Dynamic MDETR: A Dynamic Multimodal Transformer Decoder for Visual Grounding 论文阅读笔记
Dynamic MDETR: A Dynamic Multimodal Transformer Decoder for Visual Grounding 论文阅读笔记
- 一、Abstract
- 二、引言
- 三、相关工作
-
- 3.1 视觉定位
- 3.2 多模态 Transformer
- 3.3 有效的 Transformers
- 四、Dynamic MDETR
-
- 4.1 预备知识
-
- 4.1.1 Multimodal Transformer
- 4.1.2 DETR 和 MDETR
- 4.2 特征编码器
- 4.3 多模态 Transformer 编码器
- 4.4 动态多模态 Transformer 解码器
-
- 4.4.1 2D 自适应采样
- 4.4.2 文本引导解码
- 4.4.3 建模效率的讨论
- 4.5 预测头
- 4.6 损失函数
- 五、实验
-
- 5.1 数据集和评估指标
- 5.2 实施细节
- 5.3 消融实验
-
- 动态多模态编码器中的关键设计
- 精度和计算量的权衡
- 不同的初始化采样策略
- 动态采样 vs. 静态采样
- 与其他动态 Transformer 的比较
- 5.4 与其他 SOTA 方法的比较
- 5.5 可视化
-
- 不同解码器层的采样点
- 文本到图像编码器注意力图的可视化
- 六、结论
写在前面
这几天练的丹不行,但论文还是得继续读哇,也得加快效率了~~
这是一篇关于动态 Transformer 解码器的文章,看这个标题很有意思,于是拿来读读。
- 论文地址:Dynamic MDETR: A Dynamic Multimodal Transformer Decoder for Visual Grounding
- 代码地址:论文未提供
- 预计提交于:IEEE 某个顶会
- Ps:2023 年每周一篇博文,主页 更多干货,欢迎关注呀,期待 5 千粉丝有你的参与呦~
一、Abstract
多模态 Transformer 在视觉定位任务上能够很好的对齐图像和文本,但自注意力机制使得仅有编码器参与的 Transformer 框架,例如 TranVG(RIS 系列:TransVG: End-to-End Visual Grounding with Transformers 论文阅读笔记)中的计算复杂度很高。于是本文提出 Dynamic MDETR,将整个定位过程拆分为编码和解码两阶段。鉴于图像中高度的空间冗余,于是设计动态 Transformer 解码器,利用空间冗余先验来加快视觉定位过程。动态解码器由一个 2D 自适应采样模块和一个文本引导的解码模块组成。通过预测与参考点相关的 offsets,采样模块旨在选择那些包含信息量的 patches,而解码块则通过执行图像和文本特征间的交叉注意力来提取出被定位的目标信息。这俩模块可选择性堆叠从而逐渐地填补模态鸿沟,并逐渐地提炼被定位目标的参考点,最终实现视觉定位。实验效果很好。此外,为验证泛化性,建立第一个一阶段的 CLIP 视觉定位框架来实现 SOTA 的性能。
二、引言
首先指出视觉定位的定义,意义。现有的视觉定位方法可划分为两阶段方法和单阶段方法。两阶段方法首先通过离线的检测器生成 Proposals,并计算这些 Proposals 和表达式的相似度,之后选择出最佳得分的 Proposal 作为最终的预测。而单阶段方法首先将语言特征融合到图像特征图中,然后直接地用预定义的 anchors 在网格图中预测 Bounding box。
两阶段方法受限于第一阶段中生成的区域质量,并且不能进行端到端训练。单阶段方法通过移除 Proposals 生成,加快了推理速度。但在网格图上预测每个点的做法未能捕捉图像中的物体联系。此外,一些简单的多模态融合操作,例如拼接等,也不能较好地捕捉跨模态交互。
Transformer 在视觉定位任务上也有一些工作,例如 TransVG。多模态 Transformer 简单且有效,但由于图像和文本之间的注意力操作使得其计算复杂度很高。实际上,并不是图像中的所有像素都对最后的预测有帮助,例如背景像素。而在视觉定位任务中,那些不相关的物体都可以视为冗余。

单模态任务中有一些工作尝试降低空间冗余(举例:Vit 中的 Token 改进版本:Token Mreging: Your Vit But Faster 论文阅读笔记),但这些模型的训练仍然计算成本高。同时不太清楚这些方法能否适用于多模态任务上,因为需要考虑多模态的信息关联。
本文提出 Dynamic MDETR,基于相对浅层的编码器用于跨模态特征融合与对齐,以及一个动态编码器用于定位目标。核心贡献在于多模态 Transformer 解码器,消除了基于输入图像尺寸的解码复杂度问题。核心设计在于 2D 几何空间中,语言引导的空间自适应采样。通过自适应地采样少量丰富信息的视觉 tokens 用于后续的多模态解码。而这一操作可以将计算复杂度降为与图像尺寸无关的常数,同时也能减少无关 tokens 对最终 bounding box 的影响。
下面是对 Dynamic MDETR 框架的介绍:首先视觉和语言 backbone 分别提取相应的特征,然后拼接为一个序列,送入到 Transformer 编码器中用于跨模态特征融合和对齐。在之后的动态 Transformer 解码器中,首先将语言信息注入到可学习的采样 query 中,之后动态解码器产生相对于参考点的 offsets,用于 2D 特征图上的特征采样。采样出的特征在语言 queries 的引导下送入标准的 Transformer 进行解码。最后,FFN 预测头直接回归出 bounding box 的 4D 坐标。
相比于 1D 采样,本文提出的 2D 采样有下列优势:基于双线性插值的 2D 采样模块是可微分的,于是可以固定采样点的数量从而降低训练成本;在整个图像上的空间自适应采样能够避免累计误差;2D 空间中的弹性采样能够辅助学习位置和几何信息。
实验结果表明 Dynamic MDETR 很有效。此外,进一步利用 CLIP 作为 Backbone 的情况下,Dynamic MDETR 达到了单阶段视觉定位任务的 SOTA。贡献总结如下:
- 提出 Dynamic MDETR 用于视觉定位任务,采用一个相对浅层的编码器用于跨模态特征融合与对齐,提出一个动态解码器用于文本引导的视觉定位;
- 在 2D 自适应采样下,提出的动态解码器采样 2D 空间中的小部分视觉特征,降低计算复杂度到常数级;
- 实验表明 Dynamic MDETR 的效果很好;
- 进一步将 CLIP 作为 Backbone,展示了 Dynamic MDETR 框架的泛化性和可拓展性。
三、相关工作
3.1 视觉定位
这一部分和引言开头内容重复,只是多举几个例子。
3.2 多模态 Transformer
介绍下预训练和单/双流方法的流程,缺点是计算复杂度随着序列长度的增长而呈平方增加。
3.3 有效的 Transformers
Transformer 中的自注意力机制使得模型在具有全局感受野和大尺度建模能力的同时,也有很高的内存和训练成本。于是一些降低模型冗余度的方法出现了,可将 O ( n 2 ) O(n^2) O(n2) 降为 O ( n ) O(n) O(n)。
本文关注另一种形式的 Transformer,即、减少数据水平的冗余。有一些基于 tokens 的排序方法:DynamicViT、IA-RED2,一些 trick,例如 gumbel softmax,用于解决不可微问题。但在训练时,所有的 tokens 仍参与训练,因此这些方法仅能减少推理时的计算量。
受基于 offsets 的空间采样方法启发,本文基于可微分的双线性插值,提出 2D 自适应采样。与上述基于排序的方法相比,Dynamic MDETR 的采样模块能够使用少数量的弹性点用于训练和推理,从而减少了训练和推理时的计算复杂度。此外,Dynamic MDETR 保留了图像的 2D 结构和采样的视觉特征点,这能够很好地捕捉指代目标的位置、几何结构信息。
四、Dynamic MDETR
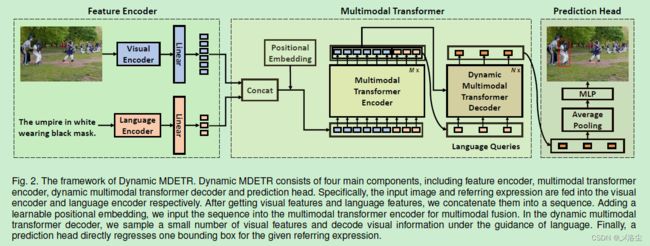
如上图所示,给定输入图像 I ∈ R 3 × H × W I\in\mathbb{R}^{3\times H\times W} I∈R3×H×W 和指代表达式 E = { w i } i = 1 L E=\{w_{i}\}_{i=1}^{L} E={wi}i=1L,其中 w i w_{i} wi 是第 i i i 个单词, L L L 为表达式的长度。视觉定位旨在输出 bounding box 的坐标 b = ( x , y , w , h ) b=(x,y,w,h) b=(x,y,w,h),其中 ( x , y ) (x,y) (x,y) 为 box 的中心坐标, ( w , h ) (w,h) (w,h) 为预测 bounding box 的宽和高。
Dynamic MDETR 有 4 个部分:特征编码器,多模态 Transformer 编码器,动态多模态 Transformer 解码器,预测头。首先从预训练的解码器中提取视觉和语言特征,然后将其拼接到同一个序列中。之后将 token 序列送入到 Transformer 编码器中进行跨模态特征对齐与融合,输出的序列再拆分为视觉和语言特征。不同于原始的 DETR 和 MDETR,本文直接使用语言特征作为 queries 而不是可学习的目标 queries。动态多模态 Transformer 解码器仅利用 2D 自适应采样,挑选出少量的样本特征点,在语言 queries 的引导下将这些视觉特征解码。最后,基于 MLP 的预测头回归出 Bounding box。
4.1 预备知识
4.1.1 Multimodal Transformer
query embedding: Q ∈ R M × C Q\in\mathbb{R}^{M\times C} Q∈RM×C,key embedding: K ∈ R N × C K\in\mathbb{R}^{N\times C} K∈RN×C,value embedding: V ∈ R N × C V\in\mathbb{R}^{N\times C} V∈RN×C。
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V M H A ( Q , K , V ) = Concat ( head 1 , ⋯ , head H ) W O h e a d i = Attention ( Q W i Q , K W i K , V W i V ) \begin{aligned} \mathrm{Attention}(Q,K,V)&=\mathrm{softmax}(\frac{QK^{\mathrm{T}}}{\sqrt{d_{k}}})V\\ \mathrm{MHA}(Q,K,V)& =\text{Concat}(\text{head}_1,\cdots,\text{head}_H)W^O \\ \mathrm{head}_{i}& =\text{Attention}(QW_i^Q,KW_i^K,VW_i^V) \end{aligned} Attention(Q,K,V)MHA(Q,K,V)headi=softmax(dkQKT)V=Concat(head1,⋯,headH)WO=Attention(QWiQ,KWiK,VWiV)
4.1.2 DETR 和 MDETR
第一段介绍下 DETR 的流程及优点,MDETR 的组成。
第二段表明 Dynamic MDETR 与这两种方法的不同之处:在 Transformer 解码器中引入 2D 自适应采样,使得解码器能够动态地选择少数量的视觉特征,例如 9% 的点;Dynamic MDETR 采用语言特征作为 queries 而不是可学习的位置 embedding,能够直接采样包含信息的视觉特征,从而在语言的引导下,在语义上聚合视觉线索。
4.2 特征编码器
采用离线的特征编码器 ResNet 加 Transformer 编码器或 ViT 作为视觉 Backbone,DETR 的权重进行初始化。对于 ViT 作为 Backbone 的情况下,采用 CLIP 预训练的权重。Bert 作为语言编码器,采用非级联的 Bert 或者 CLIP 中预训练的文本编码器权重。给定图像-表达式对 < I , E >
4.3 多模态 Transformer 编码器
多模态 Transformer 编码器包含 M M M 个标准的 Transformer 编码器层,输入为 F F F。类似 DETR,在每个编码器的输入中添加一个可学习的位置 embedding P ∈ R ( N v + N l ) × C P\in\mathbb{R}^{({N}_v+N_l)\times C} P∈R(Nv+Nl)×C。于是第 i i i 层的计算如下:
Q E i = K E i = V E i = F i − 1 F ^ i = L N ( Q E i + M H A ( Q E i + P , K E i + P , V E i ) ) F i = L N ( F i ^ + F F N ( F i ^ ) ) \begin{aligned} &Q_{E}^{i} =K_E^i=V_E^i=F^{i-1}\\ &\hat{F}^{i} =\mathrm{LN}(Q_E^i+\mathrm{MHA}(Q_E^i+P,K_E^i+P,V_E^i)) \\ &F^{i} =\mathrm{LN}(\hat{F^i}+\mathrm{FFN}(\hat{F^i})) \end{aligned} QEi=KEi=VEi=Fi−1F^i=LN(QEi+MHA(QEi+P,KEi+P,VEi))Fi=LN(Fi^+FFN(Fi^))其中 F 0 = F F^0=F F0=F。多模态 Transformer 编码器的输出为 F E = F M F_E=F^M FE=FM。
在多模态 Transformer 编码器之后,将输出的 F E F_E FE 再拆分为视觉特征 F v ∈ R N v × C F_v\in\mathbb{R}^{{N}_v\times C} Fv∈RNv×C 和语言特征 F l ∈ R N l × C {F}_l\in\mathbb{R}^{{N}_l\times C} Fl∈RNl×C,将位置 embedding P P P 划分为视觉位置 embedding P v ∈ R N v × C P_v\in\mathbb{R}^{{N}_v\times C} Pv∈RNv×C 和语言位置 embedding P l ∈ R N l × C P_l\in\mathbb{R}^{{N}_l\times C} Pl∈RNl×C 。之后将这些特征同位置 embedding 一起输入到动态 Transformer 解码器中。
4.4 动态多模态 Transformer 解码器
多模态 Transformer 编码器的计算量非常大,于是本文引入动态采样到多模态 Transformer 中,并提出一种动态多模态 Transformer 解码器,仅需要少量有区分性的视觉特征,而消除了需要依赖于输入图像尺寸的解码复杂度问题。
动态多模态 Transformer 解码器有 N N N 层,每层由两个子模块组成:2D 自适应采样+文本引导的解码。前者在 2D 特征图上采样少数量的空间点,后者解码这些采样特征。
4.4.1 2D 自适应采样

如上图 (a) 所示,提出的 2D 自适应采样模块在 2D 图像空间上采样视觉特征,通过预测相关的 offsets 来得出参考点。随着解码器层不断加深,采样点也会逐渐地汇聚在指代目标上,要么落在边界内或者边界上。因此,2D 自适应采样方法能够提取出被定位目标上有区分性的点,因此能更好的捕捉几何关系。
2D 自适应采样模块由三部分组成:一个自适应 query 生成器,一个 offsets 生成器,一个特征采样模块。以第 i i i 层解码器层为例,首先在语言 queries 上执行平均池化,得到语言 query f i i ∈ R C f_i^i\in\mathbb{R}^C fii∈RC。然后拼接最后一层的采样 query f i i − 1 ∈ R C f_i^{i-1}\in\mathbb{R}^C fii−1∈RC 和语言 query f i i ∈ R C f_i^i\in\mathbb{R}^C fii∈RC,之后送入到两层 MLP 生成语言引导的采样 query f s i ∈ R C f_s^i\in\mathbb{R}^C fsi∈RC,接着生成下一次的 offsets:
f s i = MLP ( [ f s i − 1 ; f l i ] ) f_s^i=\text{MLP}([f_s^{i-1};f_l^i]) fsi=MLP([fsi−1;fli])将采样 query f s i f_s^i fsi 输入到 offset 生成器(线性层)中,来输出与参考点相关的 offsets:
{ ( Δ x j i , Δ y j i ) } j = 1 P = L i n e a r ( f s i ) \{(\Delta x_j^i,\Delta y_j^i)\}_{j=1}^P=\mathrm{Linear}(f_s^i) {(Δxji,Δyji)}j=1P=Linear(fsi)其中 P P P 为采样点的数量, ( Δ x j i , Δ y j i ) (\Delta x_j^i,\Delta y_j^i) (Δxji,Δyji) 为预测的 offsets。于是在得到参考点 ( x r i , Δ y r i ) (x_r^i,\Delta y_r^i) (xri,Δyri) 的情况下,绝对采样位置可表示为:
{ x j i = x r i + Δ x j i y j i = y r i + Δ y j i \begin{cases}x_j^i=x_r^i+\Delta x_j^i\\y_j^i=y_r^i+\Delta y_j^i&\end{cases} {xji=xri+Δxjiyji=yri+Δyji根据这些采样点的位置,在视觉特征图上执行双线性插值得到采样的特征,用于后续文本引导的解码。采样出的视觉特征可表示为 F s i ∈ R R × C F_s^i\in\mathbb{R}^{R\times C} Fsi∈RR×C。类似的,采样相应的位置 embeddings P s i ∈ R P × C P_s^i\in\mathbb{R}^{P\times C} Psi∈RP×C。
参考点的坐标初始化为图像中心归一化坐标,即 ( 0.5 , 0.5 ) (0.5,0.5) (0.5,0.5)。采样 query 是随机初始化的可学习向量,语言 queries 来源于多模态 Transformer 编码器。在第一层的动态解码器层中,采样 query 生成器仅采用采样 query 作为输入而无需融合语言 queries。
4.4.2 文本引导解码

文本引导的解码模块输入为采样特征 F s i ∈ R P × C F_s^i\in\mathbb{R}^{P\times C} Fsi∈RP×C 及其位置编码 P s i ∈ R P × C P_s^i\in\mathbb{R}^{P\times C} Psi∈RP×C,结构类似于 Transformer 编码器-解码器。编码器旨在提取采样的视觉特征上下文信息,其输入为文本化的表示及语言 queries F l i ∈ R N l × C F_l^i\in\mathbb{R}^{N_l\times C} Fli∈RNl×C + 位置 embedding P l P_l Pl。对于编码器来说,计算如下:
Q D E i = K D E i = V D E i = F s i F ^ s i = LN ( Q D E i + MHA ( Q D E i + P s i , K D E i + P s i , V D E i ) ) F ^ s i = L N ( F ^ s i + F F N ( F ^ s i ) ) \begin{aligned} &Q_{DE}^i=K_{DE}^i=V_{DE}^i=F_{s}^i\\ &\begin{aligned}\hat{F}_s^i=\text{LN}(Q_{DE}^i+\text{MHA}(Q_{DE}^i+P_s^i,K_{DE}^i+P_s^i,V_{DE}^i))\end{aligned} \\ &\hat{F}_s^i=\mathrm{LN}(\hat{F}_s^i+\mathrm{FFN}(\hat{F}_s^i)) \end{aligned} QDEi=KDEi=VDEi=FsiF^si=LN(QDEi+MHA(QDEi+Psi,KDEi+Psi,VDEi))F^si=LN(F^si+FFN(F^si))其中 MHA ( ⋅ ) \text{MHA}(\cdot) MHA(⋅) 为多头注意力, F F N ( ⋅ ) \mathrm{FFN}(\cdot) FFN(⋅) 为前向传播网络, L N \mathrm{LN} LN 为层正则化。
对于解码器来说,计算如下:
K D D i = V D D i = F s i ^ , Q D D i = F l i F ^ l i + 1 = LN ( Q D D i + MHA ( Q D D i + P l , K D D i + P s i , V D D i ) ) F l i + 1 = L N ( F ^ l i + 1 + F F N ( F ^ l i + 1 ) ) \begin{aligned} &K_{DD}^{i} =V_{DD}^i=\hat{F_s^i},Q_{DD}^i=F_l^i \\ &\hat{F}_l^{i+1} \begin{aligned}=\text{LN}(Q_{DD}^i+\text{MHA}(Q_{DD}^i+P_{l},K_{DD}^i+P_{s}^i,V_{DD}^i))\end{aligned} \\ &F_{l}^{i+1} =\mathrm{LN}(\hat{F}_l^{i+1}+\mathrm{FFN}(\hat{F}_l^{i+1})) \end{aligned} KDDi=VDDi=Fsi^,QDDi=FliF^li+1=LN(QDDi+MHA(QDDi+Pl,KDDi+Psi,VDDi))Fli+1=LN(F^li+1+FFN(F^li+1))
4.4.3 建模效率的讨论
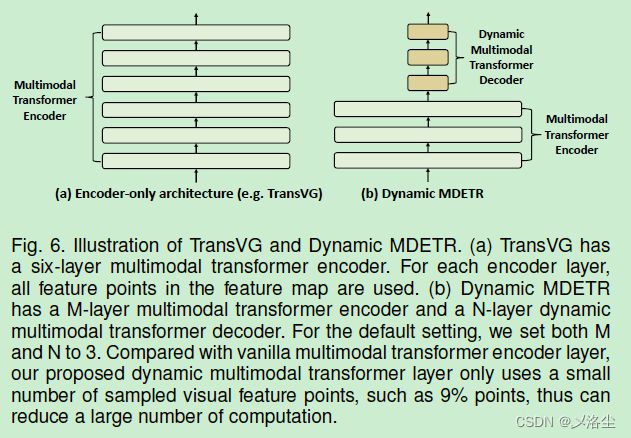
如上图所示,左边经典的 Transformer 结构能够有效建模两种模态间的关联,但自注意力和跨模态注意力使得计算成本非常高。相比之下,动态 MDETR 提出将视觉定位过程分解为编码和解码阶段。在编码阶段,主要关注于视觉语言模态的特征对齐,在解码阶段,通过文本来提取被定位目标的视觉位置。通过 2D 自适应采样,动态 Transformer 解码器使用少数量的采样点,例如 36 个点来减少计算量。
4.5 预测头
根据动态 Transformer 解码器的输出 F D ∈ R N l × C F_D\in\mathbb{R}^{N_l\times C} FD∈RNl×C 和填充的 mask m l ∈ R N l m_l\in\mathbb{R}^{N_l} ml∈RNl,计算无 mask 的平均 tokens f r e g ∈ R C f_{reg}\in\mathbb{R}^{C} freg∈RC。然后将 f r e g f_{reg} freg 送入预测头中。预测头由 3 层全连接 + ReLU 激活层组成。预测头直接回归出 4D 的 bounding box 坐标:
b ^ = ( x ^ , y ^ , w ^ , h ^ ) = M L P ( f r e g ) \hat{b}=(\hat{x},\hat{y},\hat{w},\hat{h})=\mathrm{MLP}(f_{reg}) b^=(x^,y^,w^,h^)=MLP(freg)其中 ( x ^ , y ^ ) (\hat{x},\hat{y}) (x^,y^) 为归一化的中心坐标, ( w ^ , h ^ ) (\hat{w},\hat{h}) (w^,h^) 为预测 bounding box 的宽度和高度。
4.6 损失函数
采用 L1 损失和尺寸不变的通用 IoU 损失作为优化目标。具体来说,将预测的 bounding box 视为 b ^ = ( x ^ , y ^ , w ^ , h ^ ) \hat{b}={(\hat{x},\hat{y},\hat{w},\hat{h})} b^=(x^,y^,w^,h^),目标 Box 为 b = ( x , y , w , h ) b=(x,y,w,h) b=(x,y,w,h)。于是损失函数为:
L = L L 1 ( b , b ^ ) + L G I o U ( b , b ^ ) \mathcal{L}=\mathcal{L}_{L1}(b,\hat{b})+\mathcal{L}_{GIoU}(b,\hat{b}) L=LL1(b,b^)+LGIoU(b,b^)其中 L L 1 ( ⋅ ) \mathcal{L}_{L1}(\cdot) LL1(⋅) 和 L G I o U ( ⋅ ) \mathcal{L}_{GIoU}(\cdot) LGIoU(⋅) 为 L1 损失和 GIoU 损失。
五、实验
5.1 数据集和评估指标
RefCOCO/RefCOCO+/RefCOCOg、ReferItGame、Flickr30K Entities。
Top-1 accuracy (IoU ≥ 0.5)。
5.2 实施细节
和 TransVG 类似,长边为 640,短边用 RGB 平均值填充到 640。RefCOCOg 句子长度 40,其他数据集 20。视觉 Backbone 初始化采用 ResNet,Transformer 编码器采用 DETR 的权重,语言编码器采用 BERT 无级联的版本。多模态编码器层和动态多模态解码器层的数量都为 3。采样点的数量默认为 36 点。
采用 Adamw 优化器,90 epoches。权重衰减 1 0 − 4 10^{-4} 10−4,dropout ratio 0.1。编码器的初始学习率为 1 0 − 5 10^{-5} 10−5,其他参数为 1 0 − 4 10^{-4} 10−4。在 RefCOCO/RefCOCO+/RefCOCOg 和 ReferitGame 数据集上,在第 60 个 epoch 时,学习率降低 10%。在 Flickr30K Entities 数据集上,训练 60 个 epoches,在第 40 个 epoch 时,学习率降低 10%,也不设置权重衰减和 dropout。Batch_size 128。数据增强采用 TransVG 相同的手段。
对于 CLIP 编码器,采用 ViT-B/16。多模态编码器层和动态多模态解码器层的数量也都为 3。采样点的数量默认为 160 点。训练 60 个 epoches,在第 45 个 epoch 时,学习率降低 10%。预训练特征编码器的初始学习率设为 5 × 1 0 − 6 5\times 10^{-6} 5×10−6,其他参数为 1 0 − 4 10^{-4} 10−4。在初始的 10 个 epoches 中,冻结 CLIP 编码器。而在 ReferItGame 数据集上,同样移除 dropout 和权重衰减,训练 90 个 epoches,在第 60 个 epoches 上,权重衰减 10%,但不冻结 CLIP 权重。对于 Flickr30K Entities 数据集,训练模型 40 个 epoches ,在第 30 个 epoches 上,权重衰减 10%,在最初的 6 个 epoches 上,冻结 CLIP,Batch_size 为 56。
这一部分应该是换人写了,太水了,整个实验细节写的罗里吧嗦。废话太多,有凑字数的嫌疑。
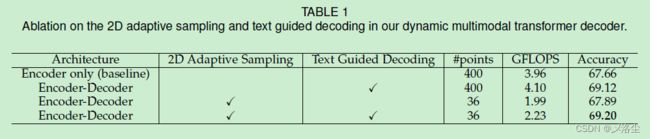
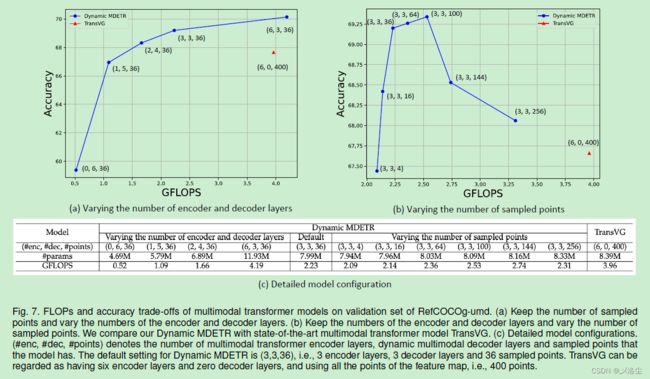
5.3 消融实验
以 ResNet-50 为 Backbone,在 RefCOCOg-umd 验证集上进行实验。
动态多模态编码器中的关键设计
精度和计算量的权衡
不同的初始化采样策略

动态采样 vs. 静态采样

与其他动态 Transformer 的比较

5.4 与其他 SOTA 方法的比较


5.5 可视化
不同解码器层的采样点

文本到图像编码器注意力图的可视化

六、结论
本文解决了图像中的空间冗余问题,提出了 Dynamic MDETR 用于视觉定位。核心设计是一个动态多模态 Transformer 解码器,由一个 2D 自适应采样模块和一个文本引导的解码模块组成。动态多模态 Transformer 解码器能够选择少部分的信息点来加快后续的文本引导的解码过程。实验很有效。此外,还验证了 Dynamic MDETR 的泛化能力,通过建立第一个 CLIP 的视觉定位框架实现了 SOTA 的性能。希望可以拓展到视频领域的空间定位上。
写在后面
前面部分一直到方法写的还可以,但从实验部分到后续结论之前,感觉是换人写了,后面太啰嗦了,太多废话,能看出来有些东西就是硬凑字数好突出工作量。如果代码不放出来,这篇文章的贡献也不如作者说的那么强,毕竟之前单模态图像领域已经有很多减小冗余的工作了。