机器学习洞察 | 降本增效,无服务器推理是怎么做到的?
2022 年,无服务器推理受到了越来越多的关注。常见的推理方式包括实时推理、批量转换和异步推理:

-
实时推理:具有低延迟、高吞吐、多模型部署的特点,能够满足 A/B 测试的需求
-
批量转换:能够基于任务 (Job-based) 的系统进行大数据集的处理
-
异步推理:具有近实时、大负载 (1 GB) 的优势,但推理时间较长(一般在 15 分钟内)
本文将为您重点介绍在机器学习中无服务器推理的发展和演变,并通过实际的场景分析和部署方式来分享无服务器推理的应用,下面就一起来看看吧:
为什么选择无服务器推理
无服务器推理本身是个相对宽泛的术语。对于开发者来说,无服务器推理代表了一种构建可自动扩展的新型应用程序的具体方式,其最突出的优势在于无需维护、运行或修复包括服务器、集群乃至负载均衡器在内的各类基础设施元素。
通常开发者在无法预测用户的访问模式时会考虑使用无服务器推理:
| 亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库! |
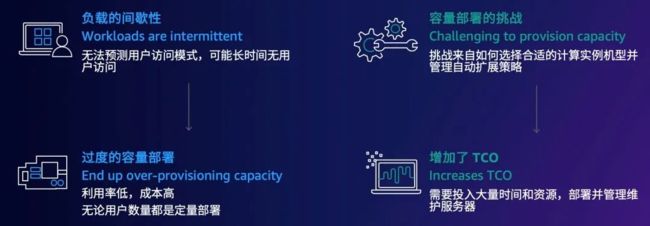
有些情况下,上线应用时会存在负载的间歇性。如果开发者不考虑用户用量而使用定量部署模式的话,当应用长时间没有用户访问时就会导致过度的容量部署,造成利用率低而成本高。
而当用量增加,面临容量部署的挑战时,开发者需要投入大量的时间和资源,部署并管理维护服务器的弹性扩展,导致 TCO (Total Cost of Ownership) ,即总拥有成本的增加。
我们通过下面这个具体的场景帮助开发者更好地理解无服务器推理:
Sarah 是一家线上订餐应用的 DevOps 的开发人员,她希望通过机器学习来为客户个性化的推荐餐厅。由于应用的访问流量不可预测,Sarah 面临管理配置自动扩展策略的挑战,担心由于过量部署资源而导致成本过高。
Sarah 决定采用无服务器推理的方式。
她不再需要自己管理配置扩展策略,也无需过量部署资源,而是根据应用的用量按需自动伸缩。全托管服务不仅节省了 Sarah 的时间也降低了推理成本,让她可以把更多的时间和资源投入到优化算法和项目上。


无服务器推理的优势
从 Sarah 的例子我们可以看出无服务器推理的优势是能够实现模型的开箱即用,帮助开发者降低机器学习的成本。
具体来说,对比早期的 Amazon Lambda 无服务器推理,开发者仍然需要配置模型参数(例如使用 EFS 放置模型时,需要自行配置 EFS 访问的终端节点来完成推理)。而 Amazon SageMaker 无服务器的推理方式拥有更好的封装,能够形成一个独立的特征和服务特性。开发者不需要自己搭建部署无服务器推理的其他工作,而是将更多的精力和资源聚焦于具体业务逻辑的实现。
Amazon SageMaker 的服务器推理能够在抽象基础设施的同时,显著降低间歇性流量工作负载的成本。
全托管的无服务器化推理
全托管的无服务器化推理有三大优势:拥有全托管的基础资源、无服务器化、能够自动伸缩资源。

-
拥有全托管的基础资源等于拥有安全、监控、日志记录、高可用、高容错的资源。
-
无服务器化代表着用户无需选择服务器类型和容量,能够直接基于推理需求来进行内存大小的选择。
-
自动伸缩资源代表着无需配置扩展策略。
一键部署无服务器化推理节点
完成无服务器化推理节点部署需要三个步骤:

- 用 ECR 镜像来存放推理代码;
- 用 S3 存放模型文件;
- 选择合适的内存大小。
在第二步中,Amazon SageMaker 将通过无服务器化推理终端节点实现自动管理计算资源;按需自动伸缩;管理日志、监控及安全。客户端应用或其它云服务将触发推理请求给无服务器化推理终端节点,而无服务器化推理终端节点经过处理后,再将推理结果发给最终客户。
代码示例:Amazon SageMaker 无服务器推理
创建节点配置:开发者需要对用户端配置内存使用大小,以及最大并发推理的调用数。
endpoint_config_response = client.create_endpoint_config(
EndpointConfigName=xgboost_epc_name,
ProductionVariants=[
{
"VariantName": "byoVariant",
"ModelName": model_name,
"ServerlessConfig": {
"MemorySizeInMB": 4096,
"MaxConcurrency": 1,
},
},
],
)创建节点及推理:
response = runtime.invoke_endpoint(
EndpointName=endpoint_name,
Body=b".345,0.224414,.131102,0.042329,.279923,-0.110329,-0.099358,0.0",
ContentType="text/csv",
)
print(response["Body"].read())完整代码可参考如下链接:
https://github.com/aws/amazon-sagemaker-examples/blob/main/serverless-inference/Serverless-Inference-Walkthrough.ipynb?trk=cndc-detail
希望这篇文章可以帮助您更清晰地了解机器学习在无服务器推理方面的进展。您也可以在 Build On Cloud 视频号观看这一部分的视频演讲:
点击查看视频:https://dev.amazoncloud.cn/video/videoDetail?id=63e393ace5e05b6ff897ca17&sc_medium=regulartraffic&sc_campaign=crossplatform&sc_channel=CSDN
欢迎阅读《机器学习洞察》系列文章中查看对于多模态机器学习和分布式训练的解读。下一篇文章我们将介绍有关 JAX 框架的演进趋势,请持续关注 Build On Cloud 微信公众号。
往期推荐
- 机器学习洞察 | 挖掘多模态数据机器学习的价值
- 机器学习洞察 | 分布式训练让机器学习更加快速准确

作者黄浩文
亚马逊云科技资深开发者布道师,专注于 AI/ML、Data Science 等。拥有 20 多年电信、移动互联网以及云计算等行业架构设计、技术及创业管理等丰富经验,曾就职于 Microsoft、Sun Microsystems、中国电信等企业,专注为游戏、电商、媒体和广告等企业客户提供 AI/ML、数据分析和企业数字化转型等解决方案咨询服务。
文章来源:https://dev.amazoncloud.cn/column/article/63e33010e5e05b6ff897ca0d?sc_medium=regulartraffic&sc_campaign=crossplatform&sc_channel=CSDN