所有位置参数整体当成元组来取值
print('阿香爱吃{1}、{3}和{0}。'.format(
'榴莲', '臭豆腐', '皮蛋', '鲱鱼罐头', '螺狮粉'))"""
阿香爱吃臭豆腐、鲱鱼罐头和榴莲。
"""
# 尝试一下越界错误# print('{1}'.format('错误用法'))"""
IndexError: tuple index out of range
"""
变量字段名
使用变量名形式的简单字段名传递关键字参数。
关键字参数的位置可以随意调换。
# 使用变量名形式的简单字段名传递关键字参数
print('我大哥是{name},今年{age}岁。'.format(name='阿飞', age=20))"""
我大哥是阿飞,今年20岁。
"""
# 关键字参数的顺序可以随意调换
print('我大哥是{name},今年{age}岁。'.format(age=20, name='阿飞'))"""
我大哥是阿飞,今年20岁。
"""
简单字段名的混合使用
混合使用数字形式和变量名形式的字段名,可以同时传递位置参数和关键字参数。
关键字参数必须位于位置参数之后。
混合使用时可以省略数字。
省略字段名 {} 不能和数字形式的字段名 {非负整数} 同时使用。
# 混合使用数字形式和变量名形式的字段名# 可以同时传递位置参数和关键字参数
print('这是一个关于{0}、{1}和{girl}的故事。'.format(
'小明', '阿飞', girl='阿香'))"""
这是一个关于小明、阿飞和阿香的故事。
"""
# 但是关键字参数必须位于位置参数之后# print('这是一个关于{0}、{1}和{girl}的故事。'.format(
# '小明', girl='阿香' , '阿飞'))"""
SyntaxError: positional argument follows keyword argument
"""
# 数字也可以省略
print('这是一个关于{}、{}和{girl}的故事。'.format(
'小明', '阿飞', girl='阿香'))
# 但是省略字段名不能和数字形式的字段名同时出现# print('这是一个关于{}、{1}和{girl}的故事。'.format(# '小明', '阿飞', girl='阿香'))"""
ValueError: cannot switch from automatic field numbering to manual field specification
"""
使用元组和字典传参
str.format() 方法还可以使用 *元组 和 **字典 的形式传参,两者可以混合使用。 位置参数、关键字参数、*元组 和 **字典 也可以同时使用,但是要注意,位置参数要在关键字参数前面,*元组 要在 **字典 前面。
# 使用元组传参
infos = '钢铁侠', 66, '小辣椒'
print('我是{},身价{}亿。'.format(*infos))"""
我是钢铁侠,身家66亿。
"""
print('我是{2},身价{1}亿。'.format(*infos))"""
我是小辣椒,身家66亿。
"""
# 使用字典传参
venom = {'name': '毒液', 'weakness': '火'}
print('我是{name},我怕{weakness}。'.format(**venom))"""
我是毒液,我怕火。
"""
# 同时使用元组和字典传参
hulk = '绿巨人', '拳头'
captain = {'name': '美国队长', 'weapon': '盾'}
print('我是{}, 我怕{weapon}。'.format(*hulk, **captain))
print('我是{name}, 我怕{1}。'.format(*hulk, **captain))
"""
我是绿巨人, 我怕盾。
我是美国队长, 我怕拳头。
"""
# 同时使用位置参数、元组、关键字参数、字典传参# 注意:# 位置参数要在关键字参数前面# *元组要在**字典前面
tup = '鹰眼',
dic = {'weapon': '箭'}
text = '我是{1},我怕{weakness}。我是{0},我用{weapon}。'
text = text.format(
*tup, '黑寡妇', weakness='男人', **dic)
print(text)"""
我是黑寡妇,我怕男人。我是鹰眼,我用箭。
"""
复合字段名
同时使用了数字和变量名两种形式的字段名就是复合字段名。
复合字段名
支持两种操作符:
. 点号
[] 中括号
使用. 点号
传递位置参数
替换字段形式:{数字.属性名}
只有一个替换字段的时候可以省略数字
class Person(object):
def __init__(self,name,age,gender):
self.name = name
self.age = age
self.gender = gender
p = Person('zhangsan',18,'female')
print('姓名是{0.name},年龄是{0.age},性别是{0.gender}'.format(p))
print('姓名是{.name}'.format(p)) # 只有一个替换字段时,可以省略数字
使用[]中括号
用列表传递位置参数
用元组传递位置参数
用字典传递位置参数
# 中括号用法:用列表传递位置参数
infos = ['阿星', 9527]
food = ['霸王花', '爆米花']
print('我叫{0[0]},警号{0[1]},爱吃{1[0]}。'.format(
infos, food))"""
我叫阿星,警号9527,爱吃霸王花。
"""
# 中括号用法:用元组传递位置参数
food = ('僵尸', '脑子')
print('我叫{0[0]},年龄{1},爱吃{0[1]}。'.format(
food, 66))"""
我叫僵尸,年龄66,爱吃脑子。
"""
# 中括号用法:用字典传递位置参数
dic = dict(name='阿星', pid=9527)
print('我是{[name]}!'.format(
dic))# 多个替换字段,不能省略数字
print('我是{0[name]},警号{0[pid]}。'.format(
dic))"""
我是阿星!
我是阿星,警号9527。
"""
转换字段
转换字段 conversion field 的取值有三种,前面要加 !:
s:传递参数之前先对参数调用 str()
r:传递参数之前先对参数调用 repr()
a:传递参数之前先对参数调用 ascii()
ascii() 函数类似 repr() 函数,返回一个可以表示对象的字符串。 但是对于非 ASCII 字符,使用 \x,\u 或者 \U 转义。
# 转换字段
print('I am {!s}!'.format('Bruce Lee 李小龙'))
print('I am {!r}!'.format('Bruce Lee 李小龙'))
print('I am {!a}!'.format('Bruce Lee 李小龙'))"""
I am Bruce Lee 李小龙!
I am 'Bruce Lee 李小龙'!
I am 'Bruce Lee \u674e\u5c0f\u9f99'!
"""
26.列表
定义列的格式:[元素1, 元素2, 元素3, ..., 元素n]
变量tmp的类型为列表
tmp = ['xiaoWang',180, 65.0]Copy
列表中的元素可以是不同类型的
使用下标获取列表元素
namesList = ['xiaoWang','xiaoZhang','xiaoHua']
print(namesList[0])
print(namesList[1])
print(namesList[2])Copy
结果:
xiaoWang
xiaoZhang
xiaoHua 列表的数据操作
我们对于可变数据(例如,列表,数据库等)的操作,一般包含增、删、改、查四个方面。
添加元素
添加元素有一下几个方法:
- append 在末尾添加元素
- insert 在指定位置插入元素
- extend 合并两个列表
append
append会把新元素添加到列表末尾
#定义变量A,默认有3个元素
A = ['xiaoWang','xiaoZhang','xiaoHua']
print("-----添加之前,列表A的数据-----A=%s" % A)
#提示、并添加元素
temp = input('请输入要添加的学生姓名:')
A.append(temp)
print("-----添加之后,列表A的数据-----A=%s" % A)Copy
insert
insert(index, object) 在指定位置index前插入元素object
strs = ['a','b','m','s']
strs.insert(3,'h')
print(strs) # ['a', 'b', 'm', 'h', 's']Copy
extend
通过extend可以将另一个集合中的元素逐一添加到列表中
a = ['a','b','c']
b = ['d','e','f']
a.extend(b)
print(a) # ['a', 'b', 'c', 'd', 'e', 'f'] 将 b 添加到 a 里
print(b) # ['d','e','f'] b的内容不变Copy
修改元素
我们是通过指定下标来访问列表元素,因此修改元素的时候,为指定的列表下标赋值即可。
#定义变量A,默认有3个元素
A = ['xiaoWang','xiaoZhang','xiaoHua']
print("-----修改之前,列表A的数据-----A=%s" % A)
#修改元素
A[1] = 'xiaoLu'
print("-----修改之后,列表A的数据-----A=%s" % A)Copy
查找元素
所谓的查找,就是看看指定的元素是否存在,以及查看元素所在的位置,主要包含一下几个方法:
- in 和 not in
- index 和 count
in, not in
python中查找的常用方法为:
- in(存在),如果存在那么结果为true,否则为false
- not in(不存在),如果不存在那么结果为true,否则false
#待查找的列表
nameList = ['xiaoWang','xiaoZhang','xiaoHua']
#获取用户要查找的名字
findName = input('请输入要查找的姓名:')
#查找是否存在
if findName in nameList:
print('在列表中找到了相同的名字')
else:
print('没有找到')Copy
结果1:(找到)

结果2:(没有找到)

说明:
in的方法只要会用了,那么not in也是同样的用法,只不过not in判断的是不存在
index, count
index用来查找元素所在的位置,如果未找到则会报错;count用来计算某个元素出现的次数。它们的使用和字符串里的使用效果一致。
>>> a = ['a', 'b', 'c', 'a', 'b']>>> a.index('a', 1, 3) # 注意是左闭右开区间
Traceback (most recent call last):
File "
ValueError: 'a' is not in list>>> a.index('a', 1, 4)3>>> a.count('b')2>>> a.count('d')0Copy
删除元素
类比现实生活中,如果某位同学调班了,那么就应该把这个条走后的学生的姓名删除掉;在开发中经常会用到删除这种功能。
列表元素的常用删除方法有:
- del:根据下标进行删除
- pop:删除最后一个元素
- remove:根据元素的值进行删除
del
movieName = ['加勒比海盗','骇客帝国','第一滴血','指环王','霍比特人','速度与激情']
print('------删除之前------movieName=%s' % movieName)del movieName[2]
print('------删除之后------movieName=%s' % movieName)Copy
pop
movieName = ['加勒比海盗','骇客帝国','第一滴血','指环王','霍比特人','速度与激情']
print('------删除之前------movieName=%s' % movieName)
movieName.pop()
print('------删除之后------movieName=%s' % movieName)Copy
remove
movieName = ['加勒比海盗','骇客帝国','第一滴血','指环王','霍比特人','速度与激情']
print('------删除之前------movieName=%s' % movieName)
movieName.remove('指环王')
print('------删除之后------movieName=%s' % movieName)Copy
排序(sort, reverse)
sort方法是将list按特定顺序重新排列,默认为由小到大,参数reverse=True可改为倒序,由大到小。
reverse方法是将list逆置。
>>> a = [1, 4, 2, 3]>>> a
[1, 4, 2, 3]>>> a.reverse() # 逆置,不排序>>> a
[3, 2, 4, 1]>>> a.sort() # 默认从小到大排序>>> a
[1, 2, 3, 4]>>> a.sort(reverse=True) # 从大到小排序>>> a
[4, 3, 2, 1]
列表的循环遍历
使用while循环
为了更有效率的输出列表的每个数据,可以使用循环来完成
namesList = ['xiaoWang','xiaoZhang','xiaoHua']
length = len(namesList) # 获取列表长度
i = 0while i
print(namesList[i])
i+=1Copy
结果:
xiaoWang
xiaoZhang
xiaoHuaCopy
使用for循环
while 循环是一种基本的遍历列表数据的方式,但是最常用也是最简单的方式是使用 for 循环
namesList = ['xiaoWang','xiaoZhang','xiaoHua']for name in namesList:
print(name)Copy
结果:
xiaoWang
xiaoZhang
xiaoHuaCopy
交换2个变量的值
# 使用中间变量
a = 4
b = 5
c = 0
c = a
a = b
b = c
print(a)
print(b)
列表嵌套
类似while循环的嵌套,列表也是支持嵌套的
一个列表中的元素又是一个列表,那么这就是列表的嵌套
此处重点掌握怎么操作被嵌套的列表
>>> schoolNames = [... [1, 2, 3],... [11, 22, 33],... [111, 222, 333]... ]>>> schoolNames[1][2] # 获取数字 3333>>> schoolNames[1][2] = 'abc' # 把 33 修改为 'abc'>>> schoolNames
[[1, 2, 3], [11, 22, 'abc'], [111, 222, 333]]>>> schoolNames[1][2][2] # 获取 'abc' 里的字符c'c'Copy
也就是说,操作嵌套列表,只要把要操作元素的下标当作变量名来使用即可。
应用
一个学校,有3个办公室,现在有8位老师等待工位的分配,请编写程序,完成随机的分配
import random
# 定义一个列表用来保存3个办公室
offices = [[],[],[]]
# 定义一个列表用来存储8位老师的名字
names = ['A','B','C','D','E','F','G','H']
i = 0for name in names:
index = random.randint(0,2)
offices[index].append(name)
i = 1for tempNames in offices:
print('办公室%d的人数为:%d'%(i,len(tempNames)))
i+=1
for name in tempNames:
print("%s"%name,end='')
print("\n")
print("-"*20)
运行结果如下:

列表推导式
所谓的列表推导式,就是指的轻量级循环创建列表
基本的方式

在循环的过程中使用if

2个for循环

3个for循环

列表的复制
查看以下代码,说出打印的结果。
a = 12
b = a
b = 13
print(b)
print(a)
nums1 = [1, 5, 8, 9, 10, 12]
nums2 = nums1
nums2[0] = 100
print(nums2)
print(nums1)Copy
思考:
- 为什么修改了 nums2里的数据,nums1的数据也会改变?
Python中的赋值运算都是引用(即内存地址)的传递。对于可变类型来说,修改原数据的值,会改变赋值对象的值。
- 怎样nums1和nums2变成两个相互独立不受影响的列表?
使用列表的 copy 方法,或者 copy 模块就可以赋值一个列表。
列表的copy方法
使用列表的copy方法,可以直接将原来的列表进行复制,变成一个新的列表,这种复制方式是浅复制。
nums1 = [1, 5, 8, 9, 10, 12]
nums2 = nums1.copy() # 调用列表的copy方法,可以复制出一个新的列表
nums2[0] = 100
# 修改新列表里的数据,不会影响到原有列表里的数据
print(nums2)
print(nums1)Copy
copy模块的使用
除了使用列表的copy方法以外,Python还提供了copy模块来复制一个对象。copy模块提供了浅复制和深复制两种方式,它们的使用方式相同,但是执行的效果有一定的差异。
浅拷贝
浅拷贝是对于一个对象的顶层拷贝,通俗的理解是:拷贝了引用,并没有拷贝内容。
import copy
words1 = ['hello', 'good', ['yes', 'ok'], 'bad']
# 浅拷贝只会拷贝最外层的对象,里面的数据不会拷贝,而是直接指向
words2 = copy.copy(words1)
words2[0] = '你好'
words2[2][0] = 'no'
print(words1) # ['hello', 'good', ['no', 'ok'], 'bad']# wrods2 里的 yes 被修改成了 no
print(words2) # ['你好', 'good', ['no', 'ok'], 'bad']Copy
深拷贝
深拷贝是对于一个对象所有层次的递归拷贝。
import copy
words1 = ['hello', 'good', ['yes', 'ok'], 'bad']
# 深拷贝会将对象里的所有数据都进行拷贝
words2 = copy.deepcopy(words1)
words2[0] = '你好'
words2[2][0] = 'no'
print(words1) # ['hello', 'good', ['yes', 'ok'], 'bad']
print(words2) # ['你好', 'good', ['no', 'ok'], 'bad']Copy
切片
列表和字符串一样,也支持切片,切片其实就是一种浅拷贝。
words1 = ['hello', 'good', ['yes', 'ok'], 'bad']
words2 = words1[:]
words2[0] = '你好'
words2[2][0] = 'no'
print(words1) # ['hello', 'good', ['no', 'ok'], 'bad']
print(words2) # ['你好', 'good', ['no', 'ok'], 'bad']
27元组
Python的元组与列表类似,不同之处在于元组的元素不能修改。元组使用小括号,列表使用方括号。
>>> aTuple = ('et',77,99.9)>>> aTuple
('et',77,99.9)
访问元组

修改元组

说明: python中不允许修改元组的数据,包括不能删除其中的元素。
count, index
index和count与字符串和列表中的用法相同
>>> a = ('a', 'b', 'c', 'a', 'b')>>> a.index('a', 1, 3) # 注意是左闭右开区间
Traceback (most recent call last):
File "
ValueError: tuple.index(x): x not in tuple>>> a.index('a', 1, 4)3>>> a.count('b')2>>> a.count('d')0
定义只有一个数据的元组
定义只有一个元素的元组,需要在唯一的元素后写一个逗号
>>> a = (11)>>> a11>>> type(a)
int>>> a = (11,) # 只有一个元素的元组,必须要在元素后写一个逗号>>> a
(11,)>>> type(a)
tupleCopy
交换两个变量的值
# 第1种方式,使用中间变量
a = 4
b = 5
c = 0
c = a
a = b
b = c
print(a)
print(b)
# 第2种方式,直接交换。
a, b = 4, 5
a, b = b, a
print(a)
print(b)
28字典
列表的缺点
当存储的数据要动态添加、删除的时候,我们一般使用列表,但是列表有时会遇到一些麻烦。
# 定义一个列表保存,姓名、性别、职业
nameList = ['xiaoZhang', '男', '木匠'];
# 当修改职业的时候,需要记忆元素的下标
nameList[2] = '铁匠'
# 如果列表的顺序发生了变化,添加年龄
nameList = ['xiaoWang', 18, '男', '铁匠']
# 此时就需要记忆新的下标,才能完成名字的修改
nameList[3] = 'xiaoxiaoWang'Copy
有没有方法,既能存储多个数据,还能在访问元素的很方便就能够定位到需要的那个元素呢?
答:
字典
字典的使用
定义字典的格式:{键1:值1, 键2:值2, 键3:值3, ..., 键n:值n}
变量info为字典类型:
info = {'name':'班长', 'id':100, 'sex':'f', 'address':'地球亚洲中国上海'}
info['name'] # 字典使用键来获取对应的值Copy
说明:
- 字典和列表一样,也能够存储多个数据
- 列表中找某个元素时,是根据下标进行的;字典中找某个元素时,是根据'名字'(就是冒号:前面的那个值,例如上面代码中的'name'、'id'、'sex')
- 字典的每个元素由2部分组成,键:值。例如 'name':'班长' ,'name'为键,'班长'为值
- 键可以使用数字、布尔值、布尔值、元组等不可变数据类型,但是一般习惯使用字符串
- 每个字典里的key都是唯一的,如果出现了多个key,后面的value会覆盖前一个key对应的value.
在习惯上:
- 列表更适合保存多个商品、多个姓名、多个时间,这样的相似数据;
- 字典更适合保存一个商品的不同信息、一个人的不同信息,这样的不同数据。
字典的增删改查
查看元素
除了使用key查找数据,还可以使用get来获取数据
info = {'name':'班长','age':18}
print(info['age']) # 获取年龄# print(info['sex']) # 获取不存在的key,会发生异常
print(info.get('sex')) # 获取不存在的key,获取到空的内容,不会出现异常
print(info.get('sex', '男')) # 获取不存在的key, 可以提供一个默认值。Copy
注意,获取默认值不会修改字典内容。
修改元素
字典的每个元素中的数据是可以修改的,只要通过key找到,即可修改
demo:
info = {'name':'班长', 'id':100}
print('修改之前的字典为 %s:' % info)
info['id'] = 200 # 为已存在的键赋值就是修改
print('修改之后的字典为 %s:' % info)Copy
结果:
修改之前的字典为 {'name': '班长', 'id': 100}
修改之后的字典为 {'name': '班长', 'id': 200}
添加元素
如果在使用 变量名['键'] = 数据 时,这个“键”在字典中,不存在,那么就会新增这个元素
demo:添加新的元素
info = {'name':'班长'}
print('添加之前的字典为:%s' % info)
info['id'] = 100 # 为不存在的键赋值就是添加元素
print('添加之后的字典为:%s' % info)Copy
结果:
添加之前的字典为:{'name': '班长'}
添加之后的字典为:{'name': '班长', 'id': 100}
删除元素
对字典进行删除操作,有一下几种:
- del
- clear()
demo:del删除指定的元素
info = {'name':'班长', 'id':100}
print('删除前,%s' % info)
del info['name'] # del 可以通过键删除字典里的指定元素
print('删除后,%s' % info)Copy
结果
删除前,{'name': '班长', 'id': 100}
删除后,{'id': 100}Copy
del删除整个字典
info = {'name':'monitor', 'id':100}
print('删除前,%s'%info)
del info # del 也可以直接删除变量
print('删除后,%s'%info)Copy
结果
删除前,{'name': 'monitor', 'id': 100}
Traceback (most recent call last):
File "
NameError: name 'info' is not definedCopy
clear清空整个字典
info = {'name':'monitor', 'id':100}
print('清空前,%s'%info)
info.clear()
print('清空后,%s'%info)Copy
结果
清空前,{'name': 'monitor', 'id': 100}
清空后,{}
字典遍历
<1> 遍历字典的key(键)

<2> 遍历字典的value(值)

<3> 遍历字典的项(元素)

<4> 遍历字典的key-value(键值对)

- 有一个列表persons,保存的数据都是字典
persons = [{'name': 'zhangsan', 'age': 18}, {'name': 'lisi', 'age': 20}, {'name': 'wangwu', 'age': 19},{'name': 'jerry', 'age': 21}]Copy
要求让用户输入一个姓名,如果这个姓名在列表里存在,就提示用户名称已存在,添加失败;如果这个姓名在列表里不存在,提示让用户输入年龄,并将用户输入的姓名和年龄添加到这个列表里。
- 有一个字典dict1 = {"a":100,"b":200,"c":300},使用代码,将字典的key和value互换,变成 {100:"a",200:"b",300:"c"}.
参考答案:(使用字典推导式)
dict1 = {"a": 100, "b": 200, "c": 300}
dict2 = {v: k for k, v in dict1.items()}
print(dict2)
29集合
set的使用
集合(set)是一个无序的不重复元素序列,可以使用大括号 { } 或者 set() 函数创建集合。
注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
创建格式:
parame = {value01,value02,...}
或者
set(value)Copy
添加元素
语法格式如下:
s.add(x)Copy
将元素 x 添加到集合 s 中,如果元素已存在,则不进行任何操作。
>>>thisset = set(("Google", "Runoob", "Taobao"))>>> thisset.add("Facebook")>>> print(thisset)
{'Taobao', 'Facebook', 'Google', 'Runoob'}Copy
还有一个方法,也可以添加元素,且参数可以是列表,元组,字典等,语法格式如下:
s.update( x )Copy
x 可以有多个,用逗号分开。
>>>thisset = set(("Google", "Runoob", "Taobao"))>>> thisset.update({1,3})>>> print(thisset)
{1, 3, 'Google', 'Taobao', 'Runoob'}>>> thisset.update([1,4],[5,6]) >>> print(thisset)
{1, 3, 4, 5, 6, 'Google', 'Taobao', 'Runoob'}Copy
移除元素
语法格式如下:
s.remove( x )Copy
将元素 x 从集合 s 中移除,如果元素不存在,则会发生错误。
>>>thisset = set(("Google", "Runoob", "Taobao"))>>> thisset.remove("Taobao")>>> print(thisset)
{'Google', 'Runoob'}>>> thisset.remove("Facebook") # 不存在会发生错误
Traceback (most recent call last):
File "
KeyError: 'Facebook'
>>>Copy
此外还有一个方法也是移除集合中的元素,且如果元素不存在,不会发生错误。格式如下所示:
s.discard( x )Copy
>>>thisset = set(("Google", "Runoob", "Taobao"))>>> thisset.discard("Facebook") # 不存在不会发生错误>>> print(thisset)
{'Taobao', 'Google', 'Runoob'}Copy
我们也可以设置随机删除集合中的一个元素,语法格式如下:
s.pop()Copy
thisset = set(("Google", "Runoob", "Taobao", "Facebook"))
x = thisset.pop()
print(x)
print(thisset)


有一个无序且元素数据重复的列表nums, nums=[5,8,7,6,4,1,3,5,1,8,4],要求对这个列表里的元素去重,并进行降序排序。
# 方法一:调用列表的sort方法
nums2 = list(set(nums))
nums2.sort(reverse=True)
print(nums2)
# 方法二:使用sorted内置函数
print(sorted(list(set(nums)),reverse=True))
30.转换
===================转换相关的===================
执行字符串
使用Python内置的eval函数,可以执行字符串里的Python代码。使用这种方式,可以将字符串转换成为其他类型的数据。
x = '1+1'
print(eval(x)) # 2
print(type(eval(x))) #
y = '{"name":"zhangsan","age":18}'
print(eval(y))
print(type(eval(y))) #
print(eval('1 > 2')) # False
eval('input("请输入您的姓名:")')Copy
转换成为字符串
JSON(JavaScriptObjectNotation, JS对象简谱)是一种轻量级的数据交换格式,它基于 ECMAScript 的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。JSON本质是一个字符串
JSON的功能强大,使用场景也非常的广,目前我们只介绍如何使用Python的内置JSON模块,实现字典、列表或者元组与字符串之间的相互转换。
使用json的dumps方法,可以将字典、列表或者元组转换成为字符串。
import json
person = {'name': 'zhangsan', 'age': 18}
x = json.dumps(person)
print(x) # {"name": "zhangsan", "age": 18}
print(type(x)) #
nums = [1, 9, 0, 4, 7]
y = json.dumps(nums)
print(y) # [1, 9, 0, 4, 7]
print(type(y)) #
words = ('hello','good','yes')
z = json.dumps(words)
print(z) # ["hello", "good", "yes"]
print(type(z)) #
使用json的loads方法,可以将格式正确的字符串转换成为字典、列表。
x = '{"name": "zhangsan", "age": 18}'
person = json.loads(x)
print(person) # {'name': 'zhangsan', 'age': 18}
print(type(person)) #
y = '[1, 9, 0, 4, 7]'
nums = json.loads(y)
print(nums) # [1, 9, 0, 4, 7]
print(type(nums)) #
31
=====================通用方法=====================





32模块和包
Python中的模块
在Python中有一个概念叫做模块(module)。
说的通俗点:模块就好比是工具包,要想使用这个工具包中的工具(就好比函数),就需要导入这个模块
比如我们经常使用工具 random,就是一个模块。使用 import random 导入工具之后,就可以使用 random 的函数。
导入模块
<1> 导入模块有五种方式
- import 模块名
- from 模块名 import 功能名
- from 模块名 import *
- import 模块名 as 别名
- from 模块名 import 功能名 as 别名
下面来挨个的看一下。
<2>import
在Python中用关键字import来引入某个模块,比如要引入系统模块 math,就可以在文件最开始的地方用import math来引入。
语法:
import 模块1,模块2,... # 导入方式
模块名.函数名() # 使用模块里的函数Copy
想一想:
为什么必须加上模块名调用呢?
答:
因为可能存在这样一种情况:在多个模块中含有相同名称的函数,此时如果只是通过函数名来调用,解释器无法知道到底要调用哪个函数。所以如果像上述这样引入模块的时候,调用函数必须加上模块
示例:
import math
#这样才能正确输出结果print math.sqrt(2)
#这样会报错
print(sqrt(2))Copy
<3>from…import
有时候我们只需要用到模块中的某个函数,只需要引入该函数即可,此时可以用下面方法实现:
from 模块名 import 函数名1,函数名2....Copy
不仅可以引入函数,还可以引入一些全局变量、类等
注意:
通过这种方式引入的时候,调用函数时只能给出函数名,不能给出模块名,但是当两个模块中含有相同名称函数的时候,后面一次引入会覆盖前一次引入。也就是说假如模块A中有函数function( ),在模块B中也有函数function( ),如果引入A中的function在先、B中的function在后,那么当调用function函数的时候,是去执行模块B中的function函数。
例如,要导入模块fib的fibonacci函数,使用如下语句:
from fib import fibonacciCopy
注意
- 不会把整个fib模块导入到当前的命名空间中,它只会将fib里的fibonacci单个函数引入
<4>from … import *
把一个模块的所有内容全都导入到当前的命名空间也是可行的,只需使用如下声明:
from modname import *Copy
注意
- 这提供了一个简单的方法来导入一个模块中的所有项目。然而这种声明不该被过多地使用。
<5> as 别名
In [1]: import time as tt # 导入模块时设置别名为 tt
In [2]: time.sleep(1)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
----> 1 time.sleep(1)
NameError: name 'time' is not defined
In [3]:
In [3]: tt.sleep(1) # 使用别名才能调用方法
In [4]:
In [4]: from time import sleep as sp # 导入方法时设置别名
In [5]: sleep(1)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
----> 1 sleep(1)
NameError: name 'sleep' is not defined
In [6]:
In [6]: sp(1) # 使用别名才能调用方法
In [7]:
常见系统模块
为了方便程序员开发代码,Python提供了很多内置的模块给程序员用来提高编码效率。常见的内置模块有:
- os模块
- sys模块
- math模块
- random模块
- datetime模块
- time模块
- calendar模块
- hashlib模块
- hmac模块
- copy模块
- uuid模块
OS模块
OS全称OperationSystem,即操作系统模块,这个模块可以用来操作系统的功能,并且实现跨平台操作。
import os
os.getcwd() # 获取当前的工作目录,即当前python脚本工作的目录
os.chdir('test') # 改变当前脚本工作目录,相当于shell下的cd命令
os.rename('毕业论文.txt','毕业论文-最终版.txt') # 文件重命名
os.remove('毕业论文.txt') # 删除文件
os.rmdir('demo') # 删除空文件夹
os.removedirs('demo') # 删除空文件夹
os.mkdir('demo') # 创建一个文件夹
os.chdir('C:\\') # 切换工作目录
os.listdir('C:\\') # 列出指定目录里的所有文件和文件夹
os.name # nt->widonws posix->Linux/Unix或者MacOS
os.environ # 获取到环境配置
os.environ.get('PATH') # 获取指定的环境配置
os.path.abspath(path) # 获取Path规范会的绝对路径
os.path.exists(path) # 如果Path存在,则返回True
os.path.isdir(path) # 如果path是一个存在的目录,返回True。否则返回False
os.path.isfile(path) # 如果path是一个存在的文件,返回True。否则返回False
os.path.splitext(path) # 用来将指定路径进行分隔,可以获取到文件的后缀名Copy
sys模块
该模块提供对解释器使用或维护的一些变量的访问,以及与解释器强烈交互的函数。
import sys
sys.path # 模块的查找路径
sys.argv # 传递给Python脚本的命令行参数列表
sys.exit(code) # 让程序以指定的退出码结束
sys.stdin # 标准输入。可以通过它来获取用户的输入
sys.stdout # 标准输出。可以通过修改它来百变默认输出
sys.stderr # 错误输出。可以通过修改它来改变错误删除Copy
math模块
math模块保存了数学计算相关的方法,可以很方便的实现数学运算。
import math
print(math.fabs(-100)) # 取绝对值
print(math.ceil(34.01)) #向上取整
print(math.factorial(5)) # 计算阶乘
print(math.floor(34.98)) # 向下取整
print(math.pi) # π的值,约等于 3.141592653589793
print(math.pow(2, 10)) # 2的10次方
print(math.sin(math.pi / 6)) # 正弦值
print(math.cos(math.pi / 3)) # 余弦值
print(math.tan(math.pi / 2)) # 正切值Copy
random模块
random 模块主要用于生成随机数或者从一个列表里随机获取数据。
print(random.random()) # 生成 [0,1)的随机浮点数
print(random.uniform(20, 30)) # 生成[20,30]的随机浮点数
print(random.randint(10, 30)) # 生成[10,30]的随机整数
print(random.randrange(20, 30)) # 生成[20,30)的随机整数
print(random.choice('abcdefg')) # 从列表里随机取出一个元素
print(random.sample('abcdefghij', 3)) # 从列表里随机取出指定个数的元素Copy
练习:
定义一个函数,用来生成由数字和字母组成的随机验证码。该函数需要一个参数,参数用来指定验证码的长度。
datetime模块
datetime模块主要用来显示日期时间,这里主要涉及 date类,用来显示日期;time类,用来显示时间;dateteime类,用来显示日期时间;timedelta类用来计算时间。
import datetime
print(datetime.date(2020, 1, 1)) # 创建一个日期
print(datetime.time(18, 23, 45)) # 创建一个时间
print(datetime.datetime.now()) # 获取当前的日期时间
print(datetime.datetime.now() + datetime.timedelta(3)) # 计算三天以后的日期时间Copy
time模块
除了使用datetime模块里的time类以外,Python还单独提供了另一个time模块,用来操作时间。time模块不仅可以用来显示时间,还可以控制程序,让程序暂停(使用sleep函数)
print(time.time()) # 获取从1970-01-01 00:00:00 UTC 到现在时间的秒数
print(time.strftime("%Y-%m-%d %H:%M:%S")) # 按照指定格式输出时间
print(time.asctime()) #Mon Apr 15 20:03:23 2019
print(time.ctime()) # Mon Apr 15 20:03:23 2019
print('hello')
print(time.sleep(10)) # 让线程暂停10秒钟
print('world')Copy
calendar模块
calendar模块用来显示一个日历,使用的不多,了解即可。
calendar.setfirstweekday(calendar.SUNDAY) # 设置每周起始日期码。周一到周日分别对应 0 ~ 6
calendar.firstweekday()# 返回当前每周起始日期的设置。默认情况下,首次载入calendar模块时返回0,即星期一。
c = calendar.calendar(2019) # 生成2019年的日历,并且以周日为其实日期码
print(c) #打印2019年日历
print(calendar.isleap(2000)) # True.闰年返回True,否则返回False
count = calendar.leapdays(1996,2010) # 获取1996年到2010年一共有多少个闰年
print(calendar.month(2019, 3)) # 打印2019年3月的日历Copy
hashlib模块
hashlib是一个提供字符加密功能的模块,包含MD5和SHA的加密算法,具体支持md5,sha1, sha224, sha256, sha384, sha512等算法。 该模块在用户登录认证方面应用广泛,对文本加密也很常见。
import hashlib
# 待加密信息
str = '这是一个测试'
# 创建md5对象
hl = hashlib.md5('hello'.encode(encoding='utf8'))
print('MD5加密后为 :' + hl.hexdigest())
h1 = hashlib.sha1('123456'.encode())
print(h1.hexdigest())
h2 = hashlib.sha224('123456'.encode())
print(h2.hexdigest())
h3 = hashlib.sha256('123456'.encode())
print(h3.hexdigest())
h4 = hashlib.sha384('123456'.encode())
print(h4.hexdigest())Copy
hmac模块
HMAC算法也是一种一种单项加密算法,并且它是基于上面各种哈希算法/散列算法的,只是它可以在运算过程中使用一个密钥来增增强安全性。hmac模块实现了HAMC算法,提供了相应的函数和方法,且与hashlib提供的api基本一致。
h = hmac.new('h'.encode(),'你好'.encode())
result = h.hexdigest()
print(result) # 获取加密后的结果Copy
copy模块
copy模块里有copy和deepcopy两个函数,分别用来对数据进行深复制和浅复制。
import copy
nums = [1, 5, 3, 8, [100, 200, 300, 400], 6, 7]
nums1 = copy.copy(nums) # 对nums列表进行浅复制
nums2 = copy.deepcopy(nums) # 对nums列表进行深复制Copy
uuid模块
UUID是128位的全局唯一标识符,通常由32字节的字母串表示,它可以保证时间和空间的唯一性,也称为GUID。通过MAC地址、时间戳、命名空间、随机数、伪随机数来保证生产的ID的唯一性。随机生成字符串,可以当成token使用,当成用户账号使用,当成订单号使用。
| 方法 |
作用 |
| uuid.uuid1() |
基于MAC地址,时间戳,随机数来生成唯一的uuid,可以保证全球范围内的唯一性。 |
| uuid.uuid2() |
算法与uuid1相同,不同的是把时间戳的前4位置换为POSIX的UID。不过需要注意的是python中没有基于DCE的算法,所以python的uuid模块中没有uuid2这个方法。 |
| uuid.uuid3(namespace,name) |
通过计算一个命名空间和名字的md5散列值来给出一个uuid,所以可以保证命名空间中的不同名字具有不同的uuid,但是相同的名字就是相同的uuid了。namespace并不是一个自己手动指定的字符串或其他量,而是在uuid模块中本身给出的一些值。比如uuid.NAMESPACE_DNS,uuid.NAMESPACE_OID,uuid.NAMESPACE_OID这些值。这些值本身也是UUID对象,根据一定的规则计算得出。 |
| uuid.uuid4() |
通过伪随机数得到uuid,是有一定概率重复的 |
| uuid.uuid5(namespace,name) |
和uuid3基本相同,只不过采用的散列算法是sha1 |
一般而言,在对uuid的需求不是很复杂的时候,uuid1或者uuid4方法就已经够用了,使用方法如下:
import uuid
print(uuid.uuid1()) # 根据时间戳和机器码生成uuid,可以保证全球唯一
print(uuid.uuid4()) # 随机生成uuid,可能会有重复
# 使用命名空间和字符串生成uuid.# 注意一下两点:# 1. 命名空间不是随意输入的字符串,它也是一个uuid类型的数据# 2. 相同的命名空间和想到的字符串,生成的uuid是一样的
print(uuid.uuid3(uuid.NAMESPACE_DNS, 'hello'))
print(uuid.uuid5(uuid.NAMESPACE_OID, 'hello'))
pip命令的使用
在安装Python时,同时还会安装pip软件,它是Python的包管理工具,可以用来查找、下载、安装和卸载Python的第三方资源包。
配置pip
可以直接在终端中输入pip命令,如果出错,可能会有两个原因:
- pip安装成功以后没有正确配置
- 安装Python时,没有自动安装pip(很少见)
配置pip
和运行Python命令一样,如果想要运行 pip 命令同样也需要将pip命令的安装目录添加到环境变量中。


安装pip
如果在Python安装对应的目录中,没有发现pip.exe文件,可能是因为在安装Python时未自动安装pip,建议将Python卸载,然后在重新安装Python时选择Install Now使用默认方式安装Python.

管理第三方包
对第三方包的管理主要包含查找、安装和卸载三个部分的操作。
安装
使用 pip install <包名>命令可以安装指定的第三方资源包。
pip install ipython # 安装ipython包Copy
使用 install 命令下载第三方资源包时,默认是从 pythonhosted下载,由于各种原因,在国内下载速度相对来说比较慢,在某些时候甚至会出现连接超时的情况,我们可以使用国内镜像来提高下载速度。
临时修改
如果只是想临时修改某个第三方资源包的下载地址,在第三方包名后面添加 -i 参数,再指定下载路径即可,格式为pip install <包名> -i <国内镜像路径>
pip install ipython -i https://pypi.douban.com/simpleCopy
永久修改
除了临时修改pip的下载源以外,我们还能永久改变pip的默认下载路径。
在当前用户目录下创建一个pip的文件夹,然后再在文件夹里创建pip.ini文件并输入一下内容:
[global]
index-url=https://pypi.douban.com/simple
[install]
trusted-host=pypi.douban.comCopy
常见国内镜像
- 阿里云 Simple Index
- 中国科技大学 Simple Index
- 豆瓣(douban) Simple Index
- 清华大学 Simple Index
- 中国科学技术大学 Simple Index
卸载
使用 pip install <包名>命令可以用来卸载指定的第三方资源包。
pip uninstall ipython # 卸载ipython包Copy
查找
使用pip list 或者 pip freeze命令可以来管理第三方资源包。这两个命令的功能一致,都是用来显示当前环境里已经安装的包,区别在于pip list会列出所有的包,包括一些无法uninstall的包;而pip freeze只会列出我们安装的第三方包。
总结
开发中,我们通常会使用很多第三方的资源包,我们在将程序部署到服务器的时候,不仅要把代码上传到服务器,同时还需要把代码里用到的第三方资源包告诉服务器。那么这里就有两个问题:
当我们电脑上运行很多个项目,每个项目使用的第三方资源包又不一致时,怎样将代码和它使用到的第三方资源包放在一起呢?答:虚拟环境
怎样将自己代码使用到的第三方资源包告诉给服务器?
-
- 使用 pip freeze > requires.txt 命令,将代码里使用到的第三方资源包以及版本号写入到 requirements.txt 文件,在部署时,同时将 requirements.txt 文件上传到服务器。
- 服务器在拿到代码以后,首先运行 pip install -r requirements.txt 命令,将文件里列出的所有第三方框架先安装到服务器,然后才能运行代码。
使用pycharm管理第三方包
除了使用pip 命令管理第三方资源包以外,我们还能使用pycharm来对第三方包进行管理

自定义模块
除了使用系统提供的内置模块以外,我们还能自己写一个模块供自己的程序使用。一个py文件就是一个模块,所以,自定义模块很简单,基本上相当于创建一个py文件。但是,需要注意的是,如果一个py文件要作为一个模块被别的代码使用,这个py文件的名字一定要遵守标识符的命名规则。
模块的查找路径
创建一个模块非常简单,安装标识符的命名规则创建一个py文件就是一个模块。但是问题是,我们需要把创建好的这个py文件放在哪个位置,在代码中使用 import语句才能找到这个模块呢?
Python内置sys模块的path属性,列出了程序运行时查找模块的目录,只需要把我们创建好的模块放到这些任意的一个目录里即可。
import sys
print(sys.path)
[
'C:\\Users\\chris\\Desktop\\Test',
'C:\\Users\\chris\\AppData\\Local\\Programs\\Python\\Python37\\python37.zip',
'C:\\Users\\chris\\AppData\\Local\\Programs\\Python\\Python37\\DLLs',
'C:\\Users\\chris\\AppData\\Local\\Programs\\Python\\Python37\\lib',
'C:\\Users\\chris\\AppData\\Local\\Programs\\Python\\Python37',
'C:\\Users\\chris\\AppData\\Roaming\\Python\\Python37\\site-packages',
'C:\\Users\\chris\\AppData\\Local\\Programs\\Python\\Python37\\lib\\site-packages'
]Copy
__all__的使用
使用from <模块名> import *导入一个模块里所有的内容时,本质上是去查找这个模块的__all__属性,将__all__属性里声明的所有内容导入。如果这个模块里没有设置__all__属性,此时才会导入这个模块里的所有内容。
模块里的私有成员
模块里以一个下划线_开始的变量和函数,是模块里的私有成员,当模块被导入时,以_开头的变量默认不会被导入。但是它不具有强制性,如果一个代码强行使用以_开头的变量,有时也可以。但是强烈不建议这样使用,因为有可能会出问题。
总结
test1.py:模块里没有__all__属性
a = 'hello'def fn():
print('我是test1模块里的fn函数')Copy
test2.py:模块里有__all__属性
x = '你好'
y = 'good'def foo():
print('我是test2模块里的foo函数')
__all__ = ('x','foo')Copy
test3.py:模块里有以_开头的属性
m = '早上好'
_n = '下午好'def _bar():
print('我是test3里的bar函数')Copy
demo.py
from test1 import *from test2 import *from test3 import *
print(a)
fn()
print(x)# print(y) 会报错,test2的__all__里没有变量 y
foo()
print(m)# print(_n) 会报错,导入test3时, _n 不会被导入
import test3
print(test3._n) # 也可以强行使用,但是强烈不建议Copy
__name__的使用
在实际开中,当一个开发人员编写完一个模块后,为了让模块能够在项目中达到想要的效果,这个开发人员会自行在py文件中添加一些测试信息,例如:
test1.py
def add(a,b):
return a+b
# 这段代码应该只有直接运行这个文件进行测试时才要执行# 如果别的代码导入本模块,这段代码不应该被执行
ret = add(12,22)
print('测试的结果是',ret)Copy
demo.py
import test1.py # 只要导入了tets1.py,就会立刻执行 test1.py 代码,打印测试内容Copy
为了解决这个问题,python在执行一个文件时有个变量__name__.在Python中,当直接运行一个py文件时,这个py文件里的__name__值是__main__,据此可以判断一个一个py文件是被直接执行还是以模块的形式被导入。
def add(a,b):
return a+b
if __name__ == '__main__': # 只有直接执行这个py文件时,__name__的值才是 __main__
# 以下代码只有直接运行这个文件才会执行,如果是文件被别的代码导入,下面的代码不会执行
ret = add(12,22)
print('测试的结果是',ret)Copy
注意事项
在自定义模块时,需要注意一点,自定义模块名不要和系统的模块名重名,否则会出现问题!
包的使用
一个模块就是一个 py 文件,在 Python 里为了对模块分类管理,就需要划分不同的文件夹。多个有联系的模块可以将其放到同一个文件夹下,为了称呼方便,一般把 Python 里的一个代码文件夹称为一个包。
1. 导入包的方式
现有以下包newmsg,包里由两个模块,分别是sendmsg.py、recvmsg.py文件。在包的上级文件夹里,有一个test.py文件,目标是在test.py文件里引入newmsg的两个模块。
目录结构如下图所示:

sendmsg.py文件里的内容如下:
def send_msg():
print('------sendmsg方法被调用了-------')Copy
recvmsg.py文件里的内容如下:
def recv_msg():
print('-----recvmsg方法被调用了--------')Copy
可以使用以下几种方式来导入模块,使用模块里的方法。
1>. 直接使用包名.模块模块名导入指定的模块。

2>. 使用from xxx import xxx 方式导入指定模块。

3>. 使用__init__.py文件,导入包里的指定模块。
可以在newmsg里创建__init__.py文件,在该文件里导入指定的内容。

在__init__.py文件里编写代码:
from . import sendmsg # 导入指定的模块 . 代表的是当前文件夹Copy
test.py文件里的代码
import newmsg # 导入时,只需要输入包名即可。在包名的__init__.py文件里,导入了指定模块
newmsg.sendmsg.sendm_msg() # 可以直接调用对应的方法# newmsg.recvmsg.recv_msg() 不可以使用 recvmsg 模块,因为 __init__.py文件里没有导入这个模块Copy
4.> 使用__init__.py文件,结合__all__属性,导入包里的所有模块。
在newmsg包里的__init__.py文件里编写代码:
__all__ = ["sendmsg","recvmsg"] # 指定导入的内容Copy
test.py文件代码:
from newmsg import * # 将newmsg里的__inint__.py文件里,__all__属性对应的所有模块都导入
sendmsg.sendmsg()
recvmsg.recvmsg()Copy
总结
- 包将有联系的模块组织在一起,即放到同一个文件夹下,并且在这个文件夹创建一个名字为__init__.py 文件,那么这个文件夹就称之为包
- 有效避免模块名称冲突问题,让应用组织结构更加清晰
2. __init__.py文件有什么用
__init__.py 控制着包的导入行为。__init__.py为空仅仅是把这个包导入,不会导入包中的模块。可以在__init__.py文件中编写内容。
newmsg/__init__.py文件:
print('hello world')Copy
别的模块在引入这个包的时候,会自动调用这段代码。

3. __all__
在__init__.py文件中,定义一个__all__变量,它控制着 from 包名 import *时导入的模块。
newmsg/__init__.py文件:
__all__ = ['sendmsg','recvmsg']

33 网络编程
网络通信的概念
简单来说,网络是用物理链路将各个孤立的工作站或主机相连在一起,组成数据链路,从而达到资源共享和通信的目的。
使用网络的目的,就是为了联通多方然后进行通信,即把数据从一方传递给另外一方。
前面的学习编写的程序都是单机的,即不能和其他电脑上的程序进行通信。为了让在不同的电脑上运行的软件,之间能够互相传递数据,就需要借助网络的功能。
- 使用网络能够把多方链接在一起,然后可以进行数据传递
- 所谓的网络编程就是,让在不同的电脑上的软件能够进行数据传递,即进程之间的通信

ip地址
生活中的地址指的就是,找到某人或某机关或与其通信的指定地点。在网络编程中,如果一台主机想和另一台主机进行沟通和共享数据,首先要做的第一件事情就是要找到对方。在互联网通信中,我们使用IP地址来查询到各个主机。

ip地址:用来在网络中标记一台电脑,比如192.168.1.1;在本地局域网上是唯一的。
ip地址的分类
每一个IP地址包括两部分:网络地址和主机地址。IP地址通常由点分十进制(例如:192.168.1.1)的方式来表示,IP地址要和子网掩码(用来区分网络位和主机位)配合使用。

A类地址
一个A类IP地址由1字节的网络地址和3字节主机地址组成,网络地址的最高位必须是“0”,
地址范围:1.0.0.1-126.255.255.254
子网掩码:255.0.0.0
二进制表示为:00000001 00000000 00000000 00000001 - 01111110 11111111 11111111 11111110
可用的A类网络有126个,每个网络能容纳1677214个主机
B类地址
一个B类IP地址由2个字节的网络地址和2个字节的主机地址组成,网络地址的最高位必须是“10”,
地址范围:128.1.0.1-191.255.255.254
子网掩码:255.255.0.0
二进制表示为:10000000 00000001 00000000 00000001 - 10111111 11111111 11111111 11111110
可用的B类网络有16384个,每个网络支持的最大主机数为256的2次方-2=65534台。
C类地址
一个C类IP地址由3字节的网络地址和1字节的主机地址组成,网络地址的最高位必须是“110”
范围:192.0.1.1-223.255.255.254
子网掩码:255.255.255.0
二进制表示为: 11000000 00000000 00000001 00000001 - 11011111 11111111 11111110 11111110
C类网络可达2097152个,每个网络支持的最大主机数为256-2=254台
D类地址
D类IP地址第一个字节以“1110”开始,它是一个专门保留的地址,并不指向特定的网络,目前这一类地址被用在多点广播(Multicast)中。
E类地址
以“1111”开始,为将来使用保留,仅作实验和开发用。
私有地址
在这么多网络IP中,国际规定有一部分IP地址是用于我们的局域网使用,也就是属于私网IP,不在公网中使用的,它们的范围是:
10.0.0.0~10.255.255.255172.16.0.0~172.31.255.255192.168.0.0~192.168.255.255Copy
注意事项:
- 每一个字节都为0的地址(“0.0.0.0”)对应于当前主机。
- IP地址中的每一个字节都为1的IP地址(“255.255.255.255”)是当前子网的广播地址。
- IP地址中凡是以“1111”开头的E类IP地址都保留用于将来和实验使用。
- IP地址中不能以十进制“127”作为开头,该类地址中数字127.0.0.1到127.255.255.255用于回路测试,如:127.0.0.1可以代表本机IP地址,用 http://127.0.0.1 就可以测试本机中配置的Web服务器
- 网络ID的第一个8位组也不能全置为“0”,全“0”表示本地网络。
网络通信方式
直接通信

说明
- 如果两台电脑之间通过网线连接是可以直接通信的,但是需要提前设置好ip地址以及网络掩码
- 并且ip地址需要控制在同一网段内,例如 一台为192.168.1.1另一台为192.168.1.2则可以进行通信
使用集线器通信

说明
- 当有多态电脑需要组成一个网时,那么可以通过集线器(Hub)将其链接在一起
- 一般情况下集线器的接口较少
- 集线器有个缺点,它以广播的方式进行发送任何数据,即如果集线器接收到来自A电脑的数据本来是想转发给B电脑,如果此时它还连接着另外两台电脑C、D,那么它会把这个数据给每个电脑都发送一份,因此会导致网络拥堵
使用交换机通信

说明
- 克服了集线器以广播发送数据的缺点,当需要广播的时候发送广播,当需要单播的时候又能够以单播的方式进行发送
- 它已经替代了之前的集线器
- 企业中就是用交换机来完成多态电脑设备的链接成网络的
使用路由器连接多个网络

复杂的通信过程

说明
- 在浏览器中输入一个网址时,需要将它先解析出ip地址来
- 当得到ip地址之后,浏览器以tcp的方式3次握手链接服务器
- 以tcp的方式发送http协议的请求数据 给 服务器
- 服务器tcp的方式回应http协议的应答数据 给浏览器
总结
- MAC地址:在设备与设备之间数据通信时用来标记收发双方(网卡的序列号)
- IP地址:在逻辑上标记一台电脑,用来指引数据包的收发方向(相当于电脑的序列号)
- 网络掩码:用来区分ip地址的网络号和主机号
- 默认网关:当需要发送的数据包的目的ip不在本网段内时,就会发送给默认的一台电脑,成为网关
- 集线器:已过时,用来连接多态电脑,缺点:每次收发数据都进行广播,网络会变的拥堵
- 交换机:集线器的升级版,有学习功能知道需要发送给哪台设备,根据需要进行单播、广播
- 路由器:连接多个不同的网段,让他们之间可以进行收发数据,每次收到数据后,ip不变,但是MAC地址会变化
- DNS:用来解析出IP(类似电话簿)
- http服务器:提供浏览器能够访问到的数据
端口
端口就像一个房子的门,是出入这间房子的必经之路。如果一个程序需要收发网络数据,那么就需要有这样的端口
在linux系统中,端口可以有65536(2的16次方)个之多!
既然有这么多,操作系统为了统一管理,所以进行了编号,这就是端口号
端口号
端口是通过端口号来标记的,端口号只有整数,范围是从0到65535.端口号不是随意使用的,而是按照一定的规定进行分配。端口的分类标准有好几种,我们这里不做详细讲解,只介绍一下知名端口和动态端口。
知名端口号
知名端口是众所周知的端口号,范围从0到1023,以理解为,一些常用的功能使用的号码是估计的,好比 电话号码110、10086、10010一样。一般情况下,如果一个程序需要使用知名端口的需要有root权限。
动态端口号
动态端口的范围是从1024到65535
之所以称为动态端口,是因为它一般不固定分配某种服务,而是动态分配。
动态分配是指当一个系统程序或应用程序程序需要网络通信时,它向主机申请一个端口,主机从可用的端口号中分配一个供它使用。
当这个程序关闭时,同时也就释放了所占用的端口号。
端口号作用
我们知道,一台拥有IP地址的主机可以提供许多服务,比如HTTP(万维网服务)、FTP(文件传输)、SMTP(电子邮件)等,这些服务完全可以通过1个IP地址来实现。那么,主机是怎样区分不同的网络服务呢?显然不能只靠IP地址,因为IP地址与网络服务的关系是一对多的关系。实际上是通过“IP地址+端口号”来区分不同的服务的。 需要注意的是,端口并不是一一对应的。比如你的电脑作为客户机访问一台WWW服务器时,WWW服务器使用“80”端口与你的电脑通信,但你的电脑则可能使用“3457”这样的端口。
socket简介
1. 不同电脑上的进程之间如何通信
首要解决的问题是如何唯一标识一个进程,否则通信无从谈起! 在1台电脑上可以通过进程号(PID)来唯一标识一个进程,但是在网络中这是行不通的。 其实TCP/IP协议族已经帮我们解决了这个问题,网络层的“ip地址”可以唯一标识网络中的主机,而传输层的“协议+端口”可以唯一标识主机中的应用进程(进程)。 这样利用ip地址,协议,端口就可以标识网络的进程了,网络中的进程通信就可以利用这个标志与其它进程进行交互。
注意:
所谓进程指的是:运行的程序以及运行时用到的资源这个整体称之为进程(在讲解多任务编程时进行详细讲解)
所谓进程间通信指的是:运行的程序之间的数据共享
2. 什么是socket
socket(简称 套接字) 是进程间通信的一种方式,它与其他进程间通信的一个主要不同是:
它能实现不同主机间的进程间通信,我们网络上各种各样的服务大多都是基于 Socket 来完成通信的
例如我们每天浏览网页、QQ 聊天、收发 email 等等。
创建socket
在 Python 中 使用socket 模块的函数 socket 就可以完成:
import socket
socket.socket(AddressFamily, Type)Copy
说明:
函数 socket.socket 创建一个 socket,该函数带有两个参数:
- Address Family:可以选择 AF_INET(用于 Internet 进程间通信) 或者 AF_UNIX(用于同一台机器进程间通信),实际工作中常用AF_INET
- Type:套接字类型,可以是 SOCK_STREAM(流式套接字,主要用于 TCP 协议)或者 SOCK_DGRAM(数据报套接字,主要用于 UDP 协议)
创建一个tcp socket(tcp套接字)
import socket
# 创建tcp的套接字
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# ...这里是使用套接字的功能(省略)...
# 不用的时候,关闭套接字
s.close()Copy
创建一个udp socket(udp套接字)
import socket
# 创建udp的套接字
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)# ...这里是使用套接字的功能(省略)...# 不用的时候,关闭套接字
s.close()Copy
说明
套接字使用流程 与 文件的使用流程很类似
- 创建套接字
- 使用套接字收/发数据
- 关闭套接字
UDP协议
UDP 是User Datagram Protocol的简称, 中文名是用户数据报协议。在通信开始之前,不需要建立相关的链接,只需要发送数据即可,类似于生活中,"写信"。
UDP通信模型

udp网络程序-发送数据
创建一个基于udp的网络程序流程很简单,具体步骤如下:
- 创建客户端套接字
- 发送/接收数据
- 关闭套接字
import socket# 1. 创建一个UDP的socket连接
udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)# 2. 获取用户输入的内容
data = input('请输入内容')# 3. 准备接收方的地址和端口号
addr = ('127.0.0.1', 8080)# 4. 将用户的输入内容进行编码,并发送到指定地址和端口
udp_socket.sendto(data.encode('gbk'), addr)# 5. 接收传递过来的消息,并指定接受的字节大小
recv_data = udp_socket.recvfrom(1024)# 6. 接收到的对象是一个元组,元组里有两个元素
print(recv_data)# 6.1 元组里的第一个数据显示接收到内容
print(recv_data[0].decode('gbk'))# 6.2 元组里的第二个数据显示发送方的地址和端口号
print(recv_data[1])# 7. 关闭socket连接
udp_socket.close()Copy

运行网络调试助手,查看运行效果:

udp网络程序-端口问题
- 会变的端口号
重新运行多次脚本,然后在“网络调试助手”中,看到的现象如下:

说明:
- 每重新运行一次网络程序,上图中红圈中的数字,不一样的原因在于,这个数字标识这个网络程序,当重新运行时,如果没有确定到底用哪个,系统默认会随机分配
- 记住一点:这个网络程序在运行的过程中,这个就唯一标识这个程序,所以如果其他电脑上的网络程序如果想要向此程序发送数据,那么就需要向这个数字(即端口)标识的程序发送即可
2. UDP绑定信息
<1>. 绑定信息
一般情况下,在一台电脑上运行的网络程序有很多,为了不与其他的网络程序占用同一个端口号,往往在编程中,udp的端口号一般不绑定 但是如果需要做成一个服务器端的程序的话,是需要绑定的,想想看这又是为什么呢? 如果报警电话每天都在变,想必世界就会乱了,所以一般服务性的程序,往往需要一个固定的端口号,这就是所谓的端口绑定。
<2>. 绑定示例
from socket import *
# 1. 创建套接字
udp_socket = socket(AF_INET, SOCK_DGRAM)
# 2. 绑定本地的相关信息,如果一个网络程序不绑定,则系统会随机分配
local_addr = ('', 7788) # ip地址和端口号,ip一般不用写,表示本机的任何一个ip
udp_socket.bind(local_addr)
# 3. 等待接收对方发送的数据
recv_data = udp_socket.recvfrom(1024) # 1024表示本次接收的最大字节数
# 4. 显示接收到的数据
print(recv_data[0].decode('gbk'))
# 5. 关闭套接字
udp_socket.close()Copy
运行结果:

<3>.总结
- 一个udp网络程序,可以不绑定,此时操作系统会随机进行分配一个端口,如果重新运行此程序端口可能会发生变化
- 一个udp网络程序,也可以绑定信息(ip地址,端口号),如果绑定成功,那么操作系统用这个端口号来进行区别收到的网络数据是否是此进程的
TCP协议
TCP协议,传输控制协议(英语:Transmission Control Protocol,缩写为 TCP)是一种面向连接的、可靠的、基于字节流的传输层通信协议,由IETF的RFC 793定义。
TCP通信需要经过创建连接、数据传送、终止连接三个步骤。
TCP通信模型中,在通信开始之前,一定要先建立相关的链接,才能发送数据,类似于生活中,"打电话"。
TCP特点
1. 面向连接
通信双方必须先建立连接才能进行数据的传输,双方都必须为该连接分配必要的系统内核资源,以管理连接的状态和连接上的传输。
双方间的数据传输都可以通过这一个连接进行。
完成数据交换后,双方必须断开此连接,以释放系统资源。
这种连接是一对一的,因此TCP不适用于广播的应用程序,基于广播的应用程序请使用UDP协议。
2. 可靠传输
1)TCP采用发送应答机制
TCP发送的每个报文段都必须得到接收方的应答才认为这个TCP报文段传输成功
2)超时重传
发送端发出一个报文段之后就启动定时器,如果在定时时间内没有收到应答就重新发送这个报文段。
TCP为了保证不发生丢包,就给每个包一个序号,同时序号也保证了传送到接收端实体的包的按序接收。然后接收端实体对已成功收到的包发回一个相应的确认(ACK);如果发送端实体在合理的往返时延(RTT)内未收到确认,那么对应的数据包就被假设为已丢失将会被进行重传。
3)错误校验
TCP用一个校验和函数来检验数据是否有错误;在发送和接收时都要计算校验和。
4) 流量控制和阻塞管理
流量控制用来避免主机发送得过快而使接收方来不及完全收下。
3. TCP与UDP的区别
- 面向连接(确认有创建三方交握,连接已创建才作传输。)
- 有序数据传输
- 重发丢失的数据包
- 舍弃重复的数据包
- 无差错的数据传输
- 阻塞/流量控制
TCP通信模型
TCP通信模型中,在通信开始之前,一定要先建立相关的链接,才能发送数据

服务器和客户端
服务器,也称伺服器,是提供计算服务的设备。由于服务器需要响应服务请求,并进行处理,因此一般来说服务器应具备承担服务并且保障服务的能力。 客户端(Client)也被称为用户端,是指与服务器相对应,为客户提供本地服务的程序。 客户端服务器架构又被称为主从式架构,简称C/S结构,是一种网络架构,它把客户端与服务器分开来,一个客户端软件的实例都可以向一个服务器或应用程序服务器发出请求。
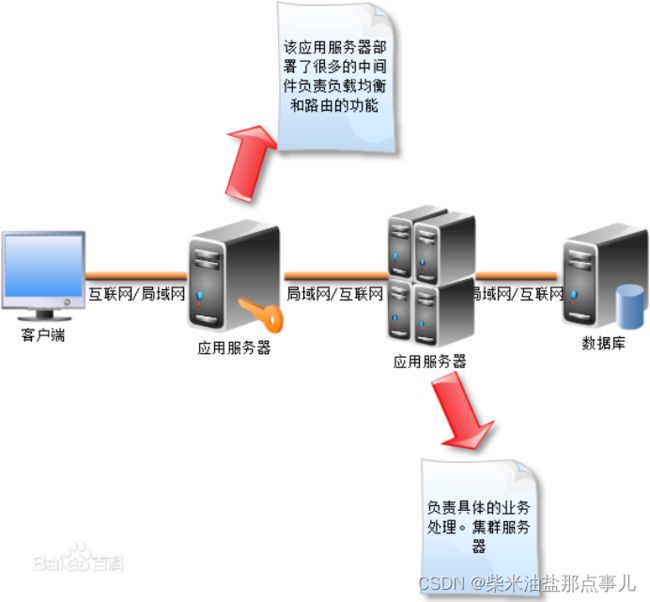
TCP客户端
相比较于TCP服务端,tcp的客户端要简单很多,如果说服务器端是需要自己买手机、查手机卡、设置铃声、等待别人打电话流程的话,那么客户端就只需要找一个电话亭,拿起电话拨打即可,流程要少很多。
示例代码:
from socket import *
# 创建socket
tcp_client_socket = socket(AF_INET, SOCK_STREAM)
# 目的信息
server_ip = input("请输入服务器ip:")
server_port = int(input("请输入服务器port:"))
# 链接服务器
tcp_client_socket.connect((server_ip, server_port))
# 提示用户输入数据
send_data = input("请输入要发送的数据:")
tcp_client_socket.send(send_data.encode("gbk"))
# 接收对方发送过来的数据,最大接收1024个字节
recvData = tcp_client_socket.recv(1024)
print('接收到的数据为:', recvData.decode('gbk'))
# 关闭套接字
tcp_client_socket.close()Copy
运行流程
输入服务器ip:10.10.0.47
请输入服务器port:8080
请输入要发送的数据:你好啊
接收到的数据为: 我很好,你呢

TCP服务端
在程序中,如果想要完成一个tcp服务器的功能,需要的流程如下:
- socket创建一个套接字
- bind绑定ip和port
- listen使套接字变为可以被动链接
- accept等待客户端的链接
- recv/send接收发送数据
示例代码:
from socket import *
# 创建socket
tcp_server_socket = socket(AF_INET, SOCK_STREAM)
# 本地信息
address = ('', 7788)
# 绑定
tcp_server_socket.bind(address)
# 使用socket创建的套接字默认的属性是主动的,使用listen将其变为被动的,这样就可以接收别人的链接了
tcp_server_socket.listen(128)
# 如果有新的客户端来链接服务器,那么就产生一个新的套接字专门为这个客户端服务# client_socket用来为这个客户端服务# tcp_server_socket就可以省下来专门等待其他新客户端的链接
client_socket, clientAddr = tcp_server_socket.accept()
# 接收对方发送过来的数据
recv_data = client_socket.recv(1024) # 接收1024个字节
print('接收到的数据为:', recv_data.decode('gbk'))
# 发送一些数据到客户端
client_socket.send("thank you !".encode('gbk'))
# 关闭为这个客户端服务的套接字,只要关闭了,就意味着为不能再为这个客户端服务了,如果还需要服务,只能再次重新连接
client_socket.close()Copy
TCP注意事项
- tcp服务器一般情况下都需要绑定,否则客户端找不到这个服务器
- tcp客户端一般不绑定,因为是主动链接服务器,所以只要确定好服务器的ip、port等信息就好,本地客户端可以随机
- tcp服务器中通过listen可以将socket创建出来的主动套接字变为被动的,这是做tcp服务器时必须要做的
- 当客户端需要链接服务器时,就需要使用connect进行链接,udp是不需要链接的而是直接发送,但是tcp必须先链接,只有链接成功才能通信
- 当一个tcp客户端连接服务器时,服务器端会有1个新的套接字,这个套接字用来标记这个客户端,单独为这个客户端服务
- listen后的套接字是被动套接字,用来接收新的客户端的链接请求的,而accept返回的新套接字是标记这个新客户端的
- 关闭listen后的套接字意味着被动套接字关闭了,会导致新的客户端不能够链接服务器,但是之前已经链接成功的客户端正常通信。
- 关闭accept返回的套接字意味着这个客户端已经服务完毕
- 当客户端的套接字调用close后,服务器端会recv解堵塞,并且返回的长度为0,因此服务器可以通过返回数据的长度来区别客户端是否已经下线
文件下载案例
TCP服务器端:
from socket import *
def get_file_content(file_name):
"""获取文件的内容"""
try:
with open(file_name, "rb") as f:
content = f.read()
return content
except:
print("没有下载的文件:%s" % file_name)
def main():
# 创建socket
tcp_server_socket = socket(AF_INET, SOCK_STREAM)
# 本地信息
address = ('', 7890)
# 绑定本地信息
tcp_server_socket.bind(address)
# 将主动套接字变为被动套接字
tcp_server_socket.listen(128)
while True:
# 等待客户端的链接,即为这个客户端发送文件
client_socket, clientAddr = tcp_server_socket.accept()
# 接收对方发送过来的数据
recv_data = client_socket.recv(1024) # 接收1024个字节
file_name = recv_data.decode("utf-8")
print("对方请求下载的文件名为:%s" % file_name)
file_content = get_file_content(file_name)
# 发送文件的数据给客户端
# 因为获取打开文件时是以rb方式打开,所以file_content中的数据已经是二进制的格式,因此不需要encode编码
if file_content:
client_socket.send(file_content)
# 关闭这个套接字
client_socket.close()
# 关闭监听套接字
tcp_server_socket.close()if __name__ == '__main__':
main()Copy
TCP客户端:
from socket import *def main():
# 创建socket
tcp_client_socket = socket(AF_INET, SOCK_STREAM)
# 目的信息
server_ip = input("请输入服务器ip:")
server_port = int(input("请输入服务器port:"))
# 链接服务器
tcp_client_socket.connect((server_ip, server_port))
# 输入需要下载的文件名
file_name = input("请输入要下载的文件名:")
# 发送文件下载请求
tcp_client_socket.send(file_name.encode("utf-8"))
# 接收对方发送过来的数据,最大接收1024个字节(1K)
recv_data = tcp_client_socket.recv(1024)
# print('接收到的数据为:', recv_data.decode('utf-8'))
# 如果接收到数据再创建文件,否则不创建
if recv_data:
with open("[接收]"+file_name, "wb") as f:
f.write(recv_data)
# 关闭套接字
tcp_client_socket.close()
if __name__ == "__main__":
main()34多任务
线程访问全局变量
import threading
g_num = 0def test(n):
global g_num
for x in range(n):
g_num += x
g_num -= x
print(g_num)
if __name__ == '__main__':
t1 = threading.Thread(target=test, args=(10,))
t2 = threading.Thread(target=test, args=(10,))
t1.start()
t2.start()Copy
在一个进程内的所有线程共享全局变量,很方便在多个线程间共享数据。缺点就是,线程是对全局变量随意遂改可能造成多线程之间对全局变量的混乱(即线程非安全)。
线程的安全问题
import threadingimport time
ticket = 20
def sell_ticket():
global ticket
while True:
if ticket > 0:
time.sleep(0.5)
ticket -= 1
print('{}卖了一张票,还剩{}'.format(threading.current_thread().name, ticket))
else:
print('{}票卖完了'.format(threading.current_thread().name))
break
for i in range(5):
t = threading.Thread(target=sell_ticket, name='thread-{}'.format(i + 1))
t.start()
同步
当多个线程几乎同时修改某一个共享数据的时候,需要进行同步控制。同步就是协同步调,按预定的先后次序进行运行。线程同步能够保证多个线程安全访问竞争资源,最简单的同步机制是引入互斥锁。
互斥锁
互斥锁为资源引入一个状态:锁定/非锁定
某个线程要更改共享数据时,先将其锁定,此时资源的状态为“锁定”,其他线程不能更改;直到该线程释放资源,将资源的状态变成“非锁定”,其他的线程才能再次锁定该资源。互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性。
threading模块中定义了Lock类,可以方便的处理锁定:
# 创建锁
mutex = threading.Lock()# 锁定
mutex.acquire()# 释放
mutex.release()Copy
注意:
- 如果这个锁之前是没有上锁的,那么acquire不会堵塞
- 如果在调用acquire对这个锁上锁之前 它已经被 其他线程上了锁,那么此时acquire会堵塞,直到这个锁被解锁为止。
和文件操作一样,Lock也可以使用with语句快速的实现打开和关闭操作。
使用互斥锁解决卖票问题
import threadingimport time
ticket = 20
lock = threading.Lock()
def sell_ticket():
global ticket
while True:
lock.acquire()
if ticket > 0:
time.sleep(0.5)
ticket -= 1
lock.release()
print('{}卖了一张票,还剩{}'.format(threading.current_thread().name, ticket))
else:
print('{}票卖完了'.format(threading.current_thread().name))
lock.release()
break
for i in range(5):
t = threading.Thread(target=sell_ticket, name='thread-{}'.format(i + 1))
t.start()Copy上锁过程:
当一个线程调用锁的acquire()方法获得锁时,锁就进入“locked”状态。
每次只有一个线程可以获得锁。如果此时另一个线程试图获得这个锁,该线程就会变为“blocked”状态,称为“阻塞”,直到拥有锁的线程调用锁的release()方法释放锁之后,锁进入“unlocked”状态。
线程调度程序从处于同步阻塞状态的线程中选择一个来获得锁,并使得该线程进入运行(running)状态。
总结
锁的好处:
- 确保了某段关键代码只能由一个线程从头到尾完整地执行
锁的坏处:
- 阻止了多线程并发执行,包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降了。
- 由于可以存在多个锁,不同的线程持有不同的锁,并试图获取对方持有的锁时,可能会造成死锁。
线程间通信
线程之间有时需要通信,操作系统提供了很多机制来实现进程间的通信,其中我们使用最多的是队列Queue.
Queue的原理
Queue是一个先进先出(First In First Out)的队列,主进程中创建一个Queue对象,并作为参数传入子进程,两者之间通过put( )放入数据,通过get( )取出数据,执行了get( )函数之后队列中的数据会被同时删除,可以使用multiprocessing模块的Queue实现多进程之间的数据传递。
import threadingimport timefrom queue import Queue
def producer(queue):
for i in range(100):
print('{}存入了{}'.format(threading.current_thread().name, i))
queue.put(i)
time.sleep(0.1)
return
def consumer(queue):
for x in range(100):
value = queue.get()
print('{}取到了{}'.format(threading.current_thread().name, value))
time.sleep(0.1)
if not value:
return
if __name__ == '__main__':
queue = Queue()
t1 = threading.Thread(target=producer, args=(queue,))
t2 = threading.Thread(target=consumer, args=(queue,))
t3 = threading.Thread(target=consumer, args=(queue,))
t4 = threading.Thread(target=consumer, args=(queue,))
t6 = threading.Thread(target=consumer, args=(queue,))
t1.start()
t2.start()
t3.start()
t4.start()
t6.start()多线程版聊天
import socketimport threading
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
s.bind(('0.0.0.0', 8080))
def send_msg():
ip = input('请输入您要聊天的ip:')
port = int(input('请输入对方的端口号:'))
while True:
msg = input('请输入聊天内容:')
s.sendto(msg.encode('utf-8'), (ip, port))
if msg == "bye":
ip = input('请输入您要聊天的ip:')
port = int(input('请输入对方的端口号:'))
def recv_msg():
while True:
content, addr = s.recvfrom(1024)
print('接收到了{}主机{}端口的消息:{}'.format(addr[0], addr[1], content.decode('utf-8')),file=open('history.txt', 'a', encoding='utf-8'))
send_thread = threading.Thread(target=send_msg)
recv_thread = threading.Thread(target=recv_msg)
send_thread.start()
recv_thread.start()进程
程序:例如xxx.py这是程序,是一个静态的。
进程:一个程序运行起来后,代码+用到的资源 称之为进程,它是操作系统分配资源的基本单元。
不仅可以通过线程完成多任务,进程也是可以的。
进程的状态
工作中,任务数往往大于cpu的核数,即一定有一些任务正在执行,而另外一些任务在等待cpu进行执行,因此导致了有了不同的状态。
- 就绪态:运行的条件都已经满足,正在等在cpu执行。
- 执行态:cpu正在执行其功能。
- 等待态:等待某些条件满足,例如一个程序sleep了,此时就处于等待态。
35 HTTP服务器
使用谷歌/火狐浏览器分析
在Web应用中,服务器把网页传给浏览器,实际上就是把网页的HTML代码发送给浏览器,让浏览器显示出来。而浏览器和服务器之间的传输协议是HTTP,所以:
- HTML是一种用来定义网页的文本,会HTML,就可以编写网页;
- HTTP是在网络上传输HTML的协议,用于浏览器和服务器的通信。
Chrome浏览器提供了一套完整地调试工具,非常适合Web开发。
安装好Chrome浏览器后,打开Chrome,在菜单中选择“视图”,“开发者”,“开发者工具”,就可以显示开发者工具:
说明
- Elements显示网页的结构
- Network显示浏览器和服务器的通信
我们点Network,确保第一个小红灯亮着,Chrome就会记录所有浏览器和服务器之间的通信:

http协议的分析
当我们在地址栏输入www.sina.com时,浏览器将显示新浪的首页。在这个过程中,浏览器都干了哪些事情呢?通过Network的记录,我们就可以知道。在Network中,找到www.sina.com那条记录,点击,右侧将显示Request Headers,点击右侧的view source,我们就可以看到浏览器发给新浪服务器的请求:
浏览器请求


说明
最主要的头两行分析如下,第一行:
GET / HTTP/1.1Copy
GET表示一个读取请求,将从服务器获得网页数据,/表示URL的路径,URL总是以/开头,/就表示首页,最后的HTTP/1.1指示采用的HTTP协议版本是1.1。目前HTTP协议的版本就是1.1,但是大部分服务器也支持1.0版本,主要区别在于1.1版本允许多个HTTP请求复用一个TCP连接,以加快传输速度。
从第二行开始,每一行都类似于Xxx: abcdefg:
Host: www.sina.comCopy
表示请求的域名是www.sina.com。如果一台服务器有多个网站,服务器就需要通过Host来区分浏览器请求的是哪个网站。
服务器响应
继续往下找到Response Headers,点击view source,显示服务器返回的原始响应数据:

HTTP响应分为Header和Body两部分(Body是可选项),我们在Network中看到的Header最重要的几行如下:
HTTP/1.1 200 OKCopy
200表示一个成功的响应,后面的OK是说明。
如果返回的不是200,那么往往有其他的功能,例如
- 失败的响应有404 Not Found:网页不存在
- 500 Internal Server Error:服务器内部出错
- ...等等...
Content-Type: text/htmlCopy
Content-Type指示响应的内容,这里是text/html表示HTML网页。
请注意,浏览器就是依靠Content-Type来判断响应的内容是网页还是图片,是视频还是音乐。浏览器并不靠URL来判断响应的内容,所以,即使URL是http://www.baidu.com/meimei.jpg,它也不一定就是图片。
HTTP响应的Body就是HTML源码,我们在菜单栏选择“视图”,“开发者”,“查看网页源码”就可以在浏览器中直接查看HTML源码:

浏览器解析过程
当浏览器读取到新浪首页的HTML源码后,它会解析HTML,显示页面,然后,根据HTML里面的各种链接,再发送HTTP请求给新浪服务器,拿到相应的图片、视频、Flash、JavaScript脚本、CSS等各种资源,最终显示出一个完整的页面。所以我们在Network下面能看到很多额外的HTTP请求。

总结
HTTP请求
跟踪了新浪的首页,我们来总结一下HTTP请求的流程:
步骤1:浏览器首先向服务器发送HTTP请求,请求包括:
方法:GET还是POST,GET仅请求资源,POST会附带用户数据;
路径:/full/url/path;
域名:由Host头指定:Host: www.sina.com
以及其他相关的Header;
如果是POST,那么请求还包括一个Body,包含用户数据
步骤2:服务器向浏览器返回HTTP响应,响应包括:
响应代码:200表示成功,3xx表示重定向,4xx表示客户端发送的请求有错误,5xx表示服务器端处理时发生了错误;
响应类型:由Content-Type指定;
以及其他相关的Header;
通常服务器的HTTP响应会携带内容,也就是有一个Body,包含响应的内容,网页的HTML源码就在Body中。
步骤3:如果浏览器还需要继续向服务器请求其他资源,比如图片,就再次发出HTTP请求,重复步骤1、2。
Web采用的HTTP协议采用了非常简单的请求-响应模式,从而大大简化了开发。当我们编写一个页面时,我们只需要在HTTP请求中把HTML发送出去,不需要考虑如何附带图片、视频等,浏览器如果需要请求图片和视频,它会发送另一个HTTP请求,因此,一个HTTP请求只处理一个资源(此时就可以理解为TCP协议中的短连接,每个链接只获取一个资源,如需要多个就需要建立多个链接)
HTTP协议同时具备极强的扩展性,虽然浏览器请求的是http://www.sina.com的首页,但是新浪在HTML中可以链入其他服务器的资源,比如 ,从而将请求压力分散到各个服务器上,并且,一个站点可以链接到其他站点,无数个站点互相链接起来,就形成了World Wide Web,简称WWW。
,从而将请求压力分散到各个服务器上,并且,一个站点可以链接到其他站点,无数个站点互相链接起来,就形成了World Wide Web,简称WWW。

HTTP格式
每个HTTP请求和响应都遵循相同的格式,一个HTTP包含Header和Body两部分,其中Body是可选的。
HTTP协议是一种文本协议,所以,它的格式也非常简单。
HTTP GET请求的格式:
GET /path HTTP/1.1
Header1: Value1
Header2: Value2
Header3: Value3Copy
每个Header一行一个,换行符是\r\n。
HTTP POST请求的格式:
POST /path HTTP/1.1
Header1: Value1
Header2: Value2
Header3: Value3
body data goes here...Copy
当遇到连续两个\r\n时,Header部分结束,后面的数据全部是Body。
HTTP响应的格式:
200 OK
Header1: Value1
Header2: Value2
Header3: Value3
body data goes here...Copy
HTTP响应如果包含body,也是通过\r\n\r\n来分隔的。
请再次注意,Body的数据类型由Content-Type头来确定,如果是网页,Body就是文本,如果是图片,Body就是图片的二进制数据。
当存在Content-Encoding时,Body数据是被压缩的,最常见的压缩方式是gzip,所以,看到Content-Encoding: gzip时,需要将Body数据先解压缩,才能得到真正的数据。压缩的目的在于减少Body的大小,加快网络传输。
手动搭建HTTP服务器
import reimport socketfrom multiprocessing import Process
class WSGIServer():
def __init__(self, server, port, root):
self.server = server
self.port = port
self.root = root
self.server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
self.server_socket.bind((self.server, self.port))
self.server_socket.listen(128)
def handle_socket(self, socket):
data = socket.recv(1024).decode('utf-8').splitlines()[0]
file_name = re.match(r'[^/]+(/[^ ]*)', data)[1]
# print(file_name)
if file_name == '/':
file_name = self.root + '/index.html'
else:
file_name = self.root + file_name
try:
file = open(file_name, 'rb')
except IOError:
response_header = 'HTTP/1.1 404 NOT FOUND \r\n'
response_header += '\r\n'
response_body = '========Sorry,file not found======='.encode('utf-8')
else:
response_header = 'HTTP/1.1 200 OK \r\n'
response_header += '\r\n'
response_body = file.read()
finally:
socket.send(response_header.encode('utf-8'))
socket.send(response_body)
def forever_run(self):
while True:
client_socket, client_addr = self.server_socket.accept()
# self.handle_socket(client_socket)
p = Process(target=self.handle_socket, args=(client_socket,))
p.start()
client_socket.close()if __name__ == '__main__':
ip = '0.0.0.0'
port = 8899
server = WSGIServer(ip, port, './pages')
print('server is running at {}:{}'.format(ip, port))
server.forever_run()WSGI接口
WSGI接口定义非常简单,它只要求Web开发者实现一个函数,就可以响应HTTP请求。我们来看一个最简单的Web版本的“Hello, web!”:
def application(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/html')])
return 'Hello, web!
'Copy
上面的application()函数就是符合WSGI标准的一个HTTP处理函数,它接收两个参数:
- environ:一个包含所有HTTP请求信息的dict对象;
- start_response:一个发送HTTP响应的函数。
在application()函数中,调用:
start_response('200 OK', [('Content-Type', 'text/html')])Copy
就发送了HTTP响应的Header,注意Header只能发送一次,也就是只能调用一次start_response()函数。start_response()函数接收两个参数,一个是HTTP响应码,一个是一组list表示的HTTP Header,每个Header用一个包含两个str的tuple表示。
通常情况下,都应该把Content-Type头发送给浏览器。其他很多常用的HTTP Header也应该发送。
然后,函数的返回值'Hello, web!
'将作为HTTP响应的Body发送给浏览器。
有了WSGI,我们关心的就是如何从environ这个dict对象拿到HTTP请求信息,然后构造HTML,通过start_response()发送Header,最后返回Body。
整个application()函数本身没有涉及到任何解析HTTP的部分,也就是说,底层代码不需要我们自己编写,我们只负责在更高层次上考虑如何响应请求就可以了。
不过,等等,这个application()函数怎么调用?如果我们自己调用,两个参数environ和start_response我们没法提供,返回的str也没法发给浏览器。
所以application()函数必须由WSGI服务器来调用。有很多符合WSGI规范的服务器,我们可以挑选一个来用。但是现在,我们只想尽快测试一下我们编写的application()函数真的可以把HTML输出到浏览器,所以,要赶紧找一个最简单的WSGI服务器,把我们的Web应用程序跑起来。
好消息是Python内置了一个WSGI服务器,这个模块叫wsgiref,它是用纯Python编写的WSGI服务器的参考实现。所谓“参考实现”是指该实现完全符合WSGI标准,但是不考虑任何运行效率,仅供开发和测试使用。
新建WSGI服务器
- 创建hello.py文件,用来实现WSGI应用的处理函数。
def application(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/html')])
print(environ)
return ['Hello, web!
'.encode('utf-8'),'hello'.encode('utf-8')]Copy
- 创建server.py文件,用来启动WSGI服务器,加载appliction 函数
# 从wsgiref模块导入:from wsgiref.simple_server import make_server# 导入我们自己编写的application函数:from hello import application
# 创建一个服务器,IP地址为空,端口是8000,处理函数是application:
httpd = make_server('', 8000, application)
print("Serving HTTP on port 8000...")# 开始监听HTTP请求:
httpd.serve_forever()
使用if管理请求路径
文件结构:
├── server.py
├── utils.py
├── pages
└── index.html
└── templates
└── info.htmlCopy
utlis.py文件
PAGE_ROOT = './pages'
TEMPLATE_ROOT = './templates'
def load_html(file_name, start_response, root=PAGE_ROOT):
"""
加载HTML文件时调用的方法
:param file_name: 需要加载的HTML文件
:param start_response: 函数,用来设置响应头。如果找到文件,请求头设置为200,否则设置为410
:param root: HTML文件所在的目录。默认PAGE_ROOT表示静态HTML文件,TEMPLATE_ROOT表示的是模板文件
:return: 读取HTML文件成功的话,返回HTML文件内容;读取失败提示资源被删除
"""
file_name = root + file_name
try:
file = open(file_name, 'rb')
except IOError:
start_response('410 GONE', [('Content-Type', "text/html;charset=utf-8")])
return ['资源被删除了'.encode('utf-8')]
else:
start_response('200 OK', [('Content-Type', "text/html;charset=utf-8")])
content = file.read()
return [content]
def load_template(file_name, start_respone, **kwargs):
"""
加载模板文件
:param file_name: 需要加载的模板文件名
:param start_respone: 函数,用来设置响应头。如果找到文件,请求头设置为200,否则设置为410
:param kwargs: 用来设置模板里的变量
:return: 读取HTML文件成功的话,返回HTML文件内容;读取失败提示资源被删除
"""
content = load_html(file_name, start_respone, root=TEMPLATE_ROOT)
html = content[0].decode('utf-8')
if html.startswith(''):
return [html.format(**kwargs).encode('utf-8')]
else:
return contentCopy
service.py文件
from wsgiref.simple_server import make_serverfrom utils import load_html, load_template
def show_home(start_response):
return load_html('/index.html', start_response)
def show_test(start_response):
start_response('200 OK', [('Content-Type', "text/html;charset=utf-8")])
return ['我是一段普通的文字'.encode('utf-8')]
def show_info(start_response):
return load_template('/info.html', start_response, name='张三',age=18})
def application(environ, start_response):
path = environ.get('PATH_INFO')
# 处理首页请求(加载一个HTML文件)
if path == '/' or path == '/index.html':
result = show_home(start_response)
return result
# 处理test.html请求(返回一个普通的字符串)
elif path == '/test.html':
return show_test(start_response)
# 处理info.html请求(加载一个模板并且返回)
elif path == '/info.html':
return show_info(start_response)
# 其它请求暂时无法处理,返回404
else:
start_response('400 NOT FOUND', [('Content-Type', "text/html;charset=utf-8")])
return ['页面未找到'.encode('utf-8')]
httpd = make_server('', 8000, application)
print("Serving HTTP on port 8000...")
httpd.serve_forever()使用字典管理请求路径
文件结构:
├── server.py
├── utils.py
├── urls.py
├── pages
└── index.html
└── templates
└── info.htmlCopy
urls.py文件:该文件里只有一个字典对象,用来保存请求路径和处理函数之间的对应关系。
urls = {
'/': 'show_home',
'/index.html': 'show_home',
'/test.html': 'show_test',
'/info.html': 'show_info'
}Copy
server.py文件:
from wsgiref.simple_server import make_serverfrom urls import urlsfrom utils import load_html, load_template
def show_home(start_response):
return load_html('/index.html', start_response)
def show_test(start_response):
start_response('200 OK', [('Content-Type', "text/html;charset=utf-8")])
return ['我是一段普通的文字'.encode('utf-8')]
def show_info(start_response):
return load_template('/info.html', start_response, name='张三',age=18})
def application(environ, start_response):
path = environ.get('PATH_INFO')
# 这里不再是一大堆的if...elif语句了,而是从urls字典里获取到对应的函数
func = urls.get(path)
if func:
return eval(func)(start_response)
# 其它请求暂时无法处理,返回404
else:
start_response('400 NOT FOUND', [('Content-Type', "text/html;charset=utf-8")])
return ['页面未找到'.encode('utf-8')]
httpd = make_server('', 8000, application)
print("Serving HTTP on port 8000...")
httpd.serve_forever()使用装饰器管理请求路径
from wsgiref.simple_server import make_serverfrom utils import load_html, load_template
g_url_route = {}
def route(url):
def handle_action(action):
g_url_route[url] = action
def do_action(start_response):
return action(start_response)
return do_action
return handle_action
@route('/index.html')@route('/')def show_home(start_response):
return load_html('/index.html', start_response)
@route('/test.html')def show_test(start_response):
start_response('200 OK', [('Content-Type', "text/html;charset=utf-8")])
return ['我是一段普通的文字'.encode('utf-8')]
@route('/info.html')def show_info(start_response):
return load_template('/info.html', start_response, name='张三', age=18)
def application(environ, start_response):
file_name = environ.get('PATH_INFO')
try:
return g_url_route[file_name](start_response)
except Exception:
start_response('404 NOT FOUND', [('Content-Type', 'text/html;charset=utf-8')])
return ['对不起,界面未找到'.encode('utf-8')]
if __name__ == '__main__':
httpd = make_server('', 8000, application)
print("Serving HTTP on port 8000...")
httpd.serve_forever()requests模块
除了使用浏览器给服务器发送请求以外,我们还可以使用第三方模块requests用代码来给服务器发送器请求,并获取结果。
url = 'https://www.apiopen.top/satinApi'
params = {'type': 1, 'page': 2}
response = requests.get(url, params)
print(response)
# 方法二: 只能用于get请求
url = 'https://www.apiopen.top/satinApi?type=1&page=1'
response = requests.get(url)# print(response)
# 2.获取请求结果
print(response.headers)
# 2)响应体(数据)# a.获取二进制对应的原数据(数据本身是图片、压缩文件、视频等文件数据)
content = response.content
print(type(content))
# b.获取字符类型的数据
text = response.text
print(type(text))
# c.获取json数据(json转换成python对应的数据)
json = response.json()
print(type(json))
print(json)
===================flask语法=============================
这里我本来是准备整理详细语法的,但是还是删除了,因为我自己其实也没有怎么特别记忆“背诵”这些语法,能不能记住还是以多在实际项目中应用吧。再者,只要会了上面的基本语法,框架的语法基本不成问题的。所以这里就不单独列了。
flask本地部署
该项目也是我参考的网上的开源项目学习的。
没有改过的项目git链接:git clone https://gitee.com/tianshibaobao/flask1(测试之后报错,所以我本地部署的是改过之后的)
本地windows运行成功的链接:git clone https://gitee.com/tianshibaobao/flask2
下载完代码,安装一下requirements.txt的依赖。
本地redis无密码启动:
启动 python app.py runserver -h 0.0.0.0 -p 5000
访问 http://127.0.0.1:5000/user/



flask vmware-linux部署
下载代码部署:
git clone https://gitee.com/tianshibaobao/flask1
安装依赖 pip instll -r requirements.txt
保证mysql(如果用我的数据,sql在根目录),redis(无密码),nginx(配置文件已经放在代码根目录)正常启动。
进入虚拟环境:workon flaskblog(我创建的名字是这个)

uwsgi启动,因为nginx无法直接处理 flask:uwsgi --ini uwsgi.ini

浏览器访问:http://192.168.140.143/user/


其他命令:
python app.py db init
python app.py db migrate
python app.py db upgrade
python app.py runserver
python app.py runserver -h 0.0.0.0 -p 8000
pip instll -r requirements.txt
python app.py runservercentos7 安装python3.7.1
centos7自带python2,由于执行yum需要python2,所以即使安装了python3也不能删除python2
1.安装依赖包
yum -y groupinstall "Development tools"
yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel libffi-devel
2.下载自己需要的python版本,例如python3.7.1,下载要花费一段时间,要耐心等待
yum -y install wget
wget https://www.python.org/ftp/python/3.7.1/Python-3.7.1.tar.xz
3.新建一个文件夹存放python3
mkdir /usr/local/python3
4.把安装包移动到该新建文件夹下,解压安装包,安装python3,依次执行以下命令,花费时间较长,耐心等待
mv Python-3.7.1.tar.xz /usr/local/python3
cd /usr/local/python3
tar -xvJf Python-3.7.1.tar.xz
cd Python-3.7.1
./configure --prefix=/usr/local/python3
make
make install
5.创建软连接
ln -s /usr/local/python3/bin/python3 /usr/bin/python3
ln -s /usr/local/python3/bin/pip3 /usr/bin/pip3
6.此时python3已经装好,在命令行中输入python3测试
7.修改yum配置文件,python2与python3共存
vi /usr/bin/yum
把#! /usr/bin/python修改为#! /usr/bin/python2(配置文件第一行)
同理
vi /usr/libexec/urlgrabber-ext-down
把文件里面的#! /usr/bin/python 也修改为#! /usr/bin/python2
此时完成python3安装,且实现与python2共存,保持yum命令可用
centos7安装虚拟环境
更新
pip3 install --upgrade pip
安装
pip3 install virtualenv
pip install --upgrade setuptools
pip3 install virtualenvwrapper
编辑
vi ~/.bashrc
export WORKON_HOME=$HOME/.virtualenvs
export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3
export VIRTUALENVWRAPPER_VIRTUALENV=/usr/local/python3/bin/virtualenv
source /usr/local/python3/bin/virtualenvwrapper.sh
source ~/.bashrc
创建
mkvirtualenv flaskblog
进入虚拟环境
workon flaskblog
删除虚拟环境命令
rmvirtualenv flaskblog
(flaskblog) [root@localhost flaskblog]# pip install -r requirements.txt
退出虚拟环境
deactivate
测试一下
python app.py runserver -h 0.0.0.0
http://192.168.140.143:5000/user/center
uwsgi和ngin关联
pip install uwsgi==2.0.18
启动 uwsgi --ini uwsgi.ini
停止 uwsgi --stop uwsgi.pid
配置ngin.conf和项目根目录的uwsgi.ini
先启动nginx:/usr/local/nginx/sbin/nginx
启动uwsgi:uwsgi --ini uwsgi.ini
uwsgi --stop uwsgi.piddjango
==========下面这个是练手的django下面项目=======================
代码和库地址:
git clone https://gitee.com/tianshibaobao/day16.git
安装Python3.9.5:
1.安装gcc
yum install gcc -y
2.安装Python依赖
yum install zlib zlib-devel -y
yum install bzip2 bzip2-devel -y
yum install ncurses ncurses-devel -y
yum install readline readline-devel -y
yum install openssl openssl-devel -y
yum install xz lzma xz-devel -y
yum install sqlite sqlite-devel -y
yum install gdbm gdbm-devel -y
yum install tk tk-devel -y
yum install mysql-devel -y
yum install python-devel -y
yum install libffi-devel -y
3.下载源码 Python3.9.5
yum install wget -y
cd /data/
wget https://www.python.org/ftp/python/3.9.5/Python-3.9.5.tgz
4.解压 & 编译 & 安装
tar -xvf Python-3.9.5.tgz
cd Python-3.9.5
./configure
make all
make install
5.Python解释器配置豆瓣源
pip3.9 config set global.index-url https://pypi.douban.com/simple/
1.安装virtualenv
pip3 install virtualenv
2.创建虚拟环境
代码:
/home/project/day16
环境:
/envs/pro
mkdir /envs
virtualenv /envs/pro --python=python3.9
3.激活虚拟环境file:/E:/code/python/test/day16/day16/settings.py
source /envs/pro/bin/activate
pip install Django==3.2.3
pip install Pillow==8.3.1
pip install PyMySQL==1.0.2
4.假设
source /envs/pro/bin/activate
cd /home/project/day16
python3 manage.py runserver 0.0.0.0:9000
在/home/project/day16创建
【pro_uwsgi.ini】
[uwsgi]
#与nginx通信
socket = 0.0.0.0:9000
#让uwsgi作为单独的web-server,这里注释掉
#http = 127.0.0.1:9000
chdir = /home/project/day16
wsgi-file = /home/project/day16/day16/wsgi.py
processes = 4
threads = 2
master = True
pidfile = uwsgi.pid
daemonize = uwsgi.log
virtualenv = /envs/pro/
【nginx.conf】
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
server {
server_name localhost; #改为自己的域名,没域名修改为127.0.0.1:80
listen 80;
charset utf-8;
location / {
include /etc/nginx/uwsgi_params;
uwsgi_pass 127.0.0.1:9000; #端口要和uwsgi里配置的一样,用来和uwsgi通信
#uwsgi_param UWSGI_SCRIPT pro_uwsgi.ini; #wsgi.py所在的目录名+.wsgi
#uwsgi_param UWSGI_CHDIR /home/project/day16; #项目路径
}
location /static {
alias /home/project/day16/app01/static/; #css等静态资源路径
}
location /media {
alias /home/project/day16/media/; #图片类静态资源路径
}
}
}


在/home/project/day16/day16 先启动【uwsgi --ini pro_uwsgi.ini 】

在启动nginx

然后在本地浏览器访问http://192.168.140.144/login/

除了样式的问题,页面还是可以正常出来的,因为没有时间调样式了,所以没有继续弄。
==========下面这个是开源的django-vue项目=======================
https://django-vue-admin.com/
官网介绍的比较详细,跟着做就好了。