OpenCV14:Haar特征
首先,我们需要了解特征是什么?所谓特征,就是某个区域的像素点经过某种运算后得到的结果。
其中,结果可能是 具体值、向量、矩阵
那么如何利用特征区分目标(即如何判断特征)?方法之一是,类似于阈值判决的方式区分。
所以问题又来了,如何得到这个判断条件呢?这时就要用到机器学习部分的内容。
总的来讲,分为三个问题:
1、弄清特征是什么。
2、如何判决特征。
3、如何得到这个判决(即如何得到判断条件)。
同样的,我们在学习haar特征的时候也是围绕这三个问题去探讨。
首先什么是haar特征?
haar特征有以下15种:
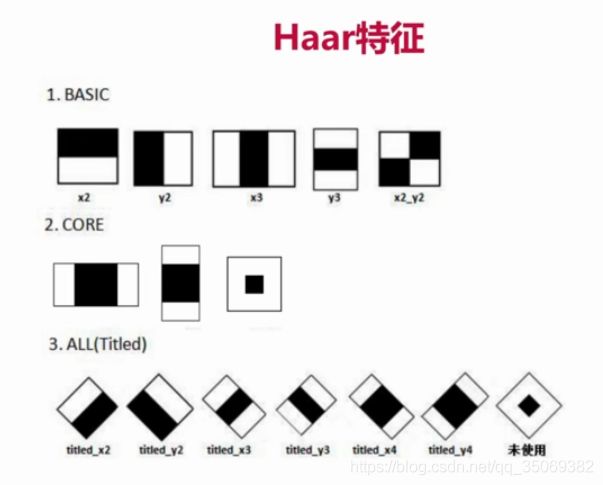
那么我们以第一种haar特征为例来讲述。

蓝色背景表示我们定义的图片,黑白矩形框表示haar特征模板,
假设模板范围为10*10,则该模板覆盖了100个像素点,黑色区域占50,白色区域占50
将当前的黑白两色模板放到图片任意位置,然后白色区域覆盖的50个像素点值之和 减去 黑色区域覆盖的50个像素点值之和,就得到了haar特征
即 haar特征 = sum(白)- sum(黑)
此外,还有其他计算方式: haar特征 = 整个区域像素点值 * 权重 + 黑色区域像素点值 * 权重。 这里的区域指10*10的区域。
接下来,我们考虑如何利用特征进行阈值判决?
Haar特征一般与Adaboost分类器结合在一起使用,因此简略介绍一下Adaboost。
Adaboost分类器的优点是:前一个基本分类器分出来的样本会在下一个分类器中得到加强。加强后的全体样本再次被用来训练下一个分类器。
比如 我们有三个苹果,一个香蕉
苹果 苹果 苹果 香蕉
0.1 0.1 0.1 0.5
由于香蕉不是我们期望的,因此在第一次训练后香蕉的系数比较大为0.5,我们将这个结果再次训练,那么苹果的系数会越来越小,香蕉的系数会越来越大。直到迭代的最大次数终止,或者,迭代到 训练出来的正确率大于等于设置好的最低值 终止。
1)Adaboost分类器的结构
一般的目标要通过15-20个强分类器,若一个目标能通过规定数量的强分类器,则视为预期结果。列如,有三个强分类器,给他们一个输入,如果由Haar特征计算出来的结果满足 X1 > ST1 and X2 > ST2 and X3 > ST3,(其中X1、X2、X3为Haar特征的代表值;ST1、ST2、ST3为三个强分类器的阈值),则被视为苹果。
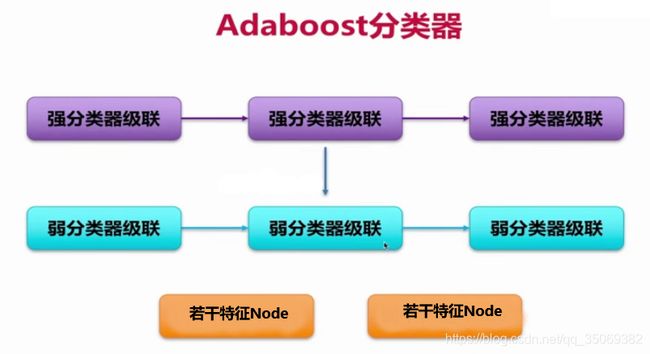
强分类器的作用是判断当前阈值与当前特征是否吻合,来达到目标判决的效果。
弱分类器的作用是计算Haar特征的X1、 X2、 X3。例如(如上图所示) X2 = sum(y1,y2,y3),其中 ![]() 指弱分类器的计算结果。
指弱分类器的计算结果。
那么 ![]() 如何得到呢?如上图所示,它是由Node节点计算得来。在OpenCV中一个弱分类器最高支持三个Haar特征,每一个Haar特征构成一个Node节点,因此每个特征都看成一个节点。
如何得到呢?如上图所示,它是由Node节点计算得来。在OpenCV中一个弱分类器最高支持三个Haar特征,每一个Haar特征构成一个Node节点,因此每个特征都看成一个节点。
以Node1为例,其对应特征Haar1,
若 Haar1 > Node1的阈值(NodeT1),则 特征Haar1对应特征节点Node1的值 z1 = alpha1;
相反,若 Haar1 < Node1的阈值(NodeT1),则 特征Haar1 对应特征节点Node1的值 z1 = alpha2;
类似的,可以计算另外两个Haar特征对应的特征节点(Node2、Node3)的值z2、z3。
那么我们就可以得到Node节点之和 Z = sum(z1,z2,z3)
若 Z > 弱分类器的阈值( WT ),则 y1 = AA(某个值)
相反,若 Z < 弱分类器的阈值( WT ),则 y1 = BB(某个值)
上面的解释是从最上层的强分类器逆着推,那么,我们将其总结一下,从最底层的Node节点向上叙述。
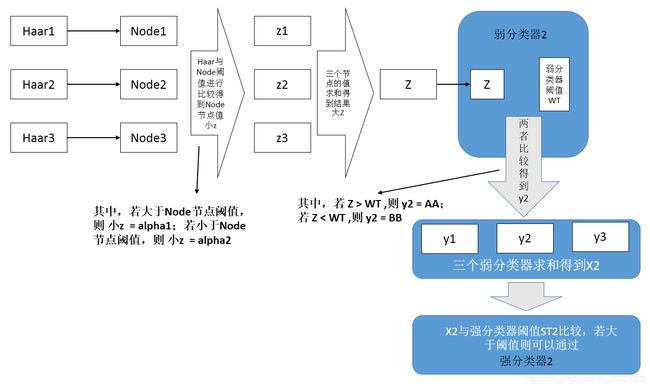
首先,每一个Node节点对应一个Haar特征,这是最底层,OpenCV中一个弱分类器规定最多三个Haar特征。
然后,Node节点本身存在阈值,经Node节点计算出来的Haar特征与其做比较,会得到新的值小 z ,这个值就是Node节点的值。
这时,将三个小z求和,得到大Z。作为输入,送至弱分类器,与弱分类器阈值WT比较,得到y值。
将三个y值求和,得到 X 。作为输入,送至强分类器,与强分类器阈值ST比较,可判断特征与目标是否吻合。
若可以连续通过三个强分类器,则说明判断的目标和原目标一致。
2)Adaboost分类器计算过程
见上面黑体所述
3) Adaboost分类器文件结构:xml类型